
Quelle est la différence entre l'apprentissage automatique et l'analyse des données, qui siège à Odnoklassniki et comment commencer votre voyage dans l'apprentissage automatique - nous en parlons dans le douzième numéro de talk-shows pour les programmeurs.
Vidéo sur la chaîne TechnostreamL'hôte du programme est Pavel Shcherbinin, directeur technique des projets médiatiques, et l'invité est Dmitry Bugaychenko, analyste à Odnoklassniki.
00:56 Dmitry Bugaychenko: de l'externalisation à l'activité OK et scientifique
02:42 Pourquoi combiner le travail à l'université et dans une grande entreprise
02:57 Où l'apprentissage automatique est appliqué dans OK
03:49 Apprentissage automatique et analyse des données - quelle est la différence?
05:08 Screencast «Nous analysons le public OK à l'aide de l'analyse des données»
22:34 Les camarades de classe
sont-ils un service de rencontres?
24:07 Par où commencer à apprendre le Machine Learning?
25:33 Dois-je participer à des championnats d'apprentissage automatique?
26:53 Comment s'entraîner en OK
28:18 Manuel d'apprentissage automatique
30:28 Événements d'apprentissage automatique
32:48 Comment le pipeline de données est-il organisé en OK (montrer au tableau)
43:42 Sondage éclairParlez un peu de vous.Nous pouvons supposer que mon cheminement de carrière a commencé en 1999, lorsque je suis entré en mathématiques. Pendant cinq ans, il a étudié activement les mathématiques, la programmation et diverses disciplines connexes. Il a ensuite travaillé assez longtemps dans une société d'externalisation. L'externalisation est une expérience très intéressante. J'ai réussi à travailler dans une grande variété de projets, de l'écriture d'un pilote pour un réfrigérateur à la création de systèmes d'entreprise distribués.
Pendant tout ce temps, en plus du travail principal, j'ai enseigné à l'université afin de maintenir le contact avec la communauté académique, ce qui était assez difficile. Quand en 2011 j'ai été invité à Odnoklassniki pour m'engager dans des systèmes de recommandation, c'était une très bonne chance, dont j'ai profité. Ici, il est possible de combiner à la fois la préparation mathématique de l'université et l'expérience pratique de la programmation. Cependant, je continue d'enseigner à l'université.
L'enseignement prend-il beaucoup de temps?1,5 jour par semaine va à l'université, mais ça vaut le coup, car nous avons déjà trois de mes anciens étudiants dans le personnel. Autrement dit, l'université fonctionne également comme une forge de personnel.
Au travail, reliez-vous calmement au fait que vous êtes parti pendant 1,5 jour?A démissionné. Tout le monde comprend ce que cela rapporte, donc je ne rencontre aucune opposition.
Dites-moi où l'apprentissage automatique est utilisé à Odnoklassniki.Nous avons beaucoup d'applications. Historiquement, le premier système d'apprentissage automatique était la recommandation musicale. Tout a commencé en 2011. Ensuite, il y a eu une croissance tout simplement explosive: la recommandation des communautés, la recommandation d'amis, "peut-être que vous vous connaissez", tente de classer le contenu dans le flux de la personne. Maintenant, de nombreux projets se développent. Quelle que soit la partie d'Odnoklassniki que vous piquez, il existe des composants liés soit à l'apprentissage automatique, soit à l'analyse des données.
Aidez nos lecteurs à séparer ces deux concepts: l'apprentissage automatique et l'analyse des données.Les données sont analysées par une personne pour trouver des schémas, des connexions, tester certaines hypothèses. Pour cela, différents moyens de statistiques mathématiques sont utilisés. L'apprentissage automatique est un moyen plus avancé de rechercher des modèles, en utilisant des techniques qui sont généralement basées sur une sorte de modèle grand et complexe avec un grand nombre de paramètres.
Nous essayons de sélectionner les paramètres de ce modèle afin qu'il décrive bien le phénomène dont nous avons besoin. Il existe de nombreux algorithmes différents, des méthodes d'énumération des paramètres, mais tout cela est fait afin de trouver une certaine régularité. Par exemple, d'après les données d'un message publié sur un réseau social, évaluez la probabilité qu'une personne en particulier mette une «classe» sur ce message. Autrement dit, l'apprentissage automatique est un outil d'analyse de données.
Pourriez-vous et moi démystifier l'un des mythes sur Odnoklassniki, selon lequel ce public a un public très âgé?Pas de problème. Il s'agit d'une carte qui reflète en temps réel les connexions de chaque utilisateur spécifique. Autrement dit, chaque point est une personne qui s'est connectée et fait quelque chose dans Odnoklassniki.
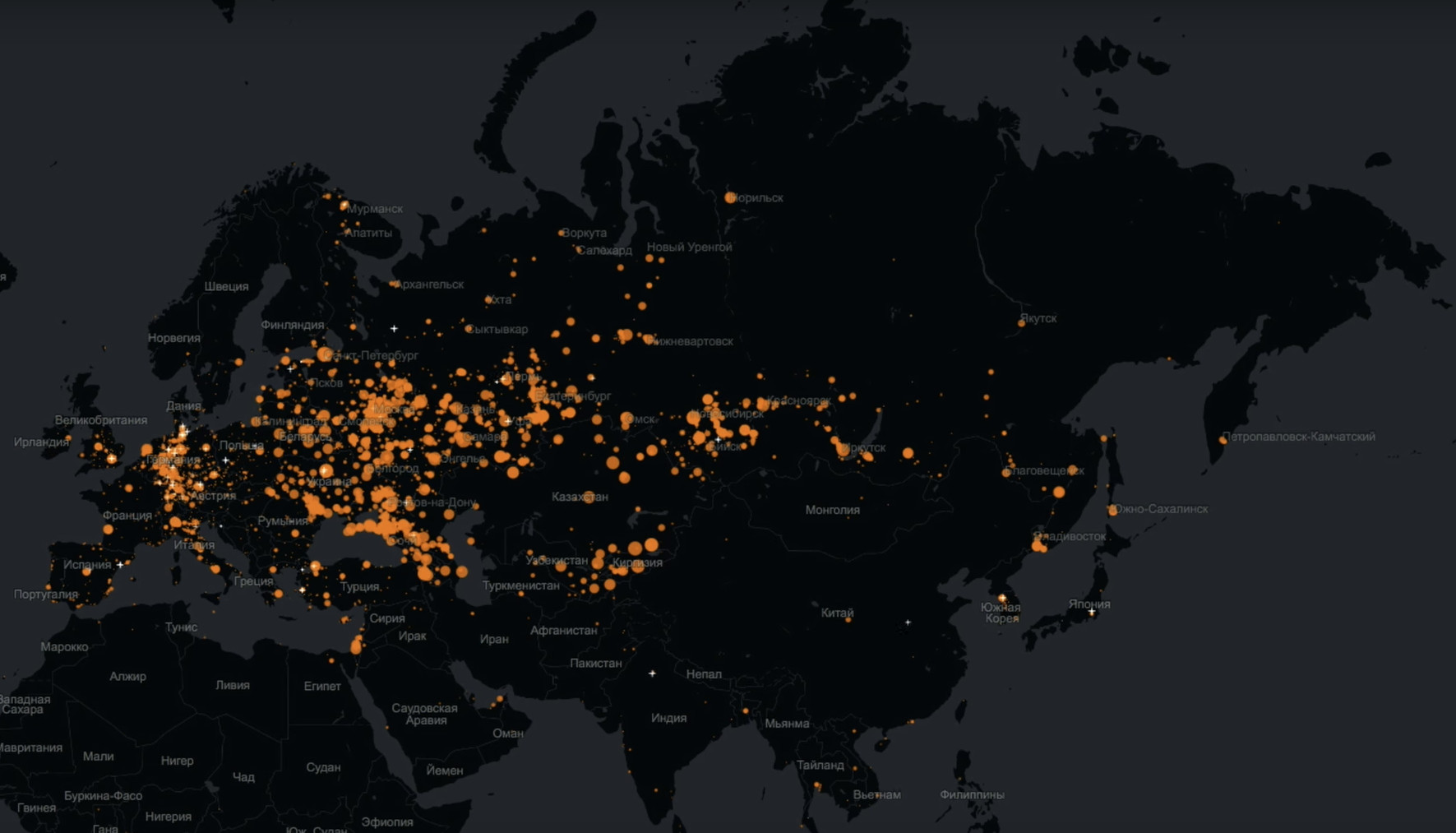
Les grands cercles rouges sont des villes dont de nombreux utilisateurs sont venus vers nous. Il est très clairement visible ici que Odnoklassniki n'est pas seulement vivant, ils couvrent presque toute l'Eurasie.
Calculons combien d'utilisateurs ont mis «classe» à Odnoklassniki hier, et voyons la répartition par âge.
Où commence le codage? Bien sûr, de l'importation de diverses données utiles pour de futurs calculs d'agrégats. Notre principal outil est
Spark , pour l'accès auquel nous utilisons le front Web
Zeppelin . Fondamentalement, les données transitent par
Apache Kafka , sont regroupées et divisées en différents blocs. Dans ce cas, nous sommes intéressés par le bloc qui décrit l'activité des utilisateurs d'hier, en particulier les classes. Il existe un champ dans lequel les données démographiques des utilisateurs sont stockées, y compris les anniversaires.

La sortie est l'année de naissance des dix premiers enregistrements. Essayons maintenant de construire un agrégat à partir de cela. Nous voulons compter le nombre d'utilisateurs uniques. Nous avons besoin de l'identifiant et de l'année de naissance, regrouper par année et calculer le nombre d'utilisateurs uniques. Et jouons un peu: il y aura sûrement des gens dont l'année de naissance n'est pas indiquée, donc nous les filtrerons afin qu'ils ne créent pas de bruit sur le graphique.
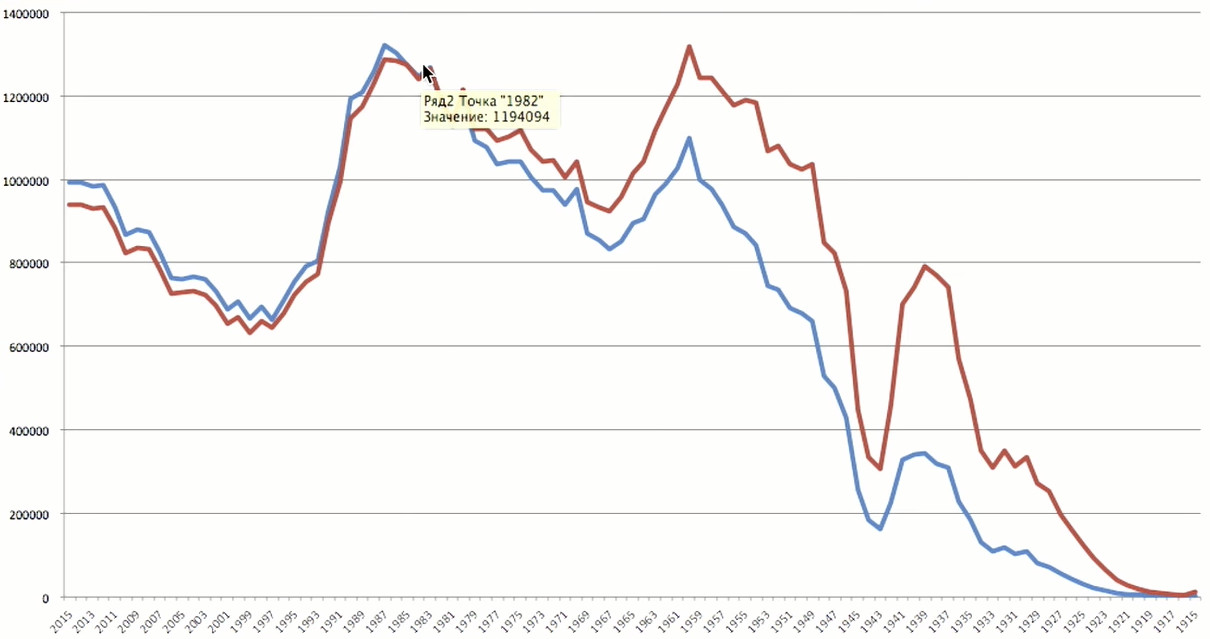
Pour effectuer le calcul, le système doit pelleter environ 1 To de données. Nous obtenons le résultat et le présentons graphiquement:

Le pic d'âge tombe entre 1983 et 35 ans. Ce sont des utilisateurs assez âgés pour eux-mêmes.
Pour mieux représenter la situation, il n'y a pas suffisamment d'informations provenant d'une seule source. Si nous parlons de la démographie des utilisateurs, la source de comparaison la plus intéressante est les statistiques sur la population de la Russie. Depuis le site Web de
Rosstat, j'ai téléchargé les données sur les années de naissance des Russes, collectées en 2016.
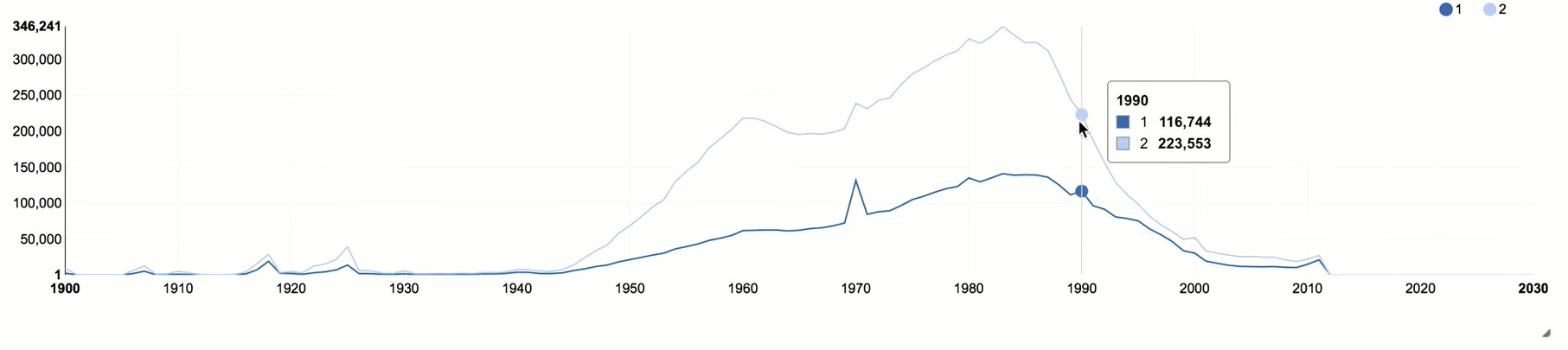
Le pic des statistiques est très proche du pic selon Odnoklassniki - nous avons des utilisateurs nés en 1983 et Rosstat - 1987. Ce qui m'a frappé, ce sont deux gros échecs. La fosse du début des années 40 est la Grande Guerre patriotique. La guerre nous a coûté non seulement plus de 20 millions de morts, mais aussi des millions de personnes à naître. C'est le gouffre démographique qui se fait encore sentir. La deuxième fosse - les années 1990. Et nous ne nous sommes pas complètement remis de cette crise. On voit la même image dans les données d'Odnoklassniki: après 1990, il y a eu une forte baisse. Nous ne pouvons toujours pas avoir de personnes nées en 2015, car l'âge minimum pour l'inscription est de 5 ans.
Ajoutez l'attribut de genre à notre échantillon et groupe non seulement par année, mais aussi par sexe.
Après 1990, il y a une forte baisse, qui est en corrélation avec la situation générale de l'âge en Russie. Les femmes mettent la «classe» beaucoup plus activement, presque deux fois plus que les hommes. C'est une image assez typique pour les réseaux sociaux, car les femmes sont plus actives socialement que les hommes.
Vous pouvez également faire attention à plusieurs pics en corrélation avec les années «rondes». Sur la base de ces pics, on peut évaluer l'influence des robots ou des personnes qui faussent délibérément leur âge, car dans de tels cas, ils indiquent généralement une sorte de date ronde.
Nous nous intéressons également à la répartition géographique de nos utilisateurs. Nous avons besoin d'un identifiant d'utilisateur pour compter les visiteurs uniques et les adresses de résidence indiquées dans les profils. Groupez par ville et calculez l'unité. Trier par le nombre d'utilisateurs en ordre décroissant et ne laisser que les 200 premières villes. Exécuter l'agrégation:

C'est la meilleure ville en termes de nombre de camarades de classe qui l'ont mise à Odnoklassniki. Naturellement, Moscou est en tête. Le sud de la Russie est bien mieux représenté que le nord-ouest. Nous avons des utilisateurs aux États-Unis, au Canada, beaucoup en Allemagne, beaucoup en Israël. Fait intéressant: 36 000 personnes de Yuzhno-Sakhalinsk ont aimé chaque jour. Et au total, selon Wikipédia, 180 000 personnes vivent dans la ville. 20% de la population de Yuzhno-Sakhalinsk est allée à Odnoklassniki et a placé une «classe».

Zoomez et voyez ce qui se passe à Moscou et dans la région de Moscou.

Les républiques d'Asie centrale, la Moldavie et l'Ukraine sont très bien représentées à Odnoklassniki.

Vous pouvez immédiatement voir où ils ont essayé de bloquer l'accès à notre réseau social, et où non.
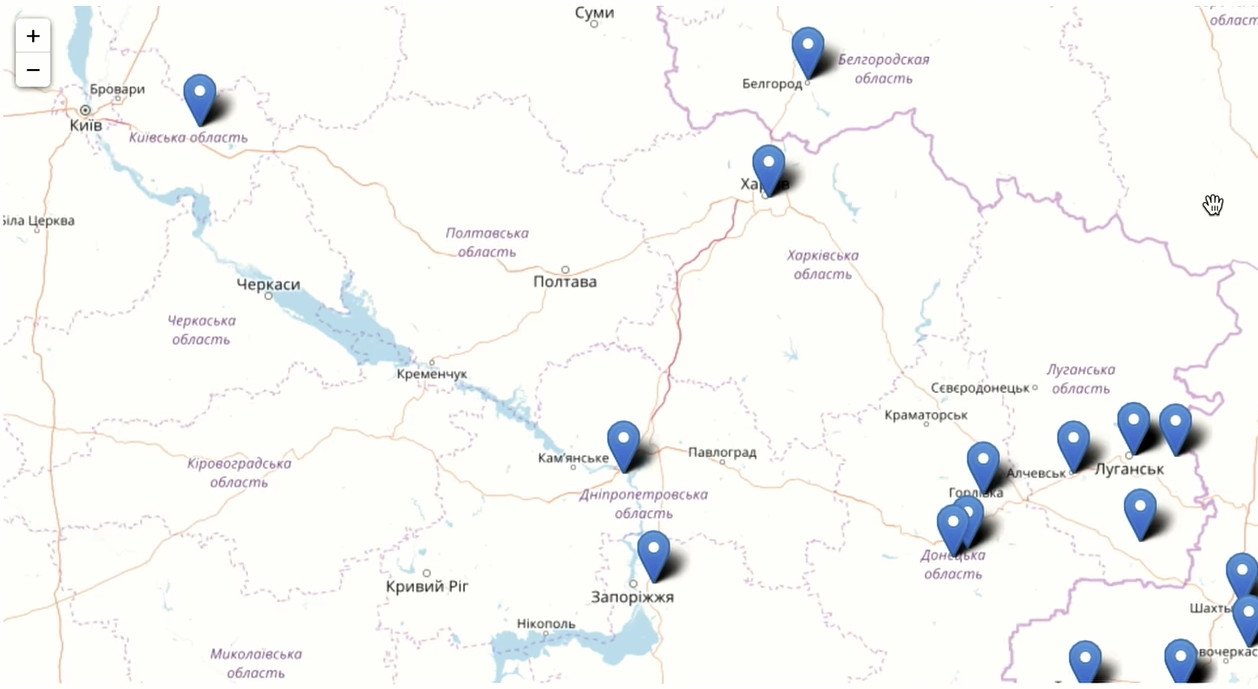
Comme vous pouvez le voir, Odnoklassniki est un produit vivant et dynamique qui est utilisé par les jeunes et les personnes âgées du monde entier, parfois même là où vous ne vous y attendez pas. Parmi toutes les catégories d'âge, nous avons le plus de 30 ans.
Les réseaux sociaux sont construits autour des communautés. Il arrive souvent que si une communauté est entrée dans un certain réseau social, elle en sait très peu sur les autres réseaux sociaux. Par conséquent, par exemple, la communauté professionnelle des journalistes peut avoir l'illusion qu'Odnoklassniki est principalement un public âgé. En fait, c'est l'opinion subjective d'une communauté. Nous avons des utilisateurs âgés de 50 à 60 ans et plus, il y a des écoliers, il y a des jeunes de 20 ans, il y a des gens matures et matures de 30 à 35 ans.
La couverture d'Odnoklassniki couvre toutes les régions de la Russie, les pays voisins, l'Ukraine, la Biélorussie et l'Asie centrale. Nous avons très bien représenté les diasporas, par exemple, la diaspora allemande d'émigrants russes, la diaspora américaine et israélienne. Ils communiquent assez activement avec leurs proches restés en Russie et dans les anciennes républiques soviétiques. De ce point de vue, Odnoklassniki contribue très bien à la mise en œuvre de la fonction de base d'un réseau social - maintenir des contacts entre des personnes vivant loin les unes des autres.
Il y a une opinion que Odnoklassniki est si attrayante pour beaucoup parce que c'est un moyen facile de rencontrer des amis et des connaissances de vos amis et parents. Autrement dit, Odnoklassniki est présenté comme un service de rencontres. Combien cette façon de dater est-elle demandée et fait-elle partie de l'idéologie d'Odnoklassniki?Le besoin de rencontrer d'autres personnes, y compris le sexe opposé, est un besoin humain fondamental. Naturellement, il s'exprime dans n'importe quel réseau social. Mais à Odnoklassniki, cela ne s'exprime ni plus ni moins que dans d'autres réseaux sociaux. Nous ne mettons pas l'accent sur les services de rencontres. L'idéologie du développement de notre réseau social est basée sur une valeur commune telle que la communication entre les gens. Ce n'est pas si important pour nous que ce soit des camarades de classe qui se sont dispersés dans différentes villes ou des gens qui recherchent un compagnon. Les deux options nous conviennent parfaitement. Nous sommes heureux que les gens se soient rencontrés et aient communiqué. Mais rien de plus
Vous faites beaucoup de machine learning. Ce sujet en excite désormais beaucoup. Par où commencer, comment entrer dans ce métier?Tout d'abord, vous devez acquérir des connaissances. Il n'y a aucun problème avec cela, il y a de merveilleux cours à
Coursera , à
Stepik et dans certains programmes universitaires qui fournissent de très bonnes connaissances de base sur l'apprentissage automatique. Pour vraiment rejoindre cette sphère, vous avez besoin d'un objectif et de savoir où vous pouvez l'appliquer. Parce qu'écouter un cours abstrait est loin d'être aussi efficace que si vous vouliez vraiment résoudre un problème ou un problème.
Dans le cas des étudiants, l'option idéale est les mémoires, les dissertations. Et même dans ce cas, j'essaie de ne pas laisser tomber la tâche d'en haut, mais d'aider les idées à venir des étudiants, alors ils auront beaucoup plus de motivation.
Autrement dit, après avoir fixé un objectif, écouter des cours en ligne, puis essayer d'appliquer les connaissances. Et tout se passera.
Il me semble qu'il y a suffisamment de tâches aujourd'hui. Un grand nombre de compétitions de Sberbank, Tinkoff et de nombreuses autres sociétés ont lieu sur la quille.Bien sûr. Mais ils se concentrent tout d'abord sur ceux qui sont déjà étroitement impliqués dans l'apprentissage automatique. De plus, très souvent lors de telles compétitions, on peut observer non pas l'apprentissage automatique, mais la haine de cap. Ces modèles qui sont formés sur la quille n'aideront pas à résoudre les problèmes pratiques, car ils pilotent trop de paramètres. En conséquence, les modèles se spécialisent spécifiquement pour des compétitions spécifiques sur la quille, et seulement en eux, des résultats sont obtenus. Et si vous transférez ces modèles dans le monde réel, ils ne fonctionneront pas.
La meilleure pratique est la pratique. Comment vous entraîner avec votre équipe?Il y a tellement de façons. Si nous parlons d'équipes de recherche, nous avons alors un projet appelé OK Data Science Lab, dans lequel nous fournissons des ressources informatiques, des données, nos connaissances et notre expérience aux personnes qui souhaitent développer leurs idées liées à l'apprentissage automatique et à l'analyse des données. Et pas forcément pour un réseau social. Par exemple, nous avons une étude dans laquelle l'auteur essaie de comprendre ce qui est le plus intéressant pour les écoliers modernes.
Si vous êtes un spécialiste et que vous cherchez du travail, nous avons toujours de nombreux postes vacants liés à l'apprentissage automatique. Visitez-nous pour une entrevue.
Existe-t-il un livre, un lecteur d'apprentissage automatique?C'est un domaine en évolution si rapide que l'écriture d'un livre ou d'un lecteur d'apprentissage automatique est trop ambitieuse. Je peux recommander l'ouvrage classique «
Éléments d'apprentissage statistique ». Il s'agit des méthodes d'apprentissage machine les plus élémentaires, issues des statistiques.
Sergey Nikolenko a publié un livre sur l'apprentissage automatique en profondeur.À mon avis, l'apprentissage en profondeur n'est pas par où commencer. Si vous possédez déjà un apprentissage automatique classique, c'est une bonne option. Mais si vous ne connaissez pas encore les techniques classiques, il est faux de commencer tout de suite par le deep learning, car cela éloigne souvent le chercheur du problème, c'est un outil très puissant. Avant de l'appliquer, vous devez analyser le problème "manuellement" de manière plus simple. Et seulement alors, avec une compréhension du sujet, passez à l'apprentissage en profondeur. Sinon, votre modèle apprendra, mais pas vous. Lorsque vous devenez plus bête que votre modèle, c'est, pour le moins, inefficace. Vous ne pouvez pas développer davantage le modèle, et c'est une impasse. Par conséquent, il est préférable de commencer par maîtriser la ML classique. Cela ne signifie pas que vous devez passer des années, il est tout à fait possible de maîtriser dans un délai raisonnable.
Avez-vous des événements d'apprentissage automatique?Nous avons une série de hackathons
SNA Hackathon . Jusqu'à présent, deux fois se sont écoulées. Pour la première fois, le hackathon était consacré à l'analyse du texte et à essayer de prédire combien de «classes» un poste particulier gagnerait. Le deuxième hackathon a eu lieu il y a un an et était consacré à l'analyse des graphiques. Il y a eu de nombreux événements intéressants. Nous avons fourni des informations sur les «amitiés» de certains de nos utilisateurs, semble-t-il, un petit morceau de données d'environ 1 Go. Mais lorsque les participants qui voulaient envoyer leurs prévisions ont essayé de travailler avec lui, presque personne ne pouvait le faire, même sur des machines avec 16 et 32 Go de mémoire, tout est tombé, s'est échangé, n'a pas voulu travailler. Nous avons même dû expliquer à la hâte comment et comment ne pas travailler avec les données.
Il s'est avéré que de nombreux spécialistes de l'apprentissage automatique, même très avancés, étaient sortis des racines et avaient commencé à oublier les principes de base de la programmation. Oubliez ce qu'est la boxe, comment les tables de hachage sont structurées, quelle surcharge de mémoire peut être si vous utilisez des tables de hachage. Si vous ne pensez pas à tout cela et que vous le faites directement en Python, Java ou Scala, les problèmes décrits seront décrits. Nous avons fait une démo en Python, le même rake est dans d'autres langues. Un graphique de 40 millions de liens, qui pourrait tenir dans 200 Mo de mémoire, explose brusquement à 20 Go simplement parce que vous avez oublié comment les structures de données de base sont organisées. C'était très impressionnant à l'époque. Même si vous êtes un spécialiste de l'apprentissage automatique, vous ne devez pas oublier les bases de la programmation.
Comment votre workflow de traitement des données est-il organisé?Les utilisateurs interagissent avec tout un écosystème de nos produits. On peut conditionnellement distinguer deux niveaux: les applications frontales (applications mobiles, portail, version mobile, diverses applications supplémentaires) et la logique métier. Les fronts interagissent souvent avec les utilisateurs et ont accès à un nombre très limité de serveurs, il existe donc des méthodes spéciales dans la logique métier qui permettent aux fronts de consigner des données.
Ces données tombent dans le bus de données unique Apache Kafka. C'est le tour qui est devenu une norme de l'industrie utilisée pour collecter des données brutes. Naturellement, il est difficile d'analyser les données brutes dans Kafka, elles sont donc régulièrement transférées vers le grand et épais Hadoop. Quelqu'un peut dire que Hadoop est le siècle dernier, maintenant Spark règne. Mais Hadoop est une plate-forme sur laquelle vous pouvez exécuter de nombreux outils. Nous avons divers outils d'analyse qui tournent au-dessus de Hadoop. J'ai souvent recours à cette classification:
- Le style de saisie des données .
- Traitement par lots. Il y a une certaine quantité de données que vous traitez d'une manière ou d'une autre.
- Traitement de flux. Vous travaillez avec des données en temps réel provenant directement de flux, en l'occurrence de notre Kafka.
Si pendant le traitement par lots, il peut y avoir des retards assez graves - nous avons collecté des statistiques pendant la journée, et vous entraînez le modèle la nuit, puis dans le cas du traitement en streaming, les retards sont mesurés en unités de secondes entre la réception des données et leur traitement.
- Analyse opérationnelle . Il s'agit du contrôle et de la surveillance des processus. Sert à la production, il doit fonctionner de lui-même, sans intervention humaine.
- Analytique interactive . Ce qu'une personne fait. La vitesse de la réaction est importante ici: ils ont fait quelque chose, ont obtenu le résultat.
Dans chacune de ces niches, nous avons notre propre écosystème de produits. Par exemple, l'analyse opérationnelle par lots utilise principalement le MapReduce classique, Apache Tez et un peu de Spark. Si nous parlons d'analyse par lots interactive, il s'agit de Spark SQL et des langages de script Pig et Hive.
Bien sûr, il n'y a pas de ligne claire, car certains langages interactifs sont souvent utilisés pour l'analyse de lots opérationnels. Apache Samza. LinkedIn. 2014 . , Spark Streaming, -.
- production, . , Kafka, . Kafka — , , . , Kafka , Streaming Index. Kafka : Casandra , SMC.
, , 99 %. - Streaming Index, . , , , «» , . , .
, , -. ?Mac.
IDE?Idea.
: ?.
Pourquoi?, .
, IT- 10 ?, .
?: , . , , , .
?, . . , , . , , .
, . «»?Comme les journalistes: combien de personnes restent à Odnoklassniki.Quel super-héros aimeriez-vous être?Probablement Tony Stark.Iron Man?Oui
Pourquoi?La technologie.