
Très probablement, vous avez déjà entendu parler du langage de programmation Go, sa popularité ne cesse de croître, ce qui est tout à fait raisonnable. Cette langue est simple, rapide et repose sur une grande communauté. L'un des aspects les plus curieux du langage est le modèle de programmation multi-thread. Les primitives sous-jacentes vous permettent de créer facilement et simplement des programmes multithreads. Cet article est destiné à ceux qui veulent apprendre ces primitives: les goroutines et les canaux. Et, à travers les illustrations, je montrerai comment travailler avec eux. J'espère que cela vous sera d'une grande aide dans votre étude future.
Programmes simples et multithreads
Vous avez probablement déjà écrit des programmes à un seul thread. Habituellement, cela ressemble à ceci: il existe un ensemble de fonctions pour effectuer diverses tâches, chaque fonction n'est appelée que lorsque la précédente a préparé des données pour elle. Ainsi, le programme s'exécute séquentiellement.
Ce sera notre premier exemple - le programme d'extraction de minerai. Nos fonctions rechercheront, extrairont et traiteront le minerai. Le minerai dans la mine dans notre exemple est représenté par des listes de chaînes, les fonctions les prennent comme paramètres et renvoient une liste de chaînes «traitées». Pour un programme monothread, notre application sera conçue comme suit:
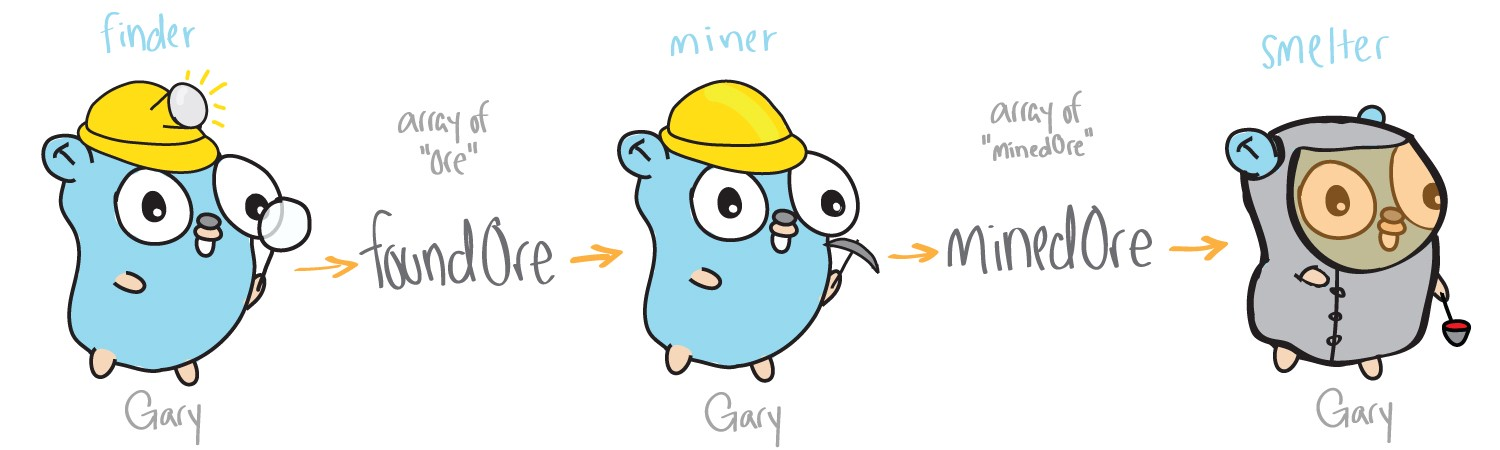
Dans cet exemple, tout le travail est effectué par un seul thread (le gopher de Gary). Trois fonctions principales: la recherche, la production et le traitement sont exécutées séquentiellement les unes après les autres.
func main() { theMine := [5]string{"rock", "ore", "ore", "rock", "ore"} foundOre := finder(theMine) minedOre := miner(foundOre) smelter(minedOre) }
Si nous imprimons le résultat de chaque fonction, nous obtenons ce qui suit:
From Finder: [ore ore ore] From Miner: [minedOre minedOre minedOre] From Smelter: [smeltedOre smeltedOre smeltedOre]
La conception et la mise en œuvre simples sont un plus d'une approche à fil unique. Mais que faire si vous souhaitez exécuter et exécuter des fonctions indépendamment les unes des autres? Ici, la programmation multithread vous est utile.
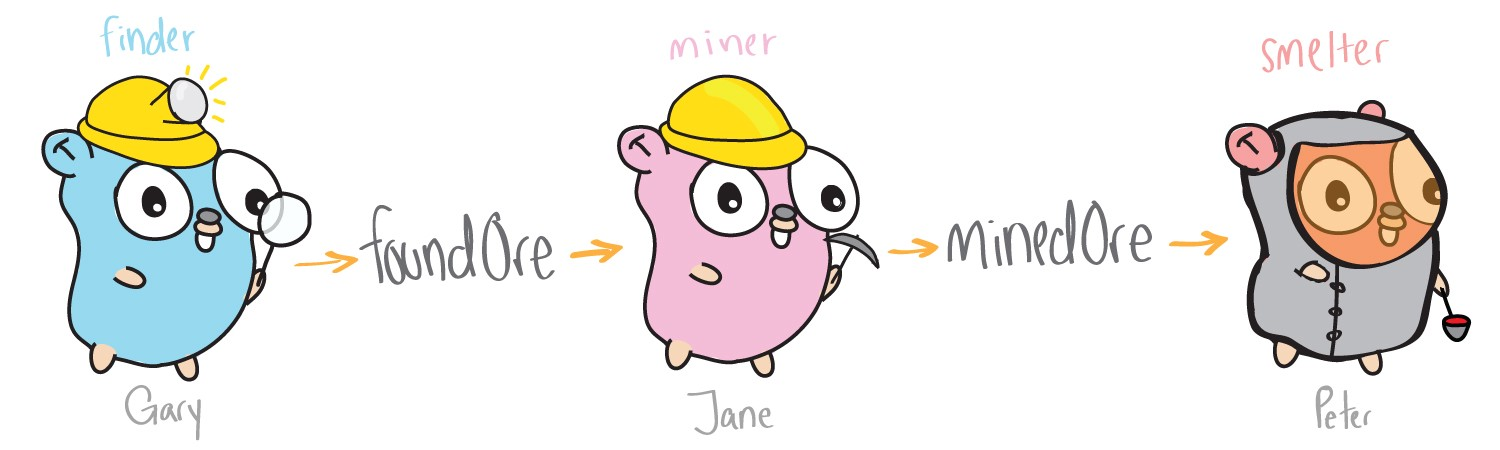
Cette approche de l'extraction du minerai est beaucoup plus efficace. Maintenant, plusieurs threads (gophers) fonctionnent indépendamment, et Gary ne fait qu'une partie du travail. Un gopher cherche du minerai, l'autre produit et le troisième fond, et tout cela est potentiellement simultané. Pour implémenter cette approche, nous avons besoin de deux choses dans le code: créer des processeurs gopher indépendamment les uns des autres et transférer le minerai entre eux. Go a des goroutines et des canaux pour cela.
Gorutins
Les goroutines peuvent être considérées comme des "threads légers", pour créer des goroutines il vous suffit de mettre le mot
- clé
go avant le code d'appel de la fonction. Pour montrer à quel point c'est simple, créons deux fonctions de recherche, appelons-les avec le mot
- clé
go et imprimons un message chaque fois qu'ils trouvent le «minerai» dans leur mine.

func main() { theMine := [5]string{"rock", "ore", "ore", "rock", "ore"} go finder1(theMine) go finder2(theMine) <-time.After(time.Second * 5)
Le résultat de notre programme sera le suivant:
Finder 1 found ore! Finder 2 found ore! Finder 1 found ore! Finder 1 found ore! Finder 2 found ore! Finder 2 found ore!
Comme vous pouvez le voir, il n'y a pas d'ordre dans lequel la fonction «trouve le minerai» en premier; les fonctions de recherche fonctionnent simultanément. Si vous exécutez l'exemple plusieurs fois, la commande sera différente. Nous pouvons maintenant exécuter des programmes multithread (multisphère), ce qui représente un progrès sérieux. Mais que faire lorsque nous devons établir une connexion entre des goroutins indépendants? Le moment est venu pour la magie des chaînes.
Chaînes
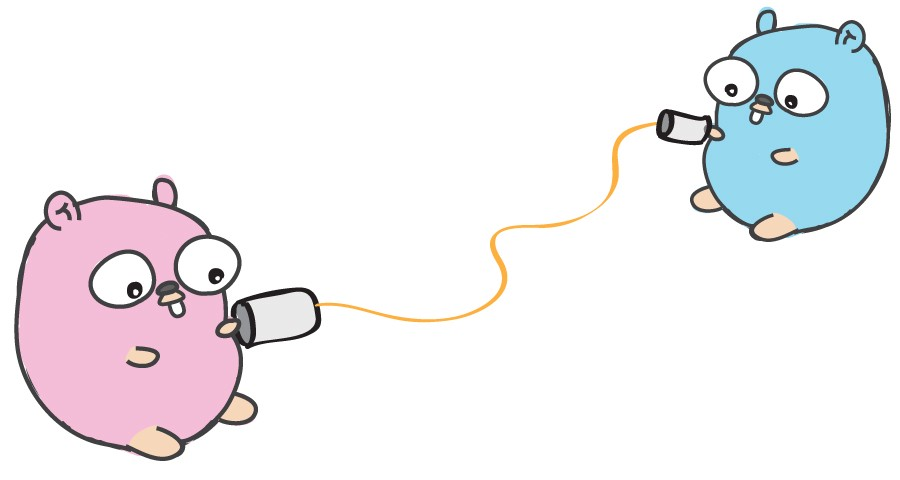
Les canaux permettent aux goroutins d'échanger des données. C'est une sorte de pipe à travers laquelle les goroutins peuvent envoyer et recevoir des informations d'autres goroutines.
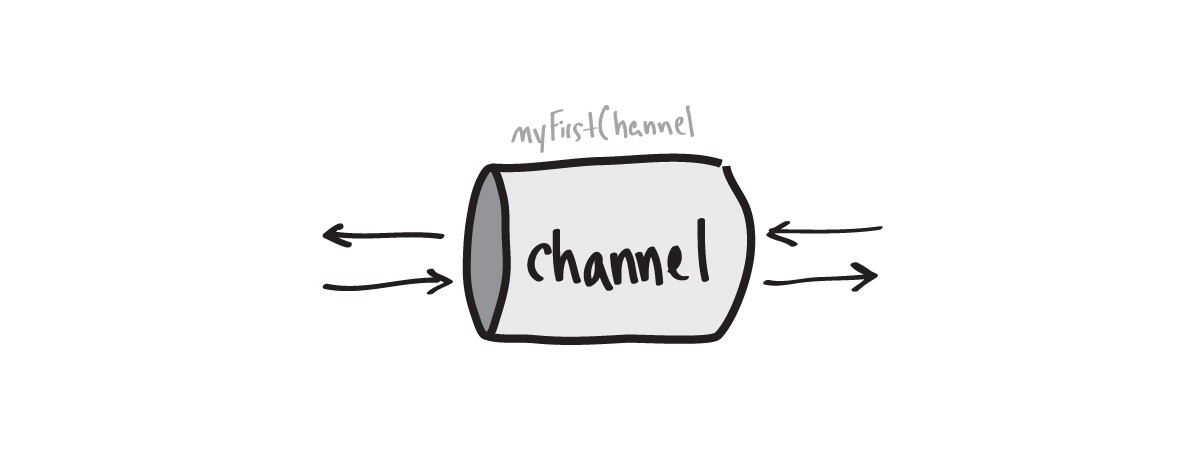
La lecture et l'écriture sur le canal sont effectuées à l'aide de l'opérateur fléché (<-), qui indique la direction du mouvement des données.

myFirstChannel := make(chan string) myFirstChannel <- "hello"
Maintenant, notre gopher-scout n'a plus besoin d'accumuler de minerai, il peut immédiatement le transférer davantage en utilisant des canaux.
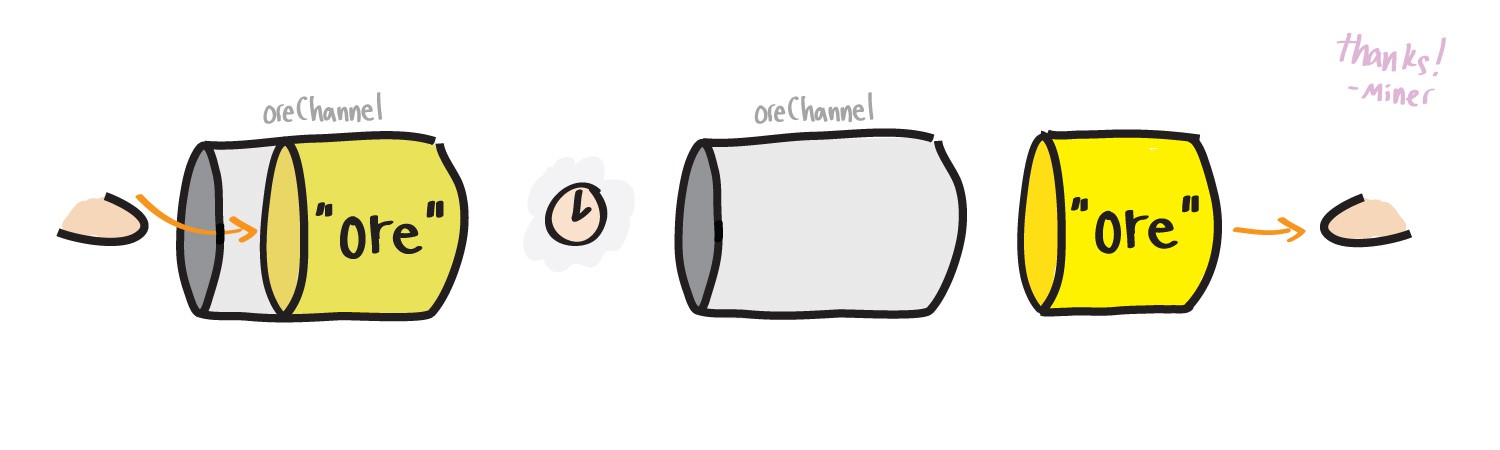
J'ai mis à jour l'exemple, maintenant le code du chercheur de minerai et du mineur est des fonctions anonymes. Ne vous embêtez pas trop si vous ne les avez pas rencontrés auparavant, gardez juste à l'esprit que chacun d'eux est appelé avec le mot clé
go , donc, il sera exécuté dans son propre goroutine. La chose la plus importante ici est que les goroutins transmettent des données entre eux en utilisant le canal
oreChan . Et nous traiterons les fonctions anonymes plus près de la fin.
func main() { theMine := [5]string{“ore1”, “ore2”, “ore3”} oreChan := make(chan string)
La conclusion ci-dessous démontre clairement que notre mineur reçoit trois fois du canal du minerai une portion à la fois.
Miner: Received ore1 from finder Miner: Received ore2 from finder Miner: Received ore3 from finder
Donc, maintenant nous pouvons transférer des données entre différents goroutines (gophers), mais avant de commencer à écrire un programme complexe, regardons quelques propriétés importantes des canaux.
Serrures
Dans certaines situations, lorsque vous travaillez avec des canaux, le goroutin peut être bloqué. Cela est nécessaire pour que les goroutines puissent se synchroniser avant de commencer ou de continuer à travailler.
Verrouillage en écriture
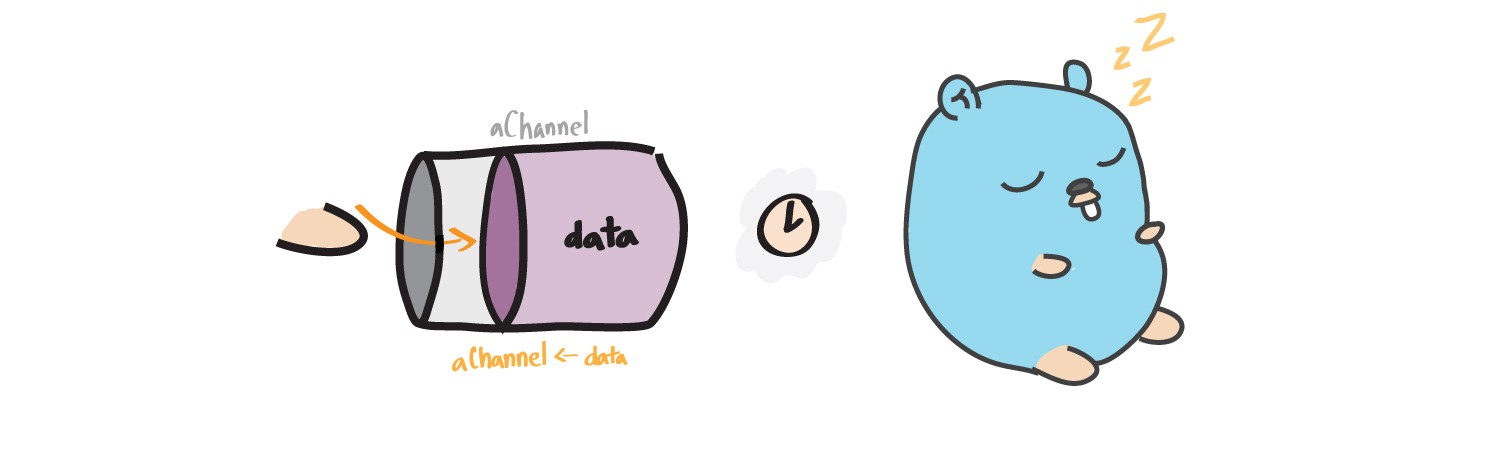
Lorsque le goroutin (gopher) envoie des données à un canal, il est bloqué jusqu'à ce qu'un autre goroutine lise les données du canal.
Verrou de lecture
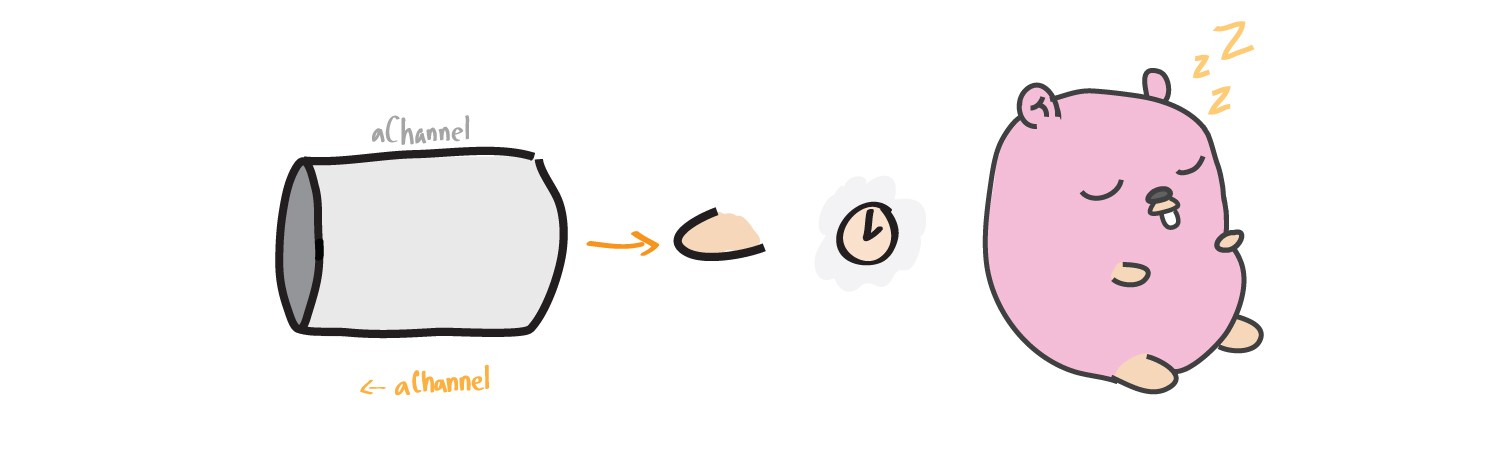
Semblable au verrouillage lors de l'écriture sur un canal, goroutin peut être verrouillé lors de la lecture à partir d'un canal jusqu'à ce que rien n'y soit écrit.
Si les écluses, à première vue, vous semblent compliquées, vous pouvez les imaginer comme un «transfert d'argent» entre deux goroutins (gophers). Lorsqu'un gopher veut transférer ou recevoir de l'argent, il doit attendre le deuxième participant à la transaction.
Après avoir traité des verrous goroutine sur les canaux, discutons de deux types de canaux différents: tamponnés et non tamponnés. En choisissant tel ou tel type, nous déterminons largement le comportement du programme.
Chaînes sans tampon
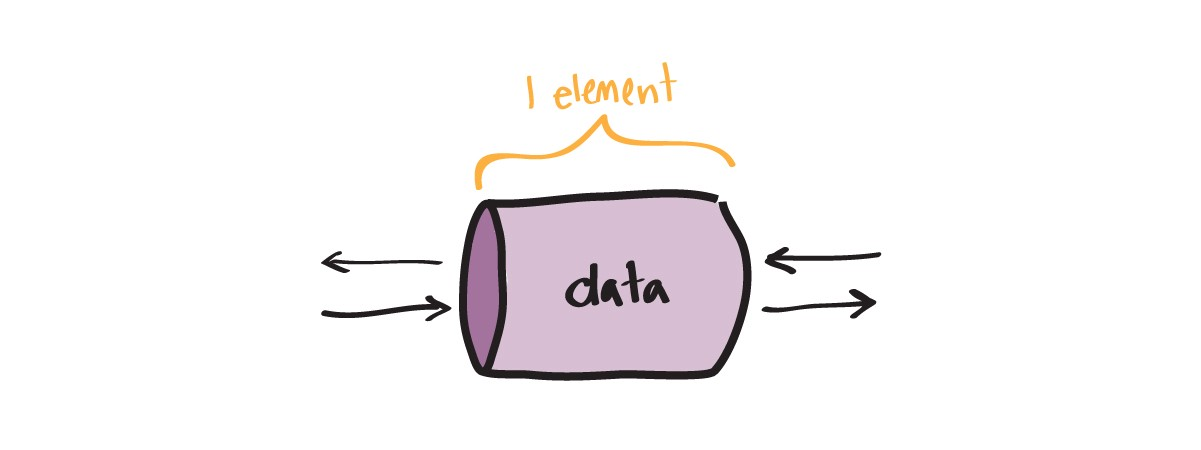
Dans tous les exemples précédents, nous avons utilisé uniquement ces canaux. Sur ces canaux, une seule donnée peut être transmise à la fois (avec blocage, comme décrit ci-dessus).
Canaux tamponnés

Les flux d'un programme ne peuvent pas toujours être parfaitement synchronisés. Supposons, dans notre exemple, qu'il se soit produit qu'un gopher-scout a trouvé trois parties de minerai, tandis qu'un gopher-miner n'a réussi à extraire qu'une partie des réserves trouvées en même temps. Ici, pour que la reconnaissance du gopher ne passe pas la majeure partie de son temps à attendre que le mineur termine son travail, nous utiliserons des canaux tamponnés. Commençons par créer un canal d'une capacité de 3.
bufferedChan := make(chan string, 3)
Nous pouvons envoyer plusieurs données sur le canal tamponné, sans avoir besoin de les lire avec un autre goroutine. C'est la principale différence avec les canaux sans tampon.

bufferedChan := make(chan string, 3) go func() { bufferedChan <- "first" fmt.Println("Sent 1st") bufferedChan <- "second" fmt.Println("Sent 2nd") bufferedChan <- "third" fmt.Println("Sent 3rd") }() <-time.After(time.Second * 1) go func() { firstRead := <- bufferedChan fmt.Println("Receiving..") fmt.Println(firstRead) secondRead := <- bufferedChan fmt.Println(secondRead) thirdRead := <- bufferedChan fmt.Println(thirdRead) }()
L'ordre de sortie dans un tel programme sera le suivant:
Sent 1st Sent 2nd Sent 3rd Receiving.. first second third
Pour éviter des complications inutiles, nous n'utiliserons pas de canaux tamponnés dans notre programme. Mais il est important de se rappeler que ces types de chaînes sont également disponibles.
Il est également important de noter que les canaux en mémoire tampon ne vous empêchent pas toujours de bloquer. Par exemple, si un scout gopher est dix fois plus rapide qu'un mineur gopher et qu'ils sont connectés via un canal tamponné d'une capacité de 2, le scout gopher sera bloqué chaque fois qu'il est envoyé, s'il y a déjà deux éléments de données dans le canal.
Tout mettre ensemble
Ainsi, armés de goroutines et de canaux, nous pouvons écrire un programme en utilisant tous les avantages de la programmation multithread dans Go.
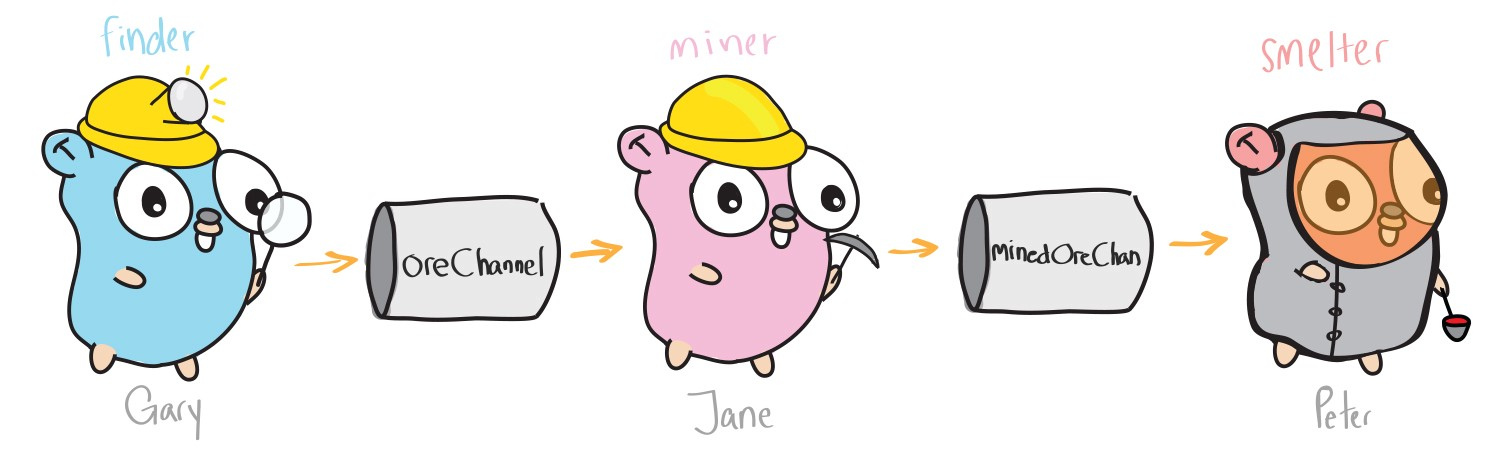
theMine := [5]string{"rock", "ore", "ore", "rock", "ore"} oreChannel := make(chan string) minedOreChan := make(chan string)
Un tel programme produira les éléments suivants:
From Finder: ore From Finder: ore From Miner: minedOre From Smelter: Ore is smelted From Miner: minedOre From Smelter: Ore is smelted From Finder: ore From Miner: minedOre From Smelter: Ore is smelted
Par rapport à notre premier exemple, il s'agit d'une amélioration majeure, maintenant toutes les fonctions sont exécutées indépendamment, chacune dans son propre goroutine. Et nous avons également obtenu un convoyeur à partir de canaux, à travers lequel le minerai est transféré immédiatement après le traitement. Pour rester concentré sur une compréhension de base du fonctionnement des chaînes et des goroutines, j'ai omis certains points, ce qui peut entraîner des difficultés de lancement du programme. En conclusion, je veux m'attarder sur ces caractéristiques de la langue, car elles aident à travailler avec les goroutines et les canaux.
Gorutins anonymes

Tout comme nous exécutons une fonction régulière dans goroutine, nous pouvons déclarer une fonction anonyme immédiatement après le mot clé
go et l'appeler en utilisant la syntaxe suivante:
Ainsi, si nous avons besoin d'appeler une fonction à un seul endroit, nous pouvons l'exécuter dans un goroutine séparé sans se soucier de sa déclaration à l'avance.
La fonction principale est la goroutine.

Oui, la fonction
principale fonctionne dans son propre goroutine. Et, plus important encore, après son achèvement, tous les autres goroutines se terminent également. C'est pour cette raison que nous avons placé un appel de temporisation à la fin de notre fonction
principale . Cet appel crée un canal et lui envoie des données après 5 secondes.
<-time.After(time.Second * 5)
Rappelez-vous que goroutine sera bloqué lors de la lecture de la chaîne jusqu'à ce que quelque chose lui soit envoyé? C'est exactement ce qui se produit lorsque le code spécifié est ajouté. Le goroutine principal sera bloqué, ce qui donnera aux autres goroutias 5 secondes de temps pour travailler. Cette méthode fonctionne bien, mais généralement une approche différente est utilisée pour vérifier que tous les goroutins ont terminé leur travail. Pour transmettre un signal de fin de travail, un canal spécial est créé, le goroutine principal est bloqué de lecture et, dès que le goroutin fille termine son travail, il écrit sur ce canal; Le goroutine principal est déverrouillé et le programme se termine.

func main() { doneChan := make(chan string) go func() {
Lire à partir d'un tuyau dans une boucle pour plage
Dans notre exemple, dans la fonction du goffer-getter, nous avons utilisé la boucle
for pour sélectionner trois éléments dans le canal. Mais que faire si on ne sait pas à l'avance combien de données peuvent être dans le canal? Dans de tels cas, vous pouvez utiliser le canal comme argument de la boucle
for-range , tout comme avec les collections. La fonction mise à jour peut ressembler à ceci:
Ainsi, le minerai lira tout ce que le scout lui envoie; l'utilisation du canal dans le cycle le garantira. Veuillez noter qu'après que toutes les données du canal ont été traitées, le cycle se verrouille à la lecture; pour éviter le blocage, vous devez fermer le canal en appelant
close (channel) .
Lecture de canaux non bloquants
En utilisant la construction
select-case , le blocage des lectures du tuyau peut être évité. Voici un exemple d'utilisation de cette construction: goroutine lira les données du canal, si seulement elles s'y trouvent, sinon le bloc
par défaut est exécuté:
myChan := make(chan string) go func(){ myChan <- “Message!” }() select { case msg := <- myChan: fmt.Println(msg) default: fmt.Println(“No Msg”) } <-time.After(time.Second * 1) select { case msg := <- myChan: fmt.Println(msg) default: fmt.Println(“No Msg”) }
Une fois lancé, ce code affichera les éléments suivants:
No Msg Message!
Enregistrement de canaux non bloquants
Les verrous lors de l'écriture sur un canal peuvent être évités en utilisant la même construction de
sélection de cas . Faisons une petite modification de l'exemple précédent:
select { case myChan <- “message”: fmt.Println(“sent the message”) default: fmt.Println(“no message sent”) }
Quoi étudier davantage

Il existe un grand nombre d'articles et de rapports qui couvrent le travail avec les chaînes et les goroutines de manière beaucoup plus détaillée. Et maintenant, avec le code, vous avez une idée claire de pourquoi et comment ces outils sont utilisés, vous pouvez tirer le meilleur parti des matériaux suivants:
Merci d'avoir pris le temps de lire. J'espère que je vous ai aidé à comprendre les chaînes, les goroutines et les avantages que les programmes multithread vous procurent.