
Les développeurs qui savent et savent travailler avec git ont grandi ces derniers temps d'un ordre de grandeur. Vous vous habituez à la vitesse d'exécution des commandes. Vous vous habituez à la commodité des succursales et à l'annulation facile des modifications. La résolution des conflits est si courante que les programmeurs sont habitués à résoudre héroïquement les conflits là où ils ne devraient pas l'être.
Notre équipe chez Directum développe un outil de développement pour les solutions de plate-forme. Si vous avez vu 1C, vous pouvez imaginer à peu près l'environnement de travail de nos «clients» - les développeurs d'applications. À l'aide de cet outil de développement, un développeur d'applications crée une solution d'application pour les clients.
Notre équipe a eu pour tâche de simplifier la vie de nos candidats. Nous sommes gâtés avec des puces modernes de Visual Studio, ReSharper et IDEA. Les candidats ont exigé que nous intégrions git out of the box dans l'outil.
Telle est la difficulté. Dans l'outil pour chaque type d'entité (contrat, rapport, annuaire, module), un verrou pourrait être présent. Un développeur a commencé à modifier le type d'entité et l'a bloqué jusqu'à ce qu'il ait terminé les modifications et les ait validées sur le serveur. À l'heure actuelle, d'autres développeurs voient le même type d'entité en lecture seule. Le développement rappelait quelque peu le travail en SVN ou l'envoi d'un document Word par mail entre plusieurs utilisateurs. Je veux tout à la fois, mais peut-être un seul.
Chaque type d'entité peut avoir de nombreux gestionnaires (ouverture d'un document, validation avant l'enregistrement, écriture dans la base de données), dans lesquels vous souhaitez écrire du code qui fonctionne avec une instance spécifique de l'entité. Par exemple, verrouillez les boutons, affichez un message à l'utilisateur ou créez une nouvelle tâche pour les interprètes. Tout le code dans le cadre de l'API fourni par la plateforme. Les gestionnaires sont des classes dans lesquelles se trouvent de nombreuses méthodes. Lorsque deux personnes devaient réparer le même fichier avec le code, cela n'était pas possible, car la plate-forme bloquait tout le type d'entité avec le code dépendant.
Nos pratiquants sont allés jusqu'au bout. Ils se sont tranquillement fourrés une copie «illégale» de notre environnement de développement, ont commenté la partie bloquante et ont fusionné nos engagements avec eux-mêmes. Le code de l'application a été conservé sous git, engagé via des outils tiers (git bash, SourceTree et autres). Nous avons tiré nos conclusions:
- Notre équipe a sous-estimé la volonté des développeurs d'applications de s'intégrer à la plateforme. Un immense respect et honneur!
- La solution qu'ils ont proposée n'est pas adaptée à la production. Avec git, les mains d'une personne sont déliées et elle est capable de créer n'importe quoi. Pour supporter toute la diversité sera stupide, ne détournez pas. De plus, il sera nécessaire d'éduquer les clients de la plateforme. La documentation de toutes les commandes git pour la plateforme rendrait l'équipe de documentation folle.

Ce que vous voulez de Git
Donc, donner pour la production avec un git out n'est pas bon. Nous avons décidé de résumer en quelque sorte la logique des principales opérations et d'en limiter le nombre. Au moins pour la première version. La liste des équipes a été réduite au fur et à mesure et peut rester:
- statut
- commettre
- tirer
- pousser
- réinitialiser --hard à HEAD
- réinitialiser au dernier commit "serveur"
Pour la première version, ils ont décidé de refuser de travailler avec des succursales. Non pas que ce soit très difficile, mais l'équipe n'a pas respecté les ressources en temps.
Périodiquement, nos partenaires envoient leur développement d'application et demandent: "Quelque chose ne fonctionne pas pour nous. Que faisons-nous de mal?". Dans ce cas, l'application se charge du développement de quelqu'un d'autre et examine le code. Cela fonctionnait comme ceci:
- Le développeur a emporté l'archive avec le développement;
- Modification de la base de données locale dans les configurations;
- Versé le développement de quelqu'un d'autre à sa base;
- Débogué, trouvé des erreurs;
- Recommandations émises;
- Il a rendu son développement.
La nouvelle méthodologie ne cadrait pas avec l'ancienne approche. J'ai dû me casser la tête. L'équipe a proposé deux approches pour résoudre ce problème:
- Stockez tous les développements dans un référentiel git. Si nécessaire, travaillez avec la décision de quelqu'un d'autre de créer une branche temporaire.
- Stocker le développement de différentes équipes dans différents référentiels. Déplacez les paramètres des dossiers chargés dans l'environnement dans le fichier de configuration.
Nous avons décidé de suivre la deuxième voie. Le premier semblait plus difficile à mettre en œuvre et, de plus, il était plus facile de se tirer une balle dans le pied avec un changement de branche.
Mais le second n'est pas non plus sucré. Les commandes décrites ci-dessus devraient fonctionner non seulement dans le même référentiel, mais avec plusieurs à la fois. Y a-t-il un changement dans les types d'entités des différents référentiels? Nous les montrons dans une seule fenêtre. Ceci est plus pratique et transparent pour le développeur d'applications. En appuyant sur le bouton de validation, l'outil valide les modifications dans chacun des référentiels. Par conséquent, les commandes pull / push / reset «sous le capot» fonctionnent avec des référentiels physiquement différents.

Libgit2sharp
Pour travailler avec git, nous avons choisi entre deux options:
- Travaillez avec git installé sur le système, en le faisant passer par Process.Start et en analysant la sortie.
- Utilisez libgit2sharp, qui via pinvoke extrait la bibliothèque libgit2.
Il nous a semblé que l'utilisation d'une bibliothèque prête à l'emploi est une solution raisonnable. En vain. Je vous dirai un peu plus tard pourquoi. Au début, la bibliothèque nous a donné l'occasion de déployer rapidement un prototype fonctionnel.
Première itération de développement
Il a été possible de l'implémenter en un mois environ. En fait, visser le git a été rapide, et la plupart du temps, nous avons essayé de guérir les blessures qui avaient été ouvertes parce que nous avions supprimé l'ancien mécanisme de stockage des fichiers source. Tout ce que l' git status renvoyé a été renvoyé à l'interface. Cliquer sur chaque fichier affiche diff. Cela ressemblait à une interface git gui.
Deuxième itération de développement
La première option était trop informative. Avec chaque type d'entité, de nombreux fichiers sont associés à la fois. Ces fichiers ont créé du bruit et il est devenu difficile de savoir quels types d'entités ont changé et quoi exactement.
Fichiers groupés par type d'entité. Chaque fichier a reçu un nom lisible par l'homme, le même que dans l'interface graphique. Les métadonnées de type d'entité sont décrites dans JSON. Ils devaient également être présentés dans un format lisible par l'homme. L'analyse des changements dans les versions json "avant" et "après" a été lancée à l'aide de la bibliothèque jsondiffpatch, puis ils ont écrit leur propre implémentation de la comparaison JSON (ci-après, j'appellerai jsondiff). Nous exécutons les résultats de la comparaison via des analyseurs qui produisent des enregistrements lisibles par l'homme. De nombreux fichiers ont été masqués, laissant une simple entrée dans l'arborescence des modifications.
Le résultat final est le suivant:
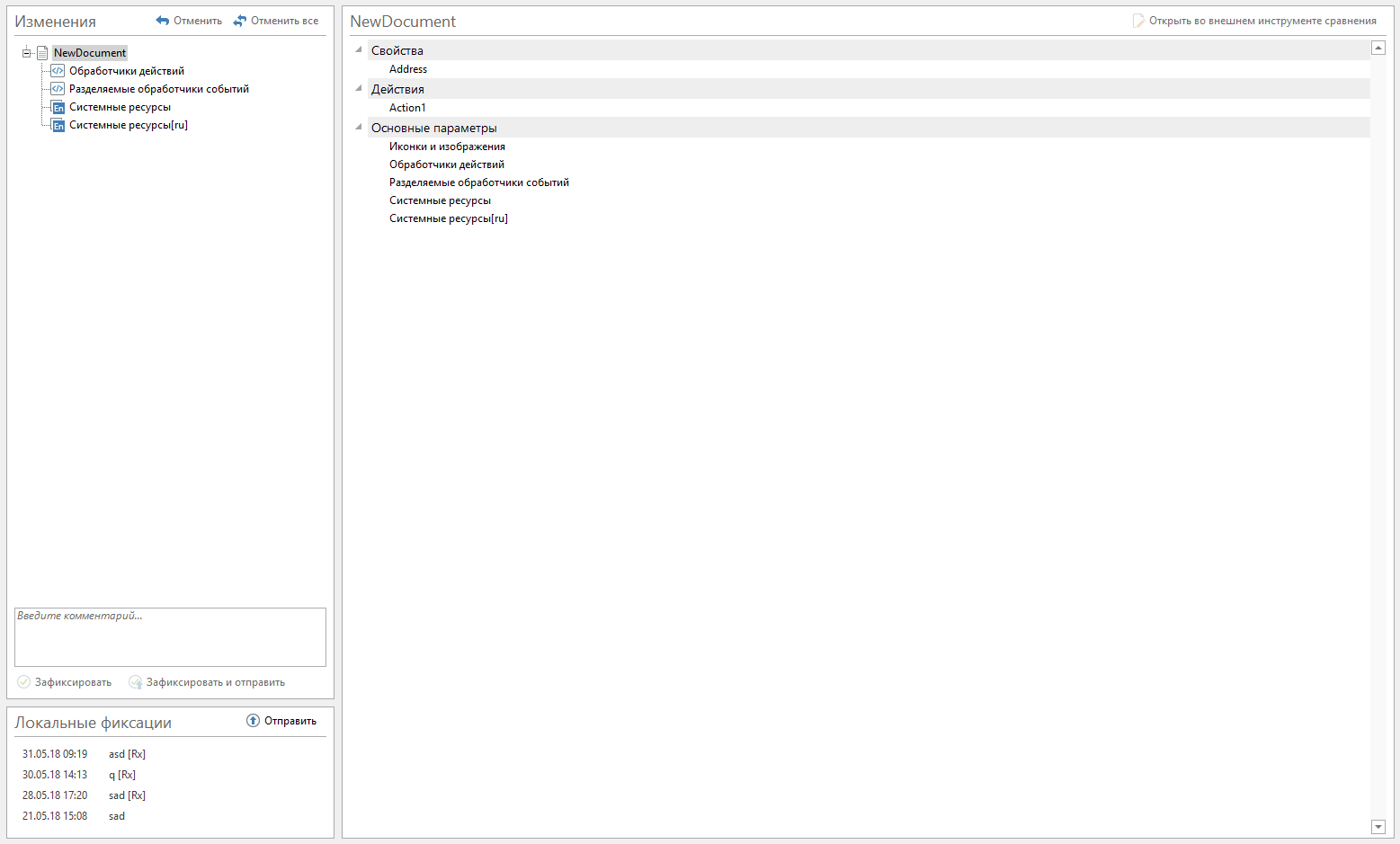
Avoir des problèmes avec libgit2
Libgit2 a généré un grand nombre de surprises inattendues. S'occuper de certains dépassait le pouvoir d'un délai raisonnable. Je vais vous dire ce dont je me souviens.
Chutes inattendues et difficiles à reproduire sur certaines opérations standard. "Aucune erreur fournie par la bibliothèque native" nous dit le wrapper. Super. Vous maudissez, vous reconstruisez la bibliothèque native en débogage, vous répétez un cas précédemment abandonné, mais il ne plante pas en mode débogage. Reconstruisez dans la version et retombez.
Si un outil tiers, par exemple SourceTree, s'exécute en parallèle avec libgit2sharp, alors commit peut ne pas valider certains fichiers. Ou se fige lors de l'affichage des différences sur certains fichiers. Dès que vous essayez de déboguer, vous ne pouvez pas reproduire.
Dans l'une de nos applications, la mise en œuvre de l'analogue git status pris 40 secondes. Quarante Carl! Dans le même temps, le git lancé depuis la console a fonctionné comme il se doit pendant une seconde. J'ai passé quelques jours pour régler le problème. Lors de la recherche de modifications, Libgit2 examine les attributs de fichier des dossiers et les compare avec l'entrée de l'index. Si l'heure de modification est différente, alors quelque chose a changé dans le dossier et vous devez regarder à l'intérieur et / ou regarder dans les fichiers. Et si rien n'a changé, vous ne devez pas monter à l'intérieur. Cette optimisation est apparemment également dans la console git. Je ne sais pas pour quelle raison, mais juste pour une personne dans l'index git mtime a changé. Pour cette raison, git a vérifié le contenu de TOUS les fichiers dans le référentiel à chaque fois pour des modifications.
Plus près de la sortie, notre équipe a cédé aux souhaits de l'équipe d'application et a remplacé git pull par fetch + rebase + autostash . Et puis un tas de bugs nous est parvenu, y compris avec "Aucune erreur fournie par la bibliothèque native".
status, pull et rebase fonctionnent beaucoup plus longtemps que d'appeler des commandes de console.
Fusion automatique
Les fichiers en développement sont divisés en deux types:
- Fichiers que l'application voit dans l'outil de développement. Par exemple, du code, des images, des ressources. Ces fichiers doivent être fusionnés comme le fait git.
- Fichiers JSON créés par l'environnement de développement, mais le développeur de l'application ne les voit que sous la forme d'une interface graphique. Ils doivent résoudre automatiquement les conflits.
- Fichiers générés qui sont automatiquement recréés lorsque vous travaillez avec l'outil de développement. Ces fichiers n'entrent pas dans le référentiel, l'outil place immédiatement soigneusement .gitignore.
Avec une nouvelle façon, deux applicateurs différents ont pu changer le même type d'entité.
Par exemple, Sasha modifiera les informations sur la façon de stocker le type d'une entité dans la base de données et d'écrire un gestionnaire pour l'événement d'enregistrement, et Sergey stylisera la représentation de l'entité. D'un point de vue git, ce ne sera pas un conflit et les deux changements fusionneront sans complexité.
Et puis Sasha a changé la propriété Property1 et a défini un gestionnaire pour cela. Sergey a créé la propriété Property2 et défini le gestionnaire. Si vous regardez la situation ci-dessus, leurs modifications n'entrent pas en conflit, bien que du point de vue de git, les mêmes fichiers soient affectés.
Je voulais que l'instrument soit en mesure de résoudre seul cette situation.
Un exemple d'algorithme pour fusionner deux JSON en cas de conflit:
Téléchargez depuis le git de base JSON.
Téléchargez depuis notre gita JSON.
Téléchargement de leur JSON à partir d'un git.
En utilisant jsondiff, nous formons les correctifs logiciels de base et les nôtres et nous les appliquons. Le JSON résultant est appelé P1.
En utilisant jsondiff, nous formons les correctifs logiciels de base et les appliquons aux nôtres. Le JSON résultant est appelé P2.
Idéalement, après application des patchs P1 === P2. Si c'est le cas, écrivez P1 sur le disque.
- Dans un cas imparfait (lorsqu'un conflit existe réellement), nous suggérons à l'utilisateur de choisir entre P1 et P2 avec la possibilité de terminer avec ses mains. Nous écrivons la sélection sur le disque.
Après la fusion, nous vérifions si l'état sans erreur de validation est atteint. Si vous n'êtes pas arrivé, annulez la fusion et demandez à l'utilisateur de la répéter. Ce n'est pas la meilleure solution, mais cela garantit au moins qu'à partir de la deuxième ou de la troisième tentative, la fusion se fera sans conséquences désagréables.
Résumé
- Les bouchers sont heureux de pouvoir les utiliser légalement.
- L'introduction de git a accéléré le développement.
- Les fusions automatiques ressemblent généralement à de la magie.
- Nous plaçons le rejet futur de libgit2 en faveur de l'invocation du processus git.