Le 28 mai, lors de la conférence
RootConf 2018, qui a eu lieu dans le cadre du festival RIT ++ 2018, dans la section «Logging and Monitoring», un rapport «Monitoring and Kubernetes» a été remis. Il raconte l'expérience de la surveillance de la configuration avec Prometheus, qui a été obtenue par Flant à la suite de l'exploitation de dizaines de projets Kubernetes en production.

Par tradition, nous sommes heureux de présenter une
vidéo avec un rapport (environ une heure,
beaucoup plus informatif
que l' article) et la principale compression sous forme de texte. C'est parti!
Qu'est-ce que la surveillance?
Il existe de nombreux systèmes de surveillance:

Il semblerait que la prise et l'installation de l'un d'entre eux - c'est tout, la question est close. Mais la pratique montre que ce n'est pas le cas. Et voici pourquoi:
- L'indicateur de vitesse indique la vitesse . Si nous mesurons la vitesse une fois par minute avec l'indicateur de vitesse, la vitesse moyenne, que nous calculons sur la base de ces données, ne coïncidera pas avec les données de l'odomètre. Et si dans le cas d'une voiture, cela est évident, alors quand il s'agit de nombreux indicateurs pour le serveur, nous l'oublions souvent.
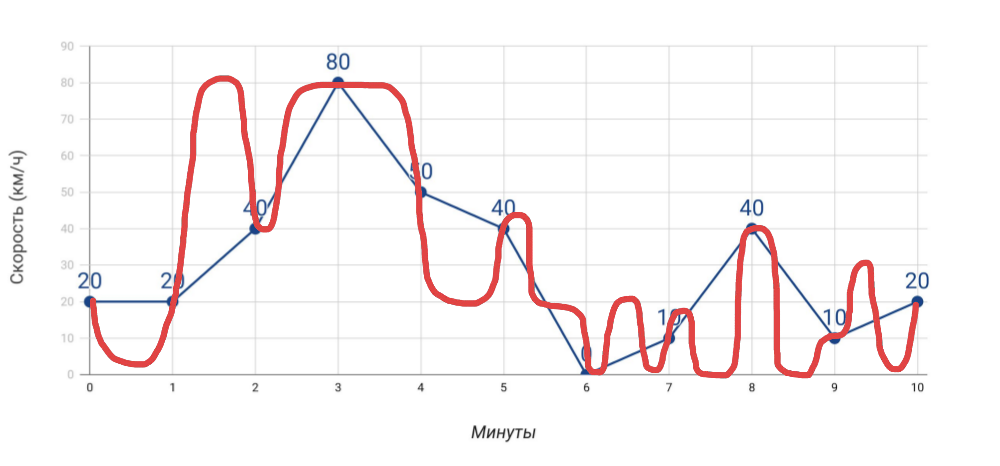
Ce que nous mesurons et comment nous avons réellement voyagé - Plus de mesures . Plus nous obtiendrons d'indicateurs différents , plus le diagnostic des problèmes sera précis ... mais seulement à condition que ce soient des indicateurs vraiment utiles, et pas seulement tout ce que vous avez réussi à collecter.
- Alertes . L'envoi d'alertes n'a rien de compliqué. Cependant, deux problèmes typiques: a) les fausses alarmes se produisent si souvent que nous cessons de répondre aux alertes, b) les alertes arrivent à un moment où il est trop tard (tout a déjà explosé). Et réaliser en contrôlant que ces problèmes ne se sont pas posés est un véritable art!
La surveillance est une tarte de trois couches, chacune étant essentielle:
- Tout d'abord, il s'agit d'un système qui vous permet de prévenir les accidents , de signaler les accidents (s'ils n'ont pas pu être évités) et d'effectuer un diagnostic rapide des problèmes.
- Que faut-il pour cela? Des données précises , des graphiques utiles (regardez-les et comprenez où est le problème), des alertes pertinentes (arrivez au bon moment et contiennent des informations claires).
- Et pour que tout cela fonctionne, un système de surveillance est nécessaire.
La configuration correcte d'un système de surveillance qui fonctionne vraiment n'est pas une tâche facile, nécessitant une approche réfléchie de la mise en œuvre même sans Kubernetes. Mais que se passe-t-il avec son apparence?
Spécificités de la surveillance Kubernetes
N ° 1. Plus grand et plus rapide
Kubernetes change beaucoup parce que l'infrastructure s'agrandit et devient plus rapide. Si auparavant, avec des serveurs de fer ordinaires, leur nombre était très limité et le processus d'ajout était très long (prenait des jours ou des semaines), puis avec les machines virtuelles, le nombre d'entités augmentait considérablement et le temps de leur introduction dans la bataille était réduit à quelques secondes.
Avec Kubernetes, le nombre d'entités a augmenté d'un ordre de grandeur, leur ajout est complètement automatisé (la gestion de la configuration est nécessaire, car sans description, un nouveau pod ne peut tout simplement pas être créé), toute l'infrastructure est devenue très dynamique (par exemple, les pods sont supprimés et libérés à chaque fois sont créés à nouveau).
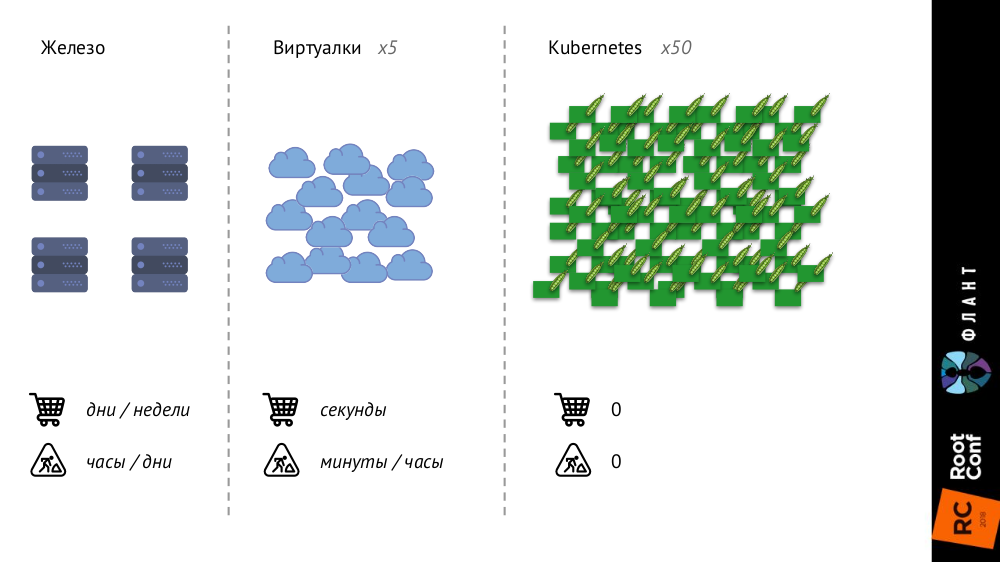
Qu'est-ce que cela change?
- En principe, nous cessons de regarder des pods ou des conteneurs individuels - maintenant nous ne nous intéressons qu'aux groupes d'objets .
- La découverte du service devient strictement obligatoire , car les "vitesses" sont déjà telles que, en principe, nous ne pouvons pas démarrer / supprimer manuellement de nouvelles entités, comme c'était le cas auparavant, lors de l'achat de nouveaux serveurs.
- La quantité de données augmente considérablement . Si des mesures antérieures étaient collectées à partir de serveurs ou de machines virtuelles, désormais à partir de pods, dont le nombre est beaucoup plus important.
- Le changement le plus intéressant que j'ai appelé le « flux de métadonnées » et je vais vous en dire plus.
Je vais commencer par cette comparaison:
- Lorsque vous envoyez votre enfant à la maternelle, on lui remet une boîte personnelle, qui lui est attribuée pour la prochaine année (ou plus) et sur laquelle son nom est indiqué.
- Lorsque vous venez à la piscine, votre casier n'est pas signé et il vous est délivré pour une «séance».
Les systèmes de surveillance classiques pensent donc qu'ils sont un jardin d'enfants , pas une piscine: ils supposent que l'objet de surveillance leur est venu pour toujours ou pour longtemps, et leur donnent des casiers en conséquence. Mais les réalités de Kubernetes sont différentes: un pod est venu dans la piscine (c'est-à-dire a été créé), a nagé dedans (jusqu'à un nouveau déploiement) et est parti (a été détruit) - tout cela se produit rapidement et régulièrement. Ainsi, le système de surveillance doit comprendre que les objets qu'il surveille ont une courte durée de vie et doit pouvoir l'oublier complètement au bon moment.
N ° 2. La réalité parallèle existe
Autre point important - avec l'avènement de Kubernetes, nous avons simultanément deux «réalités»:
- Monde Kubernetes dans lequel il y a des espaces de noms, des déploiements, des pods, des conteneurs. C'est un monde complexe, mais il est logique, structuré.
- Le monde "physique", composé de nombreux (littéralement - tas) de conteneurs sur chaque nœud.
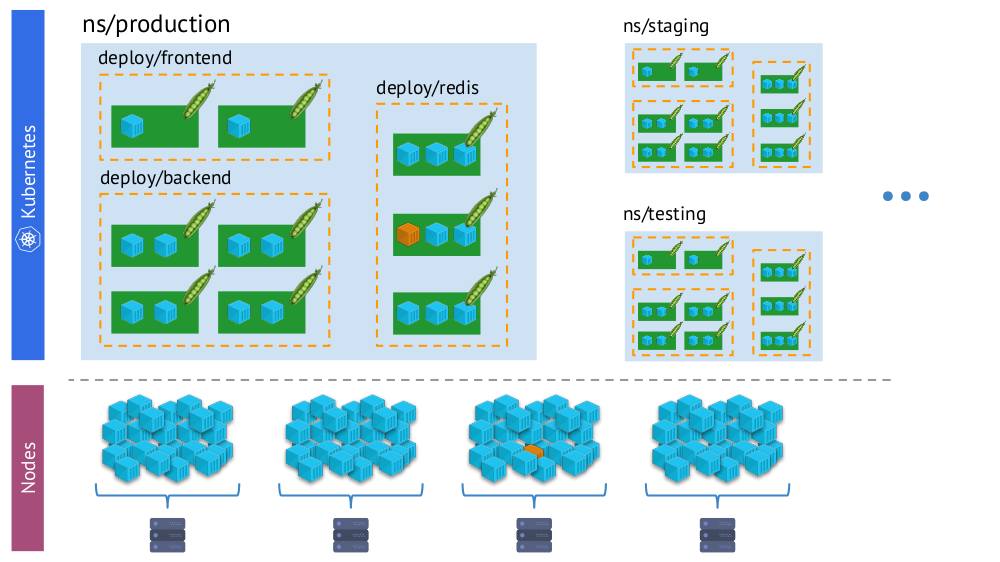 Un seul et même conteneur dans la «réalité virtuelle» de Kubernetes (ci-dessus) et le monde physique des nœuds (ci-dessous)
Un seul et même conteneur dans la «réalité virtuelle» de Kubernetes (ci-dessus) et le monde physique des nœuds (ci-dessous)Et dans le processus de surveillance, nous devons constamment
comparer le monde physique des conteneurs avec la réalité de Kubernetes . Par exemple, lorsque nous regardons un espace de noms, nous voulons savoir où se trouvent tous ses conteneurs (ou les conteneurs de l'un de ses foyers). Sans cela, les alertes ne seront pas visuelles et pratiques à utiliser - car il est important pour nous de comprendre quels objets ils signalent.
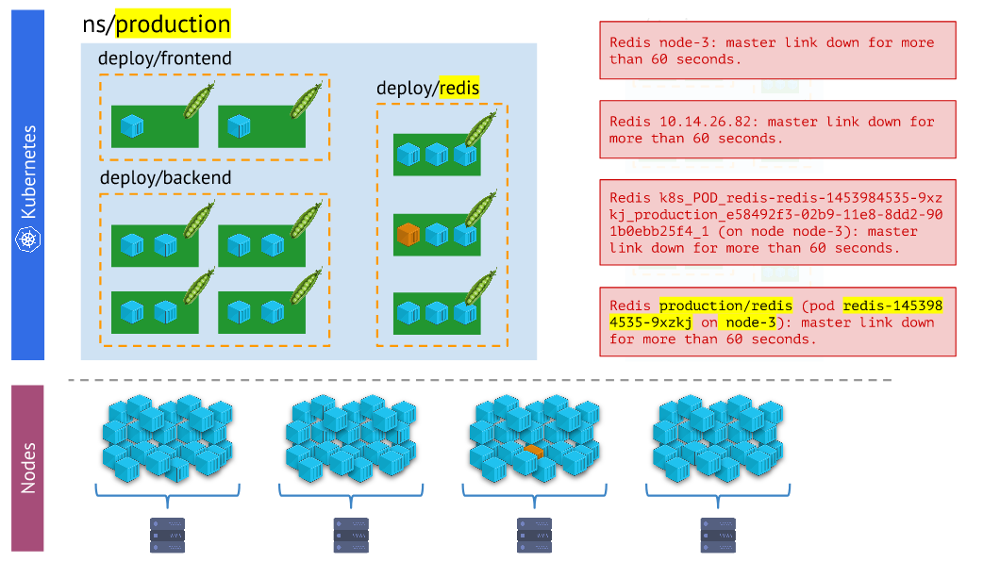 Différents types d'alertes - cette dernière est plus visuelle et pratique au travail que les autresLes conclusions
Différents types d'alertes - cette dernière est plus visuelle et pratique au travail que les autresLes conclusions sont les suivantes:
- Le système de surveillance doit utiliser les primitives intégrées de Kubernetes.
- Il y a plus d'une réalité: souvent, les problèmes ne se produisent pas avec le foyer, mais avec un nœud particulier, et nous devons constamment comprendre dans quel type de «réalité» ils se trouvent.
- Dans un cluster, en règle générale, il existe plusieurs environnements (en plus de la production), ce qui signifie que cela doit être pris en compte (par exemple, pour ne pas recevoir d'alertes la nuit sur les problèmes de développement).
Donc, nous avons trois conditions nécessaires pour que tout fonctionne:
- Nous comprenons bien ce qu'est la surveillance.
- Nous connaissons ses fonctionnalités, lesquelles apparaissent avec Kubernetes.
- Nous adoptons le Prométhée.
Et donc, pour vraiment s'entraîner, il ne reste plus qu'à faire
vraiment beaucoup d' efforts! Au fait, pourquoi exactement Prométhée? ..
Prométhée
Il existe deux façons de répondre à la question concernant le choix de Prométhée:
- Découvrez qui et quoi sont généralement utilisés pour surveiller Kubernetes.
- Considérez ses avantages techniques.
Pour la première, j'ai utilisé les données d'enquête de The New Stack (du livre électronique
The State of the Kubernetes Ecosystem ), selon lesquelles Prometheus est au moins plus populaire que les autres solutions (Open Source et SaaS), et si vous regardez, elle a un avantage statistique quintuple .
Voyons maintenant comment Prometheus fonctionne, en parallèle avec la façon dont ses capacités se combinent avec Kubernetes et résolvent les défis associés.
Comment Prometheus est-il structuré?
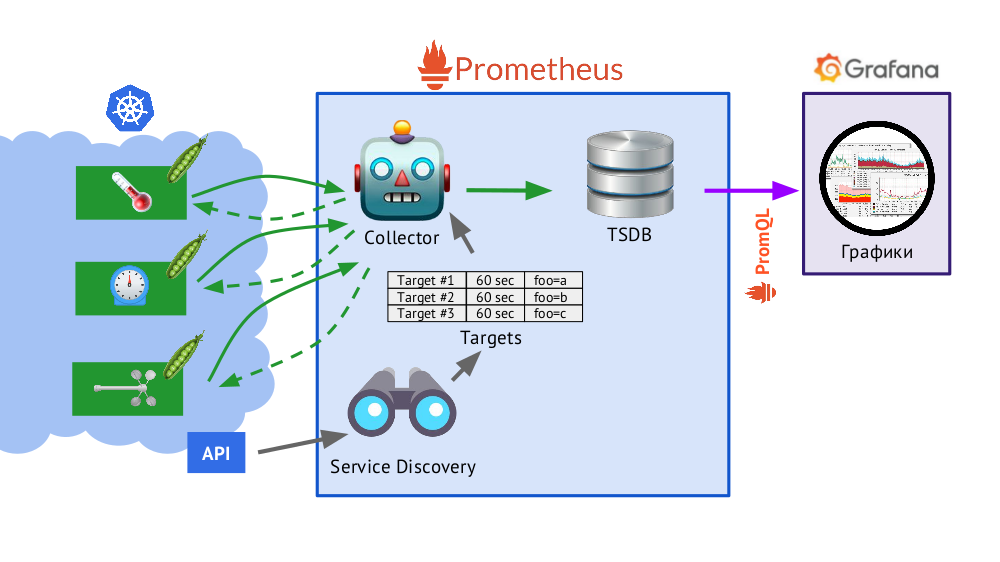
Prometheus est écrit en Go et distribué comme un seul fichier binaire, dans lequel tout est intégré. L'algorithme de base pour son fonctionnement est le suivant:

- Le collecteur lit la table des cibles , c.-à-d. une liste des objets à surveiller et la fréquence de leur interrogation (par défaut - 60 secondes).
- Après cela, le collecteur envoie une demande HTTP à chaque module dont vous avez besoin et reçoit une réponse avec un ensemble de métriques - il peut y avoir cent, mille, dix mille ... Chaque métrique a un nom, une valeur et des étiquettes .
- La réponse reçue est stockée dans la base de données TSDB , où l'horodatage de sa réception et les étiquettes de l'objet dont elle provient ont été ajoutées aux données métriques reçues.
En bref sur TSDBTSDB - base de données de séries chronologiques (DB pour séries chronologiques) sur Go, qui vous permet de stocker des données pendant un nombre de jours spécifié et le fait très efficacement (en taille, en mémoire et en entrée / sortie). Les données sont stockées uniquement localement, sans clustering et réplication, ce qui est un plus (cela fonctionne simplement et de manière garantie) et un moins (il n'y a pas de mise à l'échelle horizontale du stockage), mais dans le cas du partage Prometheus, c'est bien fait, fédération - plus à ce sujet plus tard.
- Présenté dans le schéma, Service Discovery est un moteur de découverte de service intégré à Prometheus qui vous permet de recevoir des données «de la boîte» (via l'API Kubernetes) pour créer une table d'objectifs.
À quoi ressemble ce tableau? Pour chaque entrée, il stocke l'URL utilisée pour obtenir les métriques, la fréquence des appels et les étiquettes.
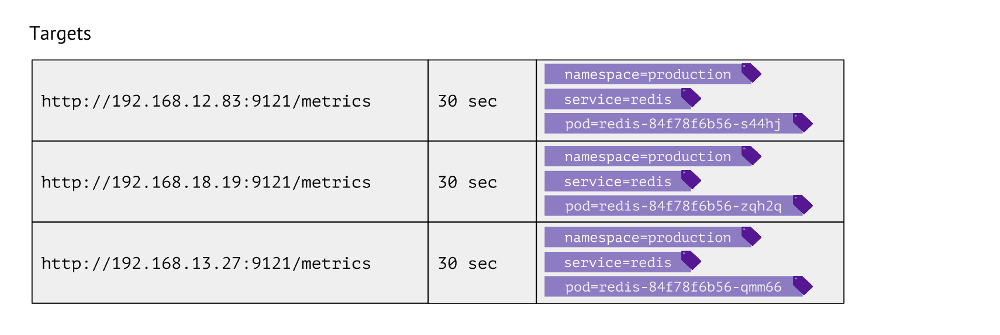
Les étiquettes sont utilisées pour la juxtaposition même des «mondes» de Kubernetes avec le physique. Par exemple, pour trouver un pod avec Redis, nous devons avoir l'espace de noms de valeurs, le service (utilisé au lieu du déploiement en raison des caractéristiques techniques d'un cas particulier) et le pod réel. Par conséquent, ces 3 étiquettes sont stockées dans des entrées de table d'objectifs pour les métriques Redis.
Ces entrées dans le tableau sont formées sur la base de la
scrape_configs Prometheus dans laquelle les objets de surveillance sont décrits: dans la section
scrape_configs , des
scrape_configs définis, qui indiquent par quelles étiquettes rechercher les objets à surveiller, comment les filtrer et quelles étiquettes enregistrer.
Quelles données Kubernetes collecte-t-il?
- Premièrement, l' assistant dans Kubernetes est assez compliqué - et il est essentiel de surveiller l'état de son travail (kube-apiserver, kube-controller-manager, kube-scheduler, kube-etcd3 ...), de plus, il est lié au nœud de cluster.
- Deuxièmement, il est important de savoir ce qui se passe à l' intérieur de Kubernetes . Pour ce faire, nous obtenons des données de:
- kubelet - ce composant Kubernetes s'exécute sur chaque nœud du cluster (et se connecte à l'assistant K8s); cAdvisor y est intégré (toutes les mesures par conteneurs), et il stocke également des informations sur les volumes persistants connectés;
- kube-state-metrics - en fait, il s'agit de l'exportateur Prometheus pour l'API Kubernetes (il vous permet d'obtenir des informations sur les objets stockés dans Kubernetes: pods, services, déploiements, etc.; par exemple, nous ne le saurons pas sans lui état du récipient ou du foyer);
- nœud-exportateur - fournit des informations sur le nœud lui-même, les mesures de base sur le système Linux (cpu, diskstats, meminfo, etc. ).
- Viennent ensuite les composants Kubernetes , tels que kube-dns, kube-prometheus-operator et kube-prometheus, ingress-nginx-controller, etc.
- La prochaine catégorie d'objets à surveiller est en fait le logiciel lancé dans Kubernetes. Ce sont des services de serveur typiques comme nginx, php-fpm, Redis, MongoDB, RabbitMQ ... Nous le faisons nous-mêmes afin que lorsque nous ajoutons certaines étiquettes au service, il commence automatiquement à collecter les données nécessaires, ce qui crée le tableau de bord actuel dans Grafana.
- Enfin, la catégorie pour tout le reste est personnalisée . Les outils Prometheus vous permettent d'automatiser la collecte de mesures arbitraires (par exemple, le nombre de commandes) en ajoutant simplement une étiquette
prometheus-custom-target à la description du service.

Graphiques
Les données reçues
(décrites ci-dessus) sont utilisées pour envoyer des alertes et créer des graphiques. Nous
dessinons des graphiques en utilisant
Grafana . Et un «détail» important ici est
PromQL , le langage de requête Prometheus qui s'intègre parfaitement avec Grafana.
Il est assez simple et pratique pour la plupart des tâches
(mais, par exemple, y joindre des jointures est déjà gênant, mais vous devez quand même le faire) . PromQL vous permet de résoudre toutes les tâches nécessaires: sélectionnez rapidement les mesures nécessaires, comparez les valeurs, effectuez des opérations arithmétiques sur celles-ci, groupez, travaillez avec des intervalles de temps et bien plus encore. Par exemple:

De plus, Prometheus a un
évaluateur qui, en utilisant le même PromQL, peut accéder à TSDB avec la fréquence spécifiée. Pourquoi ça? Exemple: commencez à envoyer des alertes dans les cas où nous avons, selon les mesures disponibles, une erreur 500 sur le serveur Web au cours des 5 dernières minutes. En plus des étiquettes qui étaient dans la demande, l'évaluateur ajoute des étiquettes supplémentaires aux données pour les alertes (que nous configurons), après quoi elles sont envoyées au format JSON à un autre composant Prometheus -
Alertmanager .
Prometheus envoie périodiquement (une fois toutes les 30 secondes) des alertes à Alertmanager, qui les déduplique (après avoir reçu la première alerte, il l'enverra et les suivantes ne seront plus envoyées).
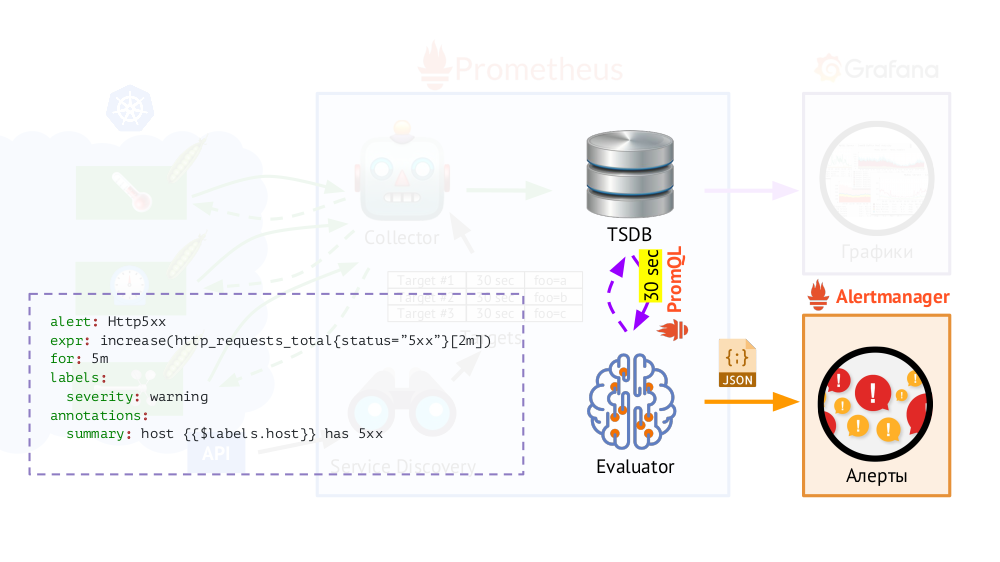 Remarque : Nous n'utilisons pas Alertmanager à la maison, mais envoyons les données de Prometheus directement à notre système, avec lequel nos assistants travaillent, mais cela n'a pas d'importance dans le schéma général.
Remarque : Nous n'utilisons pas Alertmanager à la maison, mais envoyons les données de Prometheus directement à notre système, avec lequel nos assistants travaillent, mais cela n'a pas d'importance dans le schéma général.Prométhée à Kubernetes: la vue d'ensemble
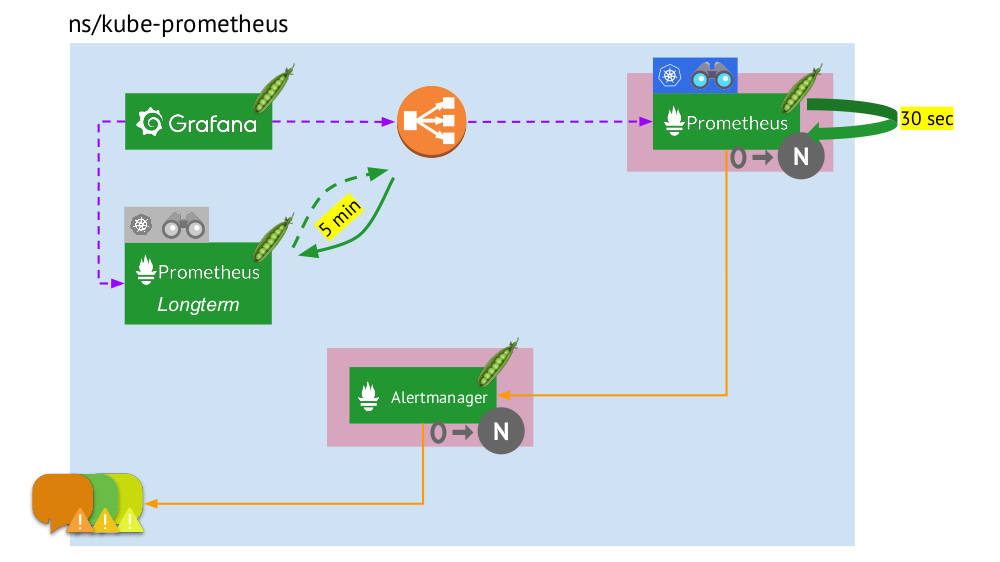
Voyons maintenant comment fonctionne l'ensemble de cet ensemble Prometheus dans Kubernetes:
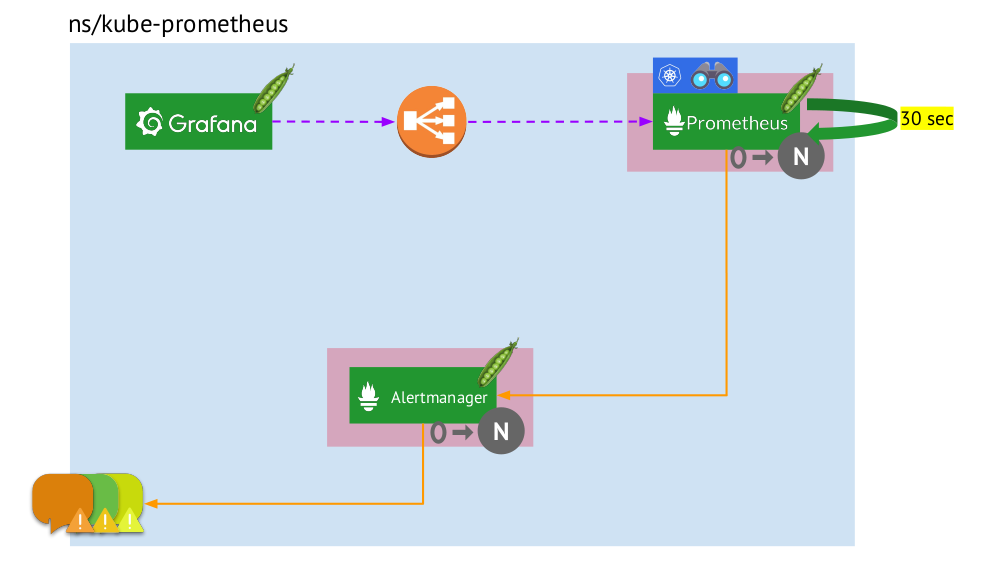
- Kubernetes a son propre espace de noms pour Prométhée (nous avons
kube-prometheus dans l'illustration) . - Cet espace de noms héberge le pod avec l'installation de Prometheus, qui, toutes les 30 secondes, collecte les métriques de toutes les cibles reçues via Service Discovery dans le cluster.
- Il abrite également un pod avec Alertmanager, qui reçoit des données de Prometheus et envoie des alertes (par courrier, Slack, PagerDuty, WeChat, intégration tierce, etc. ) .
- Prometheus fait face à un équilibreur de charge - un service régulier à Kubernetes - et Grafana accède à Prometheus par son intermédiaire. Pour garantir la tolérance aux pannes, Prometheus utilise plusieurs modules avec des installations Prometheus, chacun collectant toutes les données et les stockant dans son TSDB. Grâce à l'équilibreur, Grafana frappe l'un d'eux.
- Le nombre de pods avec Prometheus est contrôlé par le paramètre StatefulSet - nous ne fabriquons généralement pas plus de deux pods, mais vous pouvez augmenter ce nombre. De la même manière, Alertmanager est déployé via StatefulSet, pour la tolérance de panne dont au moins 3 pods sont déjà requis (puisqu'un quorum est nécessaire pour prendre des décisions sur l'envoi d'alertes).
Qu'est-ce qui manque ici? ..
Fédération pour Prométhée
Lorsque les données sont collectées toutes les 30 (ou 60) secondes, l'endroit où les stocker se termine très rapidement, et pire encore, cela nécessite beaucoup de ressources informatiques (lors de la réception et du traitement d'un si grand nombre de points de TSDB). Mais nous voulons stocker et avoir la possibilité de télécharger des informations pour
des intervalles de temps importants et e . Comment y parvenir?
Il suffit d'ajouter
une installation supplémentaire de Prometheus (nous l'appelons à
long terme ) au schéma général, dans lequel Service Discovery est désactivé, et dans le tableau des objectifs, il existe le seul enregistrement statique menant au Prometheus
principal (
principal ).
C'est possible grâce à la fédération : Prometheus vous permet de renvoyer les dernières valeurs de toutes les métriques en une seule requête. Ainsi, la première installation de Prometheus fonctionne toujours (accède toutes les 60 ou, par exemple, 30 secondes) à toutes les cibles du cluster Kubernetes, et la seconde - une fois toutes les 5 minutes, reçoit les données de la première et les stocke pour pouvoir regarder les données pendant une longue période ( mais sans détails approfondis).
 La deuxième installation de Prometheus ne nécessite pas de découverte de service, et le tableau des objectifs sera composé d'une ligne
La deuxième installation de Prometheus ne nécessite pas de découverte de service, et le tableau des objectifs sera composé d'une ligne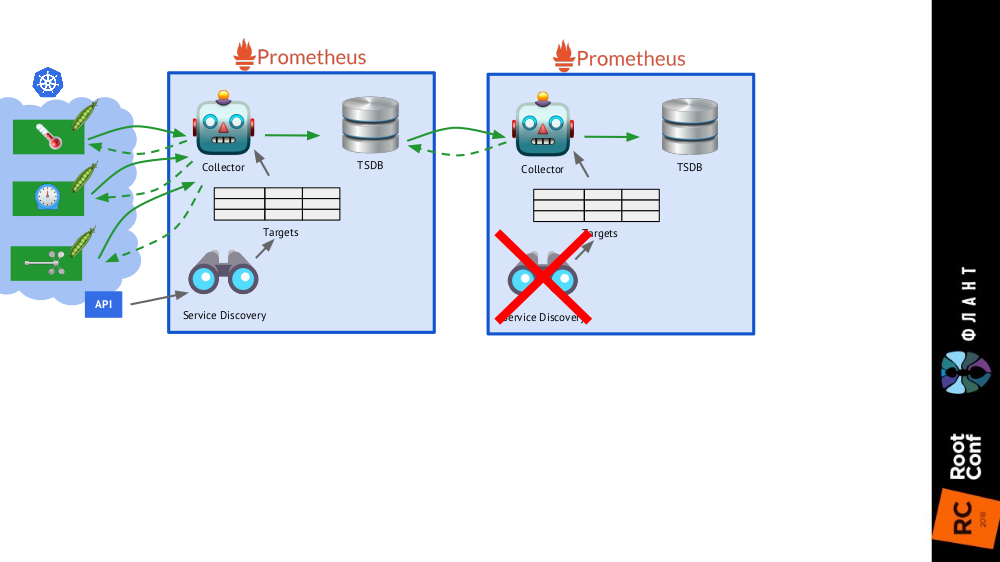 Le tout avec des installations Prometheus de deux types: principal (haut) et long terme
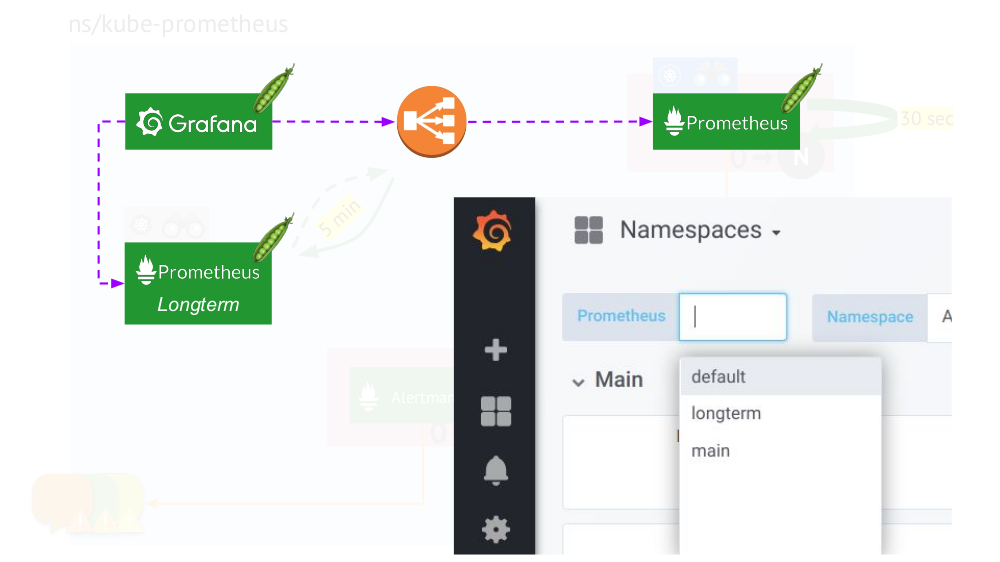
Le tout avec des installations Prometheus de deux types: principal (haut) et long termeLa touche finale consiste à
connecter Grafana aux deux installations de Prometheus et à créer des tableaux de bord d'une manière spéciale afin que vous puissiez basculer entre les sources de données (
principales ou à
long terme ). Pour ce faire, à l'aide du moteur de modèle, remplacez la variable
$prometheus au lieu de la source de données dans tous les panneaux.
Quoi d'autre est important dans les graphiques?
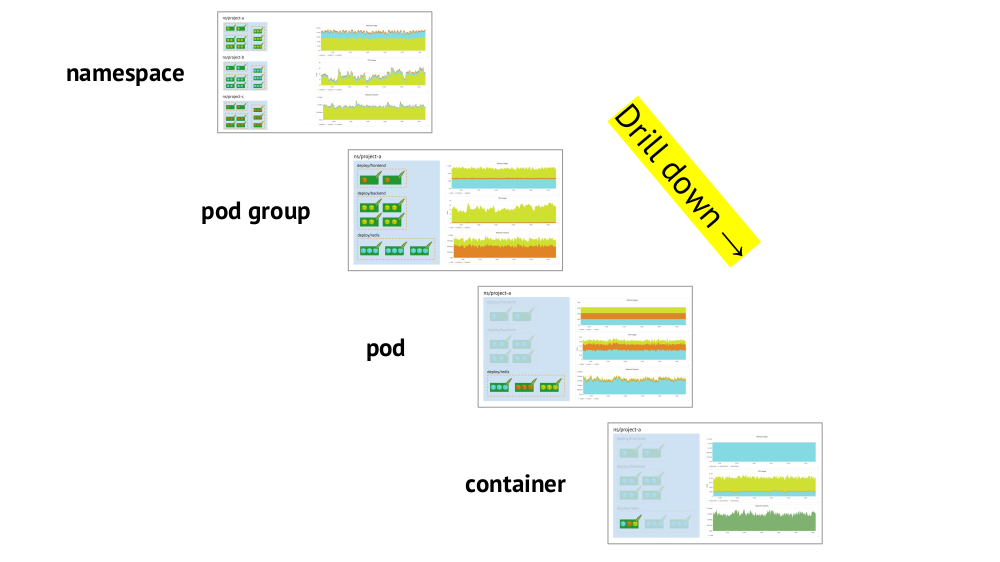
La prise en charge des primitives Kubernetes et la possibilité de
passer rapidement de l'image globale (ou une "vue" inférieure) à un service spécifique et vice versa sont deux points clés à prendre en compte lors de l'organisation des plannings.
La prise en charge des primitives (espaces de noms, pods, etc.) a déjà été mentionnée - c'est une condition nécessaire en principe pour un travail confortable dans les réalités de Kubernetes. Et voici un exemple de drill down:
- Nous regardons les graphiques de consommation de ressources par trois projets (c'est-à-dire, trois espaces de noms) - nous voyons que la partie principale du CPU (ou de la mémoire, ou du réseau, ...) tombe sur le projet A.
- Nous regardons les mêmes graphiques, mais déjà pour les services du projet A: lequel consomme le plus de CPU?
- Nous nous tournons vers les cartes du service souhaité: quel pod est «à blâmer»?
- Nous passons aux diagrammes du pod souhaité: quel conteneur faut-il "blâmer"? C'est le but recherché!
Résumé
- Énoncez avec précision ce qu'est la surveillance. (Laissez le "gâteau à trois couches" servir de rappel à cela ... ainsi que le fait que le faire cuire avec compétence n'est pas facile même sans Kubernetes!)
- N'oubliez pas que Kubernetes ajoute des spécificités obligatoires: regroupement de cibles, découverte de services, grandes quantités de données, flux de métadonnées. De plus:
- oui, certains d'entre eux sont résolus comme par magie («out of the box») dans Prométhée;
- cependant, il reste une autre partie qui doit être surveillée de manière indépendante et réfléchie.
Et rappelez-vous que le
contenu est plus important qu'un système , c'est-à-dire les graphiques et alertes corrects sont principaux, et non Prometheus (ou tout autre logiciel similaire) en tant que tels.

Vidéos et diapositives
Vidéo de la performance (environ une heure):
Présentation du rapport:
PS
Autres reportages sur notre blog:
Vous pouvez également être intéressé par les publications suivantes: