Salutations à la communauté distinguée!
La répétition est la mère de l'apprentissage, et la compréhension de l'analyse syntaxique est une compétence très utile pour tout programmeur, donc je veux soulever à nouveau ce sujet et parler cette fois de l'analyse à l'aide de la méthode de descente récursive (LL), sans formalismes (vous pouvez toujours les utiliser plus tard revenir).
Comme l'écrit le grand D. Strogov, «comprendre, c'est simplifier». Par conséquent, pour comprendre le concept d'analyse à l'aide de la méthode de descente récursive (aka LL-parsing), nous simplifions la tâche autant que possible et écrivons manuellement un analyseur d'un format similaire à JSON, mais plus simple (si vous le souhaitez, vous pouvez ensuite l'étendre à un analyseur JSON à part entière si veulent faire de l'exercice). Écrivons-le, en prenant comme base l'idée de
couper la chaîne .
Dans les livres classiques et les cours de conception de compilateurs, ils commencent généralement à expliquer le sujet de l'analyse et de l'interprétation, en soulignant plusieurs phases:
- Analyse lexicale: division du texte source en un tableau de sous-chaînes (jetons ou jetons)
- Analyse: création d'un arbre d'analyse à partir d'un tableau de jetons
- Interprétation (ou compilation): traverser l'arborescence résultante dans l'ordre souhaité (direct ou inverse) et effectuer des actions d'interprétation ou de génération de code à certaines étapes de cette traversée
pas vraimentparce que dans le processus d'analyse, nous obtenons déjà une séquence d'étapes, qui est une séquence de visites aux nœuds d'arbre, l'arbre lui-même sous forme explicite peut ne pas exister du tout, mais nous n'irons pas encore en profondeur. Pour ceux qui veulent approfondir, il y a des liens à la fin.
Maintenant, je veux utiliser une approche légèrement différente de ce même concept (analyse LL) et montrer comment vous pouvez construire un analyseur LL basé sur l'idée de couper une chaîne: les fragments sont coupés de la chaîne d'origine pendant l'analyse, elle devient plus petite, puis analysée exposé le reste de la ligne. En conséquence, nous arrivons au même concept de descente récursive, mais d'une manière légèrement différente de celle habituellement utilisée. Ce chemin sera peut-être plus pratique pour comprendre l'essence de l'idée. Et sinon, c'est quand même une opportunité de regarder une descente récursive sous un angle différent.
Commençons par une tâche plus simple: il y a une ligne avec des délimiteurs, et je veux écrire une itération sur ses valeurs. Quelque chose comme:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
Comment cela peut-il se faire? La méthode standard consiste à convertir la chaîne délimitée en un tableau ou une liste à l'aide de String.split (en Java) ou names.split (",") (en javascript), et parcourez déjà le tableau. Mais imaginons que nous ne voulons pas ou ne pouvons pas utiliser la conversion en tableau (par exemple, tout à coup, si nous programmons dans le langage de programmation AVAJ ++, dans lequel il n’existe pas de structure de données «tableau»). Vous pouvez toujours analyser la chaîne et suivre les délimiteurs, mais je n'utiliserai pas non plus cette méthode, car elle rend le code de boucle d'itération lourd et, surtout, cela va à l'encontre du concept que je veux montrer. Par conséquent, nous nous référerons à une chaîne délimitée de la même manière que nous nous rapportons aux listes dans la programmation fonctionnelle. Et là, ils définissent toujours les fonctions head (obtenir le premier élément de la liste) et tail (obtenir le reste de la liste). À partir des premiers dialectes de Lisp, où ces fonctions étaient appelées de façon absolument horrible et non intuitive: voiture et cdr (voiture = contenu du registre d'adresses, cdr = contenu du registre de décrémentation. Les légendes anciennes sont profondes, oui, eheheh.).
Notre ligne est une ligne délimitée. Mettez en surbrillance les séparateurs en violet:
Et mettez en surbrillance les éléments de la liste en jaune:

Nous supposons que notre ligne est mutable (elle peut être modifiée) et écrivons une fonction:
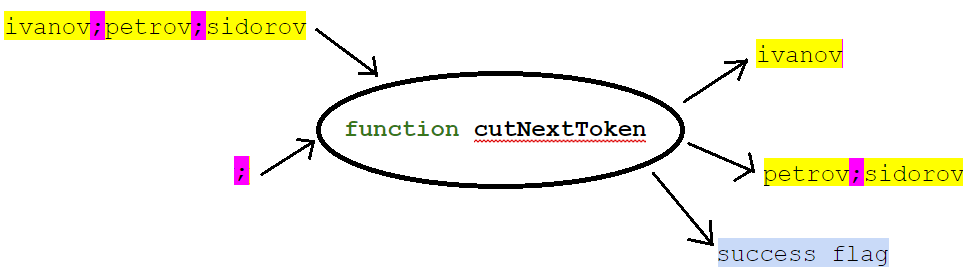
Sa signature, par exemple, pourrait être:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
En entrée de la fonction, nous donnons une liste (sous la forme d'une chaîne avec délimiteurs) et, en fait, la valeur du délimiteur. En sortie, la fonction renvoie le premier élément de la liste (segment de ligne au premier séparateur), le reste de la liste et le signe indiquant si le premier élément a été renvoyé. Dans ce cas, le reste de la liste est placé dans la même variable que la liste d'origine.
En conséquence, nous avons eu l'occasion d'écrire comme ceci:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Sorties comme prévu:
ivanov
Petrov
Sidorov
Nous l'avons fait sans conversion en ArrayList, mais nous avons gâché la variable names, et maintenant elle a une chaîne vide. Cela ne semble pas encore très utile, comme s'ils avaient changé l'alêne pour le savon. Mais allons plus loin. Là, nous verrons pourquoi c'était nécessaire et où cela nous mènera.
Analysons maintenant quelque chose de plus intéressant: une liste de paires clé-valeur. Il s'agit également d'une tâche très courante.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Conclusion:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
Aussi attendu. Et la même chose peut être réalisée avec String.split, sans couper les lignes.
Mais disons que nous voulions maintenant compliquer notre format et passer d'une valeur-clé plate à un format imbriqué rappelant JSON. Maintenant, nous voulons lire quelque chose comme ceci:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
Quel séparateur divise? Si c'est une virgule, alors dans l'un des jetons, nous aurons la ligne
'birthdate':{'year':'1984'
Évidemment pas ce dont nous avons besoin. Par conséquent, nous devons faire attention à la structure de la ligne que nous voulons analyser.
Il commence par une accolade bouclée et se termine par une accolade bouclée (jumelée à elle, ce qui est important). À l'intérieur de ces crochets se trouve une liste de paires 'clé': 'valeur', chaque paire est séparée de la paire suivante par une virgule. La clé et la valeur sont séparées par deux points. Une clé est une chaîne de lettres entourée d'apostrophes. La valeur peut être une chaîne de caractères entourée d'apostrophes, ou il peut s'agir de la même structure, commençant et se terminant par des accolades bouclées. Nous appelons une telle structure le mot «objet», comme il est d'usage de l'appeler en JSON.
Nous venons de décrire de manière informelle la grammaire de notre format de type JSON. En règle générale, les grammaires sont décrites à l'envers, sous une forme formelle, et la notation BNF ou ses variations sont utilisées pour les écrire. Mais maintenant je peux m'en passer, et nous allons voir comment vous pouvez "couper" cette ligne afin qu'elle puisse être analysée selon les règles de cette grammaire.
En fait, notre «objet» commence par une accolade bouclée qui s'ouvre et se termine par une paire qui le ferme. Que peut faire une fonction analysant un tel format? Très probablement, les éléments suivants:
- vérifier que la chaîne passée commence par une accolade ouvrante
- vérifier que la chaîne passée se termine par une paire d'accolades fermantes
- si les deux conditions sont vraies, coupez les parenthèses ouvrantes et fermantes, et ce qui reste, passez à la fonction qui analyse la liste des paires 'clé': 'valeur'
Veuillez noter: les mots «fonction analysant ce format» et «fonction analysant la liste des paires clé»: «valeur» »sont apparus. Nous avons deux fonctionnalités! Ce sont ces fonctions mêmes que dans la description classique de l'algorithme de descente récursive sont appelées «fonctions d'analyse des symboles non terminaux», et qui disent que «pour chaque symbole non terminal, sa propre fonction d'analyse est créée». Ce qui, en fait, l'analyse. Nous pourrions les nommer, disons, parseJsonObject et parseJsonPairList.
De plus, nous devons maintenant faire attention à ce que nous avons le concept de «paire de supports» en plus du concept de «séparateur». Si pour couper une ligne vers le séparateur suivant (deux points entre une clé et une valeur, une virgule entre les paires «clé: valeur»), la fonction cutNextToken nous suffisait, maintenant que nous pouvons utiliser non seulement une chaîne, mais aussi un objet, nous avons besoin fonction "couper à la prochaine paire de supports". Quelque chose comme ça:

Cette fonction coupe un fragment de la ligne de la parenthèse ouvrante à la paire qui la ferme, compte tenu des parenthèses, le cas échéant. Bien sûr, vous ne pouvez pas vous limiter aux crochets, mais utilisez une fonction similaire pour couper diverses structures de blocs qui peuvent être imbriquées: blocs d'opérateur begin..end, if..endif, for..endfor et similaires.
Dessinons graphiquement ce qui va arriver à la chaîne. Couleur turquoise - cela signifie que nous numérisons la ligne vers l'avant jusqu'au symbole surligné en turquoise pour déterminer ce que nous devons faire ensuite. Le violet est «ce qu'il faut couper, c'est quand nous coupons les fragments surlignés en violet de la ligne, et continuons à analyser ce qui en reste.

A titre de comparaison, la sortie du programme (le texte du programme est donné en annexe) qui analyse cette ligne:
Démonstration de l'analyse d'une structure de type JSON
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
À tout moment, nous savons ce que nous nous attendons à trouver dans notre ligne d'entrée. Si nous entrons dans la fonction parseJsonObject, nous nous attendons à ce que l'objet nous soit passé là-bas, et nous pouvons le vérifier par la présence d'une parenthèse ouvrante et fermante au début et à la fin. Si nous entrons dans la fonction parseJsonPairList, nous nous attendons à une liste de paires "clé: valeur" là-bas, et après avoir "mordu" la clé (avant le séparateur ":"), nous nous attendons à ce que la prochaine chose que nous "mordions" soit valeur. Nous pouvons regarder le premier caractère de la valeur et tirer une conclusion sur son type (si l'apostrophe, alors la valeur est du type "chaîne", si le crochet ouvrant est la valeur est du type "objet").
Ainsi, en coupant des fragments de la chaîne, nous pouvons l'analyser par la méthode de l'analyse descendante (descente récursive). Et lorsque nous pouvons analyser, nous pouvons analyser le format dont nous avons besoin. Ou créez votre propre format qui nous convient et démontez-le. Ou proposez un langage spécifique au domaine (DSL) pour notre domaine spécifique et concevez un interpréteur pour celui-ci. Et pour le construire correctement, sans solutions torturées sur regexp ou self-made state-machines qui se posent pour les programmeurs qui essaient de résoudre un problème qui nécessite une analyse, mais qui ne possèdent pas tout à fait le matériel.
Ici. Félicitations à tous pour l'été prochain et je vous souhaite bonne chance, amour et analyseurs fonctionnels :)
Pour plus de lecture:
Idéologique: quelques articles longs mais intéressants à lire de Steve Yeegge:
Nourriture de programmeur richeQuelques citations à partir de là:
Soit vous apprenez les compilateurs et vous commencez à écrire vos propres DSL, soit vous obtenez une meilleure langue
La première grande phase du pipeline de compilation est l'analyse
Le problème du pinocchioCitation de là:
Les conversions de type, le rétrécissement et l'élargissement des conversions, les fonctions ami pour contourner les protections de classe standard, le remplissage des minilangues en chaînes et leur analyse manuelle , il existe des dizaines de façons de contourner les systèmes de type en Java et C ++, et les programmeurs les utilisent tout le temps , car (ils ne savent pas) ils essaient en fait de créer des logiciels, pas du matériel.
Technique: deux articles sur l'analyse de la différence entre les approches LL et LR:
Analyse LL et LR démystifiéeLL et LR en contexte: pourquoi les outils d'analyse sont difficilesEt encore plus profondément dans le sujet: comment écrire un interpréteur Lisp en C ++
Interprète lisp en 90 lignes de C ++Application. Exemple de code (java) qui implémente l'analyseur décrit dans l'article: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {