 Publié par Igor Masternaya, Développeur principal, DataArt Java Community Leader
Publié par Igor Masternaya, Développeur principal, DataArt Java Community LeaderDu 18 au 19 mai, JEEonf s'est tenu à Kiev, l'un des événements les plus attendus pour toute la communauté Java de l'Europe de l'Est. DataArt s'est associé à la conférence. Des intervenants du monde entier se sont exprimés sur quatre étapes: Volker Simonis, représentant SAP chez
JCP et contributeur OpenJDK, Jürgen Höller, ingénieur en chef Pivotal, père de la bien-aimée Spring Framework, Klaus Ibsen, créateur d'Apache Camel, et Hugh McKee, évangéliste chez Lightbend.
Le programme était très chargé: en deux jours plus de 50 représentations, 45 minutes chacune. Pause de 10 minutes - et exécutez un nouveau rapport. Il faudra beaucoup de temps pour regarder toutes les vidéos lorsqu'elles apparaissent sur le réseau. Je décrirai donc brièvement les rapports que j'ai trouvés les plus intéressants et que j'ai visités personnellement.
15 ans de printemps
La conférence a été ouverte par Jürgen Höller. Il a parlé de l'histoire de Spring Framework pendant 15 ans (!), Des configurations XML «préférées» dans la version 0.9 au Spring WebFlux réactif, issu de projets de recherche influencés par
Reactive Manifesto . Jürgen a parlé de la coexistence de Spring MVC et Spring WebFlux dans Spring WEB, a expliqué pourquoi ils ont décidé de ne pas les intégrer en un seul. Le fait est que l'abstraction principale de Spring MVC est l'API Servlet 3.0 et le blocage des E / S, tandis que Spring WebFlux utilise l'abstraction des flux réactifs et des E / S non bloquantes. Vous pouvez exécuter votre service sur SpringWebFlux sur n'importe quel serveur prenant en charge les E / S non bloquantes: Netty, nouvelles versions de Tomcat (> 8.5), Jetty. La création de contrôleurs WebFlux réactifs n'est pas très différente de leur création à l'aide de Spring MVC, mais il existe encore des différences. En traitant une demande utilisateur, le contrôleur réactif ne la traite pas dans le sens habituel, mais crée un pipeline pour traiter la demande. Dispatcher appelle la méthode du contrôleur, qui crée un pipeline et le donne immédiatement en tant que flux d'éditeur. Le flux de l'éditeur dans Reactive Spring est présenté sous la forme de deux abstractions: Flux / Mono. Flux renvoie un flux d'objets, tandis que Mono renvoie toujours un seul objet.
Jürgen a également mentionné la commodité d'utiliser le style Java 8 lorsque vous travaillez avec Spring 5.0 et a promis une version candidate Spring 5.1 en juillet 2018 et une version en septembre, qui prendront en charge Java 11 et travailleront sur le réglage fin des nouvelles fonctionnalités de Spring 5.0.
Intégration Python / Java
Il y avait beaucoup de rapports, et choisir le plus intéressant dans le créneau suivant était difficile. Les descriptions étaient tout aussi intéressantes, alors j'ai fait confiance à mon instinct et j'ai décidé d'écouter Tamas Rozman, le vice-président de BlackRock de Hongrie. Mais il vaudrait mieux que j'écoute à nouveau sur Events Sourcing et CQRS. À en juger par la description, la société est engagée dans la science des données pour un grand fonds d'investissement. L'objectif du rapport était de montrer comment ils ont créé un système évolutif et stable, tout aussi pratique pour les analystes de données avec leur Python que pour les développeurs Java du système principal. Cependant, il me semblait douteux que le système construit se soit avéré vraiment pratique. Pour se lier d'amitié avec Python et Java, les ingénieurs de BlackRock ont eu l'idée de démarrer un interpréteur Python en tant que processus à partir d'une application Java. Ils y sont arrivés pour plusieurs raisons:
- Jython (Python sur la JVM) ne convenait pas en raison de la base de code obsolète 2.7 vs CPython 3.6.
- Ils ont considéré l'option de réécrire la logique de la Data Science en Java comme un processus trop long.
- Apache Spark a décidé de ne pas l'accepter, car, comme l'a expliqué le conférencier, vous ne pouvez pas mélanger des charges de travail écrites en Java et en Python. Bien qu'il ne soit pas clair pourquoi UDF et UDFA ne correspondaient pas [ 2 ]. De plus, Spark ne convenait pas, car ils avaient déjà une sorte de cadre de travail et ils ne voulaient pas vraiment en introduire un nouveau. Et, en fin de compte, ils n'ont pas non plus de Big Data, et tout le traitement se résume à des statistiques sur des fichiers pathétiques de 100 Mo.
La communication de Java avec le processus Python a été organisée à l'aide de fichiers mappés en mémoire (un fichier est utilisé comme fichier de données d'entrée) et de commandes (le deuxième fichier est la sortie du processus Python). Ainsi, la communication était quelque chose sous la forme de:
Java: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
Java: 1 + succès | 64
Python: succès | 65
Les principaux problèmes d'une telle intégration, Tamas a appelé la surcharge lors de la sérialisation et la désérialisation des paramètres d'entrée / sortie.

Java 10 App CDS
Après une présentation sur les subtilités de l'exécution de Python, je voulais vraiment écouter quelque chose de profondément technique du monde Java. Je suis donc allé au rapport de Volker Simonis, dans lequel il a parlé de la fonction de partage de données de classe Application de
Java 10+ . Dans le monde moderne construit sur des microservices dans Docker, la possibilité de partager Java Codecache et Metaspace accélère le lancement de l'application et économise de la mémoire. L'image montre les résultats du lancement de tomates dockées avec une archive partagée / partagée des classes Tomcat. Comme vous pouvez le voir, pour le deuxième processus, certaines pages en mémoire sont déjà marquées comme shared_clean - ce qui signifie que le processus actuel et au moins un (le deuxième tomcat en cours d'exécution) s'y réfèrent.

Les détails sur la façon de jouer avec CDS dans OpenJDK 10 peuvent être trouvés sur:
App CDS . En plus de diviser les classes d'applications entre les processus, il est prévu à l'avenir de partager les chaînes internes dans le
JEP-250 .
Principales limitations d'AppCDS:
Ne fonctionne pas avec des classes jusqu'à 1,5.
- Vous ne pouvez pas utiliser des classes chargées à partir de fichiers (uniquement les archives .jar).
- Les classes modifiées par le chargeur de classe ne peuvent pas être utilisées.
- Les classes chargées par plusieurs chargeurs de classe ne peuvent être réutilisées qu'une seule fois.
- La réécriture de code octet ne fonctionne pas, ce qui peut entraîner une baisse des performances allant jusqu'à 2%. JDK-8074345

Pipeline de traitement du langage naturel avec Apache Spark
Le rapport sur la PNL et Apache Spark a été présenté par Vitaliy Kotlyarenko - ingénieur de Grammarly. Vitaliy a montré comment le prototype NLP-Jobs Grammarly sur Apache Zeppelin. Un exemple a été la construction d'un pipeline simple pour la modélisation thématique basée sur l'algorithme
LDA de l'archive Internet
crawl commune . Les résultats de la modélisation des sujets ont été utilisés pour filtrer les sites avec un contenu inapproprié comme exemple de la fonction de contrôle parental. Pour créer le pipeline, nous avons utilisé des scripts Terraform et
AWS EMR Spark cluster, qui vous permettent de déployer Spark Cluster avec YARN sur Amazon. Schématiquement, le pipeline ressemble à ceci:
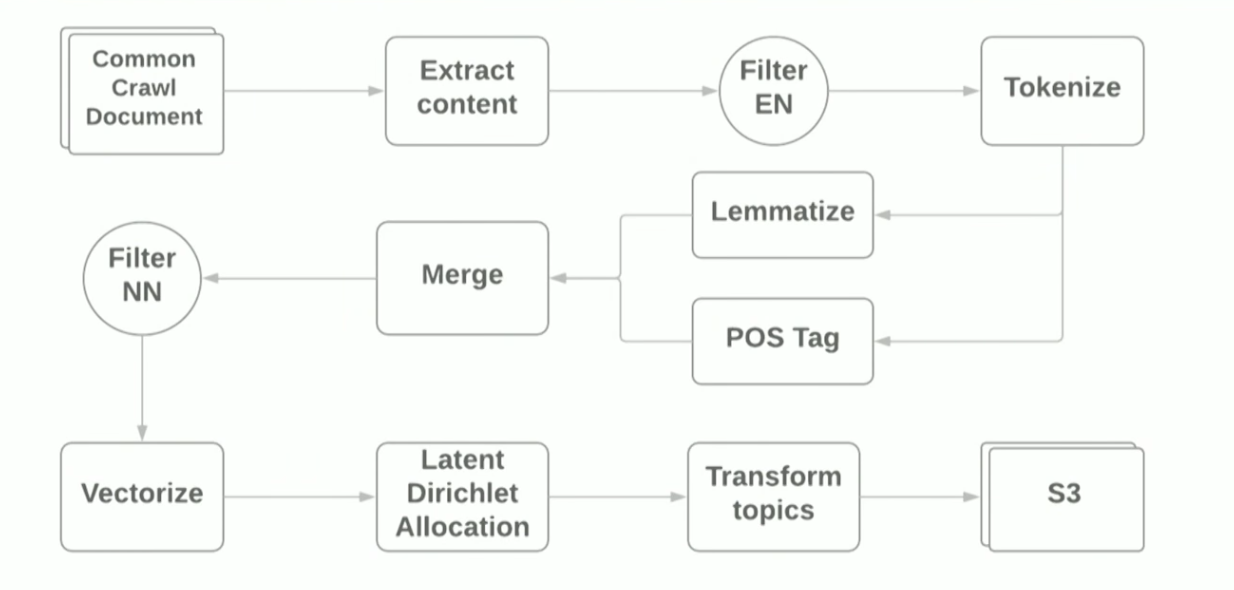
L'objectif du rapport était de montrer que l'utilisation de cadres modernes pour créer un prototype pour les tâches ML est assez simple, cependant, en utilisant des bibliothèques standard, vous rencontrez toujours des difficultés. Par exemple:
- Lors de la première étape de lecture des fichiers WARC à l'aide de la bibliothèque HadoopInputFormat , IllegalStateExceptions s'est parfois bloqué en raison d'en-têtes de fichier incorrects, la bibliothèque a dû être réécrite et les fichiers incorrects ignorés.
- Les dépendances sur la goyave - la bibliothèque de définitions de langage - se heurtaient aux dépendances que Spark traîne sur lui-même. Java 8 a aidé, avec l'aide duquel il était possible de jeter des dépendances sur la goyave dans la bibliothèque utilisée.
Au cours de la démonstration, nous avons surveillé l'exécution du travail à l'aide de l'interface utilisateur Spark standard et du sous-système de surveillance
Ganglia , qui est automatiquement disponible lors du déploiement sur AWS EMR. L'auteur s'est concentré sur la carte thermique Server Load Distribution, qui montre la répartition de la charge entre les nœuds du cluster, et a donné des conseils généraux sur l'optimisation du travail de Spark Job: augmentation du nombre de partitions, optimisation de la sérialisation des données, analyse des journaux GC. Vous pouvez en savoir plus sur l'optimisation des travaux Spark
ici . Les fichiers source de la démo se trouvent dans le
github de l' auteur du rapport.
Graal, Truffle, SubstrateVM et autres avantages: quels sont-ils et pourquoi en avez-vous besoin
Le plus attendu pour moi était un rapport d'Oleg Chirukhin de JUG.ru. Il a expliqué comment optimiser le code fini à l'aide du Graal. Qu'est-ce que le Graal? The Grail est une marque
Oracle Labs qui combine le compilateur JIT (juste à temps), le cadre pour l'écriture de langages DSL - Truffle - et la JVM spéciale (
SubstrateVM ) - une machine virtuelle universelle
à monde fermé pour laquelle vous pouvez écrire en JavaScript, Rubis, Python, Java, Scala. Le rapport s'est concentré sur le compilateur JIT et ses tests en production.
Tout d'abord, rappelez le processus d'exécution du code par la machine Java et notez que Java possède déjà deux compilateurs: C1 (compilateur client) et C2 (compilateur serveur). Grail peut être utilisé comme compilateur C2.
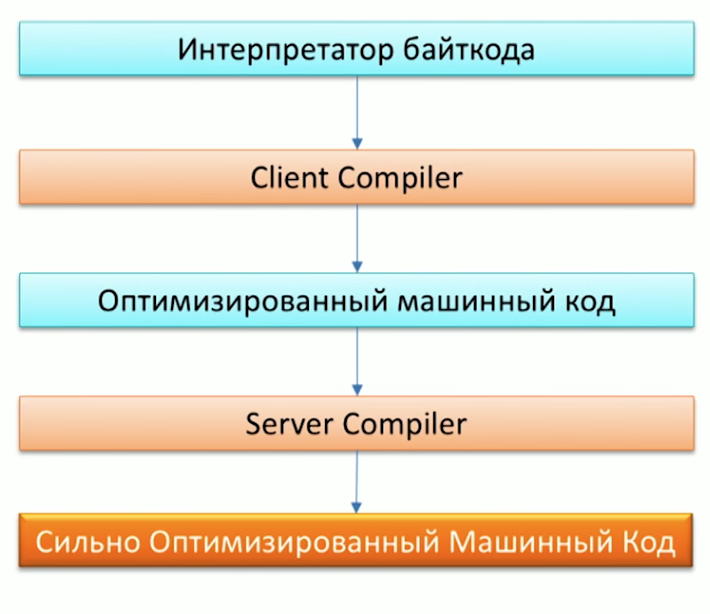
Lorsqu'on lui a demandé pourquoi nous avions besoin d'un autre compilateur, l'un des employés d'Oracle Labs, le Dr Chris Seaton, a très bien répondu dans l'article
Comprendre le fonctionnement de Graal . En bref, l'idée originale du projet Graal, ainsi que du projet
Metropolis , est de réécrire des parties du code JVM écrit en C ++ en Java. Cela permettra à l'avenir de compléter commodément le code. Par exemple, l'une des optimisations -
Analyse d'évasion spéciale - est déjà dans le Graal, mais pas dans Hotspot -
car développer le code Graal est beaucoup plus facile que le code C2 .
Cela semble génial, mais comment cela fonctionnera-t-il dans la pratique dans mon projet, demandez-vous? Graal convient aux projets:
- Ce qui jette beaucoup, créant beaucoup de petits objets.
- Écrit dans le style de Java 8, avec un tas de ruisseaux et de lambdas.
- Utilisation de différents langages: Ruby, Java, R.
L'un des premiers en production, le Graal a commencé à être utilisé sur Twitter. Vous pouvez en savoir plus à ce sujet dans une interview avec Christian Talinger, publiée sur Habré (
interview_1 et
interview_2 ). Là, il explique qu'en remplaçant C2 par Graal, Twitter a commencé à économiser environ 8% de l'utilisation du processeur, ce qui est assez bon compte tenu de la taille de l'organisation.
Lors de la conférence, nous avons également pu vérifier la vitesse de Graal en lançant l'une des références Scala en dessous -
Scala DaCapo . En conséquence, sur Graal, l'indice de référence est passé en ~ 7000 ms, et sur une JVM régulière en ~ 14000 ms! Pourquoi cela est arrivé, vous pouvez le voir en regardant les tests gclog. Le nombre d'échec d'allocation lors de l'utilisation de Graal est nettement inférieur à celui de Hotspot. Cependant, vous ne pouvez toujours pas dire que le Graal sera la solution aux problèmes de performances de votre application Java. Oleg a également montré une histoire d'échec dans son rapport, comparant le travail d'
Apache Ignite sous le Graal et sans lui - il n'y a eu aucun changement de performance notable.

Conception de microservices tolérants aux pannes
Un autre rapport sur l'architecture de microservice à sécurité intégrée a été lu par Orkhan Gasimov d'AppsFlyer. Il a introduit des modèles de conception populaires pour la création d'applications distribuées. Nous en connaissons peut-être beaucoup, mais se promener et se souvenir de chacun d'eux ne fera pas de mal du tout.
Les principaux problèmes de tolérance aux pannes des services avec lesquels les schémas décrits dans le rapport sont appelés à lutter sont: le réseau, les charges de pointe, les mécanismes RPC de communication entre les services.
Pour résoudre les problèmes avec le réseau, lorsque l'un des services n'est plus disponible, nous devons pouvoir le remplacer rapidement par un autre du même. En pratique, cela peut être réalisé avec plusieurs instances du même service et une description des chemins alternatifs vers ces instances, qui est un modèle de
découverte de service . S'engager dans des services de
pulsation et enregistrer de nouveaux services sera une instance distincte - Service Registry. Il est de coutume d'utiliser le célèbre
gardien de zoo ou
consul comme registre de service. Qui, à leur tour, ont également une nature distribuée et un support pour la tolérance aux pannes.
Après avoir résolu les problèmes de réseau, nous nous tournons vers le problème des pics de charge lorsque certains services sont en charge et traitent les demandes beaucoup plus lentement qu'en mode normal. Pour le résoudre, vous pouvez utiliser le modèle de
mise à l'
échelle automatique . Il assumera non seulement la tâche de faire évoluer automatiquement les services fortement chargés, mais arrêtera également les instances après la période de charge de pointe.
Le dernier chapitre du rapport de l'auteur était une description des problèmes possibles de communication interne RPC interservices. Urahan a accordé une attention particulière à la thèse "L'utilisateur ne devrait pas attendre un message d'erreur pendant longtemps." Une telle situation peut se produire si sa demande est traitée par la chaîne de service et que le problème se situe en bout de chaîne: en conséquence, l'utilisateur peut attendre que la demande soit traitée par chacun des services de la chaîne et ne reçoit une erreur qu'à la dernière étape. Pire encore, si le service final est surchargé et après une longue attente, le client recevra une erreur HTTP-ERROR: 500.
Pour lutter contre de telles situations, vous pouvez utiliser
Timeout s, cependant, les requêtes qui peuvent toujours être traitées correctement peuvent tomber dans le timeout. Pour ce faire, la logique de temporisation peut être compliquée et une valeur de seuil spéciale pour le nombre d'erreurs de service par intervalle de temps peut être ajoutée. Lorsque le nombre d'erreurs dépasse la valeur seuil, nous comprenons que le service est sous charge et le considérons comme indisponible, ce qui lui donne le temps nécessaire pour faire face aux tâches en cours. Cette approche décrit le modèle de
disjoncteur . Vous pouvez également utiliser CircuitBreaker.html "> Circuit Beaker comme mesure supplémentaire pour la surveillance, ce qui vous permet de répondre rapidement aux problèmes possibles et d'identifier clairement les chaînes de service qui les rencontrent. Pour ce faire, chaque appel de service doit être encapsulé dans Circuit Breaker.
Toujours dans le rapport, l'auteur a rappelé le modèle de
redondance N-Modular , conçu pour "traiter les demandes plus rapidement si possible", et a fourni un bel exemple de son utilisation pour valider l'adresse d'un client. La demande dans leur système via le cache d'adresses a été envoyée immédiatement à plusieurs fournisseurs de Geo Map, ce qui a remporté la réponse la plus rapide.
En plus des modèles décrits, les éléments suivants ont été mentionnés:
- Modèle Fast Path , qui peut être appliqué, par exemple, lors de la mise en cache des résultats de requête. L'accès au cache est alors un chemin rapide.
- Modèle de noyau d'erreur - un modèle du monde d'Akka qui implique de diviser une tâche en sous-tâches et de déléguer des sous-tâches aux acteurs en aval. De cette façon, la flexibilité de gestion des erreurs d'exécution de sous-tâche est obtenue.
- Instance Healer , qui suppose l'existence d'un service spécial - un superviseur qui gère d'autres services et répond aux changements de leur état. Par exemple, en cas d'erreur dans le service, le superviseur peut redémarrer le service problématique.

Sourcing d'événements en cluster et CQRS avec Akka et Java
Le dernier rapport sur lequel je veux attirer votre attention a été lu par l'un des évangélistes et architectes Lightbend Hugh McKee. Lightbend (anciennement Typesafe) est quelque chose comme Oracle, mais pour le langage Scala. La société développe également activement le cadre
Akka.io. Dans un rapport, Hugh a parlé de la mise en œuvre de l'approche populaire
CQRS (Command Query Responsibility Commands / SEGREGATION) sur le cadre Akka. Schématiquement, l'architecture du système CQRS ressemble à ceci:
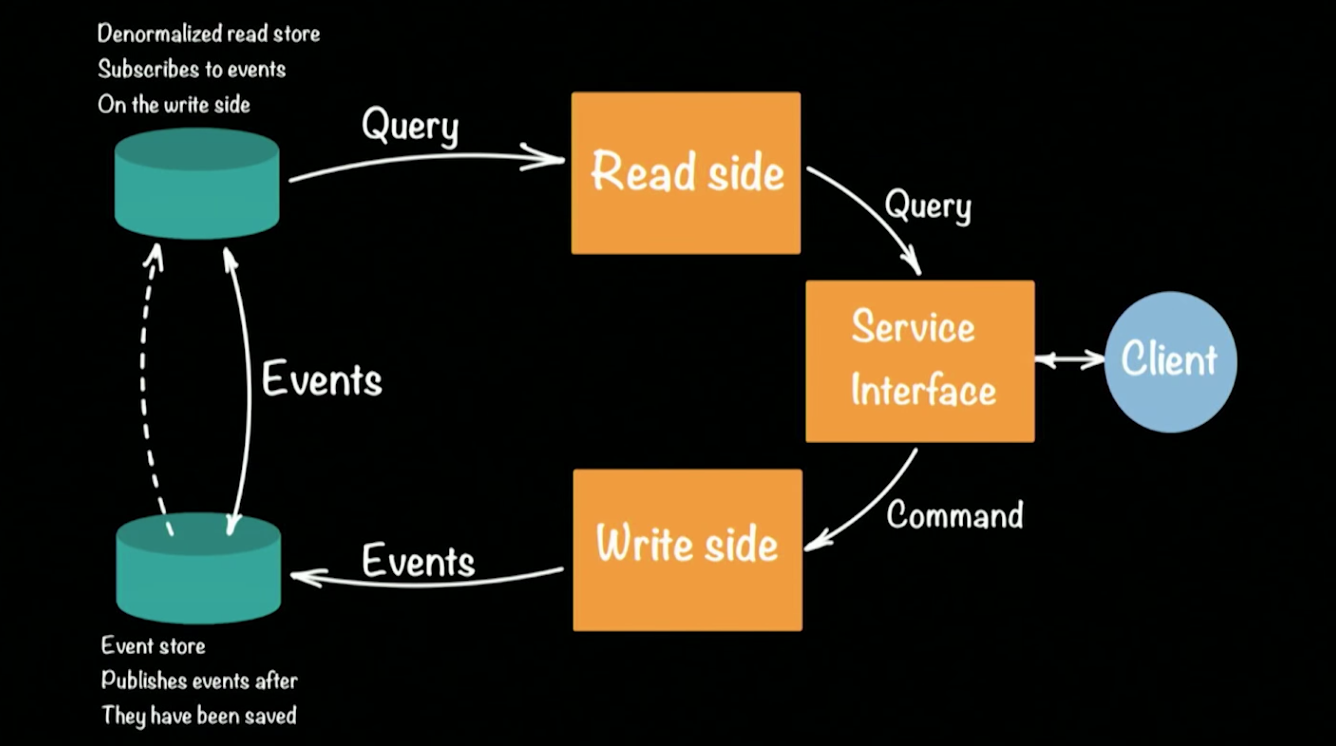
Hugh a pris un prototype de banque comme exemple de système fonctionnel. Un client dans l'architecture CQRS effectue deux opérations: requête, commande. Chaque équipe (par exemple, une transaction bancaire transférant de l'argent d'un compte à un autre) génère un événement (un fait accompli) qui sera enregistré dans l'EventStore (par exemple: Cassandra). L'agrégation de la chaîne (dépôt d'argent sur un compte, transfert de compte à compte, retrait à un guichet automatique) d'événements forme l'état actuel du client, son solde d'argent sur le compte. Les demandes pour l'état actuel vont à un référentiel séparé, un instantané du référentiel d'événements, car il est inutile de conserver un historique complet d'un compte bancaire. Il suffit de mettre à jour périodiquement le statut cast pour chaque utilisateur.
Cette approche permet de récupérer automatiquement lorsque des erreurs se produisent: pour cela, nous devons obtenir la dernière distribution de l'état de l'utilisateur et lui appliquer tous les événements qui se sont produits avant que l'erreur ne se produise. En raison de la présence de deux stockages, l'architecture CQRS tolère bien les charges de pointe (pointes) émergentes. Un grand nombre d'événements chargera le magasin d'événements, mais n'affectera pas le magasin de lecture, et les utilisateurs pourront toujours répondre aux requêtes dans la base de données.
Revenons au prototypage du système bancaire sur Akka et CQRS. Chaque client de la banque / compte / équipe éventuelle du système sera représenté par un (!)
Acteur . Une grande banque peut prendre en charge des centaines de milliers de comptes, et cela ne sera pas un problème pour Akka. La structure prête à l'emploi prend en charge le clustering et peut être exécutée sur des centaines de machines virtuelles Java. Si l'une des machines du cluster tombe en panne, Akka fournit des mécanismes spéciaux qui répondent automatiquement à de telles situations: dans notre cas, l'acteur du client peut être recréé à nouveau sur n'importe quelle machine disponible dans le cluster, et son état sera relu à partir du référentiel.
Un thread séparé n'est pas créé pour un acteur - cela permet de prendre en charge des dizaines de milliers d'acteurs au sein d'une même machine virtuelle Java. Dans le même temps, l'acteur garantit que chaque demande sera traitée séparément (!) Dans l'ordre de réception des demandes. Cette garantie élimine automatiquement les éventuelles conditions de concurrence lors du traitement des demandes. Vous pouvez comprendre le prototype du système plus en détail en ouvrant son code à l'aide des liens dans GitHub. Chaque sous-projet montre la mise en œuvre des étapes les plus complexes de la construction d'un prototype:
guêpes.
Les enregistrements de tous les rapports apparaîtront en ligne dans quelques semaines. J'espère que cet article vous aidera à déterminer l'ordre de visionnage, d'autant plus que je pense qu'il vaut la peine de regarder les performances.