Les SGBD à colonnes se sont activement développés au cours des années zéro, au moment où ils ont trouvé leur créneau et ne rivalisent pratiquement pas avec les systèmes traditionnels en minuscules. Sous la coupe, l'auteur comprend si une solution universelle est possible et comment elle est pratique.
"Il y a des progrès dans tout. ... n'ayez pas peur qu'ils vous appellent au bureau et disent:" Nous avons consulté ici, et demain vous serez cantonné ou brûlé à votre choix. "Ce serait un choix difficile. Je pense qu'il serait déconcerté par beaucoup d'entre nous. »
Yaroslav Hasek. Aventures du brave soldat Schweik.
Contexte
Combien de bases de données existent, tant cette confrontation idéologique est grande. Par curiosité, l'auteur a trouvé un livre de J. Martin d'IBM [1] dans les bacs en 1975 et est immédiatement tombé sur les mots (p. 183): «Les relations binaires sont utilisées dans les œuvres [...], c'est-à-dire relations de seulement deux domaines. Il est connu que les relations binaires donnent la plus grande flexibilité à la base. Cependant, dans les tâches commerciales, des relations de divers degrés sont pratiques. » Les relations sont comprises ici comme des relations relationnelles. Et les œuvres mentionnées datent de 1967 ... 1970.
Que Sybase IQ soit le premier SGBD à colonnes utilisé industriellement, mais au moins au niveau des idées, tout a été dit 25 ans avant.
À l'heure actuelle, les SGBD suivants sont pris en charge dans les colonnes ou à un degré ou un autre (cela est principalement pris
ici ):
Commercial
Libre et open source
Les différences
Une relation relationnelle est une collection de tuples, essentiellement une table à deux dimensions. En conséquence, il existe deux options de stockage: en ligne ou en colonne. La séparation est un peu artificielle, logique. Les développeurs de bases de données ont depuis longtemps cessé de planifier
des enregistrements de
batterie et de piste. Il incombe aux administrateurs de SGBD de décomposer de manière optimale les données du SGBD en un ou plusieurs systèmes de fichiers, et la manière dont les systèmes de fichiers organisent les données sur les disques physiques est principalement connue des développeurs de systèmes de fichiers.
Il serait logique de laisser le SGBD décider dans quel ordre stocker les données. Ici, nous parlons d'un SGBD hypothétique qui prend en charge les deux options pour organiser le stockage de données et a la capacité d'assigner une table à n'importe lequel d'entre eux. Nous ne considérons pas une option assez populaire pour prendre en charge deux bases de données - une pour le travail, la seconde pour les analyses / rapports. Ainsi que des index de colonnes à la Microsoft SQL Server. Pas parce que c'est mauvais, mais pour tester l'hypothèse qu'il existe un moyen plus élégant.
Malheureusement, aucun SGBD hypothétique ne peut choisir la meilleure façon de stocker des données. Parce que ne comprend pas comment nous allons utiliser ces données. Et sans cela, il est impossible de faire un choix, bien que ce soit très important.
La qualité la plus précieuse d'un SGBD est la capacité de traiter rapidement les données (et
les exigences
ACID , bien sûr). La vitesse du SGBD est principalement déterminée par le nombre d'opérations sur disque. Deux cas extrêmes en découlent:
- Les données sont rapidement modifiées / ajoutées, vous devez avoir le temps d'écrire. La solution évidente - une ligne (tuple), si possible, est située sur une seule page, cela ne peut pas être fait plus rapidement.
- Les données changent extrêmement rarement ou ne changent pas du tout, nous lisons les données plusieurs fois et seul un petit nombre de colonnes sont impliquées à la fois. Dans cette situation, il est logique d'utiliser une variante de stockage par colonne, puis lors de la lecture, le nombre minimum de pages possible augmentera.
Mais ce sont des cas extrêmes, dans la vie, tout n'est pas si évident.
- Si vous souhaitez lire l'intégralité du tableau, du point de vue du nombre de pages, les données ne sont pas importantes ligne par ligne ou colonne. C'est-à-dire qu'il y a une différence, bien sûr, dans la version colonne, nous avons la possibilité de mieux compresser les informations, mais pour le moment ce n'est pas important.
- Mais en termes de performances, il y a une différence car avec l'enregistrement ligne par ligne, la lecture à partir du disque se fera de manière plus linéaire. Moins de têtes de disque dur vers l'avant, des lectures sensiblement plus rapides. Une lecture de fichier plus prévisible lors de l'enregistrement ligne par ligne permet au système d'exploitation (OS) d'utiliser plus efficacement le cache disque. Ceci est important même pour les disques SSD, car le chargement par hypothèse ( lecture anticipée ) mène souvent au succès.
- La mise à jour ne modifie pas toujours l'intégralité de l'enregistrement. Supposons qu'un cas courant soit un changement sur deux colonnes. Ensuite, il sera bon que les données de ces colonnes soient sur une seule page, car vous n'avez besoin que d'un verrou de page par enregistrement au lieu de deux. D'un autre côté, si les données sont réparties sur plusieurs pages, cela permet à différentes transactions de modifier les données d'une ligne sans conflits.
Voici un examen plus approfondi. Un choix hypothétique est de rendre la table en minuscules ou en colonnes, que le SGBD doit faire au moment de sa création. Mais pour faire ce choix, il serait bon de savoir, par exemple, comment nous allons changer ce tableau. Vous devriez peut-être lancer une pièce?
- Supposons que nous utilisons une structure arborescente (ex: index clusterisé) pour le stockage. Dans ce cas, l'ajout ou même la modification de données peut entraîner un rééquilibrage de l'arbre ou de sa partie. Dans le stockage en ligne, il existe (au moins un) verrou d'écriture, ce qui peut affecter une partie importante de la table. Dans la version en colonnes, de telles histoires se produisent beaucoup plus souvent, mais font beaucoup moins de dégâts car ne concernent qu'une colonne spécifique.
- Pensez à filtrer par index. Supposons que l'échantillon soit suffisamment clairsemé. L'enregistrement ligne par ligne a alors la préférence, car dans ce cas, le rapport d'informations utiles à lire pour l'entreprise est meilleur.
- Si la filtration donne un débit plus dense et que seule une petite partie des colonnes est requise, la version colonne devient moins chère. Où est le fossé entre ces cas, comment le déterminer?
En d'autres termes, notre hypothétique SGBD n'assumera en aucun cas la responsabilité de choisir entre les options de stockage ligne par ligne et colonne, cela devrait être fait par le concepteur de la base de données.
Cependant, compte tenu de ce qui précède, le concepteur de base de données sera également dans un choix très difficile. Il dérouterait beaucoup d'entre nous.
Et si
Essentiellement, les variantes colonne et ligne - les cas extrêmes d'une idée - coupent le tableau en «rubans» et stockent les données ligne par ligne à l'intérieur de chaque bande. Dans un cas seulement, la bande est une, dans l'autre la bande dégénère en une colonne.
Alors pourquoi ne pas autoriser les options intermédiaires - si les données de certaines colonnes se lisent / se lisent ensemble, même si elles sont sur la même bande. Et s'il n'y avait pas de données (NULL) dans la bande, alors rien ne doit être stocké. Dans le même temps, le problème de la taille maximale des lignes est supprimé - vous pouvez diviser le tableau lorsqu'il existe un risque que la ligne ne tienne pas sur une seule page.
Cette idée n'est pas si originale, l'auteur a eu la chance de la voir et de l'appliquer lui-même. L'élément de nouveauté est de permettre au concepteur de base de données de déterminer comment sa table sera divisée en parties et sous quelle forme les données iront sur le disque.
Nous l'avons fait pour nous comme suit:
- lors de la création d'une table, les informations sur nos préférences sont transmises au processeur SQL à l'aide de pragmas
- initialement, lors de la création d'un tableau, il est supposé que la ligne entière sera située sur une page de l'arbre B
- cependant, vous pouvez utiliser - - #pragma page_break
afin d'indiquer au processeur SQL que les colonnes suivantes seront situées sur une autre page (dans une autre arborescence) - utilisation - - #pragma column_based
permet de dire de façon concise que les colonnes qui vont plus loin sont chacune situées sur son propre arbre - - - #pragma row_based
annule l'action basée sur les colonnes - ainsi, la table se compose d'un ou plusieurs arbres B, dont le premier élément clé est un champ IDENTITY caché. On pense que l'ordre dans lequel les enregistrements sont créés (peut être en corrélation avec l'ordre dans lequel les enregistrements sont lus) est également important et ne doit pas être négligé. La clé primaire est une arborescence distincte, cependant, cela ne s'applique pas au sujet.
À quoi cela peut-il ressembler dans la pratique?
Par exemple, comme ceci:
CREATE TABLE twomass_psc ( ra double precision, decl double precision, …
Par exemple, la table principale de l'atlas
2MASS est prise, la légende
ici et
ici .
J ,
H ,
K - sous-bandes infrarouges, il est logique de stocker les données ensemble, car dans la recherche, elles sont traitées ensemble. Ici,
par exemple :
La première photo rencontrée.
Ou
ici , encore plus beau:
Il est temps de confirmer que cela a un sens pratique.
Résultats
Ci-dessous est présenté:
- diagramme de phases (numéro X de la page enregistrée, numéro Y de la dernière enregistrée précédemment) de la procédure d'écriture des pages (nombres logiques) sur le disque lors de la création d'une table en deux versions
- dans une colonne, il est désigné par_1
- et pour un tableau découpé en 16 colonnes, il est désigné par_16
- total colonnes 181

Examinons de plus près comment cela fonctionne:
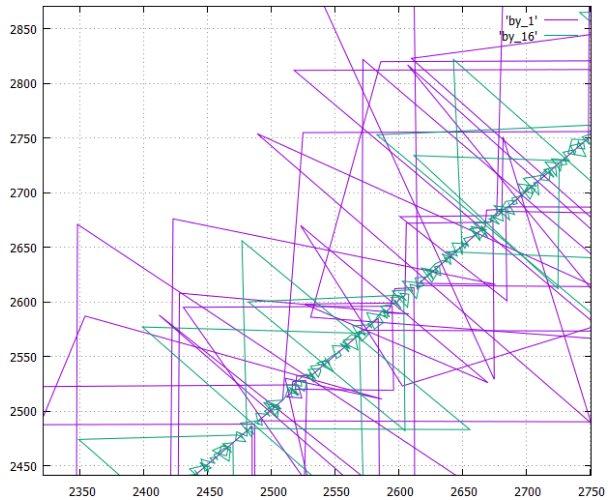
- L'option by_16 est sensiblement plus compacte, ce qui est logique, l'ultime - l'option ligne donnerait juste une ligne droite (avec des valeurs aberrantes).
- Valeurs aberrantes triangulaires - enregistrer des pages intermédiaires d'arbres B.
- L'enregistrement de données est affiché, évidemment, la lecture ressemblera à ceci.
- Il a été dit plus haut que toutes les options enregistrent la même quantité d'informations et que le flux à soustraire est approximativement le même (± efficacité de compression).
Mais ici, il est très clairement démontré que dans une version colonne, les arbres croissent à des vitesses différentes en raison des spécificités des données (dans une colonne, ils se répètent et se compressent souvent très bien, dans l'autre colonne - le bruit du point de vue du compresseur). Par conséquent, certains arbres avancent, d'autres sont en retard, lors de la lecture, nous obtenons objectivement un mode de lecture "déchiré" qui est très désagréable pour le système de fichiers. - Donc, by_16 est beaucoup plus préférable pour la lecture que pour les colonnes, il est presque aussi confortable que pour les lignes.
- Mais en même temps, la variante by_16 présente les principaux avantages d'une variante par colonne dans le cas où un petit nombre de colonnes est requis. Surtout si vous ne divisez pas la table mécaniquement pour 16 pièces, mais de manière significative, après avoir analysé les probabilités de leur utilisation conjointe.
Les sources
[1] J. Martin. Organisation de bases de données dans des systèmes informatiques. Le monde, 1978
[2]
Index des colonnes, caractéristiques d'utilisation[3] Daniel J. Abadi, Samuel Madden, Nabil Hachem.
ColumnStores vs. RowStores: en quoi sont-ils vraiment différents? , Actes de la Conférence internationale ACM SIGMOD sur la gestion des données, Vancouver, BC, Canada, juin 2008
[4] Michael Stonebraker, Uğur Çetintemel.
«Une taille unique»: une idée dont le temps est venu et disparu , 2005