Le 29 mai,
une autre conférence 2018 s'est tenue - la conférence annuelle et la plus importante de Yandex. Le YaC de cette année comprenait trois sections: les technologies marketing, la ville intelligente et la sécurité de l'information. Dans la poursuite, nous publions l'un des principaux rapports de la troisième section - de Yuri
Leonovich tracer0tong de la société japonaise Rakuten.
Comment authentifions-nous? Dans notre cas, il n'y a rien d'extraordinaire, mais je veux mentionner une méthode. En plus des types traditionnels - captcha et mots de passe à usage unique - nous utilisons Proof of Work, PoW. Non, nous n'exploitons pas de bitcoins sur les ordinateurs des utilisateurs. Nous utilisons PoW pour ralentir l'attaquant et parfois même bloquer complètement, le forçant à résoudre une tâche très difficile, sur laquelle il passera beaucoup de temps.
- Je travaille pour Rakuten International Corporation. Je veux parler de plusieurs choses: un peu de moi, de notre entreprise, de la façon d'évaluer le coût des attaques et de savoir si vous devez faire de la prévention de la fraude. Je veux vous dire comment nous avons collecté notre prévention de la fraude et quels modèles nous avons utilisés ont donné de bons résultats dans la pratique, comment ils ont fonctionné et ce qui peut être fait pour prévenir les fraudes.

À propos de moi brièvement. Il a travaillé chez Yandex, était impliqué dans la sécurité des applications Web et chez Yandex, il a également créé un système pour prévenir les fraudes. Je suis capable de développer des services distribués, j'ai un peu de formation mathématique qui aide à l'utilisation de l'apprentissage automatique dans la pratique.
Rakuten n'est pas très connu en Fédération de Russie, mais je pense que vous le savez tous pour deux raisons. Sur plus de 70 de nos services en Russie, Rakuten Viber est connu, et s'il y a des fans de football ici, vous savez peut-être que notre entreprise est le sponsor général du club de football de Barcelone.
Étant donné que nous avons tant de services, nous avons nos propres systèmes de paiement, nos propres cartes de crédit et de nombreux programmes de récompenses, nous sommes constamment soumis à des attaques de cybercriminels. Et naturellement, nous avons toujours une demande de l'entreprise pour des systèmes de protection contre la fraude.
Lorsqu'une entreprise nous demande de créer un système de protection contre la fraude, nous sommes toujours confrontés à un dilemme. D'une part, il est demandé qu'il y ait un taux de conversion élevé, afin que l'utilisateur puisse s'authentifier facilement auprès des services et effectuer des achats. Et de notre côté, de la part des agents de sécurité, je veux moins de plaintes, moins de comptes piratés. Et pour notre part, nous voulons faire monter le prix de l'attaque.
Si vous allez acheter un système de prévention de la fraude ou essayer de le faire vous-même, vous devez d'abord évaluer les coûts.

À notre avis, avons-nous besoin de la prévention de la fraude? Nous nous sommes appuyés sur le fait que nous subissons certains types de pertes financières liées à la fraude. Ce sont des pertes directes - l'argent que vous rendrez à vos clients s'ils ont été volés par des intrus. Il s'agit du coût d'un service de support technique qui communiquera avec les utilisateurs et résoudra les conflits. Il s'agit d'un retour de marchandises qui sont souvent livrées à de fausses adresses. Et il y a des coûts directs de développement du système. Si vous avez fait un système de protection contre la fraude, que vous l'avez déployé sur certains serveurs, vous paierez l'infrastructure, le développement logiciel. Et il y a un troisième aspect très important des dommages causés par les attaquants - la perte de profits. Il se compose de plusieurs composants.
Selon nos calculs, il existe un paramètre très important - la valeur à vie, LTV, c'est-à-dire que l'argent que l'utilisateur dépense dans nos services est considérablement réduit. Parce que dans la moitié des cas de fraude, les utilisateurs quittent simplement votre service et ne reviennent pas.
Nous payons également de l'argent pour la publicité, et si l'utilisateur part, il est perdu. Il s'agit du coût d'acquisition client, CAC. Et si nous avons beaucoup d'utilisateurs automatisés qui ne sont pas de vraies personnes - nous avons de faux utilisateurs actifs mensuels, des chiffres MAU, qui affectent également l'entreprise.
Regardons de l'autre côté, des attaquants.
Certains orateurs ont déclaré que les attaquants utilisent activement des réseaux de zombies. Mais quelle que soit la méthode qu'ils utilisent, ils doivent toujours investir de l'argent, payer pour l'attaque, ils dépensent également de l'argent. Notre tâche, lorsque nous créons un système de prévention de la fraude, est de trouver un tel équilibre que l'attaquant dépense trop d'argent et nous dépensons moins. Cela rend une attaque contre nous non rentable, et les attaquants s'en vont simplement pour casser un autre service.

Pour nos services de dommages, nous avons divisé les attaques en quatre types. Ceci est ciblé lorsque vous essayez de pirater un compte, un compte. Attaques d'un utilisateur ou d'un petit groupe de personnes. Ou des attaques plus dangereuses pour nous, massives et non ciblées, lorsque les attaquants attaquent de nombreux comptes, cartes de crédit, numéros de téléphone, etc.

Je vais vous dire ce qui se passe, comment ils nous attaquent. Le principal type d'attaque le plus évident que tout le monde connaît est le craquage de mot de passe. Dans notre cas, les attaquants tentent de trier les numéros de téléphone, de valider les numéros de carte de crédit. Une certaine variété est présente.
L'enregistrement en masse des comptes, pour nous c'est évidemment néfaste. Je donnerai un exemple plus tard.
Qu'est-ce qui est enregistré? Les faux comptes, certains produits inexistants, tentent de spam dans les messages de rétroaction. Je pense que cela est pertinent et similaire pour de nombreuses sociétés commerciales.
Il y a encore des problèmes qui ne sont pas évidents pour le commerce électronique, mais qui sont évidents pour Yandex - attaques sur le budget publicitaire, fraude aux clics. Eh bien, ou tout simplement le vol de données personnelles.

Je vais vous donner un exemple. Nous avons eu une attaque plutôt intéressante contre un service qui vend des livres électroniques, il y avait une opportunité pour n'importe quel utilisateur de s'inscrire et de commencer à vendre leur travail électronique, une telle opportunité pour soutenir les écrivains novices.
L'attaquant a enregistré un compte principal légal et plusieurs milliers de faux comptes de sbires. Et il a généré un faux livre, juste à partir de phrases aléatoires, cela n'avait aucun sens. Il l'a mis sur le marché, et nous avions une société de marketing, chaque serviteur avait, conditionnellement, 1 dollar, qu'il pouvait dépenser pour un livre. Et ce faux livre a coûté 1 $.
Un raid de sbires a été organisé - de faux comptes. Ils ont tous acheté ce livre, le livre a bondi dans les cotes, est devenu un best-seller, un attaquant a augmenté le prix à 10 $ conditionnel. Et depuis que le livre est devenu un best-seller, les gens ordinaires ont commencé à l'acheter, et des plaintes sont tombées sur nous que nous vendions des produits de mauvaise qualité, un livre avec un ensemble de mots dénués de sens à l'intérieur. L'attaquant a reçu un profit.
Il n'y a pas de neuvième point, il a ensuite été arrêté par la police. Le profit n'est donc pas allé pour l'avenir.
Le principal objectif de tous les attaquants dans notre cas est de dépenser le moins d'argent possible et de prendre le plus possible le nôtre.

Il y a des attaquants, une personne qui essaie simplement de contourner la logique commerciale. Mais je note que nous ne considérons pas ces attaques comme une priorité, car en termes de rapport entre le nombre de comptes piratés et l'argent volé, elles comportent un faible risque pour nous. Mais le principal problème pour nous, ce sont les botnets.

Ce sont des systèmes distribués massifs, ils attaquent nos services de partout sur la planète, de différents continents, mais ils ont certaines fonctionnalités qui facilitent leur traitement. Comme dans tout grand système distribué, les nœuds de botnet effectuent plus ou moins les mêmes tâches.
Une autre chose importante - maintenant, comme de nombreux collègues l'ont noté, les botnets sont distribués sur toutes sortes d'appareils intelligents, routeurs domestiques, haut-parleurs intelligents, etc. Mais ces appareils ont des spécifications matérielles faibles et ne peuvent pas exécuter de scripts complexes.
D'un autre côté, pour un attaquant, louer un botnet pour de simples DDoS est assez bon marché, et il faut également rechercher des mots de passe pour les comptes. Mais si vous devez implémenter une sorte de logique métier spécifiquement pour votre application ou service, le développement et la prise en charge d'un botnet deviennent très coûteux. Habituellement, un attaquant loue simplement une partie d'un botnet fini.
J'associe toujours une attaque par botnet au défilé de Pikachu à Yokohama. Nous avons 95% du trafic malveillant provenant des botnets.
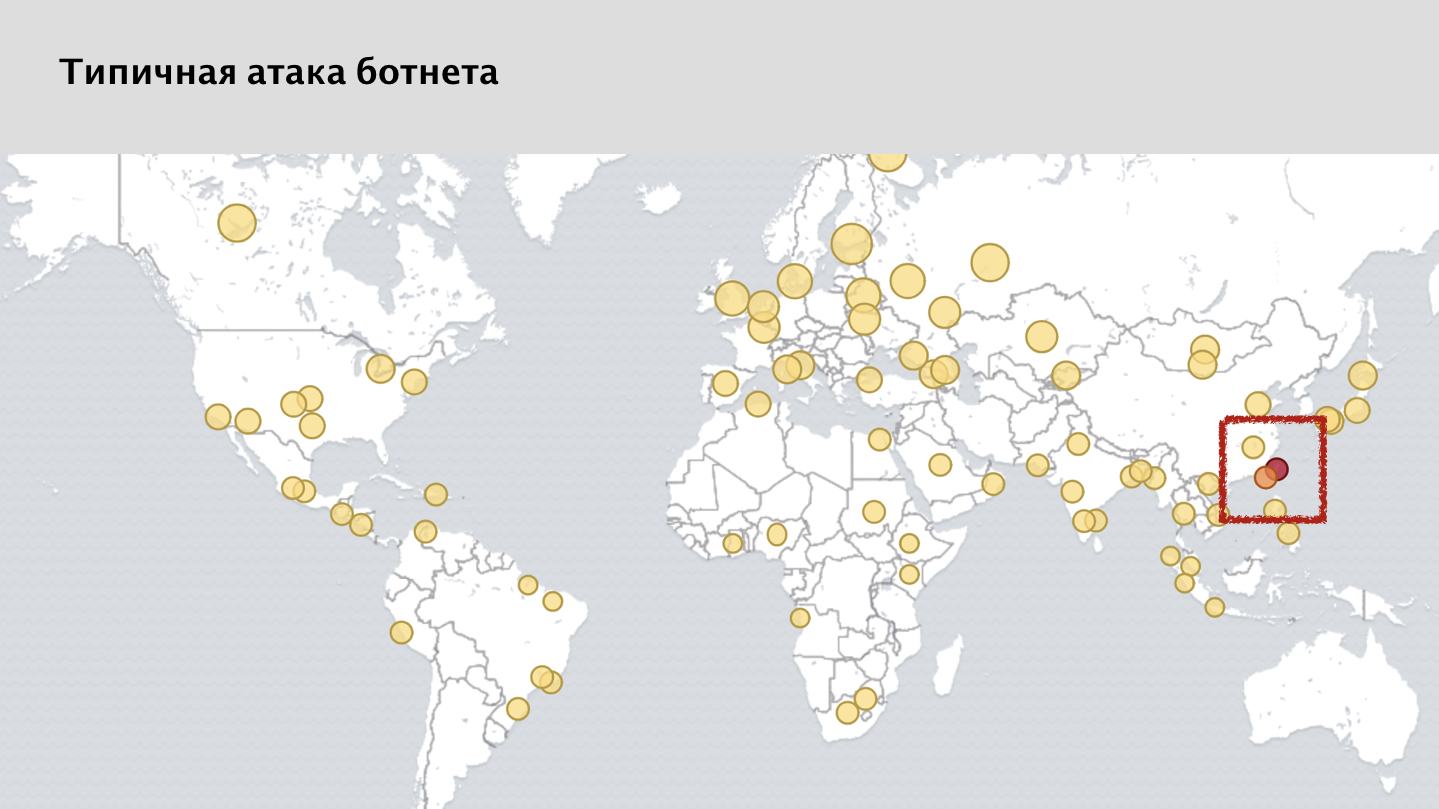
Si vous regardez la capture d'écran de notre système de surveillance, vous verrez de nombreux points jaunes - ce sont des demandes bloquées de différents nœuds. Et ici, une personne attentive peut remarquer que j'ai en quelque sorte dit que l'attaque est uniformément répartie dans le monde. Mais il y a une anomalie claire sur la carte, une tache rouge dans la région de Taiwan. Ceci est un cas assez curieux.
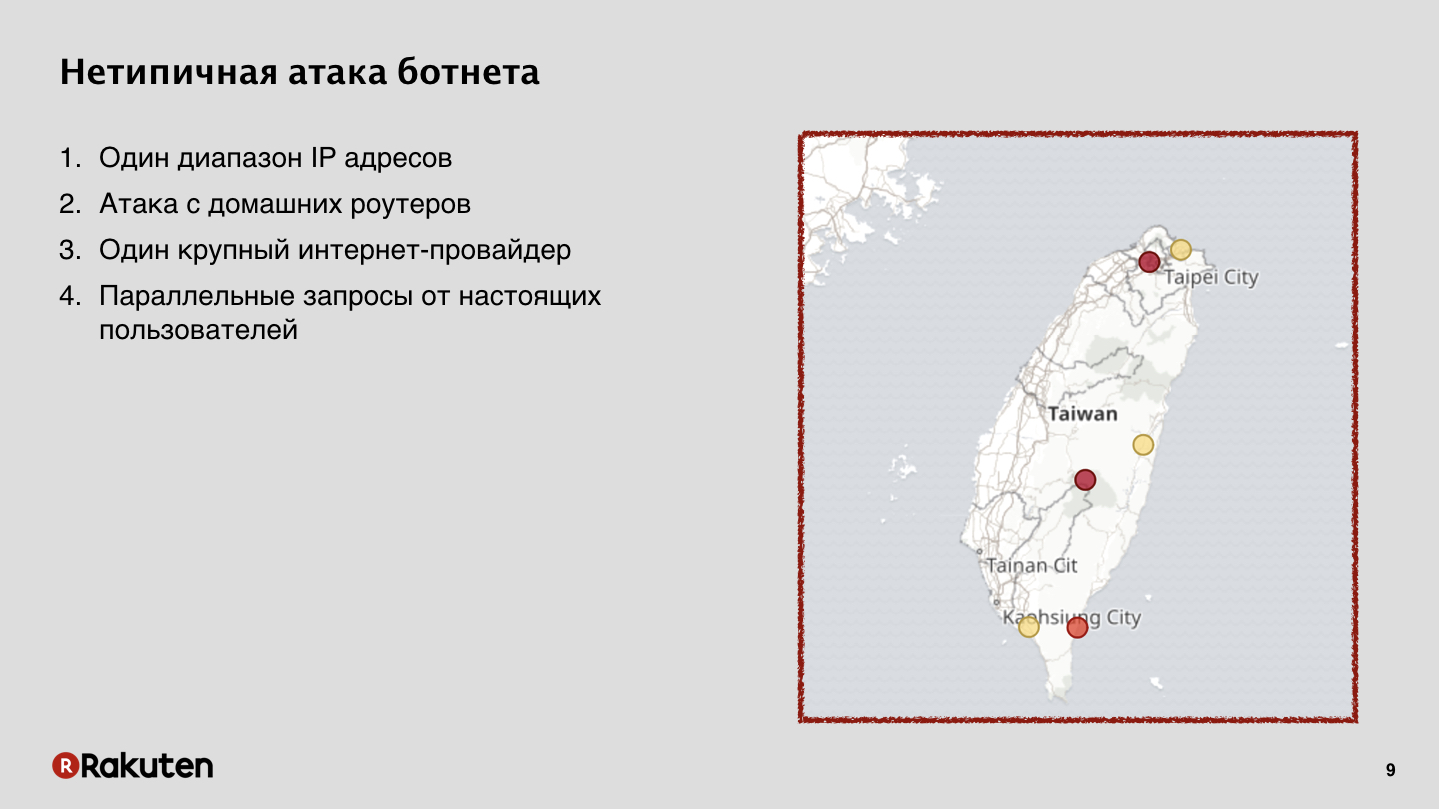
Cette attaque est venue de routeurs à domicile. À Taïwan, un important fournisseur de services Internet a été piraté, ce qui a fourni Internet à la plupart des habitants de l'île. Et pour nous, c'était un très gros problème, lié au fait que de nombreux utilisateurs légaux en même temps que l'attaque se sont rendus et ont travaillé avec nos services à partir des mêmes adresses IP. Nous avons réussi à arrêter cette attaque, mais c'était très difficile.
Si nous parlons de portée, de surface, de ce que nous protégeons. Si vous avez un petit site e-commerce ou un petit service régional, vous n'avez pas de problèmes particuliers. Vous avez un serveur, peut-être plusieurs, ou des machines virtuelles dans le cloud. Eh bien, les utilisateurs, mauvais, bons, qui viennent à vous. Il n'y a pas de problème particulier à protéger.
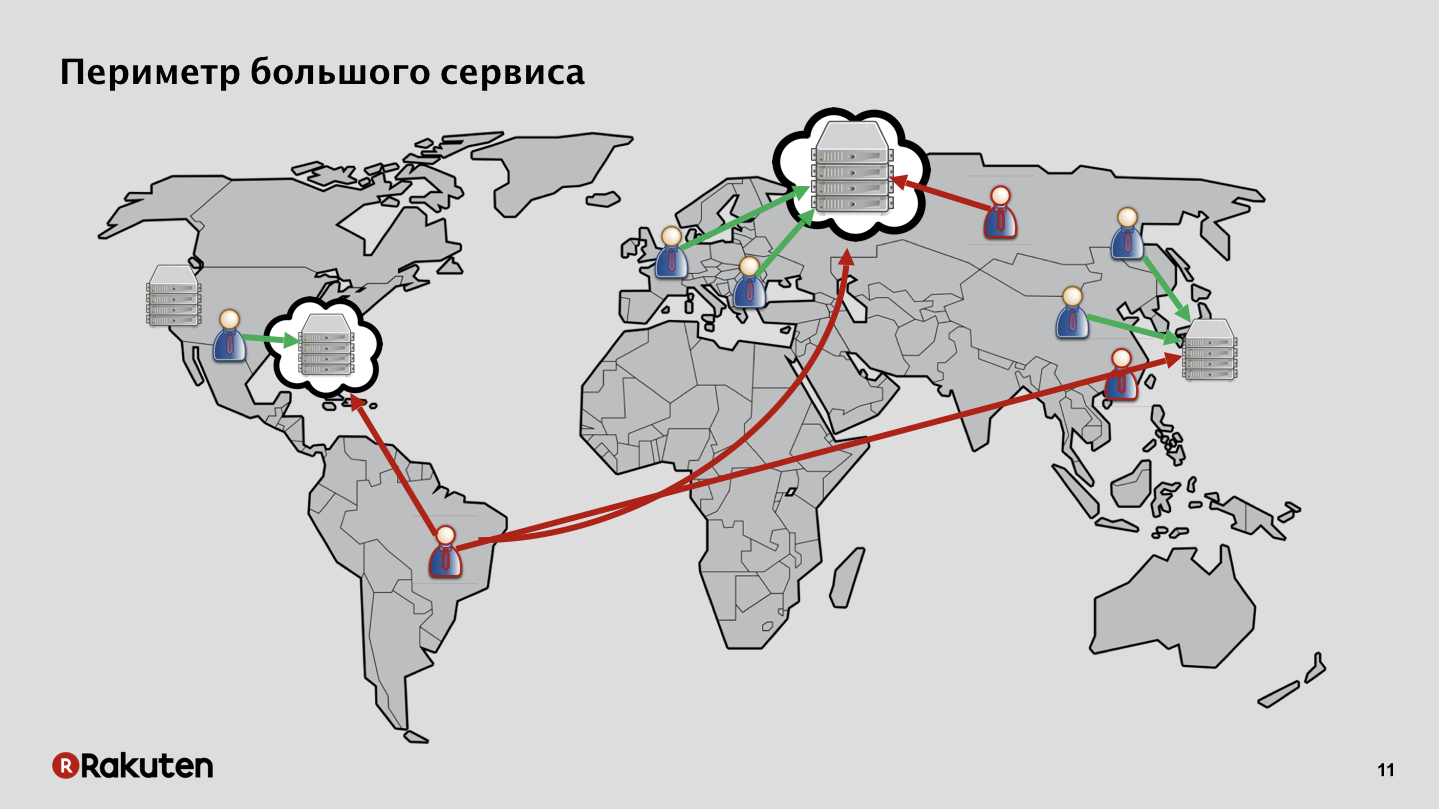
Dans notre cas, tout est plus compliqué, la surface d'attaque est immense. Nous avons des services déployés dans nos propres centres de données, en Europe, en Asie du Sud-Est, aux États-Unis. Nous avons également des utilisateurs sur différents continents, bons ou mauvais. De plus, certains services sont déployés dans l'infrastructure cloud, et pas la nôtre.
Avec autant de services et une infrastructure aussi étendue, c'est très difficile à défendre. De plus, bon nombre de nos services prennent en charge divers types d'applications et d'interfaces client. Par exemple, nous avons un service Rakuten TV qui fonctionne sur les téléviseurs intelligents, et la protection est tout à fait spéciale pour lui.

Pour résumer le problème, un grand nombre d'utilisateurs circulent dans votre système, comme les gens d'un magasin à l'intersection de Shibuya. Et parmi ce grand nombre de personnes, il est nécessaire d'identifier et d'attraper les assaillants. En même temps, il y a beaucoup de portes dans votre magasin et il y a encore plus de monde.
Alors, à partir de quoi et comment avons-nous assemblé notre système?
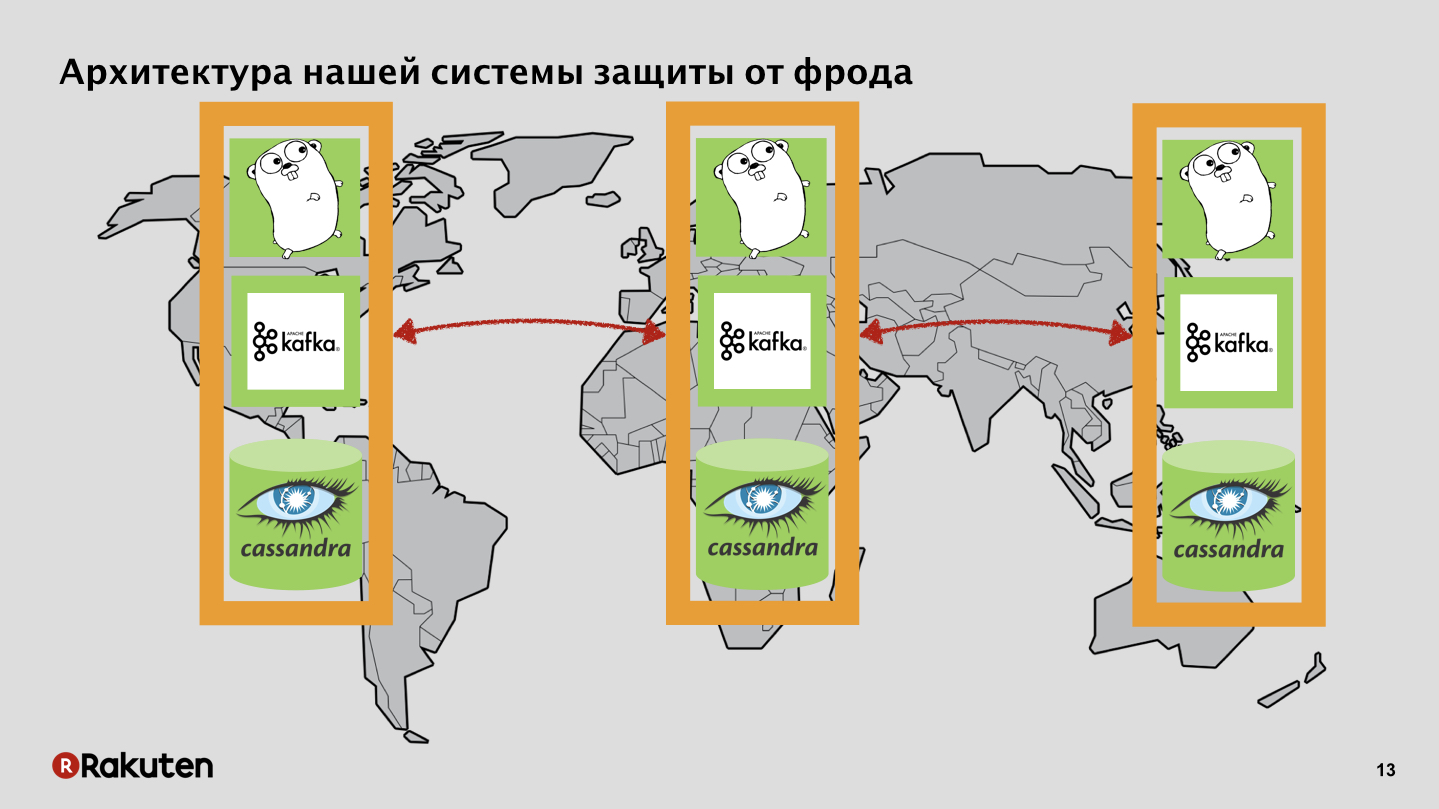
Nous avons réussi à utiliser uniquement des composants open source, c'était assez bon marché. Utilisé le pouvoir de nombreux "gophers". Une partie importante du logiciel a été écrite dans la langue Golang. Files d'attente et bases de données de messages utilisées. Pourquoi en avions-nous besoin? Nous avions deux objectifs: collecter des données sur le comportement des utilisateurs et calculer la réputation, prendre certaines mesures pour reconnaître si un utilisateur est bon ou mauvais.
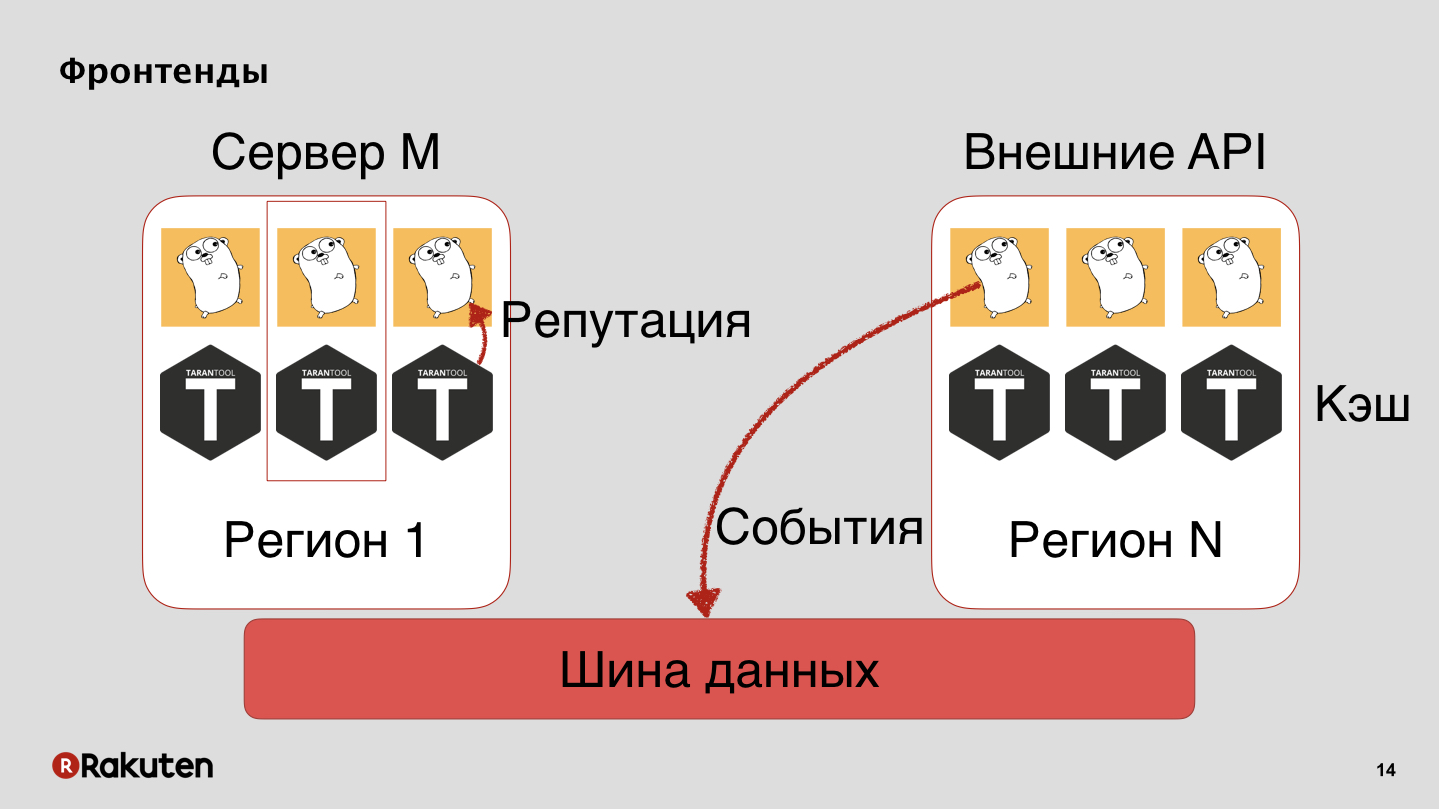
Nous avons plusieurs niveaux dans le système, nous utilisons les frontends écrits dans Golang et Tarantool comme base de mise en cache. Notre système est déployé dans toutes les régions où nos entreprises sont implantées. Nous transmettons des événements via le bus de données et nous en tirons une réputation.
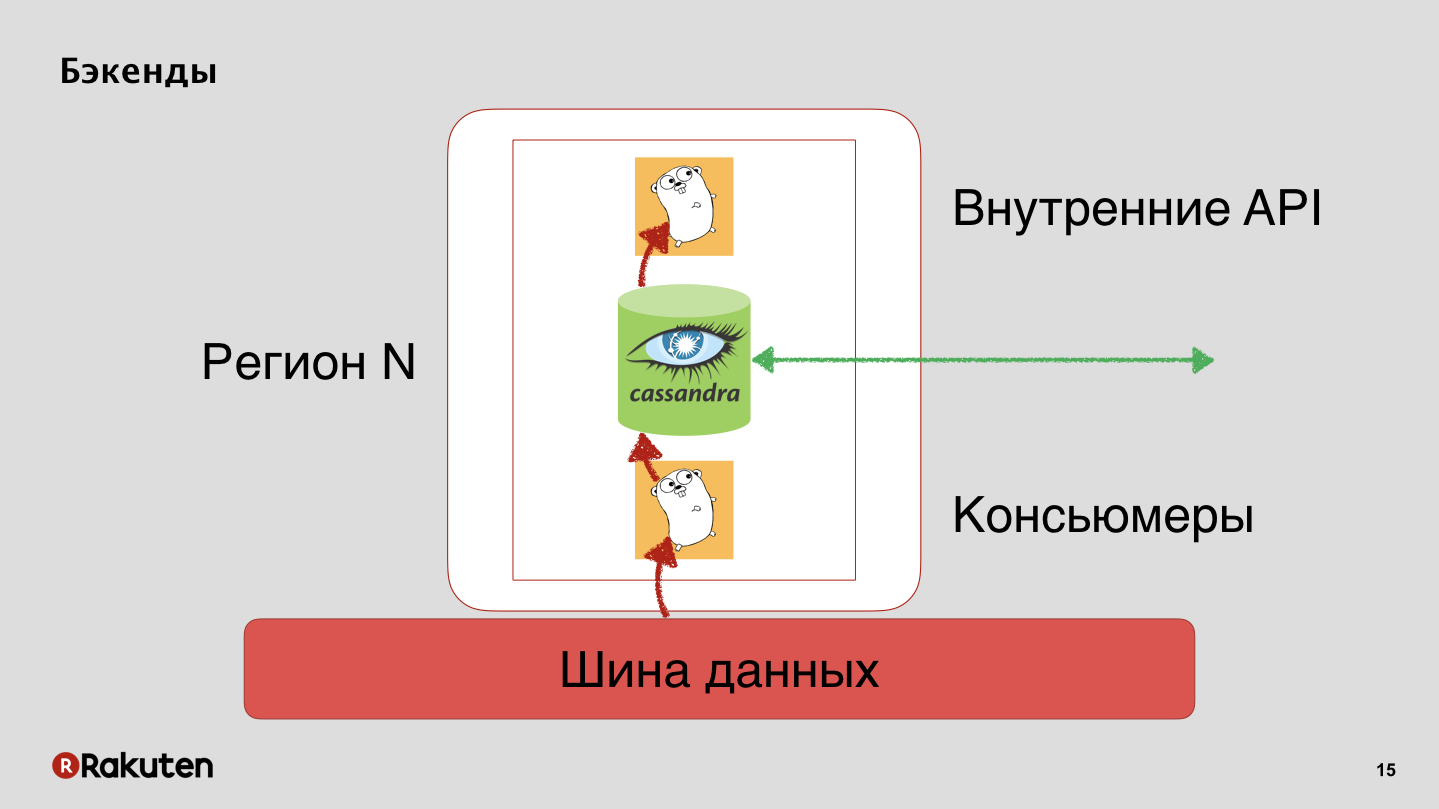
Nous avons des backends qui reproduisent également le statut de réputation des utilisateurs avec Cassandra.
Bus de données, rien de secret, Apache Kafka.
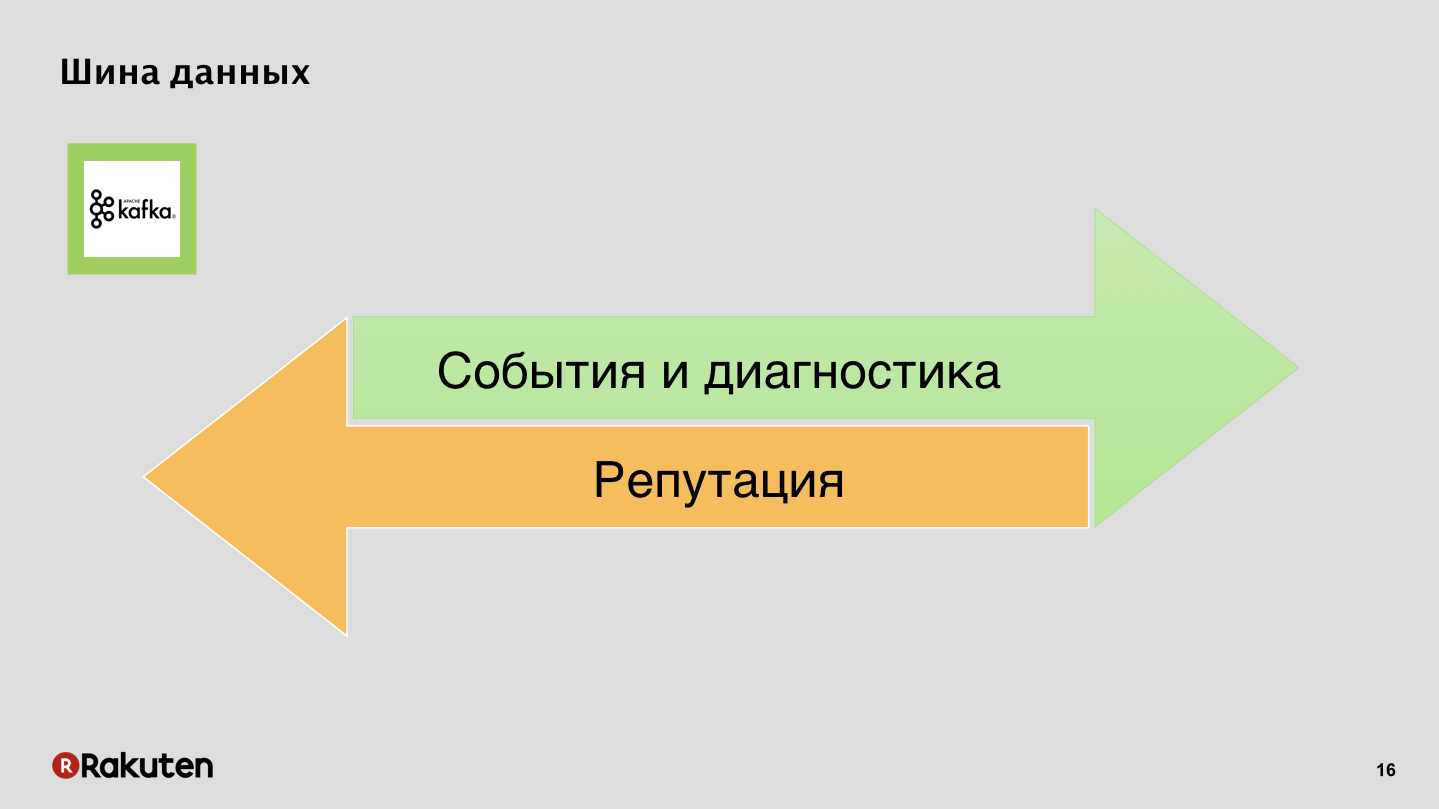
Événements et journaux dans un sens, réputation dans l'autre.
Et naturellement, le système a un cerveau qui pense que l'utilisateur est mauvais ou bon, l'activité est mauvaise ou bonne. Le cerveau est construit sur Apache Storm, et la partie amusante est ce qui se passe à l'intérieur.
Mais d'abord, je vais vous expliquer comment nous collectons des données et comment bloquer les intrus.
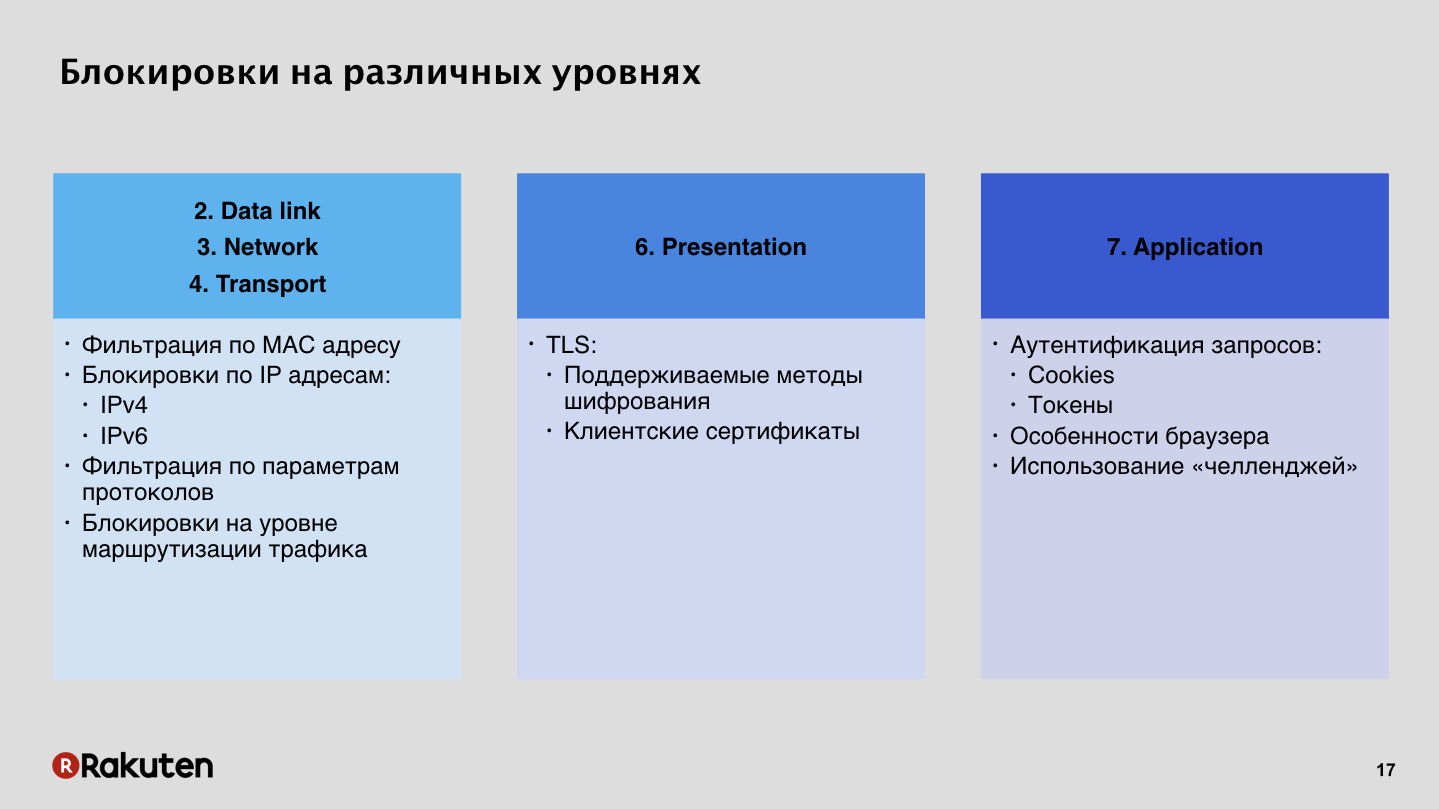
Il existe de nombreuses approches. Certains d'entre eux ont déjà été mentionnés par des collègues de Yandex dans leur premier rapport. Comment bloquer les intrus? Anton Karpov a dit que les pare-feu sont mauvais, nous ne les aimons pas. En effet, il est possible de bloquer par des adresses IP, le sujet pour la Russie est très pertinent, mais cette méthode ne nous convient pas du tout. Nous préférons utiliser des verrous de niveau supérieur, au septième niveau, au niveau de l'application, en utilisant l'authentification des demandes à l'aide de jetons, de cookies de session.
Pourquoi? Regardons d'abord les verrous bas.
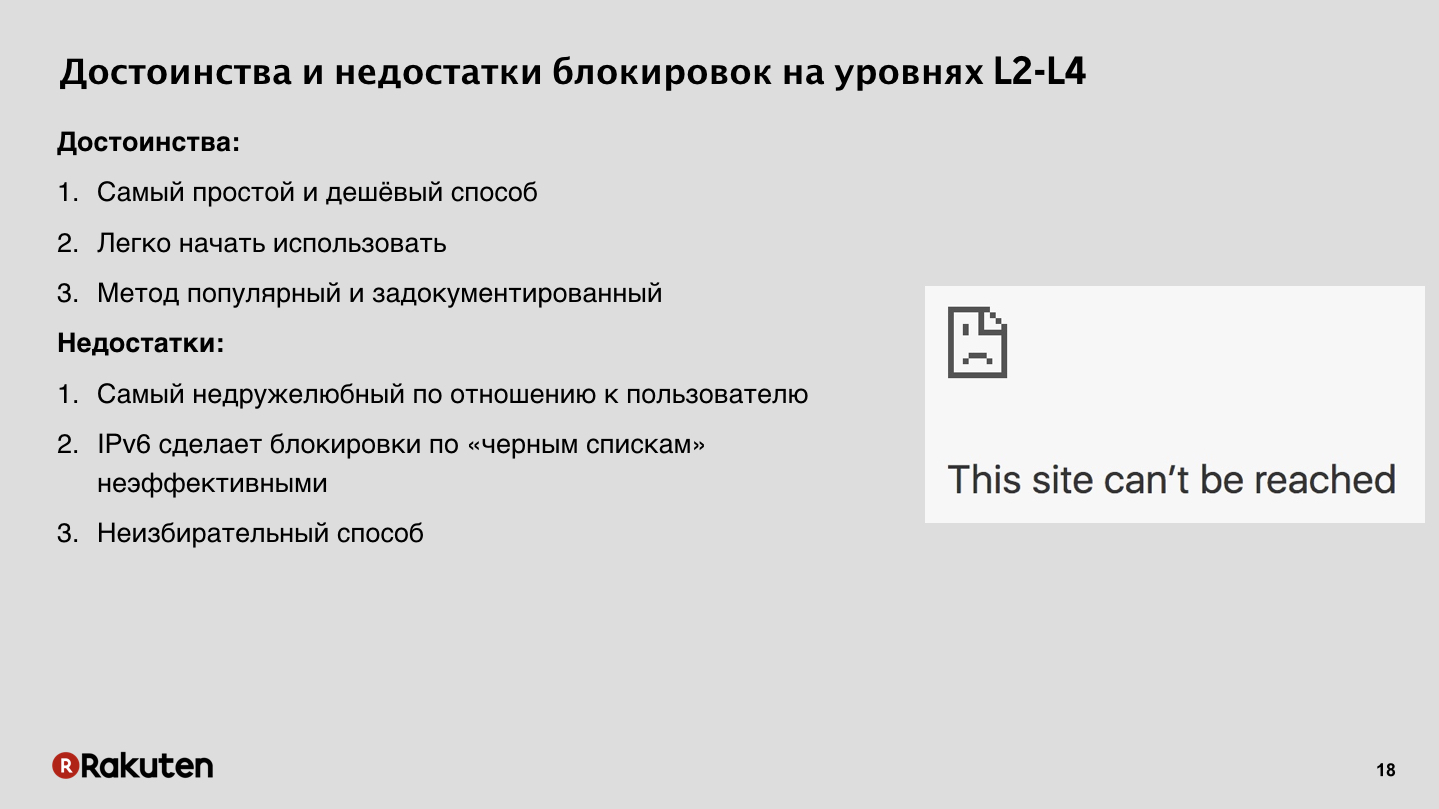
C'est un moyen peu coûteux, tout le monde sait comment l'utiliser, tout le monde a des pare-feu sur les serveurs. Un tas d'instructions sur Internet, il n'y a aucun problème à bloquer l'utilisateur par IP. Mais lorsque vous bloquez l'utilisateur à un niveau bas, il n'a aucun moyen de contourner votre système de protection en cas de faux positif. Les navigateurs modernes essaient plus ou moins d'afficher un beau message d'erreur à l'utilisateur, mais une personne ne peut en aucun cas contourner votre système, car un utilisateur ordinaire ne peut pas modifier arbitrairement ses adresses IP. Par conséquent, nous pensons que cette méthode n'est pas très bonne et peu amicale. De plus, IPv6 se déplace autour de la planète, si vous avez des tables bloquées, après un certain temps, il faudra très longtemps pour rechercher des adresses sur ces tables, et il n'y a pas d'avenir pour de tels verrous.

Notre méthode consiste à verrouiller au niveau supérieur. Nous préférons authentifier les demandes, car pour nous c'est l'occasion de s'adapter de manière très flexible à la logique métier de nos applications. Ces méthodes présentent des avantages et des inconvénients. L'inconvénient est le coût de développement élevé, la grande quantité de ressources que vous devez investir dans l'infrastructure, et l'architecture de tels systèmes, avec toute sa simplicité apparente, est toujours compliquée.
Vous avez entendu dans les rapports précédents sur diverses méthodes basées sur la biométrie, la collecte de données. Bien sûr, nous y pensons également, mais ici, il est très facile de violer la vie privée de l'utilisateur en collectant les mauvaises données que l'utilisateur veut vous confier.
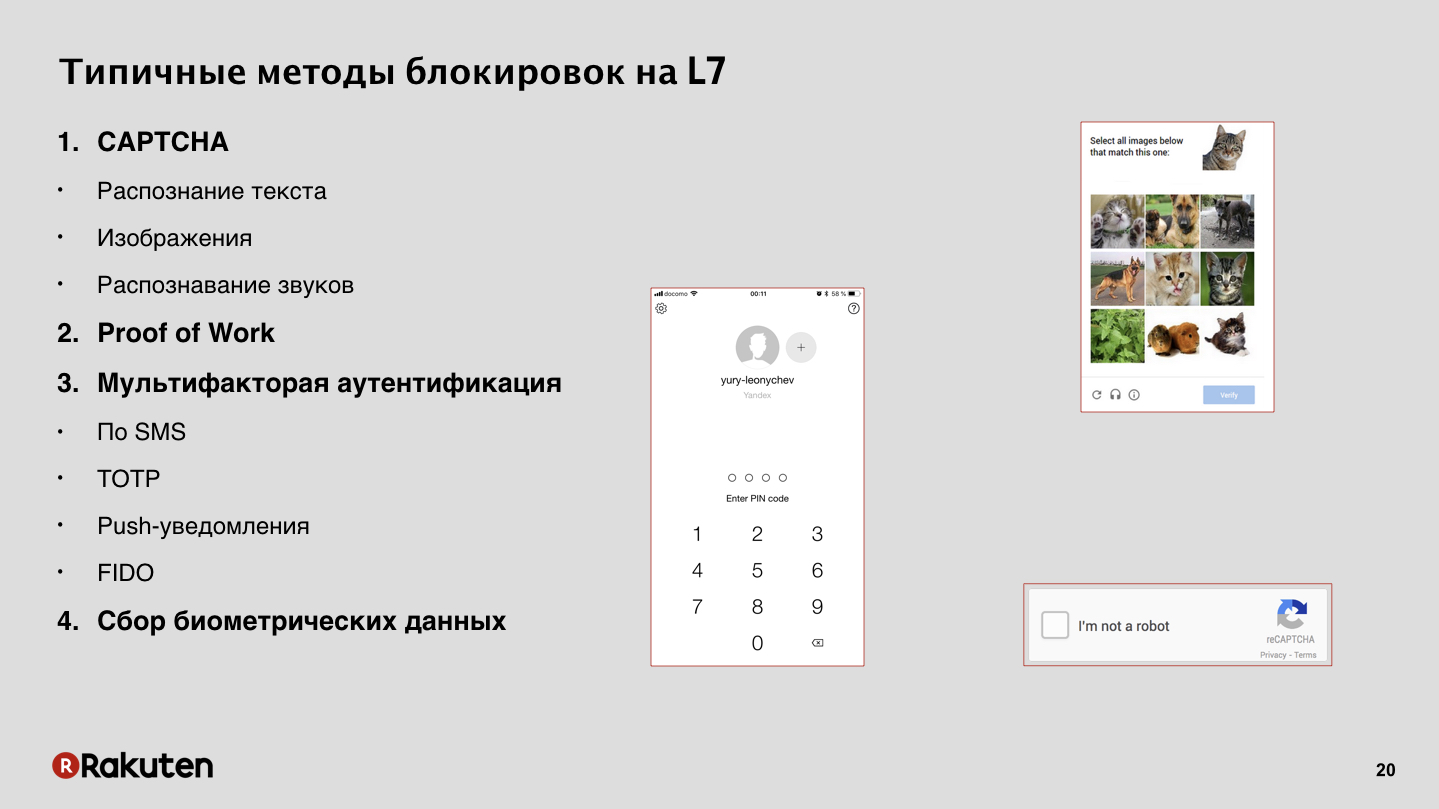
Comment authentifions-nous? Dans notre cas, il n'y a rien d'extraordinaire, mais je veux mentionner une méthode. En plus des types traditionnels - captcha et mots de passe à usage unique - nous utilisons Proof of Work, PoW. Non, nous n'exploitons pas de bitcoins sur les ordinateurs des utilisateurs. Nous utilisons PoW pour ralentir l'attaquant et parfois même bloquer complètement, le forçant à résoudre une tâche très difficile, sur laquelle il passera beaucoup de temps.
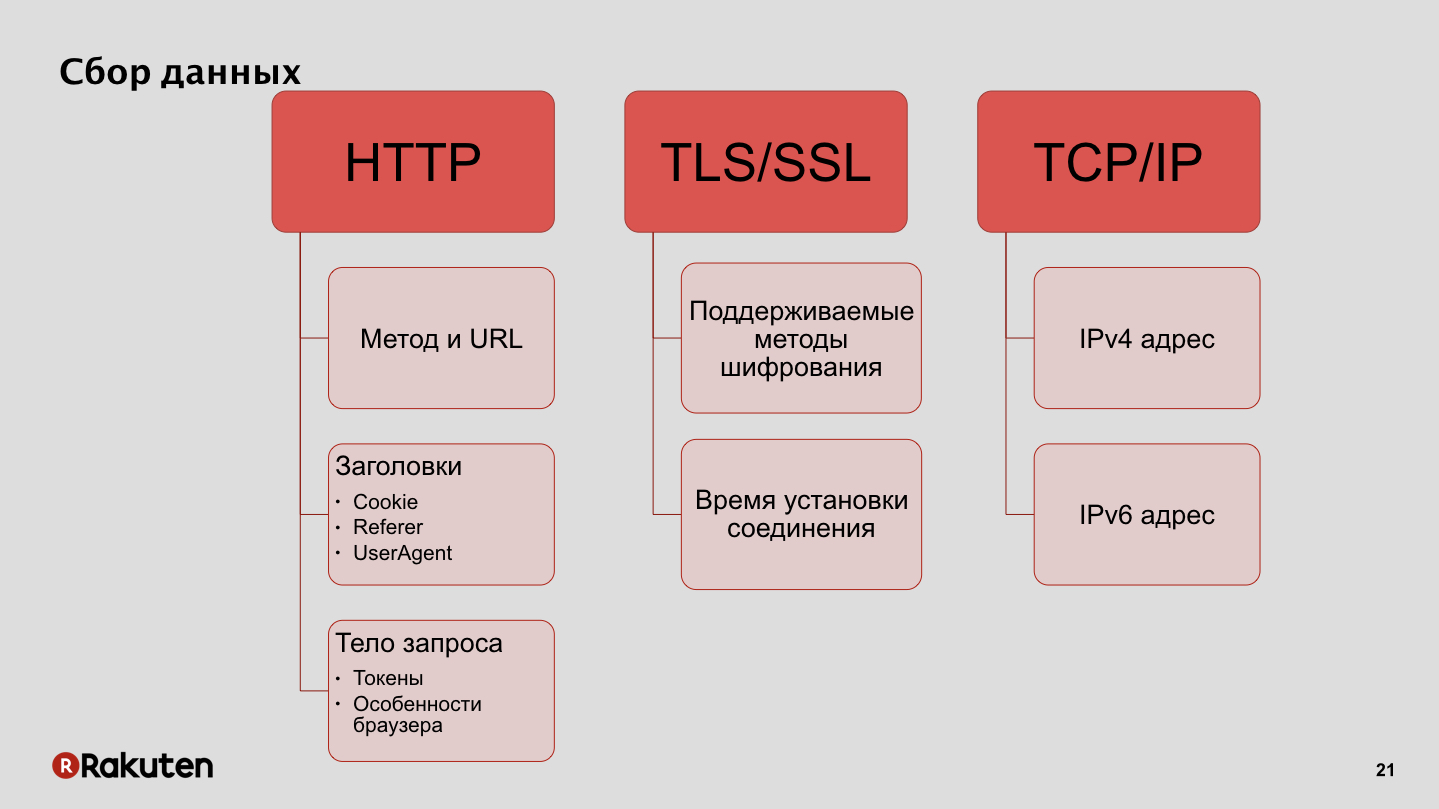
Comment collectons-nous les données? Nous utilisons les adresses IP comme l'une des fonctionnalités, l'une des sources de données pour nous est également les protocoles de cryptage pris en charge par les clients et le temps d'établissement de la connexion. En outre, les données que nous collectons à partir des navigateurs des utilisateurs, les fonctionnalités de ces navigateurs et les jetons que nous utilisons pour authentifier les demandes.
Comment détecter les intrus? Vous vous attendez probablement à ce que je dise que nous avons construit un énorme réseau de neurones et avons immédiatement attrapé tout le monde. Pas vraiment. Nous avons utilisé une approche à plusieurs niveaux. Cela est dû au fait que nous avons de nombreux services, de très gros volumes de trafic, et si vous essayez de mettre un système informatique complexe sur de tels volumes de trafic, il sera très probablement très coûteux et ralentira les services. Par conséquent, nous avons commencé avec une méthode banale simple: nous avons commencé à compter le nombre de demandes provenant de différentes adresses, de différents navigateurs.

Cette méthode est très primitive, mais elle vous permet de filtrer les attaques massives stupides comme les DDoS, lorsque des anomalies prononcées apparaissent dans le trafic. Dans ce cas, vous êtes absolument sûr qu'il s'agit d'un attaquant et vous pouvez le bloquer. Mais cette méthode ne convient qu'au niveau initial, car elle empêche uniquement les attaques les plus brutales.
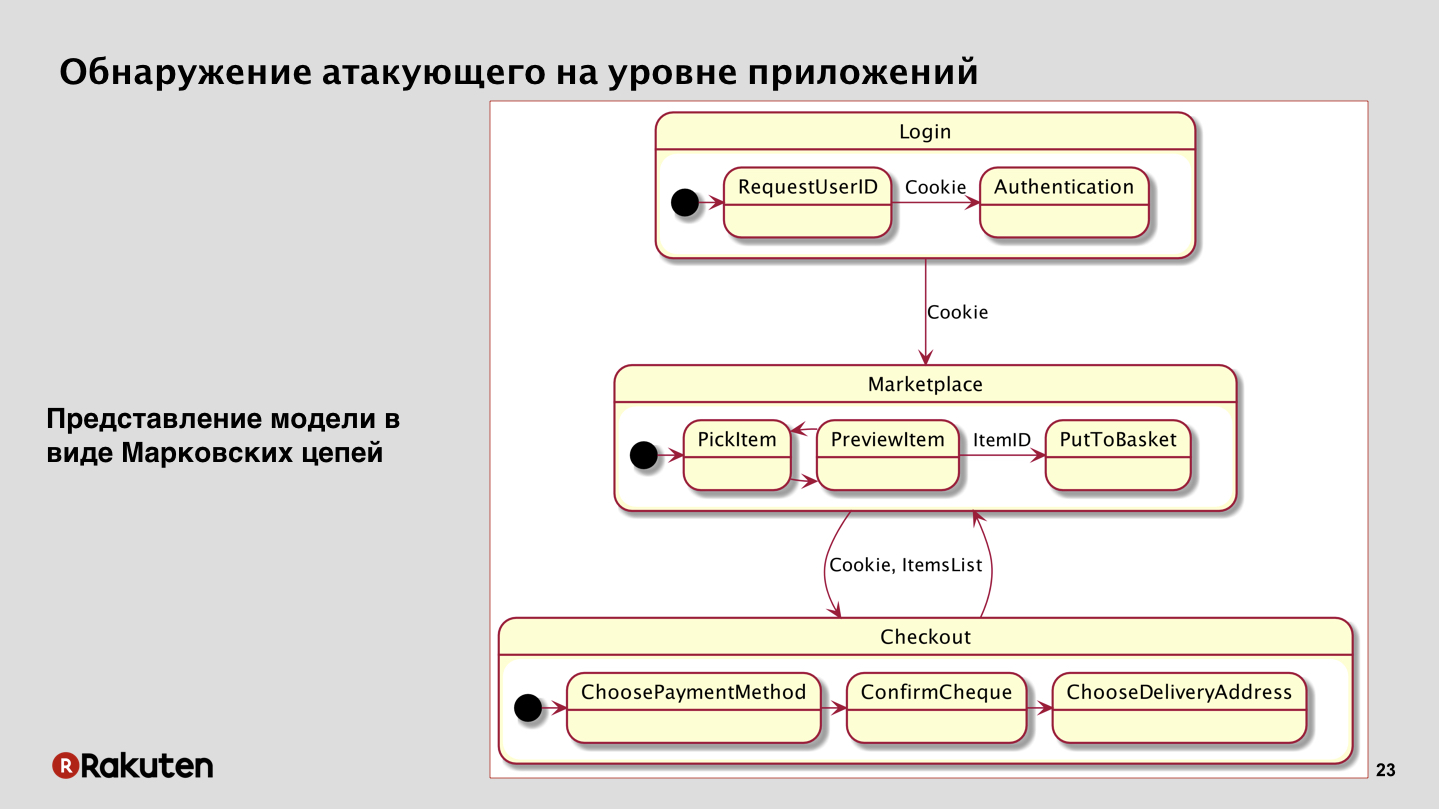
Après cela, nous sommes arrivés à la méthode suivante. Nous avons décidé de nous concentrer sur le fait que nous avons une logique métier d'applications et qu'un attaquant ne peut jamais simplement venir à votre service et voler de l'argent. S'il ne l'a pas craqué, bien sûr. Dans notre cas, si vous regardez le schéma le plus simplifié d'un marché abstrait, nous verrons que l'utilisateur doit d'abord se connecter, présenter ses informations d'identification, recevoir des cookies de session, puis aller sur le marché, y chercher des marchandises, les mettre dans le panier. Après cela, il continue à payer pour l'achat, sélectionne l'adresse, le mode de paiement, et à la fin il clique sur «payer», et finalement l'achat de marchandises a lieu.
Vous voyez, un attaquant doit prendre de nombreuses mesures. Et ces transitions entre États, entre services ressemblent à un modèle mathématique - ce sont des chaînes de Markov, qui peuvent également être utilisées ici. En principe, dans notre cas, ils ont montré de très bons résultats.

Je peux donner un exemple simplifié. En gros, il y a un moment où un utilisateur s'authentifie, quand il choisit des achats et effectue un paiement, et par exemple, il est évident comment un attaquant peut se comporter anormalement, il peut essayer de se connecter plusieurs fois avec différents comptes. Ou il peut ajouter les mauvais produits au panier que les utilisateurs ordinaires achètent. Ou effectue un nombre anormalement élevé d'actions.
Les chaînes de Markov considèrent généralement les États. Nous avons également décidé d'ajouter du temps à ces états pour nous-mêmes. Les attaquants et les utilisateurs normaux se comportent très différemment dans le temps, ce qui permet également de les séparer.
Les chaînes de Markov sont un modèle mathématique assez simple, elles sont très faciles à compter à la volée, elles vous permettent donc d'ajouter un autre niveau de protection, d'éliminer une autre partie du trafic.
La prochaine étape. Nous avons attrapé les attaquants stupides, pris les attaquants mentaux méchants. Il ne reste plus que les plus intelligents. Pour les attaquants difficiles, des fonctionnalités supplémentaires sont nécessaires. Que pouvons-nous faire?
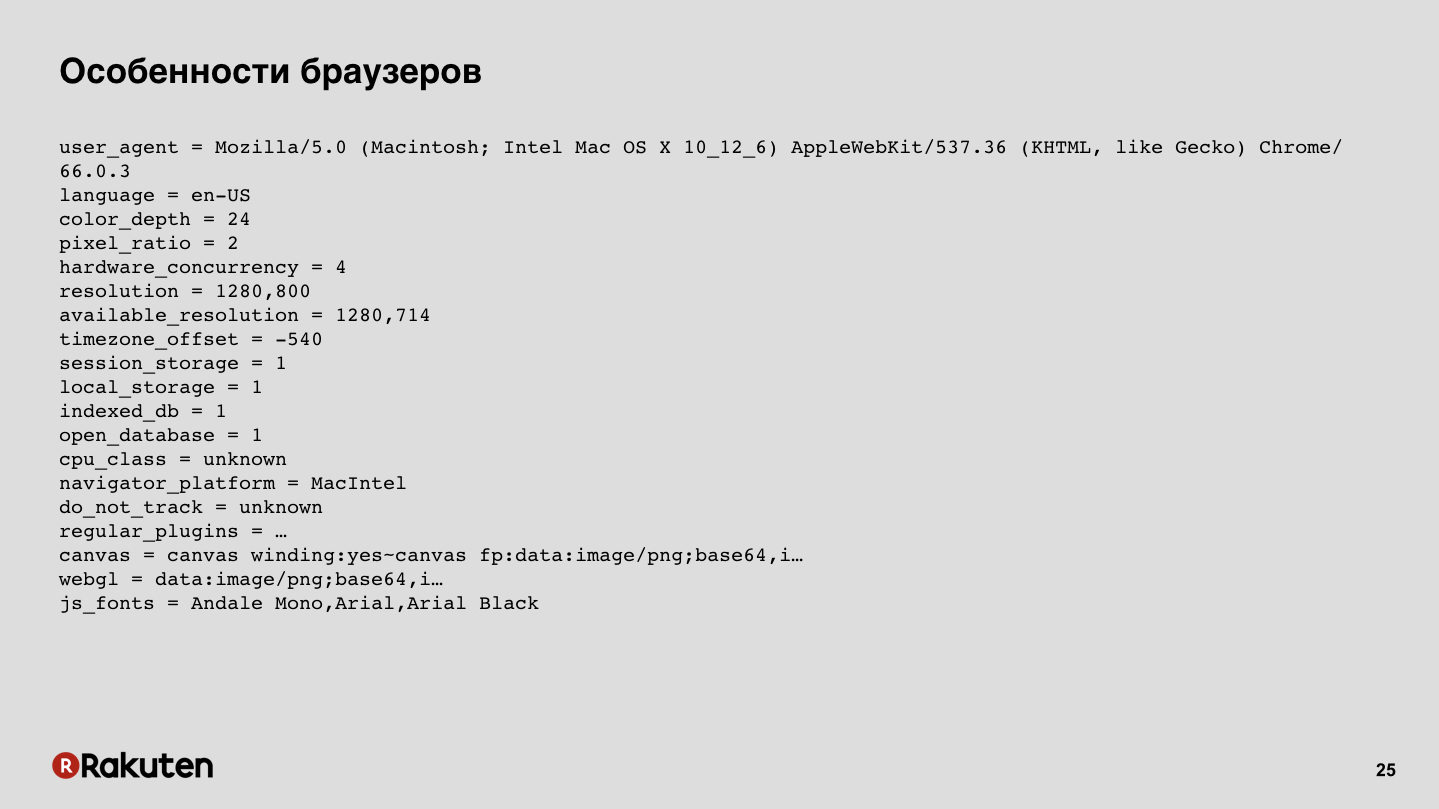
Nous pouvons collecter des empreintes digitales sur les navigateurs. Maintenant, les navigateurs sont des systèmes assez complexes, ils ont de nombreuses fonctionnalités prises en charge, ils exécutent JS, ils ont diverses capacités de bas niveau, et tout cela peut être collecté, toutes ces données. Sur la diapositive est un exemple de la sortie d'une des bibliothèques open source.
De plus, vous pouvez collecter des données sur la façon dont l'utilisateur interagit avec votre service, comment il déplace la souris, comment il touche un appareil mobile, comment il fait défiler l'écran. De telles choses sont collectées, par exemple, par Yandex.Metrica. , , .
, . ? , , , , . , . machine learning, decision tree, . Decision tree if-else, , . , . - , - — , , .
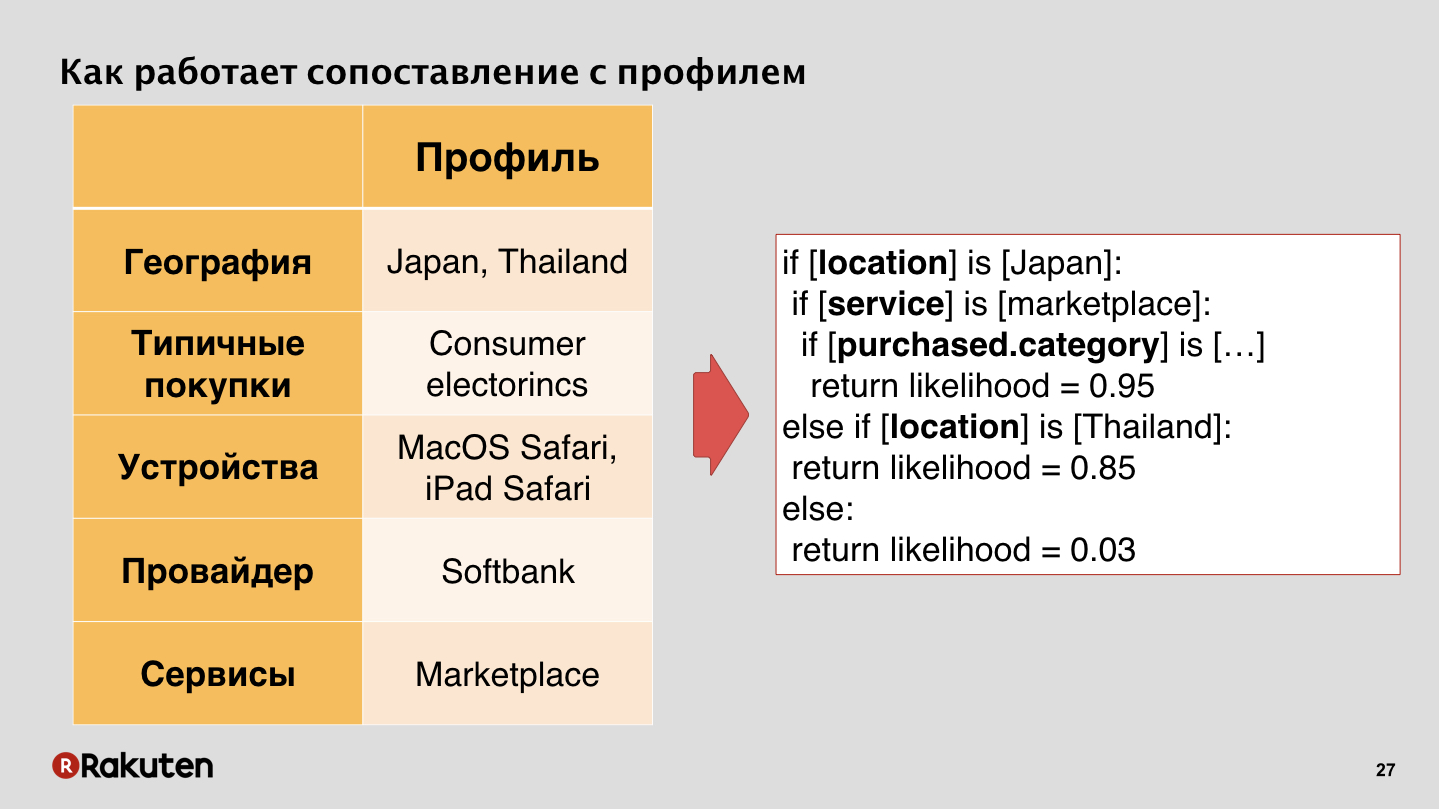
, , , - , , , Softbank, . , , . - , , , .
, , iTunes — , - , .
, , , .

. , ? , . , , , . , .
. , . . : . , .