 Montezuma's Revenge Atari Game Levels
Montezuma's Revenge Atari Game LevelsDeepMind a
démontré le processus d'apprentissage de l'IA (sa forme faible) pour passer des jeux sur Atari. La formation a été réalisée en faisant la démonstration du système de réussite des jeux vidéo sur YouTube. Cette méthode est utilisée par de nombreux joueurs humains qui, pour une raison ou une autre, n'ont pas pu passer à travers une sorte de jeu.
Habituellement, pour résoudre ce problème, il est nécessaire d'utiliser la méthode d'
apprentissage dite de
renforcement . Cette technique est assez populaire, car elle vous permet de former des robots pour effectuer diverses tâches spécifiques. Dès que le système obtient un résultat, il reçoit une petite récompense.
Les développeurs créent des algorithmes et des modèles capables d'évaluer l'environnement de jeu, y compris les récompenses possibles pour avoir terminé (points, bonus, etc.). Ces systèmes apprennent le jeu étape par étape, passant progressivement à la finale.
La nouvelle méthode développée dans DeepMind est différente de toutes les autres. Les spécialistes de la société ont pu entraîner l'IA à jouer à des jeux sous Atari tels que Montezuma's Revenge, Pitfall et Private Eye. Dans le même temps, l'accent n'a pas été mis sur les points et les prix - la formation a suivi des didacticiels sur YouTube. Et cela nous a permis d'obtenir des résultats inhabituels pour l'IA.
Le fait est que des jeux comme le même Montezuma's Revenge sont difficiles à «comprendre» pour les machines. Il n'y a pas de tâche claire, on ne sait pas où aller, quels articles collecter et quoi en faire à l'avenir. La machine est tout simplement perdue, car dans le processus de promotion, elle ne reçoit pas de récompenses et la formation avec des renforts devient ici inutile ou presque inutile.
Dans le jeu en question, vous devez contrôler un personnage nommé Panama Joe. À la fin, il doit se rendre au trésor de l'ancien temple. Selon la légende, ces trésors appartiennent à Montezuma. Vous devez d'abord trouver le premier élément critique pour réussir le jeu - la clé d'or. Pour le détecter, vous devez suivre environ 100 étapes. Mais c'est si vous savez quoi faire. Sinon, il y a un grand nombre de possibilités 100 des
18 actions initiales. C'est trop pour toute IA créée par l'homme. Eh bien, vous n'obtiendrez pas de récompense ici, tout est très, très spécifique.
Une façon de faire savoir à l'ordinateur ce qu'il faut faire est de montrer les scénarios du passage. En fait, non seulement les voitures, mais aussi les gens apprennent à effectuer diverses tâches par des exemples. La danse, les actions de l'artiste, la soudure - tout cela est mieux vu 1 fois, et non 100 fois pour savoir comment le faire.
DeepMind est arrivé à la conclusion que c'est la meilleure façon de montrer à l'ordinateur comment effectuer une tâche avec un résultat implicite. La technologie créée par des experts a vraiment aidé. Deux méthodes ont été utilisées pour enseigner l'exemple: TDC (classification de distance temporelle) et CDC (classification de distance temporelle inter-modale).
Dans le premier cas, les IA sont entraînées à déterminer la distance dans l'environnement de jeu, à remarquer la différence entre deux images différentes. L'IA «comprend» également ce qui doit être fait pour passer d'un endroit à un autre. Pour la formation sur YouTube, les vidéos se voient allouer des paires d'images dans un ordre aléatoire.
Dans le second cas, la «compréhension» de l'accompagnement sonore est également ajoutée. Les sons de presque tous les jeux correspondent aux performances de certaines actions. Par exemple, sauter, récupérer des objets, etc. Ainsi, l'ordinateur est formé pour percevoir les sons comme des éléments de jeu importants. La vidéo + le son permettent à l'ordinateur de se débrouiller assez bien dans le processus de réussite du jeu.
Voici les actions d'une IA entraînée dans Montezuma's Revenge. Le passage des deux autres jeux mentionnés au tout début est
ici .
Certes, il n'a pas été possible d'abandonner complètement le rôle des récompenses - jusqu'à présent, l'IA dépend des mêmes points. Mais la méthode habituelle d'enseignement du système, qui a été utilisée plus tôt, n'a pas permis d'arriver au moins à la clé d'or, pour laquelle les cent premiers points sont donnés. Alors l'IA, comme un chaton aveugle, a poussé dans toutes les directions, ne comprenant pas quoi faire. Certes, le système de «renforcement» est également modifié.
Dans le processus de passage de chaque 16e image vidéo du record de passage du jeu AI, il est comparé aux images de la vidéo passant le jeu par les gens. Si la comparaison montre un degré élevé de similitude, l'IA reçoit une récompense. Au fil du temps, l'IA commence à exécuter la même séquence d'actions qu'une personne, afin d'obtenir un cadre similaire.
De plus, l'IA dans de nombreux cas montre de meilleurs résultats que les joueurs humains ou d'autres algorithmes de passage, y compris Rainbow, ApeX et DQfD.
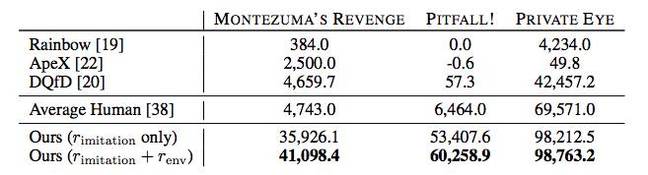
En principe, tout cela est impressionnant, mais jusqu'à présent, les avantages pratiques des réalisations de DeepMind ne sont pas clairs. Est-il possible d'utiliser la méthode d'enseignement de l'IA proposée par l'entreprise ailleurs que de passer de vieux jeux? Mais connaissant les réalisations de DeepMind dans le domaine de l'IA, il ne fait aucun doute que, d'une manière ou d'une autre, tout cela peut être utilisé à des fins pratiques - il est peu probable que des experts commencent à travailler sur la question dans un souci de "plaisir".