Ce blog est généralement dédié à la reconnaissance des plaques d'immatriculation. Mais, en travaillant sur cette tâche, nous sommes arrivés à une solution intéressante qui peut être facilement appliquée à un très large éventail de tâches de vision par ordinateur. Nous allons en parler maintenant: comment créer un système de reconnaissance qui ne vous décevra pas. Et si vous échouez, vous pouvez lui dire où est l'erreur, vous recycler et avoir une solution légèrement plus fiable qu'auparavant. Bienvenue au chat!

Que s'est-il passé?
Imaginez, vous avez fait face à la tâche: trouver la pizza sur la photo et déterminer de quel type de pizza il s'agit.
Passons brièvement en revue le chemin standard que nous avons souvent parcouru. Pourquoi? Pour comprendre comment faire ... pas besoin.
Étape 1: ramasser la base
 Étape 2:
Étape 2: pour la fiabilité de la reconnaissance, on peut noter qu'il y a de la pizza et de l'arrière-plan (nous allons donc inclure un réseau neuronal de segmentation dans la procédure de reconnaissance, mais cela en vaut souvent la peine):
 Étape 3:
Étape 3: nous le mettons sous une «forme normalisée» et classons à l'aide d'un autre réseau de neurones convolutionnels:

Super! Nous avons maintenant une base d'entraînement. En moyenne, la taille de la base d'entraînement peut être de plusieurs milliers d'images.
Nous prenons 2 réseaux de convolution, par exemple, Unet et VGG. Le premier est formé sur les images d'entrée, puis nous normalisons l'image et entraînons le VGG pour la classification. Cela fonctionne très bien, nous le transférons au client et considérons l'argent gagné honnêtement.
Ça ne marche pas comme ça!
Malheureusement, presque jamais. Plusieurs problèmes graves se posent lors de la mise en œuvre:
- Variabilité des données d'entrée. Nous avons étudié sur un exemple, en réalité, tout s'est déroulé différemment. Oui, juste pendant l'opération, quelque chose s'est mal passé.
- Très souvent, la précision de reconnaissance reste insuffisante. Je veux 99,5%, mais ça passe de 60% à 90% par une bonne journée. Mais ils voulaient, en règle générale, automatiser une solution qui fonctionne elle-même, et encore mieux que les gens!
- Ces tâches sont souvent externalisées, ce qui signifie que les contrats sont déjà clôturés, les actes sont signés et le propriétaire de l'entreprise doit décider d'investir dans la révision ou d'abandonner complètement la décision.
- Oui, il commence juste à se dégrader avec le temps, comme dans tout système complexe, si vous n'impliquez pas de spécialistes ayant participé à la création, ou le même niveau de qualification.
En conséquence, pour beaucoup de ceux qui ont touché toutes ces mécaniques avec leurs mains, il devient clair que tout doit se passer d'une manière complètement différente. Quelque chose comme ça:
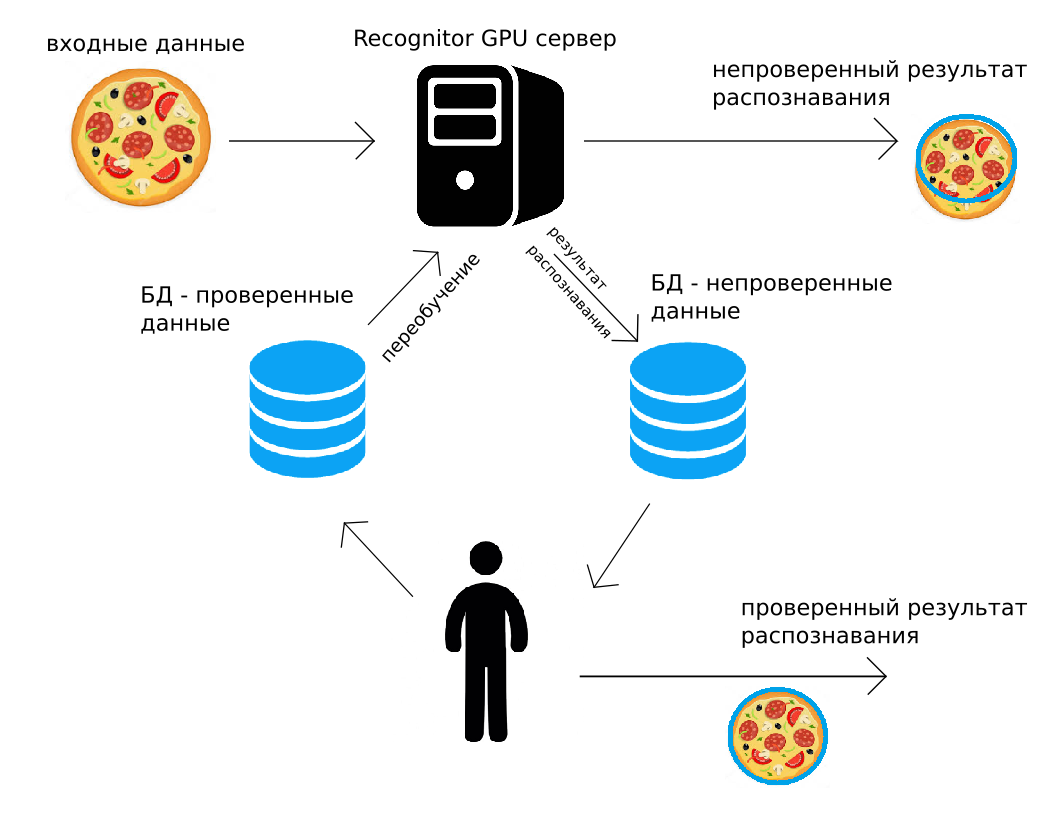
Les données sont envoyées à notre serveur (via http POST, ou en utilisant l'API Python), le serveur GPU les reconnaîtra «comme il le pourrait», retournant immédiatement le résultat. En cours de route, le même résultat de reconnaissance avec l'image est ajouté à l'archive. Une personne contrôle alors toutes les données ou une partie aléatoire de celles-ci, les corrige. Le résultat corrigé est placé dans la deuxième archive. Et puis, quand cela sera pratique (par exemple, la nuit), tous les réseaux de neurones convolutifs utilisés pour la reconnaissance seront recyclés, en utilisant les données corrigées par la personne.
Un tel circuit de reconnaissance, la supervision humaine et la formation continue résolvent bon nombre des problèmes énumérés ci-dessus. De plus, dans les solutions nécessitant une grande précision, une sortie vérifiée par l'homme peut être utilisée. Il semble que cette utilisation de données vérifiées par l'homme soit trop coûteuse, mais nous montrerons en outre qu'elle a presque toujours un sens économique.
Exemple réel
Nous avons mis en œuvre le principe décrit et l'avons appliqué avec succès sur plusieurs tâches réelles. L'un d'eux est la reconnaissance des nombres sur les images des conteneurs dans les terminaux ferroviaires prises à partir d'une tablette. C'est très pratique - pointez la tablette vers le conteneur, obtenez le numéro reconnu et utilisez-le dans le programme de la tablette.
Un exemple d'instantané typique:

Dans l'image, le nombre est presque parfait, seulement beaucoup de bruit visuel. Mais des ombres dures, de la neige, des dispositions de lettrage inattendues, des inclinaisons ou des perspectives graves se produisent lors de la prise de vue.
Et cela ressemble à un ensemble de pages Web sur lesquelles toute la «magie» se produit:
1) Téléchargement du fichier sur le serveur (bien sûr, cela ne peut pas être fait à partir de la page html, mais en utilisant Python ou tout autre langage de programmation):
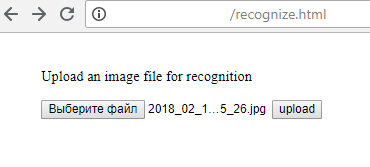
2) Le serveur renvoie le résultat de la reconnaissance:
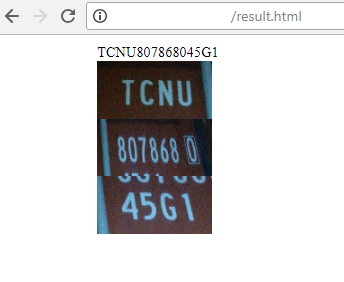
3) Et ceci est une page pour l'opérateur qui surveille le succès de la reconnaissance et, si nécessaire, corrige le résultat. Il y a 2 étapes: la recherche de zones de groupes de symboles, leur reconnaissance. L'opérateur peut corriger tout cela s'il voit une erreur.
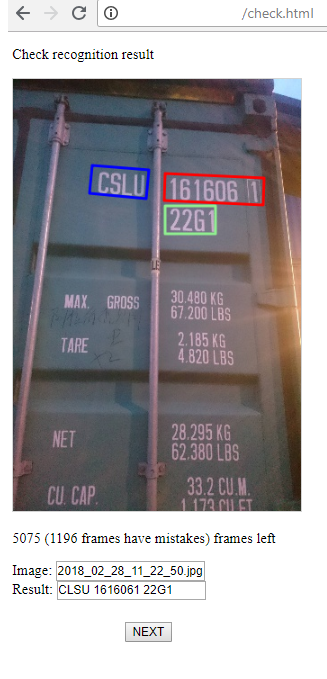
4) Voici une page simple où vous pouvez commencer à vous entraîner pour chacune des étapes de reconnaissance et, en exécutant, voir la perte actuelle.
Minimalisme sévère, mais cela fonctionne très bien!
À quoi cela peut-il ressembler du côté d'une entreprise qui envisage d'utiliser l'approche décrite (ou notre expérience et nos serveurs de reconnaissance)?
- Les réseaux neuronaux de pointe sont sélectionnés. Si tout est basé sur des solutions déboguées existantes, vous pouvez démarrer le serveur et configurer le balisage en une semaine.
- Un flux de données (de préférence sans fin) est organisé sur le serveur, plusieurs centaines de trames sont marquées.
- La formation commence. Si tout «rentre», le résultat est de 60 à 70% de reconnaissance réussie, ce qui aide grandement à poursuivre le marquage.
- Commence alors le travail systématique de présentation de toutes les situations possibles, de vérification des résultats de reconnaissance, d'édition, de recyclage. Au fur et à mesure que vous apprenez, l'intégration du système dans un processus métier devient de plus en plus rentable.
Qui d'autre fait ça?
Le thème de la boucle fermée n'est pas nouveau. De nombreuses entreprises proposent des systèmes de traitement des données d'un type ou d'un autre. Mais le paradigme du travail peut être construit de différentes manières:
- Nvidia Digits sont des modèles assez bons et puissants enveloppés dans une interface graphique intuitive où l'utilisateur doit joindre ses images et JSON. Le principal avantage - une connaissance minimale de la programmation et de l'administration vous offre une bonne solution. Moins - cette solution peut être loin d'être optimale (par exemple, il n'est pas possible de rechercher correctement les numéros de voiture via SSD). Et pour comprendre comment optimiser la solution, l'utilisateur n'a pas suffisamment de connaissances. S'il a suffisamment de connaissances, il n'a pas besoin de CHIFFRES. Le deuxième inconvénient - vous devez avoir votre propre équipement sur lequel tout configurer et déployer.
- Services de balisage tels que Mechanical Turk, Toloka, Supervise.ly. Les deux premiers vous fournissent des outils de balisage, ainsi que des personnes capables de baliser les données. Ce dernier fournit d'excellents outils, mais sans personnes. Grâce aux services, vous pouvez automatiser le travail humain, mais vous devez être un expert dans la définition de la tâche.
- Entreprises ayant déjà suivi une formation et proposant une solution fixe (Microsoft, Google, Amazon). En savoir plus à leur sujet ici (https://habr.com/post/312714/). Leurs décisions ne sont pas flexibles, pas toujours «sous le capot» seront les meilleures décisions nécessaires dans votre cas. En général, presque toujours, cela n'aide pas.
- Les entreprises qui travaillent spécifiquement avec vos données, par exemple ScaleAPI (https://www.scaleapi.com/). Ils ont une excellente API, pour le client, ce sera une boîte noire. Données d'entrée - résultat de sortie. Il est très probable qu’à l’intérieur se trouvent toutes les meilleures solutions d’automatisation, mais cela ne vous concerne pas. Des solutions assez coûteuses en termes d'une seule trame, mais si vos données sont vraiment précieuses - pourquoi pas?
- Les entreprises qui ont les outils pour faire un cycle presque complet de leurs propres mains. Par exemple, PowerAI d'IBM . C'est presque comme DIGITS, mais il suffit de baliser les jeux de données. De plus, personne n'optimise les réseaux de neurones et les solutions. Mais beaucoup de cas ont été résolus. Le modèle de réseau neuronal résultant vous est déployé et recevra un accès http. Il y a le même inconvénient ici qu'en chiffres - vous devez comprendre quoi faire. C'est votre cas qui peut «ne pas converger» ou simplement nécessiter une approche inhabituelle de la reconnaissance. En général, la solution est parfaite si vous avez une tâche assez standard, avec des objets bien séparables qui doivent être classés.
- Des entreprises qui résolvent exactement votre problème avec leurs outils. Il n'y a pas beaucoup d'entreprises de ce type. En réalité, je ne ferais référence qu'à CrowdFlower. Ici, pour de l'argent raisonnable, ils mettront des scribblers, affecteront un gestionnaire, déploieront leurs serveurs, où vos modèles seront lancés. Et pour de l'argent plus sérieux, ils pourront changer ou optimiser leurs décisions pour votre tâche.
Les grandes entreprises travaillent avec elles - ebay, oracle, tesco, adobe. A en juger par leur ouverture, ils interagissent avec succès avec les petites entreprises.
En quoi cela diffère-t-il du développement personnalisé qu'EPAM fait, par exemple? Le fait que tout est prêt ici. 99% de la solution n'est pas écrite, mais assemblée à partir de modules prêts à l'emploi: balisage de données, sélection de réseau, formation, développement. Les entreprises qui se développent sur commande n'ont pas une telle rapidité, la dynamique du développement de solutions, et l'infrastructure finie. Nous pensons que la tendance et l'approche identifiées par CrowdFlower sont vraies.
Pour quelles tâches cela fonctionne-t-il?
Peut-être que 70% des tâches sont automatisées de cette façon. Les tâches les plus appropriées sont la reconnaissance diversifiée des zones contenant du texte. Par exemple, les plaques d'immatriculation des voitures, dont nous
avons déjà parlé , les numéros de train (
voici notre exemple il y a deux ans ), les inscriptions sur les conteneurs.

De nombreuses informations techniques symboliques sont reconnues dans les usines pour rendre compte des produits et de leur qualité.
Cette approche aide beaucoup à reconnaître les produits sur les étagères des magasins et les étiquettes de prix, bien que des solutions de reconnaissance assez compliquées doivent y être créées.

Mais, vous pouvez échapper aux tâches avec des informations techniques. Toute sémantique, qu'il s'agisse de segmentation d'instance, avec la détection de voitures, d'argali, d'orignaux et d'otaries à fourrure s'inscrira également parfaitement dans cette approche.

Une direction très prometteuse est de maintenir la communication avec les gens dans les bots de chat vocal et texte. Il y aura une manière assez inhabituelle de baliser: le contexte, le type de phrase, son «remplissage». Mais le principe est le même: nous travaillons en mode automatique, une personne contrôle l'exactitude de la compréhension et des réponses. Vous pouvez recourir à l'assistance d'un opérateur en cas de ton insatisfait ou irrité du client. À mesure que les données s'accumulent, nous nous recyclons.
Comment travailler avec la vidéo?
Si vous ou au sein de votre entreprise avez développé les compétences nécessaires (un peu d'expérience en Machine Learning, en travaillant avec le Zoo Framework, à la fois hors ligne et en ligne), il n'y aura aucune difficulté à résoudre de simples problèmes de vision par ordinateur: segmentation, classification, reconnaissance de texte et autre
Mais pour la vidéo, tout n'est pas si fluide. Comment marquez-vous ces quantités infinies de données? Par exemple, il peut s'avérer qu'une fois toutes les quelques secondes, un objet (ou plusieurs objets) apparaît dans le cadre qui doit être balisé. En conséquence, tout cela peut se transformer en une visualisation image par image et prend tellement de ressources que l'on n'a même pas à parler de contrôle supplémentaire par une personne après le lancement d'une solution. Mais cela peut être surmonté si vous présentez la vidéo de la bonne manière afin de mettre en évidence les images présentant une zone d'intérêt.
Par exemple, nous sommes tombés sur d'énormes séries vidéo dans lesquelles il était nécessaire de mettre en évidence un seul objet spécifique - le couplage des quais ferroviaires. Et ce n'était vraiment pas facile. Il s'est avéré que tout n'est pas si effrayant, si vous élargissez le moniteur, choisissez une fréquence d'images, par exemple 10FPS, et placez 256 images sur une image, c'est-à-dire 25,6s dans une image:

Cela semble probablement effrayant. Mais en réalité, il faut environ 15 secondes pour cliquer sur un seul cadre, en choisissant le centre de l'accouplement de la voiture sur le cadre. Et même une personne en un jour ou deux peut marquer au moins 10 heures de vidéo. Obtenez plus de 30 000 exemples de formation. De plus, le passage des plateformes devant la caméra dans ce cas n'est pas un processus constant (mais plutôt rare, il faut le noter), il est assez réaliste même en temps quasi réel de corriger la machine de reconnaissance, en réapprovisionnant la base d'entraînement! Et si la reconnaissance se produit correctement dans la plupart des cas, une heure de vidéo peut être surmontée en quelques minutes. Et puis, négliger un contrôle total par la personne, en règle générale, n'est pas économiquement rentable.
C'est encore plus facile si la vidéo doit être marquée «oui / non» plutôt que la localisation de l'objet. Après tout, les événements sont souvent «collés ensemble» et d'un seul coup de souris, vous pouvez marquer jusqu'à 16 images à la fois.
La seule chose, en règle générale, est que vous devez utiliser 2 étapes dans l'analyse de la vidéo: rechercher des «images ou zones d'intérêt», puis travailler avec chacune de ces images (ou séquence d'images) par d'autres algorithmes.
Économie machine-humaine
Combien le coût du traitement des données visuelles peut-il être optimisé? D'une manière ou d'une autre, il est strictement nécessaire d'avoir une personne pour contrôler la reconnaissance des données. Si ce contrôle est sélectif, les coûts sont alors négligeables. Mais si nous parlons de contrôle total, dans quelle mesure cela peut-il être bénéfique? Il s'avère que cela a du sens presque toujours, si avant qu'une personne n'effectue la même tâche sans l'aide d'une machine.
Prenons le meilleur exemple au tout début: recherchez la pizza dans l'image, le balisage et la sélection du type (et en réalité, un certain nombre d'autres caractéristiques). Bien que la tâche ne soit pas aussi synthétique que cela puisse paraître. Le contrôle de l'apparence des produits de réseau de franchise existe en réalité.
Supposons que la reconnaissance à l'aide d'un serveur GPU nécessite 0,5 s de temps machine, pour qu'une personne marque complètement un cadre pendant environ 10 s (choisissez le type de pizza et sa qualité en fonction d'un certain nombre de paramètres), et pour vérifier si tout est correctement détecté par l'ordinateur, vous avez besoin de 2 s. Bien sûr, il sera difficile de savoir dans quelle mesure il est pratique de présenter ces données, mais ces délais sont tout à fait comparables à notre pratique.
Nous avons besoin de plus d'informations pour le coût de la mise en page manuelle et de la location d'un serveur GPU. En règle générale, vous ne devez pas compter sur une charge complète du serveur. Qu'il soit possible d'atteindre un chargement de 100 000 images par jour (cela prendra 60% de la puissance de traitement d'un GPU) avec un coût estimé d'une location de serveur mensuelle de 60 000 roubles. Il s'avère 2 sous pour l'analyse d'une image sur le GPU. Une analyse manuelle au coût de 30 000 r pour 40 heures de travail coûtera 26 kopecks par image.
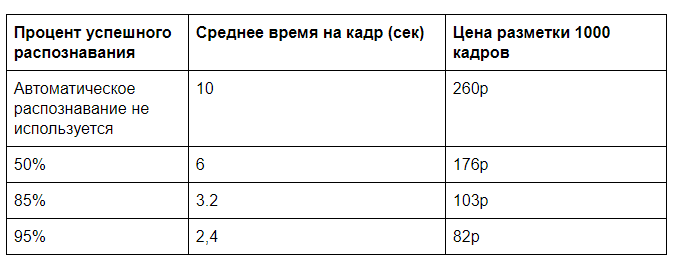
Et si vous supprimez ensuite le contrôle total, vous pourrez atteindre un prix de près de 20 roubles pour 1000 images. S'il y a beaucoup de données d'entrée, il est possible d'optimiser les algorithmes de reconnaissance, de travailler sur le transfert de données et d'atteindre une efficacité encore plus grande.
Dans la pratique, décharger une personne au fur et à mesure que le système de reconnaissance apprend a une autre signification importante - elle facilite beaucoup la mise à l'échelle de votre produit. Une augmentation significative de la quantité de données vous permet de mieux former le serveur de reconnaissance, la précision augmente. Et le nombre d'employés impliqués dans le processus de traitement des données augmentera de manière non proportionnelle au volume de données, ce qui simplifiera considérablement la croissance de l'entreprise d'un point de vue organisationnel.
En règle générale, plus vous devez saisir de texte et de contours manuellement, plus la reconnaissance automatique est rentable.
Et tout change-t-il?
Bien sûr, pas tous. Mais maintenant, certains domaines de l'entreprise ne sont pas aussi fous qu'auparavant.
Vous voulez créer un service hors ligne sans personne sur place? Plantez un opérateur à distance et surveillez
sur des caméras pour chaque client? Cela se révélera un peu pire qu'une personne vivante en place. Oui, et les opérateurs en ont besoin de plus. Et si vous déchargez l'opérateur toutes les 5 fois? Il peut s'agir d'un salon de beauté sans réception, sans contrôle en usine et sans système de sécurité. Une précision de 100% n'est pas requise - vous pouvez exclure complètement l'opérateur de la chaîne.
Il est possible d'organiser des systèmes de comptabilité assez complexes pour les services existants afin d'augmenter leur efficacité: contrôle des passagers, des véhicules, des horaires de prestation, où il existe un risque de «contournement» de la billetterie, etc.
Si la tâche est au niveau actuel de développement de la vision par ordinateur et ne nécessite pas de solutions complètement nouvelles, cela ne nécessitera pas d'investissements sérieux dans le développement.