Prologue
Actuellement, je développe un éditeur de schéma Javascript, et au cours de ce travail, j'ai rencontré un problème sur lequel cet article se concentrera, à savoir la sérialisation et la désérialisation d'objets de données complexes.
Sans entrer dans les détails du projet, je constate que selon mon idée, le schéma est un tableau d'éléments (sommets) hérité de la classe de base. En conséquence, chaque classe enfant implémente sa propre logique. De plus, les sommets contiennent des liens entre eux (flèches), qui doivent également être préservés. Théoriquement, les sommets peuvent se référer à eux-mêmes directement ou par le biais d'autres sommets. Le standard JSON.stringify n'est pas en mesure de sérialiser un tel tableau, j'ai donc décidé de créer mon propre sérialiseur qui résout les deux problèmes décrits:
- Possibilité d'enregistrer les informations de classe pendant la sérialisation et de les restaurer pendant la désérialisation.
- La possibilité d'enregistrer et de restaurer des liens vers des objets, y compris cyclique.
En savoir plus sur l'énoncé du problème et sa solution sous la coupe.
Projet sérialiseur Github
Lien vers le projet github: lien .
Des exemples complexes se trouvent également dans le dossier test-src .
Sérialiseur récursif: lien .
Sérialiseur plat: lien .
Énoncé du problème
Comme je l'ai déjà noté, la tâche initiale est de sérialiser des circuits arbitraires pour l'éditeur. Afin de ne pas perdre de temps à décrire l'éditeur, nous facilitons la tâche. Supposons que nous voulons faire une description formelle d'un schéma d'algorithme simple en utilisant les classes Javascript ES6, puis sérialiser et désérialiser ce schéma.
Sur Internet, j'ai trouvé une image appropriée de l'algorithme le plus simple pour déterminer le maximum de deux valeurs:
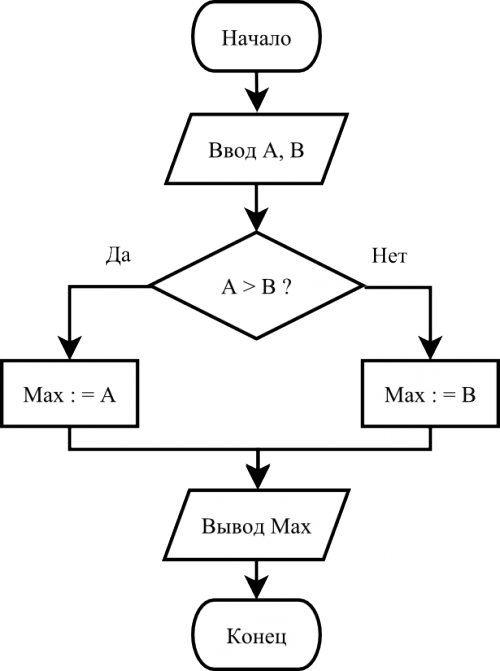
Il faut dire ici que je ne suis pas un développeur Javascript, et mon langage "natif" est C #, donc l'approche pour résoudre le problème est dictée par l'expérience du développement orienté objet en C #. En regardant ce diagramme, je vois les sommets des types suivants (les noms conditionnels et les rôles spéciaux ne jouent pas):
- Démarrer le sommet (Démarrer)
- Pic final (Terminer)
- Haut de l'équipe (commande)
- Sommet d'affectation (Let)
- Verification Verification Top (If)
Ces sommets ont quelques différences les uns par rapport aux autres dans leur ensemble de données ou leur sémantique, mais ils sont tous hérités du sommet de base (Node). Au même endroit, dans la classe Node, le champ de liens est décrit, qui contient des liens vers d'autres sommets, et la méthode addLink permet d'ajouter ces liens. Le code complet de toutes les classes peut être trouvé ici .
Écrivons le code qui collecte le circuit de l'image et essayons de sérialiser le résultat.
Code de conception d'algorithme Si nous sérialisons ce schéma en utilisant JSON.stringify, nous obtenons quelque chose de terrible. Je vais donner les premières lignes du résultat, dans lesquelles j'ai ajouté mes commentaires:
Résultat JSON.stringify [ { "id": "d9c8ab69-e4fa-4433-80bb-1cc7173024d6", "name": "Start", "links": { "2e3d482b-187f-4c96-95cd-b3cde9e55a43": { "id": "2e3d482b-187f-4c96-95cd-b3cde9e55a43", "target": { "id": "f87a3913-84b0-4b70-8927-6111c6628a1f", "name": "Command", "links": { "4f623116-1b70-42bf-8a47-da1e9be5e4b2": { "id": "4f623116-1b70-42bf-8a47-da1e9be5e4b2", "target": { "id": "94a47403-13ab-4c83-98fe-3b201744c8f2", "name": "If", "links": { ...
Parce que le premier sommet contenait un lien vers le second, et celui vers les suivants, puis à la suite de sa sérialisation l'ensemble du circuit a été sérialisé. Ensuite, le deuxième pic a été sérialisé et tout ce qui en dépendait, etc. Vous ne pouvez restaurer les liens d'origine à partir de ce hachage que par des identificateurs, mais ils ne seront d'aucune utilité si l'un des sommets se réfère à lui-même directement ou via d'autres sommets. Dans ce cas, le sérialiseur lancera une erreur TypeError Uncaught: Conversioning en erreur JSON . Si ce n'est pas clair, voici l'exemple le plus simple qui génère cette erreur: https://jsfiddle.net/L4guo86w/ .
De plus, JSON ne contient aucune information sur les classes source, il n'y a donc aucun moyen de comprendre de quel type était chaque sommet avant la sérialisation.
Conscient de ces problèmes, je suis allé en ligne et j'ai commencé à chercher des solutions toutes faites. Il y en avait beaucoup, mais la plupart étaient très volumineux ou nécessitaient une description spéciale des classes sérialisables, il a donc été décidé de faire votre propre vélo. Et oui, j'adore les vélos.
Concept de sérialiseur
Cette section s'adresse à ceux qui souhaitent participer à la création d'un algorithme de sérialisation avec moi, quoique virtuellement.
Un des problèmes avec Javascript est le manque de métadonnées qui peuvent faire des merveilles dans des langages comme C # ou Java (attributs et réflexion). En revanche, je n'ai pas besoin de sérialisation super complexe avec la possibilité de définir une liste de champs sérialisables, de validation et autres puces. Par conséquent, l'idée principale est d'ajouter des informations sur son type à l'objet et de le sérialiser avec JSON.stringify ordinaire.
Lors de la recherche de solutions, je suis tombé sur un article intéressant dont le titre se traduit par «6 mauvaises façons d'ajouter des informations de type dans JSON» . En fait, les méthodes sont très bonnes, et j'ai choisi celle au numéro 5. Si vous êtes trop paresseux pour lire l'article, mais je vous recommande fortement de le faire, alors je vais décrire brièvement cette méthode: lors de la sérialisation d'un objet, nous l'enveloppons dans un autre objet avec le seul un champ dont le nom est au format "@<type>" , et la valeur correspond aux données de l'objet. Lors de la désérialisation, nous extrayons le nom du type, recréons l'objet à partir du constructeur et lisons les données de ses champs.
Si nous supprimons les liens de notre exemple ci-dessus, alors JSON.stringify standard sérialise les données comme ceci:
JSON.stringify [ { "id": "d04d6a58-7215-4102-aed0-32122e331cf4", "name": "Start", "links": {} }, { "id": "5c58c3fc-8ce1-45a5-9e44-90d5cebe11d3", "name": "Command", "links": {}, "command": " A, B" }, ... }
Et notre sérialiseur l'enveloppera comme ceci:
Résultat de sérialisation [ { "@Schema.Start": { "id": "d04d6a58-7215-4102-aed0-32122e331cf4", "name": "Start", "links": {} } }, { "@Schema.Command": { "id": "5c58c3fc-8ce1-45a5-9e44-90d5cebe11d3", "name": "Command", "links": {}, "command": " A, B" } }, ... }
Bien sûr, il y a un inconvénient: le sérialiseur doit connaître les types qu'il peut sérialiser et les objets eux-mêmes ne doivent pas contenir de champs dont le nom commence par un chien. Cependant, le deuxième problème est résolu en accord avec les développeurs ou en remplaçant le symbole du chien par quelque chose d'autre, et le premier problème est résolu dans une ligne de code (ci-dessous sera un exemple). Nous savons exactement ce que nous allons sérialiser, non?
Résolution du problème de liaison
Il est toujours plus simple en termes d'algorithme, mais plus difficile à mettre en œuvre.
Lors de la sérialisation des instances de classes enregistrées dans le sérialiseur, nous les stockons dans le cache et leur attribuons un numéro de série. Si à l'avenir nous rencontrons à nouveau cette instance, alors dans la première définition, nous ajouterons ce numéro (le nom du champ prendra la forme "@<type>|<index>" ), et au lieu de sérialisation, nous insérerons le lien en tant qu'objet
{ "@<type>": <index> }
Ainsi, lors de la désérialisation, nous regardons quelle est exactement la valeur du champ. S'il s'agit d'un nombre, nous extrayons l'objet du cache par ce nombre. Sinon, c'est sa première définition.
Retournons le lien du premier sommet du schéma au second et regardons le résultat:
Résultat de sérialisation [ { "@Schema.Start": { "id": "a26a3a29-9462-4c92-8d24-6a93dd5c819a", "name": "Start", "links": { "25fa2c44-0446-4471-a013-8b24ffb33bac": { "@Schema.Link": { "id": "25fa2c44-0446-4471-a013-8b24ffb33bac", "target": { "@Schema.Command|1": { "id": "4f4f5521-a2ee-4576-8aec-f61a08ed38dc", "name": "Command", "links": {}, "command": " A, B" } } } } } } }, { "@Schema.Command": 1 }, ... }
Cela ne semble pas très clair à première vue, car le deuxième sommet est d'abord défini à l'intérieur du premier dans l'objet de communication Link, mais il est important que cette approche fonctionne. De plus, j'ai créé la deuxième version du sérialiseur, qui contourne l'arbre non pas en profondeur, mais en largeur, ce qui évite de telles "échelles".
Créer un sérialiseur
Cette section est destinée à ceux qui souhaitent mettre en œuvre les idées décrites ci-dessus.
Sérialiseur vierge
Comme tout autre, notre sérialiseur aura deux méthodes principales: sérialiser et désérialiser. De plus, nous aurons besoin d'une méthode qui indique au sérialiseur les classes qu'il doit sérialiser (s'inscrire) et les classes qui ne doivent pas (ignorer). Ce dernier est nécessaire afin de ne pas sérialiser les éléments DOM, les objets JQuery ou tout autre type de données qui ne peuvent pas être sérialisés ou qui ne sont pas nécessaires pour être sérialisés. Par exemple, dans mon éditeur, je stocke un élément visuel correspondant à un sommet ou un lien. Il est créé lors de l'initialisation et, bien sûr, ne doit pas tomber dans la base de données.
Code shell du sérialiseur export default class Serializer { constructor() { this._nameToCtor = [];
Explications
Pour enregistrer une classe, vous devez passer son constructeur à la méthode register de deux manières:
- s'inscrire (MyClass)
- s'inscrire ('MyNamespace.MyClass', MyClass)
Dans le premier cas, le nom de la classe sera extrait du nom de la fonction constructeur (non pris en charge dans IE), dans le second, vous spécifiez le nom vous-même. La deuxième méthode est préférable, car vous permet d'utiliser des espaces de noms, et le premier, de par sa conception, est conçu pour enregistrer les types Javascript intégrés avec une logique de sérialisation redéfinie.
Pour notre exemple, l'initialisation du sérialiseur est la suivante:
import Schema from './schema'; ...
L'objet Schema contient des descriptions de toutes les classes de vertex, de sorte que le code d'enregistrement de classe tient sur une seule ligne.
Le contexte de la sérialisation et de la désérialisation
Vous avez peut-être remarqué les classes cryptiques SerializationContext et DeserializationContext. Ce sont eux qui font tout le travail et sont nécessaires principalement pour séparer les données des différents processus de sérialisation / désérialisation, car pour chaque appel, ils doivent stocker des informations intermédiaires - un cache d'objets sérialisés et un numéro de série pour la liaison.
SerializationContext
Je vais analyser en détail uniquement le sérialiseur récursif, car leur homologue "plat" est un peu plus compliqué et ne diffère que par son approche du traitement d'un arbre d'objets.
Commençons par le constructeur:
constructor(ser) { this.__proto__.__proto__ = ser; this.cache = [];
Je this.__proto__.__proto__ = ser; d'expliquer la ligne mystérieuse de this.__proto__.__proto__ = ser;
A l'entrée du constructeur, nous acceptons l'objet du sérialiseur lui-même, et cette ligne en hérite notre classe. Cela permet d'accéder aux données du sérialiseur par this biais.
Par exemple, this._ignore fait référence à une liste de classes ignorées du sérialiseur lui-même (la "liste noire"), ce qui est très utile. Sinon, nous aurions à écrire quelque chose comme this._serializer._ignore .
Méthode de sérialisation principale:
serialize(val) { if (Array.isArray(val)) {
Il convient de noter qu'il existe trois types de données de base que nous traitons: les tableaux, les objets et les valeurs simples. Si le constructeur d'un objet est dans la "liste noire", alors cet objet n'est pas sérialisé.
Sérialisation de la baie:
serializeArray(val) { let res = []; for (let item of val) { let e = this.serialize(item); if (typeof e !== 'undefined') res.push(e); } return res; }
Vous pouvez écrire plus court via la carte, mais ce n'est pas critique. Une seule chose est importante: vérifier la valeur indéfinie. S'il y a une classe non sérialisable dans le tableau, sans cette vérification, elle tombera dans le tableau comme non définie, ce qui n'est pas très bon. Toujours dans mon implémentation, les tableaux sont sérialisés sans clés. Théoriquement, vous pouvez affiner l'algorithme de sérialisation des tableaux associatifs, mais à ces fins, je préfère utiliser des objets. De plus, JSON.stringify n'aime pas non plus les tableaux associatifs.
Sérialisation d'objets:
Code serializeObject(val) { let name = this._ctorToName[val.constructor]; if (name) {
Évidemment, c'est la partie la plus difficile du sérialiseur, son cœur. Prenons-le à part.
Pour commencer, nous vérifions si le constructeur de classe est enregistré dans le sérialiseur. Sinon, il s'agit d'un objet simple pour lequel la méthode utilitaire serializeObjectInner est appelée.
Sinon, nous vérifions si l'objet est attribué à un identifiant unique __uuid . Il s'agit d'une simple variable de compteur commune à tous les sérialiseurs et utilisée pour conserver la référence à l'instance de classe dans le cache. Vous pouvez vous en passer et stocker l'instance elle-même sans clé dans le cache, mais ensuite pour vérifier si l'objet est stocké dans le cache, vous devrez parcourir l'intégralité du cache, et ici il suffit de vérifier la clé. Je pense que c'est plus rapide en termes d'implémentation interne d'objets dans les navigateurs. De plus, je ne intentionnellement pas sérialiser les champs commençant par deux traits de soulignement, donc le champ __uuid ne tombera pas dans le json résultant, comme les autres champs de classe privée. Si cela est inacceptable pour votre tâche, vous pouvez modifier cette logique.
Ensuite, par la valeur de __uuid, nous recherchons un objet qui décrit l'instance de la classe dans le cache ( mis en cache ).
Si un tel objet existe, la valeur a déjà été sérialisée plus tôt. Dans ce cas, nous attribuons un numéro de série à l'objet, si cela n'a pas été fait auparavant:
if (!cached.index) {
Le code semble confus, et il peut être simplifié en attribuant un numéro à toutes les classes que nous sérialisons. Mais pour déboguer et percevoir le résultat, il est préférable que le numéro soit attribué uniquement aux classes auxquelles il existe des liens à l'avenir.
Lorsque le numéro est attribué, nous renvoyons le lien selon l'algorithme:
Si l'objet est sérialisé pour la première fois, nous créons une instance de son cache:
let res; let cached = { ref: { [`@${name}`]: {} } }; this.cache[val.__uuid] = cached;
Et puis sérialisez-le:
if (typeof val.serialize === 'function') {
Il y a une vérification de l'implémentation de l'interface de sérialisation par la classe (qui sera discutée plus loin), ainsi que la construction d' Object.keys(cached.ref)[0] . Le fait est que cached.ref stocke un lien vers l'objet wrapper { "@<type>[|<index>]": <> } , mais le nom du champ objet nous est inconnu, car à ce stade, nous ne savons pas encore si le nom contiendra le numéro d'objet (index). Cette construction extrait simplement le premier et le seul champ de l'objet.
Enfin, la méthode utilitaire de sérialisation des objets internes:
serializeObjectInner(val) { let res = {}; for (let key of Object.getOwnPropertyNames(val)) { if (!(isString(key) && key.startsWith('__'))) {
Nous créons un nouvel objet et copions les champs de l'ancien dans celui-ci.
DeserializationContext
Le processus de désérialisation fonctionne dans l'ordre inverse et n'a pas besoin de commentaires spéciaux.
Code /** * */ class DeserializationContext { /** * * @param {Serializer} ser */ constructor(ser) { this.__proto__.__proto__ = ser; this.cache = []; // } /** * json * @param {any} val json * @returns {any} */ deserialize(val) { if (Array.isArray(val)) { // return this.deserializeArray(val); } else if (isObject(val)) { // return this.deserializeObject(val); } else { // return val; } } /** * * @param {Object} val * @returns {Object} */ deserializeArray(val) { return val.map(item => this.deserialize(item)); } /** * * @param {Array} val * @returns {Array} */ deserializeObject(val) { let res = {}; for (let key of Object.getOwnPropertyNames(val)) { let data = val[key]; if (isString(key) && key.startsWith('@')) { // if (isInteger(data)) { // res = this.cache[data]; if (res) { return res; } else { console.error(` ${data}`); return data; } } else { // let [name, id] = key.substr(1).split('|'); let ctor = this._nameToCtor[name]; if (ctor) { // res = new ctor(); // , if (id) this.cache[id] = res; if (typeof res.deserialize === 'function') { // res.deserialize(data); } else { // for (let key of Object.getOwnPropertyNames(data)) { res[key] = this.deserialize(data[key]); } } return res; } else { // console.error(` "${name}" .`); return val[key]; } } } else { // res[key] = this.deserialize(val[key]); } } return res; } }
Fonctionnalités supplémentaires
Interface de sérialisation
Il n'y a pas de prise en charge d'interface en Javascript, mais nous pouvons convenir que si la classe implémente les méthodes de sérialisation et de désérialisation, ces méthodes seront utilisées pour la sérialisation / désérialisation, respectivement.
De plus, Javascript vous permet d'implémenter ces méthodes pour les types intégrés, par exemple, pour Date:
Sérialiser la date au format ISO Date.prototype.serialize = function () { return this.toISOString(); }; Date.prototype.deserialize = function (val) { let date = new Date(val); this.setDate(date.getDate()); this.setTime(date.getTime()); };
L'essentiel est de ne pas oublier d'enregistrer le type Date: serializer.register(Date); .
Résultat:
{ "@Date": "2018-06-02T20:41:06.861Z" }
La seule limitation: le résultat de la sérialisation ne doit pas être un entier, car dans ce cas, il sera interprété comme une référence à l'objet.
De même, vous pouvez sérialiser des classes simples en chaînes. Un exemple de sérialisation de la classe Color, qui décrit la couleur, à la ligne #rrggbb est sur github .
Sérialiseur plat
Spécialement pour vous, chers lecteurs, j'ai écrit la deuxième version du sérialiseur , qui parcourt l'arbre des objets non pas récursivement en profondeur, mais de manière itérative en largeur en utilisant une file d'attente.
Pour comparaison, je donnerai un exemple de sérialisation des deux premiers sommets de notre schéma dans les deux cas.
Sérialiseur récursif (sérialisation en profondeur) [ { "@Schema.Start": { "id": "5ec74f26-9515-4789-b852-12feeb258949", "name": "Start", "links": { "102c3dca-8e08-4389-bc7f-68862f2061ef": { "@Schema.Link": { "id": "102c3dca-8e08-4389-bc7f-68862f2061ef", "target": { "@Schema.Command|1": { "id": "447f6299-4bd4-48e4-b271-016a0d47fc0e", "name": "Command", "links": {}, "command": " A, B" } } } } } } }, { "@Schema.Command": 1 } ]
Sérialiseur plat (à l'échelle de la sérialisation) [ { "@Schema.Start": { "id": "1412603f-24c2-4513-836e-f2b0c0392483", "name": "Start", "links": { "b94ac7e5-d75f-44c1-960f-a02f52c994da": { "@Schema.Link": { "id": "b94ac7e5-d75f-44c1-960f-a02f52c994da", "target": { "@Schema.Command": 1 } } } } } }, { "@Schema.Command|1": { "id": "a93e452e-4276-4d6a-86a1-0681226d79f0", "name": "Command", "links": {}, "command": " A, B" } } ]
Personnellement, j'aime encore plus la deuxième option que la première, mais il ne faut pas oublier qu'en choisissant l'une des options, vous ne pouvez pas utiliser l'autre. Tout est question de liens. Notez que dans le sérialiseur plat, un lien vers le deuxième sommet précède sa description.
Avantages et inconvénients du sérialiseur
Avantages:
- Le code du sérialiseur est assez simple et compact (environ 300 lignes, dont la moitié sont des commentaires).
- Le sérialiseur est facile à utiliser et ne nécessite pas de bibliothèques tierces.
- Il existe un support intégré pour l'interface de sérialisation pour la sérialisation arbitraire des classes.
- Le résultat est agréablement agréable à l'œil (à mon humble avis).
- Développer un sérialiseur / désérialiseur similaire dans d'autres langues n'est pas un problème. Cela peut être nécessaire si le résultat de la sérialisation est traité au verso.
Inconvénients:
- Le sérialiseur nécessite l'enregistrement de classes qu'il peut sérialiser.
- Il existe de légères restrictions sur les noms de champ des objets.
- Le sérialiseur est écrit noob en Javascript, il peut donc contenir des bugs et des erreurs.
- Les performances sur de grandes quantités de données peuvent en souffrir.
Un inconvénient est également que le code est écrit en ES6. Bien sûr, il est possible de convertir vers des versions antérieures de Javascript, mais je n'ai pas vérifié la compatibilité du code résultant avec différents navigateurs.
Mes autres publications
- Localisation de projets sur .NET avec un interpréteur de fonctions
- Remplir des modèles de texte avec des données basées sur un modèle. Implémentation .NET à l'aide de fonctions de bytecode dynamique (IL)