Ajouté par: bonne discussion sur Hacker NewsDavid Yu sur GitHub a développé un
test de performance intéressant pour les appels de fonction via diverses interfaces externes (interfaces de fonction étrangère,
FFI ).
Il a créé un fichier objet partagé (
.so ) avec une simple fonction C. Puis il a écrit du code pour appeler à plusieurs reprises cette fonction via chaque FFI avec une dimension temporelle.
Pour C «FFI», il a utilisé la liaison dynamique standard, pas
dlopen() . Cette différence est très importante, car elle affecte vraiment les résultats des tests. Vous pouvez discuter de l'honnêteté de cette comparaison avec le FFI réel, mais elle est toujours intéressante à mesurer.
Le résultat de référence le plus surprenant est que
le FFI
de LuaJIT est
nettement plus rapide que C. Il est environ 25% plus rapide qu'un appel C natif pour une fonction d'objet partagé. Comment un langage de script typé faiblement et dynamiquement pourrait-il dépasser dans le benchmark C? Le résultat est-il exact?
En fait, c'est tout à fait logique. Le test s'exécute sous Linux, donc le retard provient de la table de liaison de procédure (PLT). J'ai préparé une expérience très simple pour démontrer l'effet dans un vieux C simple:
https://github.com/skeeto/dynamic-function-benchmarkVoici les résultats sur l'Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callIl existe trois types différents d'appels de fonction:
- Via PLT.
- Appel de fonction indirect (via
dlsym(3) ) - Appel de fonction direct (via une fonction compilée JIT)
Comme vous pouvez le voir, ce dernier est le plus rapide. Il n'est généralement pas utilisé dans les programmes C, mais c'est une option naturelle en présence d'un compilateur JIT, y compris, évidemment, LuaJIT.
Dans mon cas-test, la fonction
empty() est appelée:
void empty(void) { }
Compilez vers un objet partagé:
$ cc -shared -fPIC -Os -o empty.so empty.c
Comme dans la
comparaison PRNG précédente, la référence autant de fois que possible appelle cette fonction avant que l'alarme ne se déclenche.
Tableaux de présentation des procédures
Lorsqu'un programme ou une bibliothèque appelle une fonction dans un autre objet partagé, le compilateur ne peut pas savoir où cette fonction sera en mémoire. Les informations ne sont découvertes qu'au moment de l'exécution lorsque le programme et ses dépendances sont chargés en mémoire. Habituellement, la fonction est située dans des endroits aléatoires, par exemple, conformément à la randomisation de l'espace d'adressage (randomisation de la disposition de l'espace d'adressage, ASLR).
Comment résoudre un tel problème? Eh bien, il y a plusieurs options.
L'un d'eux consiste à marquer chaque appel dans des métadonnées binaires. Le générateur d'exécution dynamique
insère ensuite
l' adresse correcte à chaque appel. Le mécanisme spécifique dépend du
modèle de code utilisé lors de la compilation.
L'inconvénient de cette approche est qu'elle ralentit le chargement, augmente la taille des fichiers binaires et réduit l'
échange de pages de codes entre les différents processus. Le téléchargement est ralenti car tous les homologues de numérotation dynamique doivent être corrigés avec la bonne adresse avant de démarrer le programme. Le binaire est gonflé car chaque entrée a besoin d'une place dans la table. Et le manque de partage est associé à un changement de pages de codes.
D'un autre côté, le surcoût lié à l'invocation de fonctions dynamiques peut être éliminé, ce qui donne des performances de type JIT, comme le montre le cas-test.
La deuxième option consiste à acheminer tous les appels dynamiques via une table. L'homologue de numérotation d'origine fait référence au talon de ce tableau, et de là à la fonction dynamique réelle. Avec cette approche, le code n'a pas besoin d'être corrigé, ce qui conduit à un
échange trivial entre les processus. Pour chaque fonction dynamique, vous devez patcher un seul enregistrement dans le tableau. De plus, ces corrections peuvent être effectuées
paresseusement , au premier appel de la fonction, ce qui accélère encore plus le chargement.
Sur les systèmes binaires ELF, cette table est appelée Table de liaison de procédures (PLT). PLT lui-même n'est pas vraiment corrigé - il est affiché en lecture seule pour le reste du code. Au lieu de cela, le Global Offset Table (GOT) est corrigé. Le stub PLT récupère l'adresse d'une fonction dynamique du GOT et saute
indirectement à cette adresse. Pour charger des adresses de fonction paresseusement, ces entrées GOT sont initialisées avec l'adresse de la fonction qui trouve le caractère cible, met à jour le GOT avec cette adresse, puis passe à la fonction. Les appels suivants utilisent une adresse détectée paresseusement.
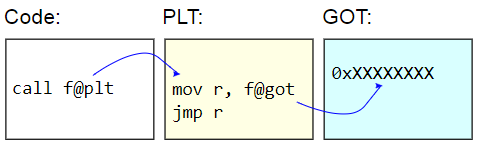
L'inconvénient du PLT est le surcoût supplémentaire lié à l'invocation d'une fonction dynamique, ce qui est apparu dans le benchmark. Étant donné que l'indice de référence
ne mesure
que les appels de fonction, la différence semble assez importante, mais en pratique, elle est généralement proche de zéro.
Voici la référence:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
Puisque
empty() trouve dans un objet partagé, l'appel passe par le PLT.
Appels dynamiques indirects
Une autre façon d'appeler dynamiquement des fonctions consiste à parcourir le PLT et à obtenir l'adresse de la fonction cible dans le programme, par exemple via
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
Si l'adresse de fonction est reçue, le coût est inférieur aux appels de fonction via PLT. Il n'y a pas de fonction intermédiaire de stub et d'accès à GOT. (Attention: si le programme a un enregistrement PLT pour cette fonction, alors
dlsym(3) peut en fait retourner une adresse de stub).
Mais c'est toujours un défi
indirect . Sur les architectures conventionnelles,
les appels de fonction
directs reçoivent leur adresse relative immédiate. Autrement dit, le but de l'appel est un décalage codé en dur par rapport au point d'appel. Le CPU peut déterminer où l'appel ira beaucoup plus tôt.
Les appels indirects ont plus de frais généraux. Tout d'abord, l'adresse doit être stockée quelque part. Même s'il ne s'agit que d'un registre, son utilisation augmente le déficit de registres. Deuxièmement, les appels indirects provoquent un prédicteur de branche dans le CPU, imposant une charge supplémentaire au processeur. Dans le pire des cas, un appel peut même entraîner l'arrêt du pipeline.
Voici la référence:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
La fonction passée à cette référence est extraite à l'aide de
dlsym(3) , donc le compilateur ne peut pas
faire quelque chose de délicat , comme convertir cet appel indirect en direct.
Si le corps de la boucle est suffisamment complexe pour provoquer un déficit de registres et ainsi donner l'adresse à la pile, alors ce repère ne peut pas non plus être honnêtement comparé au repère PLT.
Appels de fonction directs
Les deux premiers types d'appels de fonctions dynamiques sont simples et faciles à utiliser.
Les appels
directs à des fonctions dynamiques sont plus difficiles à organiser, car ils nécessitent des modifications de code lors de l'exécution. Dans mon benchmark, j'ai mis en place un
petit compilateur JIT pour générer un appel direct.
L'astuce est que sur x86-64, les transitions explicites sont limitées à une plage de 2 Go en raison de l'opérande signé 32 bits (signé immédiatement). Cela signifie que le code JIT doit être placé presque à côté de la fonction cible,
empty() . Si le code JIT doit appeler deux fonctions dynamiques différentes, divisées par plus de 2 Go, il est impossible de faire deux appels directs.
Pour simplifier la situation, mon benchmark ne s'inquiète pas du choix exact ou très soigneux de l'adresse du code JIT. Après avoir reçu l'adresse de la fonction cible, il soustrait simplement 4 Mo, l'arrondit à la page la plus proche, alloue un peu de mémoire et y écrit du code. Si tout est fait comme il se doit, pour rechercher un endroit, vous devez vérifier vos propres représentations du programme en mémoire, et cela ne peut pas être fait de manière propre et portable. Linux
nécessite l'analyse des fichiers virtuels sous / proc .
Voici à quoi ressemble mon allocation de mémoire JIT. Il suppose
un comportement raisonnable pour le cast de uintptr_t :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
Deux pages se distinguent ici: une pour l'écriture et l'autre avec du code non inscriptible. Comme dans ma
bibliothèque pour les fermetures , ici la page du bas est accessible en écriture et contient une variable en
running qui se réinitialise à l'alarme. Cette page doit être à côté du code JIT afin de fournir un accès efficace concernant RIP, en fonction des deux autres benchmarks. La page supérieure contient ce code d'assemblage:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty est la seule instruction générée dynamiquement, il est nécessaire de renseigner correctement l'adresse relative (moins 5 est indiqué par rapport à la
fin de l' instruction):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
Si la fonction
empty() n'est pas dans l'objet général, mais dans le même fichier binaire, il s'agit essentiellement d'un appel direct que le compilateur va générer pour
plt_benchmark() , en supposant que pour une raison quelconque, il n'a pas intégré
empty() .
Ironiquement, appeler un code compilé JIT nécessite un appel indirect (par exemple, via un pointeur de fonction), et il n'y a aucun moyen de contourner cela. Que puis-je faire ici, compiler JIT une autre fonction pour un appel direct? Heureusement, cela n'a pas d'importance car seul un appel direct est mesuré dans une boucle.
Pas de secret
Compte tenu de ces résultats, il devient clair pourquoi LuaJIT génère des appels aux fonctions dynamiques plus efficaces que PLT,
même s'ils restent des appels indirects . Dans mon indice de référence, les appels indirects sans PLT étaient 28% plus rapides qu'avec le PLT, et les appels directs sans PLT étaient 43% plus rapides qu'avec le PLT. Ce petit avantage des programmes JIT par rapport aux simples anciens programmes natifs est dû au rejet absolu de l'échange de code entre les processus.