
Dans un projet lié à la sécurité des systèmes Linux, nous devions intercepter les appels à des fonctions importantes à l'intérieur du noyau (telles que l'ouverture de fichiers et l'exécution de processus) pour permettre de surveiller l'activité dans le système et bloquer préventivement l'activité des processus suspects.
Au cours du processus de développement, nous avons réussi à inventer une assez bonne approche, qui nous permet d'intercepter facilement toute fonction du noyau par son nom et d'exécuter notre code autour de ses appels. L'intercepteur peut être installé à partir d'un module GPL chargeable, sans reconstruire le noyau. L'approche prend en charge les noyaux version 3.19+ pour l'architecture x86_64.
(Image de pingouin juste au-dessus: © En3l avec DeviantArt .)Approches connues
API de sécurité Linux
Le plus correct serait d'utiliser l'
API de sécurité Linux - une interface spéciale créée spécifiquement à ces fins. Dans les endroits critiques du code du noyau, les appels aux fonctions de sécurité sont localisés, ce qui, à son tour, appelle les rappels définis par le module de sécurité. Le module de sécurité peut examiner le contexte d'une opération et décider si elle est autorisée ou refusée.
Malheureusement, l'API de sécurité Linux présente quelques limitations importantes:
- les modules de sécurité ne peuvent pas être chargés dynamiquement, font partie du noyau et nécessitent une reconstruction
- il ne peut y avoir qu'un seul module de sécurité dans le système (à quelques exceptions près)
Si la position des développeurs du noyau est ambiguë quant à la multiplicité des modules, alors l'interdiction du chargement dynamique est fondamentale: le module de sécurité doit faire partie du noyau pour assurer une sécurité constante, dès le chargement.
Ainsi, pour utiliser l'API de sécurité, vous devez fournir votre propre assemblage de noyau, ainsi qu'intégrer le module complémentaire avec SELinux ou AppArmor, qui sont utilisés par les distributions populaires. Le client ne souhaitant pas souscrire à de telles obligations, cet itinéraire a donc été fermé.
Pour ces raisons, l'API de sécurité ne nous convenait pas, sinon ce serait une option idéale.
Modification de la table d'appels système
La surveillance était nécessaire principalement pour les actions effectuées par les applications utilisateur, de sorte qu'elle pouvait en principe être mise en œuvre au niveau des appels système. Comme vous le savez, Linux stocke tous les gestionnaires d'appels système dans la table
sys_call_table . La substitution de valeurs dans ce tableau entraîne une modification du comportement de l'ensemble du système. Ainsi, en conservant les anciennes valeurs du gestionnaire et en substituant notre propre gestionnaire dans la table, nous pouvons intercepter tout appel système.
Cette approche présente certains avantages:
- Contrôle total sur tous les appels système - la seule interface vers le noyau pour les applications utilisateur. En l'utilisant, nous pouvons être sûrs que nous ne manquerons aucune action importante effectuée par le processus utilisateur.
- Frais généraux minimaux. Il y a un investissement en capital unique lors de la mise à jour de la table d'appels système. Outre l'inévitable surveillance de la charge utile, la seule dépense est un appel de fonction supplémentaire (pour appeler le gestionnaire d'appels système d'origine).
- Configuration minimale du noyau. Si vous le souhaitez, cette approche ne nécessite aucune option de configuration supplémentaire dans le noyau, donc en théorie, elle prend en charge la gamme de systèmes la plus large possible.
Cependant, il souffre également de quelques défauts:
- La complexité technique de la mise en œuvre. En soi, le remplacement des pointeurs dans une table n'est pas difficile. Mais les tâches connexes nécessitent des solutions non évidentes et une certaine qualification:
- table d'appel système de recherche
- bypass de protection de modification de table
- remplacement atomique et sûr
Ce sont toutes des choses intéressantes, mais elles nécessitent un temps de développement précieux, d'abord pour la mise en œuvre, puis pour le support et la compréhension.
- Impossibilité d'intercepter certains gestionnaires. Dans les noyaux antérieurs à la version 4.16, la gestion des appels système pour l'architecture x86_64 contenait un certain nombre d'optimisations. Certains d'entre eux ont exigé que le gestionnaire d'appels système soit un adaptateur spécial implémenté dans l'assembleur. En conséquence, de tels gestionnaires sont parfois difficiles, et parfois même impossibles à remplacer par les vôtres, écrits en C. De plus, différentes optimisations sont utilisées dans différentes versions du noyau, ce qui ajoute aux difficultés techniques de la tirelire.
- Seuls les appels système sont interceptés. Cette approche vous permet de remplacer les gestionnaires d'appels système, ce qui limite les points d'entrée à eux uniquement. Toutes les vérifications supplémentaires sont effectuées au début ou à la fin, et nous n'avons que les arguments de l'appel système et sa valeur de retour. Parfois, cela conduit à la nécessité de dupliquer les contrôles de l'adéquation des arguments et des contrôles d'accès. Parfois, cela entraîne une surcharge inutile lorsque vous devez copier la mémoire du processus utilisateur deux fois: si l'argument est passé par un pointeur, nous devons d'abord le copier nous-mêmes, puis le gestionnaire d'origine copiera à nouveau l'argument pour lui-même. De plus, dans certains cas, les appels système fournissent une granularité trop faible des événements qui doivent en outre être filtrés du bruit.
Au départ, nous avons choisi et mis en œuvre avec succès cette approche, poursuivant les avantages de la prise en charge du plus grand nombre de systèmes. Cependant, à cette époque, nous ne connaissions toujours pas les fonctionnalités de x86_64 et les restrictions sur les appels interceptés. Plus tard, il s'est avéré essentiel pour nous de prendre en charge les appels système liés au démarrage de nouveaux processus - clone () et execve () - qui sont tout simplement spéciaux. C'est ce qui nous a conduit à rechercher de nouvelles options.
Utilisation de kprobes
L'une des options envisagées était l'utilisation de
kprobes : une API spécialisée principalement conçue pour le débogage et le traçage du noyau. Cette interface vous permet de définir des pré-et post-gestionnaires pour
toute instruction dans le noyau, ainsi que des gestionnaires pour entrer et revenir d'une fonction. Les gestionnaires ont accès aux registres et peuvent les modifier. Ainsi, nous pourrions obtenir à la fois une surveillance et la capacité d'influencer la suite des travaux.
Avantages de l'utilisation de kprobes pour intercepter:
- API mature. Les kprobes existent et se sont améliorés depuis des temps immémoriaux (2002). Ils ont une interface bien documentée, la plupart des écueils ont déjà été trouvés, leur travail a été optimisé autant que possible, etc. En général, toute une montagne d'avantages par rapport aux vélos auto-fabriqués expérimentaux.
- Interception de n'importe quel endroit dans le noyau. Les kprobes sont implémentées à l'aide de points d'arrêt (instructions int3) intégrés dans le code exécutable du noyau. Cela vous permet d'installer kprobes littéralement n'importe où dans n'importe quelle fonction, si elle est connue. De même, les kretprobes sont implémentées en usurpant l'adresse de retour sur la pile et vous permettent d'intercepter le retour de n'importe quelle fonction (à l'exception de celles qui en principe ne renvoient pas le contrôle).
Inconvénients des kprobes:
- Difficulté technique. Kprobes est juste un moyen de définir un point d'arrêt n'importe où dans le noyau. Pour obtenir les arguments d'une fonction ou les valeurs des variables locales, vous devez savoir dans quels registres ou où sur la pile ils se trouvent, et les extraire indépendamment de là. Pour bloquer un appel de fonction, vous devez modifier manuellement l'état du processus afin que le processeur pense qu'il a déjà renvoyé le contrôle de la fonction.
- Les Jprobes sont obsolètes. Jprobes est un module complémentaire pour kprobes qui vous permet d'intercepter facilement les appels de fonction. Il extraira indépendamment les arguments de la fonction des registres ou de la pile et appellera votre gestionnaire, qui devrait avoir la même signature que la fonction hookée. Le hic, c'est que les jprobes sont obsolètes et coupés dans les noyaux modernes.
- Frais généraux non triviaux. Les points d'arrêt sont chers, mais ponctuels. Les points d'arrêt n'affectent pas les autres fonctions, mais leur traitement est relativement coûteux. Heureusement, l'optimisation des sauts est implémentée pour l'architecture x86_64, ce qui réduit considérablement le coût des kprobes, mais elle reste plus que, par exemple, lors de la modification de la table d'appels système.
- Limitations des kretprobes. Les kretprobes sont implémentées en usurpant l'adresse de retour sur la pile. En conséquence, ils doivent stocker l'adresse d'origine quelque part afin de pouvoir y revenir après le traitement de kretprobe. Les adresses sont stockées dans un tampon de taille fixe. En cas de dépassement, lorsque trop d'appels simultanés de la fonction interceptée sont exécutés dans le système, kretprobes sautera les opérations.
- Extrusion désactivée. Puisque kprobes est basé sur des interruptions et jongle avec les registres du processeur, pour la synchronisation, tous les gestionnaires sont exécutés avec préemption désactivée. Cela impose certaines restrictions aux gestionnaires: vous ne pouvez pas attendre dedans - allouer beaucoup de mémoire, faire des E / S, dormir dans des temporisateurs et des sémaphores, et d'autres choses connues.
Dans le processus de recherche sur le sujet, nos yeux sont tombés sur le framework
ftrace , qui peut remplacer les jprobes. Il s'est avéré que cela fonctionne mieux pour nos besoins d'interception d'appels de fonction. Cependant, si vous devez suivre des instructions spécifiques dans les fonctions, les kprobes ne doivent pas être actualisés.
Épissage
Par souci d'exhaustivité, il convient également de décrire la méthode classique d'interception de fonctions, qui consiste à remplacer les instructions au début de la fonction par une transition inconditionnelle conduisant à notre gestionnaire. Les instructions d'origine sont transférées à un autre endroit et exécutées avant de revenir à la fonction interceptée. À l'aide de deux transitions, nous intégrons (épissons) notre code supplémentaire dans la fonction, par conséquent, cette approche est appelée
épissage .
C'est ainsi que l'optimisation des sauts pour kprobes est implémentée. En utilisant l'épissage, vous pouvez obtenir les mêmes résultats, mais sans coûts supplémentaires pour les kprobes et avec un contrôle complet de la situation.
Les avantages de l'épissage sont évidents:
- Configuration minimale du noyau. L'épissage ne nécessite aucune option spéciale dans le noyau et fonctionne au début de toute fonction. Vous avez juste besoin de connaître son adresse.
- Frais généraux minimaux. Deux transitions inconditionnelles - c'est toutes les actions que le code intercepté doit effectuer pour transférer le contrôle au gestionnaire et vice versa. De telles transitions sont parfaitement prédites par le processeur et sont très bon marché.
Cependant, le principal inconvénient de cette approche obscurcit sérieusement l'image:
- Difficulté technique. Elle se retourne. Vous ne pouvez pas simplement prendre et réécrire le code machine. Voici une liste courte et incomplète des tâches à résoudre:
- synchronisation de l'installation et suppression de l'interception (que faire si la fonction est appelée directement dans le processus de remplacement de ses instructions?)
- contournement de la protection lors de la modification des régions mémoire avec un code
- Invalidation du cache du processeur après le remplacement des instructions
- démontage des instructions remplaçables pour les copier en entier
- vérification de l'absence de transitions à l'intérieur de la pièce remplacée
- vérifier la possibilité de déplacer la pièce remplacée vers un autre emplacement
Oui, vous pouvez espionner les kprobes et utiliser le framework intranucléaire livepatch, mais la solution finale est encore assez compliquée. Il est effrayant d'imaginer le nombre de problèmes de sommeil dans chaque nouvelle implémentation.
En général, si vous êtes capable d'appeler ce démon, subordonné uniquement aux initiés, et que vous êtes prêt à le supporter dans votre code, l'épissage est une approche complètement fonctionnelle pour intercepter les appels de fonction. J'avais une attitude négative à l'égard de l'écriture de vélos, donc cette option est restée une sauvegarde pour nous au cas où il n'y aurait aucun progrès avec des solutions toutes faites plus faciles.
Nouvelle approche avec ftrace
Ftrace est un framework de traçage du noyau au niveau de la fonction. Il a été développé depuis 2008 et possède une interface fantastique pour les programmes utilisateur. Ftrace vous permet de suivre la fréquence et la durée des appels de fonction, d'afficher les graphiques des appels, de filtrer les fonctions d'intérêt par modèle, etc. Vous pouvez commencer à lire sur les fonctionnalités
de ftrace à
partir d'ici , puis suivre les liens et la documentation officielle.
Il implémente ftrace basé sur les clés de compilateur
-pg et
-mfentry , qui insèrent l'appel à la fonction de trace spéciale mcount () ou __fentry __ () au début de chaque fonction. En général, dans les programmes utilisateur, cette fonction de compilation est utilisée par les profileurs pour suivre les appels à toutes les fonctions. Le noyau utilise ces fonctions pour implémenter le framework ftrace.
Bien sûr, appeler ftrace à partir de
chaque fonction n'est pas bon marché, donc l'optimisation est disponible pour les architectures populaires:
ftrace dynamique . L'essentiel est que le noyau connaisse l'emplacement de tous les appels à mcount () ou __fentry __ () et dans les premières étapes du chargement remplace leur code machine par
nop - une instruction spéciale qui ne fait rien. Lorsque le traçage est inclus dans les fonctions requises, les appels ftrace sont rajoutés. Ainsi, si ftrace n'est pas utilisé, son impact sur le système est minime.
Description des fonctions requises
Chaque fonction interceptée peut être décrite par la structure suivante:
struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; };
L'utilisateur doit remplir uniquement les trois premiers champs: nom, fonction, original. Les champs restants sont considérés comme un détail d'implémentation. La description de toutes les fonctions interceptées peut être assemblée dans un tableau et des macros peuvent être utilisées pour augmenter la compacité du code:
#define HOOK(_name, _function, _original) \ { \ .name = (_name), \ .function = (_function), \ .original = (_original), \ } static struct ftrace_hook hooked_functions[] = { HOOK("sys_clone", fh_sys_clone, &real_sys_clone), HOOK("sys_execve", fh_sys_execve, &real_sys_execve), };
Les wrappers sur les fonctions interceptées sont les suivants:
static asmlinkage long (*real_sys_execve)(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp); static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
Comme vous pouvez le voir, les fonctions interceptées avec un minimum de code supplémentaire. La seule chose nécessitant une attention particulière est la signature des fonctions. Ils doivent correspondre un à un. Sans cela, évidemment, les arguments seront mal passés et tout ira en descendant. Pour intercepter les appels système, cela est moins important, car leurs gestionnaires sont très stables et, pour plus d'efficacité, prennent les arguments dans le même ordre que le système les appelle eux-mêmes. Cependant, si vous prévoyez d'intercepter d'autres fonctions, vous devez vous rappeler qu'il
n'y a pas d'interfaces stables à l'intérieur du noyau .
Initialisation de Ftrace
Tout d'abord, nous devons trouver et enregistrer l'adresse de la fonction que nous allons intercepter. Ftrace vous permet de tracer les fonctions par leur nom, mais nous avons encore besoin de connaître l'adresse de la fonction d'origine pour l'appeler.
Vous pouvez obtenir l'adresse en utilisant
kallsymes - une liste de tous les caractères du noyau. Cette liste comprend
tous les caractères, non seulement exportés pour les modules. Obtenir l'adresse de la fonction hookée ressemble à ceci:
static int resolve_hook_address(struct ftrace_hook *hook) { hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { pr_debug("unresolved symbol: %s\n", hook->name); return -ENOENT; } *((unsigned long*) hook->original) = hook->address; return 0; }
Ensuite, vous devez initialiser la structure
ftrace_ops . C'est contraignant
le champ est juste
func , indiquant un rappel, mais nous avons aussi besoin
définir des indicateurs importants:
int fh_install_hook(struct ftrace_hook *hook) { int err; err = resolve_hook_address(hook); if (err) return err; hook->ops.func = fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_IPMODIFY; }
fh_ftrace_thunk () est notre rappel que ftrace appellera lors du traçage d'une fonction. À propos de lui plus tard. Les drapeaux que nous avons mis seront nécessaires pour terminer l'interception. Ils demandent à ftrace de sauvegarder et de restaurer les registres du processeur, dont nous pouvons changer le contenu lors du rappel.
Nous sommes maintenant prêts à activer l'interception. Pour ce faire, vous devez d'abord activer ftrace pour la fonction qui nous intéresse en utilisant ftrace_set_filter_ip (), puis autoriser ftrace à appeler notre rappel en utilisant register_ftrace_function ():
int fh_install_hook(struct ftrace_hook *hook) { err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if (err) { pr_debug("register_ftrace_function() failed: %d\n", err); ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); return err; } return 0; }
L'interception est désactivée de la même manière, uniquement dans l'ordre inverse:
void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if (err) { pr_debug("unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); } }
Une fois l'appel à unregister_ftrace_function () terminé, l'absence d'activation du rappel installé dans le système (et avec lui nos wrappers) est garantie. Par conséquent, nous pouvons, par exemple, décharger le module d'intercepteur en toute sécurité, sans craindre que quelque part dans le système nos fonctions soient toujours exécutées (car si elles disparaissent, le processeur sera bouleversé).
Exécution d'un hook de fonction
Comment l'interception est-elle réellement réalisée? Très simple. Ftrace vous permet de changer l'état des registres après avoir quitté un rappel. En modifiant le registre% rip - un pointeur sur la prochaine instruction exécutable - nous modifions les instructions que le processeur exécute - c'est-à-dire que nous pouvons le forcer à exécuter une transition inconditionnelle de la fonction actuelle vers la nôtre. Ainsi nous prenons le contrôle.
Le rappel pour ftrace est le suivant:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); regs->ip = (unsigned long) hook->function; }
En utilisant la macro container_of (), nous obtenons l'adresse de notre
struct ftrace_hook à l'adresse de la
struct ftrace_hook incorporée, après quoi nous remplaçons la valeur du registre% rip dans la
struct pt_regs par l'adresse de notre gestionnaire. C’est tout. Pour les architectures autres que x86_64, ce registre peut être appelé différemment (comme IP ou PC), mais l'idée leur est en principe applicable.
Notez le
qualificatif notrace ajouté pour le rappel. Ils peuvent signaler les entités dont le suivi n'est pas autorisé à l'aide de ftrace. Par exemple, c'est ainsi que les fonctions de ftrace elle-même qui sont impliquées dans le processus de trace sont marquées. Cela aide à empêcher le système de geler dans une boucle sans fin lors du traçage de toutes les fonctions dans le noyau (ftrace peut le faire).
Le rappel ftback appelle généralement avec l'extrusion désactivée (comme kprobes). Il peut y avoir des exceptions, mais vous ne devez pas vous y fier. Dans notre cas, cependant, cette restriction n'est pas importante, nous remplaçons donc seulement huit octets dans la structure.
La fonction wrapper, qui sera appelée ultérieurement, s'exécutera dans le même contexte que la fonction d'origine. Par conséquent, là, vous pouvez faire ce qui est autorisé à être fait dans la fonction interceptée. Par exemple, si vous interceptez un gestionnaire d'interruption, vous ne pouvez toujours pas dormir dans un wrapper.
Protection d'appel récursive
: , ftrace, , . - .
, —
parent_ip — ftrace-, , . . , .
,
parent_ip , — - . , .
, ( ). , . .
, ftrace- :
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); if (!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; }
/ :
- . . , , .
- . . , .
- . kretprobes , ( ). , .
:
ls , . (, Bash)
fork () +
execve () .
clone() execve() . , execve(), .
- :
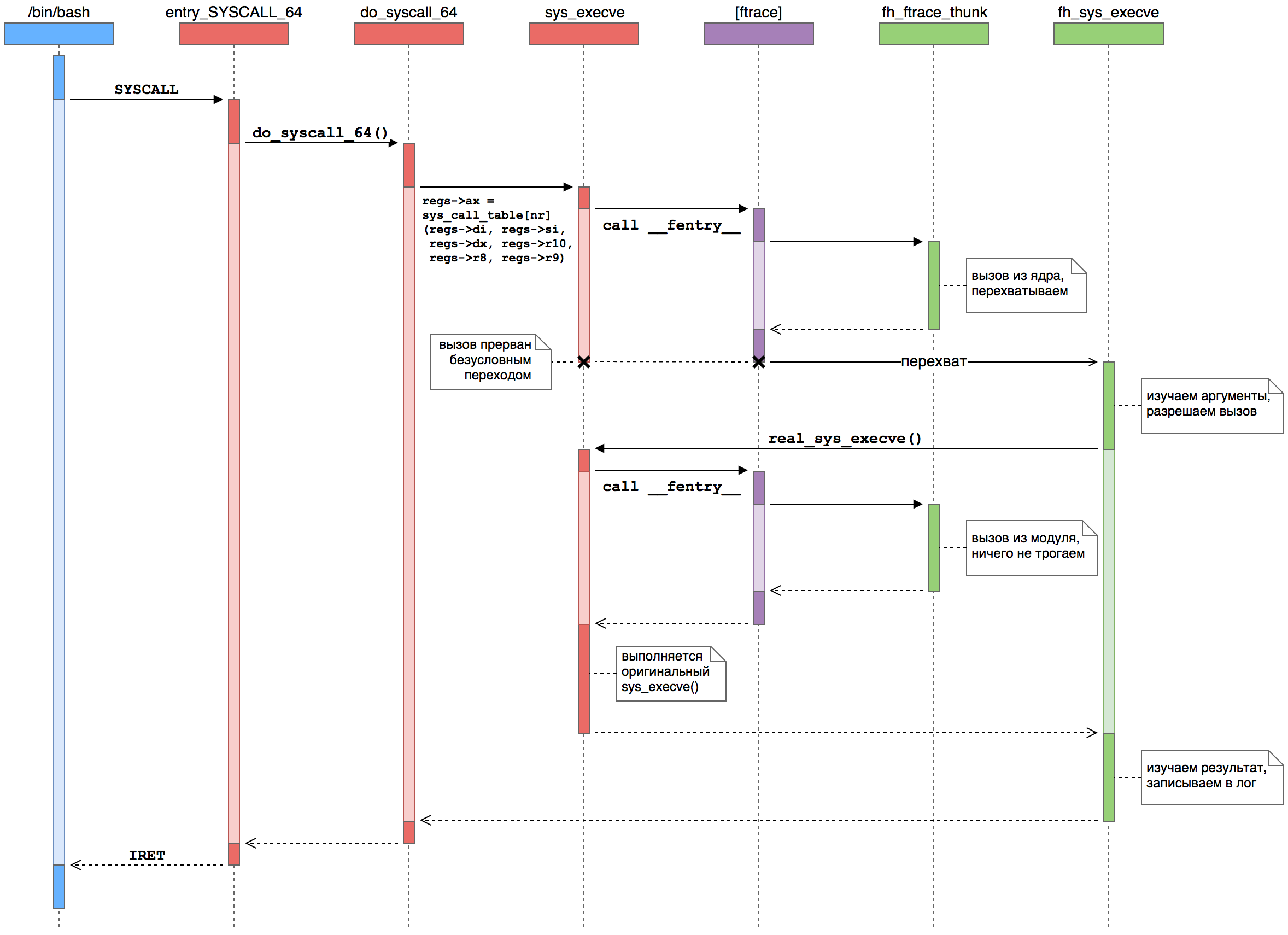
, (
) (
), ftrace (
) (
).
- SYSCALL. — entry_SYSCALL_64 (). 64- 64- .
- . , , do_syscall_64 (), .
sys_call_table — sys_execve ().
- ftrace. __fentry__ (), ftrace. , , nop , sys_execve() .
- Ftrace . ftrace , . , %rip, .
- .
parent_ip , do_syscall_64() — sys_execve() — , %rip pt_regs .
- Ftrace . FTRACE_SAVE_REGS, ftrace
pt_regs . ftrace . %rip — — .
- -. - sys_execve() . fh_sys_execve (). , do_syscall_64().
- . . fh_sys_execve() ( ) . . — sys_execve() , real_sys_execve , .
- . sys_execve(), ftrace . , -…
- . sys_execve() fh_sys_execve(), do_syscall_64(). sys_execve() . : ftrace sys_execve() .
- . sys_execve() fh_sys_execve(). . , execve() , , , . .
- . fh_sys_execve() do_syscall_64(), , . .
- . IRET ( SYSRET, execve() — IRET), . ( ) .
, :
- API . . , , . — -, .
- . . - , , , - . ( ), .
- . , ftrace, . kprobes ftrace.
?
- . ftrace :
. , , , , . , - , .
- ftrace , kprobes ( ftrace ), , , . , ftrace — , «» ftrace .
- . , . , , ftrace . , , .
- ftrace.
parent_ip ftrace . , . , : ftrace , 5 ( call), ftrace .
.
, ftrace kallsyms. :
- CONFIG_FTRACE
- CONFIG_KALLSYMS
, ftrace .
- CONFIG_DYNAMIC_FTRACE_WITH_REGS
,
3.19 , FTRACE_OPS_FL_IPMODIFY. %rip, 3.19 . , — .
, ftrace : , ( ).
x86_64 , i386 — . - i386 ftrace , ftrace . %eip — , , .
ftrace 32- x86. , ( «»), , ftrace.
: . , , . , .
, . - ftrace-
parent_ip . - , ftrace , - .
, , , . , -.
:
static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
— :
static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_devel("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_devel("execve() returns: %ld\n", ret); return ret; }
, ? , . - , .
, , , pr_devel() . printk- . , , DEBUG. :
static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { return real_sys_execve(filename, argv, envp); }
.
(tail call optimization). , . :
0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: ff 15 00 00 00 00 callq *0x0(%rip) b: f3 c3 repz retq
— :
0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax c: ff e0 jmpq *%rax
CALL — __fentry__(), . real_sys_execve ( ) CALL fh_sys_execve() RET. real_sys_execve() JMP.
«» , , CALL. , —
parent_ip . fh_sys_execve() , — .
parent_ip , .
, . . .
-:
#pragma GCC optimize("-fno-optimize-sibling-calls")
Conclusion
… Linux — . , - , .
,
Github .