Salut, nom d'utilisateur! Chaque jour, nous sommes confrontés à une recherche de données diverses. Presque tous les sites Web contenant de nombreuses informations ont désormais une recherche. La recherche se fait dans les ordinateurs personnels, dans les téléphones portables, dans divers types de logiciels. Bien sûr, si vous interrogez un développeur sur la recherche en termes de technologie, elasticsearch, lucene ou sphinx vous viendra immédiatement à l'esprit. Aujourd'hui, je veux regarder avec vous «sous le capot» d'une recherche en texte intégral et trouver une première approximation de son fonctionnement, en utilisant hh.ru comme exemple.
 Avertissement: cet article n'est pas le seul vrai point de vue et ne sert que de point d'introduction pour une introduction initiale au travail de recherche de texte et quelques options pour la mise en œuvre de ses différentes parties.
Avertissement: cet article n'est pas le seul vrai point de vue et ne sert que de point d'introduction pour une introduction initiale au travail de recherche de texte et quelques options pour la mise en œuvre de ses différentes parties.Si vous regardez les détails de la recherche, en plus de la partie évidente sous la forme d'une chaîne de recherche, vous pouvez en voir beaucoup plus:
- indice (elle suggère)
- compteur de résultats de recherche (compteur),
- différents types de tri (tri),
- facettes - caractéristiques groupées des documents, par exemple, le métro sur lequel se trouve une vacance, remplissant également la fonction de filtres (filtres),
- synonymes
- pagination
- snippet (snippet) - une petite description du document dans l'émission,
- etc.

Et tout cela sert un seul objectif - satisfaire le besoin de l'utilisateur de trouver les bonnes informations aussi rapidement et de manière pertinente que possible. Par exemple, le filtrage est important pour affiner les résultats de recherche, dans notre cas, il peut s'agir d'un filtre par expérience, emplacement ou emploi du candidat. Les facettes sont utiles pour afficher le nombre de postes vacants dans chaque tranche de salaire. Il est également important de compléter les requêtes et les documents par des synonymes afin qu'à la demande du «développeur Java», ils puissent trouver des documents «Développeur Java».
En plus de la recherche elle-même, il y a toujours beaucoup de composants qui facilitent la vie de l'utilisateur: un tuteur qui est responsable de la correction des erreurs, ou un sajest qui invite des requêtes plus appropriées lorsque vous interagissez avec la barre de recherche. Dans certains cas, il est important de pouvoir reformuler la demande. Par exemple, déplacez une partie de la demande vers des filtres: à partir de la demande «programmeur de Moscou», Moscou peut être retiré dans le filtre par ville.
1. Basique
Maintenant au point. La recherche elle-même est divisée en deux grandes étapes:
- indexation (traitement des documents et mise en page selon des structures d'index particulières, pour que vous puissiez ensuite effectuer rapidement la recherche elle-même),
- recherche (application de filtres, recherche booléenne, classement, etc.).
1.1. Indexation
Une légère digression lyrique. Je présenterai plus loin le concept de terme - car il est d'usage d'appeler l'unité minimale d'indexation et de requête. C'est l'unité même qui sera stockée dans le dictionnaire d'index. Il peut s'agir d'un mot réduit à sa forme ou base de mot normale, à son numéro, à son adresse électronique, à sa lettre n-grammes ou à autre chose. En règle générale, un terme comprend un champ dans lequel il est indexé ou dans lequel une recherche est effectuée.
Tout d'abord, vous devez transformer les documents d'entrée en un ensemble de termes et filtrer les mots vides. Ils peuvent être comme des mots fréquents - prépositions, conjonctions, interjections et autres choses, par exemple, des caractères spéciaux que nous ne voulons pas rechercher. Pour que la recherche fonctionne avec différentes formes de mots, au cours du processus d'indexation, nous amenons généralement tous les mots à un état de base. Habituellement, l'une des deux procédures est utilisée: soit la racine - le processus d'isolement de la base d'un mot (développement -> développement), soit la lemmatisation - le processus de mise en forme normale d'un mot (compétences -> compétences).
1.2 Structures d'index
La façon la plus courante de représenter un index est un index inversé. En fait, il s'agit d'une sorte de table de hachage, où la clé est un terme, et la valeur est une liste de documents (généralement une liste d'ID de document appelée liste de publications) dans laquelle ce terme est présent. Habituellement, un index inversé se compose de deux parties - un dictionnaire (dictionnaire de termes) et des listes de documents pour chaque terme (liste de publication):

De plus, l'index peut contenir des informations sur les positions des termes dans le document (indice de position), qui seront utiles lors de la recherche de termes à une certaine distance, en particulier avec des requêtes phrasales, sur la fréquence des termes, ce qui aidera à classer et à construire un plan de requête. Mais plus à ce sujet ci-dessous.
1.2.1 Dictionnaire des termes
Le dictionnaire stocke tous les termes qui existent dans l'index et est conçu pour trouver rapidement des liens vers une liste de documents. Il existe plusieurs options pour stocker un dictionnaire:
- Une table de hachage, où le terme est la clé et la valeur est un lien vers une liste de documents de ce terme.
- Une liste ordonnée par laquelle vous pouvez effectuer une recherche par recherche binaire.
- Arbre de préfixe (trie).
Le moyen le plus optimal est la dernière option, car Elle présente plusieurs avantages. Premièrement, sur un grand nombre de termes, l'arbre des préfixes occupera beaucoup moins de mémoire, car les parties répétées des préfixes ne seront stockées qu'une seule fois. Deuxièmement, nous avons immédiatement la possibilité de faire des demandes de préfixe. Et troisièmement, un tel arbre peut être compressé en combinant des parties non ramifiées.
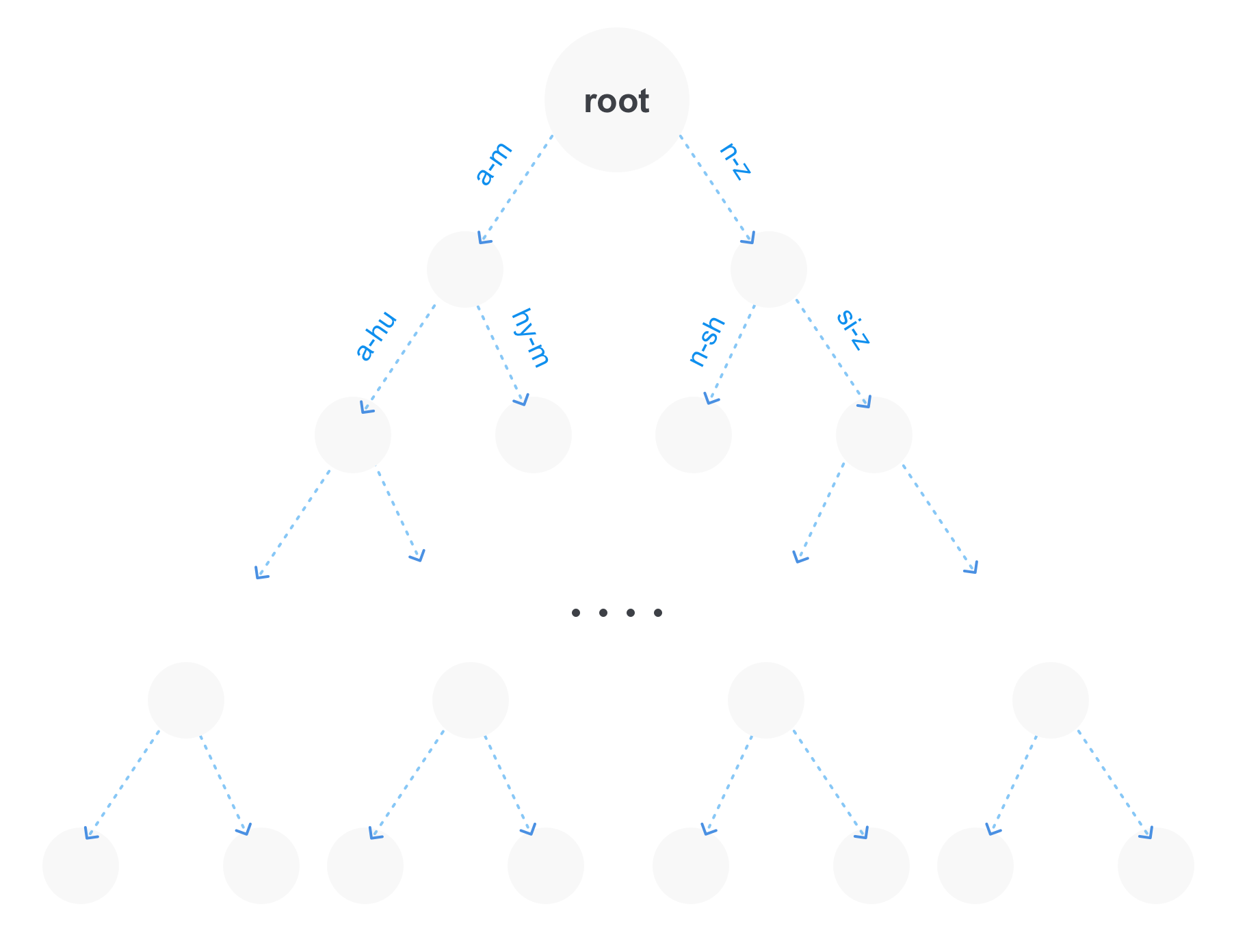
Bien sûr, un arbre de préfixe peut ne pas être la seule structure pour stocker des termes dans un index. Par exemple, un arbre de suffixes peut également être à proximité, ce qui à son tour sera plus optimal pour les requêtes avec jokers (requêtes de la forme po * sql).
1.2.2 Liste de diffusion
La liste des documents est une liste ordonnée d'identifiants de documents, qui permet de faire quelques optimisations avec elle. Habituellement, il stocke en lui-même non seulement une liste de documents dans lesquels le terme apparaît, mais aussi les positions (publications) auxquelles il se produit. Cela résout plusieurs problèmes à la fois: nous savons immédiatement combien de fois un mot apparaît dans un document, nous pouvons faire des phrases et des requêtes avec une certaine distance entre les termes, traverser plusieurs listes de documents à la fois et regarder les positions des termes.

Par exemple, dans cette liste par le terme
scala dans le 6ème document du
titre, le mot apparaît 4 fois, aux positions 2, 15, 18 et 25.
1.2.3 Documents avec plusieurs champs
La plupart du document se compose de plusieurs champs, au moins à partir du nom du document et de son corps. Cela aide lors de la recherche de parties individuelles du document et lorsque le terme est significatif lors du classement (par exemple, le terme apparaissant dans le titre peut être considéré comme plus significatif).
De plus, dans l'index, généralement non seulement les champs de texte sont stockés, mais aussi les signes de documents, certaines valeurs numériques, etc. Le stockage dans l'index prend généralement la forme de {champ-terme}.

Par exemple, si vous prenez un poste vacant, alors il aura plusieurs champs à la fois: nom, description, entreprise, paie, ville et l'expérience nécessaire. Cela est nécessaire pour que l'utilisateur puisse rechercher facilement non seulement par le nom et le texte de l'entreprise, mais aussi filtrer par salaire et expérience, voir combien de postes vacants sont dans sa ville et dans les villes voisines, ou même rechercher des postes vacants pour une entreprise particulière.
1.3 Compression et optimisation d'index
La vitesse de travail est importante pour la recherche, par conséquent, la plupart des opérations de recherche d'index sont généralement effectuées dans la RAM. Pour ce faire, il est très important d'appliquer un certain nombre d'optimisations à l'index, qui l'adapteront à une taille de mémoire limitée. En plus de cela, un certain nombre d'optimisations sont généralement appliquées, ce qui vous permet de vous déplacer autour de l'index à une vitesse plus élevée lors de la recherche, en ignorant les éléments inutiles.
1.3.1 Compression Delta
Comme nous nous souvenons que la liste des documents par terme (aka liste des publications) est ordonnée, la première idée de la façon de la compresser est de créer une liste avec les décalages d'ID au lieu de la liste avec l'ID du document par rapport aux précédents. Sur une liste spécifique de 6 identifiants, cela ressemblera à ceci:

Ainsi, en parcourant la liste, nous calculerons toujours l'identifiant actuel à partir de la valeur précédente obtenue. Par exemple, au deuxième décalage 3, nous ajoutons la première valeur 2 et obtenons l'id 5, au troisième 4 nous ajoutons 5, et obtenons 9 et ainsi de suite. Avec un grand nombre de documents, cela fonctionne très bien, en particulier en conjonction avec une autre méthode de compression - l'enregistrement de nombres au format variable.
1.3.2 VarByte et VarInt
Il s'agit d'un moyen de stocker chaque élément de liste individuel en mémoire afin qu'il occupe le minimum d'espace. Par exemple, si les trois premiers décalages ne tiennent que sur 1 octet, il n'est pas nécessaire d'en prendre plus. Étant donné que notre liste ne contient pas de documents d'identité, mais des deltas, la compression sera très efficace. Dans cette représentation des nombres, le premier bit de chaque octet est le drapeau indiquant si la représentation du numéro courant se termine sur cet octet.

Si le premier bit de l'octet 0 est alors le dernier octet du nombre, si 1 ne l'est pas.
1.3.3 Sauter la liste / Sauter la table
Une liste de sauts est l'une des structures permettant de parcourir rapidement une liste de documents d'un certain terme, en sautant une partie inutile de la liste. L'idée est de stocker des liens vers des éléments distants de la liste sur le disque en face de la liste elle-même, car après la compression, nous ne pouvons pas dire exactement où le document 100 ou 200 sera situé. Par exemple, cela est pratique lorsqu'il y a une requête de deux termes, où un terme sera fréquemment trouvé, et le second, au contraire, sera rare, et la liste des documents ne commencera qu'avec le 200e identifiant du document. Ensuite, s'il existe une liste avec des passes pour la première liste, nous pouvons gagner du temps sur le déplacement et ignorer immédiatement le bloc d'identifiants inutiles.

1.4 Demandes
1.4.0 Requête de terme
Le type de demande le plus simple dans lequel il suffit de trouver la liste appropriée des documents et d'émettre des documents triés après classement.
Par exemple, de cette façon, nous trouvons une liste de positions pour
java :

1.4.1 Requêtes booléennes (et, ou, non)
La recherche booléenne est l'une des parties les plus importantes de la recherche d'informations que nous trouvons partout. La recherche booléenne entière est basée sur une combinaison de ET, OU et NON. Par exemple, lorsque nous recherchons une requête en deux mots:
java android , puis en fait, dans une recherche simple, elle sera convertie en
java AND android . Et cela signifie que nous voulons trouver tous les documents qui contiennent les deux mots.
Il convient de mentionner tout de suite comment vous vous déplacez dans la liste des documents. Étant donné que les listes de documents pour chaque terme sont triées, il existe généralement deux façons de parcourir les listes: parcourir les documents de manière séquentielle, en les passant un par un, ou passer immédiatement à un document spécifique, en ignorant ceux qui ne sont pas nécessaires (par exemple, lorsque la première liste est beaucoup plus petite) , et nous n'avons pas besoin de parcourir un grand bloc de documents dans la deuxième liste). Dans ce cas, nous utilisons d'abord le pointeur des pointeurs de saut pour que la deuxième liste se rapproche le plus possible de l'ID de document souhaité, puis nous y déplaçons linéairement.
Au moment de la recherche, les événements suivants se produisent: dans l'index des termes java et android sont des listes de documents, puis une intersection est faite sur eux - c'est-à-dire que nous trouvons des documents qui contiennent les deux termes. Avec cette recherche, les deux méthodes de déplacement dans les listes sont utilisées pour un croisement plus rapide.

Avec les requêtes OR du formulaire java OR scala, où nous devons trouver tous les documents contenant au moins un des termes, la situation est différente - ici, nous n'avons pas besoin que le terme soit dans toutes les listes de documents à la fois. Mais il existe des requêtes avec plusieurs opérateurs OR, puis la condition pour un nombre minimum de correspondances peut se produire, par exemple, il peut y avoir une requête java OU scala OU cotlin OU clojure avec au moins deux correspondances, puis nous devons afficher tous les documents qui contiennent au moins deux mots de la requête .
Dans ce cas, le tas fonctionne plus efficacement. Nous pouvons y stocker des liens vers les itérateurs de chacune des listes et obtenir l'élément minimum pour un temps constant. Après avoir pris l'élément minimum, nous supprimons l'itérateur du tas, faisons un pas en avant et l'ajoutons à nouveau au tas. Vous pouvez stocker séparément le candidat actuel à ajouter au résultat et au compteur, combien de fois il s'est rencontré et au moment où le candidat différera de l'élément minimum dans le tas, voyez si nous passons par le nombre minimum de correspondances dans l'opération. Et soit ajouter à la liste finale des résultats, soit jeter le document.
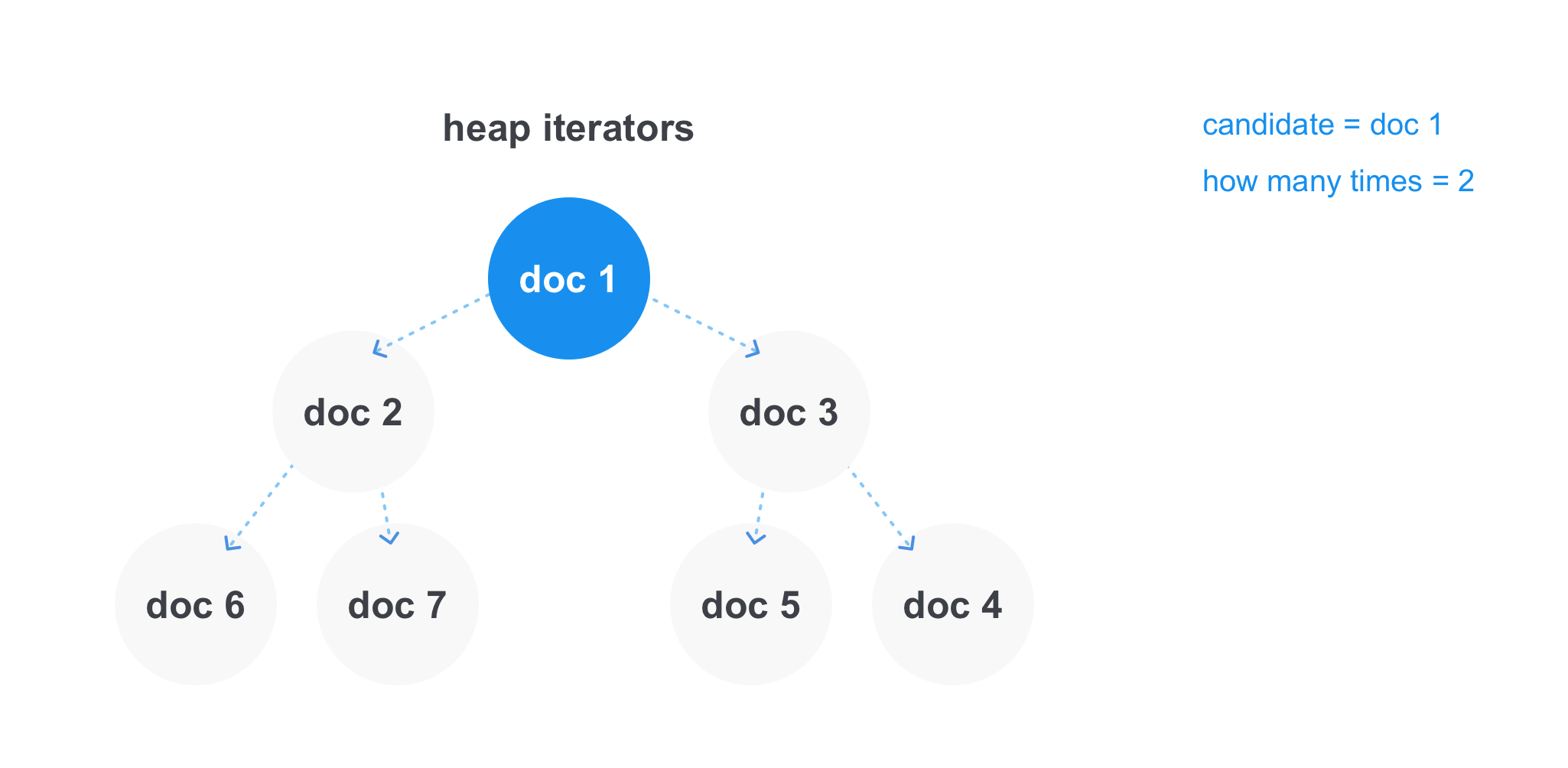
1.4.2 Préfixe / Jokers
Parfois, nous voulons trouver tous les documents qui contiennent un mot qui commence par un préfixe spécifique. Dans de tels cas, la demande de préfixe nous aidera, qui ressemblera à
jav * . Une demande de préfixe fonctionne très bien lorsque le dictionnaire est implémenté sur une arborescence de préfixes, puis nous arrivons à l'imbrication du préfixe et prenons tous les termes qui se trouvent ci-dessous.
1.4.3 Requêtes sur des phrases et requête proche
Il y a des moments où vous devez trouver la phrase entière, par exemple, "développeur Java", ou trouver des mots entre lesquels il n'y aura pas plus de quelques mots, par exemple, "Java" et "développeur", entre lesquels pas plus de 2 mots, afin que vous puissiez trouver documents contenant java android kotlin developer. Pour cela, des listes de positions de mots dans chaque document sont également utilisées.

Au moment de traverser les listes de documents, tout est identique à l'opération ET. Mais une fois le document trouvé dans les deux listes, une vérification supplémentaire est effectuée - que les termes sont à la bonne distance l'un de l'autre, par la différence de position (position).
1.4.4 Plan de demande
Habituellement, avant l'exécution de la demande elle-même, son plan est construit. Cela se produit afin d'optimiser l'exécution de la demande et de faire fonctionner des optimisations telles qu'une liste avec omissions pour la liste des documents.
Le moyen le plus simple d'optimiser votre requête est de parcourir les listes de documents par ordre croissant de taille. Ainsi, nous ne gaspillerons pas le gaspillage de documents de grandes listes qui ne sont pas dans de petites listes.
Par exemple,
analysons la requête android AND java AND sql . Disons qu'il y a 10 documents dans la liste android, en sql - 20, et en java - 100. Dans ce cas, il est préférable de traverser d'abord les plus petites listes, et la requête optimisée ressemblera à
(android AND sql) AND java .
Dans le cas de OR, le plus simple est de compter le nombre de documents à l'intersection comme la somme de deux listes potentiellement intersectées.
1.4.5 Extension de requête - Synonymes
En plus de ce que l'utilisateur entre dans la barre de recherche, la recherche essaie généralement d'étendre la requête elle-même pour trouver des documents plus pertinents. Beaucoup peut être utilisé pour étendre la recherche: l'historique des requêtes de l'utilisateur, certaines données personnalisées le concernant, etc. Mais en plus de tout cela, il existe également un moyen universel d'élargir la demande - les synonymes.
Dans ce cas, lors de l'écriture de documents dans l'index, le terme est remplacé par un «lien» dans le dictionnaire des synonymes:
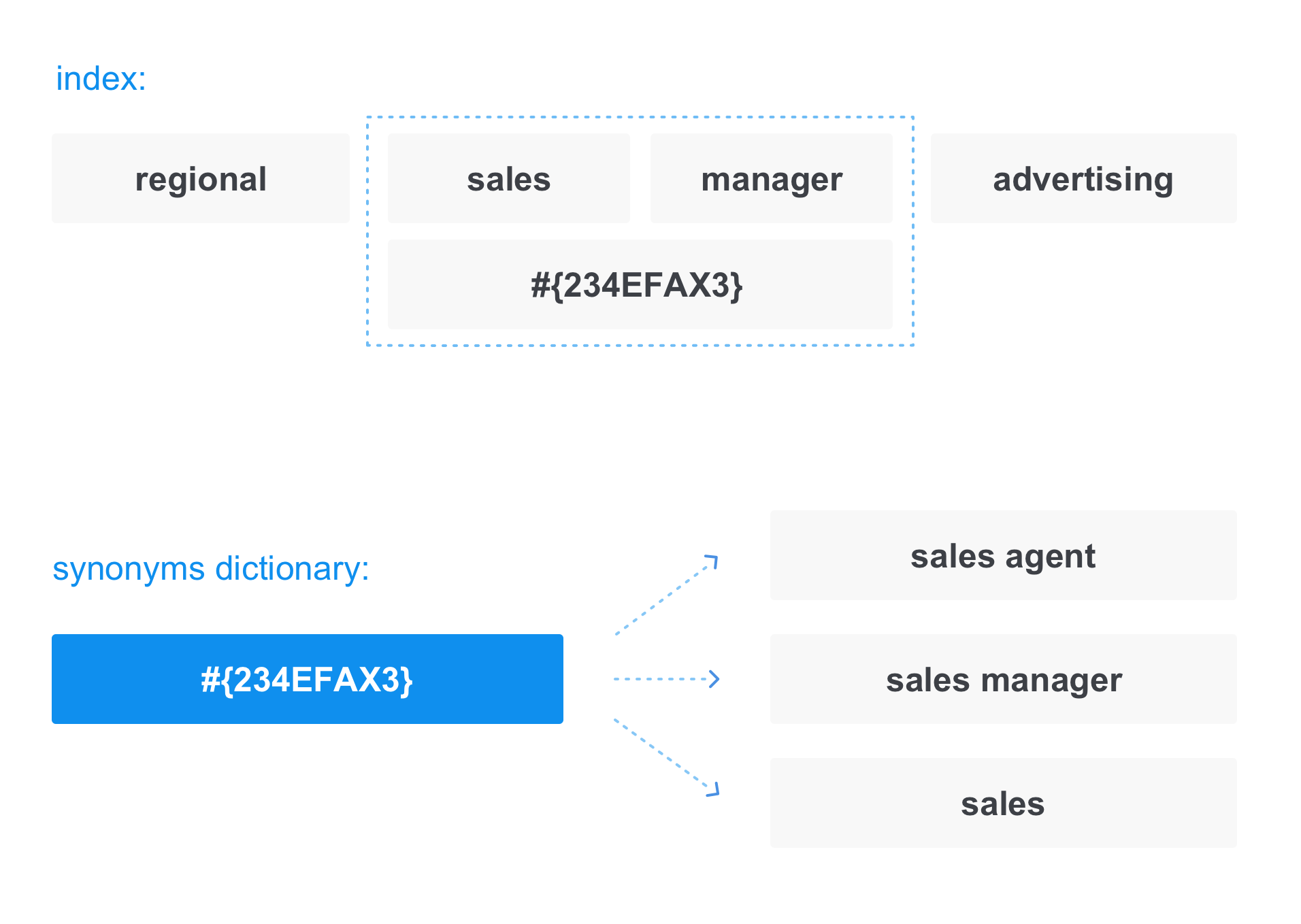
La même chose se produit lors de la conversion d'une demande. Par exemple, lorsque nous demandons un
directeur des ventes , la demande ressemble en fait à:

Ainsi, dans la réponse, nous recevrons non seulement les documents qui contiennent le directeur des ventes, mais aussi ceux qui contiennent l'agent de vente et les ventes.
1.5 Filtrage
1.5.1 Filtre à plage rapide
Parfois, nous voulons filtrer quelque chose par une gamme de valeurs, par exemple, par l'expérience des années. Supposons que nous voulons trouver tous les postes vacants avec l'expérience requise de 3 à 11 ans. La première décision est de faire une demande avec toutes les options de la gamme, en les combinant via OR. Mais le problème est qu'il peut y avoir trop de valeurs. Une façon de résoudre ce problème consiste à enregistrer la valeur avec plusieurs précisions à la fois:

Dans ce cas, nous enregistrerons 5 valeurs de précision: un an (nous considérerons cela comme la valeur initiale), deux, quatre, huit et seize.
Ensuite, lors de l'enregistrement, les événements suivants se produiront: par exemple, lors de l'enregistrement d'un document avec une exigence d'expérience de 6 ans, nous enregistrons immédiatement la valeur en toute précision:

Lors du filtrage «de 3 à 11 ans», il se produit ce qui suit: nous sélectionnons uniquement les valeurs dont nous avons besoin avec la précision requise, et nous n'obtenons que 3 valeurs au lieu de 8 et nous obtenons la requête
(valeur réelle == 3) OU (précision 4 == 4) OU (précision 4 == 8)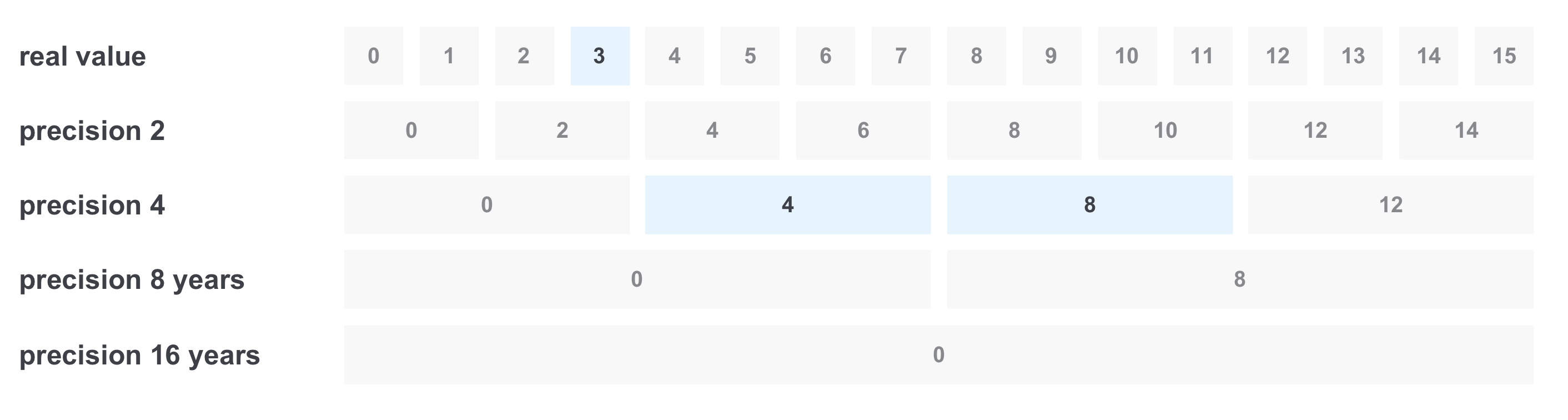
1.5.2 Masques de bits
Les masques de bits font partie intégrante d'un index. L'utilisation la plus importante est le filtrage des documents supprimés. Lorsque vous supprimez un document de l'index, la suppression physique ne se produit pas immédiatement. Une structure spéciale est écrite à côté de l'index, où chaque bit signifie l'id du document dans l'index, et lorsqu'il est supprimé, un bit est levé et lors de la recherche, ces documents sont filtrés et ne tombent pas dans la sortie.
Vous pouvez également utiliser des masques de bits pour définir des autorisations pour chaque utilisateur sur certains documents et pour mettre en cache des filtres populaires individuels. Ensuite, les masques de bits sont généralement stockés séparément de l'index.
Par exemple, nous avons des filtres populaires: la ville de Moscou, uniquement à temps partiel, sans expérience de travail. Ensuite, avant la demande, nous pouvons obtenir les masques de bits déjà enregistrés pour ces documents, les ajouter et obtenir le masque de bits final - quels documents passent par ces trois filtres, ce qui permet de gagner du temps sur le filtrage.

2. Classement
Comme nous nous en souvenons, la tâche principale de la recherche est d'obtenir les informations les plus pertinentes en un minimum de temps. Et en cela, nous serons aidés par le classement des documents après avoir filtré les documents par requête de texte et appliqué les filtres et les droits nécessaires.
Le moyen le plus simple et le moins cher de faire un classement est de simplement trier les documents par date. Dans certains systèmes, cela se faisait auparavant, par exemple, dans les actualités ou dans les annonces immobilières, de sorte que l'utilisateur a d'abord été informé des derniers documents.
Parfois, un modèle de classement par le nombre de mots trouvés dans un document peut être utilisé, par exemple, quand il n'y a pas autant de documents, et nous voulons trouver tous les documents dans lesquels au moins un des mots de la requête est trouvé. Dans ce cas, les documents dans lesquels tous les mots de la requête ou plusieurs d'entre eux sont trouvés seront plus pertinents.
Bien sûr, à l'heure actuelle, ces méthodes sont déjà devenues sans objet, et elles peuvent plus probablement être attribuées à l'histoire du problème.
2.1 TF-IDF
TF-IDF (terme fréquence - fréquence inverse des documents) est l'une des formules de classement les plus élémentaires et les plus utilisées. L'essence de la formule est de réduire les termes utilisés partout, par exemple, les prépositions et les interjections, et de rendre les termes plus significatifs qui sont rares, montrant ainsi les premiers documents avec des termes plus rares et plus significatifs de la requête. Maintenant, décomposons la formule en plusieurs parties:
TF (terme fréquence) est la fréquence du terme apparaissant dans le document. Il est calculé simplement:
TF terme `java` = nombre de termes` java` dans le document / nombre de tous les termes dans le document
IDF (fréquence de document inverse) - l'inverse de la fréquence à laquelle le mot apparaît dans la collection de documents. Aide à réduire le poids des mots couramment utilisés.
IDF (`java`) = log (nombre de documents dans la collection / nombre de documents dans lesquels le terme` java` apparaît)De plus, pour obtenir le TF-IDF du terme java, il suffit de multiplier les valeurs TF et IDF obtenues. , , . , , developer , , java developer .
2.2
, , . , , , .
2.3 BM25 BM*
BM25 (Okapi best match 25) TF-IDF . BM25F, ( ).
2.4
, :
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5
, , . ,
.
2.6 Top k
, . , , .
, .
top k .
— . k, k
* . heap. n*log(n) k.
. , , , 10 12, score 10 score . , n — (n*page size) .
3.
3.1
— . , .
, : , , . , . . ( , ). (merge).
, , :

. , , , - .
3.2 (megre)
— . «» — . , , ( ).

, , , . :
4.
, , . , - (, . .). , , , .

4.1
(, hh , ), . .
, , . -, , . -, , , .
4.2
, . , .
, hh,
, , - :
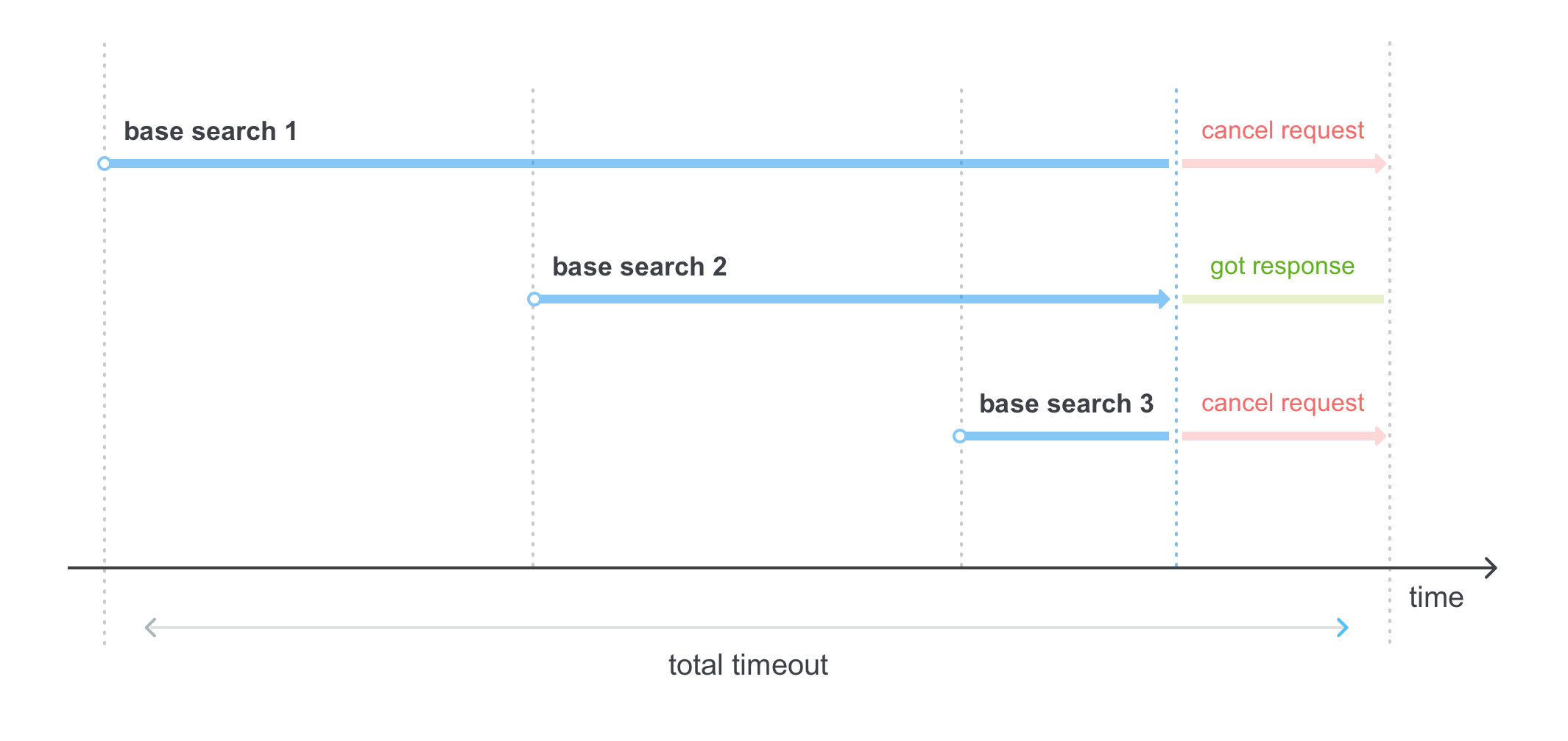
5. …
, , , . , : , , , , , (highlight), . , , , top k .
:
C'est tout, merci à tous pour votre attention, il est intéressant d'entendre vos commentaires et vos questions.PS
Je voudrais exprimer ma gratitude à gdanschin pour m'avoir aidé à écrire cet article.