Le système
anti-plagiat est un moteur de recherche spécialisé. Comme il sied à un moteur de recherche, avec son propre moteur et ses propres index de recherche. Notre indice le plus important en termes de nombre de sources est, bien sûr, dans l'Internet en langue russe. Il y a très longtemps, nous avons décidé de mettre dans cet index tout ce qui est du texte (et non une image, de la musique ou une vidéo), est écrit en russe, a une taille supérieure à 1 ko et n'est pas un "presque double" de quelque chose qui déjà dans l'index.
Cette approche est bonne car elle ne nécessite pas de prétraitement compliqué et minimise les risques de «éclabousser avec l’eau de l’enfant» - en sautant un document dont le texte peut potentiellement être emprunté. D'un autre côté, par conséquent, nous savons peu quels documents se trouvent finalement dans l'index.
Alors que l'index Internet augmente - et maintenant, pendant une seconde, il compte déjà plus de 300 millions de documents
en russe seulement - une question tout à fait naturelle se pose: y a-t-il beaucoup de documents vraiment utiles dans ce dépotoir?
Et puisque nous (
yury_chekhovich et
Andrey_Khazov )
avons repris cette réflexion, alors pourquoi ne répondons-nous pas en même temps à quelques autres questions. Combien de documents scientifiques sont indexés et combien non scientifiques? Quelle est la part des articles scientifiques parmi les diplômes, articles, résumés? Quelle est la répartition des documents par sujet?

Puisqu'il s'agit de centaines de millions de documents, il est nécessaire d'utiliser des moyens d'analyse automatique des données, notamment la technologie d'apprentissage automatique. Bien sûr, dans la plupart des cas, la qualité de l'évaluation d'experts est supérieure aux méthodes de la machine, mais il serait trop coûteux d'attirer des ressources humaines pour résoudre une tâche aussi vaste.
Nous devons donc résoudre deux problèmes:
- Créez un filtre «scientifique» qui, d'une part, vous permet de supprimer automatiquement les documents qui ne sont pas dans la structure et le contenu, et d'autre part détermine le type de document scientifique. Faites immédiatement une réserve qui, sous la rubrique «scientifique», ne fait aucunement référence à la signification scientifique ou à la fiabilité des résultats. La tâche du filtre est de séparer les documents ayant la forme d'un article scientifique, d'un mémoire, d'un diplôme, etc. à partir d'autres types de textes, à savoir fiction, articles journalistiques, articles de presse, etc.
- Mettre en œuvre un outil de classification des documents scientifiques qui relie le document à l'une des spécialités scientifiques (par exemple, physique et mathématiques , économie , architecture , études culturelles , etc.).
Dans le même temps, nous devons résoudre ces problèmes en travaillant exclusivement avec le support textuel des documents, sans utiliser leurs métadonnées, des informations sur l'emplacement des blocs de texte et des images à l'intérieur des documents.
Illustrons par un exemple. Un simple coup d'œil suffit pour distinguer un
article scientifique
à partir, par exemple, d'un
conte de fées pour enfants .

Mais s'il n'y a qu'un calque de texte (pour les mêmes exemples), vous devez lire le contenu.
Filtre scientifique et tri par type
Nous résolvons les tâches séquentiellement:
- À la première étape, nous filtrons les documents non scientifiques;
- Dans un second temps, tous les documents identifiés comme scientifiques sont classés par type: article, mémoire de doctorat, résumé de doctorat, diplôme, etc.
Cela ressemble à ceci:
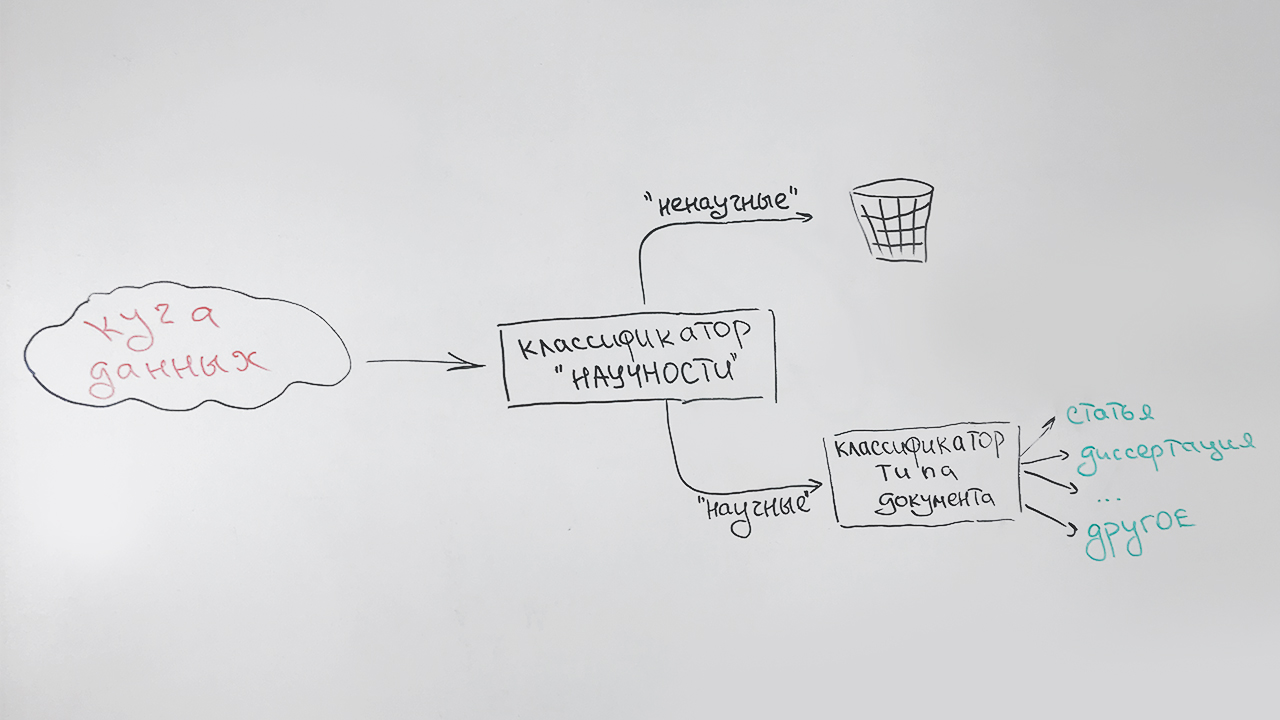
Un type spécial (non défini) est attribué aux documents qui ne peuvent être attribués de manière fiable à aucun type (principalement des documents courts - pages de sites scientifiques, résumés de résumés). Par exemple, cette publication sera attribuée à ce type, qui présente quelques signes de caractère scientifique, mais qui ne ressemble à aucun des précédents.
Il y a une autre circonstance qui doit être prise en compte. Il s'agit d'une vitesse élevée de l'algorithme et de faibles besoins en ressources - néanmoins, notre tâche est auxiliaire. Par conséquent, nous utilisons une très petite description indicative des documents:
- longueur moyenne d'une phrase dans un texte;
- partage des mots vides par rapport à tous les mots du texte;
- indice de lisibilité ;
- pourcentage de signes de ponctuation par rapport à tous les caractères du texte;
- le nombre de mots de la liste ("résumé", "dissertation", "diplôme", "certification", "spécialité", "monographie", etc.) dans la première partie du texte (l'attribut est responsable de la page de titre);
- le nombre de mots de la liste («liste», «littérature», «bibliographique», etc.) dans la dernière partie du texte (l'attribut est responsable de la liste de la littérature);
- la proportion de lettres dans le texte;
- longueur moyenne des mots;
- le nombre de mots uniques dans le texte.
Tous ces signes sont bons car ils sont calculés rapidement. En tant que classificateur, nous utilisons l'algorithme de forêt aléatoire (
forêt aléatoire ), une méthode de classification populaire en apprentissage automatique.
Avec des évaluations de qualité en l'absence d'un échantillon marqué par des experts, il est difficile, donc nous laissons le classificateur dans la collection d'articles par la bibliothèque électronique scientifique
Elibrary.ru . Nous supposons que tous les articles seront identifiés comme scientifiques.
Résultat à 100%? Rien de tel - seulement 70%. Peut-être que nous avons créé un mauvais algorithme? Nous regardons à travers les articles filtrés. Il s'avère que de nombreux textes non scientifiques sont publiés dans des revues scientifiques: éditoriaux, félicitations pour les anniversaires, nécrologies, recettes et même horoscopes. Le visionnement sélectif d'articles que le classificateur considéré comme scientifique ne révèle pas d'erreurs, par conséquent, nous reconnaissons le classificateur comme approprié.
Nous entreprenons maintenant la deuxième tâche. Ici, vous ne pouvez pas vous passer de matériel de qualité pour la formation. Nous demandons aux évaluateurs de préparer un échantillon. Nous obtenons un peu plus de 3,5 mille documents avec la distribution suivante:
| Type de document | Le nombre de documents dans l'échantillon |
|---|
| Les articles | 679 |
| Thèses de doctorat | 250 |
| Résumés de thèses | 714 |
| Collections de conférences scientifiques | 75 |
| Thèses de doctorat | 159 |
| Résumés des thèses de doctorat | 189 |
| Monographies | 107 |
| Guides d'étude | 403 |
| Thèses | 664 |
| Type indéfini | 514 |
Pour résoudre le problème de classification multiclasse, nous utilisons la même forêt aléatoire et les mêmes fonctionnalités afin de ne pas calculer quelque chose de spécial.
Nous obtenons la qualité de classification suivante:
| Précision | Complétude | Mesure F |
|---|
| 81% | 76% | 79% |
Les résultats de l'application de l'algorithme entraîné aux données indexées sont visibles dans les diagrammes ci-dessous. La figure 1 montre que plus de la moitié de la collection est constituée de documents scientifiques et que, à leur tour, plus de la moitié des documents sont des articles.
 Fig. 1. Distribution de documents par «scientifiques»
Fig. 1. Distribution de documents par «scientifiques»La figure 2 montre la répartition des documents scientifiques par type, à l'exception du type «article». On peut voir que le deuxième type de document scientifique le plus populaire est un manuel, et le type le plus rare est une thèse de doctorat.
 Fig. 2. La répartition des autres documents scientifiques par type
Fig. 2. La répartition des autres documents scientifiques par typeDe manière générale, les résultats sont conformes aux attentes. Du classificateur rapide "grossier" dont nous n'avons plus besoin.
Définition de l'objet du document
Il se trouve qu'un classificateur unifié et universellement reconnu des travaux scientifiques n'a pas encore été créé. Les plus populaires aujourd'hui sont les rubriques
VAK ,
GRNTI ,
UDC . Au cas où, nous avons décidé de classer les documents par thème sous chacune de ces catégories.
Pour construire un classificateur thématique, nous utilisons une approche basée sur la
modélisation de sujet , une manière statistique de construire un modèle pour une collection de documents texte, dans laquelle pour chaque document sa probabilité d'appartenir à certains sujets est déterminée. Comme outil de construction d'un modèle thématique, nous utilisons la bibliothèque ouverte
BigARTM . Nous avons déjà utilisé cette bibliothèque auparavant et nous savons qu'elle est idéale pour la modélisation thématique de grandes collections de documents texte.
Cependant, il y a une difficulté. En modélisation thématique, la détermination de la composition et de la structure des sujets est le résultat de la résolution d'un problème d'optimisation par rapport à une collection spécifique de documents. Nous ne pouvons pas les influencer directement. Naturellement, les thèmes résultant du réglage de notre collection ne correspondront à aucun des classificateurs cibles.
Par conséquent, afin d'obtenir la valeur inconnue finale du correcteur d'un document de demande spécifique, nous devons effectuer une conversion supplémentaire. Pour ce faire, dans l'espace de rubrique BigARTM, en utilisant l'algorithme du plus proche voisin (
k-NN ), nous recherchons plusieurs documents qui sont les plus similaires à la requête avec des rubriques connues et, sur cette base, nous attribuons la classe la plus pertinente au document de requête.
Sous une forme simplifiée, l'algorithme est illustré dans la figure:

Pour former le modèle, nous utilisons des documents provenant de sources ouvertes, ainsi que des données fournies par Elibrary.ru avec des spécialités bien connues de la Commission d'attestation supérieure, SRSTI, UDC. Nous supprimons de la collection les documents qui sont liés à des positions très générales des rubricateurs, par exemple
les problèmes généraux et complexes des sciences exactes et naturelles , car de tels documents vont grandement brouiller la classification finale.
La collection finale contenait environ 280 000 documents pour la formation et 6 000 documents pour les tests pour chacune des rubriques.
Pour nos besoins, il nous suffit de prédire les valeurs des rubriques du premier niveau. Par exemple, pour un texte avec une valeur GRNTI de
27.27.24: Fonctions harmoniques et leurs généralisations, la prédiction de la section
27: Mathématiques est correcte.
Pour améliorer la qualité de l'algorithme développé, nous y ajoutons quelques approches basées sur le bon vieux classifieur
Naive Bayes . Comme signes, il utilise la fréquence des mots les plus caractéristiques pour chacun des documents avec une valeur spécifique de l'en-tête HAC.
Pourquoi si dur? En conséquence, nous prenons les prédictions des deux algorithmes, les pondérons et produisons une prédiction moyenne pour chaque requête. Cette technique d'apprentissage automatique est appelée
assemblage . Une telle approche nous donne une augmentation notable de la qualité. Par exemple, pour la spécification SRSTI, la précision de l'algorithme d'origine était de 73%, la précision du classificateur naïf de Bayes était de 65% et leurs associations étaient de 77%.
En conséquence, nous obtenons un tel schéma de notre classificateur:
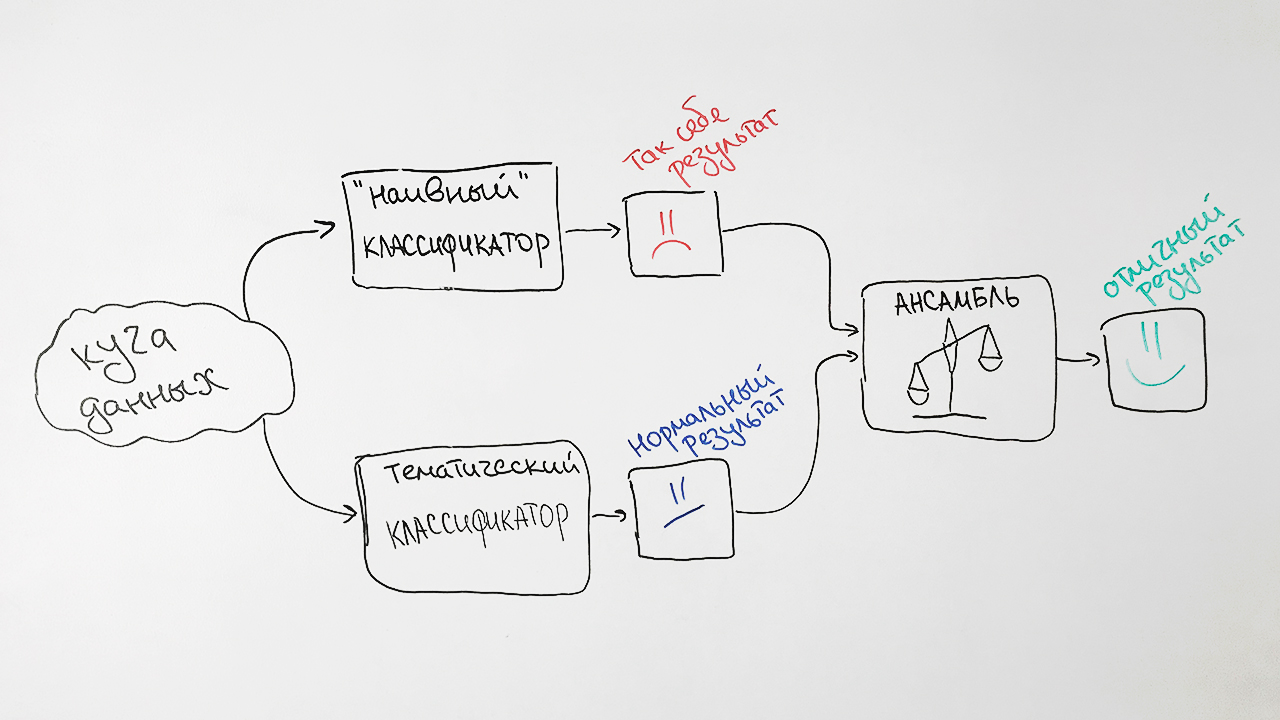
Nous notons deux facteurs qui influencent les résultats du classificateur. Tout d'abord, tout document peut se voir attribuer plusieurs valeurs de rubrique à la fois. Par exemple, les valeurs de l'intitulé de la Commission supérieure d'attestation 25.00.24 et 08.00.14 (Géographie
économique ,
sociale et politique et
économie mondiale ). Et ce ne sera pas une erreur.
Deuxièmement, dans la pratique, les valeurs des rubriques sont placées de manière experte, c'est-à-dire subjectivement. Un exemple frappant est des sujets apparemment différents comme le
génie mécanique et l'
agriculture et la foresterie . Notre algorithme a classé les articles intitulés
«Machines à éclaircir la forêt» et
«Conditions préalables au développement d'une série de tracteurs de taille standard pour les conditions de la zone nord-ouest» à l'ingénierie mécanique, et selon la disposition d'origine, ils se référaient précisément à l'agriculture.
Par conséquent, nous avons décidé d'afficher les 3 valeurs les plus probables pour chacune des catégories. Par exemple, pour l'article
«Tolérance professionnelle des enseignants (sur l'exemple de l'activité d'un enseignant russe d'une école multiethnique)», les probabilités des valeurs du titre de la Commission supérieure d'attestation ont été réparties comme suit:
| Valeur du rubricator | Probabilité |
|---|
| Sciences pédagogiques | 47% |
| Sciences psychologiques | 33% |
| Etudes culturelles | 20% |
La précision des algorithmes résultants était:
| Rubricator | Précision du Top 3 |
|---|
| SRSTI | 93% |
| VAK | 92% |
| UDC | 94% |
Les diagrammes montrent les résultats d'une étude sur la distribution des sujets de documents dans l'index Internet en langue russe pour tous (figure 3) et uniquement pour les documents scientifiques (figure 4). On voit que la plupart des documents concernent les sciences humaines: les spécifications les plus fréquentes sont l'économie, le droit et la pédagogie. De plus, parmi les seuls documents scientifiques, leur part est encore plus importante.
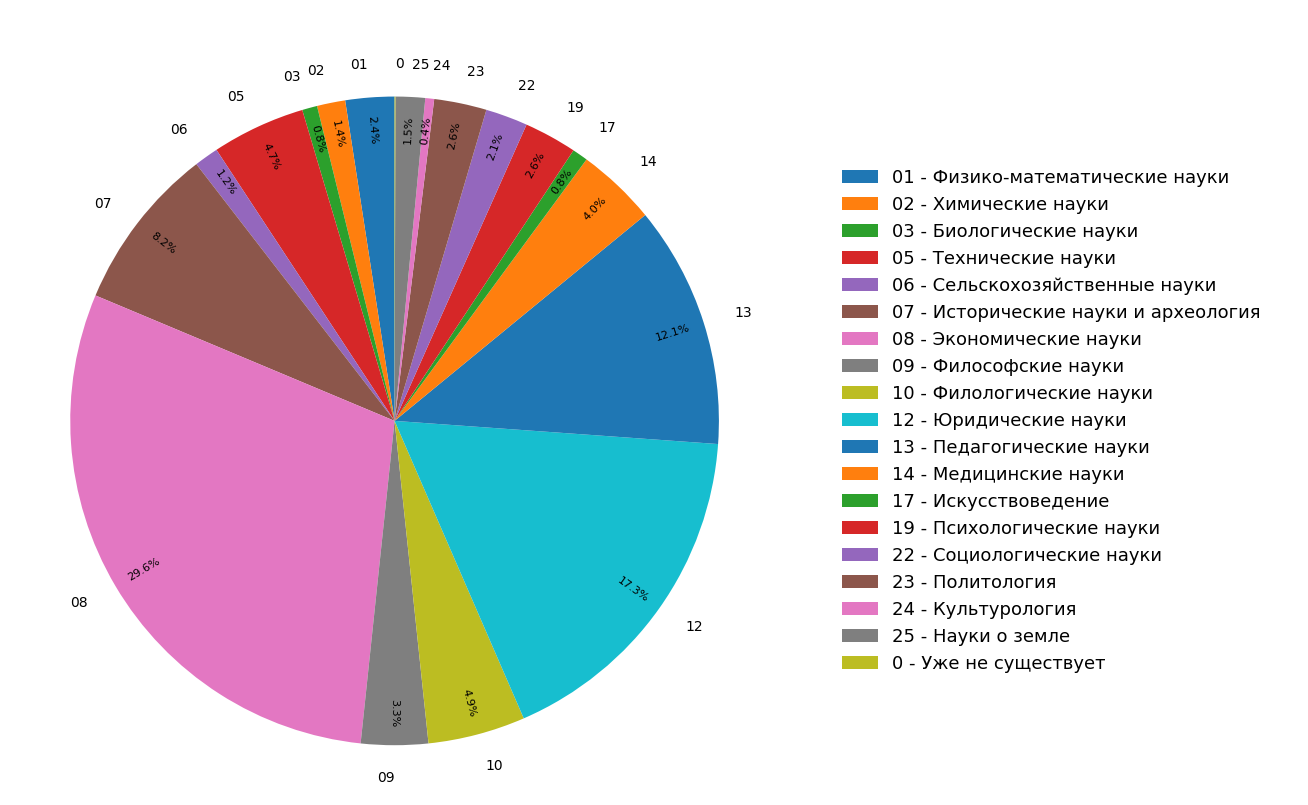 Fig. 3. Répartition des sujets dans le module de recherche
Fig. 3. Répartition des sujets dans le module de recherche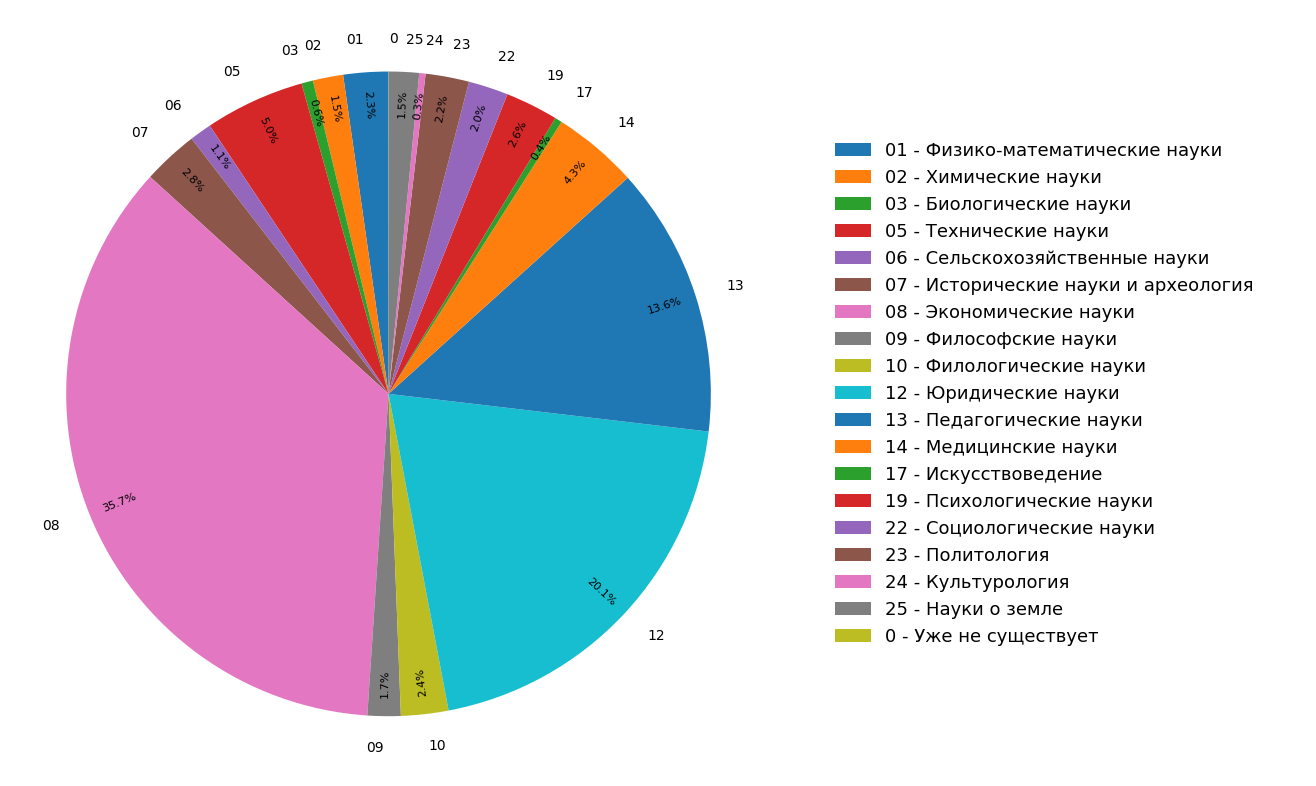 Fig. 4. La distribution des thèmes des documents scientifiques.
Fig. 4. La distribution des thèmes des documents scientifiques.En conséquence, nous avons littéralement appris des matériaux à la main non seulement la structure thématique de l'Internet indexé, mais également créé des fonctionnalités supplémentaires avec lesquelles vous pouvez «classer» un article ou un autre document scientifique en trois catégories thématiques à la fois.

La fonctionnalité décrite ci-dessus est maintenant activement implémentée dans le système anti-plagiat et sera bientôt disponible pour les utilisateurs.