
Netflix est obsédé par la disponibilité des services. Nous l'avons déjà revu sur notre blog plus d'une fois et expliqué comment nous réussissons à atteindre nos objectifs. Nous utilisons des disjoncteurs, des limites de simultanéité, des tests de chaos, etc. Aujourd'hui, nous vous présentons une autre approche innovante qui améliore considérablement la stabilité de l'application sous des charges extrêmes et évite les défaillances de service en cascade - limites adaptatives pour les connexions parallèles. Aucun effort supplémentaire n'est nécessaire pour déterminer les limites des connexions parallèles, permettant au système de maintenir un temps de réponse court. Dans le cadre de cette annonce, nous publions également dans le domaine public une bibliothèque Java simple avec des capacités d'intégration pour les servlets, les programmes de contrôle et gRPC.
Commençons par les bases
La limite des connexions parallèles est le nombre maximal de demandes que le système est capable de traiter à un certain moment. En règle générale, ce montant dépend d'une ressource limitée, telle que la puissance de traitement du processeur central. Habituellement, la limite de connexions parallèles d'un système est calculée selon la loi de Little, qui se lit comme suit: pour un système stable, le nombre maximal de connexions parallèles est égal au produit du temps moyen passé à traiter la demande et de l'intensité moyenne des demandes entrantes (L = λW). Toutes les demandes dépassant la limite de connexion parallèle ne peuvent pas être immédiatement traitées par le système, elles seront donc mises en file d'attente ou rejetées. La mise en file d'attente est une fonction importante qui vous permet d'utiliser pleinement le système dans les cas où les demandes sont reçues de manière inégale et nécessitent un temps de traitement différent.
S'il n'y a pas de limite pour la file d'attente, un plantage du système peut se produire, par exemple, si pendant longtemps l'intensité des demandes est supérieure à la vitesse de leur traitement. À mesure que la file d'attente s'allonge, le délai augmente, ce qui entraîne un dépassement du temps d'attente pour les demandes. Cela continue jusqu'à épuisement de la mémoire libre, après quoi le système se bloque. Si vous ne suivez pas le temps de retard croissant, il commencera à affecter négativement les services d'appel et entraînera des défaillances du système en cascade.

L'utilisation de limites de connexion parallèle est une pratique standard, mais la difficulté réside dans leur détermination pour les grands systèmes distribués dynamiques, où les paramètres tels que le temps de retard et le nombre possible de connexions parallèles changent constamment. L'essence de notre solution est la capacité de déterminer dynamiquement la limite des connexions parallèles. Cette limite peut être représentée comme le nombre de demandes entrantes (exécutées en parallèle et en file d'attente) que le système est en mesure de traiter jusqu'à ce que ses performances commencent à diminuer (et que le temps de retard augmente).
Solution
Auparavant, les employés de Netflix déterminaient les limites de connexion simultanées manuelles grâce à des tests de performances et à un profilage fastidieux. Le nombre résultant était correct pour une période de temps spécifique, mais bientôt la topologie du système a commencé à changer en raison de défaillances partielles, d'une mise à l'échelle automatique ou de l'introduction d'un code supplémentaire qui a affecté le temps de retard. Par conséquent, la limite est obsolète. Nous savions que nous étions capables de plus, qu'il ne nous suffisait plus de déterminer statiquement les limites de connexion. Nous avions besoin d'un moyen de déterminer automatiquement les limites inhérentes au système lui-même. En même temps, nous voulions cette méthode:
- ne nécessitait pas de travail manuel;
- ne nécessitait pas de coordination centrale;
- pourrait déterminer la limite sans aucune information sur la topologie du matériel ou du système;
- Adapté aux changements de la topologie du système;
- était simple en termes de mise en œuvre et de calculs nécessaires.
Pour résoudre ce problème, nous nous sommes tournés vers l'algorithme éprouvé de suivi de la congestion TCP. Cet algorithme détermine le nombre de paquets de données qui peuvent être transmis en parallèle (c'est-à-dire la taille de la fenêtre de débordement) sans augmenter le temps de retard ni dépasser le temps d'attente. Ces algorithmes utilisent divers indicateurs pour déterminer la limite de paquets transmis simultanément et pour redimensionner la fenêtre de débordement en conséquence.

La couleur bleue de l'image montre la limite inconnue pour les connexions parallèles au système. Tout d'abord, le client envoie un petit nombre de demandes simultanées, puis il commence à vérifier périodiquement le système pour voir s'il peut traiter plus de demandes en augmentant la fenêtre de débordement jusqu'à ce que cela entraîne une augmentation du délai. Lorsque le délai augmente encore, l'expéditeur décide qu'il a atteint la limite et réduit à nouveau la taille de la fenêtre de débordement. Un tel test continu de la limite se reflète dans le graphique que vous voyez ci-dessus.
Notre algorithme repose sur l'algorithme de suivi de congestion TCP, qui prend en compte la relation entre le temps de retard minimum (le meilleur scénario possible dans lequel la file d'attente n'est pas utilisée) et le temps de retard, qui est mesuré périodiquement au fur et à mesure de l'exécution des requêtes. Ce rapport permet de déterminer qu'une file d'attente s'est formée provoquant une augmentation du retard. Ce rapport nous donne le gradient ou l'amplitude du changement de temps de retard:
gradient = (RTTnoload / RTTactual) . Si la valeur est égale à un, alors nous comprenons qu'il n'y a pas de file d'attente et que la limite peut être augmentée. Une valeur inférieure à un indique que la file d'attente est pleine et que la limite doit être réduite. À chaque nouvelle mesure du temps de retard, la limite est ajustée en fonction du rapport ci-dessus, et avec elle la taille de file d'attente autorisée change conformément à cette formule simple:
_ = _ × + _
Pour plusieurs itérations, l'algorithme calcule une limite qui permet non seulement de maintenir le temps de retard à un niveau bas, mais aussi de former la file d'attente de requêtes nécessaire en cas de flambées d'activité. La taille de file d'attente valide peut être configurée. Il est utilisé pour déterminer la vitesse à laquelle la limite de simultanéité peut augmenter. Comme taille par défaut, nous avons choisi la racine carrée de la valeur limite actuelle. Ce choix est dû à la propriété utile de la racine carrée: aux petites valeurs, elle sera suffisamment grande par rapport à la limite pour assurer une croissance rapide, mais aux grandes valeurs, au contraire, sa valeur relative sera moindre, ce qui augmentera la stabilité du système.
Limites adaptatives en action
Les limites adaptatives côté serveur rejettent les demandes excessives et maintiennent une faible latence, ce qui permet à l'instance système de se protéger et de protéger les services dont elle dépend. Auparavant, lorsqu'il n'était pas possible de rejeter des demandes excessives, toute augmentation régulière du nombre de demandes par seconde ou de retard entraînait une augmentation encore plus importante de ce délai et, finalement, la chute de l'ensemble du système. Aujourd'hui, les services peuvent se débarrasser des charges de travail inutiles et maintenir une faible latence tout en travaillant avec d'autres outils de stabilisation, tels que la mise à l'échelle automatique.
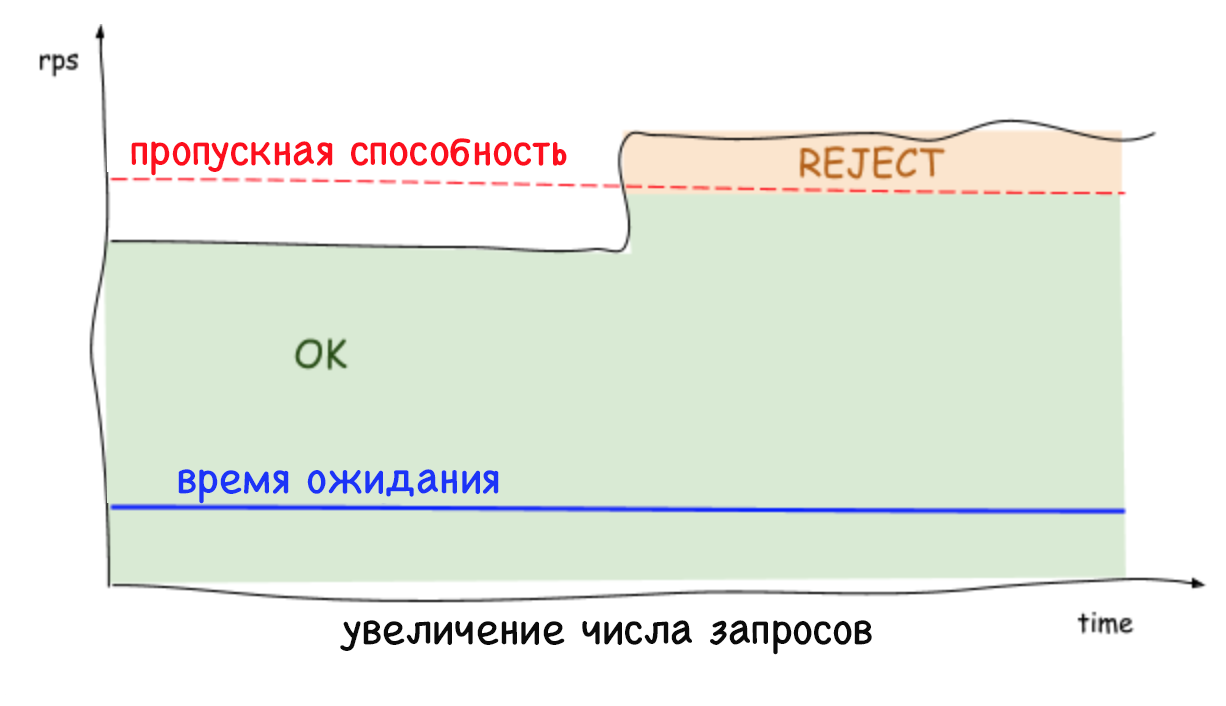
Il est important de se rappeler que des limites sont fixées au niveau du serveur (et sans aucune coordination), que le trafic vers chaque serveur peut chuter et augmenter fortement. Par conséquent, il n'est pas surprenant que la limite détectée et le nombre de connexions simultanées puissent être différents selon le serveur. Cela est particulièrement vrai dans un environnement cloud multi-clients. Par conséquent, une situation peut se produire lorsqu'un serveur est surchargé, bien que le reste soit gratuit. Dans le même temps, lors de l'équilibrage de la charge côté client, une seule demande répétée parviendra au serveur avec des ressources gratuites dans près de 100% des cas. Et ce n'est pas tout: il n'y a plus de raison de craindre que des requêtes répétées provoquent une attaque DDOS, car les services sont capables de rejeter rapidement (en moins d'une milliseconde) le trafic avec un impact minimal sur les performances.
Conclusion
L'utilisation de limites adaptatives pour les connexions parallèles élimine la nécessité de déterminer manuellement comment et dans quels cas nos services doivent rejeter le trafic. De plus, cela augmente également la fiabilité et la disponibilité globales de l'ensemble de notre écosystème de microservices.
Nous sommes heureux de partager avec vous nos méthodes de mise en œuvre et l'intégration globale de cette solution, que vous pouvez trouver dans la bibliothèque publique à
github.com/Netflix/concurrency-limits . Nous espérons que notre code aidera les utilisateurs à protéger leurs services contre les défaillances en cascade et les problèmes liés à l'augmentation de la latence, ainsi qu'à accroître leur disponibilité.