
Salut Habr!
Je m'appelle Alexey Solodky, je suis développeur PHP chez Badoo. Et aujourd'hui, je vais partager une version texte de mon discours pour le premier Badoo PHP Meetup. Une vidéo de ceci et d'autres rapports du mitap peut être trouvée
ici .
Tout système composé d'au moins deux composants (et si vous avez à la fois PHP et une base de données, alors ce sont deux composants), fait face à des classes entières de risques dans l'interaction entre ces composants.
Le département plateforme dans lequel je travaille intègre de nouveaux services internes à notre application. Et en résolvant ces problèmes, nous avons accumulé une expérience que je veux partager.
Notre backend est un monolithe PHP interagissant avec de nombreux services (il en existe actuellement environ 50). Les services interagissent rarement entre eux. Mais les problèmes dont je parle dans l'article sont également pertinents pour l'architecture de microservices. En effet, dans ce cas, les services interagissent très activement les uns avec les autres, et plus vous avez d'interaction, plus vous avez de problèmes.
Réfléchissez à ce qu'il faut faire lorsque le service tombe en panne ou s'émousse, comment organiser la collecte des métriques et que faire lorsque tout ce qui précède ne vous sauve pas.
Panne de service
Tôt ou tard, le serveur sur lequel votre service est installé tombera. Cela arrivera à coup sûr, et vous ne pouvez pas vous défendre contre cela - ne faites que réduire la probabilité. Vous pouvez être déçu par le matériel, le réseau, le code, le déploiement infructueux - n'importe quoi. Et plus vous avez de serveurs, plus cela se produit souvent.
Comment faire survivre vos services dans un monde où les serveurs plantent constamment? Une approche générale pour résoudre cette classe de problèmes est la redondance.
La redondance est utilisée partout à différents niveaux: du fer à des datacenters entiers. Par exemple, RAID1 pour se protéger contre les pannes de disque dur ou une alimentation de secours pour votre serveur en cas de panne du premier. En outre, ce schéma est largement appliqué aux bases de données. Par exemple, vous pouvez utiliser maître-esclave pour cela.
Considérons les problèmes typiques de redondance en utilisant le schéma le plus simple comme exemple:
L'application communique exclusivement avec le maître, tandis qu'en arrière-plan, de manière asynchrone, les données sont transférées à l'esclave. Lorsque le maître tombe en panne, nous passerons à l'esclave et continuerons de travailler.
Après avoir restauré le maître, nous en faisons juste un nouvel esclave, et l'ancien se transforme en maître.
Le schéma est simple, mais il a même de nombreuses nuances caractéristiques de tout schéma redondant.
Charge
Disons qu'un serveur de l'exemple ci-dessus peut supporter environ 100 000 RPS. Maintenant, la charge est de 60k RPS, et tout fonctionne comme une horloge.
Mais au fil du temps, la charge sur l'application, et donc la charge sur le maître, augmente. Vous pouvez souhaiter l'équilibrer en déplaçant une partie de la lecture vers un esclave.
Ça a l'air plutôt bien. Tient la charge, le serveur n'est plus inactif. Mais c'est une mauvaise idée. Il est important de se rappeler pourquoi vous avez initialement élevé l'esclave - pour y basculer en cas de problème avec le principal. Si vous avez commencé à charger les deux serveurs, alors lorsque votre maître se bloque - et tôt ou tard il se bloque - vous devrez commuter le trafic principal du maître vers le serveur de sauvegarde, et il est déjà chargé. Une telle surcharge rendra votre système terriblement lent ou le désactivera complètement.
Les données
Le principal problème lors de l'ajout d'une tolérance aux pannes à un service est l'état local. Si votre service est sans état, c'est-à-dire qu'il ne stocke aucune donnée modifiable, sa mise à l'échelle ne pose pas de problème. Nous soulevons juste autant de cas que nous en avons besoin et équilibrons les demandes entre eux.
Dans le cas où le service est avec état, nous ne pouvons plus le faire. Vous devez réfléchir à la façon de stocker les mêmes données sur toutes les instances de notre service afin qu'elles restent cohérentes.
Pour résoudre ce problème, l'une des deux approches est utilisée: réplication synchrone ou asynchrone. Dans le cas général, je vous conseille d'utiliser l'option asynchrone, car elle est généralement plus simple et plus rapide à écrire et, selon les circonstances, voyez si vous devez passer en synchrone.
Une
cohérence importante à prendre en compte lors de l'utilisation de la réplication asynchrone est la
cohérence éventuelle . Cela signifie qu'à un moment donné sur différents esclaves, les données peuvent être en retard sur le maître par des intervalles de temps imprévisibles et différents.
Par conséquent, vous ne pouvez pas lire les données à chaque fois à partir d'un serveur aléatoire, car des réponses différentes peuvent alors arriver aux mêmes demandes des utilisateurs. Pour contourner ce problème, le mécanisme des
sessions persistantes est utilisé , ce qui garantit que toutes les demandes d'un utilisateur vont à une seule instance.
Les avantages d'une approche synchrone sont que les données sont toujours dans un état cohérent et que le risque de perdre des données est plus faible (car il est considéré comme enregistré uniquement après que tous les serveurs l'ont fait). Cependant, vous devez payer pour cela avec la vitesse d'écriture et la complexité du système lui-même (par exemple, divers algorithmes de quorum pour la protection contre le
split-brain ).
Conclusions
- Réserve. Si les données elles-mêmes et la disponibilité d'un service particulier sont importantes, assurez-vous que votre service survivra à la chute d'une machine particulière.
- Lors du calcul de la charge, tenez compte de la chute de certains serveurs. Si votre cluster possède quatre serveurs, assurez-vous que lorsqu'un tombera, les trois autres tireront la charge.
- Choisissez le type de réplication en fonction des tâches.
- Ne mettez pas tous vos œufs dans le même panier. Assurez-vous que vous êtes suffisamment éloigné des serveurs. Selon l'importance de la disponibilité des services, vos serveurs peuvent se trouver dans des racks différents dans un centre de données, ou dans différents centres de données dans différents pays. Tout dépend de la quantité de catastrophes que vous souhaitez et êtes prêt à survivre.
Service de silence
À un moment donné, votre service peut commencer à fonctionner très lentement. Ce problème peut se produire pour de nombreuses raisons: charge excessive, retards réseau, problèmes matériels ou erreurs de code. Cela ressemble à un problème pas si terrible, mais en fait, il est plus insidieux qu'il n'y paraît.
Imaginez: un utilisateur demande une page. Nous accédons simultanément et séquentiellement aux quatre démons pour l'attirer. Ils répondent rapidement, tout fonctionne bien.
Supposons que ce cas soit géré en utilisant nginx avec un nombre fixe de travailleurs PHP FPM (avec dix, par exemple). Si chaque demande est traitée pendant environ 20 ms, alors à l'aide de calculs simples, on peut comprendre que notre système est capable de traiter environ cinq cents demandes par seconde.
Que se passe-t-il lorsque l'un de ces quatre services commence à émousser et que le traitement des demandes passe de 20 ms à un délai d'expiration de 1000 ms? Il est important de se rappeler que lorsque nous travaillons avec le réseau, le retard peut être infiniment grand. Par conséquent, vous devez toujours définir un délai d'expiration (dans ce cas, il est égal à une seconde).
Il s'avère que le backend est obligé d'attendre l'expiration du délai et de recevoir et traiter l'erreur du démon. Cela signifie que l'utilisateur reçoit la page en une seconde au lieu de dix millisecondes. Lent, mais pas fatal.
Mais quel est le vrai problème ici? Le fait est que lorsque nous traitons chaque demande par seconde, le débit tombe tragiquement à dix demandes par seconde. Et le onzième utilisateur ne pourra plus obtenir de réponse, même s'il a demandé une page qui n'est en aucun cas associée à un service ennuyeux. Tout simplement parce que les dix employés attendent un délai d'attente et ne peuvent pas traiter de nouvelles demandes.
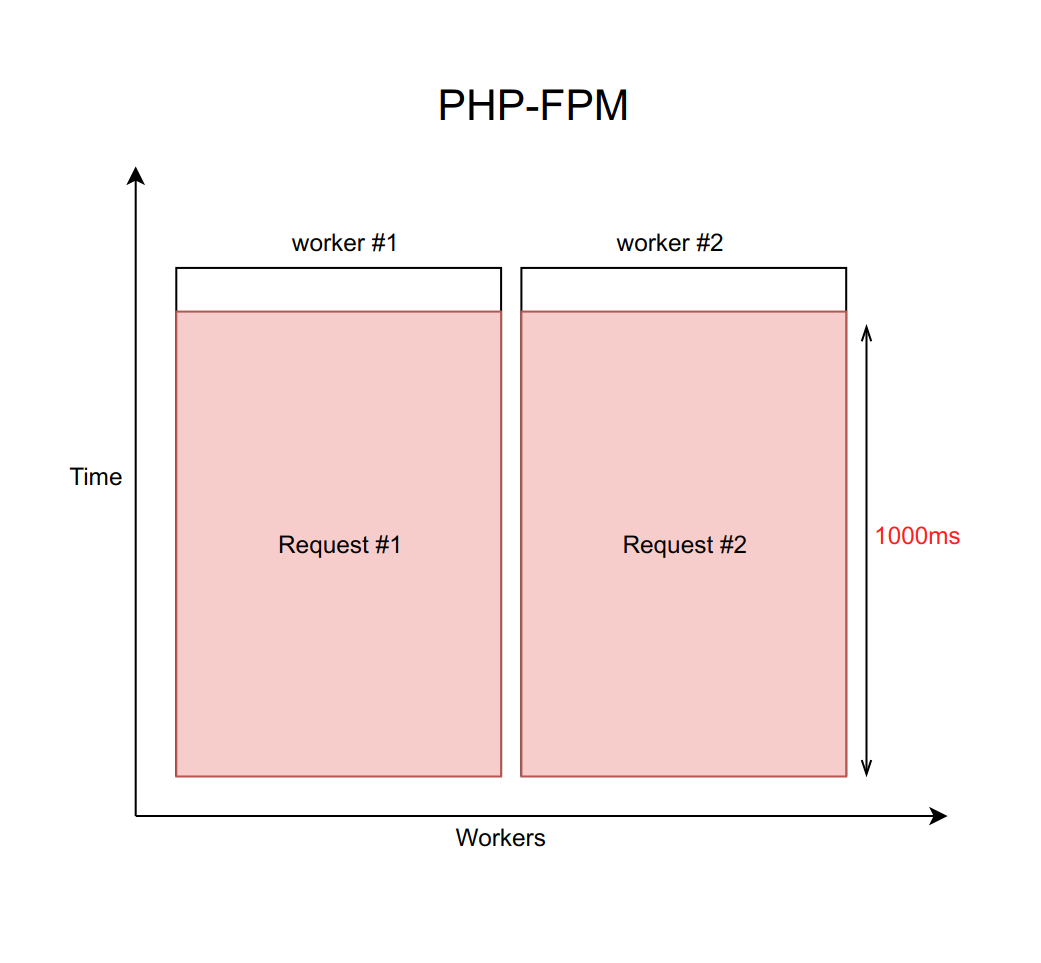
Il est important de comprendre que ce problème ne peut être résolu en augmentant le nombre de travailleurs. Après tout, chaque travailleur a besoin d'une certaine quantité de RAM pour son travail, même s'il n'effectue pas de travail réel, mais se bloque simplement en prévision d'un délai d'attente. Par conséquent, si vous ne limitez pas le nombre de travailleurs en fonction des capacités de votre serveur, l'augmentation de plus en plus de nouveaux travailleurs mettra l'ensemble du serveur. Ce cas est un exemple d'échec en cascade, lorsque la chute d'un service, même si elle n'est pas critique pour l'utilisateur, provoque une défaillance de l'ensemble du système.
Solution
Il existe un motif appelé
disjoncteur . Sa tâche est assez simple: il doit à un moment donné supprimer un service ennuyeux. Pour cela, un proxy est placé entre le service et les travailleurs. Il peut s'agir de code PHP avec stockage ou d'un démon sur l'hôte local. Il est important de noter que si vous avez plusieurs instances (votre service est répliqué), ce proxy doit suivre séparément chacune d'entre elles.
Nous avons écrit notre implémentation de ce modèle. Mais pas parce que nous aimons écrire du code, mais parce que lorsque nous avons résolu ce problème il y a de nombreuses années, il n'y avait pas de solutions toutes faites.
Je vais maintenant décrire en termes généraux notre implémentation et comment elle permet d'éviter ce problème. Et plus sur elle et ses différences par rapport à d'autres solutions peuvent être entendues
dans un rapport de Mikhail Kurmaev sur Highload Siberia fin juin. La transcription de son rapport sera également sur ce blog.
Cela ressemble à ceci:
Il existe un service Sphinx abstrait, auquel est confronté un disjoncteur. Le disjoncteur stocke le nombre de connexions actives à un démon spécifique. Dès que cette valeur atteint le seuil que nous avons défini en pourcentage des travailleurs FPM disponibles sur la machine, nous pensons que le service a commencé à ralentir. Une fois le premier seuil atteint, nous envoyons une notification au responsable du service. Une telle situation est soit un signe que les limites doivent être revues, soit un signe avant-coureur de problèmes d'ennui.
Si la situation empire et que le nombre de travailleurs inhibiteurs atteint le deuxième seuil - dans notre production, il est d'environ 10% - nous supprimons complètement cet hôte. Plus précisément, le service continue de fonctionner, mais nous cessons de lui envoyer des demandes. Le navigateur Circuit les rejette et donne immédiatement une erreur aux travailleurs, comme si le service mentait.
De temps en temps, nous ignorons automatiquement une demande d'un travailleur pour voir si le service a pris vie. S'il répond adéquatement, alors nous l'incluons à nouveau dans le travail.
Tout cela est fait afin de réduire la situation au schéma de réplication précédent. Au lieu d'attendre une seconde avant de réaliser que l'hôte n'est pas disponible, nous obtenons immédiatement une erreur et allons à l'hôte de sauvegarde.
Implémentations
Heureusement, l'Open Source ne reste pas immobile, et aujourd'hui vous pouvez prendre une solution clé en main sur Github.
Il existe deux approches principales pour implémenter un disjoncteur: une bibliothèque au niveau du code et un démon autonome qui procède par procuration aux requêtes par lui-même.
L'option avec la bibliothèque est plus appropriée si vous avez un monolithe principal en PHP, qui interagit avec plusieurs services, et les services ne communiquent presque pas entre eux. Voici quelques implémentations disponibles:
Si vous avez de nombreux services dans différentes langues et qu'ils interagissent tous, l'option au niveau du code devra être dupliquée dans toutes ces langues. Cela est gênant dans le support et conduit finalement à des différences dans les implémentations.
Mettre un démon dans ce cas est beaucoup plus facile. Dans ce cas, vous n'avez pas besoin de modifier spécialement le code. Le démon essaie de rendre l'interaction transparente. Cependant, cette option est
beaucoup plus compliquée sur le plan architectural .
Voici quelques options (la fonctionnalité y est plus riche, mais il y a aussi un disjoncteur):
Conclusions
- Ne comptez pas sur le réseau.
- Toutes les demandes réseau doivent avoir un délai d'attente, car le réseau peut donner un temps infiniment long.
- Utilisez un disjoncteur si vous souhaitez éviter les plantages d'applications en cascade en raison du ralentissement d'un petit service.
Surveillance et télémétrie
Qu'est-ce que ça donne
- Prévisibilité. Il est important de prédire quelle est la charge et ce qu'elle sera dans un mois afin d'augmenter rapidement le nombre d'instances de service. Cela est particulièrement vrai si vous avez affaire à une infrastructure de fer, car la commande de nouveaux serveurs prend du temps.
- Enquête sur les incidents. Tôt ou tard, quelque chose va mal de toute façon, et vous devrez enquêter. Et il est important d'avoir suffisamment de données pour comprendre le problème et être en mesure d'éviter de telles situations à l'avenir.
- Prévention des accidents. Idéalement, vous devez comprendre quels modèles conduisent à des plantages. Il est important de garder une trace de ces modèles et d'en informer l'équipe en temps opportun.
Que mesurer
Mesures d'intégrationPuisque nous parlons de l'interaction entre les services, nous surveillons tout ce qui est possible en relation avec la communication du service avec l'application. Par exemple:
- nombre de demandes;
- temps de traitement des demandes (y compris les centiles);
- nombre d'erreurs logiques;
- nombre d'erreurs système.
Il est important de distinguer les erreurs logiques des erreurs système. Si le service tombe, c'est une situation régulière: nous passons simplement au second. Mais ce n'est pas si effrayant. Si vous commencez une sorte d'erreur logique, par exemple, des données étranges arrivent dans le service ou le quittent, alors cela doit déjà être étudié. Très probablement, l'erreur est liée à un bogue dans le code. Elle-même ne passera pas.
Mesures internesPar défaut, le service est une boîte noire qui fait son travail de manière incompréhensible. Il est toujours souhaitable de comprendre et de collecter le maximum de données que le service peut fournir. Si le service est une base de données spécialisée qui stocke certaines données de votre logique métier, gardez une trace exacte de la quantité de données, de quel type il s'agit et d'autres mesures de contenu. Si vous avez une interaction asynchrone, il est également important de surveiller les files d'attente à travers lesquelles votre service communique: leur vitesse d'arrivée et de départ, l'heure à différentes étapes (si vous avez plusieurs points intermédiaires), le nombre d'événements dans la file d'attente.
Voyons quelles mesures peuvent être collectées en utilisant memcached comme exemple:
- rapport succès / échec;
- temps de réponse pour diverses opérations;
- RPS de diverses opérations;
- ventilation des mêmes données sur différentes clés;
- clés les plus chargées;
- toutes les métriques internes fournies par la commande stats.
Comment faire
Si vous avez une petite entreprise, un petit projet et quelques serveurs, alors c'est une bonne solution pour connecter une sorte de SaaS pour la collecte et la visualisation - c'est plus facile et moins cher. Dans ce cas, le SaaS possède généralement des fonctionnalités étendues et n'a pas à se soucier de beaucoup de choses. Exemples de tels services:
Alternativement, vous pouvez toujours installer Zabbix, Grafana ou toute autre solution auto-hébergée sur votre propre machine.
Conclusions
- Collectez toutes les métriques que vous pouvez. Les données ne sont pas superflues. Lorsque vous devrez enquêter sur quelque chose, vous direz merci pour votre prévoyance.
- N'oubliez pas l'interaction asynchrone. Si vous avez des lignes qui atteignent progressivement, il est important de comprendre à quelle vitesse elles atteignent, ce qui arrive à vos événements à la jonction entre les services.
- Si vous écrivez votre service, apprenez-lui à donner des statistiques sur le travail. Une partie des données peut être mesurée sur la couche d'intégration lorsque nous communiquons avec ce service. Le reste du service devrait être en mesure de fournir des statistiques selon la commande conditionnelle. Par exemple, dans tous nos services sur Go, cette fonctionnalité est standard.
- Personnalisez les déclencheurs. Les graphiques sont bons, mais seulement pendant que vous les regardez. Il est important que vous disposiez d'un système personnalisé qui vous permettra de savoir si quelque chose ne va pas.
Memento mori
Et maintenant un peu de tristes choses. Vous pouvez avoir l'impression que ce qui précède est une panacée, et maintenant rien ne tombera jamais. Mais même si vous appliquez tout ce qui est décrit ci-dessus, de toute façon, quelque chose tombera. Il est important de considérer cela.
Les raisons de la chute sont multiples. Par exemple, vous pouvez choisir un schéma de réplication insuffisamment paranoïaque. Une météorite est tombée dans votre centre de données, puis dans le second. Ou vous venez de déployer le code avec une erreur délicate qui est apparue de manière inattendue.
Par exemple, à Badoo, il y a une page "Les gens à proximité". Là, les utilisateurs recherchent d'autres personnes à proximité pour discuter avec eux.

Maintenant, pour rendre la page, le backend effectue des appels synchrones vers environ sept services. Pour plus de clarté, réduisez ce nombre à deux. Un service est responsable du rendu du bloc central avec des photos. Le second concerne le bloc publicitaire en bas à gauche. Ceux qui veulent devenir plus visibles peuvent y arriver. Si nous avons un service qui affiche cette publicité, le bloc disparaît tout simplement.

La plupart des utilisateurs ne savent même pas ce fait: notre équipe répond rapidement, et bientôt le bloc réapparaît simplement.
Mais nous ne pouvons pas supprimer discrètement toutes les fonctionnalités. Si nous perdons le service responsable de la partie centrale de la page, cela ne fonctionnera pas pour se cacher. Par conséquent, il est important de dire à l'utilisateur dans sa langue ce qui se passe.

Il est également souhaitable que la défaillance d'un service n'entraîne pas une défaillance en cascade. Pour chaque service, un code doit être écrit pour gérer sa chute, sinon l'application peut se bloquer dans son ensemble.
Mais ce n'est pas tout. Parfois, quelque chose tombe, sans lequel vous ne pouvez pas vivre du tout. Par exemple, une base de données centrale ou un service de session. Il est important de travailler correctement et de montrer à l'utilisateur quelque chose de suffisant, de le divertir d'une manière ou d'une autre, pour dire que tout est sous contrôle. Dans le même temps, il est important que tout soit vraiment sous contrôle et que les moniteurs soient informés du problème.
Mourir si bien
- Préparez-vous pour l'automne. Il n'y a pas de solution miracle, alors posez toujours des pailles au cas où le service tomberait complètement, même si vous utilisez la redondance.
- Évitez les échecs en cascade lorsque des problèmes avec l'un des services tuent l'application entière.
- Désactivez la fonctionnalité utilisateur non critique. C'est normal. De nombreux services sont utilisés uniquement pour des besoins internes et n'affectent pas les fonctionnalités fournies. Par exemple, un service de statistiques. Peu importe à l'utilisateur que des statistiques soient collectées auprès de vous ou non. Il est important pour lui que le site fonctionne.
Résumé
Pour intégrer de manière fiable le nouveau service dans le système, nous écrivons une API wrapper spéciale autour de lui dans Badoo, qui assume les tâches suivantes:
- équilibrage de charge;
- délais d'attente;
- basculement logique;
- disjoncteur;
- surveillance et télémétrie;
- logique d'autorisation;
- sérialisation et désérialisation des données.
Il est préférable de vous assurer que tous ces éléments sont également couverts dans votre couche d'intégration. Surtout si vous utilisez un client API Open-Source prêt à l'emploi. Il est important de se rappeler que la couche d'intégration est une source de risque accru de défaillance en cascade de votre application.
Merci de votre attention!
Littérature