La tendance NoSQL a presque 10 ans et vous pouvez en toute sécurité tirer des conclusions et des généralisations. Nous allons le faire et parler du développement de NoSQL.
Rappelez-vous comment NoSQL est né. Voyons ce qui est bon et mauvais, et ce qui a résisté à l'épreuve du temps. Analysons les fonctionnalités qui sont déjà dans SQL et qui apparaissent maintenant dans le SGBD NoSQL. Nous mettons en évidence les valeurs uniques de NoSQL et regardons un peu plus loin ce qui se passera sur le marché demain.
Et Konstantin Osipov (
@kostja ), le développeur et l'architecte du SGBD Tarantool, qui a parlé des tendances NewSQL dans son rapport au RIT ++ 2017, nous aidera à cela, car l'architecte est censé comprendre ce qui se passe dans le monde des bases de données afin qu'au moins réinventer la roue.
À propos de l'orateur : Maintenant, Konstantin Osipov travaille sur Tarantool, mais a précédemment participé au développement de MySQL, et lorsque Konstantin a commencé à travailler sur une nouvelle base de données, il était très confus pourquoi cela devrait être fait, pourquoi la prochaine base de données était nécessaire. En particulier, l'attitude vis-à-vis de NoSQL était très sceptique quant à «under-SQL».
Cependant, le développement se poursuit, certains des principes originaux disparaissent et, en même temps, les bases de données NoSQL prennent le pas sur le SQL classique. Sur la base des résultats de ces plusieurs années de transformation rapide, il est tout à fait possible de tirer des résultats intermédiaires et de se permettre de faire plusieurs prédictions pour l'avenir.
Plan
Les principes de NoSQL
Beaucoup de gens essaient maintenant de s'en tenir au terme NoSQL, mais il a été largement adopté en 2009 lorsque le hashtag
#nosql est apparu. Le développeur de Last.FM a inventé cette balise pour les bases de données distribuées mitap.
Après cela, la balise a commencé à gagner en popularité sur Twitter, et NoSQL est devenu un réservoir de vidange ou un entonnoir pour la frustration, comme je l'appelle - une frustration qui s'est accumulée pendant de nombreuses années de travail avec les bases de données traditionnelles.
NoSQL est un moyen de sortir de la frustration, une balise que tous ceux qui n'ont pas eu assez de fonctionnalités SQL se sont appropriés.
Cette frustration doit être en quelque sorte structurée et déterminée que le plus souvent les gens n'aimaient pas dans les SGBD traditionnels. On distingue 3 grands blocs de tâches pour la solution desquels NoSQL a été créé:
- mise à l'échelle horizontale;
- nouveaux modèles de données;
- nouveaux modèles de cohérence.
Voyons ce que sont ces blocs. Prenons, par exemple, les bases de données de valeurs-clés. L'idée principale du modèle de données de valeur-clé est que la base de données est simple, mais évolutive. Un grand nombre de problèmes tombent sur les épaules du développeur, mais il a une garantie stricte que sa base de données sera
évolutive à l'infini . Mais une évolutivité infinie n'est pas magique. Les garanties d'évolutivité sont obtenues grâce à la
sémantique extrêmement simple des opérations prises en charge: dans une base de données de valeurs-clés, toute opération affecte strictement un nœud de cluster.
Au départ, il était très difficile pour la communauté de séparer les modèles de données des modèles réduits. Si vous regardez la même Cassandra, dans les premières versions, son modèle de données s'appelait le magasin à colonnes larges - une base de données à colonnes larges. S'il y a un index dans la valeur-clé du SGBD, par clé, alors dans le magasin de colonnes larges, deux index sont toujours créés automatiquement: par clé et par famille de colonnes.
De plus, l'index par clé est partageable et l'index par famille de colonnes est local à un nœud de données spécifique. Pour cette raison, nous avons obtenu une mise à l'échelle horizontale, mais en même temps avons eu la possibilité d'effectuer des requêtes locales sur la famille de colonnes. Les anciens se souviennent qu'une fonctionnalité similaire a été implémentée dans Oracle, tout en conservant le modèle relationnel, et a été appelée la table jointe. Cette fonctionnalité a permis de spécifier l'emplacement physique des deux tables dans le formulaire joint. Magasin de colonnes larges à Cassandra - implémente une table jointe avec distribution automatique à travers le cluster.
La fusion du modèle de données et du modèle à l'échelle est exactement le problème qui a été résolu en utilisant le modèle relationnel. Bienvenue dans les années 70.
En plus de nouveaux modèles de données, NoSQL a mis en œuvre de nouveaux modèles de cohérence. Oui, oui, encore une fois ce fameux
théorème CAP . Parler du théorème de la PAC m'amuse tout le temps - qui en a besoin? Comme il n'y a pas d'esturgeon de la seconde fraîcheur, il n'y a donc pas d'autre réponse à la question de la cohérence des données sauf une:
la base de données doit garantir cette cohérence . Par conséquent, les nouveaux modèles de cohérence sont également, à mon avis, une tendance moribonde.
NoSQL aujourd'hui
La thèse que je veux d'abord exprimer est celle de l'ensemble du mouvement NoSQL survécu:
- mise à l'échelle horizontale;
de nouveaux modèles de données documentent et modélisent des modèles de données;nouveaux modèles de cohérence.
Parmi les thèses sur les nouveaux modèles de données, près d'un et demi ont survécu et la thèse sur les modèles de cohérence est complètement morte.
Casquette de mort
Pourquoi certains modèles de cohérence n'ont-ils pas survécu?
●
Cohérence éventuelle: inflation à termeQui utilise une base de données dotée d'une horloge vectorielle fonctionnelle et la logique métier de l'application est orientée dans ce sens? - personne. Qui utilise des bases de données dotées de CRDT (types de données répliquées sans conflit)? Qui utilise Riak? - personne. Qu'est-ce que les gens utilisent? Plus souvent PostgreSQL, moins souvent d'autres bases, par exemple MongoDB.
●
MongoDB: atomic est remplacé par isolated, les transactions sont ajoutées en 3.xxCette base de données a une réplication asynchrone. C'est une chose très facile à comprendre, bien
qu'il existe en fait 4 types de réplication asynchrone . La réplication des données de transaction peut se produire après qu'une transaction est validée localement; avant que la transaction ne soit validée localement.
Autrement dit, le point de validation sur la base de données principale peut également être corrélé avec le point de validation sur la réplique de différentes manières.
Une entrée dans le journal local a déjà été effectuée, mais elle n'a pas encore été envoyée à la réplique. Supposons que vous souhaitiez attendre qu'elle s'envole au moins vers une réplique. Volé loin - ne signifie pas volé. Arrivé - cela ne signifie pas qu'il a été écrit dans le journal local sur la réplique.
Au départ, MongoDB avait un mode: la requête arrive sur le serveur, la base de données a répondu OK - elle n'est même pas encore arrivée sur le disque, ni dans le journal de bord - elle n'est allée nulle part. Pour cette raison, tout fonctionne très rapidement, mais ensuite ils ont commencé à critiquer MongoDB pour cela, et par défaut dans les versions ultérieures 3+, après tout, il a d'abord commencé à écrire la transaction dans le journal, et seulement après cela, envoyer une confirmation au client.
Autrement dit, même la réplication asynchrone est un abîme de modèles sémantiques. Par conséquent, les
modèles de cohérence sont trop compliqués pour être compris par un large cercle de développeurs, et les transactions et la réplication synchrone remplacent l'assortiment de modèles exotiques .
Dans le contexte de la mort du modèle de cohérence, il existe toujours une tendance intéressante dans le développement d'une cohérence réellement plus stricte. Il y a des transactions à Redis, même si je ne les appellerais pas des transactions, mais au détriment de ce qu'est une vraie transaction, il y a une controverse sans cela.
Regardons l'historique des transactions dans NoSQL. Initialement, MongoDB a implémenté l'atomicité au niveau du document. Ensuite, un mode d'exécution isolé a été ajouté pour permettre aux développeurs, s'ils le souhaitent vraiment, de mettre à jour atomiquement plusieurs documents.
●
Redéfinir les transactionsÀ l'aube de NoSQL, le développeur s'est vu proposer de regrouper l'intégralité de l'analyse de rentabilisation dans un même panier. Un flux entier apparaît appelé conception pilotée par domaine, ce qui élève cette perversion au rang de modèle de conception. En effet, si tout est stocké dans un seul document, l'atomicité est obtenue simplement: vous avez fait une transaction, un processus métier et vous avez un changement atomique dans un document.
Mais il s'avère que cela ne fonctionne pas. Les données doivent être normalisées pour éviter la redondance du stockage. Ils doivent être normalisés pour les requêtes analytiques. En fin de compte, le modèle de données évolue - et le document qui hier pourrait enregistrer toutes les informations nécessaires à un scénario d'entreprise aujourd'hui doit être développé et complété.
Les problèmes d'atomicité se manifestent-ils? dans quelle mesure les modèles de données sont liés aux modèles de cohérence - l'avènement des transactions et de la réplication synchrone rend la plupart des modèles dans NoSQL inutiles.
Modèles de données
Parlons maintenant de la prochaine histoire - l'histoire avec des modèles de données.
Groupes de modèles de données inventés après SQL:
- Valeur clé
- Documentaire
- Magasin Colonne large;
- Serveur de structure de données (pour Redis);
- Bases de données graphiques.
Cool! Nous avons tellement de modèles de données! Et comment évoluent-ils bien?
Il s'agit d'une thèse, principalement liée à la soi-disant hyper-convergence, lorsque tous les projets modernes utilisent des serveurs à serveur unique bon marché et que les entreprises cessent d'acheter des machines évolutives verticalement.
L'hyperconvergence est entrée dans nos vies si profondément qu'aujourd'hui, même à l'intérieur des machines à échelle verticale, le cas échéant, il existe déjà un logiciel évolutif horizontal - regardez comment PureStorage fonctionne ou, si vous vous souvenez, la nuit, Nutanix. Bien sûr, ils vendent des armoires aux gens, mais ces armoires sont disposées à l'intérieur comme des racks ordinaires chez un hébergeur.
Autrement dit, la mise à l'échelle horizontale est une tendance qui met la pression sur tout le monde, y compris les inventeurs de nouveaux modèles de données. Alors, quels modèles de données sont bons pour la mise à l'échelle horizontale et lesquels sont mauvais?
Est-ce bon ou mauvais pour la mise à l'échelle horizontale? En fait, la réponse est assez controversée, nous y reviendrons plus tard.
Redis
Lorsque Redis a ajouté le cluster Redis, il s'est avéré que toutes les opérations du modèle de données ne s'étalonnent pas normalement horizontalement.

Ceci est une citation de la documentation où ils écrivent que quelque chose fonctionne pour eux sur un fragment particulier, et que quelque chose fonctionne vraiment comme dans un vrai cluster.
Le problème fondamental de cette approche est le même que dans MySQL, que nous avons ramassé et serré la main. Autrement dit, le développeur dispose de deux modèles de données:
- Dans l'un, il pense dans le cadre de l'algèbre relationnelle.
- Puis, quand il pense au partage indépendant, il pense au modèle de données de l'algèbre relationnelle aux fragments.
Un bon modèle de données devrait être universel . Ce qui est beau dans l'algèbre relationnelle - le résultat d'une projection est une relation, le résultat de tout opérateur est une relation. Et dès que nous commençons manuellement à partager MySQL sur le cluster, nous perdons cela.
Cependant, Redis ajoute un cluster Redis car
tout le monde veut évoluer horizontalement .
Bases de données graphiques
Les bases de données graphiques sont un bon exemple qui aide à
séparer les concepts de mise à l'échelle horizontale de l'informatique et du stockage . Les informations peuvent toujours être divisées par un nombre quelconque de nœuds. Mais si la base de données est par nature conçue pour traiter les données qu'elle stocke et que ces calculs ne sont pas mis à l'échelle horizontalement, alors le problème se pose d'un stockage horizontal efficace qui permet aux calculs de fonctionner.
Examinons le problème de la mise à l'échelle des SGBD graphiques - les SGBD SQL sont confrontés à des barrières de mise à l'échelle très similaires.
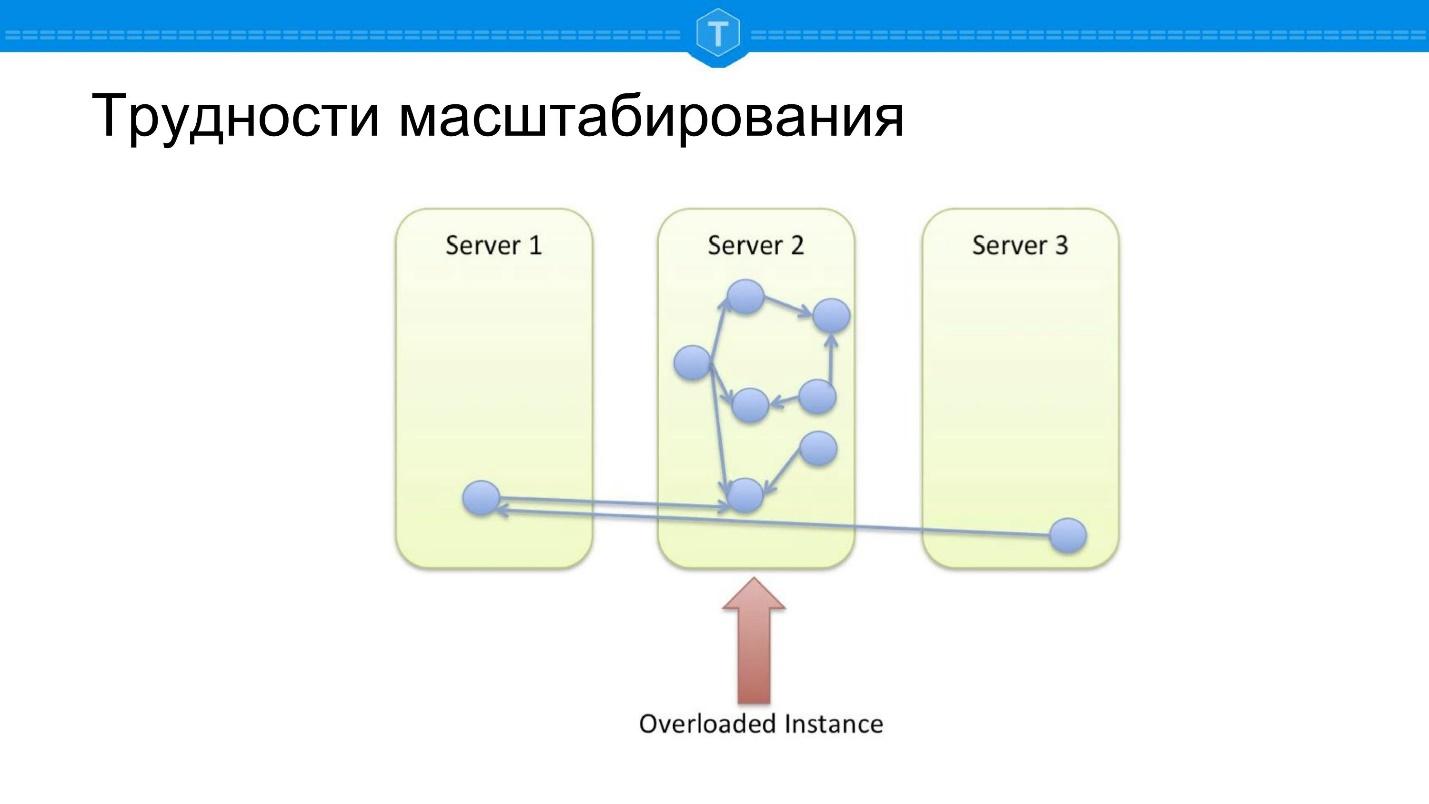
Prenez la base de données locale dans laquelle le graphique est stocké. Tôt ou tard, un nœud est rempli et nous commençons à utiliser d'autres nœuds. Dès que nous utilisons plus d'un nœud, le nœud central devient surchargé, car la localité des requêtes est perdue. Certaines requêtes sur le graphique sont obligées de parcourir plusieurs nœuds physiques, c'est-à-dire que des retards sur le réseau apparaissent.
Supposons que nous ayons fait quelque chose de différent - ils ont tout pris et tout cassé avec une bonne fonction de partage. Nous calculons un certain hachage, répartissant au hasard toutes les données de notre cluster de manière assez aléatoire - et nous obtenons un autre problème.

Si dans le schéma précédent, au moins certaines requêtes fonctionnaient correctement, alors
100% des requêtes sont stupides ici , car la plupart des requêtes de base de données sont liées à la
traversée de graphe. Tout détour par le nœud doit aller quelque part et, le plus souvent, pour calculer la demande, vous devez vous rendre sur un autre nœud.

L'idée se présente de tailler approximativement, comme le montre le diagramme ci-dessus: trouver des clusters et les placer sur vos nœuds: les sous-ensembles étroitement connectés sont placés ensemble, les sous-ensembles faiblement connectés sont espacés.
C'est une option idéale, mais l'
option idéale n'existe qu'en théorie . Les données en direct ne se prêtent pas au partitionnement statique. Pour implémenter cette approche, nous devons détecter automatiquement les clusters sur un ensemble changeant dynamiquement, déplacer constamment les nœuds en fonction des liaisons émergentes et disparaissantes.
Par conséquent, Neo4j est généralement mis à l'échelle comme les bases de données SQL classiques. Ils travaillent sur le sharding depuis un certain temps, essayant de résoudre les problèmes décrits.
La thèse que j'ai avancée est que la
mise à l'échelle horizontale met la
pression sur tout le monde , et tous les modèles de données seront tôt ou tard obligés de l'implémenter. Mais certains modèles resteront avec nous, d'autres non.
Ainsi, par exemple, si nous considérons les bases de données de valeurs-clés et de documents sous forme pure, alors mon affirmation est qu'elles ne le seront pas. Si vous regardez les bases de données graphiques, elles occupent déjà un segment important, mais sont sous la pression d'une mise à l'échelle horizontale.
Les bases de données graphiques disparaîtront-elles? Il est plus probable que des
colonnes, comme les documents, soient incluses dans tous les produits . Cette tendance est appelée bases de données multimodèles, et plus loin dans le rapport, je donnerai un exemple de la façon dont cela peut fonctionner dans la pratique. Mais pour l'instant, comme une autre illustration de la tendance des bases de données multimodèles, regardons JSON.
Json
Vous trouverez ci-dessous un exemple de la manière dont fonctionne une tendance qui devient globale.
Je maintiens que toute base de données qui est même capable de prendre en charge JSON de quelque manière que ce soit le prendra en charge.
Peut-être que certaines bases de données pour le calcul matriciel ne prendront pas en charge JSON. Mais il est très probable que cela vous sera utile. Et tout le reste le sera certainement.
| MySQL
| PostgreSQL
| Redis
| Couchbase
| Cassandra
| Neo4j
|
Stockage JSON
| Oui
| Oui
| Oui
| Oui
| Oui
| Oui!
|
Opérations sur le terrain JSON
| Oui
| Oui
| Oui
| Oui
| Non
| Non
|
Requête Json
| Oui
| Oui
| Non
| Oui
| Oui
| Non
|
Index secondaire JSON
| Oui
| Oui
| Non
| Oui
| Non
| Non
|
Ce tableau vous permet de voir visuellement ce qui se passe avec les modèles de données. Les bases de données relationnelles dans leur prise en charge de JSON sont même en avance sur celles non relationnelles de la même Cassandra. Il n'a pas de clés secondaires pour les champs JSON. Et même les bases de données graphiques commencent également à inclure JSON, car
tout le monde a besoin de JSON .
Ainsi, les bases de données multimodèles, et en particulier JSON en tant que type de données que l'on retrouve dans presque tous les produits, sont ce qui restera de NoSQL sérieusement et pendant longtemps.
Mais si toutes les bases de données prennent en charge JSON, pourquoi avez-vous besoin de bases de données NoSQL?Il ne reste qu'une seule histoire: la mise à l'échelle horizontale. Nous voulons évoluer horizontalement, et c'est pourquoi nous utilisons autre chose que MySQL ou PostgreSQL.

Ceci est le discours de Thomas Ulin, VP MySQL Engineering chez Oracle, qui parle de l'avenir de MySQL. La même chose se produit dans la communauté Postgres et d'autres produits relationnels. La pression de la mise à l'échelle horizontale affecte 100% des produits en raison de la transition vers l'hyper-convergence et le cloud computing.
Thomas dit que leur vision est un produit avec une haute disponibilité et une évolutivité prête à l'emploi. Nous parlons de haute disponibilité principalement InnoDB Cluster, c'est la réplication de groupe + InnoDB. Une telle base de données ne meurt jamais, même si elle est frappée avec un marteau.
Ensuite, Thomas écrit "
mise à l'échelle des fonctionnalités intégrées " - "nous avons créé toutes ces fonctionnalités". Le fait est qu'à travers x versions (je pense que x = 2, 3), ils recevront MySQL Cluster sous sa forme pure, qui supportera SQL sur le cluster, le stockage JSON dans le cluster.
Déjà aujourd'hui,
MySQL a un protocole X très similaire à MongoDB et est conçu pour fonctionner avec JSON.
SQL dans NoSQL
Regardons maintenant le mouvement de l'autre côté. Afin de déclarer la mort, vous devez regarder non seulement comment SQL adopte les principes de NoSQL, mais aussi vice versa.
| Mongodb
| Couchbase
| Cassandra
| Redis
|
Schéma de données
| Oui *
| Non
| Oui
| Non
|
NULLs / Absent values
| Oui *
| Oui
| Oui
| Non
|
Se joint
| Oui
| Oui
| Non
| Non
|
Clés secondaires
| Oui *
| Oui
| Oui, mais ...
| Non
|
GROUPE PAR
| Oui *
| Oui
| Non
| Non
|
JDBC / ODBC
| Non
| Oui
| Non
| Non
|
Ici, en fait, il y a aussi des idées intéressantes. J'ai pris, à mon avis, les dirigeants. Je suis d'accord que tout n'est pas là, par exemple, Elastic est également un leader NoSQL. Mais Elastic est toujours principalement une solution pour la recherche en texte intégral, donc je ne l'ai pas incluse dans le tableau.
Les bases de données des séries temporelles comme une tendance que je ne touche pas. Il y a une thèse parmi les séries chronologiques de mouvements selon laquelle il s'agit d'une niche distincte, similaire aux bases de données graphiques, mais si vous creusez plus profondément, Postgres se trouve sous le capot.
Couchbase
À mon avis, Couchbase a le plus large éventail de possibilités du monde SQL. Tout le monde sait que
Couchbase est Memcached . Dormando (
Alan Kasindorf ), l'un des développeurs de Memcached avait une vision du produit complètement différente, qui n'impliquait pas de mise à l'échelle horizontale. Par conséquent, Memcache bifurque afin de se mettre à l'échelle horizontalement. Cela s'est bien passé et a commencé à faire des affaires autour de lui, puis a fusionné avec CouchDB et ainsi de suite.
Couchbase se dit initialement qu'il s'agit d'une
base de données sans schéma . Memcache est à l'origine une valeur-clé très simple. Voyons maintenant comment cette auto-identification change avec le temps.
Par exemple, Couchbase a des clés secondaires et
les clés secondaires sont en fait le début du schéma . Si vous dites que vous avez certains champs par lesquels vous créez l'index, cela signifie que vous parlez déjà du schéma de ces documents que vous stockez.
De plus, comme Couchbase coupe progressivement toute l'histoire du passé de Memcache dans la documentation d'aujourd'hui, ils couperont également l'histoire de la cohérence éventuelle demain, bien qu'aujourd'hui il y ait encore beaucoup d'histoires sur le manque de cohérence en lecture - les clés secondaires sont finalement cohérentes.
Mais le hic, c'est que Couchbase a JDBC / ODBC. , Tableau ClickView — , CQL SQL.
— SQL., .

, - , , , - — , SQL.
, IS MISSING — , IS NULL?
JDBC, ODBC SQL ? 30-40 , SQL- SQL , , : look-in, , ..
, .
, , ., Couchbase JDBC/ODBC — . , — .
Secondary keys
, NoSQL — , — , . OrientDB, , , .
SQL- , ( , ), NoSQL, .
NoSQL- secondary keys. secondary keys?
( — ):
- , , . , range-, SQL . range- map/reduce .
- . index notes, . range- .., .
, , , , , . , .
. , NoSQL- SQL, , , .
: CockroachDB? :
, . , MySQL — legacy. , , ..
, NoSQL- legacy 10 . , , . SQL- , PostgreSQL, , MySQL Couchbase , True NewSQL.
, secondary keys. MongoDB SQL, . , JOINs, , .
Redis No, . Redis , — . , , , .
, Redis — , - . , Redis-, SQL. , Redis SQLite, — storage — Redis', in memory.
NoSQL , , ?
, NoSQL . , , , SQL . SQL .
schemaless , , , waterfall : agile, - . , , CREATE TABLE, .
, online alter table. Oracle , .
SQL , .
MongoDB — , .
MongoDB , schemaless. . , , strict. validation level validation action. Validation level , .
, , - . , , . validation action reject, warn: warning, validation action.
. , MongoDB ( Tarantool), .
Cassandra JSON, . — , . , , NoSQL, .
-, NoSQL SQL .

eventually consistent , , ,
. , — . .
?
, , . BigQuery , , Vertica, .
NoSQL . , SELECT LTP, LTP - Key-value.
, NoSQL- .
SELECT JOIN , , ,
— ..
NoSQL:
,
, , .
domain-specific languages .
NoSQL DSL. —
RethinkDB ReQL . , — domen specific language. Python, JavaScript .. — . SQL , .
ReQL, . ReQL , , — . RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
, , . , , , , . .
. , , relations. , relation , , relations ..
UPSERT:
Il ne s'agit pas entièrement de NoSQL, mais c'est une tendance qui me semble très importante - il s'agit d'un
stockage optimisé en écriture - qui, à mon avis, restera avec nous sérieusement et pendant longtemps.
Ni SQL ni NoSQL ne contiennent d'instructions écrites uniquement par nature. Même absent, qui se trouve dans MongoDB, dans un certain nombre de cas, lit également les données. L'insertion est également une opération de lecture, car si un ID est déjà défini dans le document, vous devez vérifier qu'il n'y en a pas.
Vous dites - s'il y a des index, alors nous devons lire. Mais
même s'il existe des index, la lecture n'est pas toujours nécessaire . L'idée est la suivante: vous ne voulez en aucun cas lire, vous n'avez pas besoin de le faire, vous ne vous souciez pas du résultat de la lecture. Vous souhaitez ajouter des données à la base de données si elles n'existent pas déjà. S'ils existent, disons que vous remplacez leur ancienne version par une nouvelle ou que vous exécutez une sorte de commande de fusion. Autrement dit, vous devez inventer une
nouvelle sémantique pour ne pas lire.
À mon avis, pas une seule base de données ne fournit cela maintenant, mais l'attractivité des algorithmes optimisés en écriture est si grande que je veux vraiment cette possibilité. Parce que grâce à un stockage optimisé en écriture, les arborescences LSM (RocksDB, LevelDB et autres) les
performances d'écriture sans lecture sont supérieures de 2 ordres de grandeur aux performances d'écriture avec lecture . Au lieu de 10 000 requêtes par seconde, il peut y en avoir un million sur un nœud.
C'est pourquoi la base de données des séries temporelles gagne maintenant car il lui manque cet écart sémantique. Le flux de données qui y arrive est clairement défini comme une série chronologique et est écrit très rapidement et de manière compacte dans la base de données, en particulier. car vous n'avez pas besoin de vérifier l'unicité. Il s'agit d'un ordre de grandeur plus rapide simplement parce que dans les bases de données traditionnelles, il n'y a pas d'opération sémantique de ce type qui serait uniquement en écriture.
Je pense que cela va apparaître.

Où tout cela va-t-il ensuite? Si vous regardez très loin, l'innovation ne s'arrête pas à NoSQL et NewSQL. Notre compréhension de l'information évolue constamment.
À mon avis, l'une des tendances les plus importantes de l'avenir est de supprimer de moins en moins les informations.
Pour cela, toute une série de produits sont nés, appelés bases de données temporelles.
Après NewSQL: base de données temporelle
Vous trouverez ci-dessous des captures d'écran de Microsoft SQL Server. C'est une base de données qui vous permet de poser des questions à un moment donné: il y a SELECT pour l'état actuel, mais il est toujours possible de faire SELECT pour une certaine date dans le passé.

Cela engendre un certain nombre de nouvelles applications de base de données. Tout d'abord, vous pouvez retracer l'historique d'un objet. Deuxièmement, vous pouvez calculer automatiquement des groupes, des rapports par période. Vous n'avez pas besoin de créer des tables séparées pour cela - vous avez une représentation naturelle dans une table: une entité - une table.
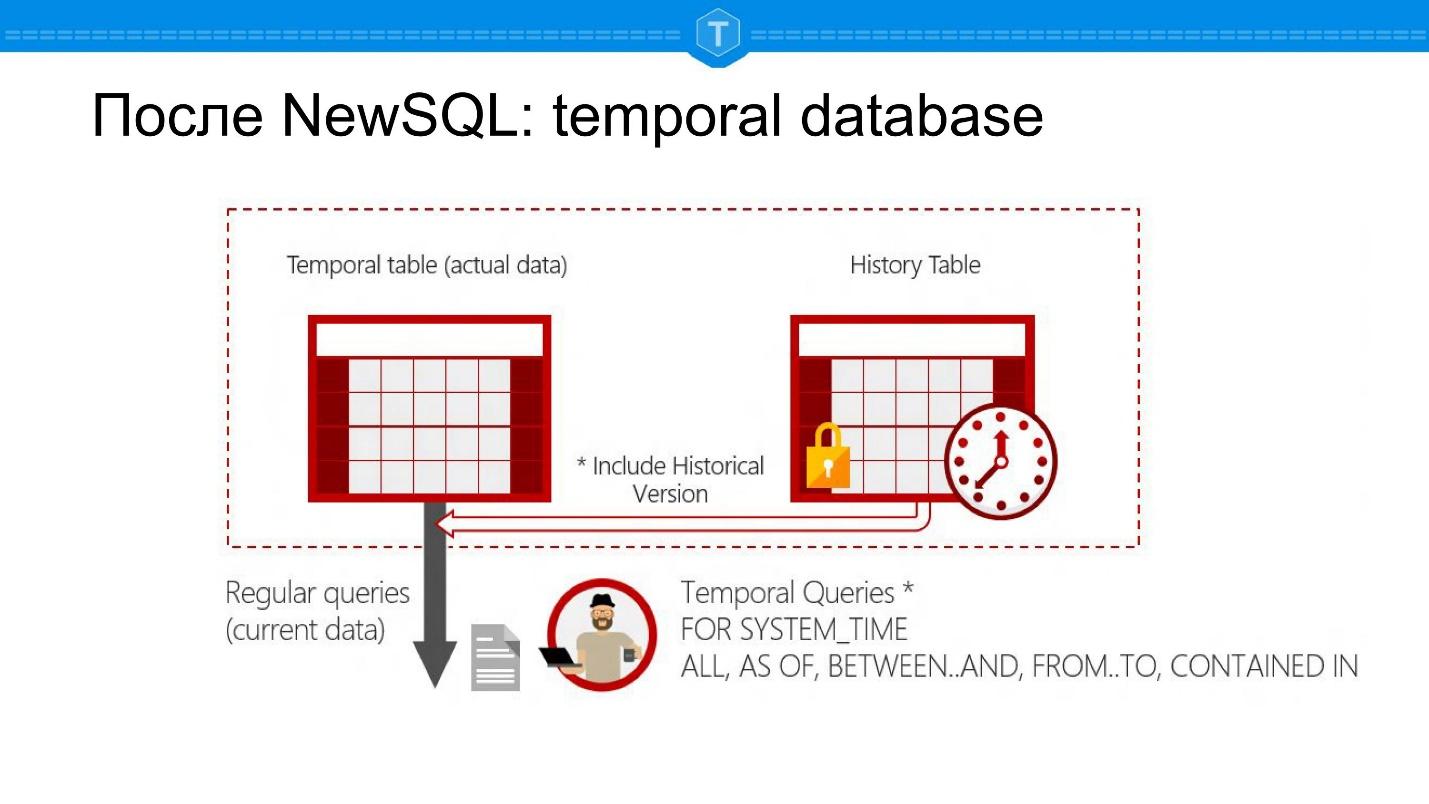
Du point de vue de la structure interne, il s'agit en fait du tableau principal et du tableau avec l'historique. Chaque ligne est associée à deux temps connus du système. Ce ne sont pas seulement deux colonnes que vous avez ajoutées, mais des données que le système prend en charge automatiquement:
- l'heure à laquelle l'enregistrement a été ajouté à la base de données,
- heure de l'événement.
Ce sont des moments différents, aussi amusants soient-ils.
Supposons qu'Ivan Ivanovich soit décédé le 17 novembre et que ce dossier ait été entré dans la base de données le 20 novembre - ces deux heures sont stockées dans ces bases de données.
À mon avis, c'est également l'une des tendances fondamentales. Pourquoi est-ce que je pense que oui? Si nous revenons aux clés secondaires et à la cohérence éventuelle, le stockage absolu de tout vous permet simplement de résoudre ce problème avec élégance.
Si nous n'avons jamais besoin de supprimer quoi que ce soit de la base de données, alors notre base de données est toujours cohérente - une histoire tellement intéressante!
Liens utiles
FAQ- Y a-t-il des développements sur la création d'une nouvelle base de données qui ne s'appliqueront pas à MySQL, PostgreSQL, MongoDB, etc.?
Dans le bon sens, la question est: y aura-t-il de nouvelles bases de données, des startups? Je pense qu'ils apparaîtront de moins en moins. La tempête s'est apaisée, et maintenant nous verrons plus tôt le départ que l'arrivée, CockroachDB a été l'un des derniers à arriver.
Venons-en au fait. Mon professeur à l'université a dit que le SGBD est une zone éternellement verte. Par conséquent, nous verrons toujours une sorte de mouvement. Mais je pense que dans un avenir proche, des produits fondamentalement différents n'apparaîtront pas, il y aura convergence, pas boom.
- Pas une question, mais plutôt un ajout: SQL essaie souvent de faire des index de recouvrement pour que le résultat de la requête SQL ne concerne pas le niveau de stockage, mais soit immédiatement obtenu à partir de l'index. L'index lui-même est en fait un cas particulier du graphique. Alors, la tendance est peut-être à ce que la base de données entière se transforme progressivement en un index graphique abrupte?
C'est une merveilleuse histoire que tous les représentants des bases de données graphiques aiment raconter à leurs clients - cela ne fonctionne pas! Parce qu'il existe de nombreuses façons de mettre à jour les index, et il existe de nombreuses options d'indexation, mais tout le monde n'a pas de graphique! Calmons-nous - tout comme tout n'est pas relationnel, tout le monde n'est pas un graphique.
- À votre avis, où iront Elastic et autres? Je parle du fait qu'il commence à résoudre des problèmes très étranges - il essaie de faire semblant des séries chronologiques et une base analytique pour travailler avec des journaux. Il semble que personne ne l'utilise pour la recherche de texte.
L'élastique n'a pas à se déplacer n'importe où, car l'élastique se sent bien. Il résout un problème commercial spécifique - c'est une recherche efficace et tout ce qui concerne cet écosystème.
Je pense que tout vient principalement du fait qu'Elastic essaie d'être tout. Mais ici, la question vient de la tâche, la tâche élastique est très similaire aux tâches de série chronologique, elle est donc justifiée. Elastic est bon pour rechercher à travers d'énormes tableaux des mêmes journaux, etc.
Il y a un cas plus étroit - c'est juste une recherche en texte intégral, mais vous n'en ferez pas grand cas. Il faut faire plus pour se différencier des concurrents en premier lieu. Par conséquent, tout cela se produit.
Mais je ne pense pas qu'Elastic fera des transactions bancaires demain. Tout va au point que Couchbase, par exemple, sera - sinon des transactions bancaires, mais quelque chose de si rapide.
Actualités
Très prochainement, le 21 juin, la Conférence Tarantool aura lieu à Moscou - ou brièvement T + Conf - une conférence non seulement sur Tarantool lui-même, mais sur l'utilisation de l' informatique en mémoire en général .
- Konstantin Osipov prévoit de rédiger un rapport dans lequel il examinera l'architecture de Vinyl, ses capacités et, plus important encore, les mécanismes de réglage et de surveillance des performances spécifiques à ce moteur de manière aussi cohérente et détaillée que possible.
- Vladimir Perepelitsa dans un format tutoriel, veut montrer que Tarantool est une base de données qui a un grand potentiel pour être utilisée comme serveur d'applications.
- Vladislav Zaitsev d'aller aborder ce sujet de son côté - du côté de l'Internet des objets et de dire , en particulier, pourquoi le système de contrôle IoT.