Chacun de nous fait une corvée. Tout le monde écrit du code passe-partout. Pourquoi? N'est-il pas préférable d'automatiser ce processus et de travailler uniquement sur des tâches intéressantes? Lisez cet article si vous souhaitez que l'ordinateur effectue un tel travail pour vous.
 Cet article est basé sur une transcription d'un rapport de Zack Sweers, développeur d'applications mobiles Uber, qui a pris la parole lors de la conférence MBLT DEV en 2017.
Cet article est basé sur une transcription d'un rapport de Zack Sweers, développeur d'applications mobiles Uber, qui a pris la parole lors de la conférence MBLT DEV en 2017.
Uber compte environ 300 développeurs d'applications mobiles. Je travaille dans une équipe appelée «plateforme mobile». Le travail de mon équipe est de simplifier et d'améliorer au maximum le processus de développement d'applications mobiles. Nous travaillons principalement sur les frameworks internes, les bibliothèques, les architectures, etc. En raison de l'effectif important, nous devons réaliser des projets à grande échelle dont nos ingénieurs auront besoin à l'avenir. Ce peut être demain, ou peut-être le mois prochain ou même un an.
Génération de code pour l'automatisation
Je voudrais démontrer la valeur du processus de génération de code, ainsi que considérer quelques exemples pratiques. Le processus lui-même ressemble à ceci:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
Ceci est un exemple d'utilisation de Kotlin Poet. Kotlin Poet est une bibliothèque avec une bonne API qui génère du code Kotlin. Alors que voit-on ici?
- FileSpec.builder crée un fichier appelé « Présentation ».
- .addComment () - Ajoute un commentaire au code généré.
- .addAnnotation () - Ajoute une annotation de type Auteur .
- .addMember () - ajoute une variable " nom " avec un paramètre, dans notre cas c'est " Zac Sweers ". % S - type de paramètre.
- .useSiteTarget () - Installe SiteTarget.
- .build () - complète la description du code qui sera généré.
Après la génération de code, les éléments suivants sont obtenus:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
Le résultat de la génération de code est un fichier avec le nom, le commentaire, l'annotation et le nom de l'auteur. La question se pose immédiatement: "Pourquoi dois-je générer ce code si je peux le faire en quelques étapes simples?" Oui, vous avez raison, mais que faire si j'ai besoin d'un millier de ces fichiers avec différentes options de configuration? Que se passe-t-il si nous commençons à modifier les valeurs de ce code? Et si nous avons plusieurs présentations? Et si nous avons beaucoup de conférences?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
En conséquence, nous arriverons à la conclusion qu'il est tout simplement impossible de maintenir un tel nombre de fichiers manuellement - il est nécessaire d'automatiser. Par conséquent, le premier avantage de la génération de code est de se débarrasser du travail de routine.
Génération de code sans erreur
Le deuxième avantage important de l'automatisation est un fonctionnement sans erreur. Tout le monde fait des erreurs. Cela se produit surtout souvent lorsque nous faisons la même chose. Les ordinateurs, au contraire, font parfaitement ce travail.
Prenons un exemple simple. Il existe une classe Personne:
class Person(val firstName: String, val lastName: String)
Supposons que nous voulons lui ajouter de la sérialisation en JSON. Nous le ferons en utilisant la bibliothèque
Moshi , car elle est assez simple et idéale pour la démonstration. Créez un PersonJsonAdapter et héritez de JsonAdapter avec un paramètre de type Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
Ensuite, nous implémentons la méthode fromJson. Il fournit un lecteur pour lire les informations qui seront finalement retournées à la personne. Ensuite, nous remplissons les champs avec le prénom et le nom et obtenons la nouvelle valeur de Personne:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
Ensuite, nous regardons les données au format JSON, les vérifions et les entrons dans les champs nécessaires:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
Est-ce que cela fonctionnera? Oui, mais il y a une nuance: les objets que nous lisons doivent être contenus dans JSON. Afin de filtrer les données excédentaires pouvant provenir du serveur, ajoutez une autre ligne de code:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
À ce stade, nous avons réussi à contourner le domaine du code de routine. Dans cet exemple, seulement deux champs de valeur. Cependant, ce code a un tas de sections différentes où vous pourriez soudainement tomber en panne. Soudain, nous avons fait une erreur dans le code?
Prenons un autre exemple:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
Si vous avez au moins un problème tous les 10 modèles environ, cela signifie que vous aurez certainement des difficultés dans ce domaine. Et c'est le cas lorsque la génération de code peut vraiment vous être utile. S'il y a beaucoup de classes, vous ne pourrez pas travailler sans automatisation, car tout le monde autorise les fautes de frappe. Avec l'aide de la génération de code, toutes les tâches seront effectuées automatiquement et sans erreur.
La génération de code présente d'autres avantages. Par exemple, il donne des informations sur le code ou vous indique si quelque chose ne va pas. La génération de code sera utile pendant la phase de test. Si vous utilisez le code généré, vous pouvez voir à quoi ressemblera réellement le code de travail. Vous pouvez même exécuter la génération de code pendant les tests pour simplifier votre travail.
Conclusion: il vaut la peine de considérer la génération de code comme une solution possible pour se débarrasser des erreurs.
Examinons maintenant les outils logiciels qui aident à la génération de code.
Les outils
- Les bibliothèques JavaPoet et KotlinPoet pour Java et Kotlin, respectivement. Ce sont les normes de génération de code.
- Patternisation. Un exemple populaire de modèles pour Java est Apache Velocity et pour les guidons iOS.
- SPI - Interface du processeur de service. Il est intégré à Java et vous permet de créer et d'appliquer une interface, puis de la déclarer dans un JAR. Lorsque le programme est exécuté, vous pouvez obtenir toutes les implémentations prêtes à l'emploi de l'interface.
- Compile Testing est une bibliothèque de Google qui aide aux tests de compilation. En termes de génération de code, cela signifie: "Voici ce que j'attendais, mais voici ce que j'ai finalement obtenu." La compilation démarrera en mémoire, puis le système vous dira si ce processus s'est terminé ou quelles erreurs se sont produites. Si la compilation est terminée, il vous sera demandé de comparer le résultat avec vos attentes. La comparaison est basée sur le code compilé, alors ne vous inquiétez pas de choses comme la mise en forme du code ou toute autre chose.
Outils de création de code
Il existe deux outils principaux pour créer du code:
- Traitement des annotations - vous pouvez écrire des annotations dans le code et demander au programme des informations supplémentaires à leur sujet. Le compilateur fournira des informations avant même d'avoir fini de travailler avec le code source.
- Gradle est un système d'assemblage d'applications avec de nombreux hooks (hook - interception d'appels de fonction) dans son cycle de vie d'assembly de code. Il est largement utilisé dans le développement Android. Il vous permet également d'appliquer la génération de code au code source, qui est indépendant de la source actuelle.
Considérons maintenant quelques exemples.
Couteau à beurre
Butter Knife est une bibliothèque développée par Jake Wharton. Il est une figure bien connue de la communauté des développeurs. La bibliothèque est très populaire parmi les développeurs Android car elle permet d'éviter la grande quantité de travail de routine auquel presque tout le monde est confronté.
Habituellement, nous initialisons la vue de cette façon:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
Avec Butterknife, cela ressemblera à ceci:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Et nous pouvons facilement ajouter un nombre illimité de vues, tandis que la méthode onCreate n'augmentera pas le code passe-partout:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Au lieu d'effectuer manuellement cette liaison à chaque fois, vous ajoutez simplement des annotations @BindView à ces champs, ainsi que les identifiants (ID) auxquels ils sont affectés.
La chose intéressante à propos de Butter Knife est qu'il va analyser le code et générer toutes ses sections similaires pour vous. Il a également une excellente évolutivité pour les nouvelles données. Par conséquent, si de nouvelles données apparaissent, il n'est pas nécessaire de réappliquer onCreate ou de suivre quelque chose manuellement. Cette bibliothèque est également idéale pour supprimer des données.
Alors, à quoi ressemble ce système de l'intérieur? La vue est recherchée par reconnaissance de code et ce processus est effectué au stade du traitement des annotations.
Nous avons ce domaine:
@BindView(R.id.title) TextView title;
A en juger par ces données, elles sont utilisées dans une certaine FooActivity:
Elle a sa propre signification (R.id.title), qui agit comme la cible. Veuillez noter que lors du traitement des données, cet objet devient une valeur constante à l'intérieur du système:
C'est normal. C'est à cela que Butter Knife devrait avoir accès de toute façon. Il existe un composant TextView en tant que type. Le champ lui-même est appelé titre. Si, par exemple, nous créons une classe de conteneur à partir de ces données, nous obtenons quelque chose comme ceci:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
Ainsi, toutes ces données peuvent être facilement obtenues lors de leur traitement. Il est également très similaire à ce que fait Butter Knife à l'intérieur du système.
En conséquence, cette classe est générée ici:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
Nous voyons ici que toutes ces données sont rassemblées. Par conséquent, nous avons la classe cible ViewBinding de la bibliothèque java Underscore. À l'intérieur, ce système est organisé de telle manière que chaque fois que vous créez une instance de la classe, il exécute immédiatement toutes ces liaisons aux informations (code) que vous avez générées. Et tout cela est précédemment généré statiquement lors du traitement des annotations, ce qui signifie qu'il est techniquement correct.
Revenons à notre pipeline de logiciels:
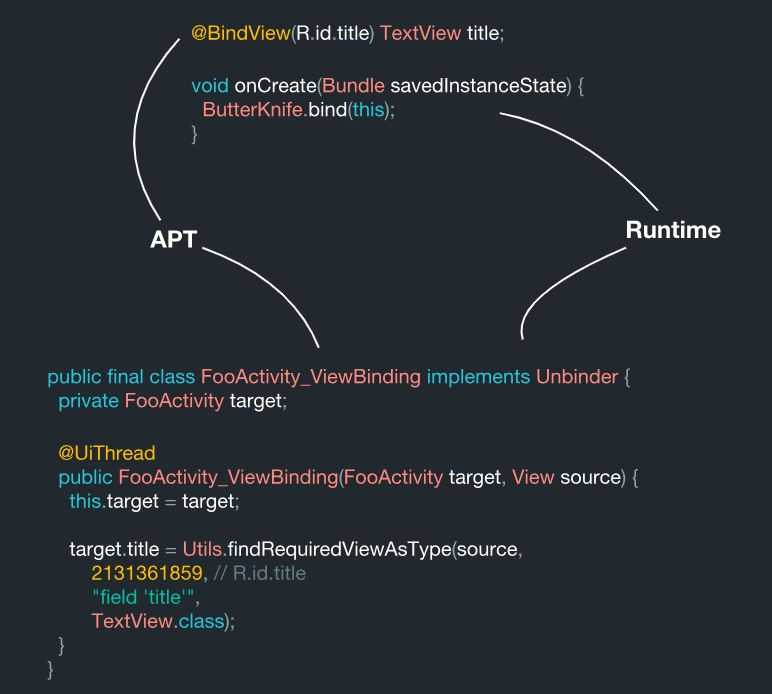
Pendant le traitement des annotations, le système lit ces annotations et génère la classe ViewBinding. Et puis pendant la méthode de liaison, nous effectuons une recherche identique pour la même classe d'une manière simple: nous prenons son nom et ajoutons le ViewBinding à la fin. En soi, une section avec un ViewBinding pendant le traitement est écrasée dans la zone spécifiée à l'aide de JavaPoet.
Rxbindings
RxBindings seul n'est pas responsable de la génération de code. Il ne gère pas les annotations et n'est pas un plugin Gradle. Ceci est une bibliothèque ordinaire. Il fournit des usines statiques basées sur le principe de la programmation réactive pour l'API Android. Cela signifie que, par exemple, si vous avez setOnClickListener, une méthode de clic apparaîtra qui retournera un flux d'événements (observables). Il agit comme un pont (modèle de conception).
Mais en réalité, il existe une génération de code dans RxBinding:
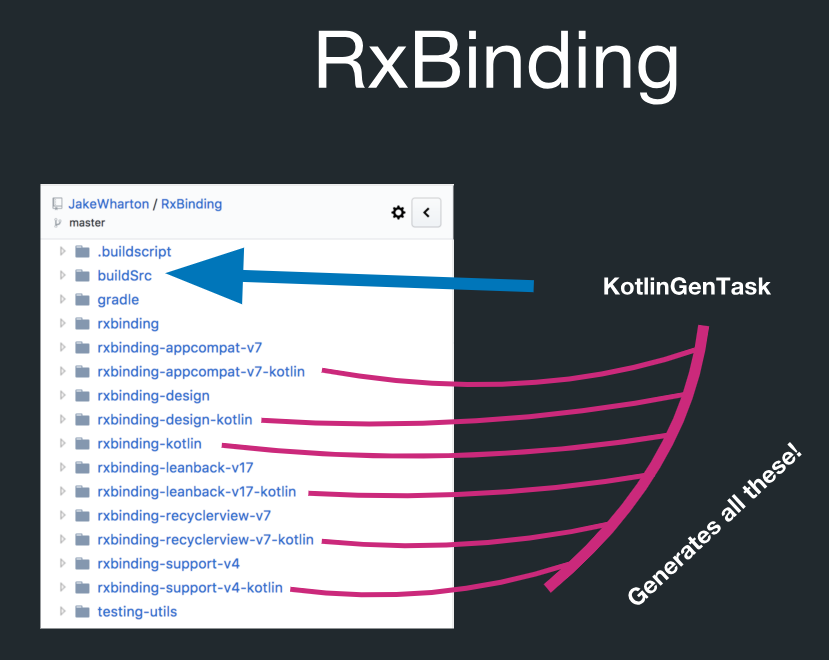
Dans ce répertoire appelé buildSrc, il y a une tâche Gradle appelée KotlinGenTask. Cela signifie que tout cela est réellement créé par la génération de code. RxBinding a des implémentations Java. Elle possède également des artefacts Kotlin qui contiennent des fonctions d'extension pour tous les types de cibles. Et tout cela est très strictement soumis aux règles. Par exemple, vous pouvez générer toutes les fonctions d'extension de Kotlin et vous n'avez pas besoin de les contrôler individuellement.
À quoi ça ressemble vraiment?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Voici une méthode RxBinding complètement classique. Les objets observables sont retournés ici. La méthode s'appelle les clics. Le travail avec les événements de clic a lieu «sous le capot». Nous omettons les fragments de code supplémentaires pour maintenir la lisibilité de l'exemple. À Kotlin, cela ressemble à ceci:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
Cette fonction d'extension renvoie des objets observables. Dans la structure interne du programme, il appelle directement l'interface Java habituelle pour nous. Dans Kotlin, vous devez changer cela en Type d'unité:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Autrement dit, en Java, cela ressemble à ceci:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Et le code Kotlin aussi:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Nous avons une classe RxView qui contient cette méthode. Nous pouvons remplacer les données correspondantes dans l'attribut cible, dans l'attribut name par le nom de la méthode et dans le type que nous développons, ainsi que dans le type de la valeur de retour. Toutes ces informations seront suffisantes pour commencer à écrire ces méthodes:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
Maintenant, nous pouvons directement substituer ces fragments dans le code Kotlin généré à l'intérieur du programme. Voici le résultat:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Service gen
Nous travaillons sur Service Gen chez Uber. Si vous travaillez dans une entreprise et que vous traitez avec des caractéristiques générales et une interface logicielle commune pour le backend et le côté client, que vous développiez des applications Android, iOS ou Web, cela n'a aucun sens de créer manuellement des modèles et des services pour le travail d'équipe.
Nous utilisons la bibliothèque
AutoValue de Google pour les modèles d'objets. Il traite les annotations, analyse les données et génère un code de hachage sur deux lignes, la méthode equals () et d'autres implémentations. Elle est également responsable du support des extensions.
Nous avons un objet de type Rider:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Nous avons des lignes avec ID, prénom, nom et adresse. Pour travailler avec le réseau, nous utilisons les bibliothèques Retrofit et OkHttp, et JSON comme format de données. Nous utilisons également RxJava pour la programmation réactive. Voici à quoi ressemble notre service API généré:
interface UberService { @GET("/rider") Rider getRider() }
Nous pouvons écrire tout cela manuellement, si nous le souhaitons. Et pendant une longue période, nous l'avons fait. Mais cela prend beaucoup de temps. Au final, cela coûte cher en temps et en argent.
Quoi et comment Uber fait aujourd'hui
La dernière tâche de mon équipe est de créer un éditeur de texte à partir de zéro. Nous avons décidé de ne plus écrire manuellement le code qui frappe ensuite le réseau, nous utilisons donc
Thrift . C'est quelque chose comme un langage de programmation et un protocole à la fois. Uber utilise Thrift comme langage pour les spécifications techniques.
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
Dans Thrift, nous définissons des contrats API entre le backend et le côté client, puis générons simplement le code approprié. Nous utilisons la bibliothèque
Thrifty pour analyser les données et JavaPoet pour la génération de code. À la fin, nous générons des implémentations à l'aide d'AutoValue:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Nous faisons tout le travail en JSON. Il existe une extension appelée
AutoValue Moshi , qui peut être ajoutée aux classes AutoValue à l'aide de la méthode statique jsonAdapter:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
Thrift contribue également au développement de services:
service UberService { Rider getRider() }
Nous devons également ajouter quelques métadonnées ici pour nous faire savoir quel résultat final nous voulons atteindre:
service UberService { Rider getRider() (path="/rider") }
Après la génération du code, nous recevrons notre service:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
Mais ce n'est là qu'un des résultats possibles. Un modèle. Comme nous le savons par expérience, personne n'a jamais utilisé un seul modèle. Nous avons de nombreux modèles qui génèrent du code pour nos services:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
En ce moment, nous avons environ 5-6 applications. Et ils ont de nombreux services. Et tout le monde passe par le même pipeline de logiciels. Écrire tout cela à la main serait fou.
Dans la sérialisation en JSON, «l'adaptateur» n'a pas besoin d'être enregistré dans Moshi, et si vous utilisez JSON, vous n'avez pas besoin de vous inscrire dans JSON. Il est également douteux de proposer aux salariés de réaliser la désérialisation en réécrivant le code via un graphe DI.
Mais nous travaillons avec Java, nous pouvons donc utiliser le modèle Factory, que nous générons via la bibliothèque
Fractory . Nous pouvons générer cela parce que nous connaissons ces types avant la compilation. Fractory génère un adaptateur comme celui-ci:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
Le code généré n'a pas l'air très bon. Si cela fait mal à l'œil, il peut être réécrit manuellement.
Ici, vous pouvez voir les types mentionnés précédemment avec les noms des services. Le système déterminera automatiquement les adaptateurs à sélectionner et les appellera. Mais ici, nous sommes confrontés à un autre problème. Nous avons 6000 de ces adaptateurs. Même si vous les divisez entre eux dans le même modèle, le modèle «Eats» ou «Driver» tombera dans le modèle «Rider» ou sera dans son application. Le code va s'étirer. Après un certain point, il ne peut même pas tenir dans un fichier .dex. Par conséquent, vous devez en quelque sorte séparer les adaptateurs:

Finalement, nous analyserons le code à l'avance et créerons un sous-projet fonctionnel pour celui-ci, comme dans Gradle:

Dans la structure interne, ces dépendances deviennent des dépendances Gradle. Les éléments utilisant l'application Rider en dépendent désormais. Avec eux, ils formeront les modèles dont ils ont besoin. En conséquence, notre tâche sera résolue, et tout cela sera réglementé par le système d'assemblage de code à l'intérieur du programme.
Mais ici, nous sommes confrontés à un autre problème: nous avons maintenant un nombre n de modèles d'usine. Tous sont compilés en divers objets:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
Dans le processus de traitement des annotations, il ne sera pas possible de lire uniquement les annotations des dépendances externes et de générer du code supplémentaire uniquement sur celles-ci.
Solution: nous avons un certain support dans la bibliothèque Fractory, ce qui nous aide d'une manière délicate. Il est contenu dans le processus de liaison des données. Nous introduisons les métadonnées en utilisant le paramètre classpath dans l'archive Java pour leur stockage supplémentaire:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
Maintenant, chaque fois que vous devez les utiliser dans l'application, nous allons dans le filtre du répertoire classpath avec ces fichiers, puis nous les extrayons à partir de là au format JSON pour savoir quelles dépendances sont disponibles.
Comment tout se combine
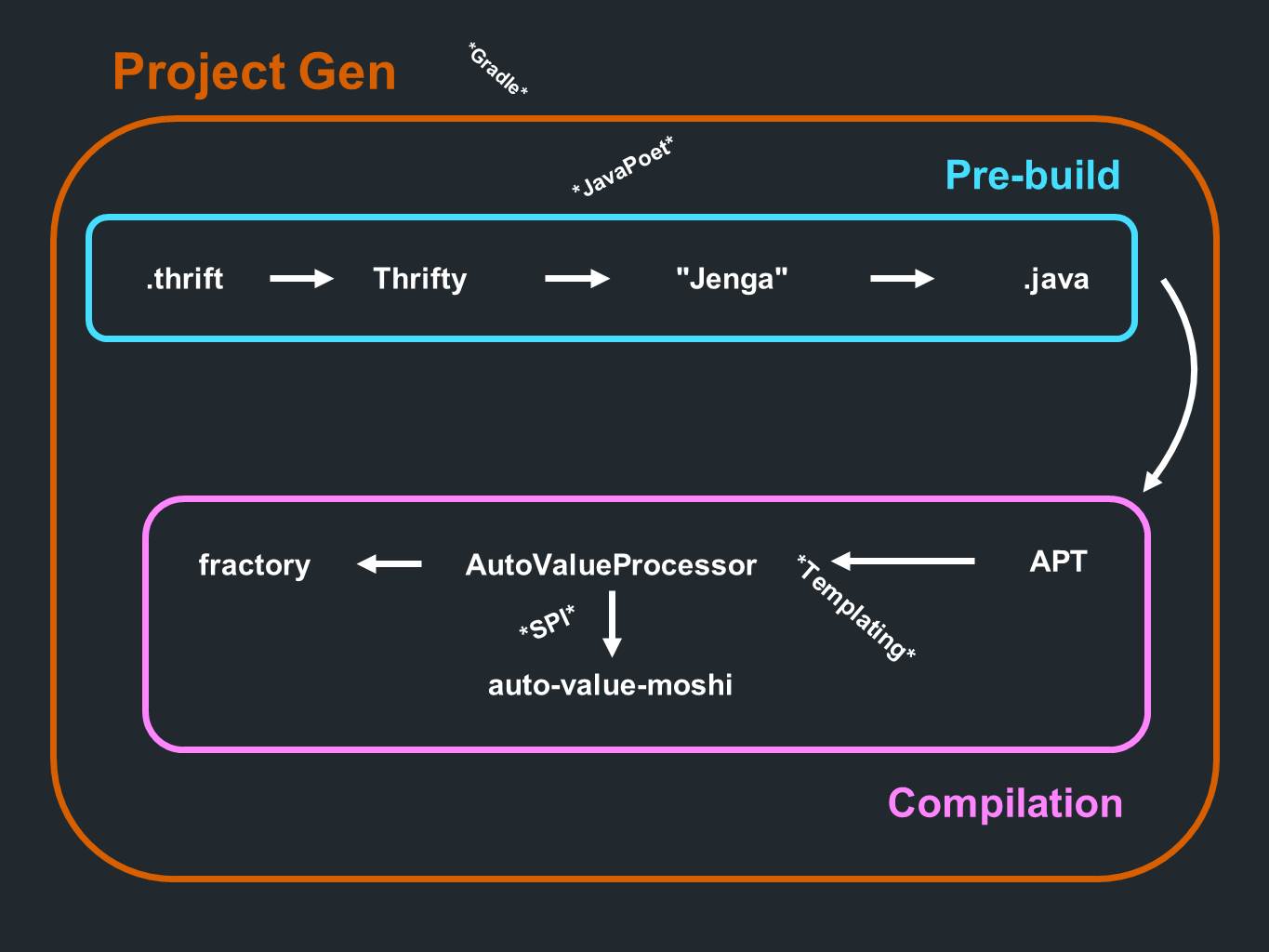
Nous avons un
Thrift . Les données de là vont à
Thrifty et passent par l'analyse. Ils passent ensuite par un programme de génération de code que nous appelons
Jenga . Il produit des fichiers au format Java. Tout cela se produit même avant la phase préliminaire du traitement ou avant la compilation. Et pendant le processus de compilation, les annotations sont traitées. C'est
au tour
d'AutoValue de générer une implémentation. Il appelle également
AutoValue Moshi pour fournir un support JSON.
Fractory est également
impliqué . Tout se passe pendant le processus de compilation. Le processus est précédé d'un composant pour créer le projet lui-même, qui génère principalement des sous-projets
Gradle .
Maintenant que vous voyez l'image complète, vous commencez à remarquer les outils mentionnés précédemment. Ainsi, par exemple, il y a Gradle, créant des modèles, AutoValue, JavaPoet pour la génération de code. Tous les outils sont non seulement utiles seuls, mais également en combinaison les uns avec les autres.Inconvénients de la génération de code
Il faut parler des pièges. Le inconvénient le plus évident est de gonfler le code et de perdre le contrôle de celui-ci. Par exemple, Dagger occupe environ 10% de tout le code de l'application. Les modèles occupent une part beaucoup plus importante - environ 25%.Chez Uber, nous essayons de résoudre le problème en jetant le code inutile. Nous devons effectuer une analyse statistique du code et comprendre quels domaines sont vraiment impliqués dans le travail. Quand nous le découvrons, nous pouvons faire quelques transformations et voir ce qui se passe.Nous prévoyons de réduire le nombre de modèles générés d'environ 40%. Cela permettra d'accélérer l'installation et le fonctionnement des applications, ainsi que de nous faire économiser de l'argent.Comment la génération de code affecte les délais de développement de projet
La génération de code, bien sûr, accélère le développement, mais le timing dépend des outils que l'équipe utilise. Par exemple, si vous travaillez à Gradle, vous le faites très probablement à un rythme mesuré. Le fait est que Gradle génère des modèles une fois par jour, et non quand le développeur le souhaite.En savoir plus sur le développement chez Uber et d'autres grandes sociétés.
Le 28 septembre, la 5e Conférence internationale des développeurs mobiles MBLT DEV débute à Moscou . 800 participants, haut-parleurs, quiz et puzzles pour ceux qui sont intéressés par le développement d'Android et iOS. Les organisateurs de la conférence sont e-Legion et RAEC. Vous pouvez devenir participant ou partenaire de MBLT DEV 2018 sur le site Web de la conférence .
Signaler la vidéo