
L'été dernier, le
concours sur le site de kaggle, dédié à la classification des images satellites des forêts amazoniennes, s'est terminé. Notre équipe a pris la 7e place sur 900+ participants. Malgré le fait que la compétition soit terminée depuis longtemps, presque toutes les méthodes de notre solution sont toujours applicables, non seulement pour les compétitions, mais aussi pour la formation de réseaux de neurones à vendre. Pour plus de détails sous cat.
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
Description de la tâche
Planet a préparé un ensemble d'images satellites en deux formats:
- TIF - RVB 16 bits + N, où N - proche infrarouge
- JPG - RVB 8 bits, qui sont dérivés de TIF et qui ont été fournis pour réduire le seuil d'entrée dans la tâche, ainsi que pour simplifier la visualisation. Lors du précédent concours à Kaggle, il était nécessaire de travailler avec des images multispectrales. non visuels, c'est-à-dire infrarouges, ainsi que les canaux avec une longueur d'onde plus longue, ont considérablement amélioré la qualité de la prédiction, à la fois en réseau et en méthodes non supervisées.
Géographiquement, les données ont été prises sur le territoire du bassin de l'Amazone, et sur les territoires des pays du Brésil, du Pérou, de l'Uruguay, de la Colombie, du Venezuela, de la Guyane, de la Bolivie et de l'Équateur, dans lesquelles des surfaces intéressantes ont été sélectionnées, dont les images ont été proposées aux participants.
Après avoir créé jpg à partir de tif, toutes les scènes ont été coupées en petits morceaux de taille 256x256. Et selon jpg reçu par les employés de Planet des bureaux de Berlin et de San Francisco, ainsi que via la plateforme Crowd Flower, un marquage a été effectué.
Les participants ont été chargés de prédire pour chaque tuile 256x256 l'une des marques météorologiques mutuellement exclusives:
Nuageux, Partiellement nuageux, Brume, Clair
Et aussi 0 ou plus de mauvais temps: agriculture, primaire, exploitation forestière sélective, habitation, eau, routes, culture itinérante, floraison, exploitation minière conventionnelle
Un total de 4 conditions météorologiques et 13 non météorologiques, météo mutuellement exclusive, mais pas de temps, mais si l'image est nuageuse, il ne devrait pas y avoir d'autres balises.

La précision du modèle a été estimée par la métrique F2:
De plus, toutes les étiquettes avaient le même poids et le premier F2 a été calculé pour chaque image, puis il y a eu une moyenne générale. Habituellement, ils le font un peu différemment, c'est-à-dire qu'une certaine métrique est calculée pour chaque classe, puis moyenne. La logique est que cette dernière option est plus interprétable, car elle vous permet de répondre à la question de savoir comment le modèle se comporte sur chaque classe particulière. Dans ce cas, les organisateurs ont opté pour la première option, qui, apparemment, est liée aux spécificités de leur entreprise.
Il y a 40 000 échantillons dans le train. Dans le test 40k. En raison de la petite taille de l'ensemble de données, mais de la grande taille des images, nous pouvons dire que c'est «MNIST sous stéroïdes»
Digression lyriqueComme vous pouvez le voir dans la description, la tâche est tout à fait compréhensible et la solution n'est pas sensée: il vous suffit de classer la grille. Et en tenant compte des spécificités du cuggle, vous pouvez également empiler un tas de modèles sur le dessus. Cependant, pour obtenir une médaille d'or, vous devez non seulement former en quelque sorte un tas de modèles. Il est impératif d'avoir de nombreux modèles de base diversifiés, chacun d'eux-mêmes montrant un résultat exceptionnel. Et déjà au-dessus de ces modèles, vous pouvez liquider l'empilement et d'autres hacks.
| membre | net | 1 recadrage | Tta | diff,% |
|---|
| alno | densenet121 | 0,9278 | 0,9294 | 0,1736 |
| nizhib | densenet169 | 0,9243 | 0,9277 | 0,3733 |
| romul | vgg16 | 0,9266 | 0,9267 | 0,0186 |
| ternaus | densenet121 | 0,9232 | 0,9241 | 0,0921 |
| albu | densenet121 | 0,9294 | 0,9312 | 0,1933 |
| kostia | resnet50 | 0,9262 | 0,9271 | 0,0907 |
| n01z3 | resnext50 | 0,9281 | 0,9298 | 0,1896 |
Le tableau montre les modèles de score F2 de tous les participants pour une seule culture et TTA. Comme vous pouvez le voir, la différence est faible pour une utilisation réelle, mais elle est importante pour le mode compétition.
Interaction d'équipeAlexander Buslaev
albuAu moment de sa participation au concours, il dirigeait toute la direction ml chez Geoscan. Mais depuis lors, il a traîné un tas de compétitions, est devenu le père de toutes les SAO dans la segmentation sémantique et est parti pour Minsk, ramant dans Mapbox, sur lequel l'
article a été
publié.Alexey Noskov
alnoChasseur universel ml. A travaillé chez Evil Martians. Maintenant retourné à Yandex.
Konstantin Lopukhin
kostialopuhinA travaillé et continue de travailler chez Scrapinghub. Depuis lors, Kostya a réussi à obtenir quelques médailles de plus et sans 5 minutes Kaggle Grandmaster
Arthur Cousin
n01z3Au moment de participer à ce concours, je travaillais chez Avito. Mais vers la nouvelle année,
la startup Lead Data Scientist de
Dbrain est passée à la blockchain. J'espère que nous ravirons bientôt la communauté avec nos compétitions avec dockers et marquages de lampes.
Evgeny Nizhibitsky
@nizhibLead Data Scientist chez Rambler & Co. De cette compétition, Eugene a découvert la capacité secrète de trouver des visages dans les compétitions d'images. Ce qui l'a aidé à faire glisser quelques compétitions sur la plateforme Topcoder. J'ai
parlé de l'un d'eux.
Ruslan
Baykulov romulEngagé dans le suivi des événements sportifs à Constanta.
Vladimir Iglovikov
ternausOn se souvient de vous pour un
article bourré d'action sur le harcèlement par les services secrets britanniques. Il a travaillé chez TrueAccord, mais a ensuite rejoint la jeunesse branchée Lyft. Où fonctionne la vision par ordinateur pour une voiture autonome. Continue de faire glisser les compétitions et a récemment reçu le Kaggle Grandmaster.
Notre association et le format de participation peuvent être qualifiés de typiques. La décision de s'unir était due au fait que nous avions tous des résultats serrés au classement. Et chacun de nous a vu son propre pipeline indépendant, qui était une solution complètement autonome du début à la fin. De plus, après la fusion, plusieurs participants se sont livrés au gerbage.
La première chose que nous avons faite a été de partager les plis. Nous nous sommes assurés que la distribution des classes dans chaque pli était la même que dans l'ensemble de données. Pour cela, la classe la plus rare a d'abord été sélectionnée, stratifiée par elle, car les images restantes ont été stratifiées par la deuxième classe la plus populaire, et ainsi de suite jusqu'à ce qu'il ne reste plus d'images.
Histogramme des classes de pli:
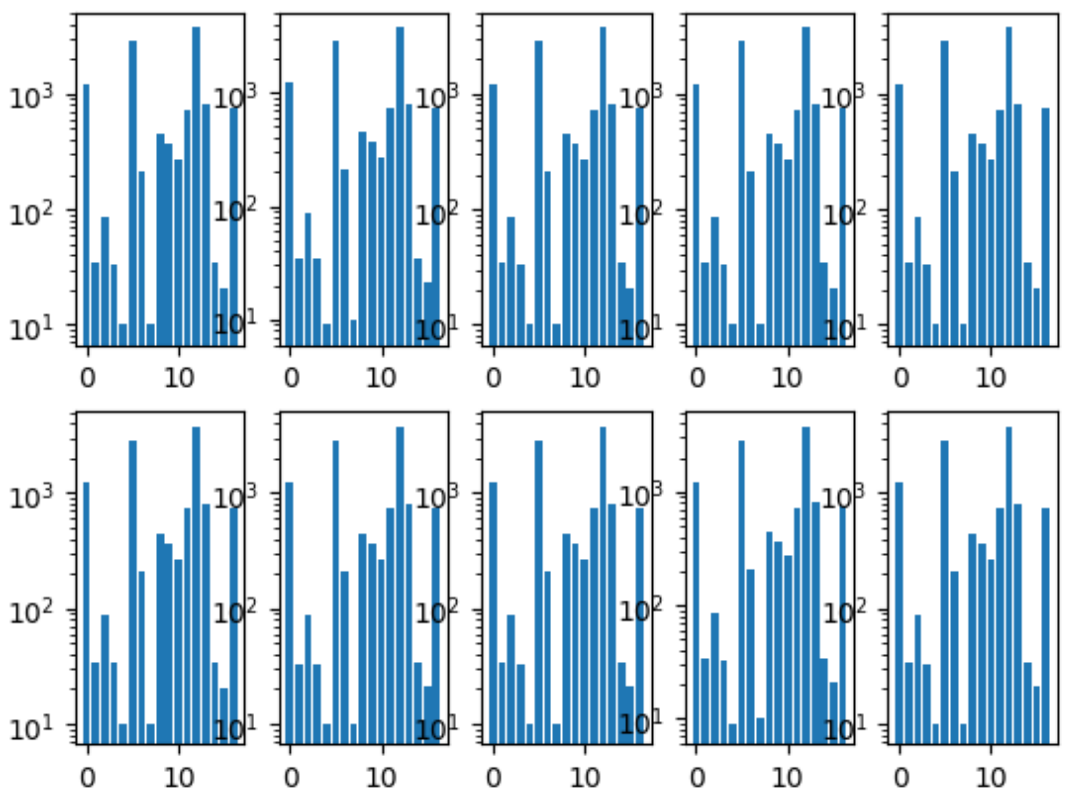
Nous avions également un référentiel commun, où chaque membre de l'équipe avait son propre dossier, dans lequel il organisait le code à sa guise.
Et nous nous sommes également mis d'accord sur le format des prédictions, car c'était le seul point d'interaction pour combiner nos modèles.
Formation au réseau de neuronesPuisque chacun de nous avait un pipeline indépendant, nous étions un échantillon de la grille du processus d'apprentissage optimal parallélisé par les gens.
Approche générale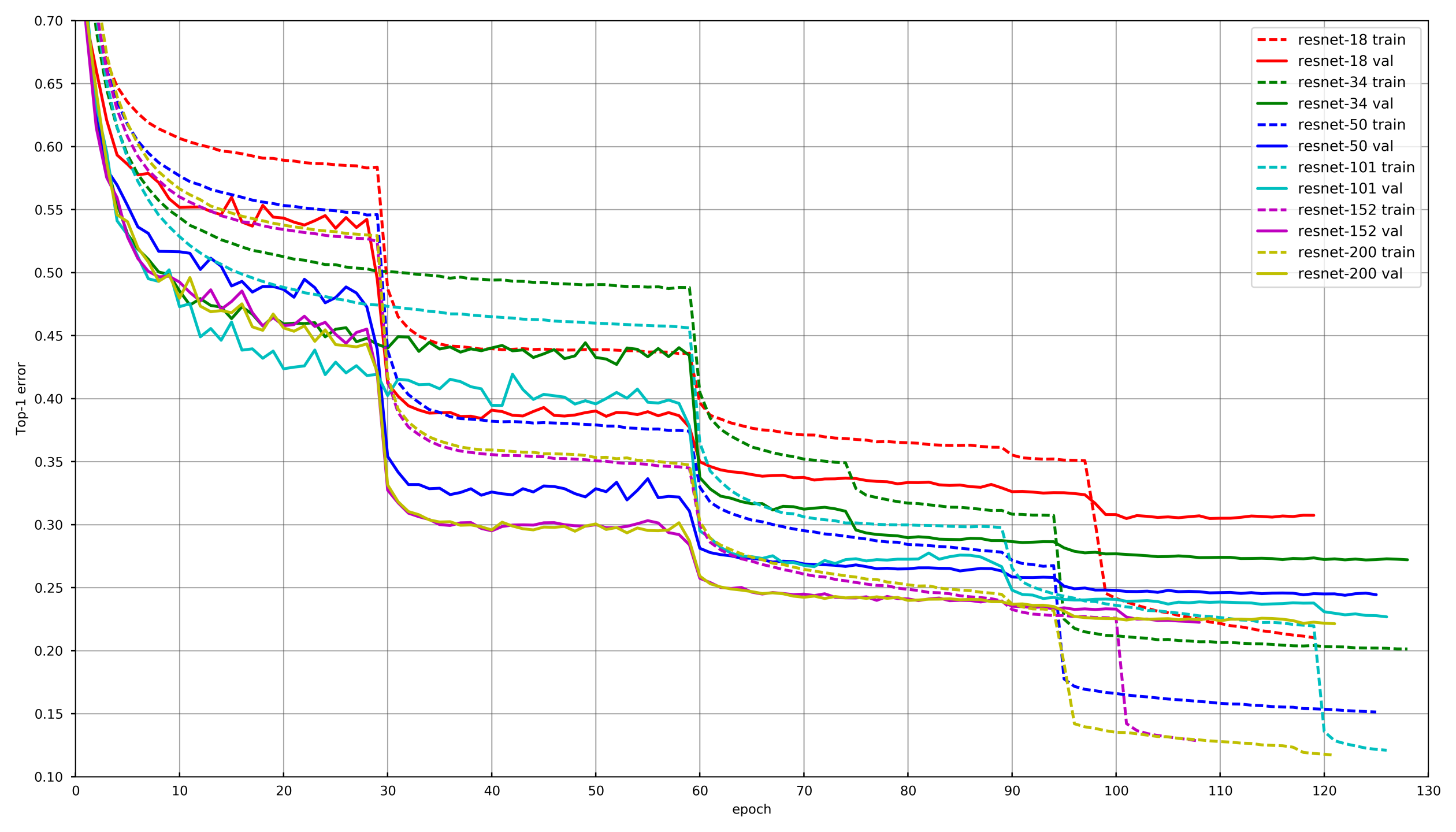
Photo de
github.com/tornadomeet/ResNetUn processus d'apprentissage typique est présenté sur le calendrier de formation des réseaux de neurones Resnet sur imagenet. Ils commencent à partir de poids initialisés au hasard avec SGD (lr 0,1 Nesterov Momentum 0,0001 WD 0,9) puis après 30 effacements, abaissent le taux d'apprentissage de 10 fois.
Conceptuellement, chacun de nous a utilisé la même approche, cependant, afin de ne pas vieillir tout en apprenant chaque réseau, la diminution de LR s'est produite si la validation n'a pas laissé tomber la perte pendant 3-5 époques consécutives. Ou, certains participants ont simplement réduit le nombre d'époques sur chaque dégât LR et baissé selon le calendrier.
AugmentationChoisir les bonnes augmentations est très important lors de la formation des réseaux de neurones. Les augmentations devraient refléter la variabilité de la nature des données. Classiquement, les augmentations peuvent être divisées en deux types: celles qui introduisent un biais dans les données et celles qui ne le font pas. Par biais, on peut comprendre diverses statistiques de bas niveau, telles que les histogrammes de couleur ou la taille caractéristique. À cet égard, disons, les augmentations et les échelles du HSV introduisent un décalage, mais pas un recadrage aléatoire.
Aux premières étapes de la formation du réseau, vous pouvez aller trop loin avec les augmentations et utiliser un ensemble très dur. Cependant, vers la fin de la formation, vous devez désactiver les augmentations ou ne laisser que celles qui n'introduisent pas de biais. Cela permet au réseau de neurones de s'adapter un peu sous le train et d'afficher un résultat légèrement meilleur à la validation.
Congélation des couchesDans la grande majorité des tâches, cela n'a aucun sens de former un réseau neuronal à partir de zéro, il est beaucoup plus efficace de jouer avec des réseaux pré-formés, par exemple avec Imagenet. Cependant, vous pouvez aller plus loin et non seulement changer la couche entièrement connectée sous la couche avec le nombre de classes souhaité, mais d'abord l'entraîner à geler toutes les convolutions. Si vous ne gelez pas les convolutions et entraînez immédiatement l'ensemble du réseau avec des poids initialisés de manière aléatoire d'une couche entièrement connectée, les poids des convolutions seront corrompus et les performances finales du réseau de neurones seront plus faibles. Sur cette tâche, cela était particulièrement visible en raison de la petite taille de l'échantillon de formation. Dans d'autres compétitions avec une grande quantité de données telles que cdiscount, il n'était pas possible de geler l'ensemble du réseau neuronal, mais des groupes de convolutions de la fin. De cette façon, l'entraînement pourrait être considérablement accéléré, car les gradients n'étaient pas pris en compte pour les couches gelées.
Recuit cycliqueCe processus ressemble à ceci. Après l'achèvement du processus de formation de base du réseau neuronal, les meilleurs poids sont pris et le processus de formation est répété. Mais cela commence par un taux d'apprentissage inférieur et se produit en peu de temps, disons 3-5 époques. Cela permet au réseau neuronal de descendre à un minimum local inférieur et de montrer de meilleures performances. Cette campagne stable améliore le résultat dans un nombre assez important de concours.
Plus en détail sur deux réceptions
iciAugmenter le temps de testComme il s'agit d'un concours et que nous n'avons pas de restriction formelle sur le temps d'inférence, vous pouvez utiliser des augmentations pendant le test. Il semble que l'image soit déformée de la même manière que lors de l'entraînement. Disons, il est réfléchi verticalement, horizontalement, tourné d'un angle, etc. Chaque augmentation donne une nouvelle image à partir de laquelle nous obtenons des prédictions. Ensuite, les prévisions de telles distorsions d'une image sont moyennées (en règle générale par des moyens géométriques). Cela donne également un profit. Dans d'autres compétitions, j'ai également expérimenté des augmentations aléatoires. Dites, vous pouvez appliquer pas un à la fois, mais simplement réduire de moitié l'amplitude des virages aléatoires, des contrastes et des augmentations de couleur, fixer la graine et faire plusieurs images déformées de manière aléatoire. Cela a également donné une augmentation.
Assemblage d'instantanés (TTA à points de contrôle multiples)L'idée de recuit peut être développée davantage. À chaque étape du recuit, le réseau neuronal vole dans des minima locaux légèrement différents. Et cela signifie que ce sont essentiellement des modèles légèrement différents qui peuvent être moyennés. Ainsi, lors des prédictions du test, vous pouvez prendre les trois meilleurs points de contrôle et faire la moyenne de leurs prédictions. J'ai également essayé de ne pas prendre les trois meilleurs, mais les trois plus divers des 10 principaux points de contrôle - c'était pire. Eh bien, pour la production, une telle astuce n'est pas applicable et j'ai essayé de faire la moyenne du poids des modèles. Cela a donné une augmentation très insignifiante mais régulière.
 Approches de chaque membre de l'équipe
Approches de chaque membre de l'équipeEn conséquence, à un degré ou à un autre, chaque membre de notre équipe a utilisé une combinaison différente des techniques ci-dessus.
| nick | Gel de conv.,
époque | Optimiseur | La stratégie | Août | Tta |
|---|
| albu | 3 | SGD | 15 décroissance de l'époque LR,
Cercle 13 époques | D4,
Scale,
Décalage
Distorsion
Contraste
Flou | D4 |
|---|
| alno | 3 | SGD | Lr decay | D4,
Scale,
Décalage
Distorsion
Contraste
Flou
Cisaillement
Multiplicateur de canaux | D4 |
|---|
| n01z3 | 2 | SGD | Drop LR, patient 10 | D4,
Scale,
Distorsion
Contraste
Flou | D4, 3 points de contrôle |
|---|
| ternaus | - | Adam | LR cyclique (1e-3: 1e-6) | D4,
Scale,
Ajout de chaîne
Contraste | D4,
récolte aléatoire |
|---|
| nizhib | - | Adam | StepLR, 60 époques, 20 par désintégration | D4,
RandomSizedCrop | D4,
4 coins,
centre
échelle |
|---|
| kostia | 1 | Adam | | D4,
Scale,
Distorsion
Contraste
Flou | D4 |
|---|
| romul | - | SGD | base_lr: 0,01 - 0,02
lr = base_lr * (0,33 ** (époque / 30))
Epoque: 50 | D4, échelle | D4, Recadrage central,
Cultures de coin |
|---|
Empilement et hacksNous avons formé chaque modèle avec chaque ensemble de paramètres sur 10 plis. Et puis sur les prédictions hors du pli (OOF), nous avons enseigné des modèles de deuxième niveau: Extra Trees, Linear Regression, Neural Network et simplement des modèles de moyenne.
Et déjà chez OOF, les prédictions des modèles de deuxième niveau ont pris des poids pour le mélange. Vous pouvez en savoir plus sur l'empilement
ici et
ici .
Dans la production réelle, curieusement, cette approche a également lieu. Par exemple, lorsqu'il existe des données multimodales (images, texte, catégories, etc.) et que vous souhaitez combiner les prédictions des modèles. Vous pouvez simplement faire la moyenne des probabilités, mais la formation d'un modèle de deuxième niveau donne le meilleur résultat.
Optimisation Baes F2De plus, les prédictions finales se sont un peu ajustées en utilisant l'optimisation bayésienne. Supposons que nous ayons des probabilités idéales, alors F2 avec le meilleur tapis d'attente (c'est-à-dire de type optimal) est obtenu par la formule suivante:
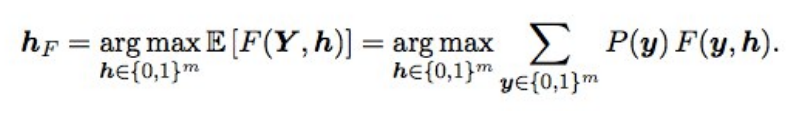
Qu'est-ce que cela signifie? Nous devons trier toutes les combinaisons (c'est-à-dire pour chaque étiquette 0 et 1), calculer la probabilité de chaque combinaison et multiplier par F2 - nous obtenons la F2 attendue. Pour quelle combinaison est-ce mieux et donnera le F2 optimal. Les probabilités étaient considérées simplement comme une multiplication des probabilités d'étiquettes individuelles (si l'étiquette est 0, nous prenons 1 - p), et afin de ne pas trier 2 en 17 options, seules les étiquettes avec une probabilité de 0,05 à 0,5 étaient échelonnées - il y en avait 3-7 dans une rangée, donc les options un peu (la soumission a été faite en quelques minutes). En théorie, il serait intéressant d'obtenir la probabilité d'une combinaison d'étiquettes, non seulement de multiplier les probabilités individuelles (car les étiquettes ne sont pas indépendantes), mais cela n'a pas fonctionné.
qu'est-ce que cela a donné? lorsque les modèles sont devenus bons, la sélection des seuils après que l'ensemble a cessé de fonctionner, et cette chose a donné une augmentation petite mais stable à la fois de la validation et du public / privé.
PostfaceEn conséquence, nous avons formé 48 modèles différents, chacun à 10 plis, soit 480 modèles du premier niveau. Une telle grille humaine m'a permis d'essayer différentes techniques lors de l'entraînement de réseaux neuronaux convolutionnels profonds, que j'utilise toujours dans le travail et les compétitions.
Était-il possible de former moins de modèles et d'obtenir le même résultat ou un meilleur résultat? Oui, tout à fait. Nos compatriotes de la 3e place, Stanislav
stasg7 Semenov et Roman
ZFTurbo Soloviev, ont coûté un plus petit nombre de modèles de premier niveau et compensé plus de 250 modèles de deuxième niveau. À propos de la solution, vous pouvez
voir l' analyse et
lire le post.
La première place est allée au meilleur ajustement mystérieux. En général, ce gars est très cool, et maintenant il est devenu le classement Keggle top1, après avoir tiré beaucoup de compétitions d'image. Il est resté longtemps anonyme, jusqu'à ce que Nvidia brise la couverture en l'
interviewant . Dans lequel il a admis que 200 subordonnés lui feraient rapport ... Il y a aussi un
article sur la décision.
Un autre des plus intéressants: largement connu dans les cercles étroits de
Jeremy Howard , le père
fastai a terminé 22m. Et si vous pensiez qu'il venait d'envoyer quelques soumissions pour son fan, alors vous ne l'avez pas deviné. Il a participé à l'équipe et envoyé 111 colis.
En outre, les étudiants diplômés de Stanford qui suivaient le légendaire cours CS231n à l'époque et qui étaient autorisés à utiliser cette tâche comme projet de cours, ont terminé toute l'équipe au milieu du classement.
En prime, j'ai
parlé à Mail.ru avec le contenu de ce message et voici une autre
présentation de Vladimir Iglovikov lors d'une réunion dans la vallée.