«Rechercher le marché des postes vacants d'analyste» était la tâche très réelle d'un très vrai analyste de premier plan d'une grande ou d'une petite entreprise. L'analyseur a réparti manuellement des dizaines de descriptions de tâches avec hh, en les répartissant en fonction des compétences demandées et en augmentant le compteur dans la colonne de feuille de calcul correspondante.
J'ai vu dans cette tâche un bon domaine pour l'automatisation et j'ai décidé d'essayer d'y faire face avec moins de sang, facilement et simplement.
Je me suis intéressé aux questions suivantes soulevées dans cette étude:
- salaire moyen des analystes d'affaires et de systèmes,
- les compétences et qualités personnelles les plus demandées dans ce poste,
- les dépendances (le cas échéant) entre certaines compétences et le niveau de salaire.
Spoiler: cela n'a pas fonctionné facilement et simplement.
Préparation des données
Si nous voulons collecter beaucoup de données sur les postes vacants, il est logique que hh ne soit pas limité. Cependant, pour expérimenter la pureté simplicité, nous commençons par cette ressource.
Collection
Pour collecter des données, nous utiliserons la recherche d'emploi via l'API hh.
Je rechercherai à l'aide de la simple requête textuelle "analyste de systèmes", "analyste commercial" et "propriétaire de produit", car les activités et les domaines de responsabilité de ces postes se chevauchent généralement.
Pour ce faire, créez une demande du formulaire https://api.hh.ru/vacancies?text="systems+analyst" et analysez le JSON reçu.
Afin d'obtenir les postes vacants les plus pertinents dans l'échantillon, nous rechercherons uniquement dans les en-têtes de postes vacants en ajoutant le paramètre search_field=name à la requête.
Ici, vous pouvez voir quels champs de postes vacants sont retournés pour cette demande. J'ai choisi ce qui suit:
- titre du poste
- la ville
- date de publication
- salaire - limites supérieure et inférieure
- devise dans laquelle le salaire est indiqué
- brut - T / F
- l'entreprise
- responsabilités
- exigences pour le candidat
De plus, je souhaite analyser plus en détail les compétences indiquées dans la section Compétences clés, mais cette section n'est disponible que dans la description de poste complète. Par conséquent, je conserverai également des liens vers les offres d'emploi trouvées, afin d'obtenir ultérieurement une liste de compétences pour chacune d'elles.
Afficher le code # :) library(jsonlite) library(curl) library(dplyr) library(ggplot2) library(RColorBrewer) library(plotly) hh.getjobs <- function(query, paid = FALSE) { # Makes a call to hh API and gets the list of vacancies based on the given search queries df <- data.frame( query = character() # , URL = character() # , id = numeric() # id , Name = character() # , City = character() , Published = character() , Currency = character() , From = numeric() # . , To = numeric() # . , Gross = character() , Company = character() , Responsibility = character() , Requerement = character() , stringsAsFactors = FALSE ) for (q in query) { for (pageNum in 0:99) { try( { data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\"" , q , "\"&search_field=name" , "&only_with_salary=", paid ,"&page=" , pageNum)) df <- rbind(df, data.frame( q, data$items$url, as.numeric(data$items$id), data$items$name, data$items$area$name, data$items$published_at, data$items$salary$currency, data$items$salary$from, data$items$salary$to, data$items$salary$gross, data$items$employer$name, data$items$snippet$responsibility, data$items$snippet$requirement, stringsAsFactors = FALSE)) }) print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\"")) } } names <- c("query", "URL", "id", "Name", "City", "Published", "Currency", "From", "To", "Gross", "Company", "Responsibility", "Requirement") colnames(df) <- names return(df) }
Dans la fonction hh.getjobs() , l'entrée accepte le vecteur des requêtes de recherche qui nous intéressent et s'affinent, nous ne sommes intéressés que par les postes vacants avec le salaire spécifié ou tout de suite (par défaut nous prenons la deuxième option). Un cadre dafa vide est créé, puis la fonction fromJSON() du package fromJSON() est jsonlite , qui prend l'URL d'entrée et renvoie une liste structurée. Ensuite, à partir des nœuds de cette liste, nous obtenons les données qui nous intéressent et remplissons les champs de trame de données correspondants.
Par défaut, les données sont données page par page, avec 20 éléments sur chaque page. Pour un maximum de 2000 postes vacants. Toutes les données que nous recevons sont enregistrées dans df .
Life hack 1: ce n'est pas du tout un fait qu'à notre demande, il y aura 2000 postes vacants, et à partir d'un moment donné, nous recevrons des pages vierges. Dans ce cas, R jure et saute hors de la boucle. Par conséquent, nous enveloppons soigneusement le contenu de la boucle interne dans try() .
Life hack 2: il est également judicieux d'ajouter la sortie de l'état actuel de la collecte de données à la console dans la boucle interne, car ce n'est pas une entreprise rapide. J'ai fait ça:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))
Après avoir rempli les données, les colonnes sont renommées afin qu'il soit pratique de travailler avec elles, et le bloc de données résultant est renvoyé.
Je vais stocker cette fonction et d'autres fonctions auxiliaires dans un fichier functions.R séparé afin de ne pas encombrer le script principal, qui ressemble jusqu'à présent à ceci:
source("functions.R") # Step 1 - get data # 1.1 get vacancies (short info) jobdf <- hh.getjobs(query = c("business+analyst" , "systems+analyst" , "product+owner"), paid = FALSE)
Nous allons maintenant acquérir de l' experience et des key_skills partir de la description complète du poste .
hh.getxp transmettons le hh.getxp données à la fonction hh.getxp , suivons les liens enregistrés vers les postes vacants et, à partir de la description complète, nous obtenons la valeur de l'expérience de travail requise. La valeur résultante est stockée dans une nouvelle colonne.
Afficher le code hh.getxp <- function(df) { df$experience <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) df[df$URL == myURL, "experience"] <- data$experience$name } ) print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df))) } return(df) }
La description de la nouvelle fonction d'assistance est envoyée à functions.R , et le script principal y accède désormais:
# s.1.2 get experience (from full info) jobdf <- hh.getxp(jobdf) # 1.3 get skills (from full info) all.skills <- hh.getskills(jobdf$URL)
Dans le fragment ci-dessus, nous formons également un nouveau all.skills données all.skills forme "job id - skill":
Afficher le code hh.getskills <- function(allurls) { analyst.skills <- data.frame( id = character(), # id skill = character() # ) for (myURL in allurls) { data <- fromJSON(myURL) if (length(data$key_skills) > 0) analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills)) print(paste0("Filling in " , which(allurls == myURL, arr.ind = TRUE) , " out of " , length(allurls))) } names(analyst.skills) <- c("id", "skill") analyst.skills$skill <- tolower(analyst.skills$skill) return(analyst.skills) }
Prétraitement
Voyons combien de données nous avons réussi à collecter:
> length(unique(jobdf$id)) [1] 1478 > length(jobdf$id) [1] 1498
Près d'un millier et demi d'emplois! Ça a l'air bien. Et apparemment, plusieurs postes vacants sont entrés dans les résultats de recherche deux fois - pour des demandes différentes. Par conséquent, la première étape consiste à ne laisser que des entrées uniques: jobdf <- jobdf[unique(jobdf$id),] .
Afin de comparer les salaires des analystes du marché du travail, j'ai besoin
1) s'assurer que toutes les données disponibles sur les salaires sont présentées dans une seule monnaie,
2) sélectionner dans une base de données séparée les postes vacants pour lesquels le salaire est indiqué.
Nous considérons chacune des sous-tâches plus en détail. Auparavant, vous pouvez savoir ce que, en principe, les devises sont trouvées dans nos données en utilisant le table(jobdf$Currency) . Dans mon cas, en plus des roubles, des dollars, des euros, des hryvnias, des tenges kazakhes et même des sommes ouzbeks sont apparus.
Pour convertir les valeurs salariales en roubles, vous devez connaître le taux de change actuel. Nous découvrirons auprès de la Banque centrale :
Afficher le code quotations.update <- function(currencies) { # Parses the most up-to-date qutations data provided by the Central Bank of Russia # and returns a table with currency rate against RUR doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp") quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE) quotationsdf <- select(quotationsdf, -Name) quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode) quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal) quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value)) quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal quotationsdf <- quotationsdf %>% select(CharCode, Value) return(quotationsdf) }
Pour vous assurer que les cours sont correctement traités dans R, vous devez vous assurer que la partie décimale est séparée par un point. En outre, vous devez faire attention à la colonne Nominal: quelque part, il est 1, quelque part 10 ou 100. Cela signifie qu'une livre sterling coûte environ 85 roubles et, par exemple, pour une centaine de drams arméniens, vous pouvez acheter ~ 13 roubles. Pour plus de commodité, j'ai réduit les valeurs à une valeur nominale de 1 par rapport au rouble.
Vous pouvez maintenant traduire. Notre script le fait en utilisant la fonction convert.currency() . Le taux de change actuel est tiré du tableau des quotations , où nous avons enregistré les données de XML fournies par la Banque centrale. De plus, la fonction d'entrée accepte la devise cible pour la conversion (par défaut RUR) et un tableau avec les postes vacants, les valeurs des fourchettes de salaire dans lesquelles il est nécessaire de conduire à une devise unique. La fonction renvoie un tableau avec des chiffres de salaire mis à jour (déjà sans la colonne Devise, car inutile).
J'ai dû bricoler avec des roubles biélorusses: après avoir reçu des données très étranges dans plusieurs approches, j'ai mené une petite recherche et j'ai découvert que depuis 2016 une nouvelle monnaie était utilisée en Biélorussie, qui diffère non seulement en taux de change, mais aussi en abréviation (désormais pas BYR, mais BYN) . Dans les répertoires hh, l'abréviation BYR est toujours utilisée, dont XML de la Banque centrale ne sait rien. Par conséquent, dans la fonction convert.currency() I pas de la manière la plus élégante Tout d'abord, je remplace l'abréviation par l'actuelle, puis je passe directement à la conversion.
Cela ressemble à ceci:
Afficher le code convert.currency <- function(targetCurrency = "RUR", df, quotationsdf) { cond <- (!is.na(df$Currency) & df$Currency == "BYR") df[cond, "Currency"] <- "BYN" currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency])) # ( ) if (!is.null(df$From)) { for (currency in currencies) { condition <- (!is.na(df$From) & df$Currency == currency) try( df$From[condition] <- df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } # ( ) if (!is.null(df$To)) { for (currency in currencies) { condition <- !is.na(df$To) & df$Currency == currency try( df$To[condition] <- df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } return(df %>% select(-Currency)) }
Vous pouvez également tenir compte du fait que certaines données sur les salaires sont présentées en valeurs brutes, c'est-à-dire que l'employé recevra un peu moins en main. Pour calculer le salaire net des résidents de la Fédération de Russie, 13% doivent être déduits de ces chiffres (30% sont déduits pour les non-résidents).
Afficher le code gross.to.net <- function(df, resident = TRUE) { if (resident == TRUE) coef <- 0.87 else coef <- 0.7 if (!is.null(df$Gross)) { if (!is.null(df$From)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,]))) df$From[index] <- df$From[index] * coef } if (!is.null(df$To)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,]))) df$To[index] <- df$To[index] * coef } df <- df %>% select(-Gross) } return(df) }
Bien sûr, je ne le ferai pas, car dans ce cas, il vaut la peine de considérer les taxes dans différents pays, et pas seulement en Russie, ou d'ajouter un filtre par pays dans la requête de recherche initiale.
La dernière étape avant l'analyse consiste à diviser les postes vacants trouvés en trois catégories: juin, moyen et senior et à écrire les postes reçus dans une nouvelle colonne. Les postes supérieurs comprendront ceux au nom desquels le mot «senior» et ses synonymes sont présents. De même, nous trouverons les positions de départ pour les mots-clés "junior" et synonymes, et parmi les intermédiaires nous inclurons tous ceux entre:
get.positions <- function(df) { df$lvl <- NA df[grep(pattern = "lead|senior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "senior" df[grep(pattern = "junior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "junior" df[is.na(df$lvl), "lvl"] <- "middle" return(df) }
Ajoutez le bloc de préparation des données au script principal.
Ajouté # Step 2 - prepare data # 2.1. Convert all currencies to target currency # 2.1.1 get up-to-date currency rates quotations <- quotations.update() # 2.1.2 convert to RUR jobdf <- convert.currency(df = jobdf, quotationsdf = quotations) # 2.2 convert Gross to Net # jobdf <- gross.to.net(df = jobdf) # 2.3 define segments jobdf <- get.positions(jobdf)
Analyse
Comme mentionné ci-dessus, je vais analyser les aspects suivants des données obtenues:
- salaire moyen BA / SA,
- les compétences et qualités personnelles les plus demandées dans ce poste,
- les dépendances (le cas échéant) entre certaines compétences et le niveau de salaire.
Revenu BA / SA moyen
Il s'est avéré que les entreprises hésitent à indiquer une limite de salaire supérieure ou inférieure.
Dans notre jobdf trame de données jobdf ces valeurs sont respectivement dans les colonnes To et From. Je veux trouver les moyennes et les écrire dans une nouvelle colonne Salaire.
Pour les cas où le salaire est indiqué en entier, cela peut facilement être fait en utilisant la fonction mean() , en filtrant tous les autres enregistrements où les données de la fiche sont manquantes en tout ou en partie. Mais dans ce cas, il resterait moins de 10% de notre échantillon d'origine, qui est déjà petit. Par conséquent, je calcule le coefficient Podgoniana , qui vous indique à quel point les valeurs To et From diffèrent en moyenne dans les postes vacants où le fork complet est indiqué, et avec son aide, je remplis les données manquantes dans les cas où une seule valeur est manquante.
Afficher le code select.paid <- function(df, suggest = TRUE) { # Returns a data frame with average salaries between To and From # optionally, can suggest To or From value in case only one is specified if (suggest == TRUE) { df <- df %>% filter(!is.na(From) | !is.na(To)) magic.coefficient <- # shows the average difference between max and min salary round(mean(df$To/df$From, na.rm = TRUE), 1) df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient } else { df <- na.omit(df) } df$salary <- rowMeans(x = df %>% select(From, To)) df$salary <- ceiling(df$salary / 10000) * 10000 return(df %>% select(-From, -To)) }
Il s'agit d'un filtrage de données "souple", qui est défini dans la fonction select.paid() avec le paramètre select.paid() suggest = TRUE . Alternativement, nous pouvons spécifier suggest = FALSE lors de l'appel de la fonction et simplement couper toutes les lignes où les données de salaire sont au moins partiellement absentes. Cependant, en utilisant un filtrage doux et un coefficient magique, j'ai réussi à enregistrer près d'un quart de l'ensemble de données d'origine dans l'échantillon.
On passe à la partie visuelle:

Sur ce graphique, vous pouvez évaluer visuellement la densité de distribution des salaires BA / SA dans deux capitales et dans les régions. Mais que se passe-t-il si nous spécifions la demande et comparons combien les hommes moyens et supérieurs des capitales reçoivent?
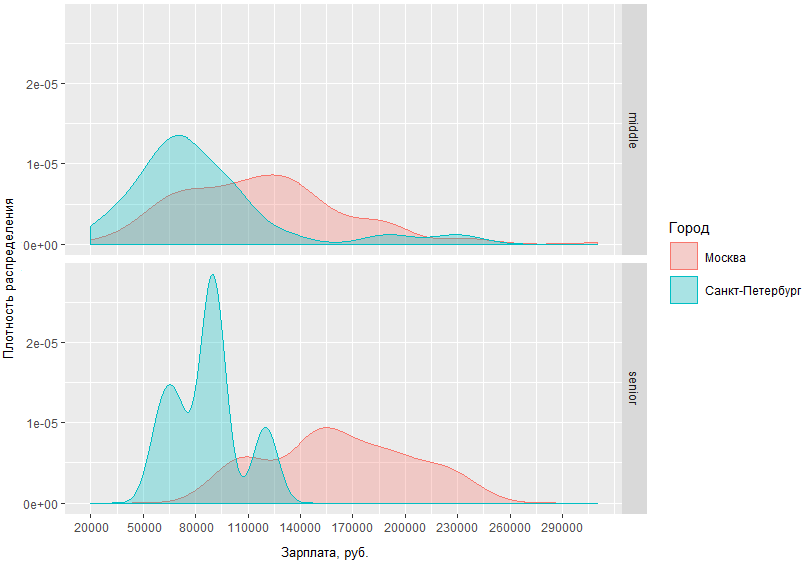
D'après le graphique obtenu, il est clair que la différence de situation salariale entre hommes moyens et seniors à Moscou et à Saint-Pétersbourg n'est pas trop différente. Ainsi, à Saint-Pétersbourg, les intermédiaires se situent généralement dans la région de 70 tr, tandis qu'à Moscou, le pic de densité tombe à ~ 120 tr et la différence de revenu des spécialistes de haut niveau à Moscou et à Saint-Pétersbourg diffère en moyenne de 60 000.
On peut aussi regarder, par exemple, les salaires des analystes à Moscou par poste:

On peut conclure que a) aujourd'hui, à Moscou, la demande en analystes débutants est beaucoup plus importante, et b) en même temps, le seuil de salaire supérieur pour ces spécialistes est beaucoup plus limité que celui des intermédiaires et des seniors.
Autre constat: le sn moyen des spécialistes moscovites de niveau moyen et élevé a une zone d'intersection assez large. Cela peut indiquer que le marché a une frontière assez floue entre ces deux étapes.
Code complet pour les graphiques sous la coupe.
Afficher # Step 3 - analyze salaries # 3.1 get paid jobs (with salaries specified) jobs.paid <- select.paid(jobdf) # 3.2 plot salaries density by region ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) + geom_density(alpha=.3) + scale_fill_discrete(guide = guide_legend(reverse=FALSE)) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10))) # 3.3 compare salaries for middle / senior in capitals ggplot(jobs.paid %>% filter(region %in% c("", "-"), lvl %in% c("senior", "middle")), aes(salary, fill = region, colour = region)) + facet_grid(lvl ~ .) + geom_density(alpha = .3) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + scale_fill_discrete(name = "") + scale_color_discrete(name = "") + guides(fill=guide_legend( keywidth=0.1, keyheight=0.1, default.unit="inch") ) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10)) # 3.4 plot salaries in Moscow by position ggplotly(ggplot(jobs.paid %>% filter(region == ""), aes(salary, fill = lvl, color = lvl)) + geom_density(alpha=.4) + scale_fill_brewer(palette = "Set2") + scale_color_brewer(palette = "Set2") + theme_light() + scale_y_continuous(name = " ") + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
Analyse des compétences clés
Nous passons à l'objectif clé de l'étude - identifier les compétences les plus recherchées pour BA / SA. Pour ce faire, nous analyserons les données qui sont explicitement indiquées dans le domaine spécial du poste vacant - compétences clés.
Compétences les plus populaires
Plus tôt, nous avons reçu une trame de données distinctes all.skills , où nous avons enregistré les paires «job id - skill». Trouver les compétences les plus courantes est facile avec la fonction table() :
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq")) htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
Vous obtenez quelque chose comme ceci:

Ici Freq est le nombre de postes vacants dans le champ "key_skills" dont la compétence correspondante de la colonne Compétence est indiquée.
"Mais ce n'est pas tout!" (C) Il est bien évident que les mêmes compétences peuvent être facilement trouvées dans différents postes vacants en termes synonymes.
J'ai compilé un petit dictionnaire de synonymes pour les noms des compétences et les ai divisés en catégories.
Le dictionnaire est un fichier csv avec des colonnes de catégorie - l'un des éléments suivants: activités, outils, connaissances, normes et personnel; compétence - le nom principal de la compétence, que j'utiliserai à la place de tous les synonymes trouvés; syn1, syn2, ... syn13 - variations réellement possibles pour chaque compétence. Certaines lignes peuvent contenir des colonnes vides de synonymes.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13 tools;axure;;;;;;;;;;;;; tools;lucidchart;;;;;;;;;;;;; standards;archimate;;;;;;;;;;;;; standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;; personal;teamwork;team player; ;;;;;;;;;;; activities;wireframing;mockup;mock-up;;-;wireframe;;ui;ux/;/ux;;;;
Tout d'abord, importez le dictionnaire, puis redistribuez à nouveau les compétences en fonction des équivalences existantes:
# Analyze skills # 4.1 import dictionary dict <- read.csv(file = "competencies.csv", header = TRUE, stringsAsFactors = FALSE, sep = ";", na.strings = "", encoding = "UTF-8") # 4.2 match skills with dictionary all.skills <- categorize.skills(all.skills, dict)
Sous la coupe, vous pouvez voir le bourrage de la fonction categorize.skills() .
ces tripes! categorize.skills <- function(analyst_skills, dictionary) { analyst_skills$skill.group <- NA analyst_skills$category <- NA for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) mypattern <- paste0(c(myskill, mypattern), collapse = "|") else mypattern <- myskill try( { analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category } ) } return(analyst_skills) }
J'ajoute la colonne des catégories et des compétences à la base de données des compétences d'origine. groupe - pour la catégorie et le nom généralisé de la compétence, respectivement. Ensuite, je passe par le dictionnaire importé et compose un modèle pour la fonction grep() partir de chaque ligne de synonymes. En ajoutant chaque valeur de colonne non vide à la ligne, je les sépare avec un tiret pour obtenir une condition "ou". Donc, pour toutes les compétences de la table source, qui inclut le uml|activity diagram|use case diagram|ucd|class diagram , j'écrirai la valeur "uml" dans la colonne skill.group. Et il en sera de même pour tout le monde! .. compétence de la trame de données d'origine.
En demandant à nouveau le sommet des compétences les plus populaires, vous pouvez voir que l'alignement des forces a quelque peu changé:
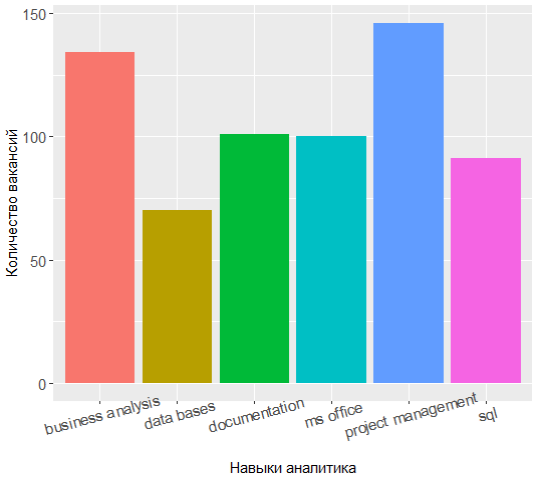
Les trois leaders ont désormais la gestion de projet, l'analyse commerciale et la documentation, et la connaissance d'UML est passée du top 7.
Il est assez intéressant de parcourir les catégories et de découvrir les compétences les plus demandées dans chacune d’elles.
Par exemple, pour la catégorie Connaissances, la situation est la suivante:
Afficher le code tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl), by = "id", sort = FALSE) tmp <- na.omit(tmp) ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

Le graphique montre que la plus grande demande concerne les connaissances dans le domaine des bases de données, des méthodologies de développement logiciel et 1C. Viennent ensuite les connaissances dans le domaine du CRM, des systèmes ERP et des bases de la programmation.
En ce qui concerne les normes, la connaissance de SQL et UML est vraiment très demandée, la notation ARIS leur vient à l'esprit, mais les GOST n'occupent que la sixième place.
Voici le code ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

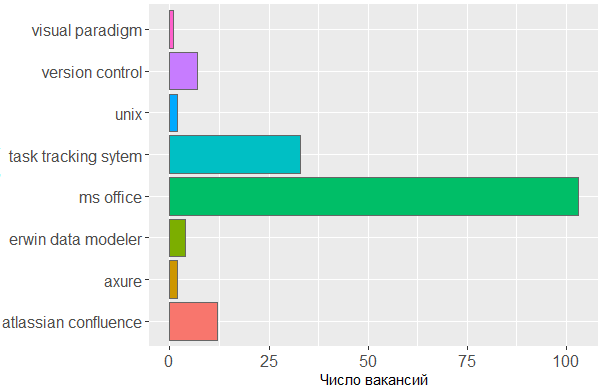
Quant aux outils utilisés, nous constatons une fois de plus que la tête est l'outil principal de l'analyste. On ne peut pas se passer de la ligne MS Office et des systèmes de suivi des tâches, mais le reste ne préoccupe guère l'éditeur dans lequel l'analyste crée ses propres schémas ou modèles d'interface.
Voici le code ggplot(tmp %>% filter(category == "tools")) + geom_histogram(colour = "#666666", stat = "count", aes(skill.group, fill = skill.group)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()
L'impact des compétences sur le revenu
Enfin, analysons dans quelle fourchette de salaires apparaissent les mentions des différentes compétences. , , , .
jobs.paid all.skills , data frame.
# 4.4 vizualize paid skills tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
:
> head(tmp) id skill skill.group category salary lvl City 2 25781585 android mobile os knowledge 90000 middle 3 25781585 project management activities 90000 middle 5 25781585 project management activities 90000 middle 6 25781585 ios mobile os knowledge 90000 middle 7 25750025 aris aris standards 70000 middle 8 25750025 - business analysis activities 70000 middle
, .. . :
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, salary)) + coord_flip() + geom_count(aes(size = ..n.., color = City)) + scale_fill_discrete(name = "") + scale_y_continuous(name = ", .") + scale_size_area(max_size = 11) + theme(legend.position = "bottom", axis.title = element_blank(), axis.text.y = element_text(size=10, angle=10)))

, BA/SA .
:
ggplot(tmp %>% filter(category == "personal", City %in% c("", "-")), aes(tools::toTitleCase(skill), salary)) + coord_flip() + geom_count(aes(size = ..n.., color = skill.group)) + scale_y_continuous(breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 20000),1), name = ", .") + scale_size_area(max_size = 10) + theme(legend.position = "none", axis.title = element_text(size = 11), axis.text.y = element_text(size=10, angle=0))
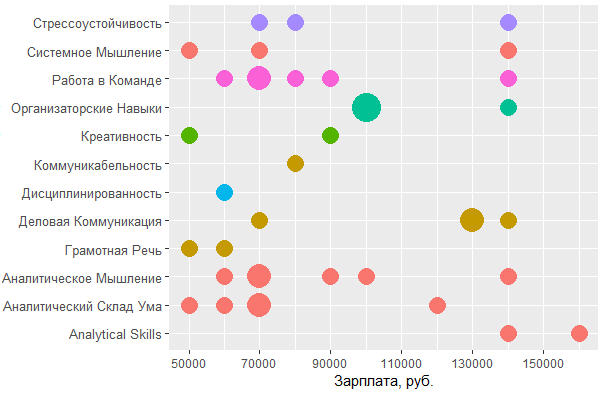
, MS Office , — , - . , , , .
, , : UML ARIS, SQL ( ) , IDEF — , "".
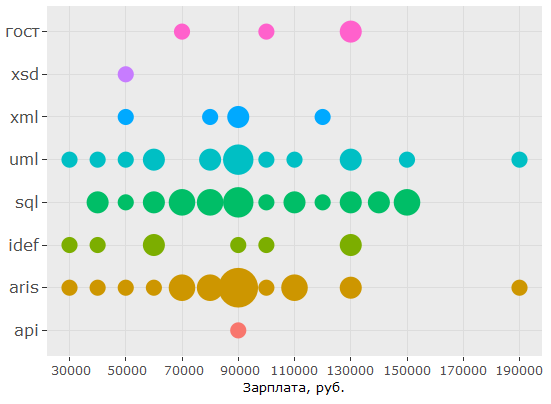
, , , . , 1478 - key_skills. , - .
, data frame:
> jobdf$Responsibility[[1]] [1] "Training course in business analysis. ● Define needs of the user/client, understand the problem which needs to be solved. ● " > jobdf$Requirement[[1]] [1] "At least 6 months' experience in business analysis. ● Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ● "
, , . URL' , .
hh.get.full.desrtion <- function(df) { df$full.description <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) if (length(data$description) > 0) { df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description } print(paste0("Filling in " , which(df$URL == myURL, arr.ind = TRUE) , " out of " , length(df$URL))) } ) } df$full.description <- tolower(df$full.description) return(df) }
- , html- ., gsub :
remove.Html <- function(htmlString) { #remove html tags return(gsub("<.*?>", "", htmlString)) }
, , , , . data frame ( df), , df "id, skill.group, category".
skills.from.desc <- function(df, dictionary) { sk <- data.frame( id = numeric() , skill.group = character() , category = character() ) for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) { mypattern <- paste0(c(myskill, mypattern), collapse = "|") } else { mypattern <- myskill } cond = grep(x = df$full.description, pattern = mypattern) tmp <- data.frame( id = df[cond, "id"], skill.group = rep(myskill, length(cond)), category = rep(category, length(cond)) ) sk <- rbind(sk, tmp) } return(sk) }
# 5 text analysis # 5.1 get full descriptions jobdf <- hh.get.full.description(jobdf) jobdf$full.description <- remove.Html(tolower(jobdf$full.description)) sk.from.desc <- skills.from.desc(jobdf, dict)
, ?
> head(sk.from.desc) id skill.group category 1 25638419 axure tools 2 24761526 axure tools 3 25634145 axure tools 4 24451152 axure tools 5 25630612 axure tools 6 24985548 axure tools > tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq")) > htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
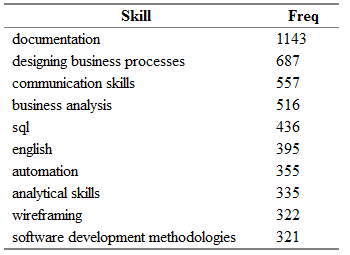
, ! Project management, key_skills, ( ).
, , key_skills -5.
, . 1478 , , key_skills, , .
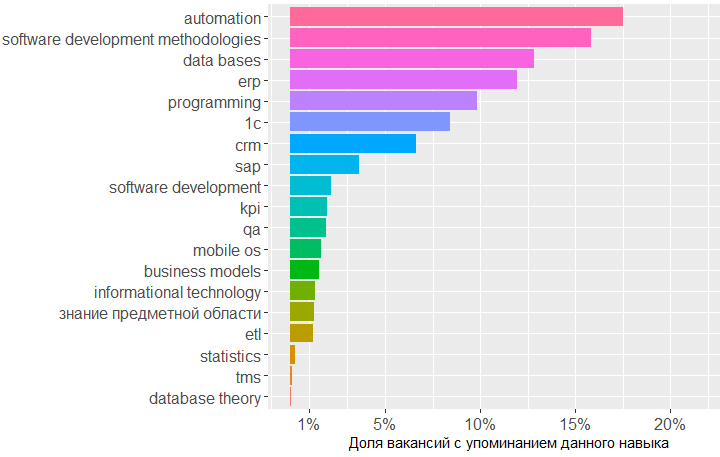
, , BA , - .
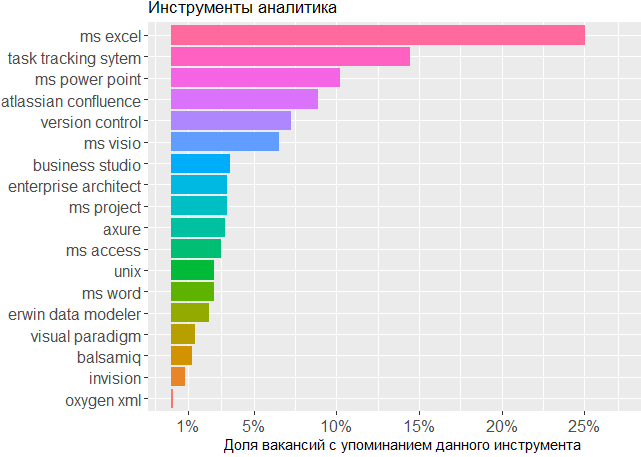
, .
data frame , , . , -.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>% filter(City %in% c("", "-")) %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
> head(tmp) id skill.group category salary lvl City 1 25243346 uml standards 160000 middle 2 25243346 requirements management activities 160000 middle 3 25243346 designing business processes activities 160000 middle 4 25243346 communication skills personal 160000 middle 5 25243346 mobile os knowledge 160000 middle 6 25243346 ms visio tools 160000 middle
, , , .
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) + geom_count(aes(color = salary, size = ..n..)) + scale_size_area(max_size = 13) + theme(legend.position = "right", legend.title = element_text(size = 10), axis.title = element_blank(), axis.text.y = element_text(size=10)) + coord_flip() + scale_color_continuous(labels = function(x) format(x, scientific = FALSE), breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 70000),1), low = "blue", high = "red", name = ", ."))
?
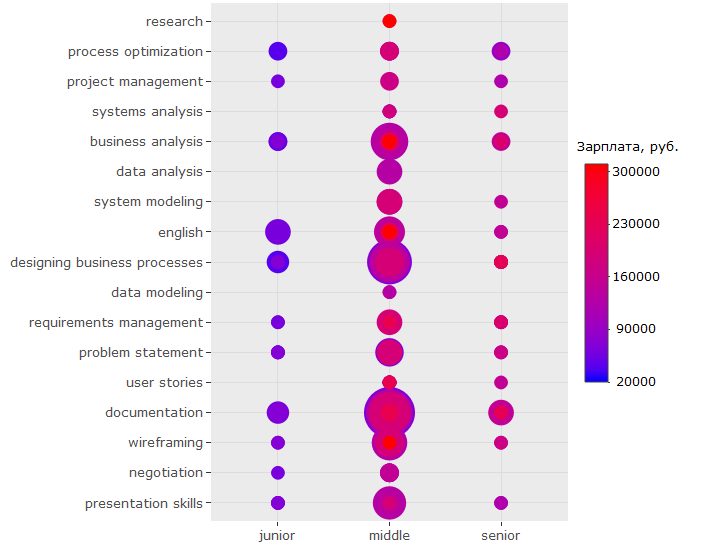
-, , - . ( , , , .)
-, , "" -, .
, key_skills.
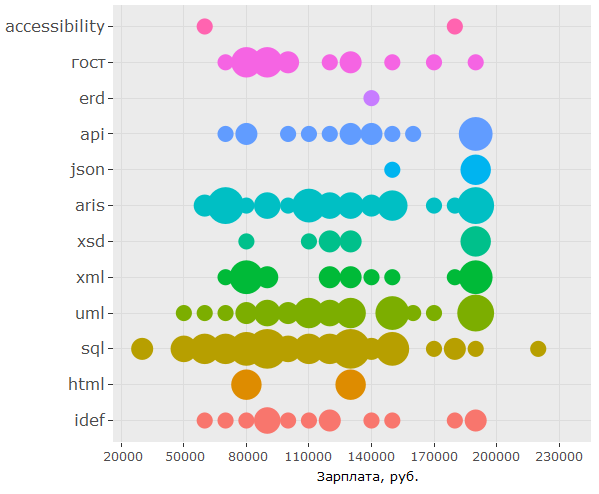
, , 150 .. UML ARIS, IDEF, , — .
:

, - , , key_skills , . , 150 .. , .
?
, - :

, , , ? , . , , . , ó ( )
, - :

-
BA/SA ,
- . , ;
- ( ) 200 .. , , ;
- ;
- — - ( , , )
key_skills hh , ;- , , , (!) ;
- , -, UX ;
- . , - 150 ..;
- , , SQL, UML & ARIS. , .. . , , ,
wordcloud2::wordcloud2(data = table(sk.from.desc$skill.group), rotateRatio = 0.3, color = 'random-dark')
