Ou comment je me suis retrouvé dans l'équipe gagnante de la compétition contradictoire Machines Can See 2018.
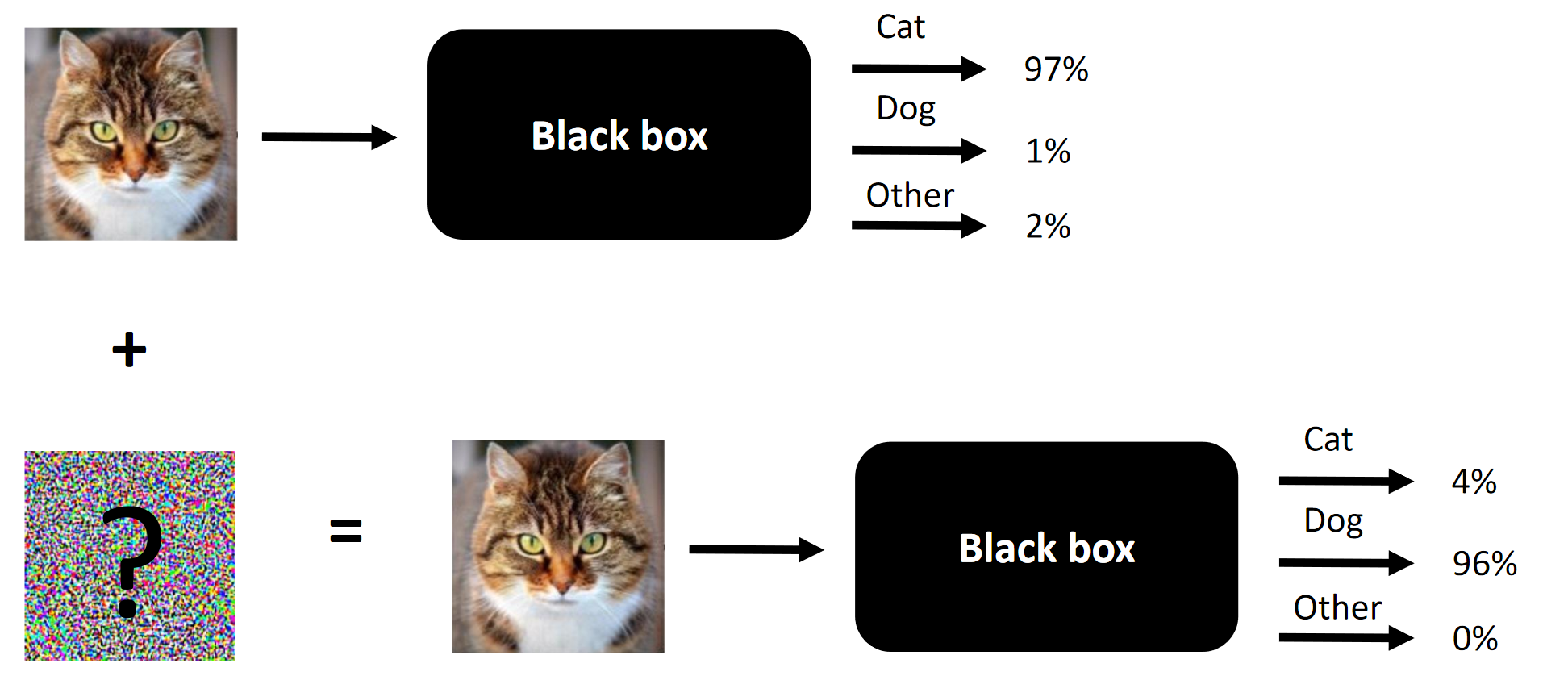 L'essence de toute attaque concurrentielle en est un exemple.
L'essence de toute attaque concurrentielle en est un exemple.Il se trouve que j'ai participé au concours Machines Can See 2018. J'ai rejoint le concours j'étais un peu en retard (environ une semaine avant la fin), mais je me suis finalement retrouvé dans une équipe de 4 personnes, où la contribution de nous trois (y compris moi) était nécessaire pour la victoire (supprimer un composant - et nous serions des étrangers).
Le but du concours est de changer les visages des gens afin que le réseau neuronal convolutionnel, présenté comme une boîte noire par les organisateurs, ne puisse pas distinguer le visage source du visage cible. Le nombre de modifications autorisées a été limité par
SSIM .
Article original publié
ici .
Remarque La traduction maladroite de la terminologie ou son absence est dictée par le manque de terminologie établie dans la langue russe. Vous pouvez suggérer vos options dans les commentaires. L'essence de la compétition est de changer le visage à l'entrée pour que la boîte noire ne puisse pas faire la distinction entre deux visages (au moins du point de vue de la distance L2 / Euclidienne)
L'essence de la compétition est de changer le visage à l'entrée pour que la boîte noire ne puisse pas faire la distinction entre deux visages (au moins du point de vue de la distance L2 / Euclidienne)Ce qui fonctionne dans les attaques concurrentielles et ce qui a fonctionné dans notre cas:
- Méthode Fast Gradient Sign (FGSM). L'ajout d'heuristiques l'a rendu PEU meilleur;
- Méthode Fast Gradient Value (FGVM). L'ajout d'heuristiques l'a rendu FORTEMENT meilleur;
- Evolution différentielle génétique (excellent article sur cette méthode) + attaques pixel par pixel;
- Ensembles de modèles (solution haut de gamme ... 6 ResNet34 «empilés»);
- Contournement intelligent des combinaisons d'images cibles;
- Essentiellement, arrêt précoce lors d'une attaque FGVM;
Ce qui n'a pas fonctionné dans notre cas:
- Ajouter un «moment d'inertie» à la FGVM (même si cela a fonctionné pour l'équipe qui s'est classée plus bas, est-il possible que les ensembles + heuristiques aient mieux fonctionné que d'ajouter un moment?);
- Attaque C&W (essentiellement une attaque de bout en bout visant les journaux du modèle à boîte blanche) - fonctionne pour la boîte blanche (BY), ne fonctionne pas pour la boîte noire (CN);
- Une approche basée sur le Siamese LinkNet de bout en bout (architecture similaire à UNet, mais basée sur ResNet). Aussi travaillé uniquement pour BY;
Ce que nous n'avons pas essayé (n'a pas eu le temps, n'a pas eu assez d'efforts ou était trop paresseux):
- Test d'augmentation interprétative pour l'apprentissage des élèves (je devrais aussi raconter les descripteurs - c'est facile, mais une idée si simple n'est pas venue tout de suite);
- Augmentation pendant l'attaque - par exemple, «refléter» l'image de gauche à droite;
À propos du concours en général:
- L'ensemble de données était «trop petit» (1000 combinaisons 5 + 5);
- L'ensemble de données sur la formation nette des étudiants était relativement volumineux (plus d'un million d'images);
- CE a été présenté comme un ensemble de modèles précompilés sur Caffe (naturellement, dans nos environnements, ils ont d'abord publié des bugs). Cela a également introduit une certaine complexité, car QW n'acceptait pas les images avec des lots;
- La compétition avait une excellente ligne de base (solution de base), sans laquelle, à mon avis, peu de personnes seraient directement impliquées sérieusement;
Ressources:
1. Aperçu du concours Machines peut voir 2018 et comment je me suis lancé
Compétition et approches
Honnêtement, j'ai été attiré par un nouveau domaine intéressant, la GTX 1080Ti Founders 'Edition en prix, et une concurrence relativement faible (qui ne serait pas comparable à 4000 personnes dans n'importe quelle compétition à Kaggle contre l'ODS entier avec 20 GPU par équipe).
Comme mentionné ci-dessus, le concours avait pour but de tromper le modèle CE afin que ce dernier ne puisse pas faire la distinction entre deux personnes différentes (au sens de la norme L2 / distance euclidienne). Eh bien, comme il s'agissait d'une boîte noire, nous avons dû distiller les réseaux étudiants sur les données fournies et espérons que les gradients du QW et du BYW seraient suffisamment similaires pour mener à bien l'attaque.
Si vous lisez des critiques d'articles (par exemple,
ici et
là , bien que ces articles ne disent pas vraiment ce qui fonctionne dans la pratique) et compilez ce que les meilleures équipes ont accompli, alors vous pouvez décrire brièvement ces meilleures pratiques:
- Les attaques les plus simples dans la mise en œuvre impliquent BY ou la connaissance de la structure interne du réseau neuronal convolutionnel (ou simplement de l'architecture) sur laquelle l'attaque est effectuée;
- Quelqu'un dans le chat a suggéré de suivre le temps d'inférence sur le CE et d'essayer de deviner son architecture;
- Ayant accès à une quantité suffisante de données, vous pouvez émuler QW avec QW bien formé
- Vraisemblablement, les méthodes les plus avancées sont:
- Attaque C&W de bout en bout (n'a pas fonctionné dans ce cas);
- Extensions FGSM intelligentes (c'est-à-dire moment d'inertie + ensembles délicats);
Honnêtement, nous étions encore confus par le fait que deux approches de bout en bout complètement différentes, mises en œuvre indépendamment par deux personnes différentes de l'équipe, ne fonctionnaient pas stupidement pour CH. Essentiellement, cela pourrait signifier que dans notre interprétation de l'énoncé du problème quelque part, il y a eu une fuite de données que nous n'avons pas remarquée (ou que les mains étaient tordues). Dans de nombreuses tâches de vision par ordinateur modernes, les solutions de bout en bout (par exemple, le transfert de style, le bassin versant profond, la génération d'images, le nettoyage du bruit et des artefacts, etc.) sont soit bien meilleures que tout ce qui était auparavant, ou ne fonctionnent pas du tout. Meh.
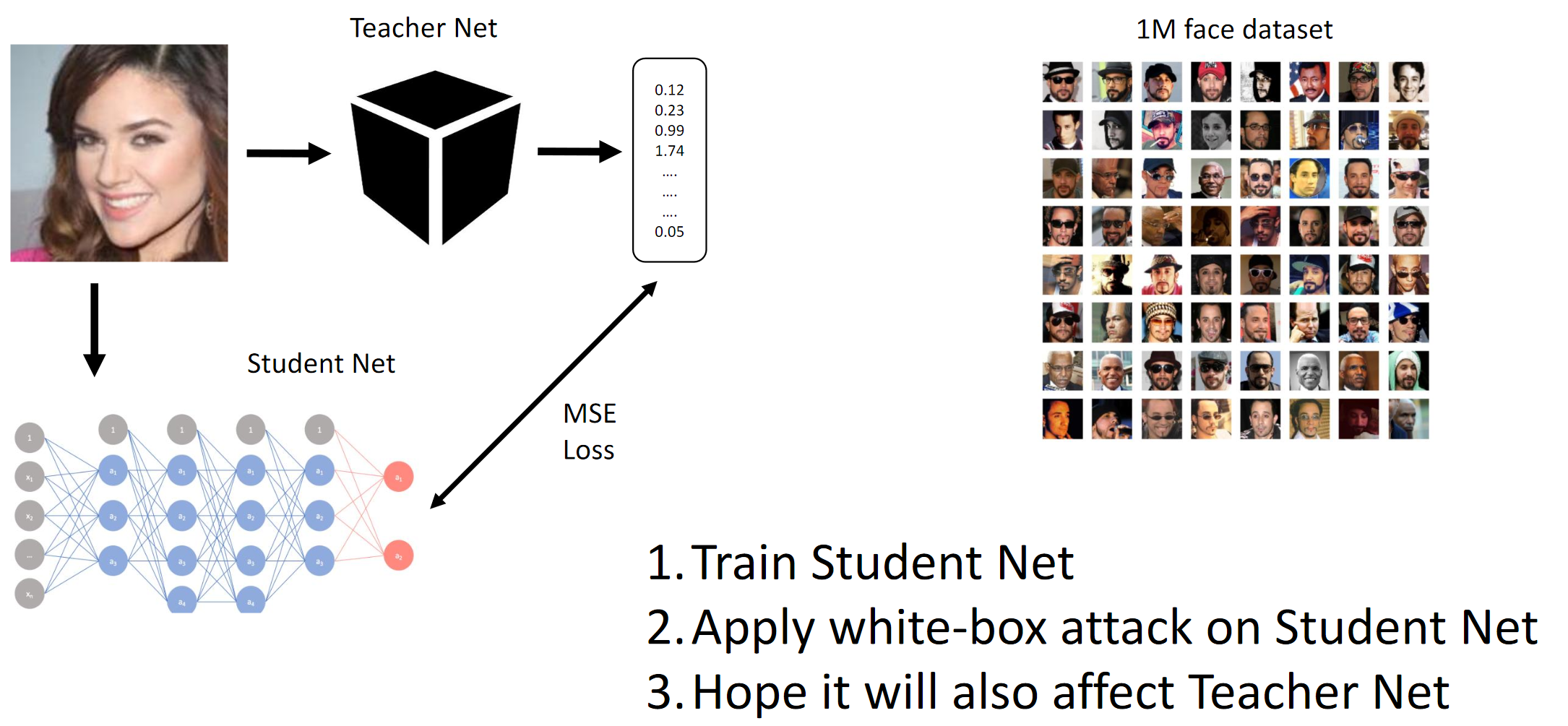 1. Former Student Net. 2. Appliquez l'attaque BY sur Student Net. 3. Les attaques de Hope Teacher Net se propagent égalementFonctionnement de la méthode du dégradé
1. Former Student Net. 2. Appliquez l'attaque BY sur Student Net. 3. Les attaques de Hope Teacher Net se propagent égalementFonctionnement de la méthode du dégradé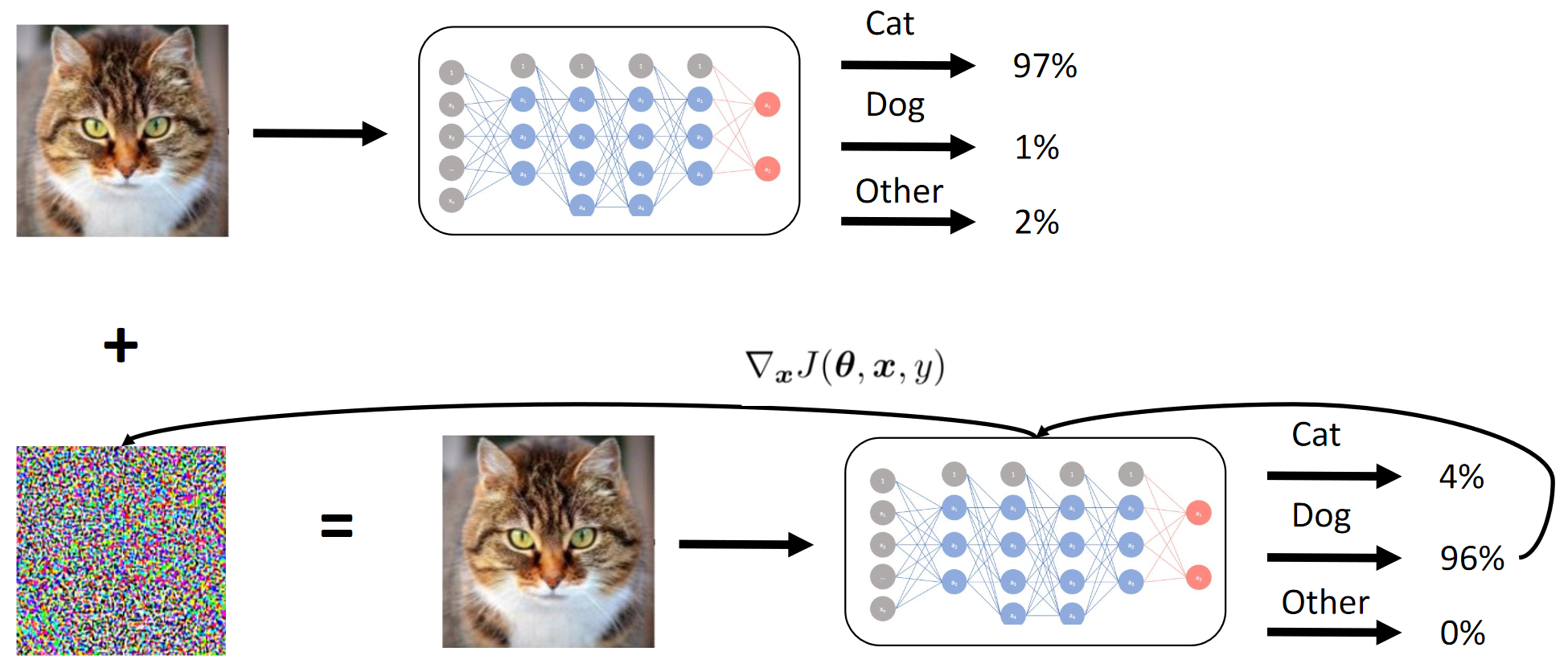
Nous obtenons essentiellement par distillation que le BY émule le BY. Ensuite, les gradients des images d'entrée par rapport à la sortie du modèle sont considérés. Le secret, comme d'habitude, réside dans l'heuristique.
Métrique cible
La métrique cible était la norme L2 moyenne (distance euclidienne) entre les 25 combinaisons d'images source et cible (5 * 5 = 25).
En raison des limites de la plate-forme (CodaLab), il était probable que les scores privés (et la fusion des équipes) aient été calculés manuellement, ce qui serait une telle histoire.

L'équipe
J'ai rejoint l'équipe après avoir formé les grilles d'étudiants, mieux que tout le monde dans le classement (pour autant que je sache), et après une petite discussion avec
Atmyre (elle a aidé avec le QW correctement compilé, car elle-même faisait face au même). Ensuite, nous avons partagé nos scores locaux sans partager les approches et le code, et en fait, 2-3 jours avant la ligne d'arrivée, les événements suivants se sont produits:
- Mes modèles continus ont floppé (oui, dans ce cas aussi);
- J'avais les meilleurs modèles étudiants;
- Ils (équipes) avaient les meilleures variations heuristiques pour FGVM (leur code était basé sur la ligne de base);
- J'ai juste essayé des modèles avec des gradients et atteint une vitesse locale autour de 1,1 - au départ, je ne voulais pas utiliser une ligne de base de mes préférences personnelles (je me suis mis au défi);
- Ils n'avaient pas assez de puissance de calcul à l'époque;
- En fin de compte, nous avons tenté notre chance et nous avons uni nos forces - j'ai investi ma puissance de calcul / réseaux de neurones convolutionnels / ensemble de tests d'ablation. L'équipe a mis sa base de code, qu'elle a peaufinée pendant quelques semaines;
Encore une fois, je tiens à la remercier pour ses précieux conseils et ses compétences organisationnelles.
Composition de l'équipe:
github.com/atmyre - basé sur les actions, était le capitaine de l'équipe au départ. Ajout d'une attaque d'évolution génétique différentielle dans la soumission finale;
github.com/mortido - la meilleure implémentation d'attaques FGVM avec une excellente heuristique + 2 modèles formés utilisant le code de base;
github.com/snakers4 - en plus des tests visant à réduire le nombre d'options pour trouver une solution, j'ai formé 3 modèles étudiants avec les meilleures métriques + fourni la puissance de calcul + aidé dans la phase de soumission finale et de présentation des résultats;
github.com/stalkermustang;En conséquence, nous avons tous beaucoup appris les uns des autres et je suis heureux que nous ayons tenté notre chance dans cette compétition. L'absence d'au moins une contribution sur trois entraînerait la défaite.
2. Étudiant en distillation CNN
J'ai réussi à obtenir la meilleure vitesse lors de la formation des modèles étudiants, car j'ai utilisé mon propre code au lieu du code de base.
Points clés / ce qui a fonctionné:- Sélection d'un programme d'entraînement pour chaque architecture individuellement;
- Premier entraînement avec désintégration Adam + LR;
- Surveillance attentive du sous-ajustement et du sur-ajustement et de la capacité du modèle;
- Réglage manuel des modes d'entraînement. Ne faites pas entièrement confiance aux schémas automatiques: ils peuvent fonctionner, mais si vous définissez bien les paramètres, le temps de formation peut être réduit de 2 à 3 fois. Ceci est particulièrement important avec les modèles lourds comme DenseNet;
- Les architectures lourdes ont mieux performé que les architectures légères, sans compter VGG;
- L'entraînement avec une perte de L2 au lieu de MSE fonctionne également, mais un peu pire;
Ce qui n'a pas fonctionné:- Architectures basées sur la création (ne conviennent pas en raison d'un sous-échantillonnage élevé et d'une résolution d'entrée plus élevée). Bien que l'équipe en troisième place ait pu d'une manière ou d'une autre utiliser Inception-v1 et des images complètes (~ 250x250);
- Architectures basées sur VGG (sur-ajustement);
- Architectures légères (SqueezeNet / MobileNet - sous-montage);
- Augmentation des images (sans modifier les descripteurs - bien que l'équipe l'ait en quelque sorte retiré de la troisième place);
- Travailler avec des images en taille réelle;
- À la fin des réseaux de neurones fournis par les organisateurs du concours, il y avait également une couche standard de lot. Cela n'a pas aidé mes collègues et j'ai utilisé mon code, car je ne comprenais pas très bien pourquoi cette couche était là;
- Utilisation de cartes de saillance avec des attaques basées sur les pixels. Je suppose que cela est plus applicable aux images en taille réelle (il suffit de comparer 112x112x search_space et 299x299x search_space);
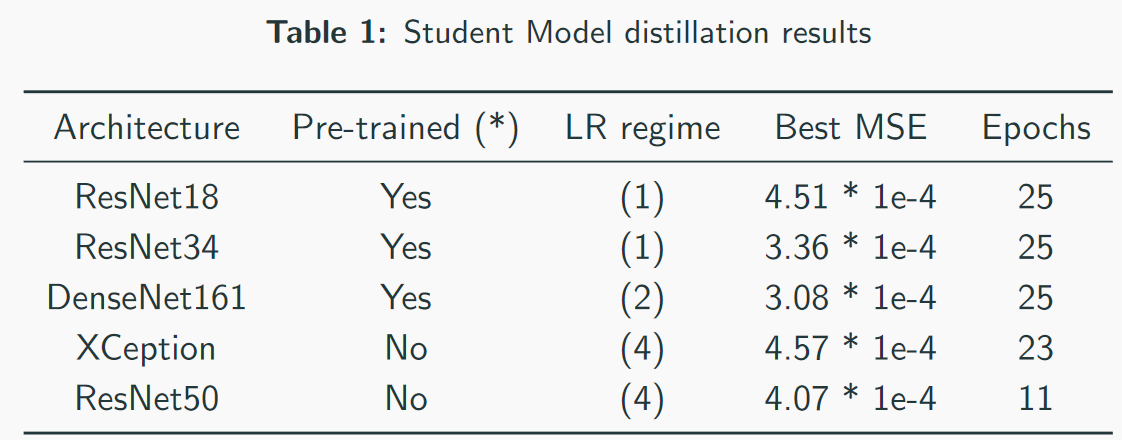 Nos meilleurs modèles - notez que la meilleure vitesse est de 3 * 1e-4. À en juger par la complexité des modèles, on peut à peu près imaginer que QW est ResNet34. Lors de mes tests, ResNet50 + a donné de moins bons résultats que ResNet34.
Nos meilleurs modèles - notez que la meilleure vitesse est de 3 * 1e-4. À en juger par la complexité des modèles, on peut à peu près imaginer que QW est ResNet34. Lors de mes tests, ResNet50 + a donné de moins bons résultats que ResNet34.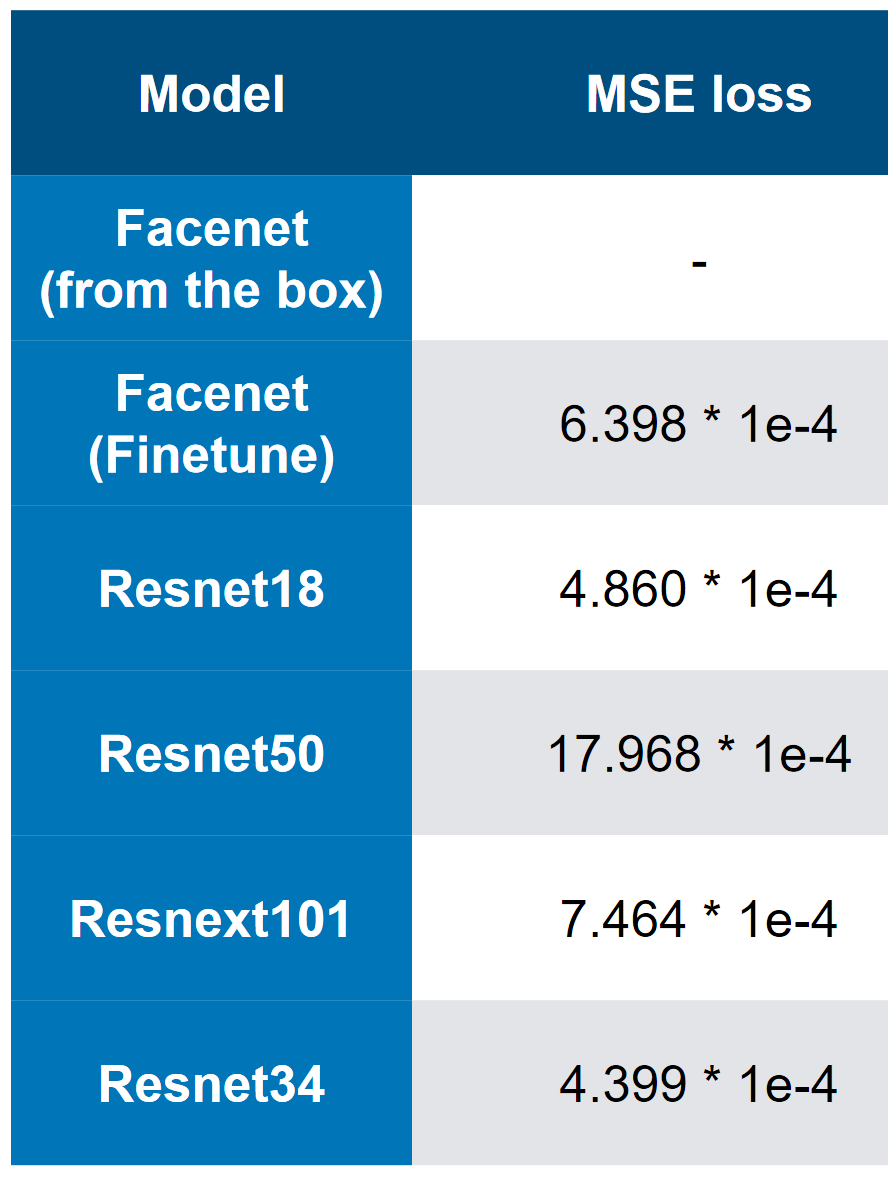 MSE première perte
MSE première perte3. La vitesse finale et l'analyse "d'ablation"
Nous avons collecté notre vitesse comme ceci:
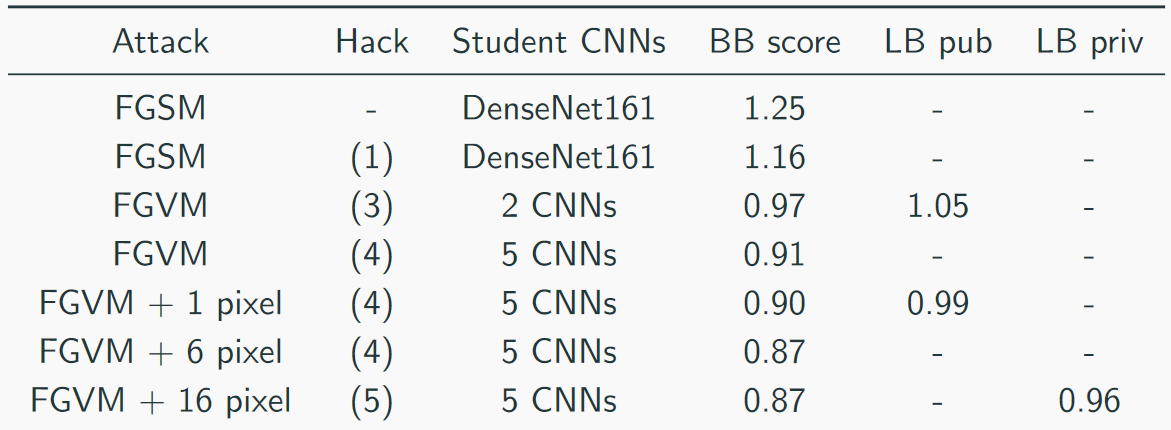
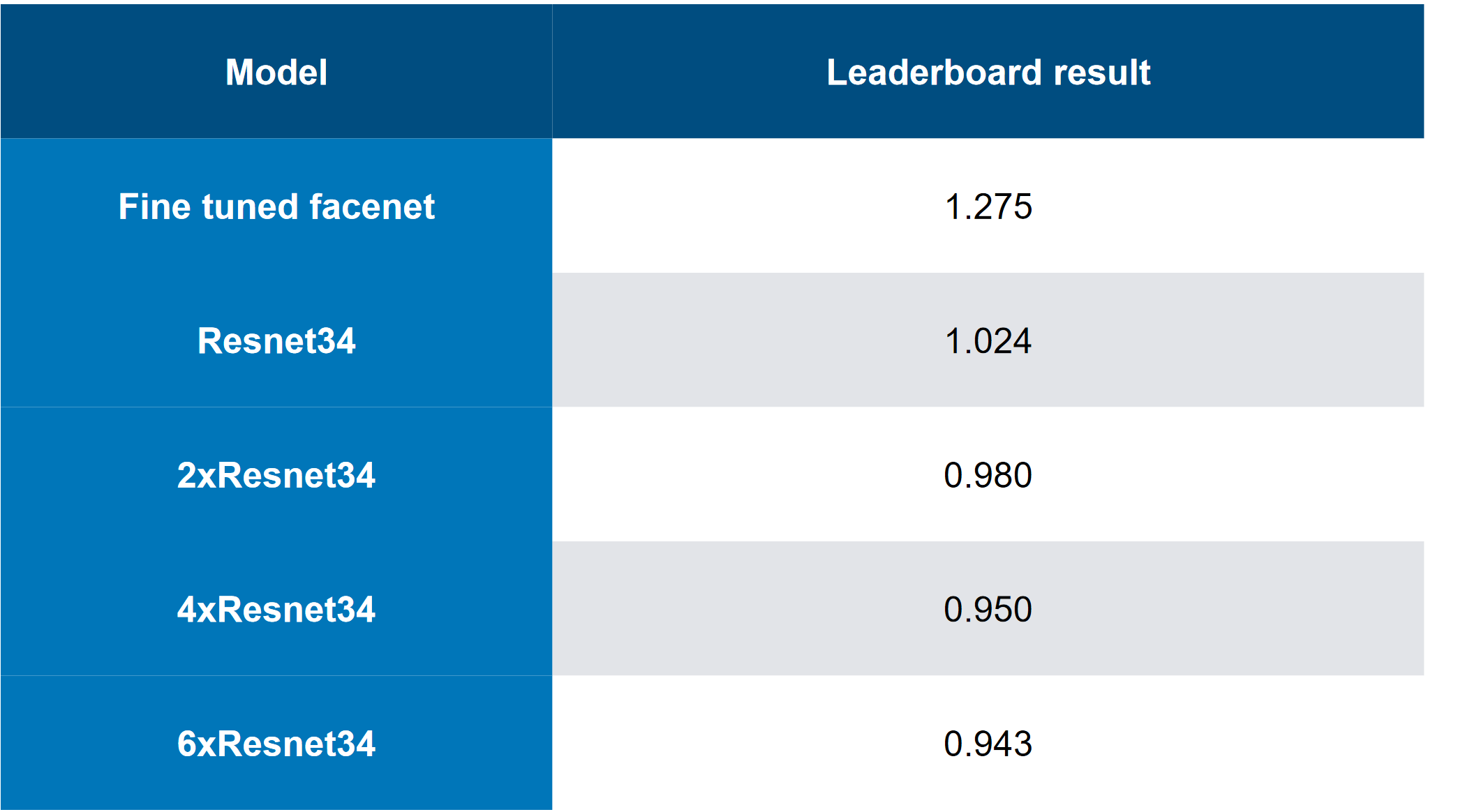
La meilleure solution ressemblait à ceci (oui, il y avait des blagues sur le fait que simplement empiler l'abattage, vous pouvez deviner que CH est un abattage):
Autres approches utiles d'autres équipes:
- Paramètre adaptatif epsilon;
- Augmentation des données
- Moment d'inertie;
- Le moment de Nesterov ;
- Images miroir;
- «Hackez» un peu les données - il n'y avait que 1000 images uniques et 5000 combinaisons d'images => il était possible de générer plus de données (pas 5 cibles, mais 10, car les images étaient répétées);
Heuristique utile pour FGVM:
- Génération de bruit par la règle: Bruit = pince eps * (grad / grad.std (), -2, 2);
- Un ensemble de plusieurs CNN en pondérant leurs gradients;
- Enregistrer les modifications uniquement si elles réduisent la perte moyenne;
- Utilisez des combinaisons de cibles pour un ciblage plus cohérent
- Utilisez uniquement des gradients supérieurs à la moyenne + std (pour FGSM);
Sammari court:
- En premier lieu, une décision plus "maladroite"
- Nous avions la solution la plus "diversifiée";
- En troisième place, la solution la plus «élégante»;
Solutions de bout en bout
Même s'ils ont échoué, ils méritent un nouvel essai à l'avenir sur de nouvelles tâches. Voir les détails dans le référentiel, mais en fait, nous avons essayé ce qui suit:
- Attaque C&W;
- Siamese LinkNet;
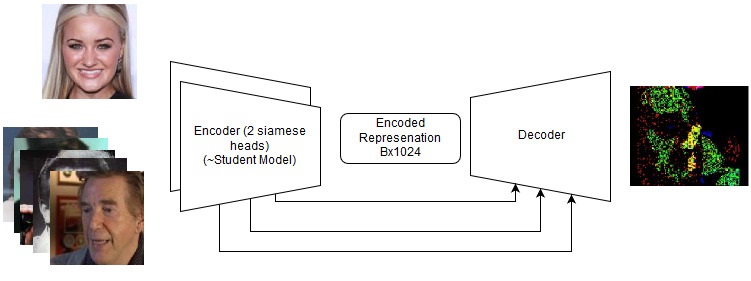 Modèle de bout en bout
Modèle de bout en bout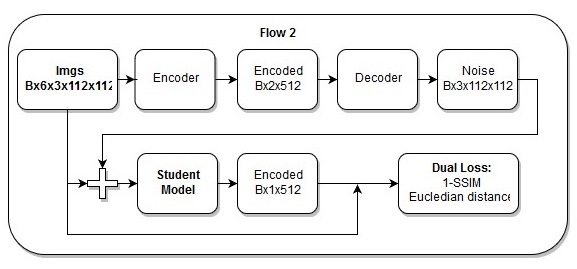 La séquence d'actions dans le modèle de bout en bout
La séquence d'actions dans le modèle de bout en boutJe pense aussi que ma
perte est tout simplement magnifique.
5. Références et documents de lecture supplémentaires
- Page Concours ;
- Notre référentiel ;
- Une série d'articles sur la VAE est un sujet similaire;
- Ressources SSIM
- Wiki
- Implémentation de PyTorch "backpropable"
- Ressources pour l'évolution différentielle
- Présentations
- 2 articles les plus utiles:
- 2 articles de revue "en haut":