
Annotation
Le traitement des données en temps réel exactement une fois ( exactement une fois ) est une tâche extrêmement simple et nécessite une approche sérieuse et réfléchie tout au long de la chaîne de calculs. Certains pensent même qu'une telle tâche est impossible . En réalité, je veux avoir une approche qui fournit un traitement tolérant aux pannes sans aucun délai et l'utilisation de divers stockages de données, ce qui met en avant de nouvelles exigences encore plus strictes pour le système: simultané une seule fois et l'hétérogénéité de la couche persistante. À ce jour, une telle exigence ne prend en charge aucun des systèmes existants.
L'approche proposée révélera de manière cohérente les ingrédients secrets et les concepts nécessaires qui facilitent la mise en œuvre d' un traitement simultané hétérogène simultané à partir de deux composants.
Présentation
Le développeur de systèmes distribués passe par plusieurs étapes:
Étape 1: algorithmes . Voici l'étude des algorithmes de base, des structures de données, des approches de programmation telles que la POO, etc. Le code est exclusivement monothread. La phase initiale d'entrée dans la profession. Cependant, c'est assez compliqué et peut durer des années.
Étape 2: Multithreading . Ensuite, des questions se posent pour extraire une efficacité maximale du fer, il y a le multithreading, l'asynchronie, la course, le débogage, le strace, les nuits blanches ... Beaucoup sont bloqués à ce stade et commencent même à ressentir un frisson inexplicable à un moment donné. Mais seuls quelques-uns parviennent à comprendre l'architecture de la mémoire virtuelle et des modèles de mémoire, des algorithmes sans verrouillage / sans attente et divers modèles asynchrones. Et presque personne jamais - la vérification de code multi-thread.
Étape 3: Distribution . Ici, une telle poubelle se produit que ni dans un conte de fées ni un stylo à décrire.
Il semblerait que quelque chose de compliqué. Nous faisons la transformation: plusieurs threads -> de nombreux processus -> de nombreux serveurs. Mais chaque étape de la transformation entraîne des changements qualitatifs, et ils tombent tous sur le système, l'écrasant et le transformant en poussière.
Et le point ici est de changer le domaine de gestion des erreurs et la disponibilité de la mémoire partagée. Si auparavant, il y avait toujours un morceau de mémoire qui était disponible dans chaque thread, et si vous le souhaitez, dans chaque processus, maintenant il n'y a pas un tel morceau et ne peut pas l'être. Chacun pour soi, indépendant et fier.
Si plus tôt, une défaillance du flux a enterré le flux et le processus en même temps, et c'était bien, car n'a pas conduit à des échecs partiels, maintenant les échecs partiels deviennent la norme et à chaque fois avant chaque action, vous pensez: "Et si?". C'est tellement ennuyeux et distrayant d'écrire, en fait, les actions elles-mêmes que le code à cause de cela croît non pas parfois, mais par ordre de grandeur. Tout se transforme en nouilles de gestion des erreurs, de changement d'état et de préservation du contexte, de restauration en raison de défaillances d'un composant, d'un autre composant, de l'inaccessibilité de certains services, etc. etc. Après avoir raté la surveillance de tout cela, vous pouvez passer une bonne nuit de sommeil sur votre ordinateur portable préféré.
Que ce soit une question de multithreading: j'ai pris le mutex et suis allé déchiqueter la mémoire partagée pour le plaisir. La beauté!
En conséquence, nous avons que les modèles clés et testés au combat ont été retirés, et les nouveaux, pour les remplacer, pour une raison quelconque, n'ont pas été livrés, et il s'est avéré comme dans une blague sur la façon dont la fée a agité sa baguette et la tour est tombée du réservoir.
Cependant, les systèmes distribués ont un ensemble de pratiques éprouvées et d'algorithmes éprouvés. Cependant, chaque programmeur qui se respecte considère qu'il est de son devoir de rejeter des réalisations bien connues et de faire du vélo son propre bien, malgré l'expérience acquise, un nombre considérable d'articles scientifiques et de recherches universitaires. Après tout, si vous pouvez utiliser des algorithmes et du multithreading, comment pouvez-vous vous retrouver dans un pétrin avec la distribution? Il ne peut y avoir deux opinions ici!
En conséquence, les systèmes sont bogués, les données divergent et se détériorent, les services deviennent périodiquement indisponibles pour l'écriture, ou même complètement indisponibles, car soudainement un nœud s'est écrasé, le réseau est tombé en panne, Java a consommé beaucoup de mémoire et GC est terne, et il existe de nombreuses autres raisons qui pourraient retarder sa fin aux autorités.
Cependant, même avec des approches connues et éprouvées, la vie ne devient pas plus facile, car les primitives fiables distribuées sont lourdes avec des exigences sérieuses pour la logique du code exécutable. Par conséquent, les coins sont coupés dans la mesure du possible. Et, comme cela arrive souvent, avec des raccourcis hâtifs, la simplicité et l'évolutivité relative apparaissent, mais la fiabilité, la disponibilité et la cohérence d'un système distribué disparaissent.
Idéalement, je ne voudrais pas du tout penser que notre système est distribué et multithread, c'est-à-dire travailler au 1er étage (algorithmes), sans penser aux 2e (multithreading + asynchronie) et 3e (distribution). Cette façon d'isoler les abstractions augmenterait considérablement la simplicité, la fiabilité et la vitesse d'écriture du code. Malheureusement, pour le moment, cela n'est possible que dans les rêves.
Cependant, les abstractions individuelles permettent un isolement relatif. L'un des exemples typiques est l' utilisation de coroutines , où au lieu de code asynchrone nous obtenons synchrone, c'est-à-dire on passe de la 2ème étape à la 1ère étape, ce qui nous permet de simplifier considérablement la rédaction et la maintenance du code.
L'article révèle successivement l'utilisation d'algorithmes sans verrouillage pour construire un système temps réel évolutif distribué, cohérent et fiable, c'est-à-dire comment les réalisations sans verrouillage de la 2e étape aident à la mise en œuvre de la 3e, réduisant la tâche aux algorithmes à un seul thread de la première étape.
Énoncé du problème
Cette tâche illustre seulement quelques approches importantes et est présentée comme un exemple pour introduire des problèmes dans le contexte. Il peut être facilement généralisé à des cas plus complexes, ce qui sera fait à l'avenir.
Tâche: traitement des données en streaming en temps réel .
Il existe deux flux de nombres. Le gestionnaire lit les données de ces flux d'entrée et sélectionne les derniers nombres pour une certaine période. Ces nombres sont moyennés sur cet intervalle de temps, c'est-à-dire dans une fenêtre de données glissante pour un temps donné. La valeur moyenne obtenue doit être écrite dans la file d'attente de sortie pour un traitement ultérieur. De plus, si le nombre de nombres dans la fenêtre dépasse un certain seuil, alors augmentez de un le compteur dans la base de données transactionnelle externe.
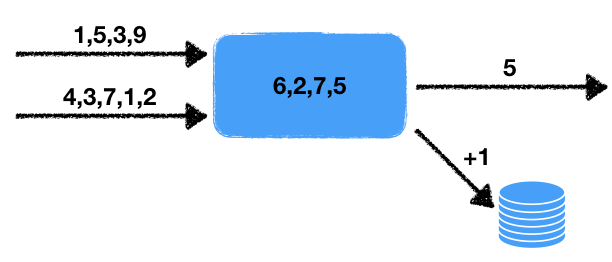
Nous notons certaines caractéristiques de ce problème.
- Non-déterminisme . Il existe deux sources de comportement non déterministe: il s'agit d'une lecture de deux flux, ainsi que d'une fenêtre temporelle. Il est clair que la lecture peut être effectuée de différentes manières, et le résultat final dépendra de la séquence dans laquelle les données seront extraites. La fenêtre temporelle modifie également le résultat du début à la quantité de données dans la fenêtre dépendra de la vitesse de travail.
- L'état du gestionnaire . Il existe un état du gestionnaire sous la forme d'un ensemble de nombres dans la fenêtre, dont dépendent les résultats actuels et ultérieurs du travail. C'est-à-dire nous avons un gestionnaire avec état.
- Interaction avec le stockage externe . Il est nécessaire de mettre à jour la valeur du compteur dans la base de données externe. Le point crucial est que le type de stockage externe est différent du stockage de l'état du processeur et des threads.
Tout cela, comme nous le montrerons ci-dessous, affecte sérieusement les outils utilisés et les méthodes de mise en œuvre possibles.
Il reste à ajouter une petite touche à la tâche, ce qui transfère immédiatement la tâche d'un domaine au-delà de la complexité à un impossible: une garantie concomitante en une seule fois est nécessaire.
Exactement une fois
Exactement une fois est souvent interprété de manière trop large, ce qui émascule le terme lui-même et cesse de répondre aux exigences initiales de la tâche. Si nous parlons d'un système qui s'exécute localement sur un ordinateur - alors tout est simple: prenez plus, jetez plus loin. Mais dans ce cas, nous parlons d'un système distribué dans lequel:
- Le nombre de gestionnaires peut être important: chaque gestionnaire travaille avec sa propre donnée. De plus, les résultats peuvent être ajoutés à divers endroits, par exemple, une base de données externe, éventuellement même mélangée.
- Chaque gestionnaire peut interrompre soudainement le traitement. Un système tolérant aux pannes implique un fonctionnement continu même en cas de défaillance de certaines parties du système.
Ainsi, nous devons être préparés au fait que le gestionnaire peut tomber, et un autre gestionnaire devrait reprendre le travail déjà effectué et poursuivre le traitement.
La question se pose immédiatement: que signifiera exactement une fois si le gestionnaire non déterministe fonctionne? Après tout, à chaque redémarrage, nous recevons, de manière générale, différents états résultants. La réponse ici est simple: avec exactement une fois, il y a une telle exécution du système dans laquelle chaque valeur d'entrée est traitée exactement une fois, donnant le résultat de sortie correspondant. De plus, cette exécution n'a pas besoin d'être physiquement sur le même nœud. Mais le résultat devrait être comme si tout était traité sur un seul nœud logique sans se bloquer .
Exactement simultané
Pour aggraver les exigences, nous introduisons un nouveau concept: simultané une seule fois . La différence fondamentale avec une seule fois exactement est l'absence de pauses pendant le traitement, comme si tout était traité sur le même noeud sans pertes et sans pauses . Dans notre tâche, nous aurons besoin d'exactement simultané exactement une fois , pour la simplicité de la présentation, afin de ne pas considérer une comparaison avec les systèmes existants qui ne sont pas disponibles aujourd'hui.
Les conséquences d'une telle exigence seront discutées ci-dessous.
Transactionnel
Afin que le lecteur soit encore plus profondément imprégné de la complexité qui est apparue, examinons divers mauvais scénarios qui doivent être pris en compte lors du développement d'un tel système. Nous essaierons également d'utiliser une approche générale qui nous permettra de résoudre le problème ci-dessus en tenant compte de nos exigences.
La première chose qui me vient à l'esprit est la nécessité d'enregistrer l'état du gestionnaire et les flux d'entrée et de sortie. L'état des flux de sortie est décrit par une simple file d'attente de nombres, et l'état des flux d'entrée par leur position. En substance, un flux est une file d'attente infinie et une position dans la file d'attente définit uniquement un emplacement.

L'implémentation naïve suivante d'un gestionnaire survient à l'aide d'une sorte d'entrepôt de données. À ce stade, les propriétés spécifiques du référentiel ne seront pas importantes pour nous. Nous utiliserons le langage Pseco pour illustrer l'idée (Pseco: = pseudo code):
handle(input_queues, output_queues, state): # input_indexes = storage.get_input_indexes() # while true: # items, new_input_indexes = input_queues.get_from(input_indexes) # state.queue.push(items) # duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) output_queues[0].push(avg) if need_update_counter: # (B) db.increment_counter() # (C) storage.save_state(state) # (D) storage.save_queue_indexes(new_input_indexes) # (E) input_indexes = new_input_indexes
Voici un algorithme simple à un seul thread qui lit les données des flux d'entrée et écrit les valeurs souhaitées selon la tâche décrite ci-dessus.
Voyons ce qui se passe en cas de chute d'un nœud à des moments arbitraires, ainsi qu'après la reprise du travail. Il est clair qu'en cas de chute aux points (A) et (E) tout ira bien: soit les données n'ont pas encore été enregistrées n'importe où et nous restaurez simplement l'état et continuons sur un autre nœud, soit toutes les données nécessaires ont déjà été enregistrées et continuons simplement l'étape suivante.
Cependant, en cas de chute à tous les autres points, des troubles inattendus nous attendent. Si une baisse se produit au point (B) , alors lorsque le gestionnaire est redémarré, nous restaurons l'état et réenregistrons la valeur moyenne dans approximativement la même plage de nombres. Dans le cas d'une chute au point (C) en plus du doublon moyen, un doublon se produira dans l'incrément de la valeur. Et en cas de baisse de (D) nous obtiendrons un état incohérent du gestionnaire: l'état correspond à un nouveau moment dans le temps, et nous lirons les valeurs des flux d'entrée anciens.

Dans le même temps, rien ne changera fondamentalement lors de la réorganisation des opérations d'enregistrement: les incohérences et les doublons le resteront. Ainsi, nous arrivons à la conclusion que toutes les actions visant à modifier l'état du gestionnaire dans le référentiel, la file d'attente de sortie et la base de données doivent être effectuées de manière transactionnelle, c'est-à-dire tout est atomique en même temps.
En conséquence, il est nécessaire de développer un mécanisme de sorte que différents stockages puissent changer transactionnellement leur état, et non à l'intérieur de chacun indépendamment, mais transactionnellement entre tous les stockages simultanément. Bien sûr, vous pouvez placer notre stockage dans une base de données externe, cependant, la tâche supposait que le moteur de base de données et le moteur pour le cadre de traitement des données en streaming sont séparés et fonctionnent indépendamment l'un de l'autre. Ici, je veux considérer le cas le plus difficile, car les cas simples ne sont pas intéressants à considérer.
Réactivité compétitive
Considérez l'exécution concurrentielle exactement une fois de plus. Dans le cas d'un système tolérant aux pannes, nous avons besoin de poursuivre le travail à partir d'un certain point. Il est clair que ce point se situera dans le passé, car Pour maintenir les performances, il est impossible de stocker tous les moments de changements d'état dans le présent et dans le futur: soit le dernier résultat des opérations, soit un groupe de valeurs pour augmenter le débit est enregistré. Ce comportement nous amène immédiatement au fait qu'après restauration de l'état du processeur, il y aura un certain retard dans les résultats, il augmentera avec l'augmentation de la taille du groupe de valeurs et de la taille de l'état.
En plus de ce retard, il existe également des retards dans le système associés au chargement de l'état sur un autre nœud. En plus de cela, la détection d'un nœud problématique prend également un certain temps, et souvent beaucoup. Cela est dû, tout d'abord, au fait que si nous fixons un temps de détection court, des fausses alarmes fréquentes sont possibles, ce qui entraînera toutes sortes d'effets spéciaux désagréables.
De plus, avec l'augmentation du nombre de processeurs parallèles, il s'avère soudainement que tous ne fonctionnent pas aussi bien même en l'absence de pannes. Parfois, des émoussements se produisent, ce qui entraîne également des retards de traitement. La raison de ces contours peut être variée:
- Logiciel : pauses du GC, fragmentation de la mémoire, pauses d'allocateur, interruption du noyau et planification des tâches, problèmes avec les pilotes de périphériques entraînant des ralentissements.
- Matériel : charge élevée du disque ou du réseau, limitation du processeur en raison de problèmes de refroidissement, surcharge, etc., ralentissement du disque en raison de problèmes techniques.
Et ce n'est en aucun cas une liste exhaustive des problèmes qui peuvent ralentir les gestionnaires.
En conséquence, le ralentissement est une donnée avec laquelle il faut vivre. Parfois, ce n'est pas un problème grave, et parfois il est extrêmement important de maintenir une vitesse de traitement élevée malgré les échecs ou les ralentissements.
Immédiatement, l'idée de duplication de systèmes se pose: exécutons pour un même flux de données non pas un mais deux processeurs à la fois, voire trois. Le problème ici est que dans ce cas, des doublons et un comportement système incohérent peuvent facilement se produire. En règle générale, les cadres ne sont pas conçus pour ce comportement et suggèrent que le nombre de gestionnaires à un moment donné ne dépasse pas un. Les systèmes qui permettent la duplication d'exécution décrite sont appelés simultanés une seule fois .
Cette architecture vous permet de résoudre plusieurs problèmes à la fois:
- Comportement à sécurité intégrée: si l'un des nœuds tombe, l'autre continue simplement de fonctionner comme si de rien n'était. Aucune coordination supplémentaire n'est nécessaire, car le second gestionnaire est exécuté quel que soit l'état du premier.
- Suppression des contours: celui qui a fourni le résultat en premier est bon pour lui. L'autre n'aura qu'à prendre un nouvel état et continuer à partir de ce moment.
Cette approche, en particulier, vous permet d'effectuer un calcul long et difficile pour un temps plus prévisible, car la probabilité que les deux soient stupides et tombent beaucoup moins.
Évaluation des probabilités
Essayons d'évaluer les avantages de la duplication des performances. Supposons que quelque chose se passe en moyenne tous les jours avec le gestionnaire: soit le GC est émoussé, soit le nœud est couché, soit les conteneurs sont devenus cancéreux. Supposons également que nous préparions des paquets de données en 10 secondes.
La probabilité que quelque chose se produise lors de la création du pack est alors de 10 / (24 · 3600) ≃ 1e-4 .
Si vous exécutez deux gestionnaires en parallèle, la probabilité que les deux volent soit ≃ 1e-8 . Cet événement arrivera donc dans 23 ans! Oui, les systèmes ne vivent pas autant, ce qui signifie que cela n'arrivera jamais!
De plus, si le temps de préparation de l'emballage sera encore plus court et / ou que les émoussements se produiront encore moins souvent, ce chiffre ne fera qu'augmenter.
Ainsi, nous concluons que l'approche envisagée augmente considérablement la fiabilité de l'ensemble de notre système. Il ne reste plus qu'à résoudre une petite question comme celle-ci: où lire pour savoir comment créer un système simultané en une seule fois . Et la réponse est simple: vous devez lire ici.
Demi transaction
Pour une discussion plus approfondie, nous avons besoin du concept d'une demi-transaction . La façon la plus simple de l'expliquer est avec un exemple.
Envisagez de transférer des fonds d'un compte bancaire à un autre. L'approche traditionnelle utilisant des transactions en langage Pseco peut être décrite comme suit:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
Cependant, que se passe-t-il si ces transactions ne sont pas disponibles pour nous? À l'aide de verrous, cela peut être fait comme suit:
transfer(from, to, amount): # lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
Cette approche peut conduire à des blocages, comme les verrous peuvent être pris en différentes séquences en parallèle. Pour corriger ce comportement, il suffit d'introduire une fonction qui prend simultanément plusieurs verrous dans une séquence déterministe (par exemple, trie par clés), ce qui élimine complètement les éventuels blocages.
Cependant, la mise en œuvre peut être quelque peu simplifiée:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # , # .. db.set(db.get...) lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
Cette approche rend également l'état final cohérent, en préservant les invariants par le type de prévention des dépenses excessives de fonds. La principale différence par rapport à l'approche précédente est que dans une telle mise en œuvre, nous avons un certain laps de temps pendant lequel les comptes sont dans un état incohérent. A savoir, une telle opération implique que l'état total des fonds dans les comptes ne change pas. Dans ce cas, il y a un intervalle de temps entre lock_from.release() et db.lock(to) , pendant lequel la base de données peut donner une valeur incohérente: le montant total peut différer de la bonne vers le bas.
En fait, nous avons divisé une transaction pour transférer de l'argent en deux demi-transactions:
- La première demi-transaction fait un chèque et déduit le montant nécessaire du compte.
- La deuxième demi-transaction écrit le montant retiré sur un autre compte.
Il est clair que la division d'une transaction en transactions plus petites, d'une manière générale, viole le comportement transactionnel. Et l'exemple ci-dessus ne fait pas exception. Cependant, si toutes les demi-transactions de la chaîne sont entièrement remplies, le résultat sera cohérent avec tous les invariants préservés. C'est précisément ce qui est une propriété importante d'une chaîne de demi-transaction.
Perdant temporairement une certaine cohérence, nous acquérons néanmoins une autre caractéristique utile: l'indépendance des opérations et, par conséquent, une meilleure évolutivité. L'indépendance se manifeste dans le fait qu'une demi-transaction à chaque fois fonctionne avec une seule ligne, lisant, vérifiant et modifiant ses données, sans communiquer avec d'autres données. Ainsi, vous pouvez mélanger une base de données dont les transactions fonctionnent avec un seul fragment. De plus, cette approche peut être utilisée dans le cas de référentiels hétérogènes, c'est-à-dire les demi-transactions peuvent commencer sur un type de stockage et se terminer sur un autre. Ce sont ces propriétés utiles qui seront utilisées à l'avenir.
Une question légitime se pose: comment mettre en œuvre la demi-transe dans les systèmes distribués et non le râteau? Pour résoudre ce problème, vous devez considérer l'approche sans verrouillage.
Sans verrou
Comme vous le savez, les approches sans verrouillage améliorent parfois les performances des systèmes multithreads, en particulier dans le cas d'un accès concurrentiel à la ressource. Cependant, il n'est absolument pas évident qu'une telle approche puisse être utilisée dans des systèmes distribués. Examinons en profondeur ce qu'est le verrouillage sans clé et pourquoi cette propriété sera utile pour résoudre notre problème.
Certains développeurs ne comprennent pas toujours ce qu'est le sans-verrou. Le regard borné suggère que cela est lié aux instructions du processeur atomique. Il est important de comprendre ici que le verrouillage signifie l'utilisation d’atomes, l’inverse n’est pas vrai, c’est-à-dire tous les «atomiques» n'offrent pas un comportement sans verrouillage.
Une propriété importante de l'algorithme sans verrouillage est qu'au moins un thread progresse dans le système. Mais pour une raison quelconque, beaucoup attribuent cette propriété comme une définition (c'est une définition si franche que l'on peut trouver, par exemple, sur Wikipedia ). Ici, il est nécessaire d'ajouter une nuance importante: des progrès sont réalisés même dans le cas d'émoussages d'un ou plusieurs fils. Il s'agit d'un point très critique qui est souvent ignoré et qui a de sérieuses implications pour un système distribué.
Pourquoi l'absence d'une condition de progression d'au moins un thread annule-t-elle le concept d'un algorithme sans verrouillage? Le fait est que dans ce cas, le spinlock habituel sera également sans verrouillage. En effet, celui qui a pris le verrou fera des progrès. Existe-t-il un thread avec progress => lock-free?
De toute évidence, sans verrou signifie sans verrou, tandis que le verrou tournant par son nom indique qu'il s'agit d'un vrai verrou. C'est pourquoi il est important d'ajouter une condition au progrès, même dans le cas d'émoussés. Après tout, ces retards peuvent durer indéfiniment, car la définition ne dit rien sur la ligne du temps supérieure. Et si c'est le cas, ces retards seront en quelque sorte équivalents à la coupure des flux. Dans ce cas, les algorithmes sans verrouillage produiront des progrès dans ce cas.
Mais qui a dit que les approches sans verrouillage s'appliquent exclusivement aux systèmes multithreads? En remplaçant les threads dans le même processus sur le même nœud par des processus sur différents nœuds et la mémoire partagée des threads avec un stockage distribué partagé, nous obtenons un algorithme distribué sans verrouillage.
Une chute de nœud dans un tel système équivaut à un retard dans l'exécution d'un thread pendant un certain temps, car il est temps de restaurer le travail. Dans le même temps, l'approche sans verrouillage permet aux autres participants du système distribué de continuer à travailler. De plus, des algorithmes spéciaux sans verrouillage peuvent être exécutés en parallèle, détectant un changement concurrentiel et supprimant les doublons.
L' approche Exactly-once implique la présence d'un stockage distribué cohérent. Ces stockages représentent en règle générale une énorme table de valeurs-clés persistante. Opérations possibles: set , get , del . Cependant, une opération plus compliquée est requise pour l'approche sans verrouillage: CAS ou compare-and-swap. Examinons plus en détail cette opération, les possibilités de son utilisation, ainsi que les résultats qu'elle donne.
Cas
CAS ou compare-and-swap est la primitive de synchronisation principale et importante pour les algorithmes sans verrouillage et sans attente. Son essence peut être illustrée par le Pseco suivant:
CAS(var, expected, new): # , atomic, atomic: if var.get() != expected: return false var.set(new) return true
Parfois, pour l'optimisation, ils renvoient non pas true ou false , mais la valeur précédente, car très souvent, ces opérations sont effectuées en boucle, et pour obtenir la valeur expected , vous devez d'abord la lire:
CAS_optimized(var, expected, new): # , atomic, atomic: current = var.get() if current == expected: var.set(new) return current # CAS CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
Cette approche peut sauver une lecture. Dans le cadre de notre examen, nous utiliserons une forme simple de CAS , car si vous le souhaitez, cette optimisation peut être effectuée indépendamment.
Dans le cas de systèmes distribués, chaque modification est versionnée. C'est-à-dire nous lisons d'abord la valeur du magasin, obtenant la version actuelle des données. Et puis nous essayons d'écrire, en attendant que la version des données n'ait pas changé. Dans ce cas, la version est incrémentée à chaque mise à jour des données:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
Cette approche vous permet de contrôler plus précisément la mise à jour des valeurs, en évitant le problème ABA . En particulier, la gestion des versions est prise en charge par Etcd et Zookeeper.
Notez la propriété importante que donne l'utilisation des opérations CAS_versioned . Le fait est qu'une telle opération peut être répétée sans préjudice de la logique supérieure. Dans la programmation multi-thread, cette propriété n'a pas de valeur spéciale, car là, si l'opération a échoué, alors nous savons avec certitude qu'elle ne s'appliquait pas. Dans le cas de systèmes distribués, cet invariant est violé, car la demande peut atteindre le destinataire, mais la réponse réussie n'est plus là. Par conséquent, il est important de pouvoir renvoyer des requêtes sans craindre de casser les invariants de la logique de haut niveau.
C'est cette propriété que CAS_versioned opération CAS_versioned . En fait, cette opération peut être répétée à l'infini jusqu'à ce que la réponse réelle du destinataire soit renvoyée. Ce qui, à son tour, génère toute une classe d'erreurs liées à l'interaction réseau.
Exemple
Voyons comment, basé sur CAS_versioned et demi-transactions, pour transférer d'un compte à un autre, qui appartiennent, par exemple, à différentes copies d'Etcd. Ici, je suppose que la fonction CAS_versioned déjà implémentée en conséquence sur la base de l'API fournie.
withdraw(from, amount): # CAS- while true: # version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS- while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
Ici, nous avons divisé notre opération en demi-transactions, et nous effectuons chaque demi-transaction via l'opération CAS_versioned . Cette approche vous permet de travailler indépendamment avec chaque compte, ce qui permet d'utiliser un stockage hétérogène qui n'est pas connecté les uns aux autres. Le seul problème qui nous attend ici est la perte d'argent en cas de chute du processus en cours dans l'intervalle entre les demi-transactions.
File d'attente
Pour continuer, vous devez implémenter une file d'attente d'événements. L'idée est que pour que les gestionnaires communiquent entre eux, vous devez disposer d'une file d'attente de messages ordonnée dans laquelle les données ne sont ni perdues ni dupliquées. Par conséquent, toute interaction dans la chaîne de gestionnaires sera basée sur cette primitive. C'est également un outil utile pour analyser et auditer les flux de données entrants et sortants. En plus de cela, des mutations de l'état des gestionnaires peuvent également être effectuées via la file d'attente.
La file d'attente se composera d'une paire d'opérations:
- Ajoutez un message à la fin de la file d'attente.
- Réception d'un message de la file d'attente à l'index spécifié.
Dans ce contexte, je n'envisage pas de supprimer des messages de la file d'attente pour plusieurs raisons:
- Plusieurs processeurs peuvent lire à partir de la même file d'attente. La suppression de la synchronisation sera une tâche non triviale, mais pas impossible.
- Il est utile de maintenir une file d'attente pendant un intervalle relativement long (jour ou semaine) pour le débogage et l'audit. L'utilité de cette propriété est difficile à surestimer.
- Vous pouvez supprimer les anciens éléments selon le calendrier ou en définissant TTL sur les éléments de la file d'attente. Il est important de s'assurer que les processeurs parviennent à traiter les données avant que le balai arrive et nettoie tout. Si le temps de traitement est de l'ordre de quelques secondes et le TTL de l'ordre de jours, rien de tout cela ne devrait se produire.
Pour stocker les éléments et mettre en œuvre efficacement l'ajout, nous avons besoin de:
- La valeur avec l'index actuel. Cet index pointe vers la fin de la file d'attente pour l'ajout d'éléments.
- , .
lock-free
: . :
- CAS .
- .
, , .
- lock-free . , , . Lock-free? ! , 2 : . lock-free, — ! , , , . . , .. , .
- . , . .
, lock-free .
Lock-free
, , : , .. , :
push(queue, value): # index = queue.get_current_index() while true: # , # var = queue.at(index) # = 0 , .. # , if var.CAS_versioned(0, value): # , queue.update_index(index + 1) break # , . index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # cur_index, version = queue.get_current_index_versioned() # , # , . if cur_index >= index: # - , # break if queue.current_index_var().CAS_versioned(version, index): # , break # - . # , ,
. , ( — , , ). lock-free . ?
, push , ! , , .
. : . , - , - . , , .. . . ? , .. , , .
, , . .. . , , . , .
, . , . , , . , .
, , , .
. .
, :
- , .. stateless.
- , — .
, , concurrent exactly-once .
:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
. :
handle(input, output, state): # index = state.get() while true: value = input.get(index) output.push(value) index += 1 # state.set(index)
exactly-once . , , , .
exactly-once , , . .., , , , , — :
# get_next_index(queue): index = queue.get_index() # while queue.has(index): # queue.push index = max(index + 1, queue.get_index()) return index # . # true push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # queue.update_index(index + 1) return true return false handle(input, output, state): # # {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # : , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # , input_index += 1 # , push_at false, # fsm_state = {PREPARING, input_index} state.set(fsm_state)
push_at ? , . , , , . , . . - , lock-free .
, :
- : .
- , : .
: concurrent exactly-once .
? :
- , ,
push_at false. . - , . , , .
concurrent exactly-once ? , , . , . .
:
# , , # .. true, # true. # false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # , , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # , # if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

, . , .
kernel panic, , .. . . : , . , .
, , .
: .
: , , , , :
# : # - input_queues - # - output_queues - # - state - # - handler - : state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes case {HANDLING, user_state, input_indexes}: # inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # , next_indexes = next(inputs, input_indexes) # # user_state, outputs = handler(user_state, inputs) # , # fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # , # output_index = output_queues[output_pos].get_next_index() # fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # if output_queues[output_pos].push_at_idempotent( value, output_index ): # , output_pos += 1 # , PREPARING. # # fsm_state = if output_pos == len(outputs): # , # {HANDLING, user_state, input_indexes} else: # # , # {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

: HANDLING . , .., , . , . , PREPARING WRITING , . , HANDLING .
, , , . , . , .
. . .

:
my_handler(state, inputs): # state.queue.push(inputs) # duration state.queue.trim_time_window(duration) # avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none none ]
, , concurrent exactly-once handle .
:
handle_db(input_queue, db): while true: # tx = db.begin_transaction() # . # , # index = tx.get_current_index() # tx.write_current_index(index + 1) # value = intput_queue.get(index) if value: # tx.increment_counter() tx.commit() # , , #
. Parce que , , , , concurrent exactly-once . .
— . , , .
, , . , , .
. , . Parce que , . . .
— . , , . , - , , . , .. , , .
. , , . , , .
. , . : , . , .
, , :
- , . .
- . , .
- . , . , , . .. . : .
, , -, , -, .
, . :
transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
withdraw , , deposit : ? deposit - (, , ), . , , , , ? , , - , .
, , , . , , , . , . , , . Parce que , , . , : , — .
, .
: , , , , . , - :
, , .
, , .. , , . , .
: lock-free , . , .. , .
CAS . , :
# , handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # ... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # , output_index
, . . :
- PREPARING . , .
- WRITING . . , PREPARING .
, . , , — . :
- . , , .. , .
- , .. . , .
, lock-free , , .
, . , Stale Read , . — CAS: . :
- Distributed single register — (, etcd Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — (, MySQL, PostgreSQL ..):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL :
- Strict Consistency
: ? , , . , , CAS . , , Read My Writes .
Conclusion
exactly-once . , .. , , , . , , , , .. , .
lock-free .
:
- : .
- : .
- : : exactly-once .
- Concurrent : .
- Real-time : .
- Lock-free : , .
- Deadlock free : , .
- Race condition free : .
- Hot-hot : .
- Hard stop : .
- No failover : .
- No downtime : .
- : , .
- : .
- : .
- : .
, . Mais c'est une autre histoire.

:
- Concurrent exactly-once.
- Semi-transactions .
- Lock-free two-phase commit, .
- .
- lock-free .
- .
[1] : ABA.
[2] Blog: You Cannot Have Exactly-Once Delivery
[3] : .
[4] : 3: .
[5] : .