(merci pour l'idée du titre grâce à Sergey G. Brester
sebres )
Chers collègues, le but de cet article est de partager l'expérience d'une opération de test d'un an d'une nouvelle classe de solutions IDS basées sur les technologies de déception.
Pour préserver la cohérence logique de la présentation du matériel, je considère nécessaire de commencer par les prémisses. Donc, les problèmes:
- Les attaques dirigées sont le type d'attaque le plus dangereux, malgré le fait que leur part dans le nombre total de menaces est faible.
- Une sorte de moyen efficace garanti de protéger le périmètre (ou un complexe de tels moyens) n'a pas encore été inventé.
- En règle générale, les attaques dirigées se déroulent en plusieurs étapes. Surmonter le périmètre n'est qu'une des étapes initiales qui (vous pouvez me lancer des pierres) ne causent pas beaucoup de dégâts à la «victime», sauf s'il s'agit bien entendu d'une attaque DEoS (Destruction of service) (chiffreurs, etc.). La véritable «douleur» commence plus tard, lorsque les actifs saisis commencent à être utilisés pour pivoter et développer une attaque «en profondeur», mais nous ne l'avons pas remarqué.
- Puisque nous commençons à subir de réelles pertes lorsque les attaquants atteignent néanmoins les objectifs de l'attaque (serveur d'applications, SGBD, stockage de données, référentiels, éléments d'infrastructure critiques), il est logique qu'une des tâches du service SI soit d'interrompre les attaques avant ce triste événement. Mais pour interrompre quelque chose, vous devez d'abord le découvrir. Et le plus tôt sera le mieux.
- Par conséquent, pour une gestion des risques réussie (c'est-à-dire pour réduire les dommages causés par les attaques ciblées), il est essentiel de disposer d'outils qui fournissent un TTD minimum (temps de détection - le temps entre le moment de l'invasion et le moment de la détection de l'attaque). Selon l'industrie et la région, cette période est en moyenne de 99 jours aux États-Unis, 106 jours dans la région EMEA, 172 jours dans la région APAC (M-Trends 2017, A View From the Front Lines, Mandiant).
- Qu'offre le marché?
- Bacs à sable. Un autre contrôle préventif loin d'être idéal. Il existe des tonnes de techniques efficaces pour détecter et contourner les bacs à sable ou les solutions de liste blanche. Les gars du "côté obscur" ont encore une longueur d'avance.
- UEBA (profilage comportemental et systèmes de détection de déviation) - en théorie, il peut être très efficace. Mais, à mon avis, c'est dans un avenir lointain. En pratique, il reste très coûteux, peu fiable et nécessite une infrastructure informatique et de sécurité de l'information très mature et stable, qui dispose déjà de tous les outils qui généreront des données pour l'analyse comportementale.
- Le SIEM est un bon outil d'investigation, mais il n'est pas capable de voir et de montrer quelque chose dans le temps, car les règles de corrélation sont les mêmes signatures.
- En conséquence, le besoin d'un tel instrument a mûri:
- travaillé avec succès dans des conditions de périmètre déjà compromis,
- détecté des attaques réussies en mode quasi-temps réel quels que soient les outils et les vulnérabilités utilisés,
- ne dépend pas des signatures / règles / scripts / politiques / profils et autres choses statiques,
- n'exigeait pas la disponibilité de grandes quantités de données et de leurs sources pour l'analyse,
- Cela permettrait de définir les attaques non pas comme une sorte de notation des risques grâce au travail des «meilleurs au monde, des mathématiques brevetées et donc fermées», ce qui nécessite des investigations supplémentaires, mais pratiquement comme un événement binaire - «Oui, ils nous attaquent» ou «Non, tout va bien»,
- Il était universel, effectivement évolutif et réellement mis en œuvre dans n'importe quel environnement hétérogène, quelle que soit la topologie de réseau physique et logique utilisée.
Les solutions dites de déception revendiquent désormais le rôle d'un tel outil. Autrement dit, des solutions basées sur le bon vieux concept de hanipot, mais avec un niveau de mise en œuvre complètement différent. Ce sujet est désormais clairement à la hausse.
Selon les résultats du
sommet Gartner Security & Risc Management 2017, les solutions de déception sont incluses dans le TOP 3 des stratégies et outils dont l'application est recommandée.
Selon le rapport
TAG Cybersecurity Annual 2017 Deception, Deception est l'une des principales lignes de développement des solutions IDS Intrusion Detection Systems).
La section entière du dernier
rapport sur l'
état de la sécurité informatique de Cisco sur SCADA est basée sur les données de l'un des leaders de ce marché, TrapX Security (Israël), dont la solution fonctionne dans notre zone de test depuis un an maintenant.
TrapX Deception Grid vous permet de chiffrer et d'exploiter un IDS massif distribué de manière centralisée, sans augmenter la charge de licence et les exigences matérielles. En fait, TrapX est un constructeur qui vous permet de créer à partir des éléments de l'infrastructure informatique existante un grand mécanisme pour détecter les attaques à l'échelle de l'entreprise entière, une sorte de «signalisation» de réseau distribué.
Structure de la solution
Dans notre laboratoire, nous étudions et testons en permanence diverses innovations dans le domaine de la sécurité informatique. Maintenant, environ 50 serveurs virtuels différents sont déployés ici, y compris les composants TrapX Deception Grid.
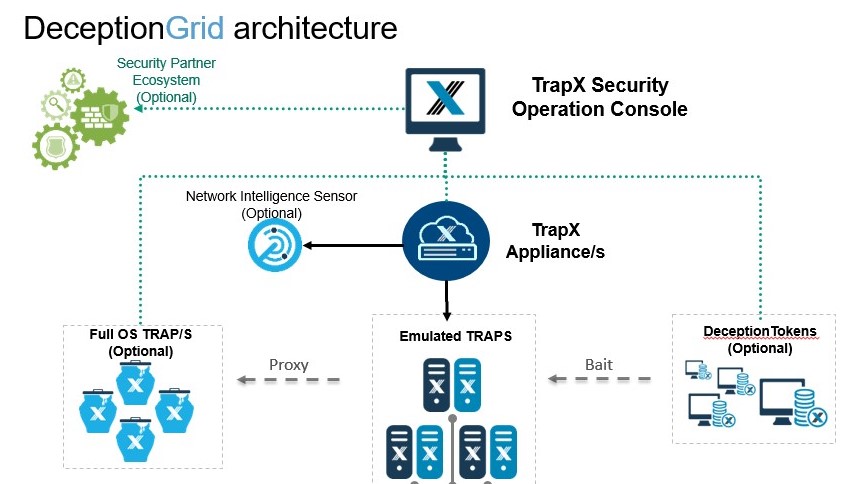
Donc, de haut en bas:
- TSOC (TrapX Security Operation Console) - le cerveau du système. Il s'agit de la console de gestion centrale avec laquelle vous pouvez configurer, déployer la solution et tout le travail quotidien. Puisqu'il s'agit d'un service Web, il peut être déployé n'importe où - sur le périmètre, dans le cloud ou chez le fournisseur MSSP.
- TrapX Appliance (TSA) est un serveur virtuel dans lequel nous utilisons le port de jonction pour connecter les sous-réseaux que nous voulons surveiller. De plus, tous nos capteurs réseau «vivent» ici.
Il y a un TSA (mwsapp1) déployé dans notre laboratoire, mais en réalité il peut y en avoir plusieurs. Cela peut être nécessaire dans les grands réseaux où il n'y a pas de connectivité L2 entre les segments (un exemple typique est «Holding et filiales» ou «Siège social et succursales») ou s'il y a des segments isolés dans le réseau, par exemple, les systèmes de contrôle de processus. Dans chacune de ces branches / segments, vous pouvez déployer votre TSA et le connecter à un seul TSOC, où toutes les informations seront traitées de manière centralisée. Cette architecture vous permet de construire des systèmes de surveillance distribués sans avoir besoin d'une restructuration fondamentale du réseau ou d'une rupture de la segmentation existante.
De plus, chez TSA, nous pouvons soumettre une copie du trafic sortant via TAP / SPAN. En cas de détection de connexions avec des botnets bien connus, des serveurs de commandes, des sessions TOR, nous obtiendrons également le résultat dans la console. Le Network Intelligence Sensor (NIS) en est responsable. Dans notre environnement, cette fonctionnalité est implémentée sur le pare-feu, nous ne l'avons donc pas utilisée ici. - Pièges d'application (système d'exploitation complet) - poignées de serveur Windows traditionnelles. Ils ne nécessitent pas beaucoup, car la tâche principale de ces serveurs est de fournir des services informatiques au niveau supérieur de capteurs ou d'identifier les attaques sur les applications métier qui peuvent être déployées dans un environnement Windows. Nous avons un tel serveur installé dans le laboratoire (FOS01)
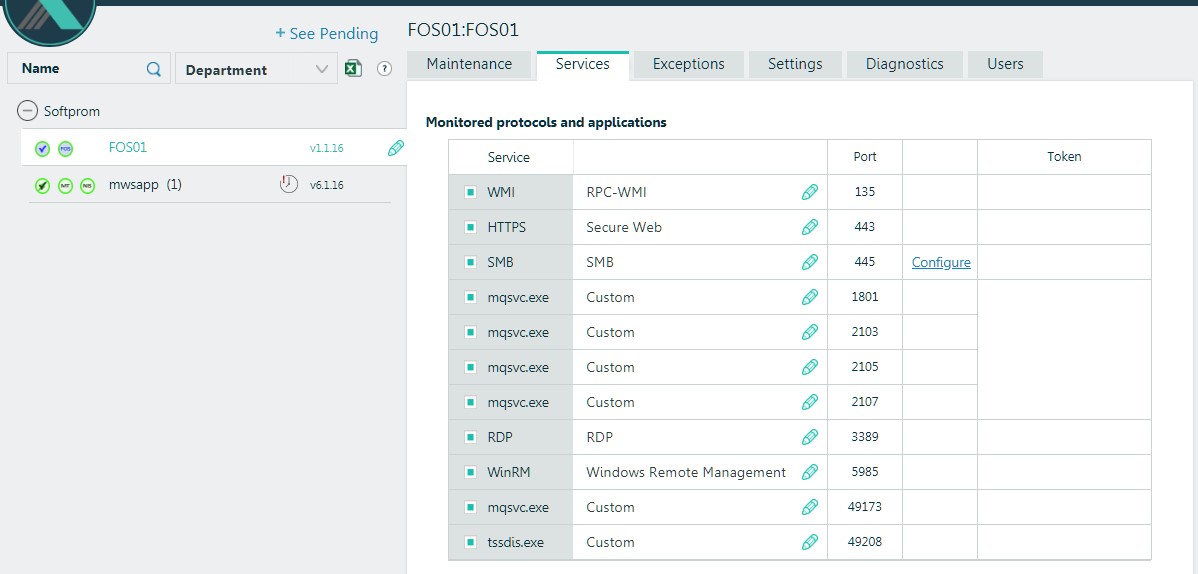
- Pièges émulés - le composant principal de la solution, qui nous permet de créer un champ "mine" très dense pour les attaquants avec une seule machine virtuelle et de saturer le réseau de l'entreprise, tous ses vlan-s, avec nos capteurs. L'attaquant voit un tel capteur, ou un hôte fantôme, comme un vrai PC ou serveur Windows, un serveur Linux ou un autre appareil que nous décidons de lui montrer.
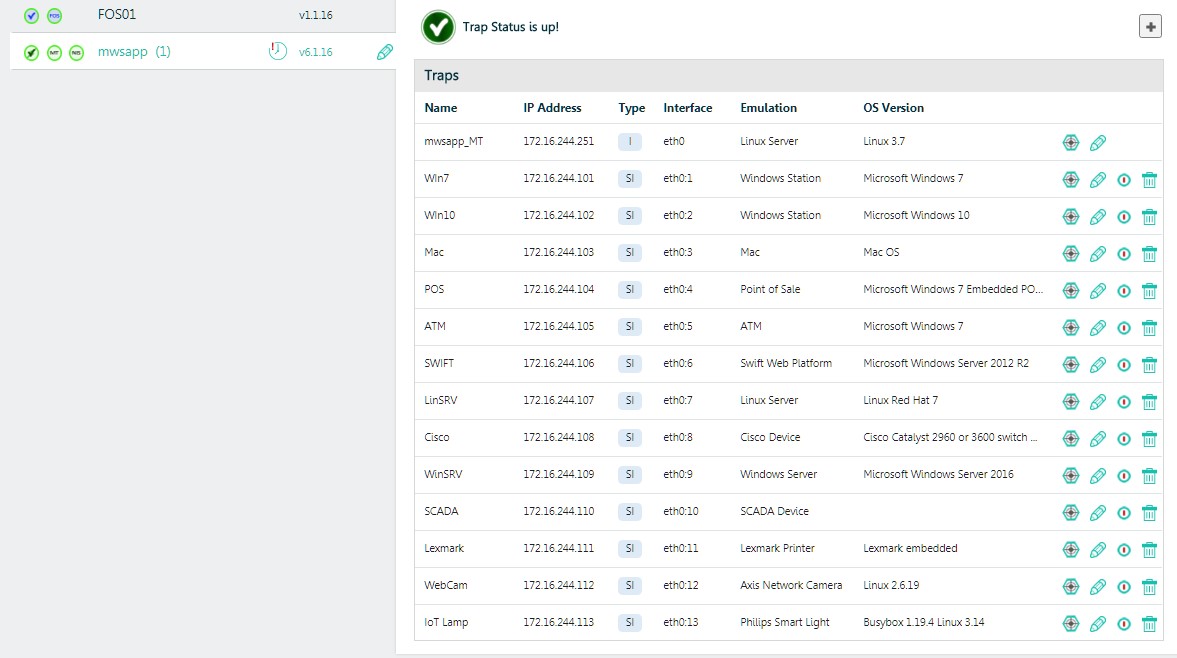
Pour des raisons commerciales et de curiosité, nous avons déployé «chaque créature par paires» - PC Windows et serveurs de différentes versions, serveurs Linux, ATM avec Windows intégré, SWIFT Web Access, imprimante réseau, commutateur Cisco, caméra IP Axis, MacBook, PLC -un appareil et même une ampoule intelligente. Au total - 13 hôtes. En général, le vendeur recommande de déployer de tels capteurs à hauteur d'au moins 10% du nombre d'hôtes réels. La barre supérieure est l'espace d'adressage disponible.
Un point très important est que chacun de ces hôtes n'est pas une machine virtuelle à part entière qui nécessite des ressources et des licences. C'est un accroc, une émulation, un processus sur le TSA, qui a un ensemble de paramètres et une adresse IP. Par conséquent, avec l'aide d'un seul TSA, nous pouvons saturer le réseau avec des centaines d'hôtes fantômes qui agiront comme capteurs dans le système d'alarme. C'est cette technologie qui vous permet de faire évoluer de manière économique le concept de "Hanipot" à l'échelle de toute grande entreprise distribuée.
Du point de vue du côté attaquant, ces hôtes sont attrayants car ils contiennent des vulnérabilités et semblent des cibles relativement faciles. L'attaquant voit les services sur ces hôtes et peut interagir avec eux, les attaquer à l'aide d'outils et de protocoles standard (smb / wmi / ssh / telnet / web / dnp / bonjour / Modbus, etc.). Mais utiliser ces hôtes pour développer une attaque et lancer votre code est impossible.
- La combinaison de ces deux technologies (FullOS et pièges émulés) nous permet d'atteindre une forte probabilité statistique qu'un attaquant rencontre tôt ou tard un élément de notre réseau de signaux. Mais comment rendre cette probabilité proche de 100%?
Les soi-disant jetons (jetons de déception) entrent dans la bataille. Grâce à eux, nous pouvons inclure dans nos IDS distribués tous les PC et serveurs d'entreprise disponibles. Les jetons sont placés sur de vrais utilisateurs de PC. Il est important de comprendre que les jetons ne sont pas un agent qui consomme des ressources et peut provoquer des conflits. Les jetons sont des éléments d'information passifs, une sorte de "chapelure" pour le côté attaquant, qui le conduisent dans un piège. Par exemple, les lecteurs réseau mappés, les signets pour les faux administrateurs Web dans le navigateur et les mots de passe enregistrés pour eux, les sessions ssh / rdp / winscp enregistrées, nos pièges avec commentaires dans les fichiers hôtes, les mots de passe stockés en mémoire, les informations d'identification des utilisateurs inexistants, les fichiers de bureau, l'ouverture ce qui déclenchera le système, et bien plus encore. Ainsi, nous plaçons l'attaquant dans un environnement déformé saturé de ces vecteurs d'attaque qui ne constituent pas réellement une menace pour nous, mais plutôt le contraire. Et il n'a aucun moyen de déterminer où se trouvent les vraies informations et où elles sont fausses. Ainsi, non seulement nous fournissons une définition rapide d'une attaque, mais nous ralentissons également considérablement sa progression.
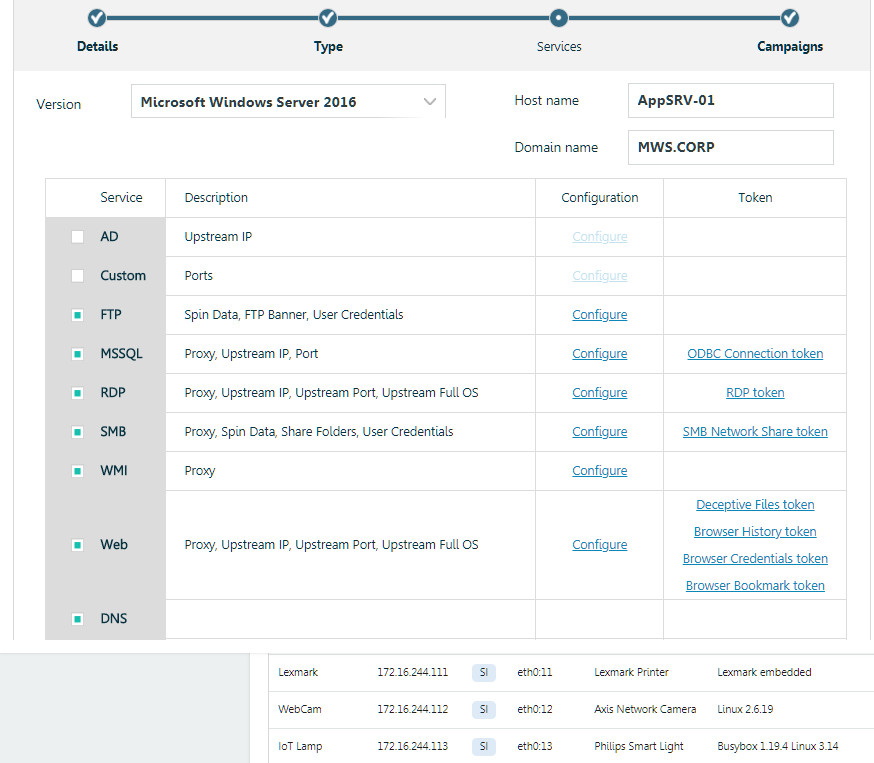 Un exemple de création d'une interruption réseau et de définition de jetons. Interface conviviale et édition manuelle des configurations, scripts, etc.
Un exemple de création d'une interruption réseau et de définition de jetons. Interface conviviale et édition manuelle des configurations, scripts, etc.Dans notre environnement, nous avons configuré et placé un certain nombre de ces jetons sur FOS01 exécutant Windows Server 2012R2 et un PC de test sous Windows 7. Ces machines exécutent RDP et nous les «publions» périodiquement dans la DMZ, qui affiche également un certain nombre de nos capteurs (pièges émulés). Ainsi, nous obtenons un flux constant d'incidents, pour ainsi dire, de manière naturelle.
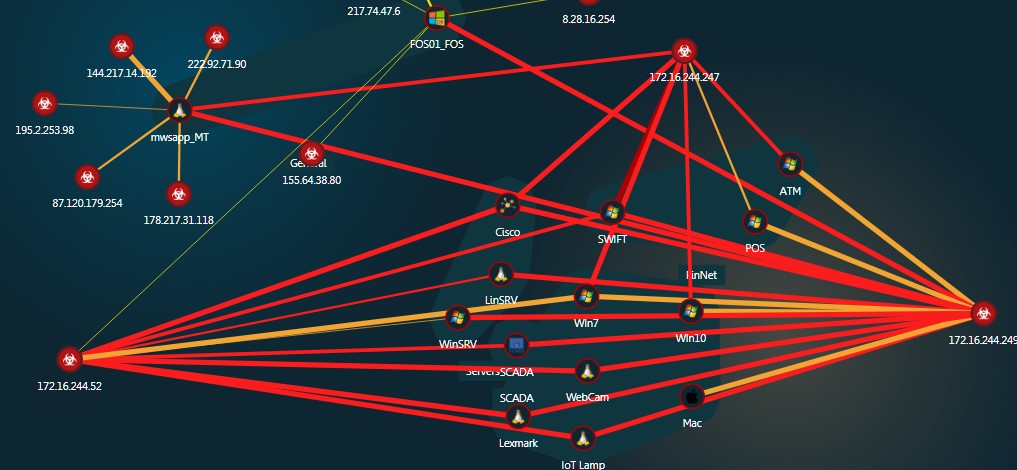
Donc, une brève statistique pour l'année:
56208 - incidents enregistrés
2 912 - hôtes source d'attaque détectés.
Carte d'attaque interactive et cliquableDans le même temps, la solution ne génère aucun méga-journal ou flux d'événements, dont la compréhension est longue. Au lieu de cela, la solution elle-même classe les événements par leur type et permet à l'équipe SI de se concentrer principalement sur les plus dangereux - lorsque la partie attaquante tente d'augmenter les sessions de contrôle (interaction) ou lorsque des charges binaires (infection) apparaissent dans notre trafic.
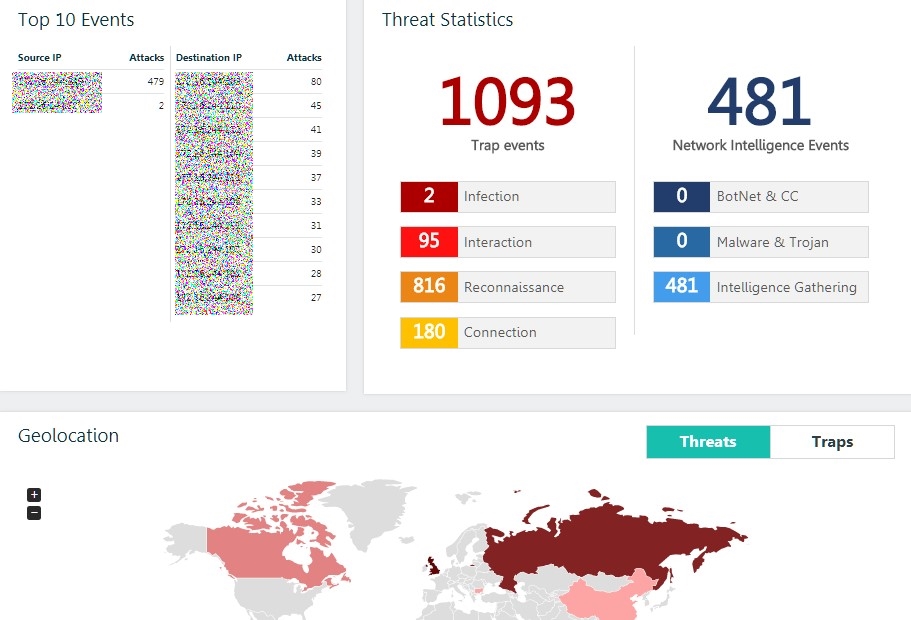
Toutes les informations sur les événements sont lisibles et présentées, à mon avis, sous une forme facile à comprendre même à un utilisateur ayant des connaissances de base dans le domaine de la sécurité de l'information.
La plupart des incidents signalés sont des tentatives d'analyse de nos hôtes ou des connexions uniques.
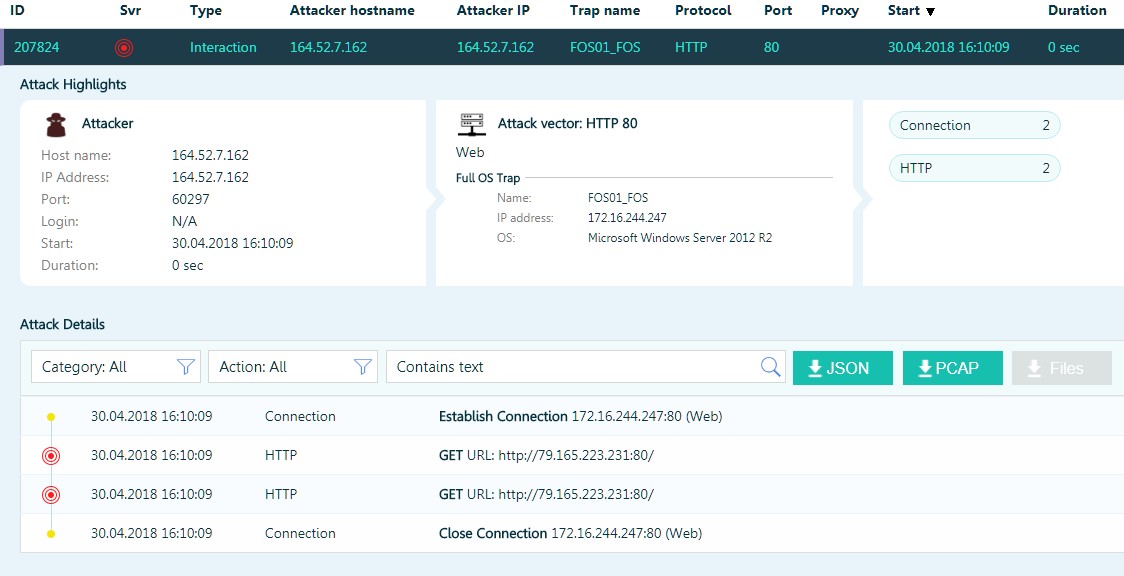
Ou tentatives de devinettes de mot de passe pour RDP
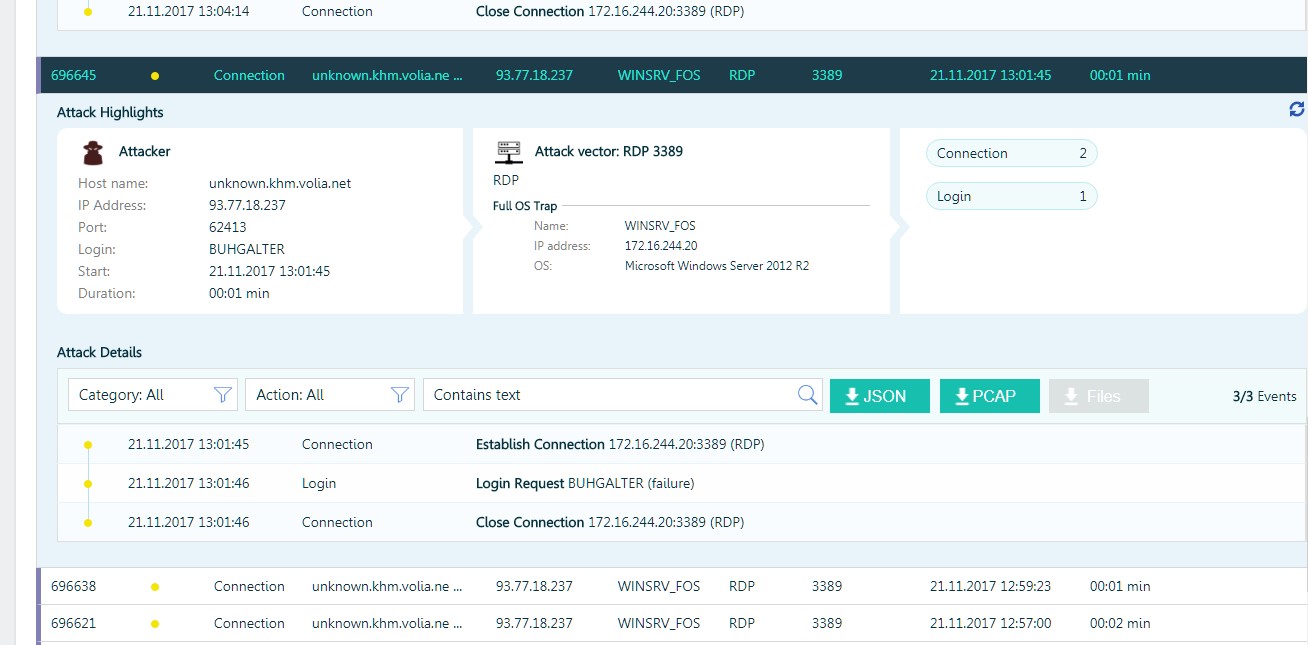
Mais il y a eu des cas plus intéressants, en particulier lorsque les attaquants ont «réussi» à récupérer un mot de passe pour RDP et à accéder au réseau local.
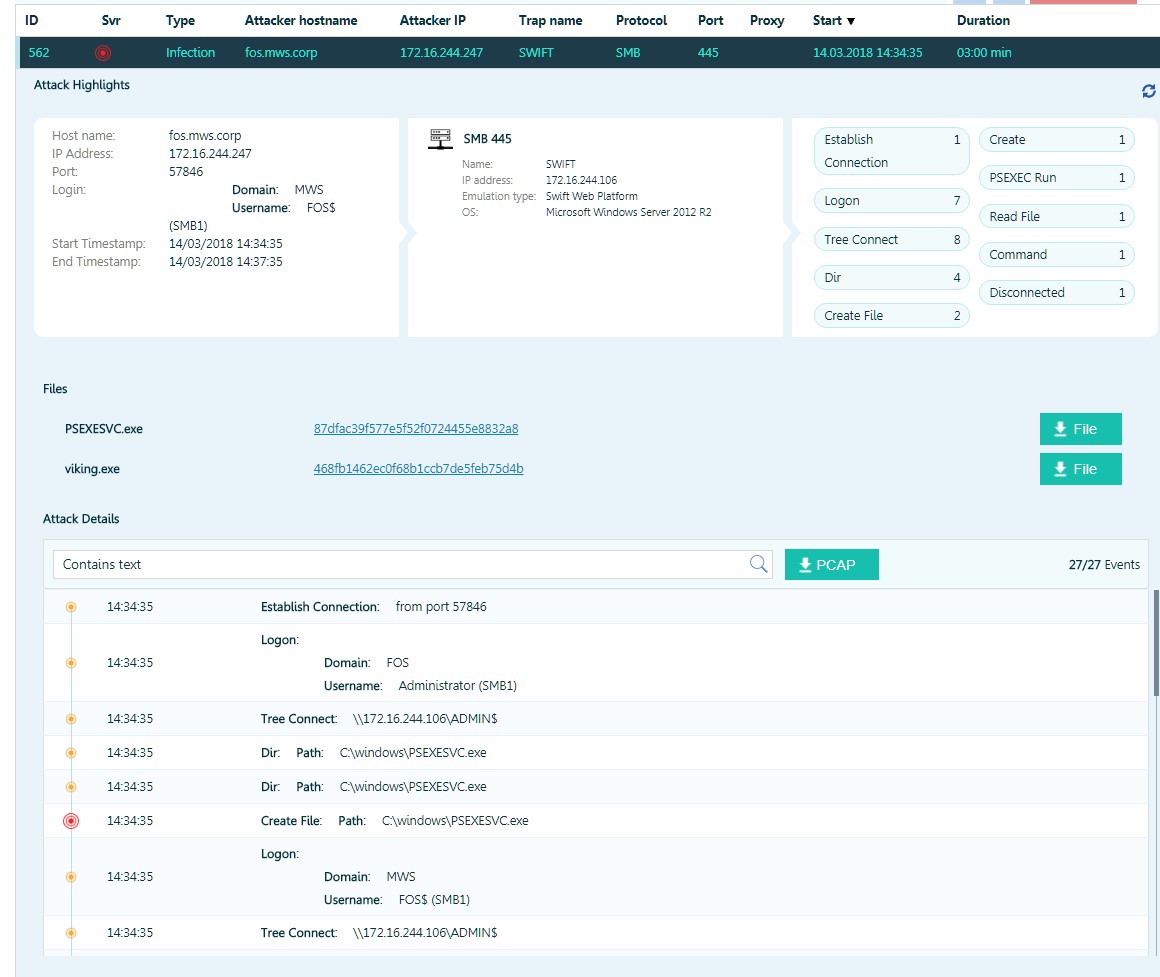
Un attaquant tente d'exécuter du code à l'aide de psexec.
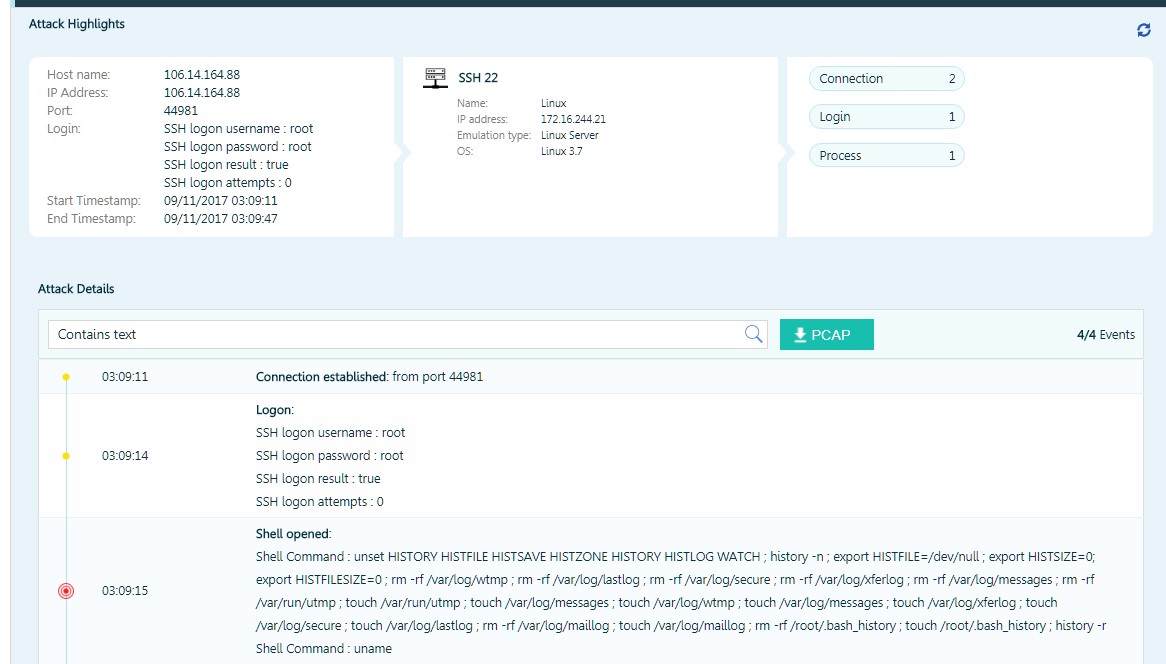
L'attaquant a trouvé une session enregistrée qui l'a piégé en tant que serveur Linux. Immédiatement après la connexion avec un ensemble de commandes prédéfini, il a essayé de détruire tous les fichiers journaux et les variables système correspondantes.
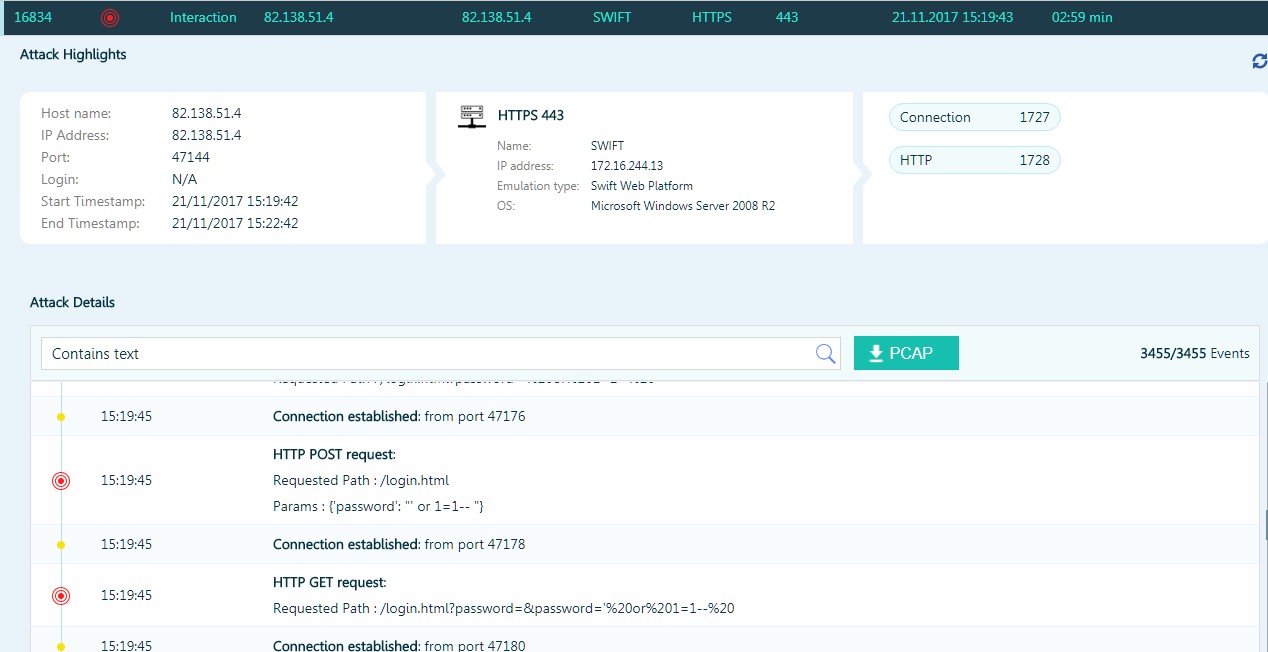
L'attaquant tente d'injecter SQL dans un piège qui imite SWIFT Web Access.
En plus de ces attaques «naturelles», nous avons effectué un certain nombre de nos propres tests. L'un des plus indicatifs est de tester le temps de détection d'un ver de réseau sur un réseau. Pour ce faire, nous avons utilisé un outil de GuardiCore appelé
Infection Monkey . Il s'agit d'un ver de réseau qui peut capturer Windows et Linux, mais sans une sorte de «charge utile».
Nous avons déployé un centre de commande local, lancé la première instance de ver sur l'une des machines et reçu la première notification dans la console TrapX en moins d'une minute et demie. TTD 90 secondes contre 106 jours en moyenne ...
Grâce à la capacité d'intégration avec d'autres classes de solutions, nous ne pouvons que passer de la détection rapide des menaces à la réponse automatique à celles-ci.
Par exemple, l'intégration avec les systèmes NAC (Network Access Control) ou avec CarbonBlack déconnectera automatiquement les PC compromis du réseau.
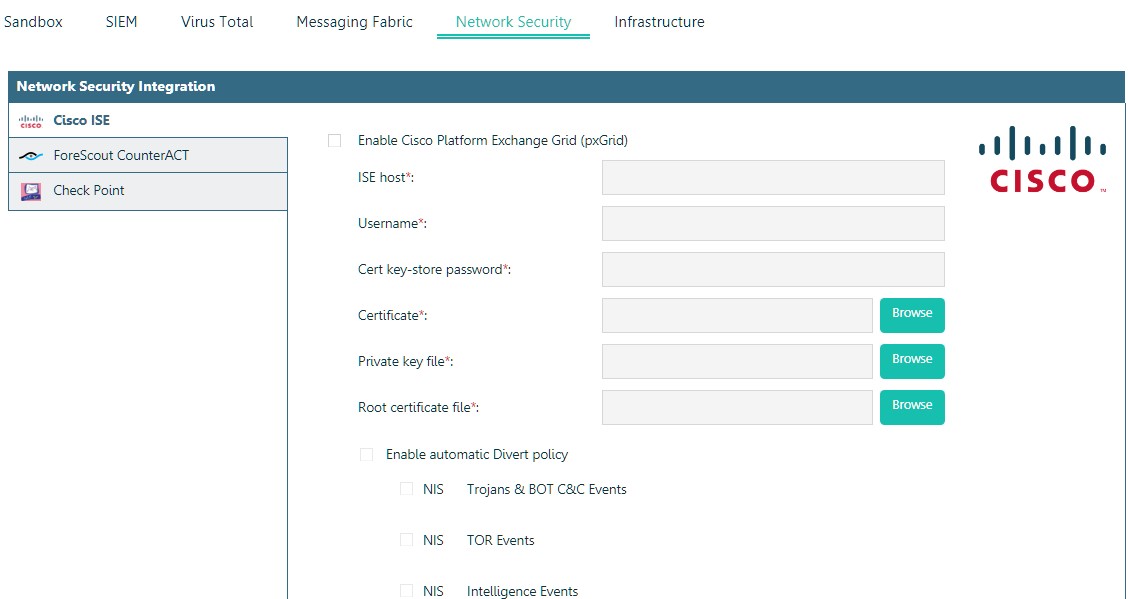
L'intégration avec des bacs à sable vous permet de transférer automatiquement les fichiers impliqués dans l'attaque pour analyse.
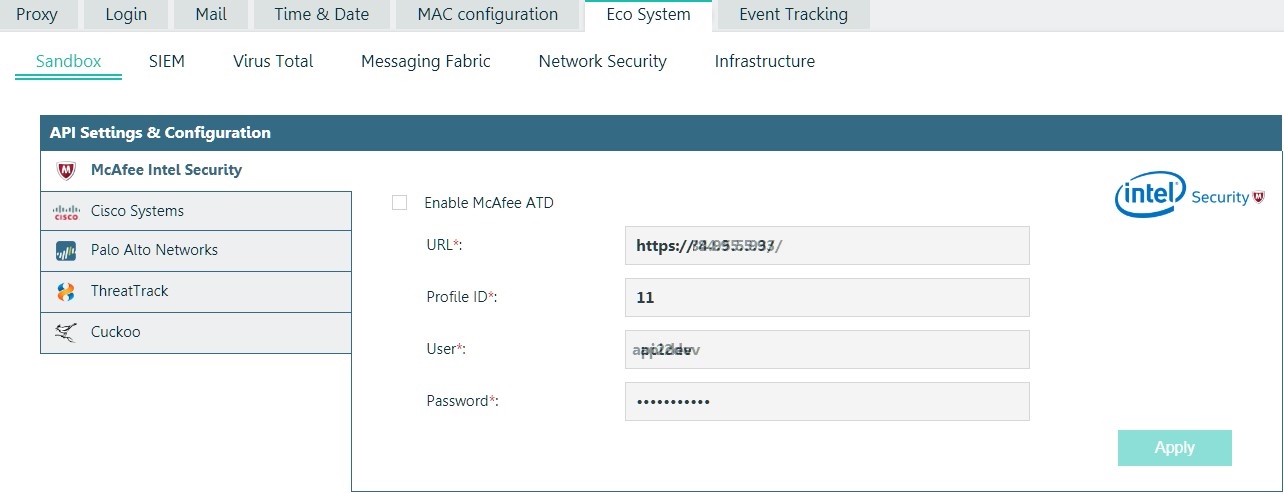
Intégration McAfee
La solution possède également son propre système de corrélation d'événements intégré.
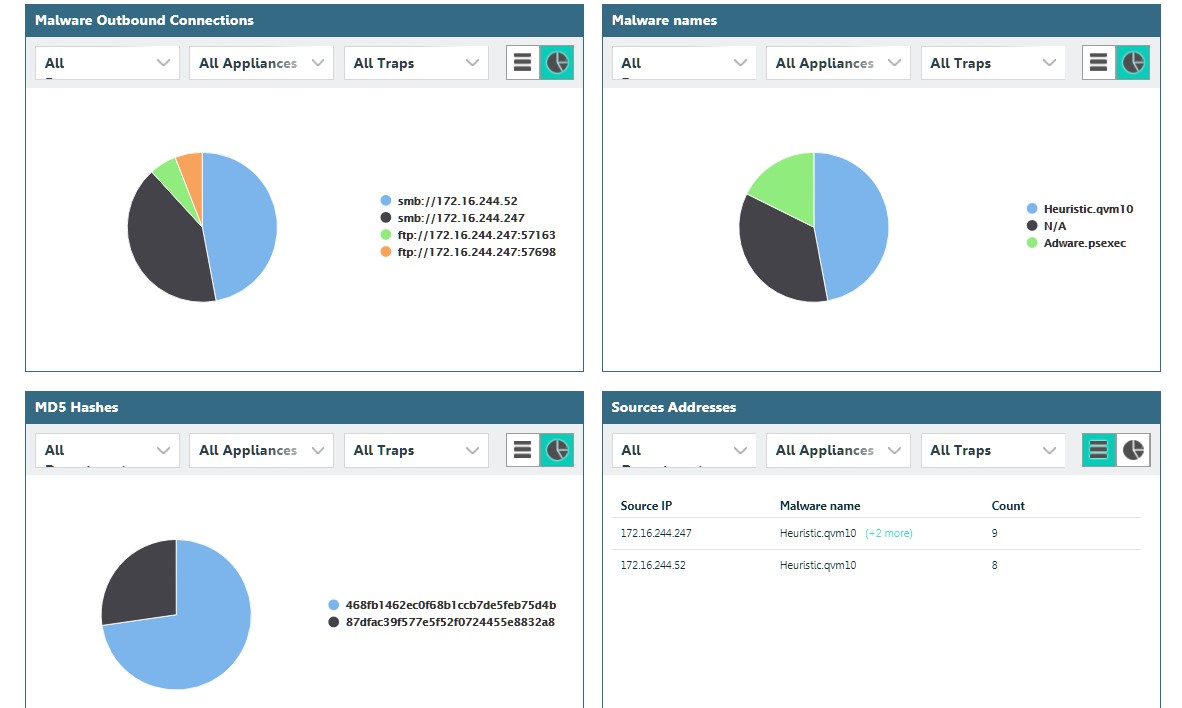
Mais ses capacités ne nous convenaient pas, nous l'avons donc intégré à HP ArcSight.
Le système de billetterie intégré permet de faire face aux menaces détectées "partout dans le monde".
Étant donné que la solution «dès le départ» a été développée pour les besoins des agences gouvernementales et d'un grand segment des entreprises, alors, bien sûr, un modèle d'accès basé sur les rôles, l'intégration avec AD, un système développé de rapports et de déclencheurs (alertes d'événements), l'orchestration pour les grandes structures de détention ou les fournisseurs MSSP y sont mis en œuvre.
Au lieu d'un CV
S'il existe un système de surveillance similaire qui, au sens figuré, couvre notre dos, alors avec le compromis du périmètre, tout ne fait que commencer. Plus important encore, il existe une réelle opportunité de faire face aux incidents de sécurité de l'information, et non de gérer leurs conséquences.