La première partie, «Évaluation de Cavium ThunderX2: le rêve d'un serveur armé devenu réalité» est
iciConfiguration et méthodologie des tests
Pour la revue ThunderX2, tous nos tests ont été effectués sur Ubuntu Server 17.10, noyau Linux 4.13 64 bits. Nous utilisons généralement la version LTS, mais comme Cavium est livré avec cette version particulière d'Ubuntu, nous n'avons pas pris le risque de changer le système d'exploitation. La distribution Ubuntu inclut le compilateur GCC 7.2.

Vous remarquerez que la quantité de DRAM varie dans nos configurations de serveur. La raison est simple: Intel a 6 canaux de mémoire et le ThunderX2 de Cavium a 8 canaux de mémoire.
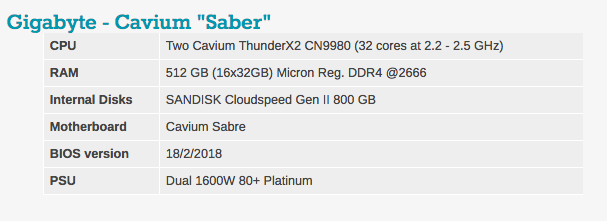
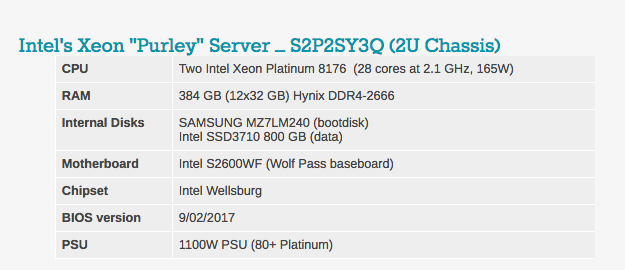
Les paramètres typiques du BIOS peuvent être vus ci-dessous. Il convient de noter que l'hyperthreading et la technologie de virtualisation Intel sont inclus.
Autres remarquesLes deux serveurs sont alimentés selon la norme européenne - 230 V (maximum 16 ampères). La température de l'air intérieur est contrôlée et maintenue à 23 ° C par nos instruments Airwell CRAC.
Consommation d'énergie
Il convient de mentionner que le système Gigabyte «Sabre» consommait 500 watts s'il ne fonctionnait qu'avec Linux (c'est-à-dire qu'il était surtout inactif). Cependant, sous charge, le système consomme environ 800 W, ce qui a en principe répondu à nos attentes, puisque nous avons deux puces TDP de 180 W à l'intérieur. Comme c'est généralement le cas avec les premiers systèmes de test, nous ne pouvons pas faire de comparaisons de puissance précises.
En fait, Cavium affirme que les systèmes actuels de HP, Gigabyte et autres seront beaucoup plus efficaces. Le système de test Sabre utilisé présentait plusieurs problèmes de gestion de l'alimentation: contrôle incorrect du micrologiciel du ventilateur, erreur BMC et bloc d'alimentation trop alimenté (1600 W).
Sous-système de mémoire: bande passante
L'utilisation de la référence de la bande passante Stream de John McCalpin sur les derniers processeurs devient de plus en plus difficile de mesurer le plein potentiel de la bande passante système à mesure que le nombre de canaux de base et de mémoire augmente. Comme vous pouvez le voir sur les résultats ci-dessous, l'estimation du débit n'est pas facile. Le résultat dépend grandement des paramètres sélectionnés.

Théoriquement, ThunderX2 a 33% de bande passante de plus qu'Intel Xeon, puisque le SoC a 8 canaux de mémoire par rapport à six canaux Intel. Ces nombres de débit élevés ne sont atteints que dans des conditions très spécifiques et nécessitent un certain réglage pour éviter l'utilisation de la mémoire distante. En particulier, nous devons veiller à ce que les flux ne soient pas acheminés d'une prise à l'autre.
Pour commencer, nous avons essayé d'obtenir les meilleurs résultats sur les deux architectures. Dans le cas d'Intel, le compilateur ICC a toujours donné de meilleurs résultats avec quelques optimisations de bas niveau dans les boucles de flux. Dans le cas du Cavium, nous avons suivi les instructions du Cavium. En gros, l'image résultante est une idée de la bande passante que ces processeurs peuvent atteindre à leurs pics. Pour être honnête avec Intel, avec des paramètres idéaux (AVX-512), vous pouvez atteindre 200 Go / s.
Cependant, il est évident que le système ThunderX2 peut fournir 15 à 28% de bande passante en plus à ses cœurs de processeur. Le résultat est de 235 Go / s, soit environ 120 Go / s par emplacement. Ceci, à son tour, est environ 3 fois plus grand que le ThunderX d'origine.
Sous-système de mémoire: délai
Bien que les mesures de bande passante ne s'appliquent qu'à une petite partie du marché des serveurs, presque toutes les applications dépendent fortement de la latence du sous-système de mémoire. Pour tenter de mesurer le cache et la latence de la mémoire, nous avons utilisé LMBench. Les données que nous voulons voir comme résultat sont «Retard à chargement aléatoire, pas = 16 octets». Notez que nous exprimons la latence L3 et le délai DRAM en nanosecondes, car nous n'avons pas de valeurs d'horloge de cache L3 exactes.
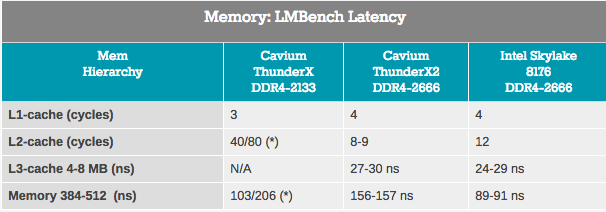
Le cache ThunderX2 L2 est accessible avec une latence très faible et lorsque vous utilisez un seul flux, le cache L3 ressemble à un concurrent du cache L3 intégré d'Intel. Cependant, lorsque nous sommes arrivés à la DRAM, Intel a montré beaucoup moins de latence.
Sous-système de mémoire: TinyMemBench
Pour mieux comprendre les architectures respectives, le test open source TinyMemBench a été utilisé. Le code source a été compilé à l'aide de GCC 7.2 et le niveau d'optimisation a été défini sur -O3. La stratégie de test est bien décrite dans le manuel de référence:
Le temps moyen est mesuré pour les accès aléatoires à la mémoire dans des tampons de différentes tailles. Plus le tampon est grand, plus la contribution relative des accès au cache TLB, des accès L1 / L2 et DRAM est importante. Tous les nombres représentent le temps supplémentaire qui doit être ajouté à la latence du cache L1 (4 cycles).
Nous avons testé avec une et deux lectures aléatoires (sans pages énormes), car nous voulions voir comment le système de mémoire traitait plusieurs demandes de lecture.
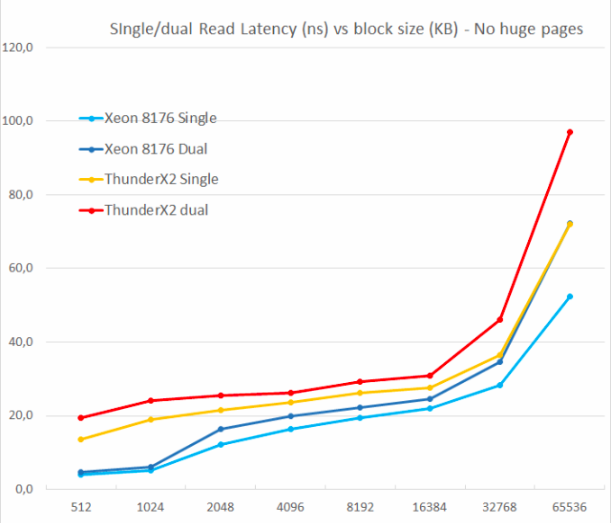
L'un des principaux inconvénients du ThunderX d'origine était l'incapacité à prendre en charge plusieurs échecs en suspens. La simultanéité au niveau de la mémoire est une caractéristique importante pour tout cœur de processeur moderne hautes performances: avec son aide, elle évite les erreurs de cache qui peuvent provoquer une «faim» en arrière-plan. Ainsi, un cache non bloquant est une caractéristique clé pour les grands cœurs.
ThunderX2 ne souffre pas du tout de ce problème, grâce à son cache non bloquant. Tout comme le noyau Skylake dans Xeon 8176, la deuxième lecture augmente la latence totale de seulement 15-30%, pas 100%. Selon TinyMemBench, le noyau Skylake a une latence nettement meilleure. Le point de référence de 512 Ko est facile à expliquer: le noyau Skylake est toujours en train de récupérer de son L2 rapide, et le noyau ThunderX2 doit accéder à L3. Mais les nombres de 1 et 2 Mo montrent que les prefetchers Intel offrent un sérieux avantage, car la latence est la moyenne des caches L2 et L3. Les taux de latence sont similaires dans la plage de 8 à 16 Mo, mais dès que nous dépassons la L3 (64 Mo), Skylake d'Intel offre une mémoire à latence plus faible.
Performances à un seul thread: SPEC CPU2006
Pour commencer à mesurer les performances informatiques réelles, nous commençons par le package SPEC CPU2006. Les lecteurs avertis remarqueront que SPEC CPU2006 était obsolète lorsque SPEC CPU2017 est apparu. Mais en raison du temps de test limité et du fait que nous n'avons pas pu retester ThunderX, nous avons décidé de nous en tenir au CPU2006.
Étant donné que SPEC est presque aussi bon pour le compilateur que le matériel, nous pensons qu'il sera approprié de formuler notre philosophie de test. Vous devez évaluer les indicateurs réels et ne pas gonfler les résultats du test. Par conséquent, il est important de créer, dans la mesure du possible, des conditions «comme dans le monde réel» avec les paramètres suivants (les critiques constructives sur cette question sont les bienvenues):
- Gcc 64 bits: le compilateur le plus utilisé sous Linux, un bon compilateur qui n'essaye pas d '«interrompre» les tests (libquantum ...)
- -Ofast: optimisation du compilateur que de nombreux développeurs peuvent utiliser
- -fno-strict-aliasing: requis pour compiler certains sous-tests
- exécution de base: chaque sous-test se compile de la même manière
Tout d'abord, vous devez mesurer les performances des applications dans lesquelles, pour une raison quelconque, un retard se produit en raison d'un «environnement multithread hostile». Deuxièmement, vous devez comprendre à quel point l'architecture ThunderX LLC fonctionne avec un seul thread par rapport à l'architecture Skylake d'Intel. Veuillez noter que dans ce modèle Skylake particulier, vous pouvez overclocker la fréquence à 3,8 GHz. La puce fonctionnera à une fréquence de 2,8 GHz dans presque toutes les situations (28 threads sont actifs) et supportera 3,4 GHz avec 14 threads actifs.
En général, Cavium positionne ThunderX2 CN9980 (1795 $) comme «meilleur que 6148» (3072 $), un processeur fonctionnant à 2,6 GHz (20 threads) et atteignant 3,3 GHz sans aucun problème (jusqu'à 16 threads actifs ) D'un autre côté, Intel-SKU aura un avantage significatif de 30% en termes de vitesse d'horloge dans de nombreuses situations (3,3 GHz contre 2,5 GHz).
Cavium a décidé de compenser le déficit de fréquence par le nombre de cœurs, offrant 32 cœurs - soit 60% de plus que le Xeon 6148 (20 cœurs). Il convient de noter qu'un plus grand nombre de cœurs entraînera une diminution du rendement dans de nombreuses applications (par exemple, Amdahl). Par conséquent, si Cavium veut ébranler la position dominante d'Intel avec ThunderX2, chaque cœur devrait au moins offrir des performances compétitives dans le monde réel. Ou dans ce cas, ThunderX2 devrait fournir au moins 66% (2,5 contre 3,8) de performances Skylake à un seul thread.
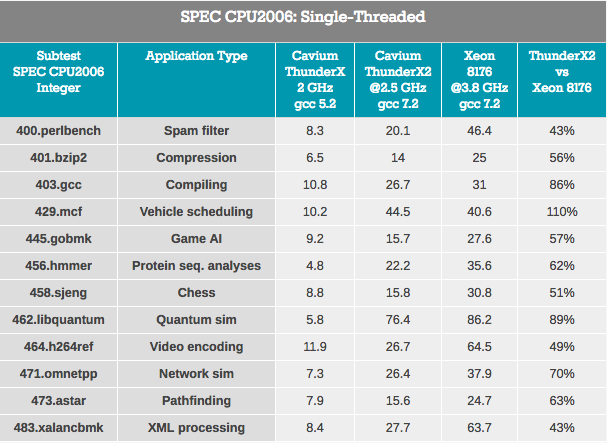
Les résultats sont flous car ThunderX2 fonctionne avec le code ARMv8 (AArch64) et Xeon utilise le code x86-64.
Tests de suivi de pointeur - Le traitement XML (également les grands tampons OoO) et la recherche de chemins qui dépendent généralement d'un grand cache L3 pour réduire l'impact de la latence d'accès sont les pires pour ThunderX2. On peut supposer qu'une latence plus élevée du système DRAM dégrade les performances.
Les charges de travail dans lesquelles l'influence de la prédiction de branche est plus élevée (au moins sur x86-64: un pourcentage plus élevé de choisir la mauvaise branche) - gobmk, sjeng, hmmer - ne sont pas les meilleures charges sur ThunderX2.
Il convient également de noter que les instructions perlbench, gobmk, hmmer et h264ref sont connues pour bénéficier du plus grand cache L2 de Skylake (512 Ko). Nous vous montrons seulement quelques pièces du puzzle, mais ensemble, ils peuvent aider à assembler l'image.
Du côté positif, ThunderX2 a bien fonctionné pour gcc, qui fonctionne principalement à l'intérieur du cache L1 et L2 (en s'appuyant ainsi sur une faible latence L2), et l'impact des performances du prédicteur de branche est minime. En général, le meilleur test pour TunderX2 est mcf (distribution de véhicules dans les transports publics), qui, comme vous le savez, ignore presque complètement le cache de données L1, en s'appuyant sur le cache L2, et c'est le point fort de ThunderX2. Mcf demande également de la bande passante mémoire. Libquantum est un test qui a le plus grand besoin de bande passante mémoire. Le fait que Skylake offre une bande passante à un seul thread assez médiocre est probablement aussi la raison pour laquelle ThunderX2 a si bien fonctionné sur libquantum et mcf.
SPEC CPU2006 Cont: performances basées sur les cœurs avec SMT
Au-delà des performances monothread, les performances multithread au sein d'un même cœur doivent également être prises en compte. L'architecture du processeur Vulcan a été initialement conçue pour utiliser SMT4 pour garder ses cœurs chargés et augmenter le débit global, et nous en parlerons maintenant.
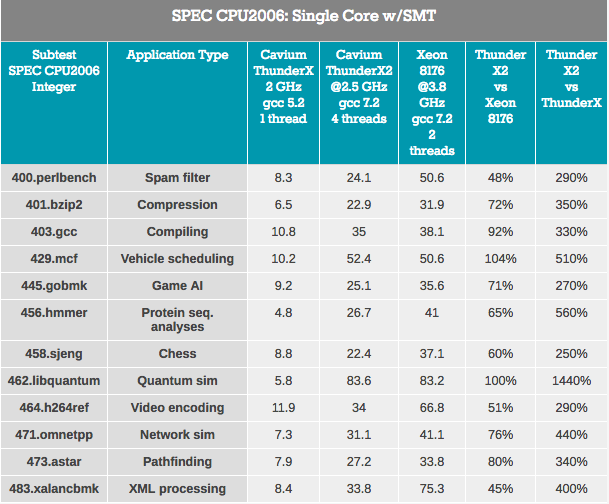
Tout d'abord, le noyau ThunderX2 a "subi" de nombreuses améliorations significatives par rapport au premier noyau ThunderX. Même avec libquantum à l'esprit, ce test peut facilement s'exécuter 3 fois plus rapidement sur l'ancien noyau ThunderX après quelques améliorations et optimisations du compilateur. Eh bien, le nouveau ThunderX2 n'est pas moins de 3,7 fois plus rapide que son frère aîné. Cette supériorité d'IPC élimine tous les avantages de l'ancien ThunderX.
En regardant l'impact du SMT, nous voyons en moyenne que le SMT à 4 voies améliore les performances de ThunderX2 de 32%. Cela varie de 8% pour l'encodage vidéo à 74% pour Pathfinding. Intel, quant à lui, gagne 18% par rapport à son SMT bidirectionnel, de 4% à 37% dans les mêmes scénarios.
Dans l'ensemble, l'augmentation des performances de ThunderX2 est de 32%, ce qui est plutôt bien. Mais ici, la question évidente se pose: en quoi est-elle différente des autres architectures SMT4? Par exemple, IBM POWER8, qui prend également en charge SMT4, affiche une augmentation de 76% dans le même scénario.
Cependant, ce n'est pas tout à fait une comparaison du similaire avec le similaire, car la puce IBM a un back-end beaucoup plus large: elle peut traiter 10 instructions, tandis que le noyau ThunderX2 est limité à 6 instructions par cycle. Le cœur POWER8 est plus gourmand: le processeur ne pouvait accueillir que 10 de ces cœurs "ultra-larges" dans un budget de puissance de 190 W à 22 nm. Très probablement, une nouvelle augmentation des performances de l'utilisation de SMT4 nécessitera des cœurs encore plus grands et, à son tour, affectera sérieusement le nombre de cœurs disponibles dans ThunderX2. Néanmoins, il est intéressant de regarder cette augmentation de 32% à l'avenir.
Dans la partie (3) suivante:
- Performances Java
- Performances Java: énormes pages
- Apache Spark 2.x Benchmarking
- Résumé
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?