La première et la
deuxième partie, «Évaluation du Cavium ThunderX2: le rêve du serveur Arm est devenu réalité».
Performances Java
SPECjbb 2015 est un benchmark Java Business Benchmark utilisé pour évaluer les performances des serveurs exécutant des applications Java typiques. Il utilise les dernières fonctionnalités Java 7 et XML, confondant avec la sécurité.

Veuillez noter que nous avons mis à jour la version de SPECjbb 1.0 vers la version 1.01.

Nous avons testé SPECjbb avec quatre groupes d'injecteurs de transactions et de backends. La raison pour laquelle nous utilisons le test Multi JVM est qu'il est plus proche des conditions réelles: plusieurs machines virtuelles sur un serveur sont une pratique courante, en particulier sur les serveurs avec plus de 100 threads. La version Java est OpenJDK 1.8.0_161.
Chaque fois que nous publions les résultats de SPECjbb, nous recevons des commentaires selon lesquels nos performances sont trop faibles. Par conséquent, nous avons décidé de passer un peu plus de temps et de prêter attention aux différents paramètres.
- Paramètres du noyau, tels que les horaires du planificateur de tâches, l'effacement du cache de pages
- Désactivation des fonctions d'économie d'énergie, configuration manuelle du comportement de l'état c.
- Régler les ventilateurs à la vitesse maximale (nous dépensons beaucoup d'énergie en faveur de quelques points de performance supplémentaires)
- Désactivation des fonctions RAS (par exemple, nettoyage de la mémoire)
- Nombreux réglages pour différents paramètres Java ... C'est irréaliste, car à chaque fois que vous exécutez l'application sur différentes machines (ce qui arrive souvent dans le cloud), des spécialistes coûteux doivent configurer les réglages pour une machine spécifique, ce qui peut en outre entraîner l'arrêt de l'application sur d'autres machines
- Configurez des paramètres NUMA et des mappages CPU très spécifiques aux SKU. La migration entre deux références SKU différentes dans le même cluster peut entraîner de graves problèmes de performances.
Dans un environnement de production, le réglage doit être simple et, de préférence, pas trop spécifique à la machine. À cette fin, nous avons appliqué deux types de paramètres. Le premier est une configuration très simple pour mesurer les performances prêtes à l'emploi pour tout placer sur un serveur avec 128 Go de RAM:
"-server -Xmx24G -Xms24G -Xmn16G"Pour la deuxième configuration, à la recherche du meilleur indicateur de débit, nous avons joué avec «-XX: + AlwaysPreTouch», «-XX: -UseBiasLocking» et «specjbb.forkjoin.workers». «+ AlwaysPretouch» réinitialise toutes les pages de mémoire avant de commencer, ce qui réduit l'impact sur les performances des nouvelles pages. «-UseBiasLockin» désactive le verrouillage baisé, qui est activé par défaut. Le verrouillage biaisé donne la priorité à un thread qui a déjà chargé des données rivales dans le cache. Le revers du verrouillage biaisé est un processus supplémentaire assez complexe (rebias) qui peut réduire les performances dans le cas d'une stratégie mal choisie.
Le graphique ci-dessous montre les performances maximales de notre référence MultiJVM SPECJbb.

ThunderX2 atteint des performances de 80 à 85% du Xeon 8176. Ce chiffre est suffisant pour dépasser le Xeon 6148. Fait intéressant, les systèmes Intel et Cavium obtiennent leurs meilleurs résultats de différentes manières. Dans le cas de Dual ThunderX2, nous avons utilisé:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingAlors que le système Intel a réalisé les meilleures performances, tout en laissant un verrou de décalage (par défaut). Nous avons remarqué que le système Intel - probablement en raison du nombre relativement "impair" de threads - a une charge moyenne du processeur légèrement inférieure (quelques pour cent) et un cache L3 plus grand, ce qui fait du verrouillage biaisé une bonne stratégie pour cette architecture.
Enfin, nous avons Critical-jOPS, qui mesure le débit en fonction des limites de temps de réponse.

Avec l'utilisation active d'un grand nombre de threads, vous pouvez obtenir beaucoup plus de Critical-jOPS en augmentant la distribution de RAM sur la JVM. Étonnamment, le système Dual ThunderX2 - avec son nombre plus élevé de flux et sa vitesse d'horloge inférieure - affiche le meilleur moment, offrant une bande passante élevée, tout en maintenant un temps de réponse de 99% à une certaine limite.
L'augmentation de la taille du tas permet à Intel de réduire légèrement l'écart (jusqu'à x2), mais au détriment de la bande passante (de -20% à -25%). Il semble que la puce Intel nécessite plus de personnalisation que ARM. Pour explorer cela plus avant, nous nous sommes tournés vers Transparant Huge Pages (THP).
Performances Java: grandes pages
Habituellement, pour le processeur, quelqu'un rejoue rarement un autre dans le facteur 3, mais nous avons décidé d'étudier la question plus en profondeur. Le candidat le plus évident était Huge Pages, ou comme tout le monde sauf la communauté Linux l'appelle «Large Pages».
Chaque processeur moderne met en cache les mappages de mémoire virtuelle et physique dans ses TLB. La taille de page «normale» est de 4 Ko, donc avec 1536 éléments, le noyau Skylake peut mettre en cache environ 6 Mo par cœur. Au cours des 15 dernières années, la capacité de DRAM est passée de quelques Go à des centaines de Go, et donc les échecs TLB sont devenus une préoccupation. Un miss TLB est assez cher - vous avez besoin de quelques accès mémoire pour lire quelques tables et enfin trouver une adresse physique.
Tous les processeurs modernes prennent en charge les grandes pages. En x86-64 (Intel et AMD), une option populaire est de 2 Mo, une page de 1 Go est également disponible. Pendant ce temps, une grande page sur ThunderX2 fait au moins 0,5 Go. L'utilisation de grandes pages réduit le nombre de ratés TLB (bien que le nombre d'entrées dans les TLB soit généralement beaucoup plus faible pour les grandes pages), réduit le nombre d'accès à la mémoire requis en cas de manque d'un TLB.
Cependant, il était temps avant que Linux ne prenne en charge cette fonctionnalité de manière pratique. La fragmentation de la mémoire, les paramètres conflictuels et difficiles à configurer, les incompatibilités et surtout les noms très confus ont causé beaucoup de problèmes. En fait, de nombreux éditeurs de logiciels conseillent toujours aux administrateurs de serveurs de désactiver les pages volumineuses.
À cette fin, voyons ce qui se passe si nous activons les pages immenses transparentes et enregistrons les meilleurs paramètres discutés précédemment.
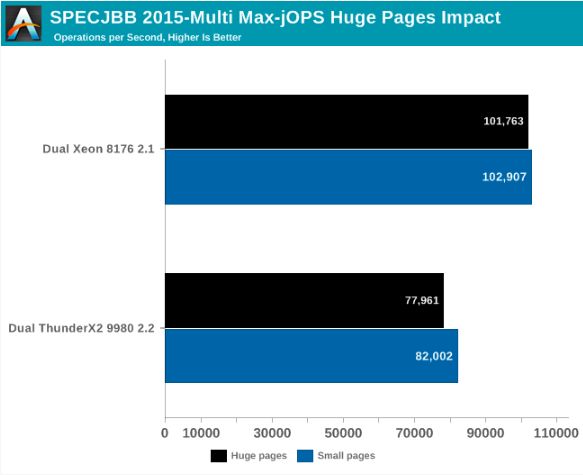
Globalement, pour Max-jOPs, l'impact sur les performances n'est pas spectaculaire; il s'agit en fait d'une petite régression. Xeon perd environ 1% de sa bande passante, ThunderX2 - environ 5%.
Passons à la métrique Critical-jOPS, où le débit est mesuré comme le 99e centile de la limite de temps de réponse.

Énorme différence! Au lieu de la défaite, Intel va au-delà de ThunderX2. Cependant, il faut dire que les performances avec des pages de 4 Ko sont apparemment une sérieuse faiblesse dans l'architecture Intel.
Apache Spark 2.x Benchmarking
Enfin, notre arsenal dispose du test Apache Spark. Apache Spark est le fruit du traitement du Big Data. L'accélération des applications Big Data reste un projet prioritaire dans le laboratoire universitaire où je travaille (Sizing Servers Lab University of West-Flanders), nous avons donc préparé un benchmark qui utilise de nombreuses fonctionnalités Spark et est basé sur une utilisation réelle.

Le test est décrit dans le schéma ci-dessus. Nous commençons avec 300 Go de données compressées collectées à partir de CommonCrawl. Ces fichiers compressés constituent un grand nombre d'archives Web. Nous décompressons les données à la volée pour éviter une longue attente, qui est principalement liée au périphérique de stockage. Ensuite, nous extrayons les données textuelles significatives des archives à l'aide de la bibliothèque Java BoilerPipe. À l'aide de l'outil de traitement du langage naturel Stanford CoreNLP, nous extrayons des entités («mots qui signifient quelque chose») du texte, puis calculons quelles URL contiennent le plus d'occurrences de ces objets. L'algorithme Alternating Lessest Square est utilisé pour recommander les URL les plus intéressantes pour un sujet particulier.
Pour obtenir une meilleure mise à l'échelle, nous lançons 4 artistes. Le chercheur Esley Havenert a reconfiguré le test Spark afin qu'il puisse s'exécuter sur Apache Spark 2.1.1.
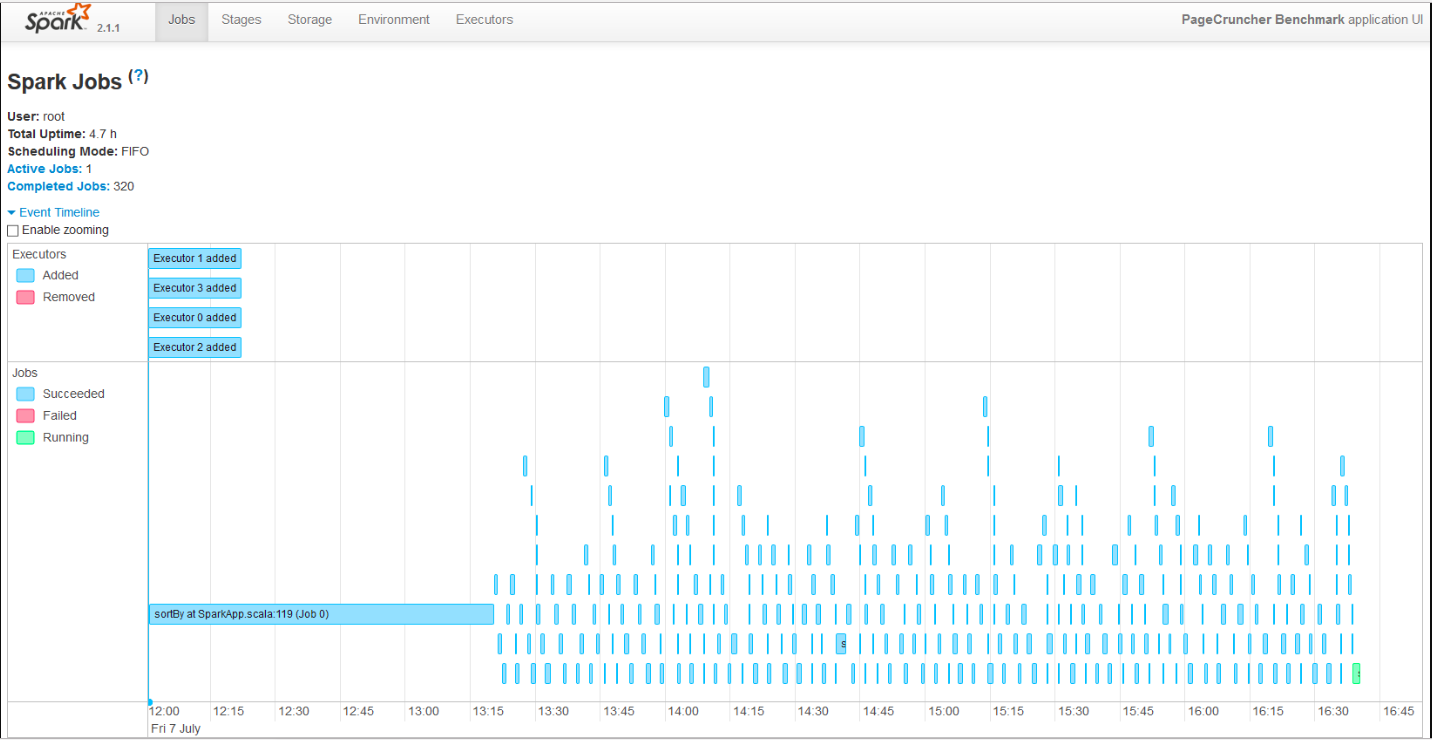
Voici les résultats:

(*) EPYC et Xeon E5 V4 sont plus anciens, fonctionnent sur le noyau 4.8 et Java 1.8.0_131 légèrement plus ancien au lieu de 1.8.0_161. Bien que nous nous attendions à ce que les résultats soient très similaires sur le noyau 4.13 et Java 1.8.0_161, car nous n'avons pas vu beaucoup de différence dans Skylake Xeon entre ces deux paramètres.
Le traitement des données est très parallèle et charge très intensivement le processeur, mais pour les phases de "shuffling" nécessite beaucoup d'interaction avec la mémoire. Le temps passé à communiquer avec le périphérique de stockage est négligeable. La phase ALS ne s'étend pas sur de nombreux threads, mais représente moins de 4% du temps de test total.
ThunderX2 fournit 87% des performances de l'EPYC 7601, deux fois plus cher. Comme cet indicateur évolue bien avec le nombre de cœurs, nous pouvons estimer que le Xeon 6148 obtiendra environ 4,8. sur Apache Spark Ainsi, alors que ThunderX2 ne peut pas vraiment menacer le Xeon Platinum 8176, il donne la même chose que le Gold 6148 et son frère pour beaucoup moins d'argent.
Et à la fin
Pour résumer tout, nos tests SPECInt montrent que les cœurs ThunderX2 ont encore quelques défauts. Notre première impression négative est que le code de branchement intensif - en particulier en combinaison avec les erreurs de cache L3 habituelles (délai DRAM élevé) - fonctionne assez lentement. Ainsi, il y aura des cas particuliers où ThunderX2 ne sera pas le meilleur choix.
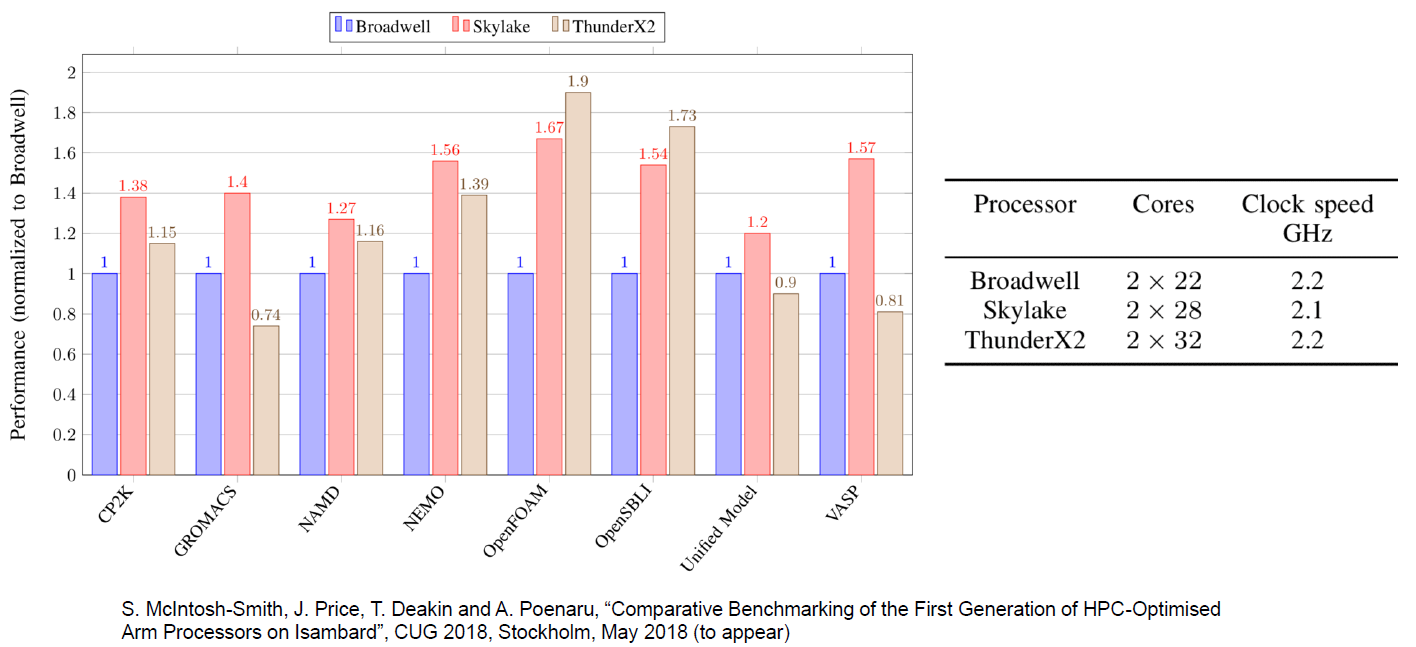
Cependant, en plus de certains marchés de niche, nous sommes presque sûrs que ThunderX2 deviendra un acteur solide. Par exemple, les mesures de performances effectuées par nos collègues de l'Université de Bristol confirment notre hypothèse selon laquelle les charges de travail HPC intenses telles que OpenFoam (CFD) et NAMD.run fonctionnent bien sur ThunderX2
Sur la base des résultats des premiers tests du logiciel serveur que nous avons réussi à faire, nous pouvons être agréablement surpris. Performances ThunderX2 pour un dollar à la fois sur Java Server (SPECJbb) et sur le traitement des données volumineuses - désormais - de loin les meilleures sur le marché des serveurs. Nous devons tester à nouveau le processeur AMD EPYC et la version dorée de la génération actuelle (Skylake) de Xeon, mais en même temps, il sera très difficile de battre 80 à 90% des performances du processeur 8176 pour un quart de son coût.
Comme avantage supplémentaire pour Cavium et ThunderX2, il convient de mentionner que l'écosystème Arm Linux est déjà mature en 2018; les noyaux Linux spécialisés et d'autres outils ne sont plus nécessaires. Vous installez simplement le serveur Ubuntu, Red Hat ou Suse et vous pouvez automatiser le déploiement et l'installation de logiciels à partir de référentiels standard. Il s'agit d'une amélioration significative par rapport à ce que nous avons connu lors du lancement de ThunderX. En 2016, une simple installation à partir de référentiels Ubuntu classiques pouvait causer des problèmes.
Donc, dans l'ensemble, ThunderX2 est un rival très puissant. Cela peut être encore plus dangereux pour EPYC AMD que pour Skylake Xeon d'Intel en raison du fait que Cavium et AMD sont en concurrence pour le même groupe de clients, étant donné la possibilité d'abandonner Intel. Cela est dû au fait que les clients qui ont investi dans des logiciels d'entreprise coûteux (Oracle, SAP) sont moins sensibles aux coûts du côté matériel, ils sont donc beaucoup moins susceptibles de passer à une nouvelle plate-forme matérielle. Et ces personnes ont investi dans Intel au cours des 5 dernières années, car c'était la seule option.
En retour, cela signifie que ceux qui sont plus flexibles et sensibles aux prix, tels que les fournisseurs d'hébergement et de cloud, pourront désormais choisir un serveur Arm alternatif avec un excellent rapport performances / dollar. Et avec HP, Cray, Pengiun, Gigabyte, Foxconn et Inventec proposant des systèmes basés sur ThunderX2, les fournisseurs de qualité ne manquent pas.
En bref, ThunderX2 est le premier SoC à concurrencer Intel et AMD sur le marché des serveurs CPU. Et c'est une agréable surprise: enfin, une solution pour les serveurs Arm est apparue!
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?