La réplication de flux, apparue en 2010, est devenue l'une des fonctionnalités révolutionnaires de PostgreSQL et à l'heure actuelle, presque aucune installation n'est complète sans l'utilisation de la réplication en streaming. Il est fiable, facile à configurer et peu exigeant pour les ressources. Cependant, malgré toutes ses qualités positives, au cours de son fonctionnement, divers problèmes et situations désagréables peuvent survenir.
Alexey Lesovsky (
@lesovsky ) à Highload ++ 2017 a expliqué comment
diagnostiquer divers types de problèmes à l' aide d'outils intégrés et tiers
et comment les résoudre . Sous les coupes, le décodage de ce rapport, construit sur un principe en spirale: d'abord, nous listons tous les outils de diagnostic possibles, puis passons à la liste des problèmes communs et à leur diagnostic, puis voyons quelles mesures d'urgence peuvent être prises, et enfin comment y faire face de manière radicale.
À propos de l'orateur : Alexei Lesovsky, administrateur de base de données chez Data Egret. L'un des sujets préférés d'Alexey dans PostgreSQL est la réplication en streaming et le travail avec les statistiques, donc le rapport de Highload ++ 2017 était consacré à la façon de trouver des problèmes en utilisant des statistiques et quelles méthodes utiliser pour les résoudre.
Plan
- Un peu de théorie, ou comment fonctionne la réplication dans PostgreSQL
- Outils de dépannage ou ce que PostgreSQL et la communauté ont
- Dépannage des cas:
- problèmes: leurs symptômes et diagnostic
- les décisions
- mesures à prendre pour que ces problèmes ne se posent pas.
Pourquoi tout ça? Cet article vous aidera à mieux comprendre la réplication en streaming, à découvrir comment trouver et résoudre rapidement les problèmes afin de réduire le temps de réaction aux incidents désagréables.
Un peu de théorie
PostgreSQL possède une entité telle que Write-Ahead Log (XLOG), un journal des transactions.
Presque toutes les modifications apportées aux données et aux métadonnées dans la base de données sont enregistrées dans ce journal. Si un accident se produit soudainement, PostgreSQL démarre, lit le journal des transactions et restaure les modifications enregistrées des données. Cela garantit la fiabilité - l'une des propriétés les plus importantes de tout SGBD et PostgreSQL.
Le journal des transactions peut être rempli de deux manières:
- Par défaut, lorsque les backends apportent des modifications à la base de données (INSERT, UPDATE, DELETE, etc.), toutes les modifications sont enregistrées de manière synchrone dans le journal des transactions:
- Le client a envoyé une commande COMMIT pour confirmer les données.
- Les données sont enregistrées dans le journal des transactions.
- Une fois la fixation effectuée, le contrôle est donné au backend et il peut continuer à recevoir des commandes du client.
- La deuxième option est l' écriture asynchrone dans le journal des transactions, lorsqu'un processus d'écriture WAL dédié distinct écrit les modifications dans le journal des transactions avec un certain intervalle de temps. De ce fait, une augmentation des performances du backend est obtenue, car il n'est pas nécessaire d'attendre la fin de la commande COMMIT.
Plus important encore, la réplication en streaming est basée sur ce journal de transactions. Nous avons plusieurs membres de réplication en streaming:
- maîtriser où tous les changements ont lieu;
- plusieurs répliques qui acceptent le journal des transactions du maître et reproduisent toutes ces modifications sur leurs données locales. Il s'agit de la réplication en streaming.
Il convient de rappeler que tous ces journaux de transactions sont stockés dans le répertoire pg_xlog dans $ DATADIR - le répertoire contenant les principaux fichiers de données du SGBD. Dans la 10ème version de PostgreSQL, ce répertoire a été renommé pg_wal /, car il n'est pas rare que pg_xlog / occupe beaucoup d'espace, et les développeurs ou administrateurs qui le confondent sans le savoir avec les journaux, le suppriment négligemment et tout devient mauvais.
PostgreSQL dispose de plusieurs services d'arrière-plan impliqués dans la réplication en streaming. Regardons-les du point de vue du système d'exploitation.
- Du côté du processus maître - expéditeur WAL. Il s'agit d'un processus qui envoie des journaux de transactions aux répliques, chaque réplique aura son propre expéditeur WAL.
- La réplique, à son tour, exécute le processus WAL Receiver, qui reçoit les journaux de transactions sur la connexion réseau de l'expéditeur WAL et les transmet au processus de démarrage.
- Le processus de démarrage lit les journaux et reproduit sur le répertoire de données toutes les modifications enregistrées dans le journal des transactions.
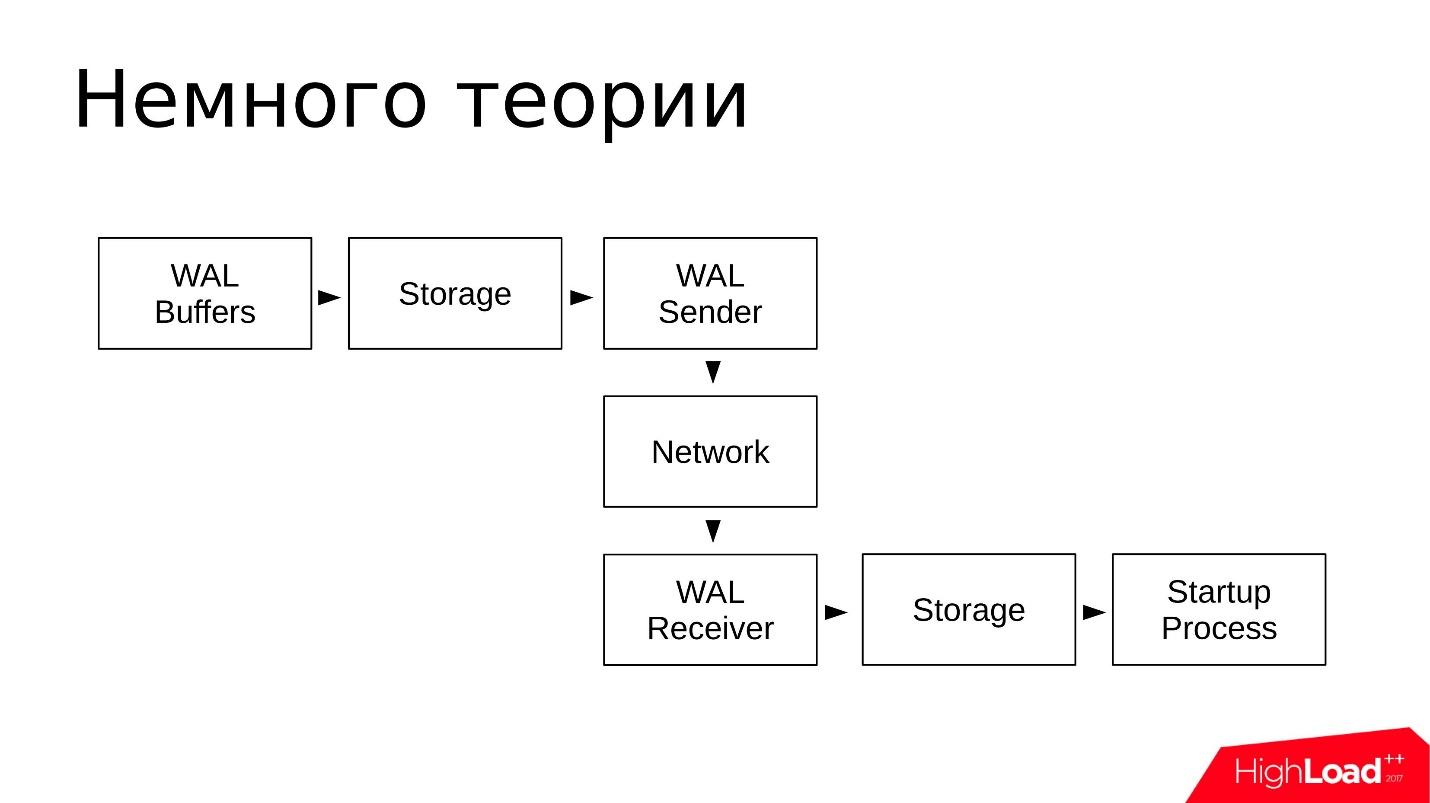
Schématiquement, cela ressemble à ceci:
- Les modifications sont écrites dans les tampons WAL, qui seront ensuite écrites dans le journal des transactions;
- Les journaux sont stockés dans le répertoire pg_wal /;
- WAL Sender lit le journal des transactions à partir du référentiel et les transmet sur le réseau;
- Le récepteur WAL reçoit et stocke dans son stockage - dans le local pg_wal /;
- Le processus de démarrage lit tout ce qui est accepté et se reproduit.
Le schéma est simple. La réplication de flux fonctionne de manière assez fiable et a été parfaitement exploitée pendant de nombreuses années.
Outils de dépannage
Voyons quels outils et utilitaires la communauté et PostgreSQL proposent pour étudier les problèmes rencontrés avec la réplication en streaming.
Outils tiers
Commençons par des outils tiers. Ces utilitaires sont d'un
plan plutôt
universel ; ils peuvent être utilisés non seulement pour enquêter sur les incidents liés à la réplication en streaming. Ce sont généralement des
utilitaires de tout administrateur système .
- haut du package procps. En remplacement de top, vous pouvez utiliser tous les utilitaires tels que atop, htop et similaires. Ils offrent des fonctionnalités similaires.
Avec l'aide de top, nous examinons: l'utilisation des processeurs (CPU), la charge moyenne (charge moyenne) et l'utilisation de la mémoire et de l'espace d'échange.
- iostat de sysstat et iotop. Ces utilitaires indiquent l'utilisation des unités de disque et les E / S créées par les processus du système d'exploitation.
Avec l'aide d'iostat, nous examinons: l'utilisation du stockage, combien d'iops en ce moment, quel débit sur les périphériques, quels retards lors du traitement des demandes d'E / S (latence). Ces informations assez détaillées sont extraites du système de fichiers procfs et sont fournies à l'utilisateur sous forme visuelle.
- nicstat est un analogue d'iostat, uniquement pour les interfaces réseau. Dans cet utilitaire, vous pouvez observer l'utilisation des interfaces.
En utilisant nicstat, nous regardons: de même, l'utilisation des interfaces, certaines erreurs qui se produisent sur les interfaces, le débit est également un utilitaire très utile.
- pgCenter est un utilitaire pour travailler uniquement avec PostgreSQL. Il affiche les statistiques PostgreSQL dans une interface de type supérieur, et vous pouvez également y voir des statistiques liées à la réplication en streaming.
Avec l'aide de pgCenter, nous regardons: des statistiques sur la réplication. Vous pouvez observer le décalage de réplication, l'évaluer d'une manière ou d'une autre et prévoir le travail futur.
- perf est un utilitaire pour une enquête plus approfondie sur les causes des "cliquetis souterrains", quand en fonctionnement il y a des problèmes étranges au niveau du code PostgreSQL.
Avec l'aide de la perf, nous recherchons: des coups souterrains. Pour que perf fonctionne pleinement avec PostgreSQL, ce dernier doit être compilé avec des caractères de débogage, afin que vous puissiez regarder la pile de fonctions dans les processus et quelles fonctions prennent le plus de temps CPU.
Tous ces utilitaires sont nécessaires pour
tester les hypothèses qui surviennent lors du dépannage - où et ce qui ralentit, où et ce que vous devez corriger, vérifiez. Ces utilitaires permettent de s'assurer que nous sommes sur la bonne voie.
Outils intégrés
Que propose PostgreSQL lui-même?
Vues système
En général, il existe de nombreux outils pour travailler avec PostgreSQL. Chaque fournisseur qui fournit un support PostgreSQL propose ses propres outils. Mais, en règle générale, ces outils sont basés sur des statistiques PostgreSQL internes. À cet égard, PostgreSQL fournit des vues système dans lesquelles vous pouvez effectuer diverses sélections et obtenir les informations dont vous avez besoin. Autrement dit, en utilisant un client standard, généralement psql, nous pouvons effectuer des requêtes et voir ce qui se passe dans les statistiques.
Il existe plusieurs vues du système. Pour travailler avec la réplication en streaming et enquêter sur les problèmes, nous n'avons besoin que de: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts et auxiliaire pg_stat_activity et pg_stat_archiver.
Il y en a peu, mais cet ensemble suffit pour vérifier s'il y a des problèmes.
Fonctions d'assistance
En utilisant des fonctions auxiliaires, vous pouvez prendre des données à partir de représentations du système statistique et les transformer en une forme plus pratique pour vous. Les fonctions auxiliaires ne sont également que quelques pièces.
- pg_current_wal_lsn () (l'ancien analogue de pg_current_xlog_location ()) est la fonction la plus nécessaire qui vous permet de voir la position actuelle dans le journal des transactions. Un journal des transactions est une séquence continue de données. En utilisant cette fonction, vous pouvez voir le dernier point, obtenir la position où le journal des transactions s'est arrêté maintenant.
- pg_last_wal_receive_lsn (), pg_last_xlog_receive_location () est une fonction similaire à ce qui précède, uniquement pour les répliques. La réplique reçoit le journal des transactions et vous pouvez voir la dernière position du journal des transactions reçue;
- pg_wal_lsn_diff (), pg_xlog_location_diff () est une autre fonction utile. Nous lui donnons deux positions du journal des transactions, et elle montre diff - la distance entre ces deux points en octets. Cette fonction est toujours utile pour déterminer le décalage entre le maître et les répliques en octets.
Une liste complète des fonctions peut être obtenue avec la méta-commande psql: \ df * (wal | xlog | lsn | location) *.
Vous pouvez le taper dans psql et voir toutes les fonctions que contiennent wal, xlog, Isn, location. Il y aura environ 20 à 30 fonctions de ce type et elles fourniront également diverses informations sur le journal des transactions. Je vous recommande de vous familiariser.
Utilitaire Pg_waldump
Avant la version 10.0, il s'appelait pg_xlogdump. L'utilitaire pg_waldump est nécessaire lorsque nous voulons examiner les segments du journal des transactions, savoir quels enregistrements de ressources y sont arrivés et ce que PostgreSQL y a écrit, c'est-à-dire pour une étude plus détaillée.
Dans la version 10.0, toutes les vues système, fonctions et utilitaires qui comprenaient le mot xlog ont été renommés. Toutes les occurrences des mots xlog et location ont été remplacées respectivement par les mots wal et lsn. La même chose a été faite avec le répertoire pg_xlog qui est devenu le répertoire pg_wal.
L'utilitaire pg_waldump décode simplement le contenu des segments XLOG dans un format lisible par l'homme. Vous pouvez voir ce que les soi-disant enregistrements de ressources tombent dans les journaux de segment pendant le travail de PostgreSQL, quels index et fichiers de tas ont été modifiés, quelles informations destinées à la réserve y sont arrivées. Ainsi, de nombreuses informations peuvent être consultées à l'aide de pg_waldump.
Mais il y a une clause de non-responsabilité qui est écrite dans la documentation officielle : pg_waldump peut afficher des données légèrement incorrectes lorsque PostgreSQL est en cours d'exécution (peut donner des résultats erronés lorsque le serveur est en cours d'exécution - quoi que cela signifie)
Vous pouvez utiliser la commande:
pg_waldump -f - /wal_10 \ $(psql -qAtX - "select pg_walfile_name(pg_current_wal_lsn())")
Il s'agit d'un analogue de la commande tail -f pour les journaux de transactions uniquement. Cette commande affiche la fin du journal des transactions qui se produit en ce moment. Vous pouvez exécuter cette commande, elle trouvera le dernier segment avec l'entrée de journal de transactions la plus récente, se connectera à elle et commencera à afficher le contenu du journal de transactions. Une équipe un peu délicate, mais ça marche quand même. Je l'utilise souvent.
Dépannage des cas
Ici, nous examinons les problèmes les plus courants qui se posent dans la pratique des consultants, quels symptômes peuvent être et comment les diagnostiquer:
Les retards de réplication sont le problème le plus courant . Plus récemment, nous avons eu une correspondance avec le client:
- Nous avons interrompu la réplication maître-esclave entre les deux serveurs.
- Décalage détecté de 2 heures, pg_dump a démarré.
- D' accord, je vois. Quel est notre décalage admissible?
- 16 heures à max_standby_streaming_delay.
- Que se passera-t-il lorsque ce décalage sera dépassé? Sirène hurlante?
- Non, les transactions seront battues et le rouleau WAL reprendra.
Nous avons des problèmes de décalage de réplication tout le temps, et presque chaque semaine nous les résolvons.
Le gonflement du répertoire pg_wal / où les segments du journal des transactions sont stockés est un problème qui se produit moins fréquemment. Mais dans ce cas, il est nécessaire de prendre des mesures immédiates afin que le problème ne se transforme pas en situation d'urgence lorsque les répliques tombent.
Les longues requêtes qui s'exécutent sur le réplica entraînent des
conflits lors de la récupération . Il s'agit d'une situation où nous commençons une sorte de chargement sur la réplique, vous pouvez exécuter des requêtes de lecture sur les répliques, et à ce moment ces requêtes interfèrent avec la reproduction du journal des transactions. Il y a un conflit et PostgreSQL doit décider d'attendre la fin de la requête ou de la terminer et de continuer à lire le journal des transactions. Il s'agit d'un conflit de réplication ou d'un conflit de récupération.
Processus de récupération: 100% d'utilisation du processeur - Le processus de récupération d'un journal des transactions sur les répliques prend 100% du temps du processeur. C'est aussi une situation rare, mais plutôt désagréable, car conduit à une augmentation du retard de réplication et est généralement difficile à étudier.
Retards de réplication
Les décalages de réplication se produisent lorsque la même demande, exécutée sur le maître et sur la réplique, renvoie des données différentes. Cela signifie que les données sont incohérentes entre le maître et les répliques et qu'il y a un certain décalage. La réplique doit reproduire une partie des journaux de transactions afin de rattraper l'assistant. Le symptôme principal ressemble exactement à ceci: il y a une requête et ils retournent des résultats différents.
Comment rechercher de tels problèmes?- Il existe une vue de base sur l'assistant et sur les répliques - pg_stat_replication . Il affiche des informations sur tous les expéditeurs WAL, c'est-à-dire sur les processus qui envoient des journaux de transactions. Chaque réplique aura une ligne distincte qui affiche des statistiques pour cette réplique particulière.
- La fonction auxiliaire pg_wal_lsn_diff () vous permet de comparer différentes positions dans le journal des transactions et de calculer le même décalage. Avec son aide, nous pouvons obtenir des chiffres spécifiques et déterminer où nous avons un grand décalage, où est un petit et déjà répondre en quelque sorte au problème.
- La fonction pg_last_xact_replay_timestamp () fonctionne uniquement sur la réplique et vous permet de voir l'heure à laquelle la dernière transaction perdue a été effectuée. Il existe une fonction now () bien connue qui montre l'heure actuelle, nous soustrayons l'heure qui nous est montrée par la fonction pg_last_xact_replay_timestamp () de la fonction now () et obtenons le décalage temporel.
Dans la 10ème version de pg_stat_replication, des champs supplémentaires sont apparus qui montrent le décalage déjà sur l'assistant, donc cette méthode est déjà obsolète, mais, néanmoins, elle peut être utilisée.
Il y a un petit piège. S'il n'y a pas de transactions sur l'Assistant pendant une longue période et qu'il ne génère pas de journaux de transactions, la dernière fonction affichera un décalage croissant. En fait, le système est tout simplement inactif, il n'y a aucune activité dessus, mais en surveillant, nous pouvons voir que le décalage augmente. Cet écueil mérite d'être rappelé.
La vue est la suivante.

Il contient des informations sur chaque expéditeur WAL et plusieurs champs qui sont importants pour nous. Il s'agit principalement de
client_addr - l'adresse réseau de la réplique connectée (généralement une adresse IP) et un ensemble de champs
lsn (dans les anciennes versions, il est appelé emplacement), je vais en parler un peu plus loin.
Dans la 10e version, des champs de
décalage sont apparus - il s'agit d'un décalage exprimé dans le temps, c'est-à-dire un format plus lisible par l'homme. Le décalage peut être exprimé en octets ou en temps - vous pouvez choisir ce que vous préférez.
En règle générale, j'utilise cette demande.

Ce n'est pas la requête la plus complexe que pg_stat_replication imprime dans un format plus pratique et compréhensible. Ici, j'utilise les fonctions suivantes:
- pg_wal_lsn_diff () pour lire les diffs. Mais entre quoi je pense que les différences sont? Nous avons plusieurs champs - sent_lsn, write_lsn, flush_lsn, replay_lsn. En calculant la différence entre le champ actuel et le champ précédent, nous pouvons comprendre avec précision où nous avons pris du retard, où exactement le retard se produit.
- pg_current_wal_lsn () , qui montre la position actuelle du journal des transactions. Nous regardons ici la distance entre la position actuelle dans le journal et celle envoyée - combien de journaux de transactions ont été générés mais pas envoyés.
- sent_lsn , write_lsn - c'est la quantité envoyée à la réplique, mais non enregistrée. Autrement dit, il est maintenant situé quelque part sur le réseau, ou il a été reçu par une réplique, mais n'a pas encore été écrit des tampons réseau vers le stockage sur disque.
- write_lsn, flush_lsn - ceci est écrit, mais n'a pas été émis par la commande fsync - comme s'il était écrit, mais peut être situé quelque part dans la RAM, dans le cache de pages du système d'exploitation. Dès que nous faisons fsync, les données sont synchronisées avec le disque, accèdent au stockage persistant et tout semble fiable.
- replay_lsn, flush_lsn - données sauvegardées, fsync exécuté, mais pas répliqué.
- current_wal_lsn et replay_lsn est une sorte de décalage total qui inclut toutes les positions précédentes.
Quelques exemples

La réplique 10.6.6.8 est mise en évidence ci-dessus. Elle a un
décalage en attente , elle a généré des journaux de transactions, mais ils ne sont toujours pas envoyés et reposent sur le maître. Très probablement, il y a une sorte de problème avec les performances du réseau. Nous vérifierons cela en utilisant l'utilitaire nicstat.
Nous lancerons nicstat, voir l'utilisation de l'interface, s'il y a des problèmes et des erreurs. Nous pouvons donc tester cette hypothèse.

Le
décalage d'écriture est indiqué ci-dessus. En fait, ce décalage est assez rare, je ne le vois presque pas comme grand. Le problème peut être lié aux disques, et nous utilisons l'utilitaire iostat ou iotop - nous examinons l'utilisation des stockages sur disque, dont les E / S sont créées par les processus, puis nous découvrons pourquoi.
 Purger et relire les décalages
Purger et relire les décalages - le plus souvent, le décalage se produit là lorsque le périphérique de disque sur la réplique n'a pas le temps de simplement perdre toutes les modifications qui arrivent du maître.
Avec les utilitaires iostat et iotop, nous examinons également ce qui se passe avec l'utilisation du disque et pourquoi les freins.
Et le dernier
total_lag est une métrique utile pour surveiller les systèmes. Si notre seuil total_lag est dépassé, une case à cocher est levée dans la surveillance, et nous commençons à enquêter sur ce qui s'y passe.
Test d'hypothèse
Vous devez maintenant déterminer comment approfondir un problème particulier. J'ai déjà dit que s'il s'agit d'un décalage réseau, nous devons vérifier si tout est en ordre avec le réseau.
Maintenant, presque tous les hébergeurs fournissent 1 Gb / s ou même 10 Gb / s, donc une
bande passante obstruée est le scénario le plus improbable . En règle générale, vous devez examiner les erreurs. nicstat contient des informations sur les erreurs sur les interfaces, vous pouvez constater qu'il y a des problèmes avec les pilotes, soit avec la carte réseau elle-même, soit avec les câbles.
Nous étudions
les problèmes de stockage en utilisant iostat et iotop. iostat est nécessaire pour visualiser l'image générale du stockage sur disque: recyclage des périphériques, bande passante des périphériques, latence. iotop - pour une recherche plus précise, lorsque nous devons identifier le processus qui charge le sous-système de disque. S'il s'agit d'une sorte de processus tiers, il peut simplement être détecté, terminé et peut-être que le problème disparaîtra.
Tout d'abord, nous examinons
les délais de récupération et les conflits de réplication via top ou pg_stat_activity: quels processus sont en cours d'exécution, quelles requêtes sont en cours d'exécution, leur temps d'exécution, leur durée d'exécution. S'il s'agit de longues requêtes, nous examinons pourquoi elles fonctionnent longtemps, les photographions, les comprenons et les
optimisons - nous examinerons les requêtes elles-mêmes.
S'il s'agit d'une
grande quantité de journaux de transactions générés par l'assistant, nous pouvons le détecter par
pg_stat_activity . Peut-être que certains processus de sauvegarde y sont démarrés, une sorte de vide a été démarré (pg_stat_progress_vacuum) ou un point de contrôle est en cours d'exécution. Autrement dit, si trop de journaux de transactions sont générés et que la réplique n'a tout simplement pas le temps de la traiter, à un moment donné, elle risque de tomber, et ce sera un problème pour nous.
Et bien sûr,
pg_wal_lsn_diff () pour déterminer le décalage et déterminer où nous avons le décalage spécifiquement - sur le réseau, sur les disques ou sur les processeurs.
Options de solution
Problèmes de réseau / stockageTout est assez simple ici, mais du point de vue de la configuration, cela n'est généralement pas résolu. Vous pouvez serrer certains écrous, mais en général, il y a 2 options:
- Vérifier la charge de travail
Vérifiez quelles demandes sont en cours d'exécution. Peut-être que certaines migrations sont lancées qui génèrent beaucoup de journaux de transactions, ou cela peut être un transfert, une suppression ou une insertion de données.
Tout processus qui génère des journaux de transactions peut entraîner un retard de transaction . Toutes les données de l'assistant sont générées le plus rapidement possible, nous avons modifié les données, les avons envoyées à la réplique et la réplique peut s'adapter ou échouer - cela ne concerne pas l'assistant. Un décalage peut apparaître ici et vous devez en faire quelque chose.
- Mettre à niveau le matériel
L'option la plus stupide - peut-être que nous avons rencontré les performances du fer, et vous avez juste besoin de le changer. Il peut s'agir de vieux disques ou de SSD de mauvaise qualité, ou d'un plug in dans les performances d'un contrôleur RAID. Ici, nous n'explorons plus la base elle-même, mais vérifions les performances de nos glandes.
Délais de récupérationSi nous avons des conflits de réplication en raison de longues demandes, entraînant une augmentation du délai de relecture, la
première chose que nous faisons est de
tirer de longues demandes qui s'exécutent sur la réplique, car elles retardent la lecture des journaux de transactions.
Si les longues requêtes sont liées à la non-optimalité de la requête SQL elle-même (nous le découvrons en utilisant EXPLAIN ANALYZE), il vous suffit d'approcher cette requête différemment et de la réécrire. Ou il existe une option pour configurer une
réplique distincte pour les requêtes de rapport . Si nous faisons des rapports qui fonctionnent depuis longtemps, ils doivent être soumis à une réplique distincte.
Il y a toujours la possibilité d'
attendre . Si nous avons une sorte de décalage au niveau de quelques kilo-octets ou même des dizaines de mégaoctets, mais nous pensons que cela est acceptable, nous attendons simplement que la demande soit terminée et le décalage se résoudra automatiquement. C'est aussi une option, et il arrive souvent qu'elle soit acceptable.
WAL haut volumeSi nous générons un grand volume de journaux de transactions, nous devons réduire ce
volume par unité de temps , pour que la réplique doive moins mâcher les journaux de transactions.
Cela se fait généralement
via la configuration . Solution partielle en définissant le paramètre full_page_writes = off. Cette option active / désactive l'enregistrement d'images complètes de pages changeantes dans le journal des transactions. Cela signifie que lorsque nous avons eu l'opération de service d'écriture d'un point de contrôle (CHECKPOINT), la prochaine fois que nous changerons un bloc de données dans la zone des tampons partagés, l'image complète de cette page ira dans le journal des transactions, et pas seulement la modification elle-même. Avec toutes les modifications ultérieures sur la même page, seules les modifications seront enregistrées dans le journal des transactions. Et ainsi de suite jusqu'au prochain point de contrôle.
Après le point de contrôle, nous enregistrons l'image complète de la page, ce qui affecte le volume du journal des transactions enregistré. S'il y a beaucoup de points de contrôle par unité de temps, disons que 4 points de contrôle sont effectués par heure, et qu'il y aura beaucoup d'images en pleine page, ce sera un problème. Vous pouvez désactiver l'enregistrement d'images complètes et cela affectera le volume du WAL. Mais encore une fois, c'est une demi-mesure.
Remarque: La recommandation de désactiver full_page_writes doit être soigneusement étudiée, car l'auteur a oublié de préciser lors du rapport que la désactivation d'un paramètre peut, dans certaines circonstances, se produire dans des situations d'urgence (endommagement du système de fichiers ou de son journal, écriture partielle sur des blocs, etc.) fichiers de base de données potentiellement corrompus. Par conséquent, soyez prudent, la désactivation du paramètre peut augmenter le risque de corruption des données dans les situations d'urgence.Une autre demi-mesure consiste à
augmenter l'intervalle entre les points de contrôle . Par défaut, le point de contrôle est effectué toutes les 5 minutes, ce qui est assez courant. En règle générale, cet intervalle est augmenté à 30-60 minutes - c'est un temps tout à fait acceptable pour lequel toutes les pages sales parviennent à se synchroniser sur le disque.
Mais la principale solution est, bien sûr, d'
examiner notre charge de travail - quel type d'opérations lourdes se déroulent là-bas, associées à la modification des données, et, peut-être, d'essayer de faire ces changements par lots.
Supposons que nous ayons une table, nous voulons en supprimer plusieurs millions d'enregistrements. La meilleure option n'est pas de supprimer ces millions à la fois avec une seule demande, mais de les diviser en paquets de 100 à 200 000 afin que, premièrement, de petites quantités de WAL soient générées, deuxièmement, le vide a le temps de passer à travers les données supprimées, et donc le décalage n'était pas si grand et critique.
Gonflement pg_wal /
Maintenant, parlons de la façon dont vous pouvez constater que le répertoire pg_wal / est enflé.
En théorie, PostgreSQL le maintient toujours dans un état optimal pour lui-même au niveau de certains fichiers de configuration, et, en règle générale, il ne doit pas dépasser certaines limites.
Il existe un paramètre max_wal_size, qui détermine la valeur maximale. De plus, il y a le paramètre wal_keep_segments - un nombre supplémentaire de segments que le maître stocke pour la réplique si la réplique est soudainement indisponible pendant une longue période.
Après avoir calculé la somme de max_wal_size et wal_keep_segments, nous pouvons approximativement estimer l'espace que le répertoire pg_wal / occupera. Si elle croît rapidement et occupe beaucoup plus d'espace que la valeur calculée, cela signifie qu'il y a un problème et que vous devez faire quelque chose.
Comment détecter de tels problèmes?
Sur le système d'exploitation Linux, il existe la
commande du -csh . Nous pouvons simplement surveiller la valeur et surveiller le nombre de journaux de transactions que nous avons là-bas; Gardez une étiquette calculée, combien il doit et combien il prend réellement, et répondez en quelque sorte aux changements de nombres.
Un autre endroit que nous regardons est les
vues pg_replication_slots et
pg_stat_archiver . Les raisons les plus courantes pour lesquelles pg_wal / occupe beaucoup d'espace sont les emplacements de réplication oubliés ou l'archivage interrompu. D'autres raisons ont également leur place, mais dans ma pratique, elles étaient très rares.
Et, bien sûr, il y a toujours des erreurs dans les journaux PostgreSQL associés à la commande archive. Malheureusement, il n'y aura pas d'autres raisons liées à pg_wal / overflow. Nous ne pouvons y détecter que des erreurs d'archivage.
Options pour les problèmes:
CRUD lourd - lourdes opérations de rafraîchissement des données - lourd INSERT, DELETE, UPDATE, associé à la modification de plusieurs millions de lignes. Si PostgreSQL doit effectuer une telle opération, il est clair qu'une grande quantité de journal des transactions sera générée. Il sera stocké dans pg_wal /, et cela augmentera l'espace occupé. C'est, encore une fois, comme je l'ai dit plus tôt, c'est une bonne pratique de simplement les diviser en packs et de mettre à jour non pas la totalité de la baie, mais 100, 200, 300 000 chacun.
Un emplacement de réplication oublié ou inutilisé est un autre problème courant. Les gens utilisent souvent la réplication logique pour certaines de leurs tâches: ils configurent des bus qui envoient des données à Kafka, envoient des données à une application tierce qui décode la réplication logique dans un autre format et les traite en quelque sorte.
La réplication logique fonctionne généralement via des emplacements . Il se trouve que nous avons configuré un emplacement de réplication, joué avec l'application, réalisé que cette application ne nous convenait pas, désactivé l'application, supprimée
et les emplacements de réplication continuent de vivre .
PostgreSQL pour chaque emplacement de réplication enregistre des segments du journal des transactions au cas où une application distante ou une réplique se connecte à nouveau à cet emplacement, puis l'assistant peut leur envoyer ces journaux des transactions.
Mais le temps passe, personne ne se connecte à l'emplacement, les journaux de transactions s'accumulent et occupent à un moment donné 90% de l'espace. Nous devons découvrir ce que c'est, pourquoi tant d'espace est pris. En règle générale, cet emplacement oublié et inutilisé doit simplement être supprimé et le problème sera résolu. Mais plus à ce sujet plus tard.
Une autre option pourrait être une
archive_command cassée . Lorsque nous avons une sorte de référentiel de journal de transactions externe que nous conservons pour les tâches de reprise après sinistre, une commande d'archivage est généralement configurée, moins souvent pg_receivexlog est configuré. La commande enregistrée dans archive_command est très souvent une commande distincte ou un script qui prend des segments du journal des transactions de pg_wal / et le copie dans le stockage d'archive.
Il arrive que nous ayons effectué une sorte de mise à niveau des packages système, par exemple, dans rsync, la version a changé, les indicateurs ont été mis à jour ou modifiés, ou dans une autre commande qui a été utilisée dans la commande archive, le format a également changé - et le script ou le programme lui-même qui est spécifié dans archive_command se casse. Par conséquent, les archives cessent d'être copiées.
Si la commande archive a fonctionné avec une sortie différente de 0, un message à ce sujet sera écrit dans le journal et le segment restera dans le répertoire pg_wal /.
Jusqu'à ce que nous constations que notre équipe d'archives est en panne, les segments s'accumuleront et le lieu se terminera également à un moment donné.
Ensemble de mesures d'urgence (100% d'espace utilisé):1.
CRUD , — pg_terminate_backend().
- , , , .. , pg_wal/, .
2.
root — reserved space ratio (ext filesystems).
ext ext 5%. , , 5% — . , , 1% , tune2fs -m 1. PostgreSQL , . 100% .
3.
(LVM, ZFS,...).
LVM ZFS, LVM ZFS, , , . , .
4. —
, , HE pg_wal/ .
, , , . ! PostgreSQL , . , , , .
, pg_xlog/ pg_wal/ — log , , , , - — !
, 100% CPU, .
workload . , ? , - , -. : , tablespace, tablespace.
. , , , , , , .
— .checkpoints_segments/max_wal_size, wal_keep_segments . , , — 10-20 wal_keep_segments, max_wal_size. , . PostgreSQL pg_wal/ .
pg_replication_slots — . ,
, — . , , . .
WAL, ,
pg_stat_archiver , . ,
, , , .
checkpoint . , , . , PostgreSQL .
, checkpoint .
, , — . - , . , .
— PostgreSQL :
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
2 — , , . : , , . ( 30 ),
PostgreSQL — .
. , , . - , timeout . — ALTER, , .
. , tablespace , tablespace. , , - — .
?
pg_stat_databases, pg_stat_databases_conflicts . , . , .
,
. , . , . , , , .
Que faire
, — :
- max_standby_streaming_delay ( ). , . .
- hot_stadby_feedback ( /). , vacuum - , . bloat . , , , hot_stadby_feedback .
- DBA — . , . , , , - , .
- , , , , DBA — , , . max_standby_streaming_delay . , . , , , . — , .
Recovery process: 100% CPU usage
, , ,
100% . , , 100%. , pg_stat_replication, , replay, , .
:
- top — — 100% CPU usage recovery process;
- pg_stat_replication — , , .
, . , :
- perf top/record/report ( debug—);
- GDB;
- pg_waldump.
, , . workload,
. , , PostgreSQL shared buffers ( ). .
Solution
,
. - workload, - , - : « , - ».
pgsql-hackers ,
pgsql-bugs , , . , .
—
- , , .
. , , , .
. , , , , , — .
,
, — . , , , .
, ,
— , , .
, Highload++ Siberia , 25 26 . , , .
- MySQL ClickHouse.
- , Oracle.
- , , — , .
- , VK ClickHouse, , .