
Demain, il y aura des communiqués de presse officiels sur la fusion de l'ancienne Silicon Valley, MIPS, avec la jeune société d'IA Wave Computing. Les informations sur cet événement ont été divulguées aux médias hier, et bientôt CNet, Forbes, EE Times et un tas de sites de haute technologie ont publié des articles sur cet événement. Aujourd'hui, Derek Meyer, président de la société issue du regroupement (photo ci-dessous à droite), a déclaré: «D'accord, partagez les informations avec vos amis» et j'ai décidé d'écrire quelques mots sur les technologies et les personnes associées à cet événement.
Le principal investisseur dans MIPS et Wave est le milliardaire Dado Banatao (photo ci-dessous, au centre à gauche), qui a fondé la société Chips & Technoilogies dans les années 1980, qui fabriquait des chipsets pour les premiers employés. Il y a d'autres célébrités dans Wave + MIPS, comme Stephen Johnson (photo en haut à droite), l'auteur du compilateur C le plus populaire du début des années 1980. MIPS est bien connu en Russie. Dans les mains du designer Smriti (photo de gauche) se trouve une carte de Zelenograd, où se trouvent les licenciés MIPS Elvis-NeoTek et Baikal Electronics.
Wave a déjà sorti une puce composée de milliers d'unités de traitement, essentiellement des processeurs simplifiés. Cette conception est optimisée pour un calcul de réseau neuronal très rapide. Wave a un compilateur qui transforme un graphique de flux de données en un fichier de configuration pour cette structure.
La société issue de la fusion créera une puce composée d'un mélange de ces unités de calcul et de noyaux MIPS multithread. Maintenant, Wave vend sa technologie sous la forme d'un boîtier pour centres de données, pour le calcul de réseaux de neurones dans le cloud. Les puces suivantes seront utilisées dans les appareils intégrés.
Les réseaux de neurones sont traditionnellement représentés sous forme de graphique de flux de données. Il s'agit d'un graphe dont les nœuds contiennent des constantes, des variables et des opérations arithmétiques sur des scalaires, des vecteurs et des matrices:
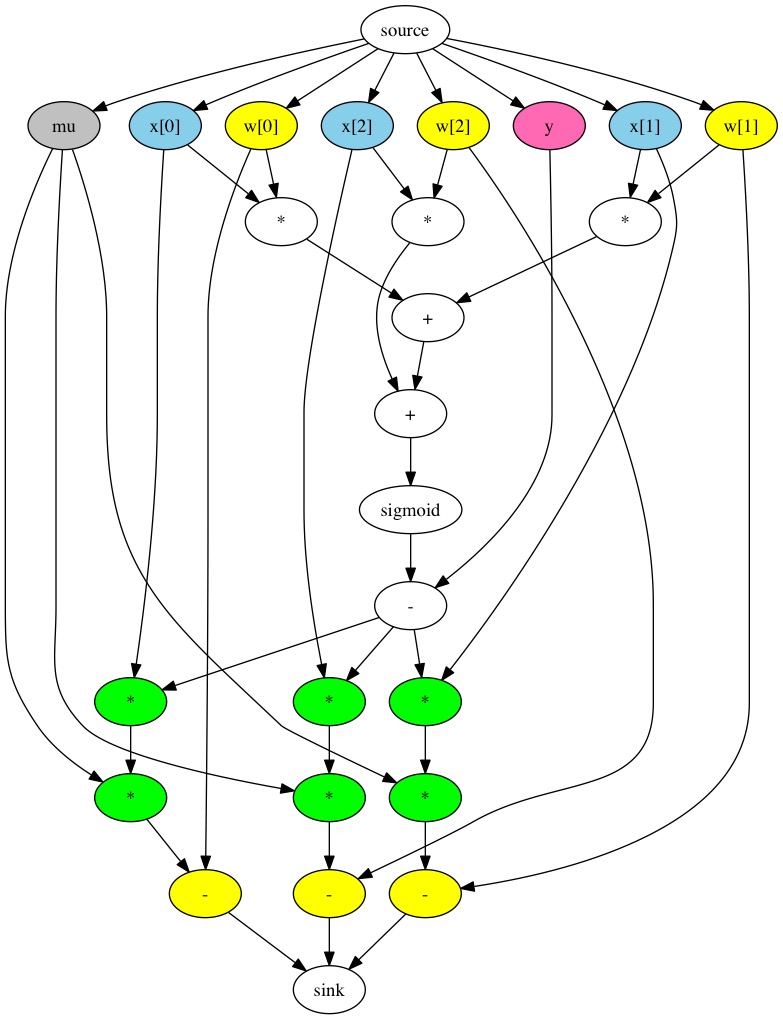
Google a créé la bibliothèque TensorFlow, qui est une API pour construire de tels graphiques et exécuter des calculs sur une grille - à la fois une inférence régulière et une formation utilisant backpropfgftion. Cette API est le plus souvent utilisée avec python, le code sur lequel ressemble à ceci:

Dans le même temps, le python dans l'exemple ci-dessus utilise la redéfinition des opérations arithmétiques, qui en réalité ne calculent pas, mais construisent un graphique en mémoire. En C, le code de construction d'un graphe dans TensorFlow ressemble à ceci:

Dans Google, j'ai un ami programmeur ukrainien Mikhail Simbirsky qui utilise TensorFlow sur python. Les réseaux de neurones de Google sont utilisés, par exemple, pour analyser le comportement des utilisateurs afin de les cibler avec de la publicité. Certains calculs pour la formation des réseaux neuronaux de Google prennent des jours et des semaines, malgré le fait que Google utilise le GPU NVidia et ses propres accélérateurs Google. Ce n'est pas une tâche facile, car le transfert de données entre processeurs et GPU prend du temps:
L'un des problèmes de conception des processeurs et des GPU est que le GPU est inactif pendant longtemps:

Un autre problème est la bande passante mémoire insuffisante des interfaces. Wave en combinaison avec MIPS va résoudre l'un et l'autre problème. Dans les nouveaux produits, le processeur n'utilisera pas l'accélérateur comme coprocesseur, mais ils fonctionneront ensemble.
Pour cela, les cœurs MIPS seront modifiés pour éventuellement créer une plate-forme matérielle standard pour l'IA. L'avantage des cœurs MIPS I6400 / I6500 (Samurai / Daimio) et MIPS I7200 (sous licence MediaTek) est le multithreading. ARM n'a pas de multithreading. Voici à quoi ressemble le pipeline multi-thread au cœur du MIPS I6400:
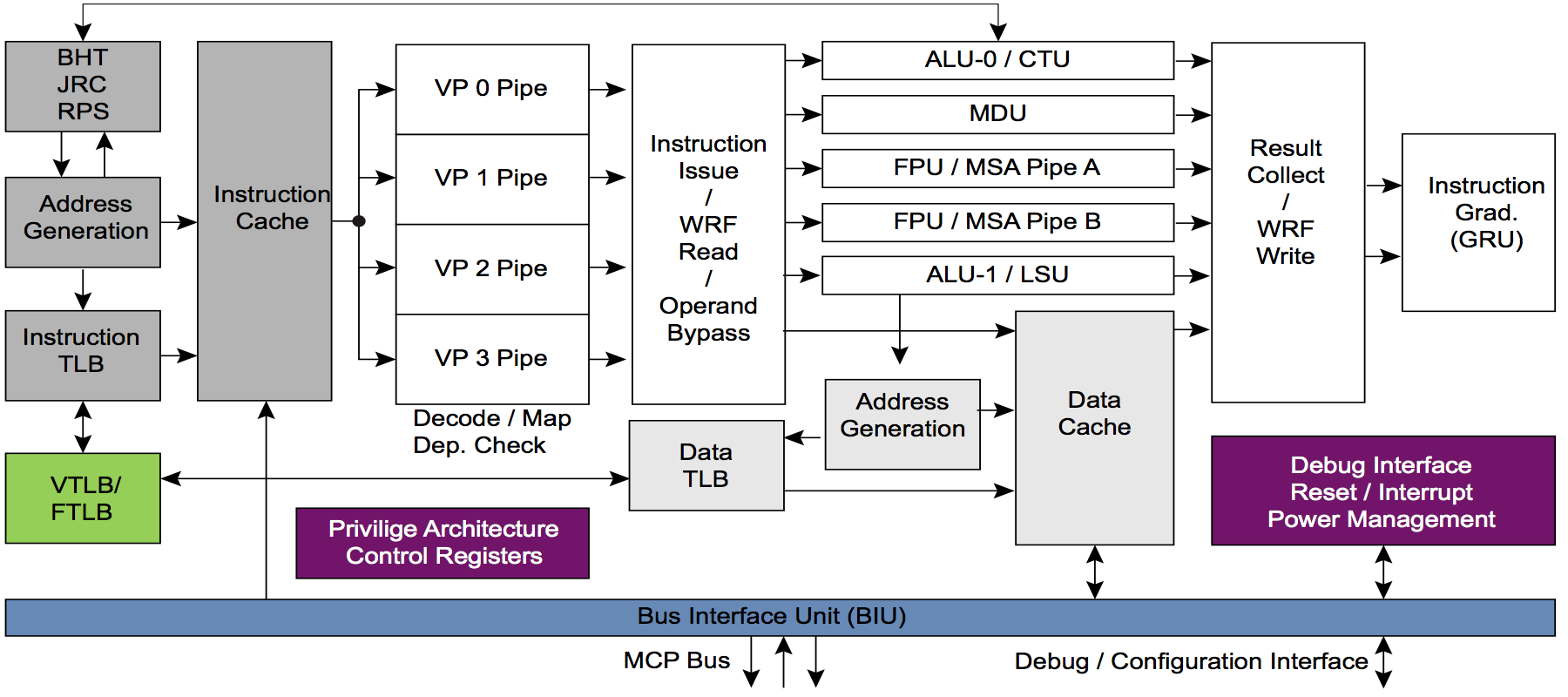
Et maintenant, la question s'adresse aux commentateurs les plus avertis: à votre avis, quel est l'avantage du multithreading pour une combinaison de CPU et d'accélérateur matériel? En particulier, l'accélérateur de Wave, qui est une variante du soi-disant CGRA - Coarse Grained Reconfigurable Array - tableaux reconfigurables à grains grossiers.
Si vous êtes familier avec FPGA (Field Programmable Gate Array) / FPGA (Programmable Logic Integrated Circuits), l'idée de CGRA est quelque peu similaire, mais ils ne fonctionnent pas avec des bits individuels, mais avec des bus entiers de 8 à 64 bits et dans chaque cellule il y a ALU, et pour plusieurs cellules - un coprocesseur arithmétique. Voici à quoi ressemble toute la hiérarchie:
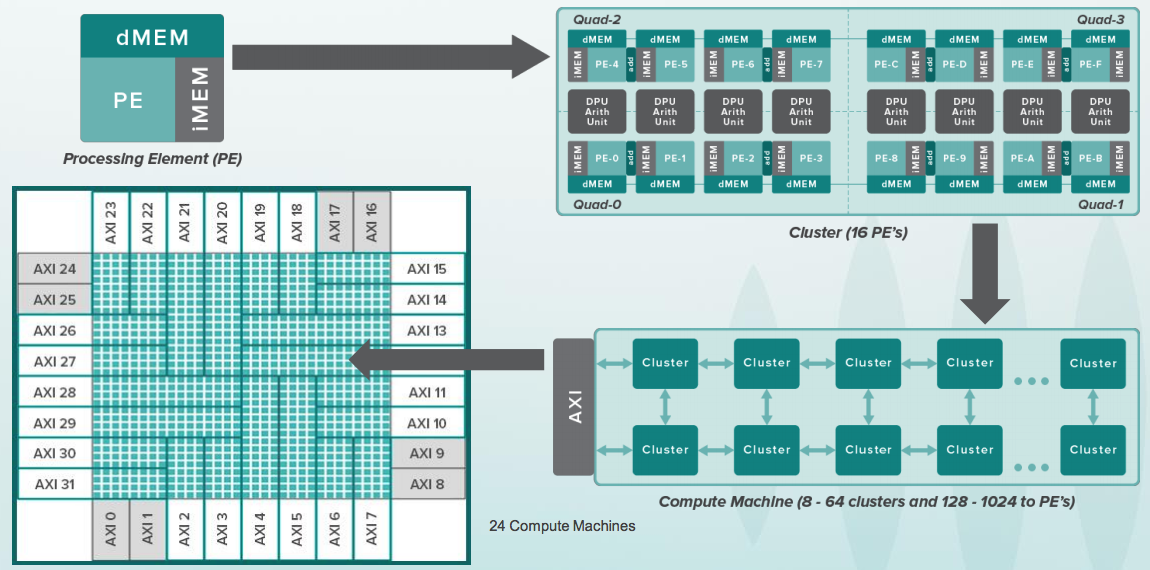
Et voici une cellule reconfigurable. Elle a un petit tampon avec des instructions qui ressemblent aux commandes simples des microcontrôleurs de batterie 8 bits, tels que 6502, qui était dans les premiers ordinateurs Apple. Dans le même temps, les processeurs de l'ancienne Apple fonctionnaient à une fréquence de quelques mégahertz et les cellules de CGRA fonctionnaient à une fréquence de plusieurs gigahertz. De plus, il n'y avait qu'un seul processeur chez Apple, mais il y a 16 mille cellules de ce type:

Le cristal de Wave est clairement énorme, vous devez donc utiliser des circuits localement synchrones avec un signal d'horloge pour chaque groupe de cellules. Mais le plus gros problème n'est pas le matériel, mais le logiciel. Le graphique de calcul de la grille doit être dispersé sur ce tas d'appareils avec une connaissance exacte dans quel cycle il sera calculé. C'est ce qu'on appelle la planification statique. Par conséquent, Wave a embauché un tas de compilateurs, dont le célèbre bison - Stephen Johnson, qui se tenait aux origines avec Kernigan et Richie. Voici ce que Dennis Ritchie a écrit sur Stephen Johnson:
Dans les années 80, C a rapidement gagné en popularité et les compilateurs sont devenus disponibles sur presque toutes les machines et tous les systèmes d'exploitation; en particulier, il est devenu populaire comme langage de programmation pour les ordinateurs personnels, à la fois pour les développeurs de logiciels commerciaux pour ces machines et pour les utilisateurs ordinaires qui aiment la programmation. Au début de la décennie, presque tous les compilateurs étaient basés sur le pcc de Johnson; en 1985, il y avait déjà de nombreux compilateurs créés par des développeurs indépendants.
Quand j'avais 18 ans (en 1988) et j'étais étudiant au MIPT, Stephen Johnson était mon Dieu. J'ai participé au développement de deux compilateurs basés sur son Portable C Compiler. Un compilateur était pour Electronics SS LSI, la Croix-Rouge, l'équivalent soviétique du supercalculateur vectoriel Cray-1. Le deuxième compilateur était pour Orbit 20-700, un ordinateur intégré dans les chasseurs soviétiques MiG-29 et autres du début des années 1980.
J'ai donc juste dû prendre une photo avec Stephen Johnson. Il m'a parlé d'autres outils qu'il avait créés à la fois pour Unix et pour l'automatisation de la conception, le profilage automatique, etc.

Et bien sûr, Dado Banatao a été photographié avec un investisseur dans toutes ces affaires. Il était une fois, Dado Banatao a créé le chipset pour le premier gribouillage. Il a débogué des pilotes avec Ballmer. «Parfois, Bill Gates entrait dans la pièce, ce qui nous dérangeait», explique Dado Banatao. Aujourd'hui, selon Internet, il dispose de cinq milliards de dollars. Il est le philippin de haute technologie le plus célèbre, crée un centre d'IA et gère d'autres programmes éducatifs dans son pays natal.

Dado Banatao a fait le plus d'argent à Marvell. Voici son bureau à Santa Clara sous le soleil du soir:

Wave emploie de nombreuses personnes qui travaillaient auparavant dans MIPS. Et certains des MIPS étaient dans Silicon Graphics, puisque MIPS faisait partie de Silicon Graphics dans les années 1990. À cette époque, les processeurs MIPS se trouvaient dans des stations graphiques utilisées à Hollywood pour tourner les premiers films graphiques réalistes tels que Jurassic Park. Ces stations graphiques avec Irina, une Sibérienne, au Computer History Museum de Mountain View, en Californie:

À la fin de la fête d'aujourd'hui, en l'honneur de l'annonce officielle de demain et des publications de presse d'hier, des gâteaux et du champagne ont eu lieu:

Demain, il y aura beaucoup de travail - de Verilog RTL (mes responsabilités directes) à discuter d'architecture, d'applications et même de parler à des scientifiques des données (ils se sentent d'un autre univers, d'ailleurs, cela est mutuel avec les ingénieurs électroniques et les compilateurs).