En termes simples, le modèle de régression en statistique mathématique est construit sur la base de données connues, qui sont des paires de nombres. Le nombre de ces paires est prédéterminé. Si vous imaginez que le premier nombre d'une paire est la valeur de la coordonnée et le second , alors l'ensemble de ces paires de nombres peut être représenté sur le plan dans le système de coordonnées cartésiennes comme un ensemble de points. Ces paires de nombres ne sont pas prises au hasard. En pratique, en règle générale, le deuxième nombre dépend du premier. Construire une régression signifie prendre une ligne (plus précisément une fonction) qui se rapproche le plus possible (se rapproche) d'un grand nombre des points ci-dessus.
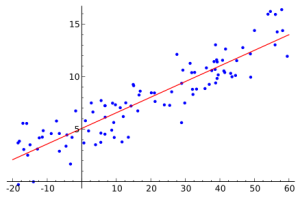
À quoi tout cela sert-il? Tout d'abord, cela est nécessaire pour la préparation de la soi-disant prévisions. Besoin souvent de découvrir
savoir seulement
s'il diffère de ces X, sur la base desquels la régression a été construite. Je vais donner un exemple simple. Il existe des statistiques sur la dépendance de la croissance d'une personne à son âge sur la base de 100 personnes différentes étudiées. Ainsi, nous avons 100 paires de nombres {âge; croissance}. Dans le même temps, la «croissance» est une quantité dépendante et «l'âge» est indépendant. En construisant correctement un modèle de régression, nous pouvons «prédire» la croissance avec certitude par n'importe quelle valeur d'âge.
En pratique, selon la situation, des fonctions linéaires, paraboliques, de puissance et autres sont utilisées dans la construction de modèles de régression. Dans le cadre des statistiques mathématiques, le modèle de régression linéaire est le plus souvent considéré. Parfois, ils touchent à un cas plus compliqué - un modèle parabolique. En faisant une généralisation, il est facile de deviner que les modèles linéaires et paraboliques sont des cas particuliers d'un modèle plus complexe - polynomial. Construire un modèle de régression signifie trouver les paramètres de la fonction qui y apparaîtra. Pour la régression linéaire - deux paramètres: coefficient et terme libre.
La régression polynomiale peut être utilisée dans les statistiques mathématiques pour modéliser les composantes de tendance des séries chronologiques. Une série chronologique est, en fait, une série de nombres qui dépendent du temps. Par exemple, la température quotidienne moyenne de l'année écoulée ou le revenu mensuel de l'entreprise. L'ordre du polynôme simulé est évalué par des méthodes spéciales, par exemple, par le critère de série. L'objectif de construire un modèle de régression polynomiale dans le domaine des séries chronologiques est toujours le même: la prévision.
Pour commencer, nous considérons le problème de la régression polynomiale de manière générale. Tout raisonnement est basé sur une généralisation du raisonnement dans les problèmes de régression linéaire et parabolique. Après ces considérations, je passerai à un cas spécial - la considération de ce modèle pour les séries chronologiques.
Soit deux séries d'observations données (variable indépendante) et (variable dépendante) . L'équation polynomiale a la forme
où
- paramètres de ce polynôme,
. Parmi eux
- un membre gratuit. Trouvons les paramètres des moindres carrés (OLS)
compte tenu de la régression.
Par analogie avec la régression linéaire, OLS est également basé sur la minimisation de l'expression suivante:
Ici - valeurs théoriques qui sont les valeurs du polynôme (1) aux points . En substituant (1) à (2), on obtient
Basé sur la condition nécessaire pour l'extrémum de la fonction les variables nous assimilons ses dérivées partielles à zéro, c'est-à-dire
En divisant les côtés gauche et droit de chaque égalité par 2, nous révélons la deuxième somme:
En ouvrant les crochets, nous transférons dans chacun
expression, le dernier terme avec
vers la droite et diviser les deux côtés par
. En conséquence, nous avons
expressions formant un système d'équations normales linéaires pour
. Il a la forme suivante:
\ left \ {\ begin {array} {l} b_0 + b_1 \ overline x + b_2 \ overline {x ^ 2} + \ dots + b_k \ overline {x ^ k} = \ overline y \\ b_0 \ overline x + b_1 \ overline {x ^ 2} + b_2 \ overline {x ^ 3} + \ dots + b_k \ overline {x ^ {k + 1}} = \ overline {xy} \\ b_0 \ overline {x ^ 2} + b_1 \ overline {x ^ 3} + b_2 \ overline {x ^ 4} + \ dots + b_k \ overline {x ^ {k + 2}} = \ overline {x ^ 2y} \\ \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \ ldots \\ b_0 \ overline {x ^ k} + b_1 \ overline {x ^ {k + 1}} + b_2 \ overline {x ^ {k + 2}} + \ dots + b_k \ overline {x ^ {2k}} = \ overline {x ^ ky} \ end {array} \ right. \ \ \ \ \ (3)
Vous pouvez réécrire le système (3) sous forme matricielle: où
A = \ left (\ begin {array} {ccccc} 1 & \ overline x & \ overline {x ^ 2} & \ ldots & \ overline {x ^ k} \\ \ overline x & \ overline {x ^ 2 } & \ overline {x ^ 3} & \ ldots & \ overline {x ^ {k + 1}} \\ \ overline {x ^ 2} & \ overline {x ^ 3} & \ overline {x ^ 4} & \ ldots & \ overline {x ^ {k + 2}} \\ \ vdots & \ vdots & \ vdots & \ ddots & \ vdots \\ \ overline {x ^ k} & \ overline {x ^ {k + 1} } & \ overline {x ^ {k + 2}} & \ ldots & \ overline {x ^ {2k}} \ end {array} \ right), \ \ B = \ left (\ begin {array} {c} b_0 \\ b_1 \\ b_2 \\\ vdots \\ b_k \ end {array} \ right), \ \ C = \ left (\ begin {array} {c} \ overline y \\\ overline {xy} \\ \ overline {x ^ 2y} \\\ vdots \\\ overline {x ^ ky} \ end {array} \ right).
Passons maintenant à l'application des faits ci-dessus dans le cas des séries chronologiques. Que les séries chronologiques soient données où . Il est nécessaire de construire une tendance d'ordre polynomial , qui se rapproche le plus précisément possible de la série temporelle donnée. Comme variable indépendante nous prendrons basé sur la définition d'une série chronologique. Ces X sont une série de nombres naturels qui dénotent une période de temps. En tant que les valeurs des séries temporelles sont prises . On voit que les valeurs des éléments matrices système indépendant de . Comme dans le cas général, évidemment,
puis dans le cas de séries chronologiques
où
Articles vecteurs matriciels de termes libres généralement obtenu comme
Et dans le cas des séries chronologiques
où
Ainsi, après avoir résolu le système (3), nous pouvons trouver les paramètres souhaités de la tendance polynomiale
Pour remplir les matrices du système et le résoudre, l'une des méthodes numériques peut être utilisée lors de la modélisation d'une tendance sur un ordinateur. Dans ce cas, le résultat du calcul sera assez précis.
En conséquence, la composante tendance prendra la forme:
Il convient également de noter que la composante de tendance simulée
, déterminé non seulement pour les périodes actuelles
, mais aussi pour les périodes futures
.
Je remarque tout de suite que la régression polynomiale ne modélise que la composante tendance de la série chronologique. Un modèle de série chronologique complet implique également d'autres composants, ce qui dépasse le cadre de cet article.
Dans la pratique, je n'ai personnellement pas vu de séries chronologiques avec un ordre de tendance polynomial supérieur à 2. Ceci explique la prévalence des modèles de régression linéaire et prabolique comme cas particuliers de polynôme.