Bref historique: ma dernière note décrivait une approche de stockage et de récupération de données sur laquelle vous pouvez créer un concepteur d'applications - une alternative aux plates-formes de développement modernes, mais sans avoir besoin de programmation. Cette invention peut potentiellement transformer le monde entier de l'informatique, telle que nous la connaissons.
J'ai effectué une recherche de brevets et rendu public le résultat pour m'assurer qu'il n'y avait pas d'homologues architecturaux. Puis il a reçu un brevet et a publié un article avec des explications, qui contenait plusieurs remarques audacieuses sur les volumes, l'évolutivité, la vitesse et d'autres choses.
Bien sûr, l'article a soulevé un grand nombre de questions qui doivent être traitées séparément: la différence avec les solutions existantes et une analyse comparative des performances et des plans de création de requêtes de base de données. Et répondez également à la question: de quoi s'agit-il et pourquoi?
Étant donné que le sujet est douloureux pour beaucoup et que les avantages revendiqués sont très ambitieux, les commentaires ont été plutôt durs. La raison est compréhensible - dans l'article, tout le monde voit immédiatement «EAV», sur lequel les personnes sérieuses écrivent encore des recherches, tandis que le problème de performance n'est généralement pas résoluble. Comme j'ai été aimablement informé dans les commentaires, l'EAV a un tas de lacunes, c'est bien connu, et quiconque réclame une solution finale aux problèmes de l'EAV doit obtenir de généreux coups de pied dans le karma afin de revenir à la raison.
Il n'y a qu'une subtilité: l'article ne présente pas l'EAV en tant que tel
La question la plus populaire était: "en quoi est-ce différent de l'EAV, du KV, de Magento ...".
Il semblerait que les différences résident dans tout ce qui ne rentre pas dans les propriétés listées:
- La structure - dans le tableau sont 5 colonnes et 3 index
- Méthode d'échantillonnage - un tableau décrit les types de données et leurs relations (métadonnées) et les données elles-mêmes
Mais une telle réponse ne convenait pas à beaucoup de lecteurs, je vais donc essayer de l'expliquer plus en détail.
La structure décrite utilise le répertoire EAV, complété par l'attribut ID, car tout attribut est également une entité indépendante qui peut avoir ses propres attributs, ainsi que servir de valeur de référence. Autrement dit, la structure est conçue non seulement comme une référence EAV, pourquoi, en fait, je ne peux pas l'appeler EAV.
Plus important encore, l'EAV ne peut pas être une solution autosuffisante, c'est juste un guide, l'un des éléments du système. Je parle d'une solution complète et autonome, qui ne nécessite rien de plus pour créer une structure, des données et les gérer.
Pour expliquer en quoi la solution diffère de Datomic, Magento et des dizaines de milliers d'autres solutions et produits, vous devrez les comparer des dizaines de milliers de fois. Par conséquent, je me risquerai à proposer une technique simple par laquelle, en quelques minutes, vous pourrez faire une comparaison avec n'importe quel système et identifier la différence, le cas échéant.
Il est nécessaire de vérifier le respect des conditions suivantes pour le système comparé:
1. Toutes les données sont stockées dans une table (voir également la clause 3.) contenant au moins les champs suivants: ID, ID parent, ID type, valeur
2. Pour le tableau, au moins les indices suivants sont construits: ID; Tapez ID + valeur; ID parent + ID type.
3. Il peut y avoir plusieurs tables, mais toutes contiennent la structure minimale de l'élément 1 et des index, qui diffèrent par le type du champ Valeur
4. Le tableau contient une description des types de données.
5. Le tableau contient une description des détails des types de données (à partir de l'ensemble des types qui y sont décrits)
6. Le tableau contient des objets de données avec une référence à leur type (à partir de l'ensemble des types qui y sont décrits)
7. Le tableau contient les détails des objets avec un lien vers le parent et le type
8. La sélection des objets se fait avec l'indication obligatoire du type d'objet
9. La sélection des détails de l'objet se fait avec l'indication obligatoire du parent et du type
10. La sélection de l'objet par ses détails se fait avec l'indication obligatoire du type de détails
11. (facultatif) Les objets sont connectés via les détails contenant comme type d'ID de l'objet lié
Si toutes les conditions préalables sont remplies, vous disposez d'un système qui correspond à la description des notes discutées ici.
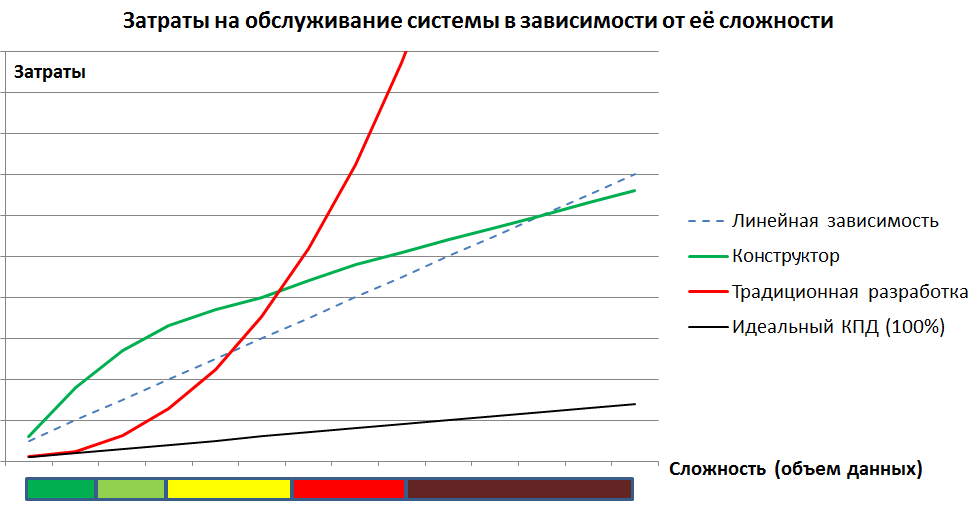
Des problèmes plus importants jettent un doute sur l'énoncé des performances du système à mesure que le volume augmente.
Pour les tests comparatifs, deux bases de données identiques ont été réalisées, dont l'une a été construite dans les tableaux habituels de la base de données relationnelle, et l'autre en utilisant la méthodologie déclarée. Voici les résultats des tests de deux bases de données avec des textes de requête, des mesures de temps et l'analyse des plans d'exécution.
Dans les commentaires sur le dernier message, une structure simple de données connexes a été proposée , adaptée aux tests. Je l'ai pris comme base: il s'agit d'une liste de 1 048 552 livres de 142 654 auteurs générés à partir de données aléatoires.
La structure ressemble à ceci (cliquez pour voir)CREATE TABLE `author` (
`id` int(11) NOT NULL,
`author` varchar(128) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `books` (
`id` int(8) NOT NULL,
`name` varchar(256) NOT NULL,
`author` int(8) NOT NULL,
`pages` int(4) NOT NULL,
`year` int(4) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `author`
ADD PRIMARY KEY (`id`),
ADD KEY `author` (`author`);
ALTER TABLE `books`
ADD PRIMARY KEY (`id`),
ADD KEY `name` (`name`(255)),
ADD KEY `author` (`author`);
ALTER TABLE `books`
ADD CONSTRAINT `books_ibfk_1` FOREIGN KEY (`author`) REFERENCES `author` (`id`);
:

: 1 @2.4GHz, 1GB RAM, SSD.
207 289 .
, , .
: , . .
:
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE author.author LIKE '%aro%' AND books.author=author.id
LIMIT 1000
( ):

«aro», 465 .
193 :

:

266 :

, 266 6 ( , - , ). 264 .
:
SELECT a225.val v1_225,a217.val v2_217,a223.val v3_217,a219.val v4_217
FROM test a225
LEFT JOIN (test r217 JOIN test a217 USE INDEX (PRIMARY)) ON r217.up=a217.id AND a225.id=r217.t AND a217.t=217
LEFT JOIN test a223 ON a223.up=a217.id AND a223.t=223
LEFT JOIN test a219 ON a219.up=a217.id AND a219.t=219
WHERE a225.up!=0 AND a225.t=225 AND a225.val LIKE '%aro%'
LIMIT 1000
:

, , «», , , .
, , ( ).
, , . .
, :
, . . Magento, , .
,
, , .
:
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE author.author LIKE 'lac%' AND books.author=author.id
LIMIT 1000
3.1 :

8.4 , 6 :

, , .
:

:

, ( ):
, , . , .
—
: . :
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE books.name LIKE '% %' AND books.author=author.id
LIMIT 50
:

: 148 2490 . 17 !
, , , , . :

: 181 25 . , , 7 .
:
SELECT author.author, books.name, books.pages, books.year
FROM books INNER JOIN author ON books.author=author.id
WHERE books.name LIKE '% %'
LIMIT 50
: 62 47 . . , , . , .
, , , .
, , , . , .
: () . :
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE books.pages=150 AND books.year=1972 AND books.author=author.id
LIMIT 50
:

, 30 :


, , . .
, : , .
: DDL DML .