Bonjour, Habr! Nous continuons notre série expérimentale d'articles, en observant que vous pouvez en temps réel influencer le processus de création d'un jeu sur UWP. Aujourd'hui, nous allons parler de la question «Où stocker les données?» Qui se pose constamment dans les rangs des développeurs. Rejoignez-nous et partagez vos réflexions dans les commentaires!
 Je donne la parole à l'auteur, Alexei Plotnikov .
Je donne la parole à l'auteur, Alexei Plotnikov .Dans un article précédent, j'ai soulevé la question de la synchronisation pratique des données utilisateur entre les appareils et tout d'abord j'ai résolu le problème de son identification, mais c'est la plus petite fraction de ce qui reste à faire pour atteindre les objectifs.
Un problème beaucoup plus complexe est la manière, et surtout, l'emplacement des données utilisateur et, grâce aux efforts de Microsoft, lorsqu'il pose une telle question, la première chose qui vient à l'esprit est
Microsoft Azure . La plateforme cloud Azure comprend une gamme de services si vaste qu'il semble qu'aucune tâche ne puisse être résolue avec son aide. Que ce soit vrai ou non, je ne peux pas en juger, mais ma tâche est certainement à la portée de cette plate-forme. Cependant, tout d'abord.
Nous commençons petit - qu'est-ce qu'un cloud? Pour la première fois, j'ai entendu parler du cloud en 2012, puis l'expression «cloud computing» a été le plus souvent utilisée. L'idée initiale de ces calculs était de répartir le travail informatique entre différents appareils distants les uns des autres. Particulièrement impressionnant a parlé de l'avenir, dans lequel même les tâches les plus difficiles seront traitées en quelques instants en raison du fait que les calculs seront répartis entre tous les ordinateurs du monde.
Dans la pratique, tout se résumait à des centres de données disséminés dans le monde entier et fournissant leur puissance de calcul aux consommateurs, et le concept initial n'était que la distribution entre les machines à l'intérieur du centre de données et entre les centres de données eux-mêmes (le plus souvent dans la même région).
Sur la base de ce qui précède, nous pouvons supposer que lorsque vous entendez le mot "cloud", vous pouvez le percevoir comme un "hébergement" plus familier, à la seule différence que la puissance du cloud peut être étendue sans effort supplémentaire de votre part.
La deuxième question que vous pourriez vous poser est pourquoi Azure? «Comme il s'agit d'un article sur le blog Microsoft, l'auteur ne parlera que de ses produits», dites-vous, et vous vous tromperez. Les raisons d'utiliser Azure sont beaucoup plus courantes - puisqu'il s'agit d'un produit Microsoft, il présente le degré d'intégration le plus élevé possible avec leurs autres produits, à l'aide duquel mon application est en cours de développement.
Cependant, je note que la société met tout en œuvre pour rendre l'utilisation d'Azure attrayante pour les développeurs pour Android ou iOS. Eh bien, le dernier problème, mais non le moindre, est le coût d'utilisation du cloud. Depuis que je suis titulaire d'un abonnement BizSpark, j'ai obtenu un prêt mensuel pour un sac avec des intérêts supérieurs à la couverture de mes besoins en cloud, bien que les conditions fournies gratuitement peuvent également couvrir la plupart des besoins d'un développeur privé.
Passons maintenant à la sélection directe d'un mécanisme de synchronisation et de stockage des données. Je ne vais pas être rusé, en tant que personne autodidacte, je dois souvent faire face à des technologies dont je n'ai aucune idée avant de connaître UWP, j'ai résolu des problèmes similaires en utilisant des bases de données SQL.
Cependant, UWP n'a pas les outils pour travailler avec les SGBD SQL classiques, et SQLite est proposé comme alternative, et, après avoir commencé son étude, j'ai découvert qu'une telle base de données est intégrée, ce qui convient pour un stockage et une utilisation pratiques des données locales, mais ne convient absolument pas pour le placement de données dans le stockage à distance. Déjà en train d'écrire cet article, lorsque la bonne technologie a été choisie, je suis tombé sur l'une des solutions Azure dans le domaine du développement d'applications mobiles, qui vous permet de synchroniser les données de la table SQLite entre les appareils, mais après mûre réflexion, je suis resté sur le choix initial.
Soit dit en passant, faire le choix initial n'a pas été difficile, car Microsoft a poliment proposé une liste de technologies auxquelles le développeur UWP devrait probablement faire face. Dans les dernières versions de Visual Studio, lors de la création d'un nouveau projet UWP, vous verrez une page avec des recommandations pour commencer, où l'un des liens indique «Ajout d'un service recommandé». En cliquant sur ce lien, l'onglet «Connecter le service» s'ouvre et nous y voyons déjà l'option «Stockage cloud avec service de stockage Azure».
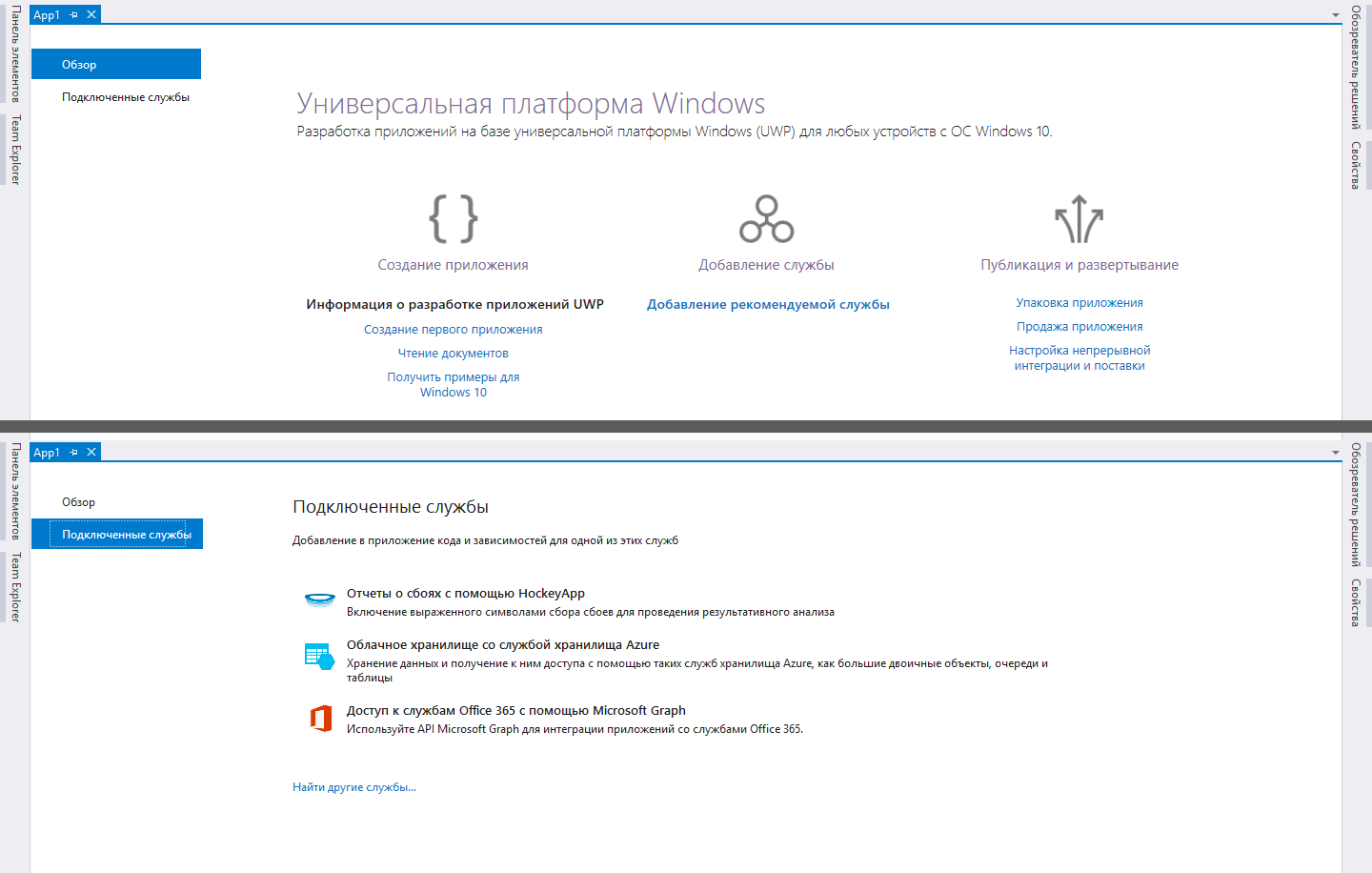
L'intuition suggère que c'est exactement ce dont vous avez besoin, j'ai donc décidé de me concentrer sur une étude approfondie de cette question en vue d'une utilisation ultérieure dans le projet.
Le stockage cloud est un ensemble de plusieurs produits pour différentes tâches, qui peuvent être lus
ici , mais je m'intéressais principalement au stockage de table, qui s'est avéré être la base de données NoSQL.
NoSQL est une base de données sans schéma, c'est-à-dire dans laquelle la table n'a pas besoin d'être structurée à l'avance. En fait, la table dans ce cas n'est qu'une partie du chemin d'accès à ce qu'on appelle la section, ce qui signifie qu'une seule table peut contenir des lignes, par exemple, avec trois et cinq colonnes à la fois. Pour bien comprendre les fonctionnalités du stockage de table, je vous conseille de lire attentivement le
manuel , mais je considérerai ce sujet de mon point de vue banal, car au final le matériel s'adresse aux débutants, qui je suis dans ce sujet.
Pour commencer, voyons comment créer une table NoSQL:1. Enregistrez un compte Azure
gratuit . Si vous avez un abonnement MSDN ou BizSpark et qu'il est déjà activé dans Azure, vous pouvez ignorer cette étape. Un compte gratuit vous donne un prêt de 200 $ pour le premier mois, puis un accès gratuit à une certaine quantité de ressources de la plupart des services Azure. Traduit dans un langage compréhensible, tout est fait de manière à ce que vous n'ayez pas à payer jusqu'à ce que votre produit gagne suffisamment pour couvrir les dépenses, sans parler de l'utilisation d'Azure pour l'autoformation.
Mais même si vous franchissez le seuil gratuit, les prix d'un stockage de table sont beaucoup plus fidèles que pour une quantité similaire de bases de données SQL. Par exemple, au moment de la rédaction de cet article, j'ai créé jusqu'à présent deux tableaux avec une seule entrée. Pendant 18 jours de la période de référence, je me suis tourné vers elle en moyenne 20 à 30 fois par jour et 2 kopecks ont été radiés du compte de crédit pour cette période. En augmentant ces coûts pour le volume prévu, j'ai réalisé qu'ils étaient plus que couverts par les revenus potentiels de l'application.
2. Maintenant que vous avez un compte dans Azure, nous procédons à la création d'un compte de stockage.
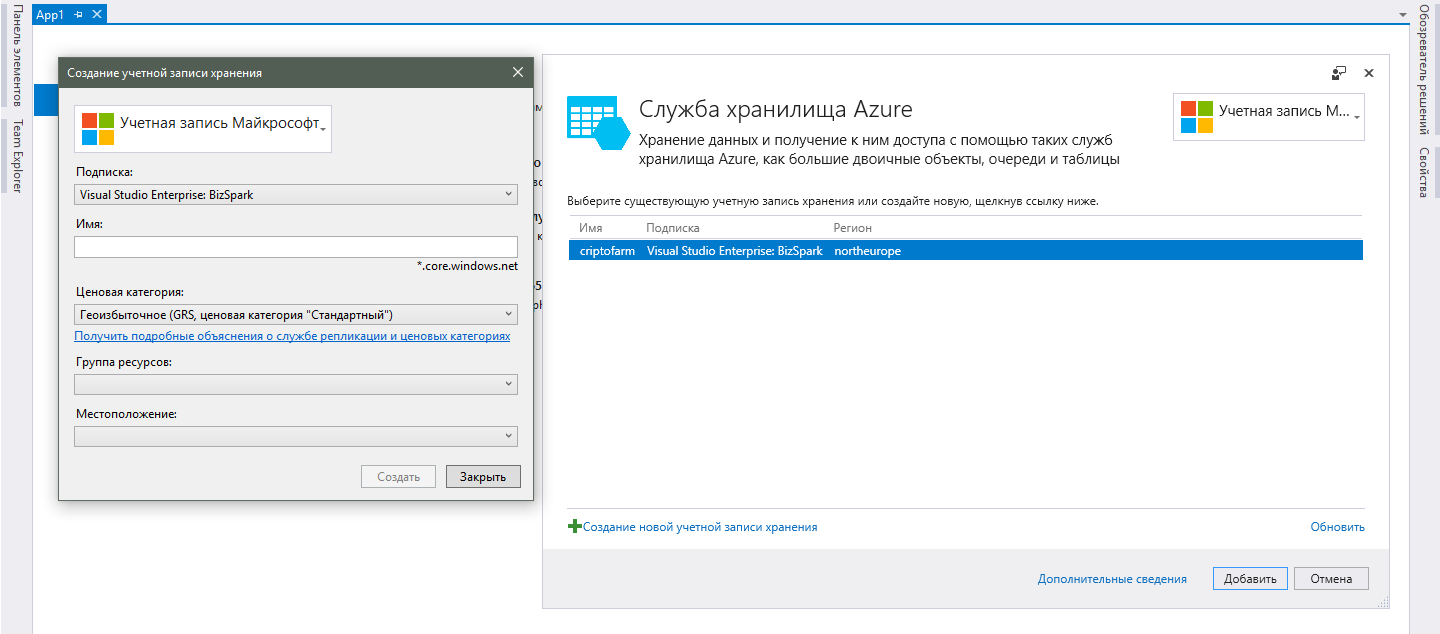
Vous pouvez tout faire à partir de la même page de connexion aux services Visual Studio, que j'ai décrite ci-dessus. Si vous avez soudainement fermé cette page, vous pouvez l'ouvrir en double-cliquant sur «Services connectés» dans l'Explorateur de solutions. Après avoir sélectionné le service requis, une fenêtre avec les comptes de stockage disponibles s'ouvrira et, pour en ajouter un nouveau, cliquez sur le bouton correspondant.
Dans la nouvelle fenêtre, vous devrez effectuer les étapes suivantes:- Pour commencer, vous devrez vous connecter avec votre compte Microsoft. Vous devez utiliser le compte auquel vos abonnements sont liés ou un compte Azure gratuit.
- Une fois connecté à votre compte, votre abonnement (a) apparaîtra dans le champ "Abonnement". Tout est simple avec le choix, donc les commentaires sont superflus.
- Dans le champ "Nom", indiquez le nom souhaité du service de stockage. Étant donné qu'il s'agit également du nom de domaine du service, il doit être unique dans tous les comptes disponibles dans Azure, et pas seulement dans le vôtre.
- Le champ «Catégorie de prix» vous demandera de comprendre les différences entre une plate-forme cloud et l'hébergement conventionnel, car en cliquant sur le lien sous le champ, vous pouvez voir une liste de prix, mais pas une explication intelligible, qui vous donne chaque option. Bien sûr, dans la nature des liens annexes, vous pouvez trouver des informations complètes sur toutes ces abréviations comme GRS et LRS, mais cela est superflu pour le développeur moyen. Il suffit de comprendre que plus le tarif est cher, plus les centres de données seront impliqués dans le traitement et le stockage de vos données et plus la probabilité de leur sécurité est élevée. Pour un petit projet, le taux LRS le plus bas est correct.
- Un «groupe de ressources» est une combinaison de plusieurs services Azure pour une seule gestion. Dans notre cas, créez-en un nouveau, attribuez un nom convivial et continuez.
- La dernière chose à choisir est le «lieu» de votre service. Par emplacement, on entend l'emplacement réel des centres de données qui seront chargés de travailler avec nos données. Veuillez noter que je parle au pluriel, car dans une région il peut y avoir plusieurs centres de données et le travail peut être réparti entre eux (au cas où vous choisiriez une catégorie de prix conseillée). Choisissez celui qui est le plus proche de votre base d'utilisateurs principale. Cependant, si vous prévoyez de vous développer à l'échelle du monde entier et que vous avez besoin d'une réponse maximale partout dans le monde, personne ne vous dérange pour chaque version régionale de l'application pour créer un compte de stockage distinct et implémenter la synchronisation des données entre eux. C'est un haut niveau d'extensibilité qui est le principal avantage du cloud.
3. Après avoir créé le compte de stockage, il sera ajouté à la liste et vous pourrez continuer en cliquant sur le bouton "Ajouter". Le résultat de cette action sera l'ajout d'un package NuGet pour travailler avec Azure au projet et l'enregistrement de la chaîne de connexion dans le fichier app.config du projet.
Malheureusement, il est impossible de travailler avec des valeurs de ce fichier dans UWP (ou peut-être avec de terribles béquilles), il vous suffit donc de copier la chaîne de connexion vers le service de stockage à partir de là vers un emplacement pratique dans le projet et passez à l'étape suivante.
4. Il reste maintenant à créer une table et à commencer à travailler avec elle. Et c'est ici que commence le travail individuel, en fonction directe des tâches.
Le fait est qu'avant de commencer à créer des tables, vous devez réfléchir soigneusement à l'architecture de stockage de vos données. Travailler avec le stockage de la table est si pratique que la création d'une nouvelle table directement à partir du code ne prend que quelques lignes, et avec une telle commodité, il y a un désir naturel d'allouer une table distincte pour chaque utilisateur, car à la fin la tâche consiste à synchroniser les données entre ses appareils. Cependant, lorsque vous travaillez avec une technologie inconnue, vous ne devez pas prendre de décisions hâtives et vous devez soigneusement peser le pour et le contre. Un
article spécial
du manuel peut aider à prendre la bonne décision, mais préparez-vous à le relire plusieurs fois, car il est très difficile d'apprendre toutes les données tout de suite, surtout en tenant compte de la masse des nouveaux termes.
Je vais continuer l'histoire en tenant compte du fait que vous avez toujours lu le manuel et compris certaines des fonctionnalités de l'utilisation du stockage de table. Par exemple, j'ai réalisé que conceptuellement une table n'est pas une sorte d'unité isolée et est plutôt un endroit pour un regroupement logique d'enregistrements. Ceci est facile à comprendre si vous présentez le tableau comme un dossier dans lequel vous stockez des fichiers de données. Un dossier en lui-même ne prend pas d'espace et ne fait pas partie intégrante des fichiers, mais définit simplement une partie du chemin d'accès aux fichiers qui sont logiques, mais pas nécessaires, à enregistrer dans ce dossier.
La conclusion est assez simple - personne ne prend la peine de stocker les paramètres de tous les utilisateurs dans une table, l'essentiel est que la paire de valeurs dans les colonnes PartitionKey et RowKey est unique à l'intérieur de la table. Ceci est à nouveau implémenté dans mon projet, car l'ID utilisateur agira comme PartitionKey, et par exemple, la chaîne «UserName» comme RowKey, ce qui nous permettra de déterminer l'enregistrement unique dans lequel le nom d'utilisateur est stocké. Mais comme je l'ai dit ci-dessus, nous devons peser tous les avantages et les inconvénients, alors pesons:
- "Pour" une table séparée pour les données de chaque utilisateur est la commodité de percevoir la structure des données. Si nous prenons la table comme un dossier avec des fichiers, il est logique que tous les fichiers d'un utilisateur se trouvent dans le même dossier et il est plus courant de travailler avec une telle architecture.
- Tous les autres facteurs sont «contre» un tableau distinct. Données utilisateur dans une table distincte - cette précision est pratique jusqu'à ce que le nombre de ces tables soit dans les milliers. Étant donné que le compte de stockage est un niveau supérieur au-dessus de la table, aucun autre regroupement n'est fourni pour eux.
Compte tenu de la base d'utilisateurs potentiels, nous risquons de nous noyer dans des milliers de tables individuelles, de perdre celles qui ont une valeur prioritaire. Dans le même temps, le stockage des paramètres de tous les utilisateurs dans un seul tableau simplifie l'administration et le travail avec les données afin de collecter des informations statistiques ou de mettre en œuvre des fonctions sociales.
De plus, le faible coût d'utilisation du stockage de table vous permet de dupliquer toutes les données dans des tables distinctes, selon la logique requise. En particulier, je prévois de créer un tableau supplémentaire avec le nom d'utilisateur, un lien vers l'avatar et une indication d'appartenance au pays, qui sera utilisé pour les tableaux de notation ou d'autres fonctions sociales qui peuvent être ajoutées à l'application.
Donc, lorsque vous avez compris la structure de stockage des données, ajoutons enfin une nouvelle table. Puisque nous avons refusé de le créer au niveau du code, deux options restent: via le portail Web Azure ou en utilisant l'outil spécial Microsoft Azure Storage Explorer, qui peut être téléchargé à partir de storageexplorer.com. Dans les deux cas, il est nécessaire de sélectionner le compte de stockage souhaité et dans la section "Service Tables / Tables" de sélectionner "+ Table / Créer une table". Dans la boîte de dialogue qui apparaît, entrez le nom souhaité et validez les modifications.
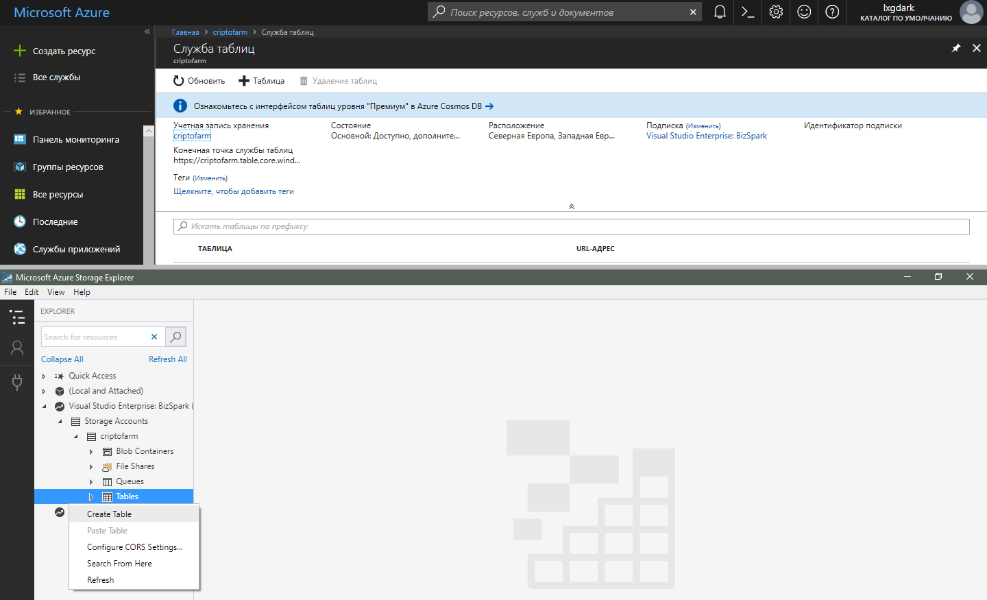
Après cela, vous pouvez travailler avec la nouvelle table du code sans aucun problème.
Les principales opérations que je vais effectuer avec la table sont l'insertion et l'extraction de lignes, appelées «entités» dans la terminologie de stockage de la table. Un tel terme est plus facile à comprendre lorsque vous réalisez que pour insérer et récupérer une entité, vous devrez lui mapper une classe héritée de TableEntity de Microsoft.WindowsAzure.Storage.Table. La classe successeur contiendra déjà certains champs obligatoires, tels que, par exemple, PartitionKey (nom de section) et RowKey (nom de ligne), et ces champs que nous implémentons indépendamment seront des colonnes dans la ligne (propriétés d'entité).
Prenons un exemple de tableau dans lequel une liste de tous les joueurs avec leur nom, leur avatar et leur appartenance au pays sera stockée.
: Imports Microsoft.WindowsAzure.Storage Imports Microsoft.WindowsAzure.Storage.Table
J'ai décidé de mettre les méthodes de travail avec la table dans une classe séparée pour la commodité de travailler à partir de différents points de l'application. Créez-le et ajoutez immédiatement les constantes précédemment connues:
Public Class AzureWorker Private Const AzureStorageConnectionString As String = " , app.config" Private Const GamerListTableNameString As String = "GamerList" ' … End Class
Maintenant, nous devons créer une classe que nous mapperons à l'entité (ligne) à l'intérieur du tableau:
Private Class GamerListClodTableDataClass Inherits TableEntity Public Const RowKeyValue As String = "UserID" Public Sub New () RowKey = RowKeyValue End Sub Public Property UserName As String = "" Public Property UserountryID As String = "" Public Property UserAvatar As String = "" End Class
La classe à mapper doit être héritée de TableEntity et avoir des champs pour les données que nous prévoyons de placer dans la table. Notez que la définition de valeurs pour une RowKey ou une PartitionKey au niveau de la classe n'est pas nécessaire, mais dans mon cas, la RowKey est définie car elle est immuable quelle que soit l'autre entrée.
Mais, comme à ce stade vous n'avez probablement pas complètement compris l'essence de travailler avec le stockage de table, je vais expliquer la logique établie à ce stade. Le moyen le plus rapide de travailler avec une table consiste à interroger l'entité par le nom de la chaîne et le nom de la section, vous devez donc connaître ces données à l'avance. De plus, la combinaison de PartitionKey et RowKey doit être unique dans la table, ce qui signifie qu'il est logique d'écrire un ID utilisateur unique dans l'une de ces clés et d'attribuer à la deuxième clé un nom que nous connaîtrons toujours. C'est exactement ce qui se fait dans la classe GamerListClodTableDataClass.
La dernière étape préparatoire avant les requêtes directes sur la table est la création de son objet dans une fonction distincte:
Private Shared Function GetCloudTable(tableName As String) As CloudTable Dim storageAccount As CloudStorageAccount = CloudStorageAccount.Parse(AzureStorageConnectionString) Dim tableClient As CloudTableClient = storageAccount.CreateCloudTableClient() Dim table As CloudTable = tableClient.GetTableReference(tableName) Return table End Function
Ceci est fait pour ne pas dupliquer le code chaque fois que nous voulons lire ou écrire des données dans la table. Veuillez noter que ce code ne fait pas de requêtes directes sur le cloud et sera exécuté sans problème en l'absence de connexion. Il ne fait que créer étape par étape un objet table à partir de données existantes, telles que la chaîne de connexion de stockage et le nom de la table.
Enfin, passons à l'utilisation directe de la table et commençons par enregistrer les données utilisateur actuelles:
Public Shared Async Function SavedOrUpdateUserData(u As UserManager) As Task(Of Boolean) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim UserDataClodTableData As New GamerListClodTableDataClass With {.PartitionKey = u.UserId, .UserName = u.UserName.Trim, .UserountryID = u.UserountryID, .UserAvatar = "https://apis.live.net/v5.0/" & u.UserId & "/picture"} Dim insertOperation As TableOperation = TableOperation.InsertOrReplace(UserDataClodTableData) Await table.ExecuteAsync(insertOperation) Return True End If Catch ex As Exception End Try Return False End Function
La requête est effectuée en tant que fonction asynchrone afin que le code appelant puisse obtenir le résultat de l'exécution (True en cas de succès et False en cas d'échec). En outre, un paramètre du type UserManager est transmis à la fonction, qui est une référence à la classe avec des données utilisateur. Nous avons créé une telle classe dans un article précédent, à la seule différence que dans cette version, il existe un champ UserountryID qui stocke des données sur le pays de l'utilisateur.
Pour les requêtes sur la table, vous devez d'abord créer son objet en utilisant la chaîne de connexion au référentiel et le nom de la table (nous avons mis ce processus dans une fonction distincte plus tôt). Ensuite, vous devez vérifier l'existence de la table et, bien que nous soyons sûrs que nous ayons une table avec ce nom, une erreur peut se produire, par exemple, en raison d'un manque de connectivité réseau ou en raison d'une défaillance dans le cloud (c'est pourquoi ce code est placé dans le Try / Catch). Ensuite, avant d'écrire dans la table, vous devez créer une instance de la classe UserDataClodTableData et affecter la valeur requise à ses champs, puis seulement créer l'opération InsertOrReplace. Comme vous pouvez le deviner à partir du nom de l'opération, il insérera une nouvelle ligne dans la table si des lignes avec la même paire de PartitionKey et RowKey n'existent pas dans la table et remplacera les données si une telle ligne existe déjà. Eh bien, l'équipe finale ExecuteAsync, en fait, effectuera l'action prévue du côté du stockage de la table.
La lecture des données d'une table est aussi simple que leur écriture. Demandons par exemple un nom d'utilisateur:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim retrieveOperation As TableOperation = TableOperation.Retrieve(Of GamerListClodTableDataClass)(id, GamerListClodTableDataClass.RowKeyValue) Dim retrievedResult As TableResult = Await table.ExecuteAsync(retrieveOperation) If retrievedResult.Result IsNot Nothing Then Return CType(retrievedResult.Result, GamerListClodTableDataClass).UserName End If End If Catch ex As Exception End Try Return "" End Function
Ce code ne diffère presque pas du précédent et commence également par créer un objet table et vérifier son existence. De plus, comme en enregistrement, nous créons une opération, mais cette fois une opération d'extraction, qui nécessite l'indication de PartitionKey et RowKey. Après cela, nous extrayons le résultat à l'aide d'ExecuteAsync et travaillons avec l'objet résultant du type TableResult, ce qui revient en fait à convertir la propriété Result en type de classe en cours de mappage et en extrayant le nom d'utilisateur.
Travailler avec une table n'est pas limité aux opérations de lecture et d'écriture et prend en charge de nombreux scripts différents. Par exemple, vous pouvez créer une requête qui extraira toutes les entités avec la clé de partition spécifiée ou toutes les entités qui ont le champ spécifié, mais il est important de se rappeler la vitesse de ces opérations, ainsi que la quantité de données qui seront transmises sur le réseau.
L'exemple ci-dessus est le plus optimal du point de vue de la vitesse de requête, car le système d'adressage trouvera très probablement une entité le long du chemin "nom de stockage \ nom de table \ PartitionKey + RowKey", cependant, pour obtenir un seul nom, nous chargeons l'entité entière dans son ensemble, ce qui n'est pas avantageux sur la quantité de données transférées.
Voici un code de fonction modifié tenant compte de l'optimisation maximale des requêtes:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim projectionQuery As TableQuery(Of DynamicTableEntity) = New TableQuery(Of DynamicTableEntity)().Where(TableQuery.CombineFilters(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, id), "and", TableQuery.GenerateFilterCondition("RowKey", QueryComparisons.Equal, GamerListClodTableDataClass.RowKeyValue))).Select({"UserName"}) Dim resolver As EntityResolver(Of String) = Function(pk, rk, ts, props, etag) Return props("UserName").StringValue End Function Dim result As TableQuerySegment(Of String) = Await table.ExecuteQuerySegmentedAsync(projectionQuery, resolver, Nothing) If result.Count > 0 Then Return result(0) End If End If Catch ex As Exception End Try Return "" End Function
Au lieu de créer un objet opération, dans ce code, nous créons un objet requête qui contient plusieurs méthodes pour déterminer ce qui doit être obtenu en conséquence. La méthode Where crée un filtre qui indique la nécessité de renvoyer uniquement les lignes pour lesquelles PartitionKey et RowKey sont égales aux valeurs spécifiées, et la prochaine sélection indique que seule la colonne UserName doit être sélectionnée.
Avec une telle requête, cela n'a aucun sens de comparer le résultat avec n'importe quelle classe, par conséquent, l'IDictionary est utilisé comme valeur de retour, où la clé est le nom de la colonne et la valeur est son contenu. Étant donné que la fonction ExecuteQuerySegmentedAsync ne sait pas quel résultat de son exécution sera obtenu, il est possible (et dans ce cas nécessaire) de passer un délégué EntityResolver, qui fait référence à une fonction qui prend la valeur souhaitée dans le dictionnaire. Le résultat de tout cela devient TableQuerySegment dans le premier index dont le nom de l'utilisateur demandé est stocké.
En général, l'utilisation de requêtes au lieu de l'opération d'extraction de base vous permet d'étendre considérablement les possibilités de travailler avec une table, mais soyez prudent, car contrairement au SQL classique, ici la vitesse de traitement des requêtes dépend directement de ses paramètres. Personne ne vous dérange pour exécuter une requête afin de récupérer tous les enregistrements utilisateur dont les noms sont égaux à celui donné, mais une telle requête sera plus longue que son homologue en SQL. Pour l'apprendre, je vous renvoie une fois de plus au guide de conception de table auquel j'ai fait référence ci-dessus, et je vous recommande également d'étudier l'
article , qui fournit des exemples sur l'utilisation du stockage de table.
Important! Les articles de lien utilisent du code pour les applications .NET classiques et sont différents de l'implémentation UWP. Heureusement, cette différence n'est pas significative et les analogues sont intuitifs (le plus souvent, les différences sont dans le préfixe Async).En conclusion, je partagerai les résultats de l'utilisation du stockage Azure dans mon projet pour le moment. Au premier démarrage, après avoir reçu l'ID utilisateur et téléchargé les données depuis le Live ID, je lui propose de choisir un alias (pseudo) au cas où le nom stocké dans le profil ne lui conviendrait pas. Ensuite, le surnom entré est enregistré dans la classe UserManager au lieu de la norme, et toutes ces données sont enregistrées dans la table GamerList. Au prochain démarrage, l'ID utilisateur est reçu en arrière-plan et un alias est demandé au référentiel. En conséquence, l'utilisateur voit son surnom dans le jeu, et non le nom du profil standard.
Également à l'avenir, un tableau avec une liste d'utilisateurs sera utile pour entrer des fonctions sociales dans le jeu et, maintenant, j'ai trouvé au moins une application pour ces données. Dans la mise en œuvre de cette tâche, les outils Azure tels que le stockage de file d'attente et les fonctions Azure m'aideront à nouveau, mais j'en parlerai dans l'un des articles suivants.