Dire ce que sont les caches, qu'est-ce que le cache de résultats, comment il est fait dans Oracle et dans d'autres bases de données n'est pas très intéressant et joli. Mais tout prend des couleurs complètement différentes lorsqu'il s'agit d'exemples spécifiques.
Alexander Tokarev (
shtock ) a construit son rapport sur Highload ++ 2017 à partir de cas. Et c'est précisément sur la base de cas qu'il a dit quand un cache fait maison pourrait être pratique, quelle est la douleur du cache de résultats côté serveur et comment le remplacer par un cache côté client, et en général, il a présenté un certain nombre de conseils utiles pour configurer le cache de résultats dans Oracle.
À propos de l'orateur: Alexander Tokarev travaille chez DataArt et s'occupe des problèmes liés aux bases de données, à la fois en termes de construction de systèmes à partir de zéro et d'optimisation des systèmes existants.
Commençons par quelques questions rhétoriques. Avez-vous travaillé avec Oracle Result Cache? Croyez-vous qu'Oracle est une base de données adaptée à toutes les occasions? Selon l'expérience d'Alexandre, la plupart des gens répondent à la dernière question par la négative,
cent rêveurs ont un rêveur . Mais grâce à sa foi, les progrès avancent.
Soit dit en passant, Oracle possède déjà 14 bases de données - jusqu'à présent 14 - ce qui se passera à l'avenir est inconnu.
Comme déjà mentionné, tous les problèmes et solutions seront illustrés par des cas spécifiques. Il s'agira de deux cas de projets DataArt et d'un exemple tiers.
Caches de base de données
Pour commencer, quels caches sont dans les bases de données. Tout est clair ici:
- Cache tampon - cache de données - cache pour les pages de données / blocs de données;
- Cache d'instructions - cache d'instructions et de leurs plans - cache de plan de requêtes;
- Cache des résultats - cache des résultats des lignes - lignes des requêtes;
- Cache du système d'exploitation - cache du système d'exploitation.
De plus, le cache de résultats, dans l'ensemble, est utilisé uniquement dans Oracle. Il était une fois dans MySQL, mais il a ensuite été héroïquement coupé. Dans PostgreSQL, il n'est pas là non plus, il est présent sous une forme ou une autre uniquement dans le produit pgpool tiers.
Cas 1. Retailer Vault
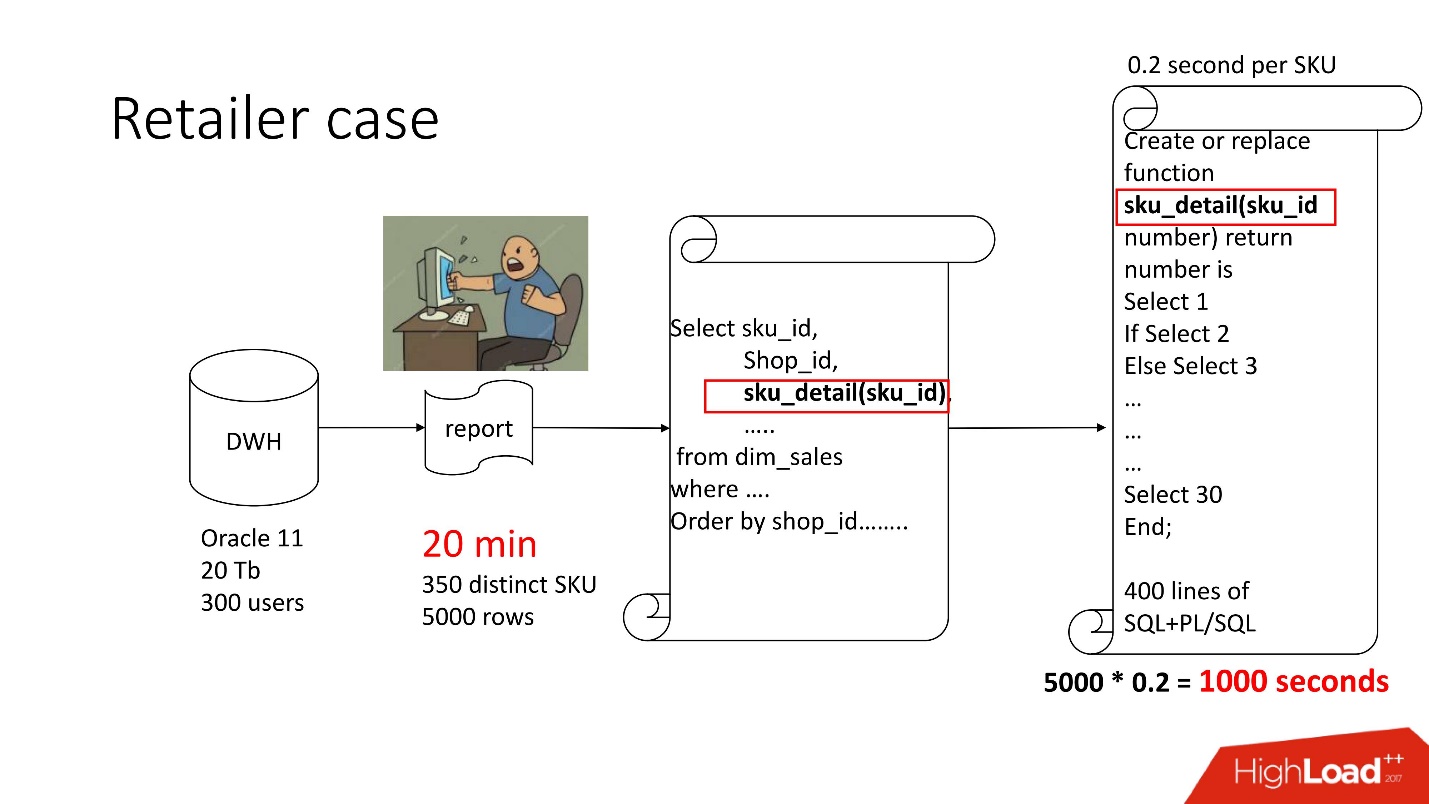
Ci-dessus est le diagramme de produit que nous avons accompagné - le référentiel (Oracle 11, 20 To, 300 utilisateurs), et il contient une sorte de rapport morne, dans lequel il y avait 350 produits uniques pour 5000 lignes de données. Cela a pris environ 20 minutes et les utilisateurs étaient tristes.
La présentation de ce rapport, comme tout le monde, est disponible sur le site de la conférence Highload ++.
Ce rapport a SELECT, JOINs et une fonction. Une fonction en tant que fonction, tout irait bien, seulement il calcule un paramètre mystérieux appelé la «valeur de prix de transfert», cela fonctionne pendant 0,2 s - cela ne semble rien, mais il est appelé autant de fois qu'il y a de lignes dans le tableau. Cette fonction a 400 lignes de SQL + PL / SQL, car le produit est en support, ça fait peur de le changer.
Pour la même raison, result_cache n'a pas pu être utilisé.
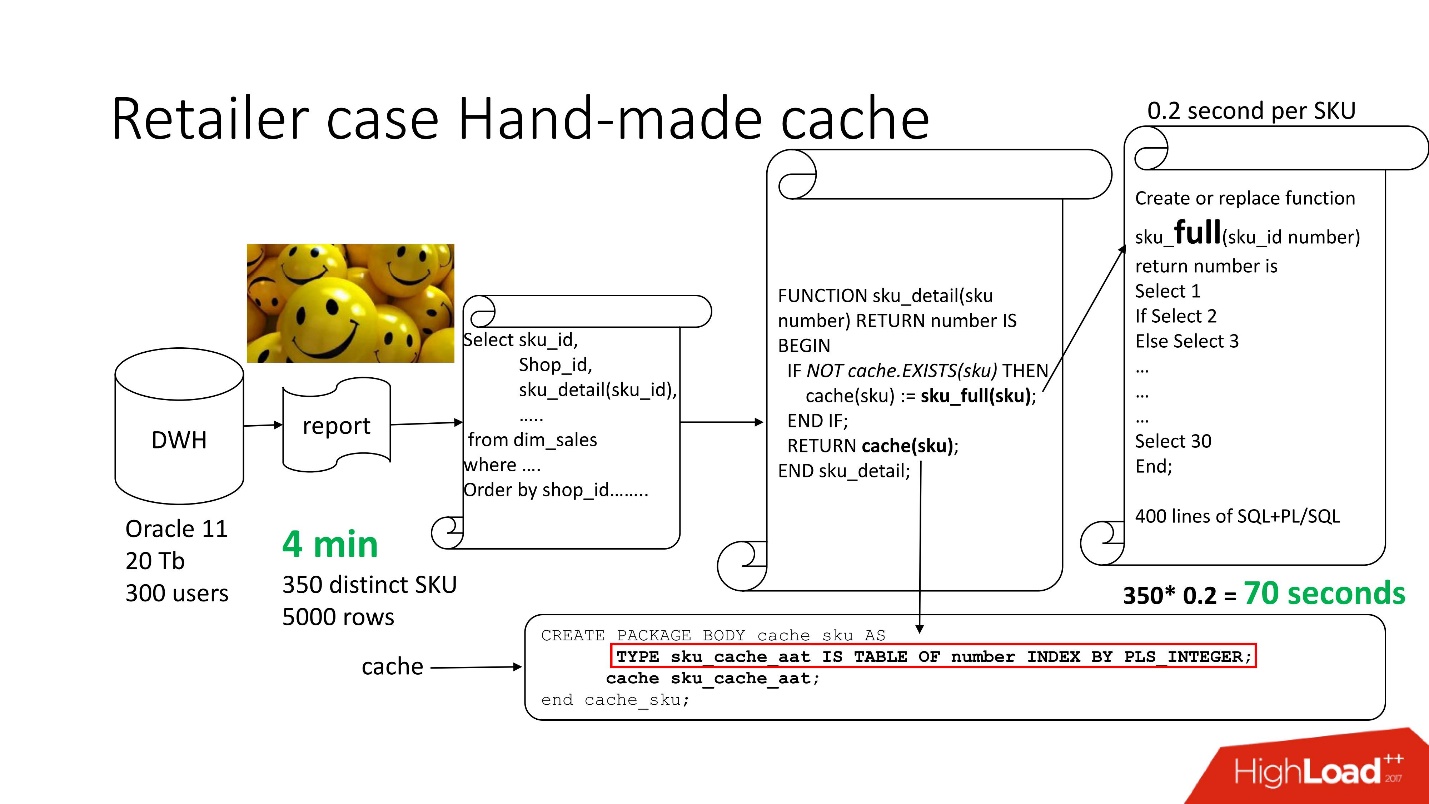
Pour résoudre le problème, nous utilisons l'
approche standard
avec une mise en cache faite à la main : nous laissons les 3 premiers blocs du circuit, tels quels, renommez simplement notre fonction sku_detail () en sku_full () et déclarez un tableau associatif, où respectivement:
- les clés sont nos références (articles de base),
- Les valeurs sont le prix de conversion de transfert calculé.
Nous rendons la fonction de cache (sku) évidente: s'il n'y a pas un tel identifiant dans notre tableau associatif, notre fonction est lancée, le résultat est mis en cache, enregistré et renvoyé. En conséquence, si un tel identifiant est, alors tout cela ne se produit pas. En fait, nous avons obtenu un
cache à la demande .
Ainsi, nous avons réduit le nombre d'appels de fonction au montant réellement nécessaire.
Le temps de traitement des rapports a été réduit à 4 minutes , tous les utilisateurs se sentaient bien.
Mémoire cache faite à la main
Les inconvénients et avantages de ce système sont clairs à partir de cette grande image intelligente, à laquelle nous allons beaucoup répondre - c'est l'architecture de la mémoire.
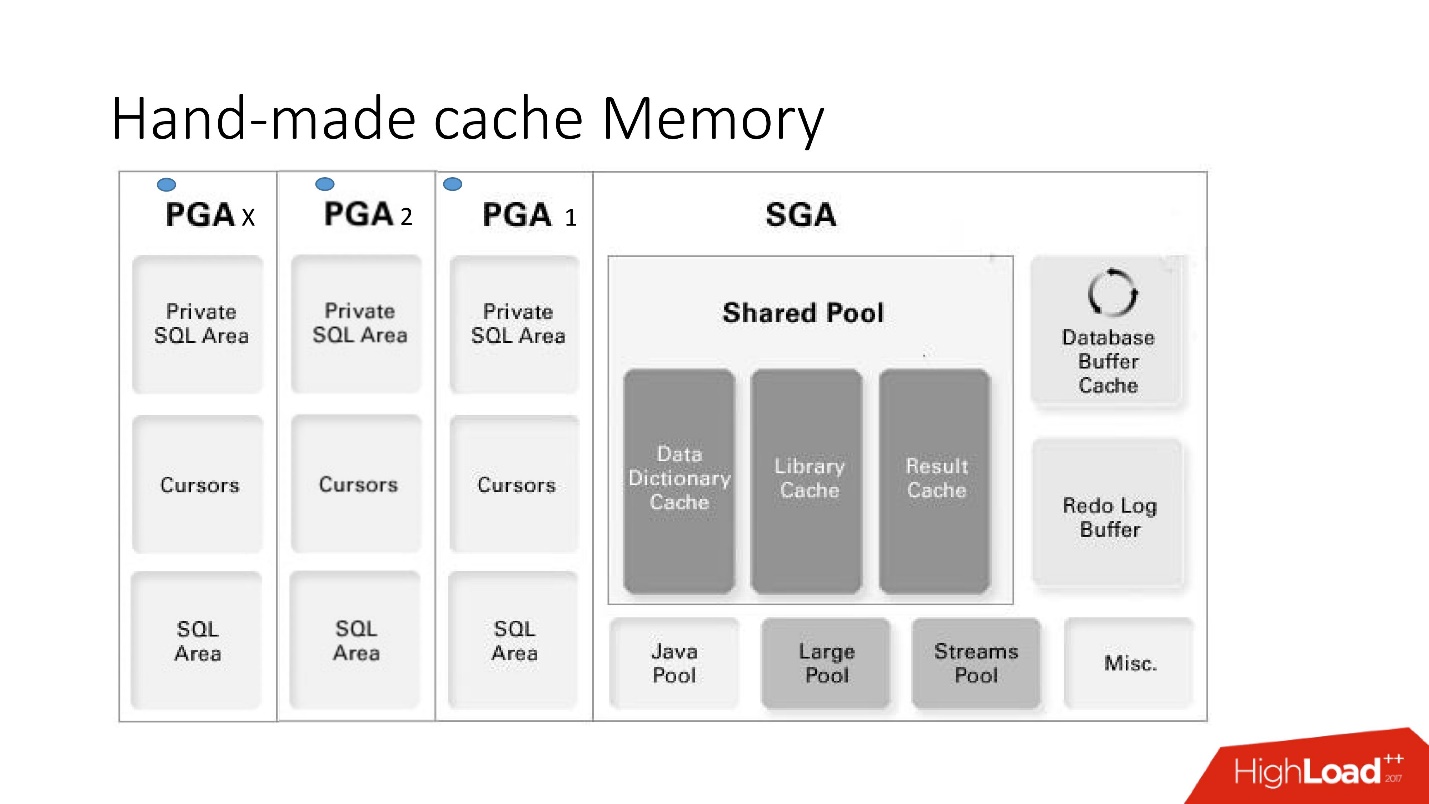
Il est important de comprendre dans quelle zone de mémoire se trouvent les collections. Ils sont placés dans une zone mémoire appelée PGA.
La zone globale du programme est instanciée à chaque connexion à la base de données. C'est ce qui détermine les avantages et les inconvénients, car plus de connexions - plus de mémoire et de
mémoire chère, serveur , administrateurs sont tendres.

- Avantages: tout fonctionne très rapidement, très facile à faire, aucune configuration n'est requise, aucun problème d'implication interprocessus.
- Les inconvénients sont compréhensibles: si la logique stockée est interdite dans le projet, ils ne peuvent pas être utilisés, il n'y a pas de mécanisme d'invalidation automatique, et puisque la mémoire sur le cache est allouée dans une session de base de données, pas une instance, sa consommation est surévaluée . De plus, dans le cas du cas d'utilisation du pool de connexions, vous devez vous rappeler de vider les caches s'il doit y avoir une mise en cache différente pour chaque session.
Il existe d'autres options pour les caches faits à la main basés sur des vues matérialisées, des tables temporaires, mais à partir d'eux, il y a une grande charge sur le système d'entrée-sortie, donc ici nous ne les considérons pas. Ils sont plus applicables à d'autres bases de données dans lesquelles de tels problèmes sont généralement résolus en stockant la procédure stockée dans une table intermédiaire et en récupérant les données avant d'accéder à une requête lourde. Et seulement s'il n'a pas été trouvé ce qui est nécessaire, la demande initiale est appelée.

Ce qui précède est une illustration de cette approche du problème de mise en cache pour obtenir une liste de produits associés dans MsSQL. En général, l'approche est relativement similaire, mais elle ne fonctionne pas dans la mémoire de la base de données à la fois en termes d'obtention de données et de remplissage principal, ce qui
peut être plus lent .
En général, result_cache fait maison est activement utilisé, mais result_cache dans la base de données est une approche différente de la mise en œuvre de cette tâche. Nous le verrons et comment cela n'a pas fonctionné rapidement.
Cas 2. Traitement de la documentation financière
Donc, notre deuxième cas.
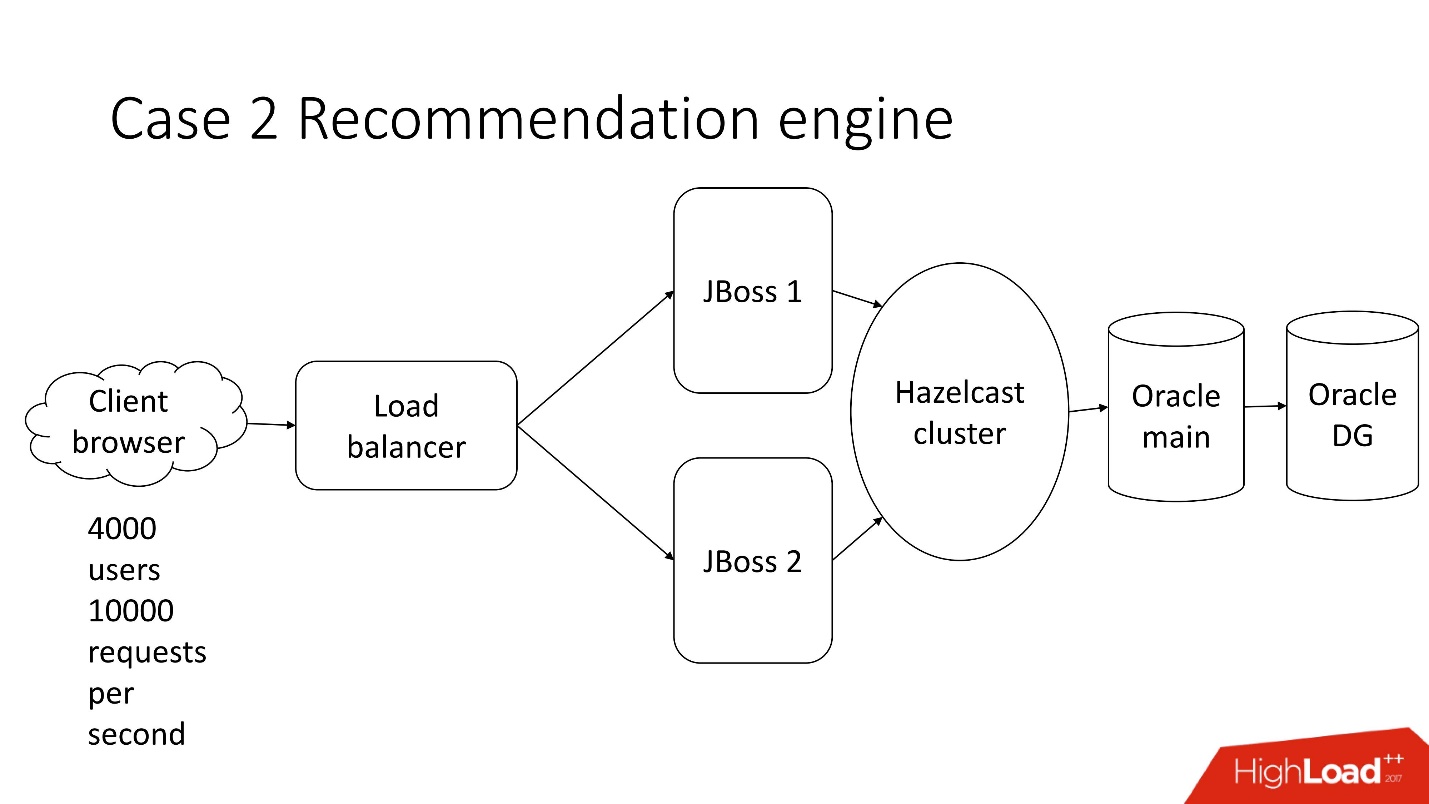
Il s'agit d'un système de traitement de la documentation financière semi-automatisé - une entreprise morne avec une architecture classique, qui comprend:
- client léger;
- 4 000 utilisateurs qui vivent dans différentes parties du monde;
- équilibreur;
- 2 JBoss pour le calcul de la logique métier;
- cluster en mémoire;
- noyau Oracle;
- Sauvegarde Oracle
L'une des nombreuses tâches de ce système est le
calcul des recommandations .

Il existe des documents, pour chaque indicateur qui n'est pas automatiquement reconnu par le système, un ensemble d'indicateurs est proposé soit à partir de documents clients antérieurs, soit d'un secteur similaire, ou à rentabilité similaire, tandis que l'indicateur est comparé à la valeur reconnue afin de ne pas en offrir trop. Ce qui est important, les
documents sont multilingues .
L'utilisateur sélectionne la valeur souhaitée et répète l'opération pour chaque ligne vide.
Simplifiée, cette tâche consiste à: les documents arrivent sous la forme de paires clé-valeur provenant de différents systèmes de reconnaissance, et les paramètres sont reconnus quelque part, mais pas quelque part. Il faut s'assurer qu'au final les utilisateurs traitent les documents et que toutes les valeurs sont reconnues. La recommandation vise précisément à simplifier cette tâche et prend en compte:
- Multilinguisme - environ 30 langues. Chaque langue a ses propres racines, synonymes et autres fonctionnalités.
- Les données précédentes de ce client, ou, à défaut, les données d'un client de la même industrie ou d'un client de profit similaire.
En fait, il s'agit d'environ 12 règles très complexes.
Hypothèses initiales:- Pas plus de 100 utilisateurs à la fois;
- 2-3 colonnes pour la reconnaissance;
- 100 lignes.
Pas de surcharge du tout - tout est ennuyeux.
Il est donc temps de sortir. Le gel du code s'est produit, Java a peur de toucher et il faut au moins 5 minutes pour traiter un document.
Ils viennent à l'équipe de développement de la base de données pour demander de l'aide. Bien sûr, parce que
si quelque chose ralentit dans la JVM, alors en soi, vous devez modifier ou réparer la base de données .

Nous avons étudié les documents et réalisé que dans les paires clé-valeur, les valeurs sont souvent répétées - 5 à 10 fois. En conséquence, nous avons décidé d'utiliser la base de données pour mettre en cache, car elle a déjà été testée.
Nous avons décidé d'utiliser le cache de résultats Oracle côté serveur, car:
- les possibilités d'optimisation de SQL ont été épuisées, car il utilise le moteur de recherche en texte intégral d'Oracle;
- le cache sera utilisé pour les paramètres en double;
- la plupart des données pour les recommandations sont recalculées une fois par heure, car elles utilisent un index de texte intégral;
- PL / SQL est interdit .
Cache de résultat Oracle
Le cache de résultats - la mise en cache Oracle des résultats - a les propriétés suivantes:
- Il s'agit de la zone de mémoire dans laquelle tous les résultats de la requête sont fouillés;
- lire cohérent, et son invalidation automatique se produit;
- des modifications minimes de l'application sont nécessaires. Vous pouvez faire en sorte que l'application ne doive pas être modifiée du tout;
- bonus - vous pouvez mettre en cache la logique PL / SQL, mais c'est interdit ici.
Comment l'activer?Méthode numéro 1
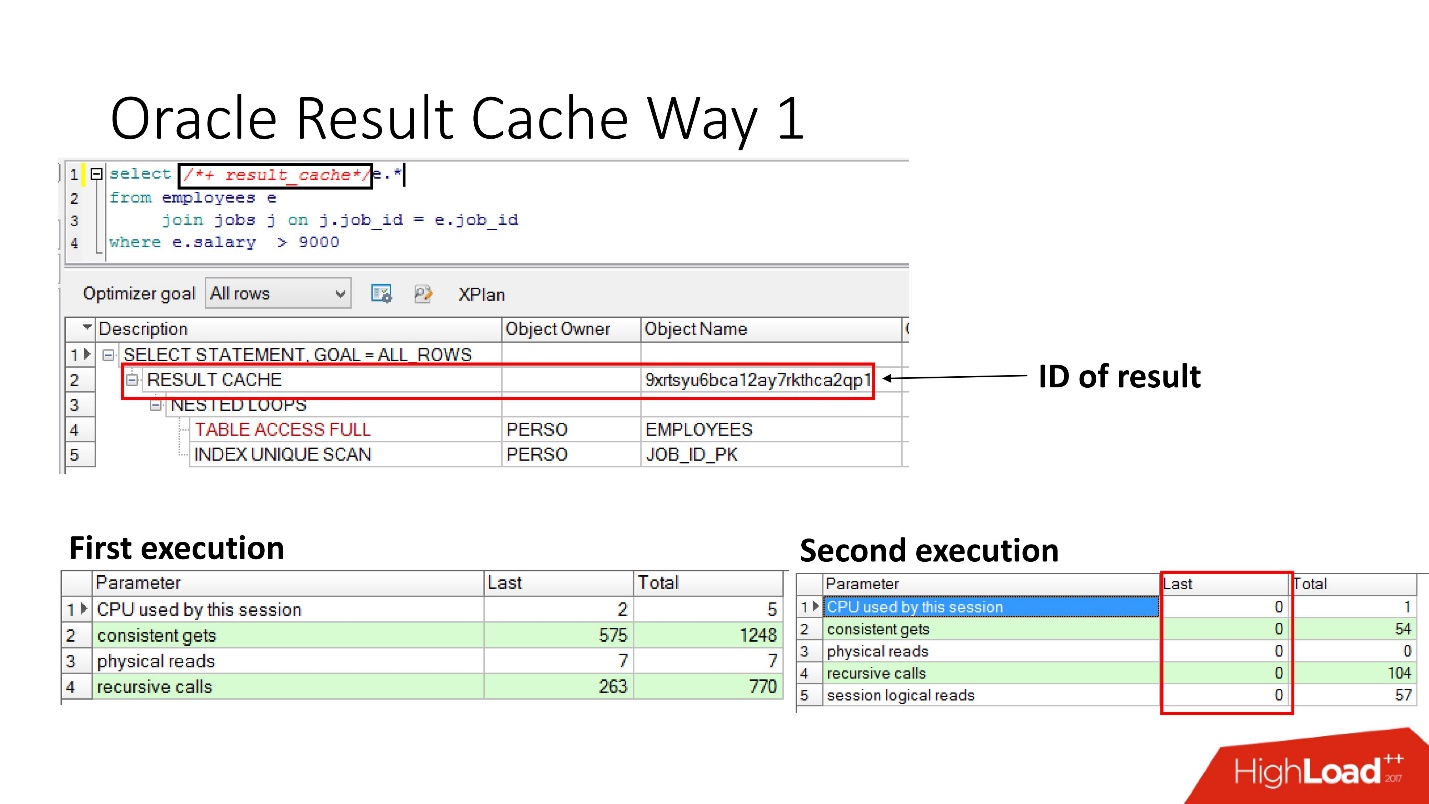
Il est très simple de
spécifier l'instruction result_cache . La diapositive montre que l'identifiant du résultat est apparu. Par conséquent, la première fois que la requête est exécutée, la base de données effectuera un certain travail; lors de l'exécution suivante, dans ce cas, aucun travail n'est nécessaire. Tout va bien.
Méthode numéro 2
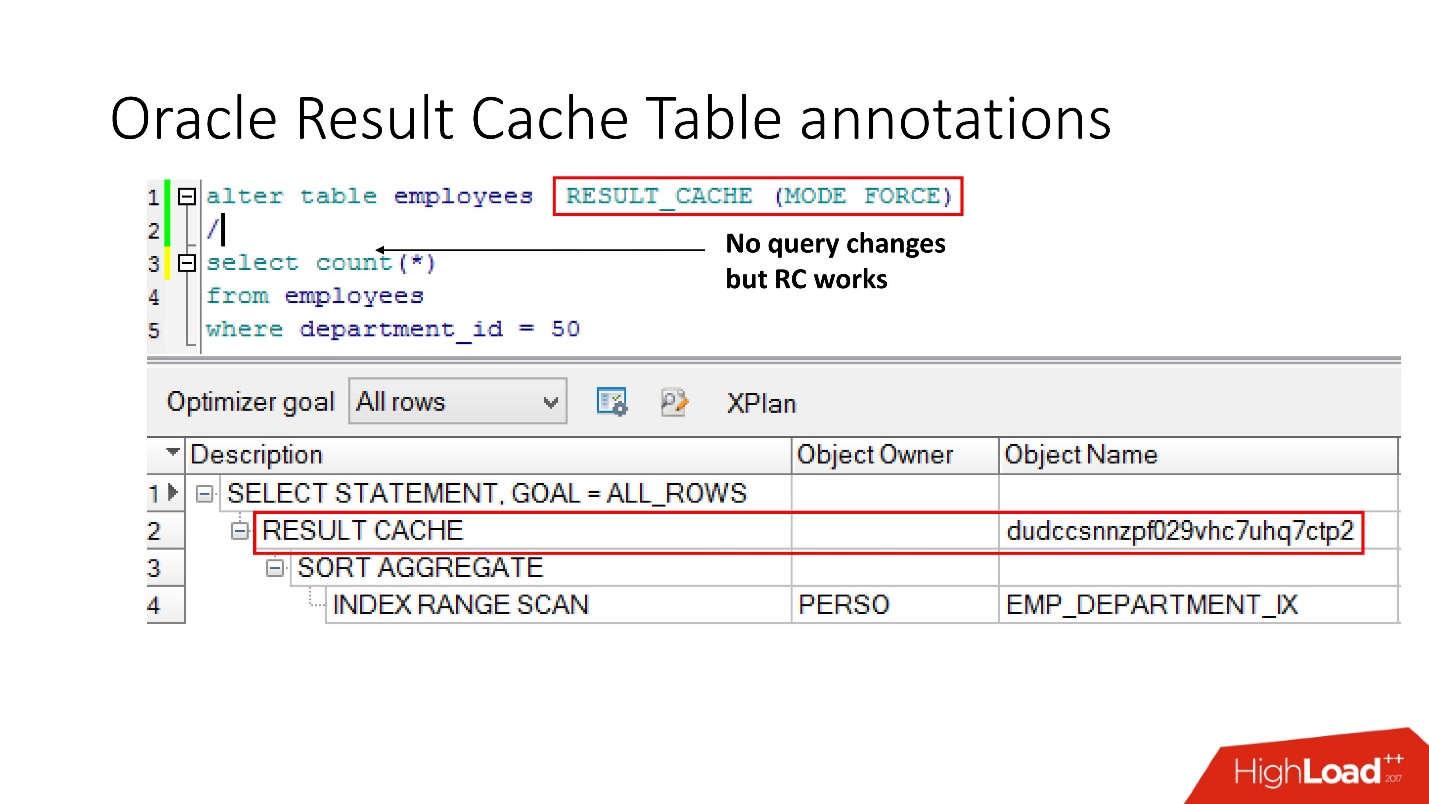
La deuxième façon permet aux développeurs d'applications de ne rien faire - ce sont les soi-disant annotations. Nous indiquons une coche pour la table que la demande doit être placée dans result_cache. En conséquence, il n'y a aucun indice, nous ne touchons pas à l'application, et tout est déjà dans result_cache.
À propos, que pensez-vous, si une requête fait référence à deux tables, dont l'une est marquée comme result_cache, et la seconde ne l'est pas, le résultat d'une telle requête est-il mis en cache?
La réponse est non, pas du tout.
Pour qu'il soit mis en cache, toutes les tables participant à la requête doivent avoir une annotation result_cache.
Suivi des dépendances
Il existe des vues pertinentes dans lesquelles vous pouvez voir quelles sont les dépendances.
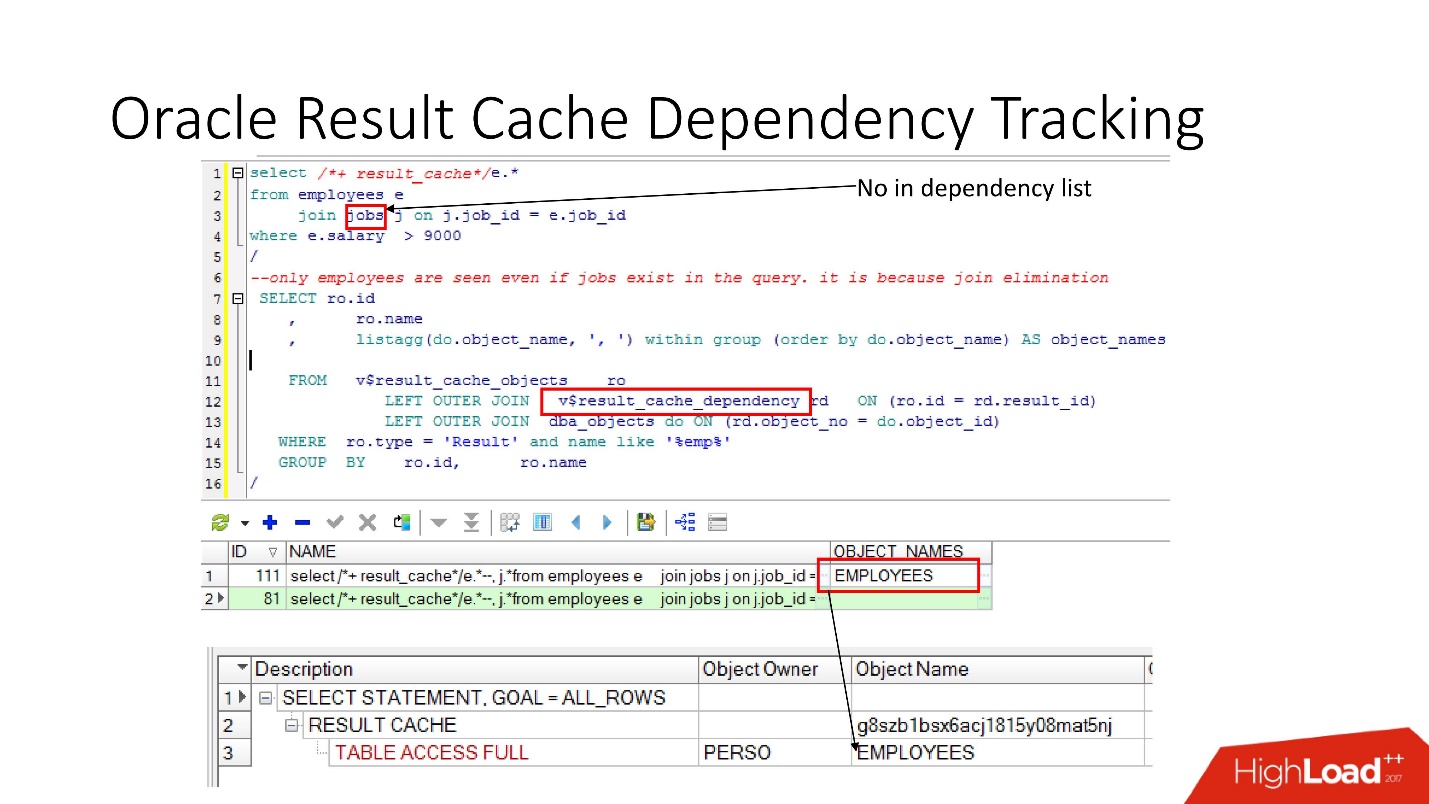
Dans l'exemple ci-dessus, la requête JOIN est une table dans laquelle il existe une dépendance. Pourquoi? Parce que Oracle détermine la dépendance non seulement en analysant, mais l'implémente en
fonction des résultats du plan de travail .
Dans ce cas, un tel plan a été choisi car une seule table est utilisée et, en fait, la table des emplois est liée à la table des employés via une contrainte de clé étrangère. Si nous supprimons la contrainte de clé étrangère qui permet cette transformation d'élimination de jointure, nous verrons alors deux dépendances, car le plan changera de cette façon.
Oracle ne suit pas ce qui n'a pas besoin d'être suivi .
Dans PL / SQL, la dépendance s'exécute au moment de l'exécution afin que vous puissiez utiliser du SQL dynamique et faire d'autres choses.
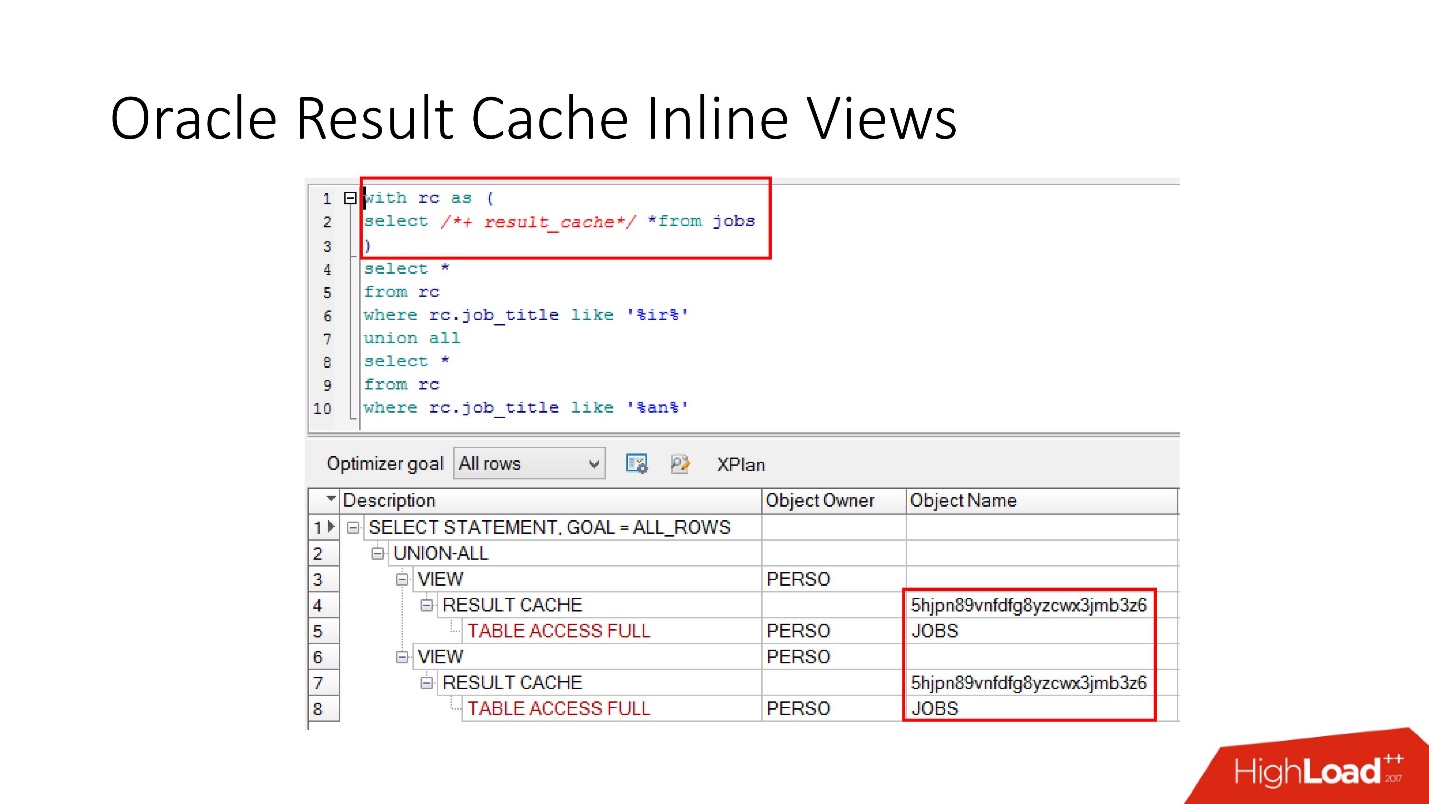
Veuillez noter que vous pouvez mettre en cache non seulement la demande entière, mais
vous pouvez mettre en cache la vue en ligne avec et depuis . Supposons pour une chose que nous ayons besoin d'un cache, et l'autre serait préférable de lire dans la base de données afin de ne pas le surcharger. Nous prenons une vue en ligne, la déclarons à nouveau en tant que result_cache et voyons qu'une seule partie est mise en cache, et pour la seconde, nous accédons à la base de données à chaque fois.
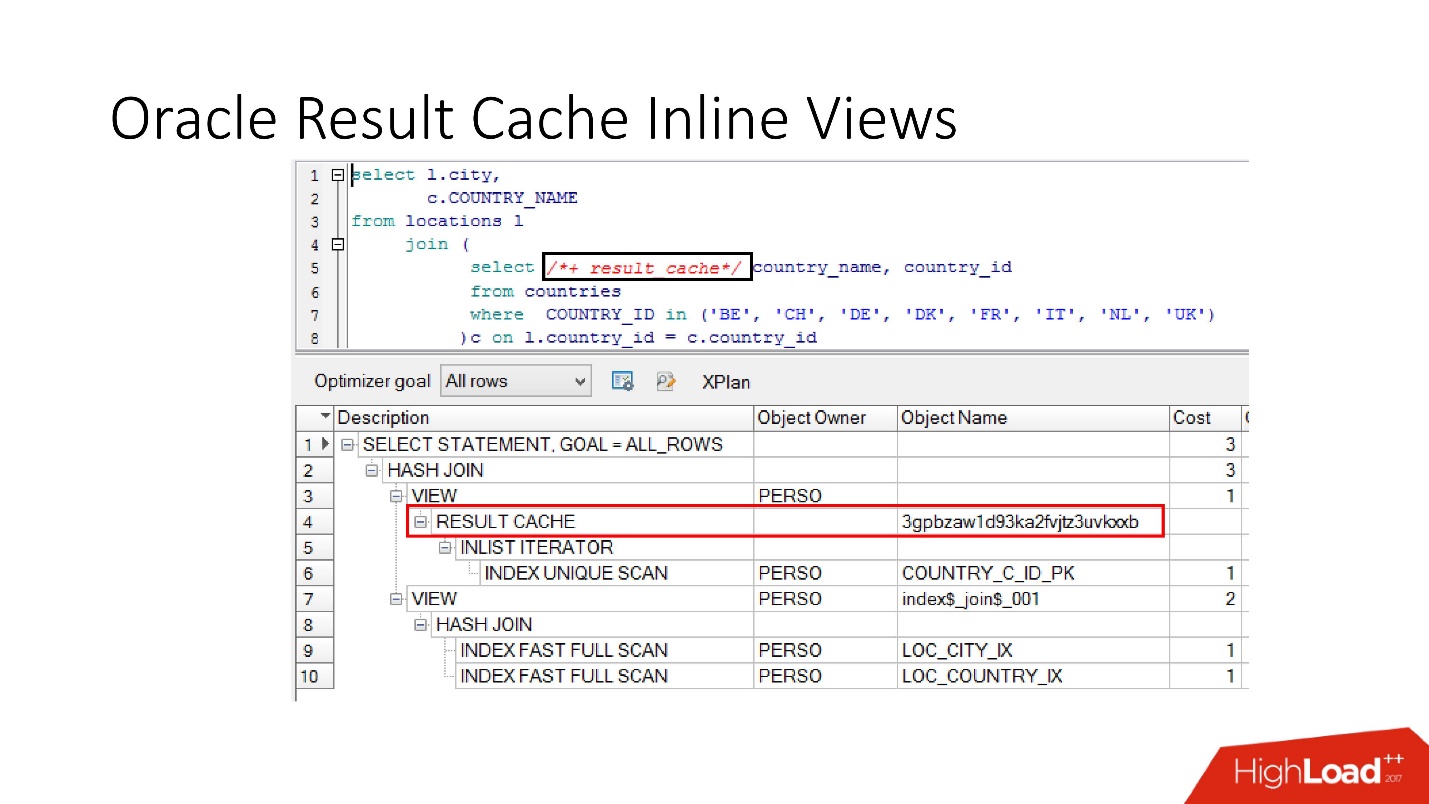
Et enfin, les
bases de données ont également une encapsulation , bien que personne n'y croit. Nous prenons une vue, y mettons result_cache, et nos programmeurs ne réalisent même pas qu'il est mis en cache. Ci-dessous, nous voyons qu'en fait, seule une partie de cela fonctionne.
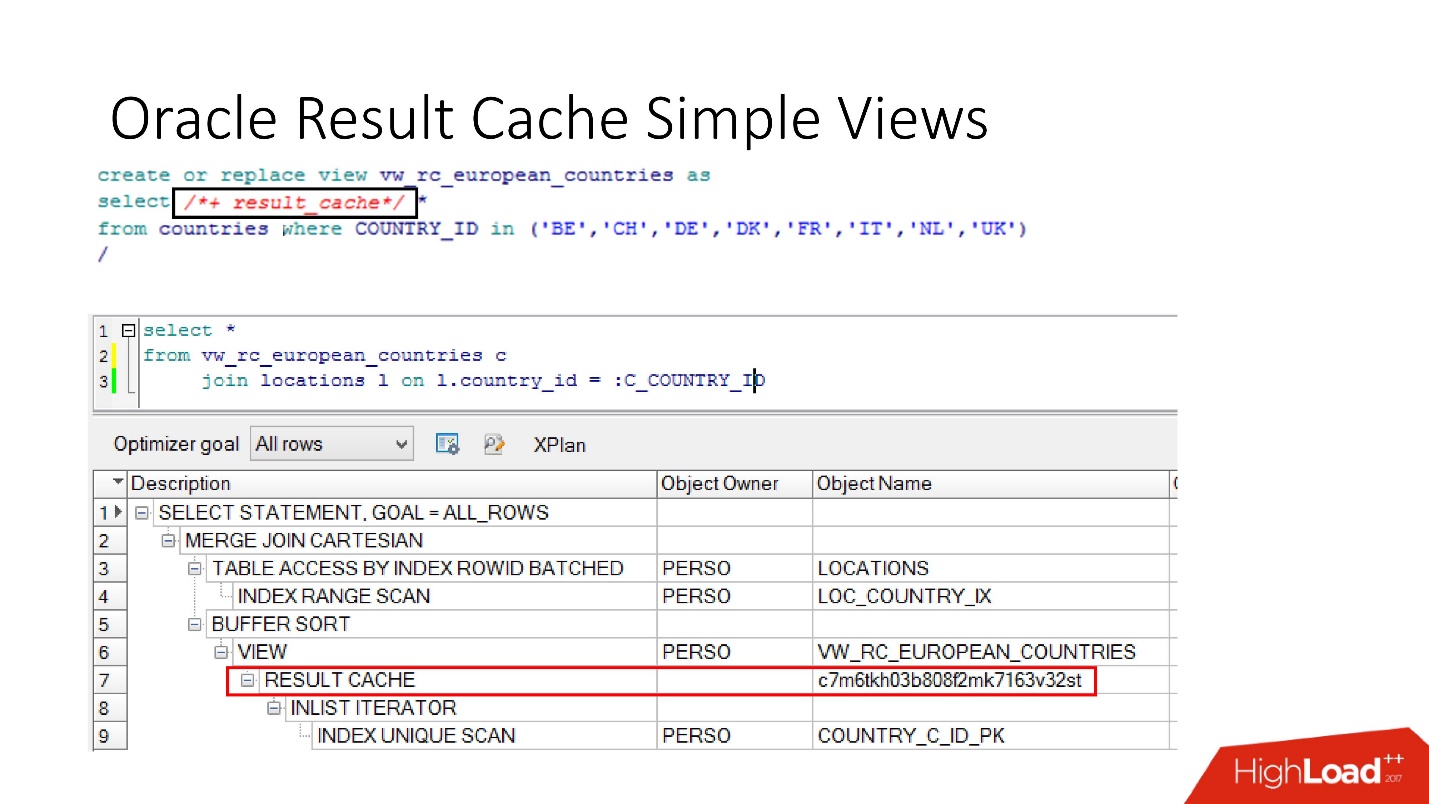
Handicap
Voyons donc quand Oracle invalide result_cache. Le statut Publié indique l'état actuel de la validité du cache. Lorsque la demande de result_cache, comme je l'ai dit, il n'y a pas de travaux dans la base de données
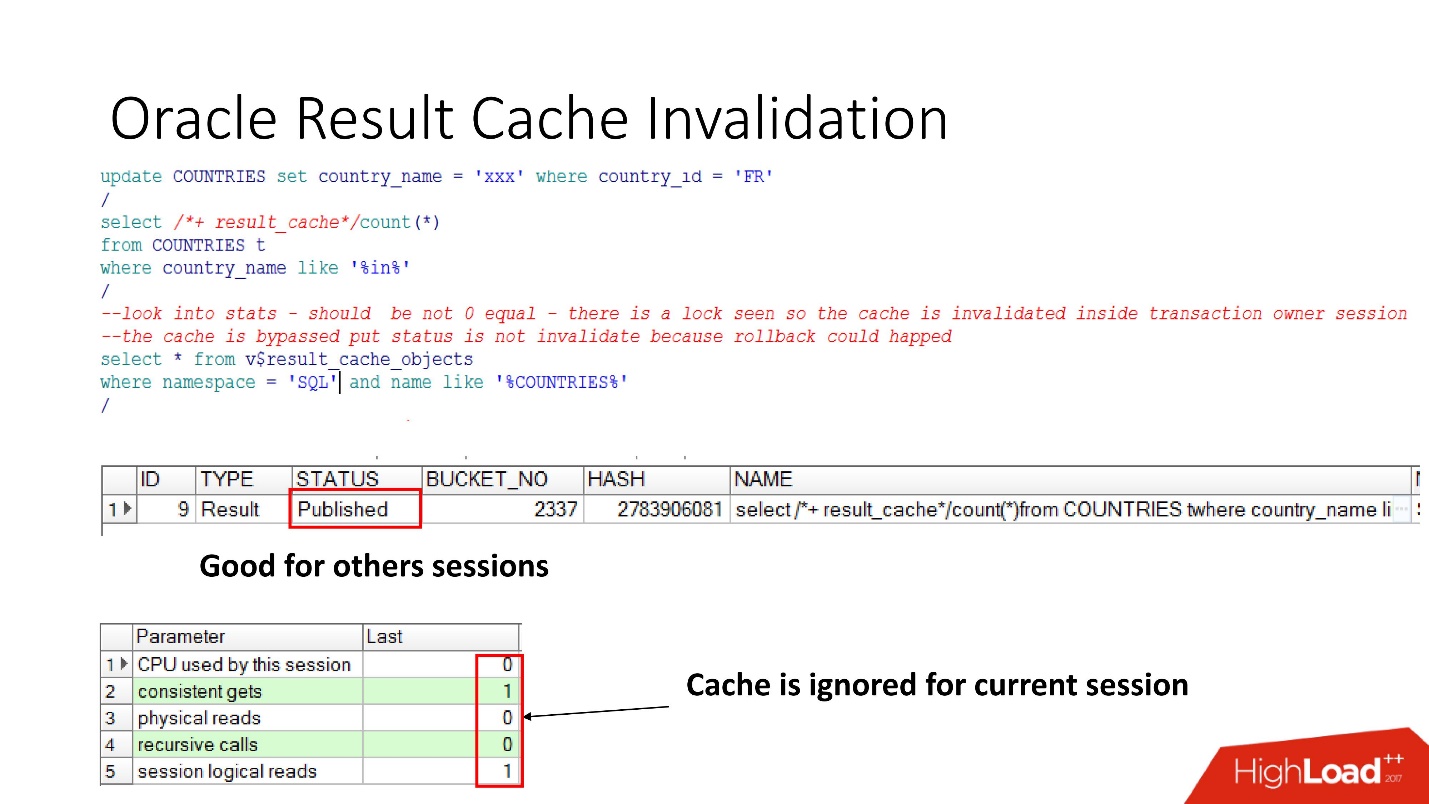
Lorsque nous avons effectué la mise à jour, le statut est toujours publié, car la mise à jour n'a pas été validée et les autres sessions devraient voir l'ancien result_cache. C'est la cohérence de lecture notoire.
Mais dans la session en cours, nous verrons que la charge a disparu, car c'est dans cette session que le cache est ignoré. C'est tout à fait raisonnable, faisons un commit - le résultat deviendra invalide, tout fonctionne par lui-même.

Il semblerait - un rêve! La dépendance est considérée comme correcte - uniquement en fonction de la demande. Mais non, un certain nombre de nuances ont été révélées.
Oracle produit des handicaps et dans un certain nombre de cas non évidents :
- Avec tout appel SELECT FOR UPDATE, les dépendances s'envolent.
- Si la table a des clés étrangères non indexées et qu'une mise à jour se produit sur la table marquée result_cache, qui n'a rien affecté du tout, mais que quelque chose a changé dans la table parent, le cache devient également invalide.
- C'est la chose la plus intéressante qui gâche autant que possible la vie - s'il y a une mise à jour infructueuse sur la table marquée comme result_cache, rien n'a fonctionné, mais dans la même transaction, d'autres modifications ont été appliquées qui ont affecté la première table, puis de toute façon result_cache sera réinitialisé.
Result_cache a toujours un tel contre-modèle, quand les développeurs, ayant entendu qu'il y a quelque chose de vraiment cool, pensent: «Oh, il y a du stockage! Maintenant, nous allons prendre une requête qui fonctionne sur 2-3 partitions - à la date actuelle et sur la précédente, marquez-la comme result_cache, et elle sera toujours prise en mémoire! "
Mais quand vous changez de patricia avec le recul, le cache entier vole, car en fait, l'unité de suivi des dépendances dans result_cache est toujours une table, et je ne sais pas s'il y aura des partitions ou non.
Nous avons pensé et décidé que nous irions à la production d'un système de recommandation avec de telles choses:
- Nous ne mettrons pas toutes nos tables en cache, nous ne prendrons que celles nécessaires.
- Définissez result_cache pour la requête de longue durée.
Nous avons tout vérifié, effectué des tests de performance, le
temps de traitement - 30 s . Tout est super, allez en production!
Se précipita - s'endormit. Nous arrivons le matin. Nous voyons une lettre: "La reconnaissance prend au moins 20 minutes, les sessions se figent." Pourquoi gèlent-ils? Comment
30 secondes se sont-elles transformées en 20 minutes ?
Ils ont commencé à comprendre, à regarder la base de données:
- sessions actives - 400;
- en moyenne dans un document de reconnaissance - 500;
- colonnes minimum - 5-8;
- le nombre de sessions dans la base de données est toujours égal au nombre d'applications utilisateur multiplié par 3! Et result_cache n'aime pas y avoir accès fréquemment.
Après avoir mené une enquête interne, nous avons découvert que les développeurs Java font la reconnaissance dans 3 threads.
Nous étions bouleversés - une charge 5 fois, une chute, une dégradation, et même avec de tels paramètres, une telle affaissement n'aurait pas dû se produire.
De toute évidence, vous devez comprendre.
Suivi

Pour la surveillance, nous avons deux éléments clés:
- V $ RESULT_CACHE_OBJECTS - une liste de tous les objets;
- V $ RESULT_CACHE_STATISTICS - statistiques agrégées de result_cache dans son ensemble.
MEMORY_REPORT sont des variations sur un thème, nous n'en aurons pas besoin.
Oracle est magique! Il existe une excellente documentation, mais elle est conçue pour ceux qui passent d'autres bases de données afin qu'ils lisent et pensent qu'Oracle est très cool! Mais
toutes les informations sur result_cache ne reposent que sur le support .

Il y a une nuance qui consiste dans le fait que dès que nous nous tournons vers ces objets pour résoudre le problème, nous l'aggravons en nous enterrant enfin! Jusqu'à Oracle12.2, avant le patch dont il était sorti en octobre de l'année dernière, ces requêtes rendent result_cache inaccessible pour le statut et pour l'écriture jusqu'à ce qu'elles soient complètement comptées.
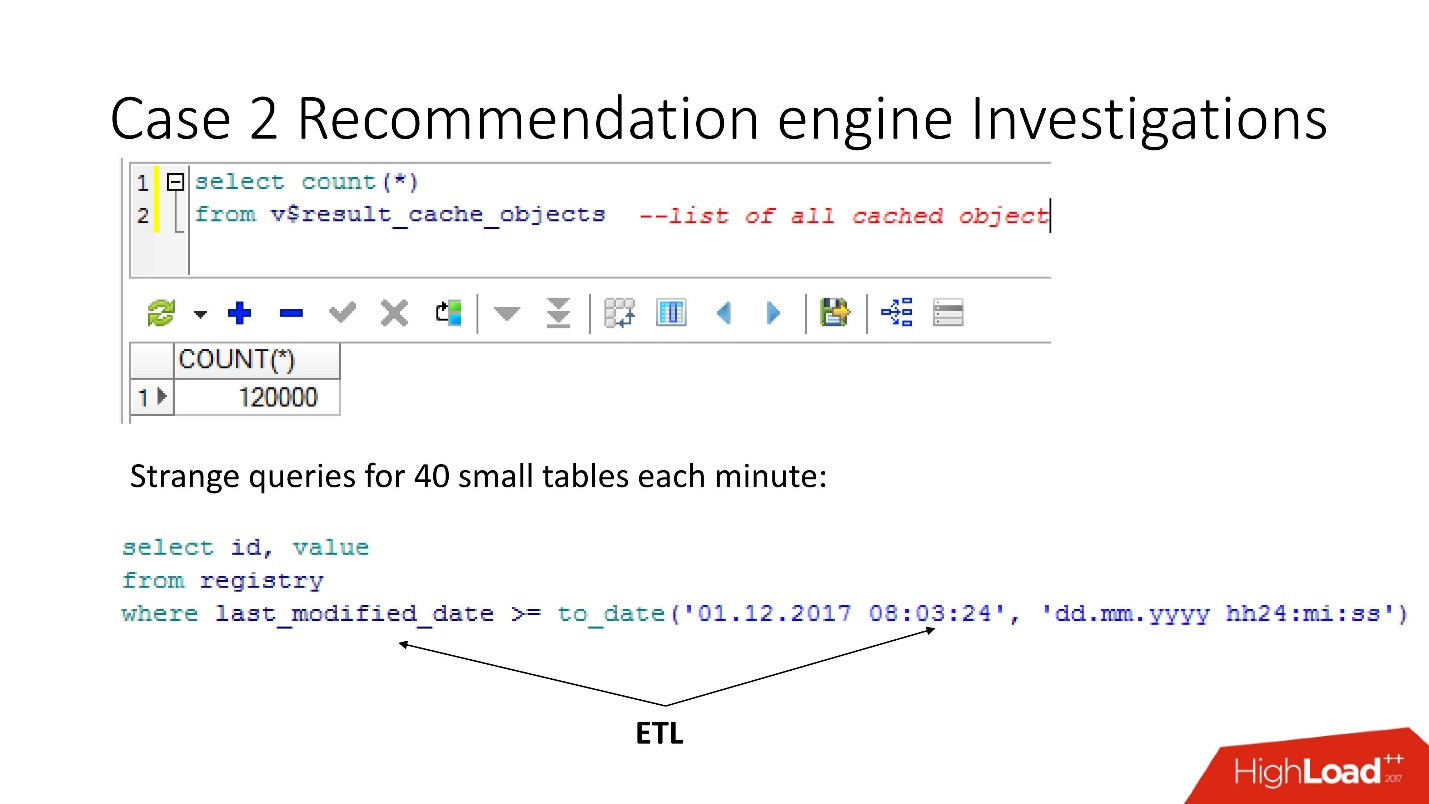
Ainsi, en utilisant la vue v $ result_cache_objects, nous avons découvert qu'il y a des milliers d'entrées dans la liste des objets mis en cache - bien plus que ce à quoi nous nous attendions. De plus, il s'agissait d'objets provenant de certaines de nos requêtes sur d'étranges tables - petites tablettes et requêtes last_modified_date. De toute évidence,
quelqu'un a défini ETL sur notre base .
Avant d'aller jurer aux développeurs ETL, nous avons vérifié que l'option result_cache force était activée pour ces tables, et nous nous sommes souvenus que nous l'avons activée nous-mêmes, car certaines de ces données étaient souvent requises par l'application et la mise en cache était appropriée.
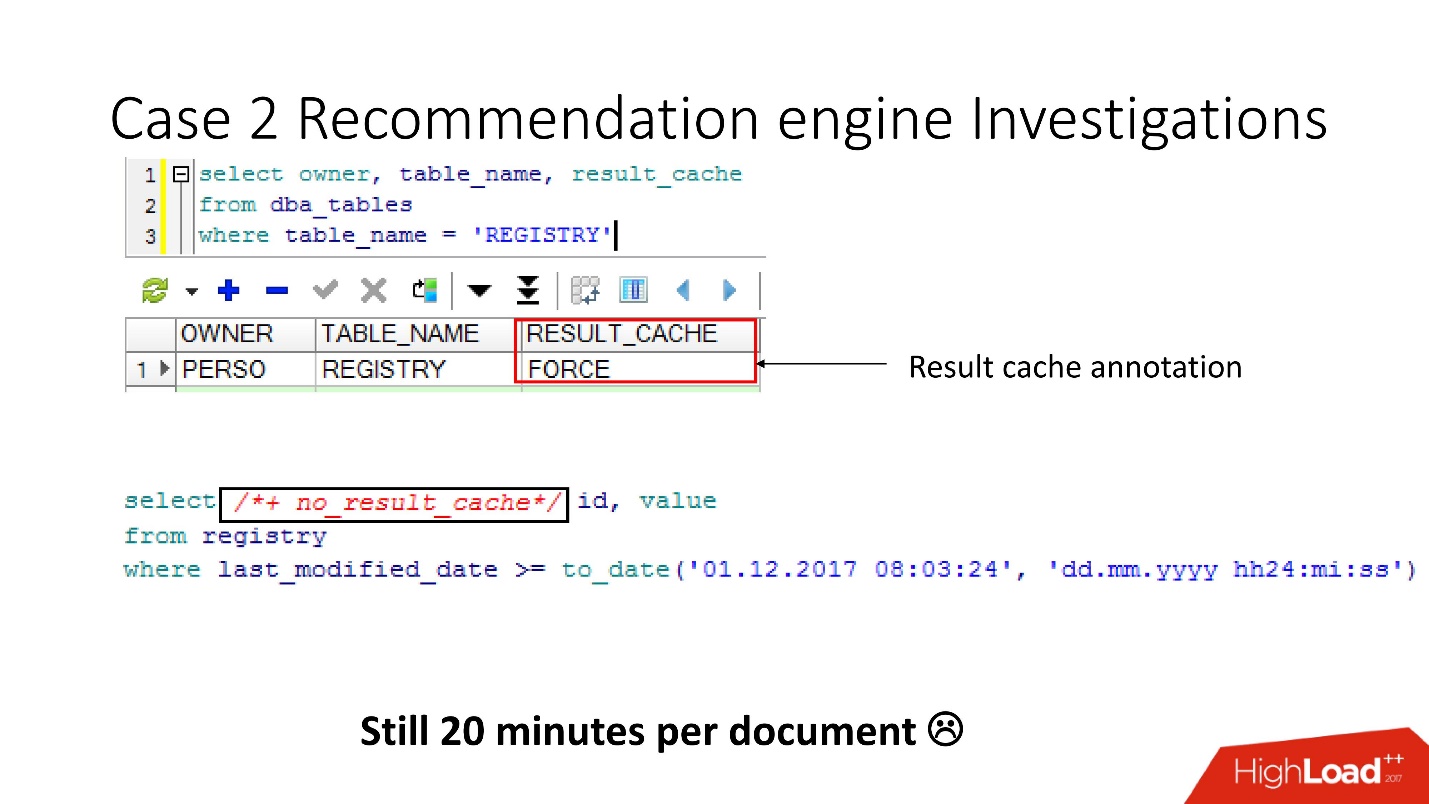
Mais il s'est avéré que
toutes ces demandes prenaient et lavaient notre cache . Heureusement, les développeurs ont eu la possibilité d'influencer l'ETL en production, nous avons donc pu modifier result_cache pour exclure ces demandes infimes.
Pensez-vous que c'est plus facile? - Ne te sens pas mieux! Le nombre d'objets mis en cache a diminué, puis est remonté à 12 000. Nous avons continué à étudier ce qui était mis en cache, car la vitesse n'a pas changé.

Nous regardons - un tas de demandes, et si intelligents, mais tous incompréhensibles. Quiconque a travaillé avec Oracle 12 sait que DS SVC est une statistique adaptative. Il est nécessaire pour améliorer les performances, mais lorsqu'il y a result_cache, il s'avère que cela le tue parce que la compétition se produit. Ceci, bien sûr, n'est écrit
qu'à l'appui .
Nous savions comment la charge de travail est organisée et comprenions que dans notre cas, les statistiques adaptatives n'amélioreraient pas particulièrement radicalement nos plans. Par conséquent, nous l'avons héroïquement désactivé - le résultat, comme il est écrit dans le manuel secret, est de 10 minutes par document. Pas mal, mais pas assez.
Loquets
La concurrence entre result_cache et DS SVC est due au fait qu'Oracle a des verrous - petits verrous légers.

Sans entrer dans les détails de leur fonctionnement, nous essayons de mettre plusieurs fois un verrou nommé - cela n'a pas fonctionné - Oracle décroche et s'endort
Quiconque est dans le sujet peut dire que dans le result_cache, deux verrous sont mis sur chaque bloc avec fetch. Ce sont les détails. Il existe deux types de verrous dans result_cache:
1. Verrouillez la période pendant que nous écrivons des données dans result_cache.

Autrement dit, si votre demande a fonctionné pendant 8 s, pendant la période de ces 8 s, les autres mêmes demandes (le mot-clé «idem») ne pourront rien faire, car elles attendent que les données soient écrites dans result_cache. D'autres demandes seront enregistrées, mais elles n'attendront le verrou que sur la première ligne. Le temps qu'ils devront attendre est inconnu; il s'agit du paramètre non documenté result_cache_timeout. Après cela, ils commencent à ignorer result_cache, pour ainsi dire, et travaillent lentement. Cependant, dès que le verrou de la dernière ligne de la porte a été libéré, ils recommencent automatiquement à travailler avec result_cache.
2. Le deuxième type de verrous - pour recevoir de result_cache également de la 1ère ligne à la dernière.
Mais comme la récupération provient de la mémoire instantanée, elles sont supprimées très rapidement.

N'oubliez pas que lorsque le DBA voit des verrous dans la base de données, il commence à dire: «Loquets! Temps d'attente - tout est parti! »Et c'est ici que commence le jeu le plus intéressant:
convaincre DBA que le temps d'attente des verrous est en fait incomparablement plus court que le temps de nouvelle tentative de requête .

Comme le montre notre expérience, nos mesures,
verrous sur result_cache occupent eux-mêmes 10% des demandes .
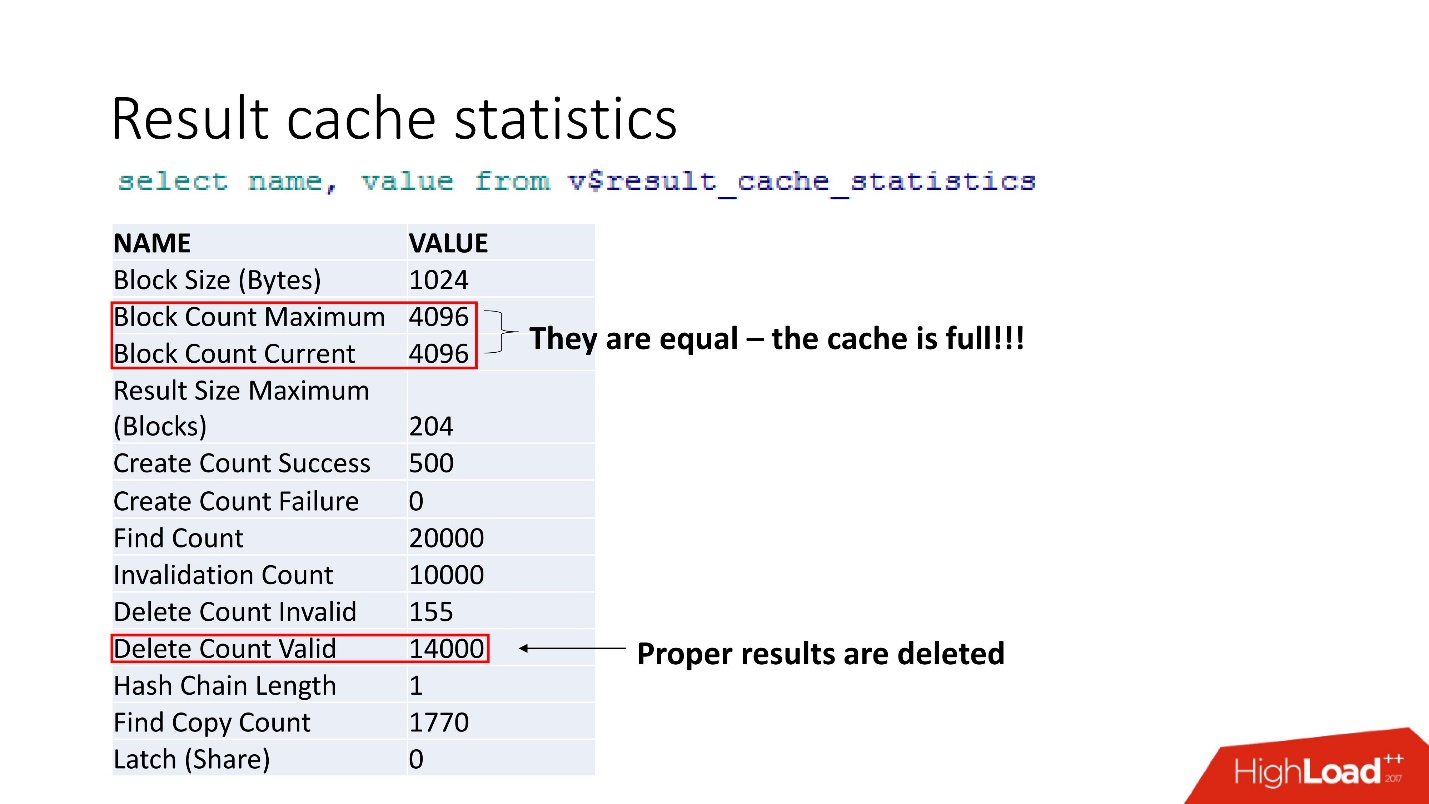
Ce sont des statistiques agrégées. Le fait que tout soit mauvais peut être compris par le fait que le cache est obstrué. Une autre confirmation est que les résultats corrects sont supprimés. Autrement dit, le
cache est écrasé . Il semble que nous soyons intelligents et considérons toujours la taille de la mémoire - nous avons pris la taille de ligne de notre résultat mis en cache pour notre recommandation, multipliée par le nombre de lignes, et quelque chose s'est mal passé.

support 2 , ,
result_cache . .
, . , , , workload 5 . , , .
?: . , .
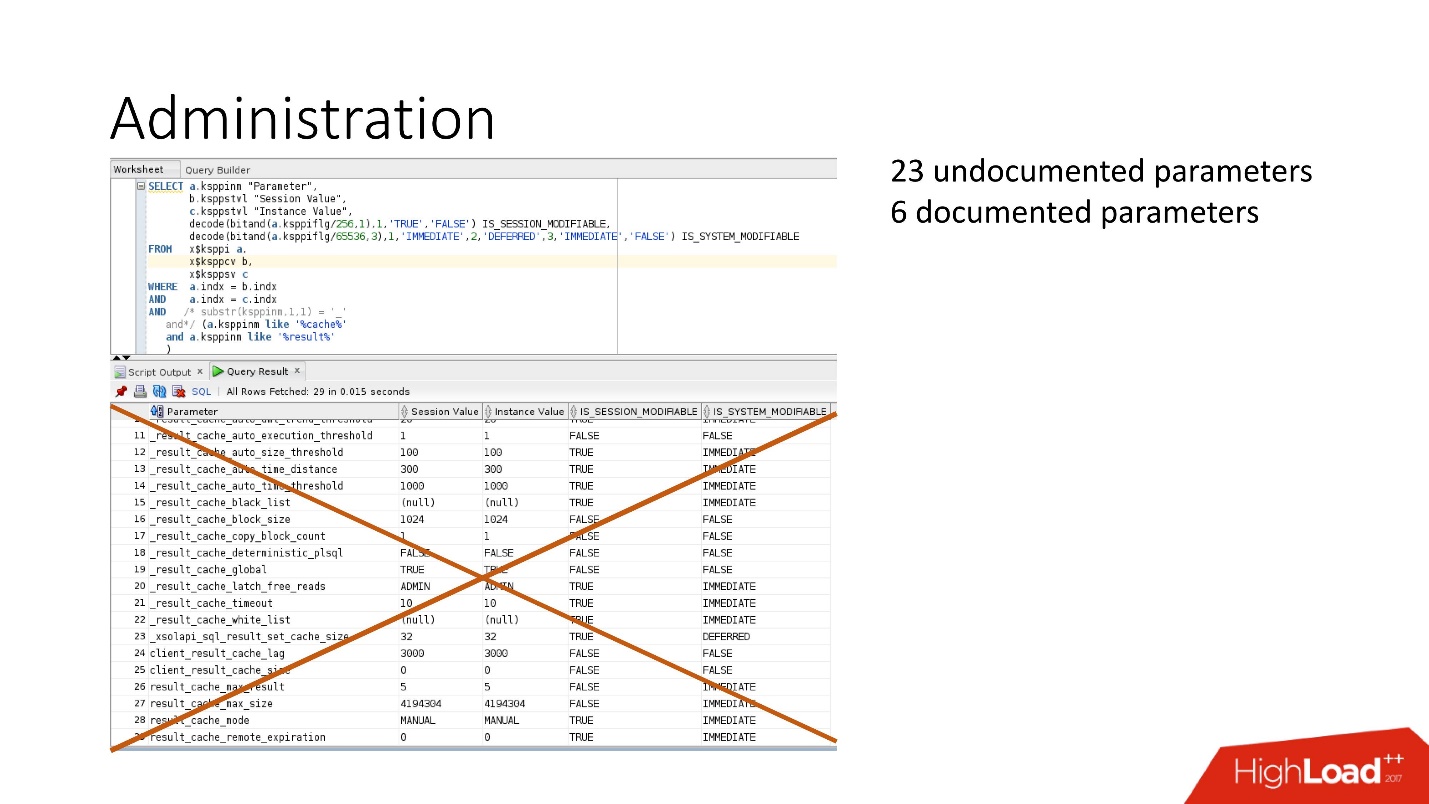
4 :
- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
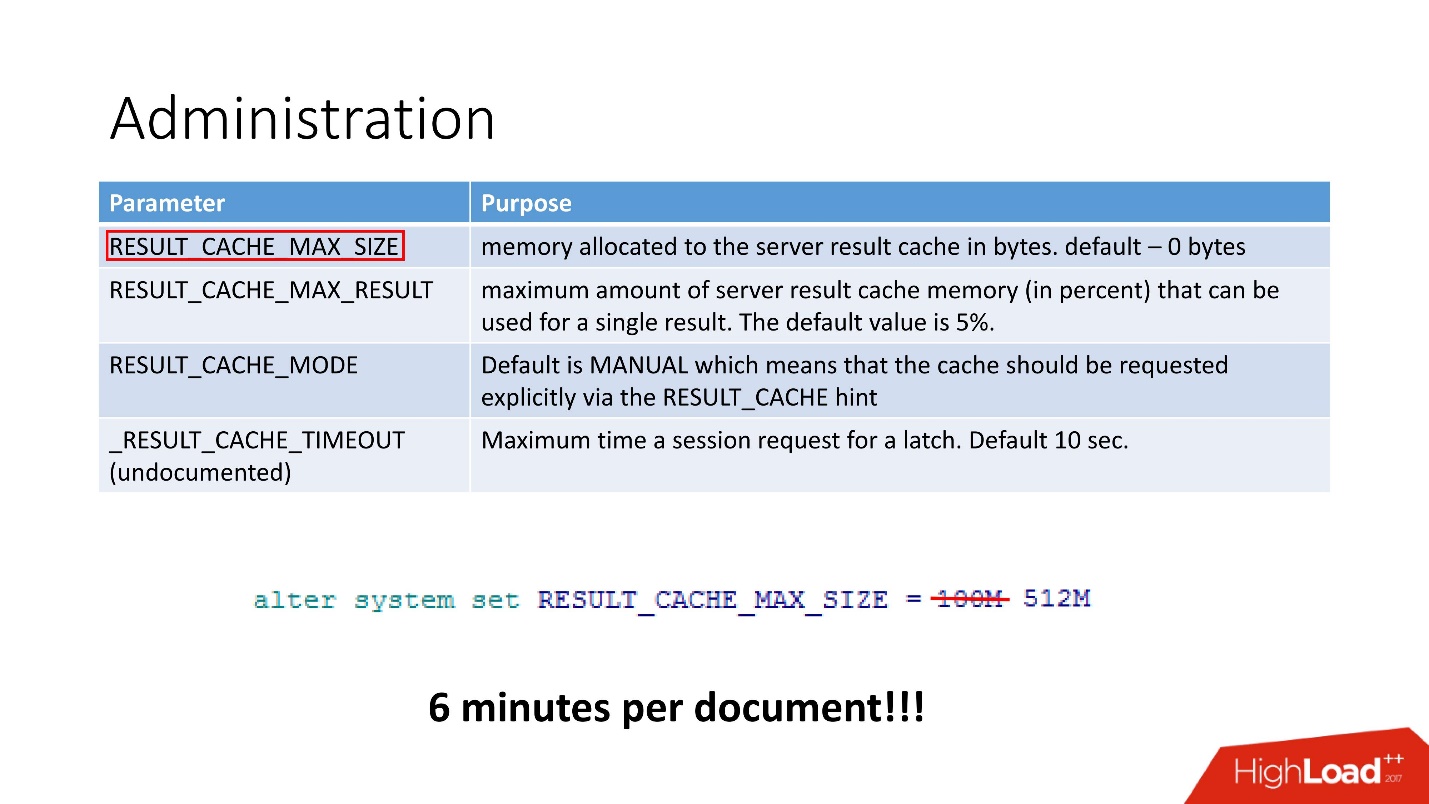
— . , 100 512, 6 .
, - . , Invalidation Count = 10000.
, . , job , . , . job , , .
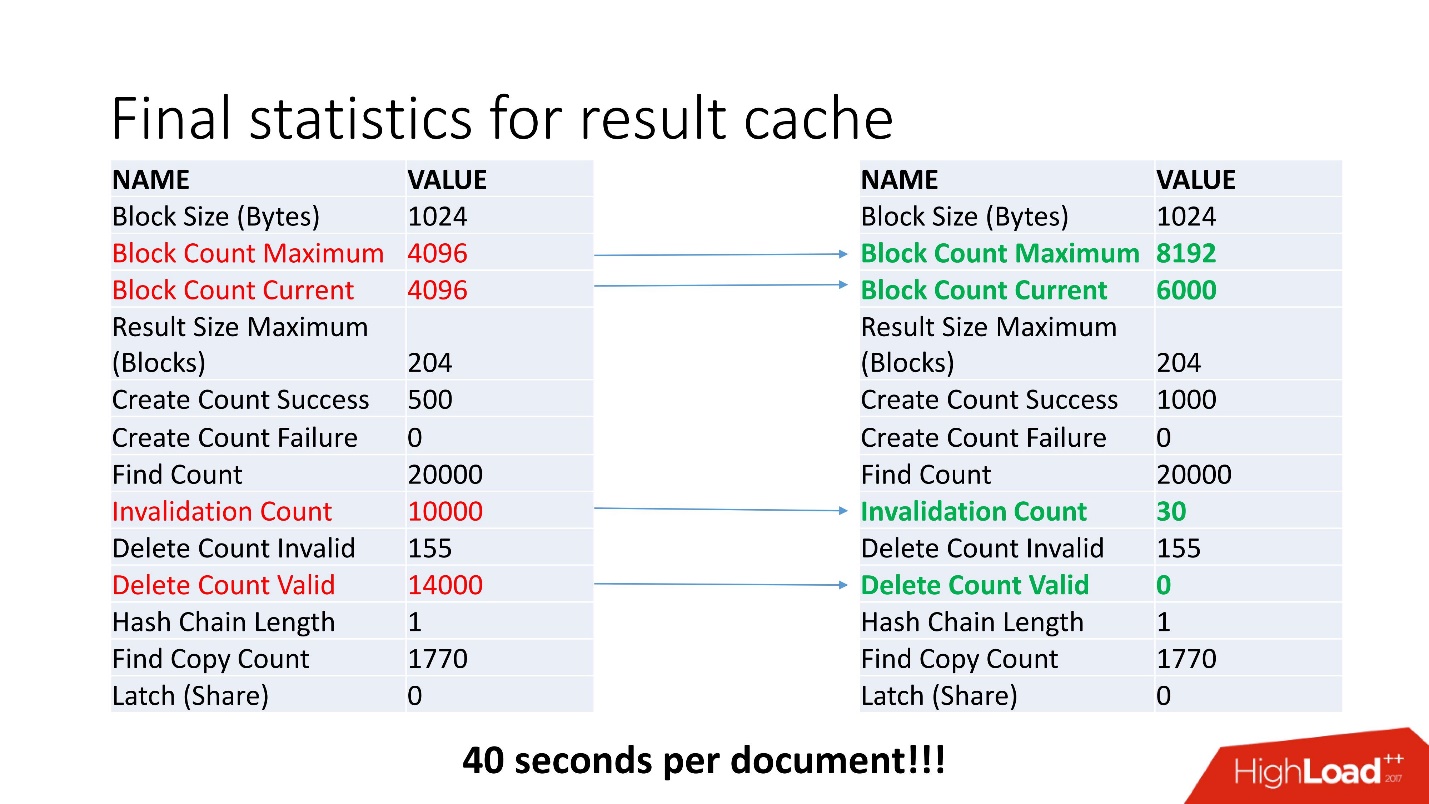
, invalid , .
40 .
, . , , Oracle. !
 SHELFLIVE
SHELFLIVE — , read-consistent , 10 , . . , , .
—
SNAPSHOT . , , read-consistent — .
:

- — SYS.
- . , , Oracle , , . , Oracle , , 12.2 . , external - support, .
- sql pl/sql : current_date, current_time . , current_time, .
- .
- , CLOB, BLOB .
Result cache inside Oracle
Result_cache — Oracle Core. , , job result_cache (, hint, ) , APEX.

, Dynamic sampling , , , result_cache.

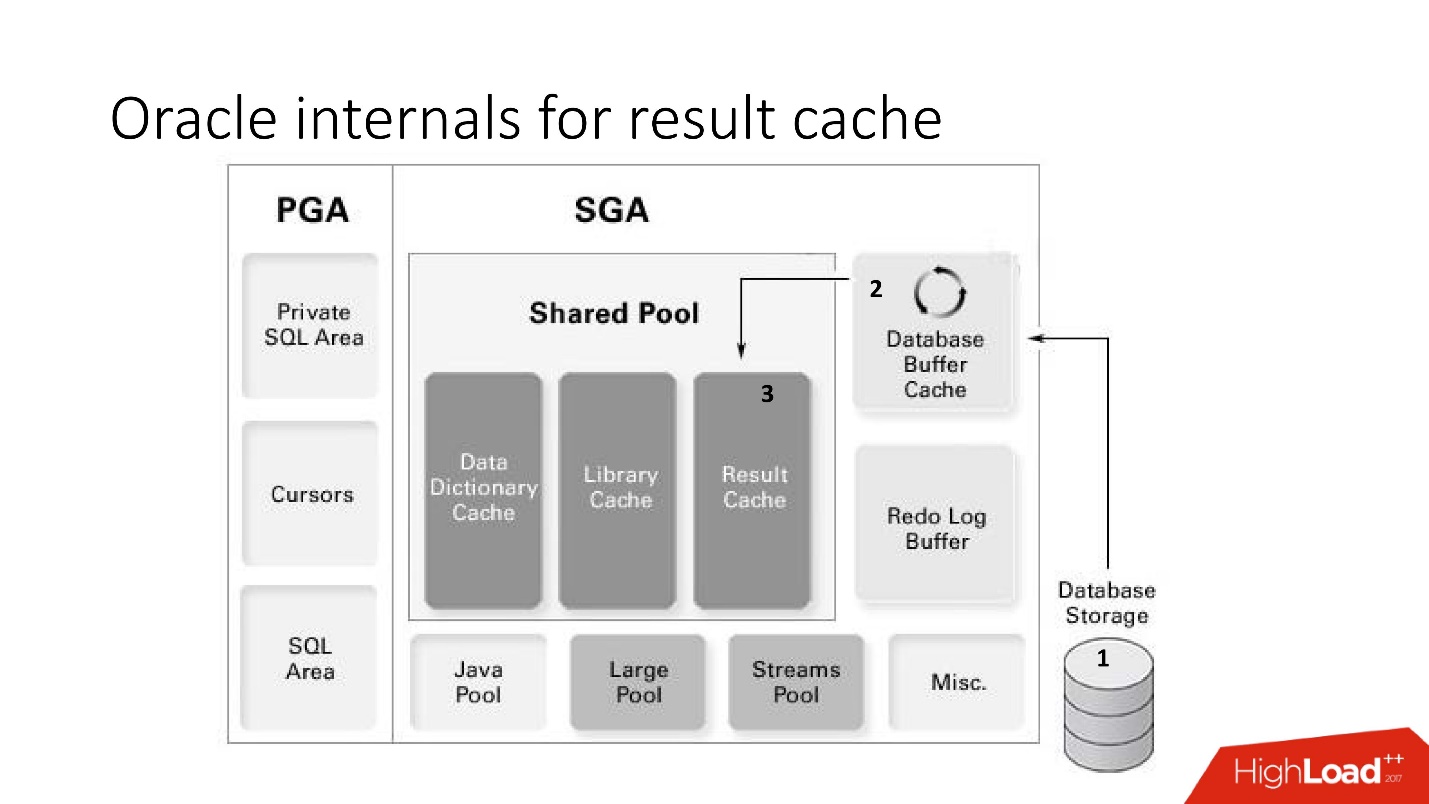
Oracle internals for result cache
result_cache:
- (storage) ;
- result_cache;
- result_cache shared pool.
 Avantages:
Avantages:- .
- read-consistent.
- Result_cache, , .
Inconvénients:!
, . support Oracle, , 29 2017 .: Oracle E-Business suite result_cache, .

, , . support , , .

:
- - ;
- , , , , v$result_cache_memory dbms_result_cache.memory_report, .
, , , v_result_cache_objects .
, support note — support , .

, , : - . , , :
- hint result_cache;
- hint no result_cache;
- black_list, , , -.
?- , - , , ;
- Désactivez le cache pendant la période de démarrage, c'est-à-dire rapidement déconnecté, versé et allumé. Il vaut mieux que le système ralentisse un peu, mais ça marche, puis ça descend.
Comme nous l'avons remarqué, le principal problème avec les caches sur le serveur est le coût de la mémoire coûteuse du serveur . Oracle a une troisième solution finale.Cache des résultats côté client

Le schéma de son appareil est illustré ci-dessus, ce sont les principaux composants de la base de données et du pilote.
Lors du premier accès côté client, le cache de résultats va à la base de données, qui est préconfigurée, reçoit la taille du cache client de la base de données et installe ce cache une fois sur le client lors de la première connexion. La requête mise en cache accède d'abord à la base de données et écrit des données dans le cache. Les threads restants demandent un cache de pilote partagé, économisant ainsi la mémoire et les ressources du serveur. Soit dit en passant, parfois en fonction de la charge, le pilote envoie des statistiques sur l'utilisation du cache à la base de données, qui peuvent ensuite être consultées.
Une question intéressante est: comment se produit le handicap?Il existe deux modes d'invalidation, qui sont accentués par le paramètre Invalidation lag. C'est la quantité d'Oracle qui permet au cache du pilote d'être non cohérent.
Le premier mode est utilisé lorsque les demandes sont fréquentes et que le décalage d'invalidation ne se produit pas. Dans ce cas, le flux ira à la base de données, mettra à jour les caches et en lira les données.
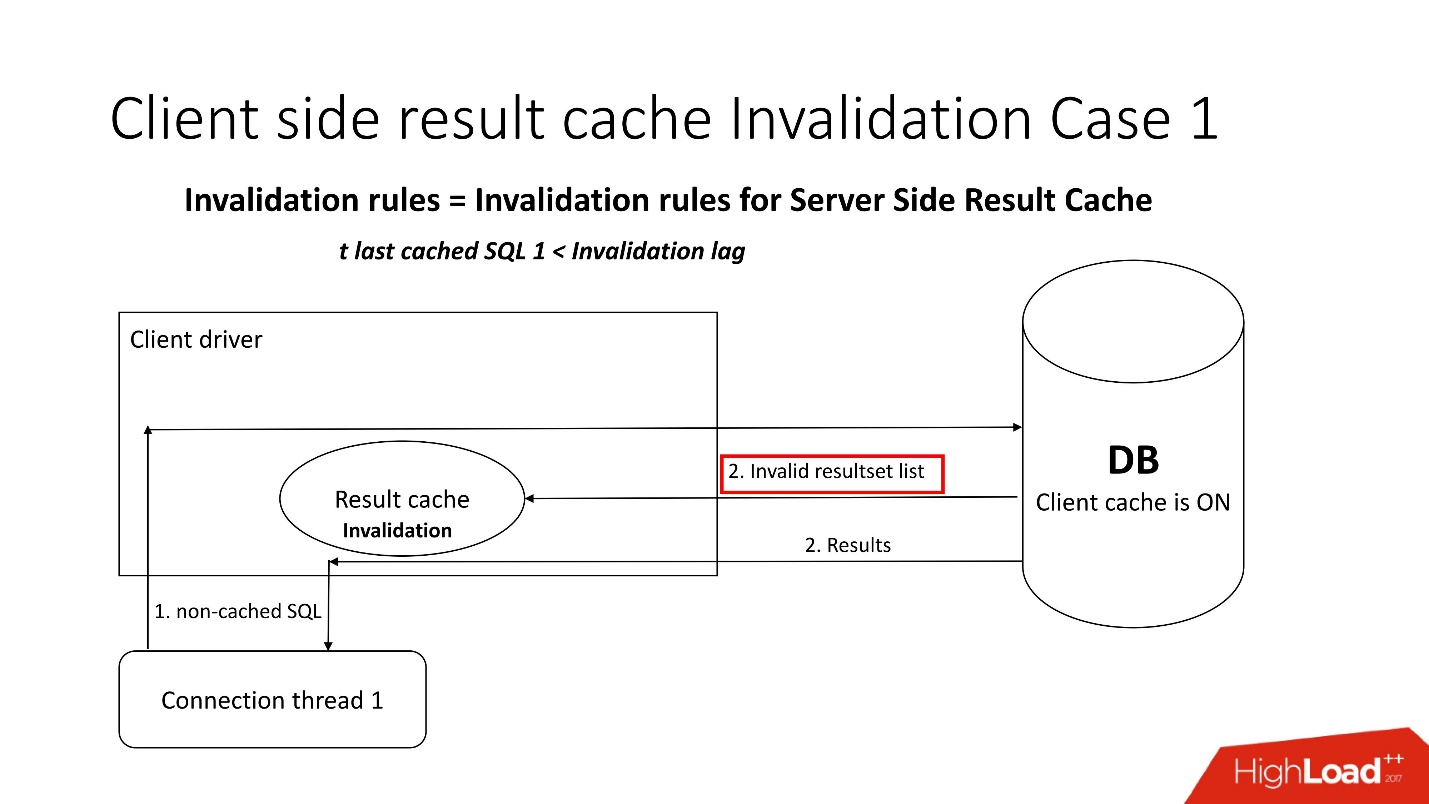
Si le délai d'invalidation échoue, toute demande non mise en cache, faisant référence à la base de données, en plus des résultats de la requête, apporte une liste d'objets non valides. Par conséquent, ils sont marqués comme non valides dans le cache et tout fonctionne comme dans l'image du premier scénario.
Dans le second cas, si plus de temps s'est écoulé que le délai d'invalidation, le client result_cache lui-même va dans la base de données et dit: "Donnez-moi une liste de modifications!" Autrement dit, il maintient lui-même son état adéquat.
La configuration du cache de résultats côté client est très simple . Il y a 2 options:
- CLIENT_RESULT_CACHE_LAG - valeur de décalage du cache;
- CLIENT_RESULT_CACHE_SIZE - taille (minimum 32 Ko, maximum - 2 Go).

Du point de vue du développeur de l'application, le cache client n'est pas très différent du cache serveur, ils ont également entré l'indice result_cache. Si tel est le cas, il commencera à être utilisé par le client - à la fois sur .Net et sur Java.

Après avoir fait 10 itérations de la requête, j'ai obtenu ce qui suit.

Le premier attrait est la création, puis 9 accès au cache. Le tableau indique que la mémoire est également allouée en blocs. Faites également attention à SELECT - ce n'est pas très intuitif. Pour être honnête, avant de commencer à traiter cela, je ne savais même pas qu'il y avait une telle représentation de
GV$SESSION_CONNECT_INFO . Pourquoi Oracle ne l'a pas amené directement à cette table (et c'est une table, pas une vue), je ne pouvais pas comprendre. Mais c'est pourquoi je pense que cette fonctionnalité n'est pas très populaire, même si, il me semble, elle est très utile.
Avantages de la mise en cache client:- mémoire client bon marché;
- tout pilote disponible - JDBC, .NET, etc.;
- impact minimal sur le code d'application.
- Réduction de la charge sur le CPU, les E / S et généralement la base de données;
- pas besoin d'apprendre et d'utiliser toutes sortes de couches de mise en cache intelligente et d'API;
- pas de loquets.
Inconvénients:- cohérence dans la lecture avec un retard - en principe, c'est maintenant une tendance;
- besoin du client Oracle OCI;
- limitation de 2 Go par client, mais en général 2 Go, c'est beaucoup;
- Pour moi personnellement, la principale limitation est un peu d'informations sur la production.
Sur le support, que nous utilisons toujours lorsque nous travaillons avec result_cache, je n'ai trouvé que 5 bugs. Cela suggère que, très probablement, peu de gens en ont besoin.
Donc, nous rassemblons tout ce qui est dit ci-dessus.
Cache fait à la main
Mauvais scénarios:- Changement instantané - si après avoir modifié les données, le cache doit immédiatement devenir non pertinent. Pour les caches créés par vous-même, il est difficile de créer l'invalidation correcte en cas de modification des objets sur lesquels ils sont construits.
- Si l'utilisation de la logique stockée dans la base de données est interdite par les politiques de développement.
Bons scénarios:- Il existe une solide équipe de développement de bases de données.
- Logique PL / SQL implémentée.
- Il existe des limitations qui empêchent l'utilisation d'autres techniques de mise en cache.
Cache des résultats côté serveur
Mauvais scénarios:- Beaucoup de résultats différents qui ne font que laver le cache entier;
- Les demandes prennent plus de temps que _RESULT_CACHE_TIMEOUT ou ce paramètre n'est pas configuré correctement.
- Les résultats de très grandes sessions sont chargés dans le cache dans des threads parallèles.
Bons scénarios:- Quantité raisonnable de résultats mis en cache.
- Ensembles de données relativement petits (200 à 300 lignes).
- SQL assez cher, sinon tout le temps ira aux verrous.
- Tables plus ou moins statiques.
- Il y a un DBA, qui en cas de quelque chose viendra et sauvera tout le monde.
Cache de résultats côté client
Mauvais scénarios:- Lorsque le problème même de l'invalidité instantanée se pose.
- Pilotes fins requis.
Bons scénarios:- Il existe une équipe de développement normale pour la couche intermédiaire.
- Beaucoup de SQL est déjà utilisé sans utiliser une couche de mise en cache externe qui peut être facilement connectée.
- Il y a des restrictions sur les glandes.
Conclusions
Je crois que mon histoire concerne la douleur du cache de résultats côté serveur, donc les conclusions sont les suivantes:
- Évaluez toujours correctement la taille de la mémoire en tenant compte du nombre de requêtes et non du nombre de résultats, c'est-à-dire: blocs, APEX, travail, statistiques adaptatives, etc.
- N'ayez pas peur d'utiliser des options de vidage automatique du cache (instantané + durée de conservation).
- Ne surchargez pas le cache avec des requêtes lors du chargement de grandes quantités de données; désactivez result_cache avant cela. Réchauffez le cache.
- Assurez-vous que _result_cache_timeout répond à vos attentes.
- N'utilisez JAMAIS FORCE pour toute la base de données. Besoin d'une base de données en mémoire - utilisez une solution spécialisée en mémoire.
- Vérifiez si l'option FORCE est utilisée de manière appropriée pour les tables individuelles afin qu'elle ne fonctionne pas comme nous le faisons avec un ETL tiers.
- Décidez si les statistiques adaptatives sont aussi bonnes que celles décrites par Oracle (_optimizer_ads_use_result_cache = false).
Highload ++ Siberia lundi prochain, le planning est prêt et publié sur le site. Il existe plusieurs rapports dans le sujet de cet article:
- Alexander Makarov (CFT GC) présentera une méthode pour identifier les goulots d'étranglement du côté serveur du logiciel en utilisant la base de données Oracle comme exemple.
- Ivan Sharov et Konstantin Poluektov vous diront quels problèmes surviennent lors de la migration du produit vers de nouvelles versions de la base de données Oracle, et promettent également de donner des recommandations sur l'organisation et la réalisation de ces travaux.
- Nikolay Golov vous expliquera comment garantir l'intégrité des données dans une architecture de microservices sans transactions distribuées et connectivité étroite.
Rencontrez-moi à Novossibirsk!