Cet article se concentrera sur certains algorithmes de recherche et descriptions de points d'image spécifiques. Ici, ce sujet a déjà été
soulevé , et plus
d'une fois . Je considérerai que les définitions de base sont déjà familières au lecteur, nous examinerons en détail les algorithmes heuristiques FAST, FAST-9, FAST-ER, BRIEF, rBRIEF, ORB, et discuterons des idées étincelantes qui les sous-tendent. En partie, ce sera une traduction gratuite de l'essence de plusieurs articles [1,2,3,4,5], il y aura un code pour «essayer».

Algorithme FAST
FAST, proposé pour la première fois en 2005 dans [1], a été l'une des premières méthodes heuristiques pour trouver des points singuliers, qui a gagné en popularité en raison de son efficacité de calcul. Pour décider s'il faut considérer un point C donné comme spécial ou non, cette méthode considère la luminosité des pixels sur un cercle centré au point C et au rayon 3:

En comparant la luminosité des pixels du cercle avec la luminosité du centre C, nous obtenons pour chacun trois résultats possibles (plus clair, plus sombre, semble-t-il):
$ inline $ \ begin {array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $ inline $
Ici I est la luminosité des pixels, t est un seuil de luminosité prédéterminé.
Un point est marqué comme spécial s'il y a n = 12 pixels dans une rangée qui sont plus sombres, ou 12 pixels qui sont plus clairs que le centre.
Comme la pratique l'a montré, en moyenne, pour prendre une décision, il a fallu vérifier environ 9 points. Afin d'accélérer le processus, les auteurs ont suggéré de ne vérifier d'abord que quatre pixels avec des nombres: 1, 5, 9, 13. Si parmi eux, il y a 3 pixels plus clairs ou plus foncés, une vérification complète est effectuée sur 16 points, sinon, le point est immédiatement marqué comme " pas spécial. " Cela réduit considérablement le temps de travail, pour prendre une décision en moyenne, il suffit de sonder seulement environ 4 points d'un cercle.
Un peu de code naïf se trouve
iciParamètres variables (décrits dans le code): rayon du cercle (prend les valeurs 1, 2, 3), paramètre n (dans l'original, n = 12), paramètre t. Le code ouvre le fichier in.bmp, traite l'image, l'enregistre dans out.bmp. Les images sont ordinaires en 24 bits.
Construire un arbre de décision, Tree FAST, FAST-9
En 2006, en [2], il a été possible de développer une idée originale en utilisant l'apprentissage automatique et les arbres de décision.
Le FAST d'origine présente les inconvénients suivants:
- Plusieurs pixels adjacents peuvent être marqués comme des points spéciaux. Nous avons besoin d'une certaine mesure de la «force» d'une fonction. L'une des premières mesures proposées est la valeur maximale de t à laquelle le point est toujours considéré comme spécial.
- Un test rapide en 4 points n'est pas généralisé pour n inférieur à 12. Ainsi, par exemple, visuellement, les meilleurs résultats de la méthode sont obtenus avec n = 9, pas 12.
- J'aimerais aussi accélérer l'algorithme!
Au lieu d'utiliser une cascade de deux tests de 4 et 16 points, il est proposé de tout faire en un seul passage dans l'arbre de décision. De manière similaire à la méthode d'origine, nous comparerons la luminosité du point central avec les points du cercle, mais dans cet ordre pour prendre la décision le plus rapidement possible. Et il s'avère que vous pouvez prendre une décision pour seulement ~ 2 (!!!) comparaisons en moyenne.
Le sel est de savoir comment trouver le bon ordre pour comparer les points. Trouvez en utilisant l'apprentissage automatique. Supposons que quelqu'un ait noté pour nous dans l'image beaucoup de points spéciaux. Nous les utiliserons comme un ensemble d'exemples de formation, et l'idée est de choisir
avec empressement celui qui donnera le plus d'informations à cette étape comme point suivant. Par exemple, supposons qu'au départ, dans notre échantillon, il y avait 5 points singuliers et 5 points non singuliers. Sous la forme d'une tablette comme celle-ci:
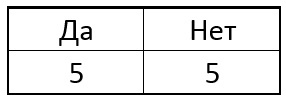
Maintenant, nous choisissons l'un des pixels p du cercle et pour tous les points singuliers, nous comparons le pixel central avec le pixel sélectionné. Selon la luminosité du pixel sélectionné près de chaque point particulier, le tableau peut avoir le résultat suivant:
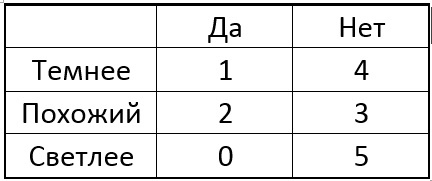
L'idée est de choisir un point p pour que les nombres dans les colonnes du tableau soient aussi différents que possible. Et si maintenant, pour un nouveau point inconnu, nous obtenons le résultat de comparaison «Plus léger», alors nous pouvons déjà dire tout de suite que le point n'est «pas spécial» (voir tableau). Le processus se poursuit de manière récursive jusqu'à ce que les points d'une seule des classes tombent dans chaque groupe après s'être divisés en "plus sombres comme plus clairs". Il s'avère un arbre de la forme suivante:
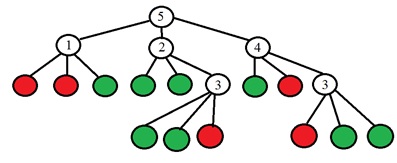
La valeur binaire est dans les feuilles de l'arbre (le rouge est spécial, le vert n'est pas spécial), et aux autres sommets de l'arbre est le numéro du point qui doit être analysé. Plus précisément, dans l'article d'origine, ils proposent de faire un choix du nombre de points en changeant l'entropie. L'entropie de l'ensemble de points est calculée:
$$ afficher $$ H = \ gauche ({c + \ overline c} \ droite) {\ log _2} \ gauche ({c + \ overline c} \ droite) - c {\ log _2} c - \ overline c {\ log _2} \ overline c $$ display $$
c est le nombre de points singuliers,
$ inline $ {\ bar c} $ inline $ Est le nombre de points non singuliers de l'ensemble
Changement d'entropie après le point de traitement p:
$$ afficher $$ \ Delta H = H - {H_ {foncé}} - {H_ {égal}} - {H_ {brillant}} $$ afficher $$
En conséquence, un point est sélectionné pour lequel le changement d'entropie sera maximum. Le processus de division s'arrête lorsque l'entropie est nulle, ce qui signifie que tous les points sont soit singuliers, soit vice versa - tous ne sont pas spéciaux. Avec une implémentation logicielle, après tout cela, l'arbre de décision trouvé est converti en un ensemble de constructions de type "if-else".
La dernière étape de l'algorithme est l'opération de suppression des non-maximums pour en obtenir un à partir de plusieurs points adjacents. Les développeurs suggèrent d'utiliser la mesure d'origine basée sur la somme des différences absolues entre le point central et les points du cercle sous cette forme:
$$ affiche $$ V = \ max \ left ({\ sum \ limits_ {x \ in {S_ {bright}}} {\ left | {{I_x} - {I_p}} \ right | - t, \ sum \ limits_ {x \ in {S_ {dark}}} {\ left | {{I_p} - {I_x}} \ right | - t}}} \ right) $$ display $$
Ici
$ inline $ {S_ {bright}} $ inline $ et
$ inline $ {S_ {dark}} $ inline $ respectivement, les groupes de pixels sont plus clairs et plus sombres, t est la valeur seuil de luminosité,
$ inline $ {I_p} $ inline $ - luminosité du pixel central,
$ inline $ {{I_x}} $ inline $ - luminosité du pixel sur le cercle. Vous pouvez essayer l'algorithme avec le
code suivant . Le code est tiré d'OpenCV et libéré de toutes les dépendances, il suffit de l'exécuter.
Optimiser l'arbre de décision - FAST-ER
FAST-ER [3] est un algorithme des mêmes auteurs que le précédent, un détecteur rapide est construit de manière similaire, la séquence optimale de points est également recherchée pour comparaison, un arbre de décision est également construit, mais en utilisant une méthode différente - la méthode d'optimisation.
Nous comprenons déjà qu'un détecteur peut être représenté comme un arbre de décision. Si nous avions un critère pour comparer les performances de différents arbres, nous pouvons maximiser ce critère en triant différentes variantes d'arbres. Et en tant que tel critère, il est proposé d'utiliser la «répétabilité».
La répétabilité montre à quel point les points singuliers d'une scène sont détectés sous différents angles. Pour une paire d'images, un point est appelé «utile» s'il se trouve sur une trame et peut théoriquement se trouver sur une autre, c'est-à-dire Ne bloquez pas les éléments de la scène. Et le point est appelé "répété" (répété), s'il se trouve également dans la deuxième image. Étant donné que l'optique de la caméra n'est pas idéale, le point sur la deuxième image peut ne pas être dans le pixel calculé, mais quelque part à proximité dans son voisinage. Les développeurs ont pris un quartier de 5 pixels. Nous définissons la répétabilité comme le rapport du nombre de points répétés au nombre de points utiles:
$$ afficher $$ R = \ frac {{{N_ {répété}}}} {{{N_ {utile}}}} $$ afficher $$
Pour trouver le meilleur détecteur, une méthode de simulation de recuit est utilisée. Il y a déjà un
excellent article sur Habré à son sujet. En bref, l'essence de la méthode est la suivante:
- Une solution initiale au problème est sélectionnée (dans notre cas, il s'agit d'une sorte d'arbre de détection).
- La répétabilité est considérée.
- L'arbre est modifié aléatoirement.
- Si la version modifiée est meilleure par le critère de répétabilité, alors la modification est acceptée, et si pire, elle peut être acceptée ou non, avec une certaine probabilité, qui dépend d'un nombre réel appelé "température". À mesure que le nombre d'itérations augmente, la température tombe à zéro.
De plus, la construction du détecteur implique désormais non plus 16 points du cercle, comme auparavant, mais 47, mais la signification ne change pas du tout:

Selon la méthode de recuit simulé, nous définissons trois fonctions:
• Fonction de coût k. Dans notre cas, nous utilisons la répétabilité comme valeur. Mais il y a un problème. Imaginez que tous les points de chacune des deux images soient détectés comme singuliers. Ensuite, il s'avère que la répétabilité est de 100% - l'absurdité. D'un autre côté, même si nous avons trouvé un point particulier sur deux images, et ces points coïncident - la répétabilité est également de 100%, mais cela ne nous intéresse pas non plus. Et donc, les auteurs ont proposé de l'utiliser comme critère de qualité:
$$ afficher $$ k = \ gauche ({1 + {{\ gauche ({\ frac {{{w_r}}} {R}} \ droite)} ^ 2}} \ droite) \ gauche ({1 + \ frac {1} {N} \ sum \ limits_ {i = 1} {{{\ left ({\ frac {{{d_i}}} {{{w_n}}}} right)} ^ 2}}} \ droite) \ gauche ({1 + {{\ gauche ({\ frac {s} {{{w_s}}}} droite)} ^ 2}} \ droite) $$ afficher $$
r est la répétabilité
$ inline $ {{d_i}} $ inline $ Est le nombre d'angles détectés sur l'image i, N est le nombre d'images et s est la taille de l'arbre (nombre de sommets). W sont des paramètres de méthode personnalisés.]
• Fonction du changement de température dans le temps:
$$ display $$ T \ left (I \ right) = \ beta \ exp \ left ({- \ frac {{\ alpha I}} {{{I _ {\ max}}}} \ right) $$ display $$
où
$ inline $ \ alpha, \ beta $ inline $ Sont les coefficients, Imax est le nombre d'itérations.
• Une fonction qui génère une nouvelle solution. L'algorithme apporte des modifications aléatoires à l'arbre. Tout d'abord, sélectionnez un sommet. Si le sommet sélectionné est une feuille d'un arbre, alors avec une probabilité égale nous faisons ce qui suit:
- Remplacez le sommet par un sous-arbre aléatoire de profondeur 1
- Changer la classe de cette feuille (points singuliers-non singuliers)
S'il ne s'agit PAS d'une feuille:
- Remplacez le numéro du point testé par un nombre aléatoire de 0 à 47
- Remplacer le sommet par une feuille avec une classe aléatoire
- Échangez deux sous-arbres de ce sommet
La probabilité P d'accepter le changement à l'itération I est:
$ inline $ P = \ exp \ left ({\ frac {{k \ left ({i - 1} \ right) - k \ left (i \ right)}} {T}} \ right) $ inline $
k est la fonction de coût, T est la température, i est le numéro d'itération.
Ces modifications de l'arbre permettent à la fois la croissance de l'arbre et sa réduction. La méthode est aléatoire, elle ne garantit pas que le meilleur arbre sera obtenu. Exécutez la méthode plusieurs fois, en choisissant la meilleure solution. Dans l'article d'origine, par exemple, ils s'exécutent 100 fois par 100 000 itérations chacun, ce qui prend 200 heures de temps processeur. Comme le montrent les résultats, le résultat est meilleur que Tree FAST, en particulier dans les images bruyantes.
BREF descripteur
Une fois les points singuliers trouvés, leurs descripteurs sont calculés, c'est-à-dire ensembles de caractéristiques caractérisant le voisinage de chaque point singulier. BRIEF [4] est un descripteur heuristique rapide, construit à partir de 256 comparaisons binaires entre la luminosité des pixels dans une image
floue . Le test binaire entre les points x et y est défini comme suit:
$$ afficher $$ \ tau \ gauche ({P, x, y} \ droite): = \ left \ {{\ begin {array} {* {20} {c}} {1: p \ left (x \ droite) <p \ gauche (y \ droite)} \\ {0: p \ gauche (x \ droite) \ ge p \ gauche (y \ droite)} \ end {array}} \ droite. $$ display $$

Dans l'article d'origine, plusieurs méthodes de choix des points pour les comparaisons binaires ont été envisagées. Il s'est avéré que l'un des meilleurs moyens était de sélectionner au hasard des points en utilisant une distribution gaussienne autour d'un pixel central. Cette séquence aléatoire de points est sélectionnée une fois et ne change plus. La taille du voisinage considéré du point est de 31x31 pixels et l'ouverture de flou est de 5.
Le descripteur binaire résultant résiste aux changements d'éclairage, la distorsion de la perspective est rapidement calculé et comparé, mais est très instable à la rotation dans le plan de l'image.
ORB - rapide et efficace
Le développement de toutes ces idées a été l'algorithme ORB (Oriented FAST and Rotated BRIEF) [5], dans lequel une tentative a été faite pour améliorer les performances BRIEF pendant la rotation de l'image. Il est proposé de calculer d'abord l'orientation du point singulier puis d'effectuer des comparaisons binaires conformément à cette orientation. L'algorithme fonctionne comme ceci:
1) Les points caractéristiques sont détectés en utilisant l'arborescence FAST rapide dans l'image d'origine et dans plusieurs images de la pyramide des vignettes.
2) Pour les points détectés, la mesure de Harris est calculée, les candidats avec une faible valeur de la mesure de Harris sont rejetés.
3) L'angle d'orientation du point singulier est calculé. Pour cela, les moments de luminosité pour le voisinage du point singulier sont d'abord calculés:
$ inline $ {m_ {pq}} = \ sum \ limits_ {x, y} {{x ^ p} {y ^ q} I \ left ({x, y} \ right)} $ inline $
x, y - coordonnées pixel, I - luminosité. Et puis l'angle d'orientation du point singulier:
$ inline $ \ theta = {\ rm {atan2}} \ left ({{m_ {01}}, {m_ {10}}} \ right) $ inline $
Tout cela, les auteurs ont appelé «l'orientation centroïde». En conséquence, nous obtenons une certaine direction pour le voisinage du point singulier.
4) Ayant l'angle d'orientation du point singulier, la séquence de points pour les comparaisons binaires dans le descripteur BRIEF tourne selon cet angle, par exemple:
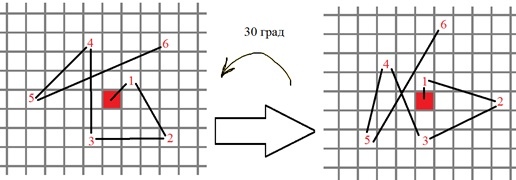
Plus formellement, les nouvelles positions des points de test binaires sont calculées comme suit:
$$ afficher $$ \ gauche ({\ begin {array} {* {20} {c}} {{x_i} '} \\ {{y_i}'} \ end {array}} \ right) = R \ left (\ theta \ right) \ cdot \ left ({\ begin {array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ right) $$ display $$
5) Sur la base des points reçus, le descripteur binaire BRIEF est calculé
Et ce n'est pas tout! Il y a un autre détail intéressant dans ORB qui nécessite une explication séparée. Le fait est qu'au moment où nous «tournons» tous les points singuliers vers un angle nul, le choix aléatoire des comparaisons binaires dans le descripteur cesse d'être aléatoire. Cela conduit au fait que, d'une part, certaines comparaisons binaires s'avèrent dépendantes les unes des autres, et d'autre part, leur moyenne n'est plus égale à 0,5 (1 est plus clair, 0 est plus sombre lorsque le choix était aléatoire, puis la moyenne était 0,5) et tout cela réduit considérablement la capacité du descripteur à distinguer les points singuliers entre eux.
Solution - vous devez sélectionner les tests binaires «corrects» dans le processus d'apprentissage, cette idée souffle la même saveur que la formation d'arbre pour l'algorithme FAST-9. Supposons que nous ayons déjà trouvé un tas de points singuliers. Considérez toutes les options possibles pour les tests binaires. Si le voisinage est 31 x 31 et que le test binaire est une paire de 5 x 5 sous-ensembles (en raison du flou), il existe de nombreuses options pour choisir N = (31-5) ^ 2. L'algorithme de recherche des "bons" tests est le suivant:
- Nous calculons le résultat de tous les tests pour tous les points singuliers
- Organiser l'ensemble des tests en fonction de leur distance à la moyenne 0,5
- Créez une liste qui contiendra les "bons" tests sélectionnés, appelons la liste R.
- Ajouter à R le premier test de l'ensemble trié
- Nous prenons le test suivant et le comparons avec tous les tests de R. Si la corrélation est supérieure au seuil, alors nous rejetons le nouveau test, sinon nous l'ajoutons.
- Répétez l'étape 5 jusqu'à ce que nous tapions le nombre de tests requis.
Il s'avère que les tests sont sélectionnés pour que, d'une part, la valeur moyenne de ces tests soit aussi proche que possible de 0,5, d'autre part, de sorte que la corrélation entre les différents tests soit minimale. Et c'est ce dont nous avons besoin. Comparez comment c'était et comment c'est devenu:
Heureusement, l'algorithme ORB est implémenté dans la bibliothèque OpenCV de la classe cv :: ORB. J'utilise la version 2.4.13. Le constructeur de classe accepte les paramètres suivants:
nfeatures - nombre maximum de points singuliers
scaleFactor - multiplicateur pour la pyramide d'images, plus d'un. La valeur 2 implémente la pyramide classique.
nlevels - le nombre de niveaux dans la pyramide d'images.
edgeThreshold - le nombre de pixels à la frontière de l'image où les points singuliers ne sont pas détectés.
firstLevel - laissez zéro.
WTA_K - le nombre de points requis pour un élément du descripteur. S'il est égal à 2, la luminosité de deux pixels sélectionnés au hasard est comparée. C'est ce qui est nécessaire.
scoreType - si 0, alors harris est utilisé comme mesure caractéristique, sinon - la mesure FAST (basée sur la somme des modules des différences de luminosité aux points du cercle). La mesure FAST est légèrement moins stable, mais plus rapide.
patchSize - la taille du voisinage dans lequel des pixels aléatoires sont sélectionnés pour la comparaison. Le code recherche et compare les points singuliers dans deux images, "templ.bmp" et "img.bmp"
Codecv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
Si quelqu'un a aidé à comprendre l'essence des algorithmes, ce n'est pas en vain. À tous Habr.
Références:
1.
Points de fusion et lignes pour un suivi haute performance2.
Apprentissage automatique pour la détection des virages à grande vitesse3.
Plus rapide et meilleur: une approche d'apprentissage automatique pour la détection des coins4.
BREF: Caractéristiques élémentaires indépendantes robustes binaires5.
ORB: une alternative efficace au SIFT ou au SURF