L'expressivité est une propriété intéressante des langages de programmation. En combinant simplement des expressions, vous pouvez obtenir des résultats impressionnants. Certaines langues rejettent délibérément l'idée d'expressivité, mais Kotlin n'est certainement pas une telle langue.
En utilisant des constructions de langage de base et un peu de sucre, nous essaierons de recréer le SQL dans la syntaxe Kotlin aussi près que possible.

Lien GitHub pour les impatients
Notre objectif est d'aider le programmeur à détecter un sous-ensemble spécifique d'erreurs au stade de la compilation. Kotlin, étant un langage fortement typé, nous aidera à nous débarrasser des expressions invalides dans la structure de la requête SQL. En prime, nous obtiendrons plus de protection contre les fautes de frappe et l'aide de l'IDE dans la rédaction des demandes. Il n'est pas possible de corriger complètement les failles SQL, mais il est tout à fait possible de corriger certaines zones problématiques.
Cet article vous expliquera la bibliothèque Kotlin, qui vous permet d'écrire des requêtes SQL dans la syntaxe Kotlin. De plus, nous jetons un coup d'œil à l'intérieur de la bibliothèque pour comprendre comment cela fonctionne.
Un peu de théorie
SQL signifie Structured Query Language, c'est-à-dire la structure des requêtes est présente, bien que la syntaxe soit médiocre - le langage a été créé pour qu'il puisse être utilisé par tout utilisateur qui n'a même pas de compétences en programmation.
Cependant, sous SQL se trouve une base assez puissante sous la forme de la théorie des bases de données relationnelles - tout y est très logique. Pour comprendre la structure des requêtes, nous nous tournons vers une sélection simple:
SELECT id, name
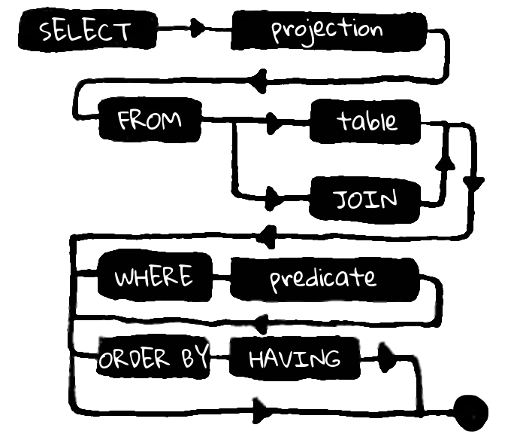
Ce qui est important à comprendre: la demande se compose de trois parties consécutives. Chacune de ces parties, d'une part, dépend de la précédente, et d'autre part, implique un ensemble limité d'expressions pour poursuivre la demande. En fait, ce n'est même pas tout à fait le cas: l'expression FROM est ici clairement primaire par rapport à SELECT, car quel ensemble de champs nous pouvons choisir dépend de la table à partir de laquelle la sélection est faite, mais pas vice versa.
Portage vers Kotlin
Donc, FROM est principal par rapport à toute autre construction de langage de requête. C'est à partir de cette expression que surgissent toutes les options possibles pour poursuivre la requête. Dans Kotlin, nous reflétons cela à travers la fonction from (T), qui prendra un objet d'entrée, qui est une table qui a un ensemble de colonnes.
object Employees : Table("employees") { val id = Column("id") val name = Column("name") val organizationId = Column("organization_id") }
La fonction renverra un objet qui contient des méthodes qui reflètent la poursuite possible de la demande. La construction from vient toujours en premier, avant toute autre expression, elle implique donc un grand nombre d'extensions, y compris le SELECT final (par opposition à SQL, où SELECT vient toujours avant FROM). Le code équivalent à la requête SQL ci-dessus ressemblera à ceci:
from(Employees) .where { e -> e.organizationId eq 1 } .select { e -> e.id .. e.name }
Fait intéressant, de cette manière, nous pouvons empêcher SQL non valide même au moment de la compilation. Chaque expression, chaque appel de méthode dans la chaîne implique un nombre limité d'extensions. Nous pouvons contrôler la validité de la demande en utilisant le langage Kotlin. Par exemple, l'expression where n'implique pas une continuation sous la forme d'une autre où et, en outre, from, mais les groupBy, ayant, les constructeurs orderBy, limit, offset et final select sont tous valides.
Lambdas est passé comme arguments aux instructions where et select, conçues pour construire le prédicat et la projection, respectivement (nous les avons mentionnés plus tôt). Une table est transmise à l'entrée lambda afin que vous puissiez accéder aux colonnes. Il est important que la sécurité des types soit également maintenue à ce niveau - avec l'aide de la surcharge de l'opérateur, nous pouvons nous assurer que le prédicat sera finalement une expression pseudo-booléenne qui ne peut pas être compilée s'il y a une erreur de syntaxe ou une erreur liée au type. Il en va de même pour la projection.
fun where(predicate: (T) -> Predicate): WhereClause<T> fun select(projection: (T) -> Iterable<Projection>): SelectStatement<T>
Rejoignez
Les bases de données relationnelles vous permettent de travailler avec de nombreuses tables et les relations entre elles. Ce serait bien de donner au développeur l'opportunité de travailler avec JOIN dans notre bibliothèque. Heureusement, le modèle relationnel correspond bien à tout ce qui a été décrit précédemment - il vous suffit d'ajouter la méthode join, qui ajoutera un deuxième tableau à notre expression.
fun <T2: Table> join(table2: T2): JoinClause<T, T2>
JOIN, dans ce cas, aura des méthodes similaires à celles fournies par l'expression FROM, à la seule différence que les lambdas de projection et de prédicat prendront chacun deux paramètres pour pouvoir accéder aux colonnes des deux tables.
from(Employees) .join(Organizations).on { e, o -> o.id eq e.organizationId } .where { e, o -> e.organizationId eq 1 } .select { e, o -> e.id .. e.name .. o.name }
Gestion des données
Le langage de manipulation de données est un outil de langage SQL qui, en plus d'interroger des tables, vous permet d'insérer, de modifier et de supprimer des données. Ces modèles correspondent bien à notre modèle. Pour prendre en charge la mise à jour et la suppression, il suffit de compléter les expressions from et where par une variante avec l'appel des méthodes correspondantes. Pour prendre en charge l'insertion, nous introduisons une fonction supplémentaire.
from(Employees) .where { e -> e.id eq 1 } .update { e -> e.name("John Doe") } from(Employees) .where { e -> e.id eq 0 } .delete() into(Employees) .insert { e -> e.name("John Doe") .. e.organizationId(1) }
Description des données
SQL fonctionne avec des données structurées sous forme de tables. Les tableaux nécessitent une description avant de travailler avec eux. Cette partie du langage est appelée langage de définition de données.
Les instructions CREATE TABLE et DROP TABLE sont implémentées de manière similaire - la fonction over servira de point de départ.
over(Employees) .create { integer(it.id).primaryKey(autoIncrement = true).. text(it.name).unique().notNull().. integer(it.organizationId).foreignKey(references = Organizations.id) }
over(Employees).drop()