Après avoir lu l'article "
Google Neural Machine Translation ", je me suis souvenu de la dernière traduction automatique à échec épique de Google exécutée récemment sur Internet. Qui ne peut pas attendre beaucoup, nous revenons immédiatement au bas de l'article.
Eh bien, pour commencer, un peu de théorie:
GNMT est le système de traduction automatique neuronale (
NMT ) de Google qui utilise un réseau neuronal (
ANN ) pour augmenter la précision et la vitesse de traduction, et en particulier pour créer de meilleures options de traduction plus naturelles pour le texte dans Google Translate.
Dans le cas de GNMT, il s'agit de la méthode dite de traduction basée sur des
exemples (
EBMT ), c'est-à-dire
L'ANN qui sous-tend la méthode apprend à partir de millions d'exemples de traduction, et contrairement à d'autres systèmes, cette méthode permet la
traduction dite
zéro , c'est-à-dire la traduction d'une langue à une autre sans exemples explicites pour cette paire de langues spécifiques. dans le processus d'apprentissage (dans l'échantillon de formation).
 Fig. 1. Traduction Zero-Shot
Fig. 1. Traduction Zero-ShotDe plus, GNMT est conçu principalement pour améliorer la traduction des phrases et des phrases, car juste dans la traduction contextuelle, vous ne pouvez pas utiliser la version littérale de la traduction, et souvent la phrase est traduite complètement différemment.
De plus, en revenant à la traduction zéro, Google essaie de mettre en évidence un composant commun qui est valide pour plusieurs langues à la fois (à la fois lors de la recherche de dépendances et lors de la création de relations pour les phrases et les expressions).
Par exemple, dans la figure 2, cette «communauté» interlingua est représentée parmi toutes les paires possibles pour le japonais, le coréen et l'anglais.
 Fig. 2. Interlingua. Présentation tridimensionnelle des données réseau pour le japonais, le coréen et l'anglais
Fig. 2. Interlingua. Présentation tridimensionnelle des données réseau pour le japonais, le coréen et l'anglais .
La partie (a) montre la "géométrie" générale de ces traductions, où les points sont colorés par le sens (et la même couleur pour le même sens dans plusieurs paires de langues).
La partie (b) montre une augmentation dans l'un des groupes, la partie © aux couleurs de la langue d'origine.
GNMT utilise le grand apprentissage en profondeur
ANN (
DNN ), qui, tiré de millions d'exemples, devrait améliorer la qualité de la traduction, en appliquant une approximation abstraite contextuelle pour l'option de traduction la plus appropriée. En gros, il choisit le meilleur résultat, dans le sens de la grammaire la plus appropriée du langage humain, tout en tenant compte de la communauté de construction de liens, de phrases et de phrases pour plusieurs langues (c'est-à-dire en mettant en évidence et en enseignant séparément le modèle ou les couches interlingua).
Cependant, DNN, à la fois dans le processus d'apprentissage et dans le processus de travail, s'appuie généralement sur l'inférence statistique (probabiliste) et est rarement lié par des algorithmes supplémentaires non probabilistes. C'est-à-dire Pour évaluer le meilleur résultat possible qui est sorti du variateur, l'option statistiquement la meilleure (probable) sera sélectionnée.
Tout cela, naturellement, dépend en outre de la qualité de l'échantillon d'apprentissage (et / ou de la qualité des algorithmes dans le cas d'un modèle d'auto-apprentissage).
Étant donné la méthode de traduction zéro et en se souvenant d'un composant commun (interlingua), en présence d'une connexion profonde logique positive pour une langue et de l'absence de composants négatifs pour d'autres langues, une erreur abstraite est apparue dans le processus d'apprentissage et, par conséquent, la traduction d'une certaine phrase pour une langue sera très probablement répétée pour d'autres langues ou même des paires de langues.
Échec épique réellement frais
Toutes les images sont cliquables (comme preuve sur la page Google Translate correspondante).Allemand: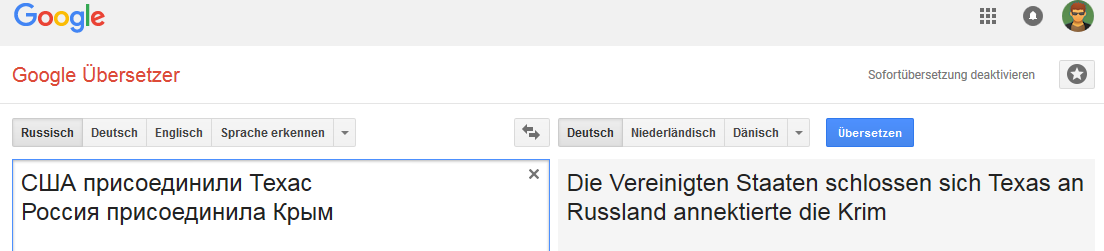 Anglais:
Anglais: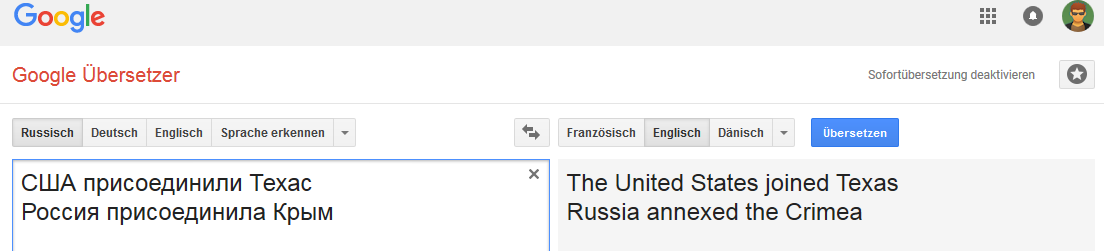 Néerlandais:
Néerlandais: Danois:
Danois: Français:
Français:
Etc.
Au lieu d'une conclusion
La connexion est stable pour le mot Russie (en ce sens que lorsque la Russie est remplacée, par exemple, par l'Empire russe, l'option de «transfert» change).
Et ce n'est pas très stable avec certains changements de phrases qui ne sont pas typiques de la traduction en anglais, mais communs, par exemple, pour le russe, l'allemand et le néerlandais.
Ceci est malheureusement loin d'être le seul cas et Internet regorge de toutes sortes d'erreurs Google Translate.
Et il me semble qu'une partie considérable des erreurs existantes se manifeste en raison d'une combinaison de plusieurs facteurs, allant de la qualité de l'échantillon d'apprentissage à la qualité des algorithmes d'analyse sémantique et morphologique pour une langue particulière (et le modèle d'apprentissage en particulier).
Une fois, un collègue a suggéré de participer au Google Text Normalization Challenge (pour le russe et l'anglais) sur kaggle ...
Avant d'accepter, j'ai ensuite fait une petite analyse de la qualité de l'échantillon de test de formation pour toutes les classes de jetons pour les deux langues ... et en conséquence j'ai refusé de participer du tout, car plus j'en creusais, plus le sentiment que la compétition serait comme une loterie ou que celui qui gagner gagnerait gagnerait le plus précisément sera en mesure de répéter toutes les erreurs commises lors de la création semi-manuelle de l'ensemble de formation Google.
J'ai même voulu écrire un article sur le sujet "Comment lancer facilement 50K ...", mais le temps - que ce soit bien.
Si quelqu'un est soudain intéressé - je vais essayer de me tailler un peu.
[UPD] Pourquoi est-ce en fait un fichier. Sans être distrait par les paroles, le sous-texte «politique» et toutes sortes de tentatives pour justifier «une personne traduirait ainsi», etc.
1. Il s'agit d'une mauvaise traduction. Le point.
2. Dans ce cas illustratif, GNMT montre une absence totale de tout modèle de classification (au sens de
CADM , dans lequel Google doit briller, car ils ont beaucoup de données de partout). Dans la mesure où les sujets dans les deux cas sont des pays / états, et les suppléments sont des entités géographiques (territoire).
Même la règle de plausibilité la plus stupide d'une classification floue de K-nn n'aurait jamais fait une telle erreur. Nous sommes déjà silencieux sur les algorithmes modernes de classification et de construction des relations (sémantiques).
Comme le dicton n'a rien de personnel, de simples calculs ... Eh bien, si Google a décidé sans discernement d'alimenter son réseau avec des coupures de presse des tabloïdes, alors j'ai de mauvaises nouvelles pour lui.
PS Cependant, comme un professeur que j'ai respecté m'a dit un jour: "Il est parfois très difficile de prouver à un pic qu'il est un pic, surtout s'il est sûr qu'il est plus intelligent qu'un professeur."