
Bonjour, Habr! Je m’appelle Alexey Pristavko, je suis directeur des projets Web chez DataLine. Mon article d'aujourd'hui porte sur la façon de résoudre ou d'éviter les problèmes de performances des applications Web.
Cela se concentrera sur la façon d'optimiser les applications Web qui souffrent de problèmes chroniques d'évolutivité, de performances ou de fiabilité.
Toute personne intéressée - bienvenue sous la coupe!
Terminologie
Commençons par regarder la terminologie. Parlant de la performance des projets Web ou des systèmes Web, je veux dire principalement le back-end et le composant serveur. Ce qui se passe lors du chargement des pages dans un navigateur est une histoire complètement différente, qui, très probablement, sera consacrée à un article séparé.
- La mesure des performances de l' application sera le nombre de requêtes traitées par seconde (RPS) et leur vitesse d'exécution (TTFB - Time to First Byte).
- Par conséquent, par évolutivité du système, nous entendons un ensemble d'opportunités pour augmenter le RPS.
Maintenant sur la fiabilité. Ici, il est nécessaire de séparer deux concepts: la tolérance aux pannes et la tolérance aux catastrophes.
- Résilience aux défaillances - la capacité d'un système à échouer si un ou plusieurs serveurs ne parviennent pas à continuer de fonctionner dans les paramètres requis.
- Les systèmes avec une redondance de sauvegarde complète (ce que l'on appelle la deuxième épaule) et capables de fonctionner sans une forte panne avec la défaillance complète de l'un des centres de données sont considérés comme résistants aux catastrophes .
Dans le même temps, un système tolérant aux catastrophes est un système à sécurité intégrée. Une situation dans laquelle un système tolérant aux catastrophes, mais pas tolérant aux pannes continue de fonctionner sur une seule «épaule» est tout à fait normale. Mais si l'un des serveurs tombe en panne, le système échouera également.
Maintenant que nous avons compris les concepts clés et actualisé la terminologie actuelle, il est temps de passer directement aux bases de l'optimisation et des hacks de vie.
Par où commencer l'optimisation

Comment comprendre par où commencer l'optimisation? Avant de vous précipiter pour optimiser, respirez profondément et passez du temps à rechercher l'application.
Assurez-vous de dessiner un diagramme détaillé. Affichez dessus tous les composants de l'application et leurs relations. Après avoir examiné ce schéma, vous pouvez découvrir des vulnérabilités jusque-là discrètes et des points de défaillance potentiels.
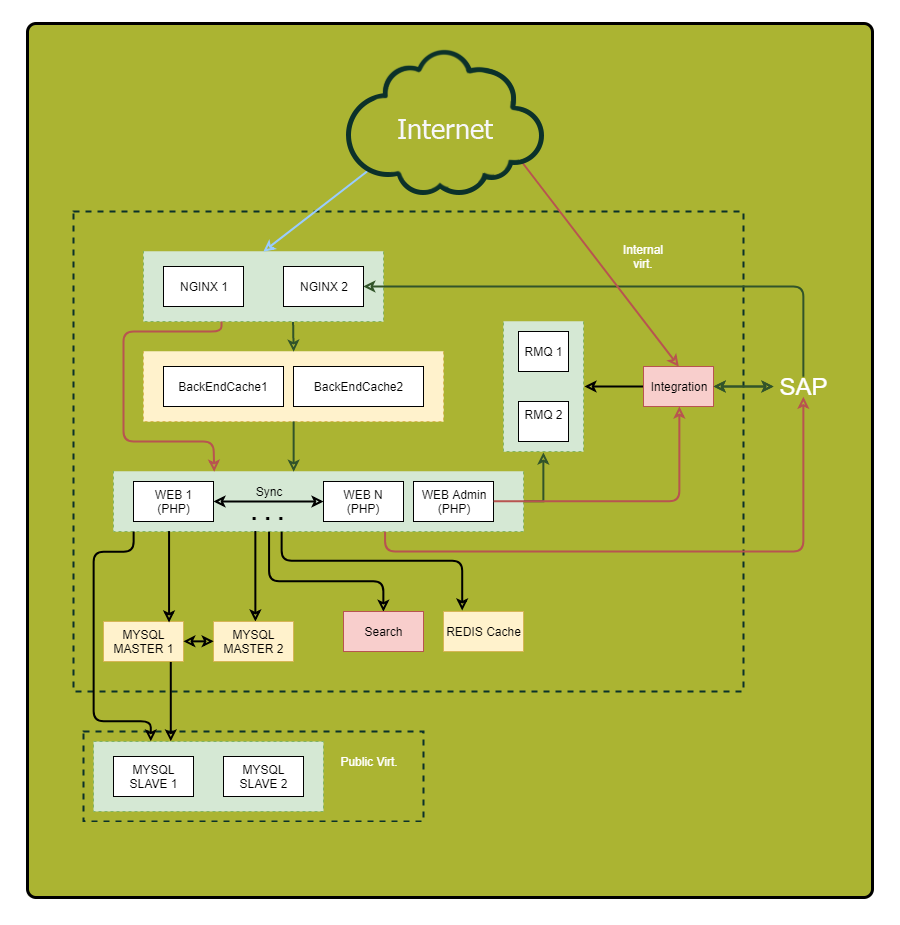
«Quoi? O?? Quand? " - optimiser les requêtes
Portez une attention particulière aux demandes synchrones. Permettez-moi de vous rappeler que ce sont de telles demandes lorsque nous envoyons une demande dans le même fil et attendons une réponse. C'est là que se trouvent les raisons des graves freins lorsque quelque chose ne va pas de l'autre côté. Par conséquent, si vous pouvez réduire le nombre de demandes synchrones ou les remplacer par des demandes asynchrones, faites-le.
Voici quelques astuces pour vous aider à suivre vos demandes:
- Attribuez un identifiant unique à chaque demande entrante. Nginx a une variable intégrée $ request_id pour cela. Passez l'identifiant dans les en-têtes du back-end et écrivez dans tous les journaux. Ainsi, vous pouvez facilement suivre les demandes.
- Enregistrez non seulement la fin de la demande sur le composant externe, mais également son début. Vous mesurez donc la durée réelle de l'appel externe. Il peut différer considérablement de ce que vous voyez sur le système distant, par exemple, en raison de problèmes de réseau ou de freins DNS.
Ainsi, les données sont collectées. Analysons maintenant les points problématiques. Définissez:
- Où passe le plus de temps?
- D'où viennent la plupart des demandes?
- D'où viennent les demandes les plus longues?
En conséquence, vous obtiendrez une liste des sections les plus intéressantes du système pour l'optimisation.
Astuce: si un point "collecte" un grand nombre de petites requêtes, essayez de les combiner en une seule grande requête pour réduire les frais généraux. Les résultats de longues requêtes ont souvent un sens dans le cache.
Nous cachons judicieusement
Il existe des règles générales de mise en cache sur lesquelles vous devez vous baser lors de l'optimisation:
- Plus le cache est proche du consommateur, plus la tâche est rapide. Pour l'application, l'endroit «le plus proche» sera RAM. Pour l'utilisateur, son navigateur.
- La mise en cache accélère l'acquisition des données et réduit la charge sur la source.
Si dix serveurs Web effectuent les mêmes requêtes de base de données, un cache intermédiaire centralisé, par exemple dans Redis, donnera un pourcentage plus élevé de hits (par rapport au cache local) et réduira la charge globale sur la base de données, ce qui améliorera considérablement l'image globale.
Astuce 1: effectuez la mise en cache des composants de la page finie du côté Nginx à l'aide de Edge Side Include. Il s'intègre bien à l'architecture microservice / SOA et décharge le système dans son ensemble, améliorant considérablement la vitesse de réponse.
Astuce 2: Gardez une trace de la taille des objets dans le cache, du taux d'accès et des volumes d'écriture / lecture. Plus l'objet est grand, plus il faudra de temps pour le traiter. Si vous écrivez dans le cache plus souvent ou plus que vous lisez, un tel cache n'est pas votre ami. Il vaut la peine d'enlever ou d'envisager d'augmenter son efficacité.
Astuce 3: Utilisez vos propres caches de base de données dans la mesure du possible. Une configuration appropriée peut accélérer le travail.
Profils de charge
Nous passons pour charger des profils. Comme vous le savez, il existe deux types principaux: OLAP et OLTP.
- Pour OLAP (Online Analytical Processing), la quantité de trafic dépensée par seconde est importante.
- Pour OLTP (Online Transaction Processing), l'indicateur clé est la vitesse de réponse, les délais en millisecondes.
Le plus souvent, il est efficace de séparer ces deux types de charges. Au minimum, vous aurez besoin d'un réglage séparé de la base de données et, éventuellement, d'autres composants du système.
Conseil: Les demandes de lecture du panneau d'administration sont généralement traitées à l'aide du type OLAP. Créez une copie distincte de la base de données et un serveur Web pour cette tâche afin de décharger le système principal.
Bases de données

Nous avons donc naturellement abordé l'une des étapes les plus difficiles de l'optimisation, à savoir l'optimisation de la base de données.
Permettez-moi de vous rappeler la règle générale: plus la base de données est petite, plus elle fonctionne rapidement. L'organisation même de la base de données est cruciale en matière de rapidité.
Si possible, stockez
les données historiques , les journaux d'application et
les données
fréquemment utilisées dans différentes bases de données. Mieux encore, publiez-les sur différents serveurs. Cela facilitera non seulement la vie de la base de données principale, mais donnera également plus d'espace pour une optimisation supplémentaire, par exemple, dans certains cas, cela permettra d'utiliser différents index pour différentes charges. De plus, «l'uniformité» de la charge simplifie la vie du planificateur et de l'optimiseur de requêtes du serveur de base de données.
Et encore une fois sur l'importance de la planification
Afin de ne pas dérouter l'optimisation là où elle n'est pas vraiment nécessaire, choisissez du matériel en fonction des tâches.
- Pour les demandes petites mais fréquentes, il est préférable de prendre plus de cœurs de processeur.
- Pour les demandes lourdes - moins de cœurs avec une vitesse d'horloge plus élevée.
Essayez de mettre le volume de travail de la base de données dans la RAM. Si cela n’est pas possible ou qu’il existe un grand nombre de demandes d’écriture, il est temps de se tourner vers le transfert des bases de données vers les disques SSD. Ils donneront une augmentation significative de la vitesse de travail avec le disque.
Mise à l'échelle

Ci-dessus, j'ai décrit les mécanismes clés de l'amélioration des performances des applications sans augmenter leurs ressources physiques.
Nous allons maintenant parler de la façon de choisir une stratégie de mise à l'échelle et d'augmenter la résilience.
Il existe deux types de mise à l'échelle du système:
- vertical - la croissance des ressources tout en maintenant le nombre d'entités;
- horizontal - une augmentation du nombre d'entités.
Grandir
Commençons par choisir une stratégie de mise à l'échelle verticale.
Considérons d'abord l'
augmentation de la puissance du système . Si votre système fonctionne sur un seul serveur, vous devrez choisir entre augmenter la capacité du serveur actuel ou en acheter un autre.
Il peut sembler que la première option est plus facile et plus sûre. Mais il sera plus clairvoyant d'acheter un serveur de plus et de recevoir une grande tolérance aux pannes en bonus à la productivité. J'en ai parlé au début de l'article.
Si votre système possède plusieurs serveurs et que le choix est d'augmenter la capacité des serveurs existants ou d'en acheter d'autres, faites attention au côté financier. Par exemple, un serveur puissant peut coûter plus cher que deux serveurs 50% «plus faibles». Par conséquent, il sera raisonnable de s’attarder sur la deuxième option de compromis. Dans le même temps, avec un grand nombre de serveurs, le rapport entre performances, consommation électrique et coût d'un rack complet est crucial.
Grandir
La mise à l'échelle horizontale est une histoire de tolérance aux pannes et de clustering. Dans le cas général, plus nous avons d'instances d'une entité, plus la tolérance aux pannes de l'ensemble de la solution est élevée.
La première chose que vous souhaitez probablement mettre à l'échelle est probablement les
serveurs d'applications . Le premier obstacle à cela est l'organisation du travail avec des sources de données centralisées. En plus des bases de données, il s'agit également de données de session et de contenu statique. Voici ce que je vous recommande de faire:
- Pour stocker des sessions, utilisez Couchbase, pas le Memcached habituel, car il fonctionne avec le même protocole, mais, contrairement à Memcached, il prend en charge le clustering.
- Toutes les statistiques , en particulier les gros volumes d'images et de documents, sont stockées séparément et servies à l'aide de Nginx, et non à partir du code d'application. Cela vous fera économiser de l'argent sur les flux et simplifiera la gestion de l'infrastructure.
«Tirer» la base de données
Difficile de faire évoluer les bases de données. Il existe deux techniques principales pour cela: le partitionnement et la réplication. Considérez-les.
Lors de la
réplication, nous ajoutons des copies complètement identiques de la base de données au système, tout en
partageant , les parties logiquement séparées, les fragments. Dans le même temps, il est hautement souhaitable d'effectuer un sharding en parallèle avec la réplication (réplication) de chaque fragment afin de ne pas perdre la tolérance aux pannes.
N'oubliez pas: souvent, un cluster de base de données se compose d'un nœud maître qui prend en charge le flux d'écriture et de plusieurs nœuds esclaves utilisés pour la lecture. Du point de vue de la tolérance aux pannes, cela est légèrement meilleur qu'un seul serveur, car la tolérance aux pannes globale est déterminée par l'élément le moins stable du système.
Les schémas avec plus de deux assistants de base de données (topologie en anneau) sans confirmation de l'enregistrement sur chaque serveur, souffrent très souvent d'incohérence. En cas de panne d'un des serveurs, il sera extrêmement difficile de restaurer l'intégrité logique des données du cluster.
Conseil: Si dans votre cas, il n'est pas rationnel d'avoir plusieurs serveurs maîtres, envisagez la possibilité architecturale du système de fonctionner sans maître pendant au moins une heure. En cas d'accident, cela vous donnera le temps de remplacer le serveur sans temps d'arrêt de l'ensemble du système.
Conseil: Si vous devez conserver plus de 2 maîtres de base de données, je vous recommande d'envisager des solutions NoSQL, car beaucoup d'entre elles ont des mécanismes intégrés pour mettre les données dans un état cohérent.
Dans la poursuite de la tolérance aux pannes, n'oubliez en aucun cas que la réplication vous assure
uniquement contre les pannes physiques du serveur . Il ne sera pas enregistré contre la corruption des données logiques en raison d'une erreur de l'utilisateur.
N'oubliez pas: toutes les données importantes doivent être sauvegardées et stockées sous forme de copie indépendante et non modifiable.
Au lieu d'une conclusion
Enfin, quelques conseils de performance pour la sauvegarde:
Astuce 1: extrayez les données d'une réplique de base de données distincte afin de ne pas surcharger le serveur actif.
Astuce 2: Ayez sous la main une réplique supplémentaire, légèrement "en retard" de la base de données. En cas d'accident, cela contribuera à réduire la quantité de données perdues.
Les méthodes et techniques présentées dans cet article ne doivent jamais être utilisées à l'aveuglette, sans analyser la situation actuelle et comprendre ce que vous souhaitez réaliser. Vous pouvez rencontrer une «sur-optimisation» et le système résultant ne sera que 10% plus rapide, mais 50% plus vulnérable aux accidents.
C’est tout. Si vous avez des questions, je me ferai un plaisir d'y répondre dans les commentaires.