Lors du Data Festival 2 à Minsk, Vladimir Iglovikov, ingénieur en vision industrielle à Lyft, a
parfaitement remarqué que la meilleure façon d'apprendre la Data Science est de participer à des concours, d'exécuter des solutions d'autres personnes, de les combiner, d'obtenir des résultats et de montrer votre travail. En fait, dans le cadre de ce paradigme, j'ai décidé d'examiner de plus près le
concours d' évaluation du risque de crédit pour le crédit immobilier et d'expliquer (aux débutants, aux scientifiques et tout d'abord à moi-même) comment analyser correctement ces ensembles de données et construire des modèles pour eux.
(photo
d'ici )

Home Credit Group est un groupe de banques et d'organisations de crédit non bancaires qui mène des opérations dans 11 pays (dont la Russie sous le nom de Home Credit and Finance Bank LLC). Le but du concours est de créer une méthodologie pour évaluer la solvabilité des emprunteurs qui n'ont pas d'antécédents de crédit. Ce qui semble plutôt noble - les emprunteurs de cette catégorie ne peuvent souvent pas obtenir de crédit de la banque et sont obligés de se tourner vers des escrocs et des microcrédits. Il est intéressant que le client ne fixe pas d'exigences de transparence et d'interprétabilité du modèle (comme c'est généralement le cas avec les banques), vous pouvez utiliser n'importe quoi, même un réseau de neurones.
L'échantillon de formation se compose de 300+ milliers d'enregistrements, il y a beaucoup de signes - 122, parmi eux, il y en a de nombreux catégoriques (non numériques). Les panneaux décrivent l'emprunteur avec suffisamment de détails, jusque dans le matériau dont sont faits les murs de sa maison. Une partie des données est contenue dans 6 tableaux supplémentaires (données sur le bureau de crédit, solde de carte de crédit et prêts antérieurs), ces données doivent également être traitées d'une manière ou d'une autre et chargées dans les principales.
Le concours ressemble à une tâche de classification standard (1 dans le champ CIBLE signifie toute difficulté de paiement, 0 signifie aucune difficulté). Cependant, ce n'est pas 0/1 qui devrait être prédit, mais la probabilité de problèmes (qui, incidemment, peut être facilement résolue par les méthodes de prédiction de probabilité Predict_Proba que tous les modèles complexes ont).
À première vue, l'ensemble de données est assez standard pour les tâches d'apprentissage automatique, les organisateurs ont offert un gros lot de 70 000 $, en conséquence, plus de 2600 équipes participent à la compétition aujourd'hui, et la bataille est en millièmes de pour cent. Cependant, d'autre part, une telle popularité signifie que l'ensemble de données a été étudié de haut en bas et de nombreux noyaux ont été créés avec une bonne EDA (Exploratory Data Analisys - recherche et analyse des données dans le réseau, y compris graphiques), Ingénierie des fonctionnalités (travail avec des attributs) et avec des modèles intéressants. (Le noyau est un exemple de travail avec un ensemble de données que n'importe qui peut disposer pour montrer son travail à d'autres kugglers.)
Les grains méritent l'attention:
Pour travailler avec des données, le plan suivant est généralement recommandé, que nous essaierons de suivre.
- Comprendre le problème et se familiariser avec les données
- Nettoyage et formatage des données
- EDA
- Modèle de base
- Amélioration du modèle
- Interprétation du modèle
Dans ce cas, vous devez tenir compte du fait que les données sont assez étendues et ne peuvent pas être maîtrisées immédiatement, il est logique d'agir par étapes.
Commençons par importer les bibliothèques dont nous avons besoin en analyse pour travailler avec des données sous forme de tableaux, construire des graphiques et travailler avec des matrices.
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
Téléchargez les données. Voyons voir ce que nous avons tous. Cet emplacement dans le répertoire "../input/", soit dit en passant, est lié à l'exigence de placer vos noyaux sur Kaggle.
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']Il y a 8 tables avec des données (sans compter la table HomeCredit_columns_description.csv, qui contient une description des champs), qui sont interconnectées comme suit:
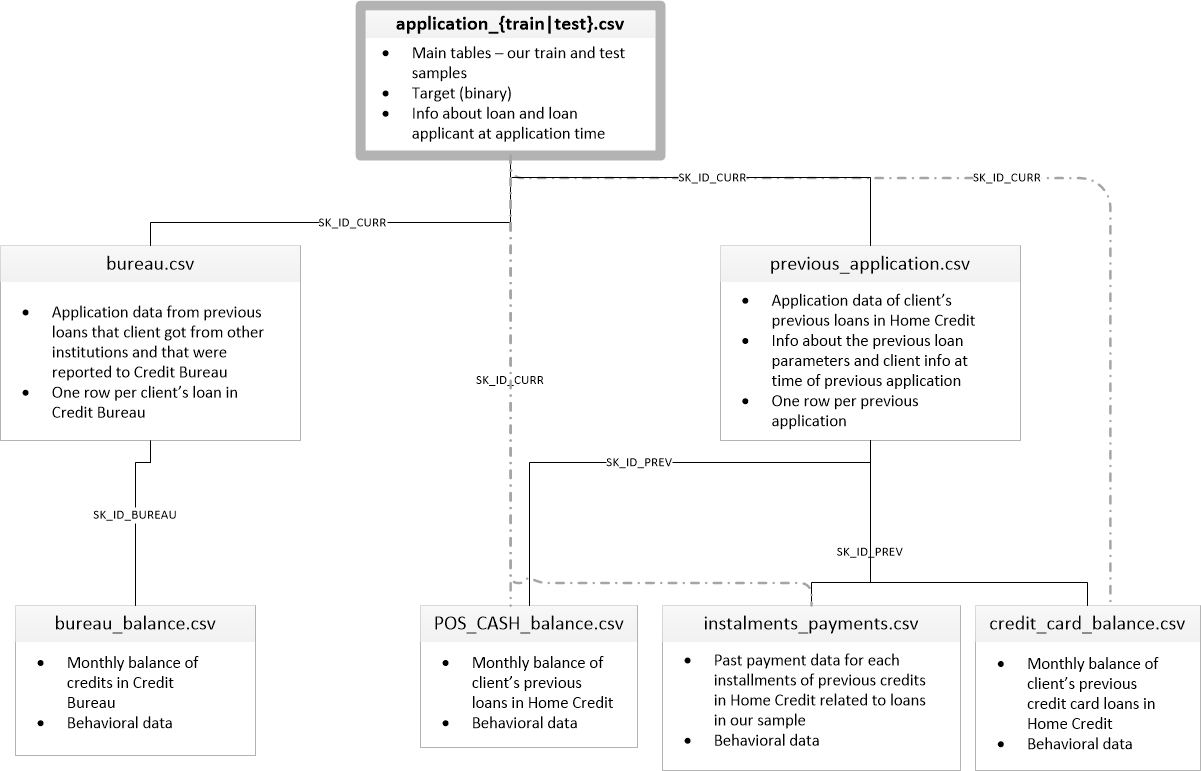
application_train / application_test: données de base, l'emprunteur est identifié par le champ SK_ID_CURR
bureau: données sur les prêts antérieurs d'autres établissements de crédit d'un bureau de crédit
bureau_balance: données mensuelles sur les prêts antérieurs du bureau. Chaque ligne correspond au mois d'utilisation du prêt
previous_application: Demandes précédentes de prêts en crédit immobilier, chacune a un champ unique SK_ID_PREV
POS_CASH_BALANCE: données mensuelles sur les crédits en crédit immobilier avec émission de liquidités et crédits pour l'achat de biens
credit_card_balance: données mensuelles du solde de la carte de crédit dans le crédit à domicile
installments_payment: historique des paiements des prêts précédents au crédit à domicile.
Concentrons-nous d'abord sur la principale source de données et voyons quelles informations peuvent en être extraites et quels modèles construire. Téléchargez les données de base.
- app_train = pd.read_csv (CHEMIN + 'application_train.csv',)
- app_test = pd.read_csv (CHEMIN + 'application_test.csv',)
- print ("format de l'ensemble de formation:", app_train.shape)
- print ("test sample format:", app_test.shape)
- format d'exemple de formation: (307511, 122)
- format de l'échantillon de test: (48744, 121)
Au total, nous avons 307 000 enregistrements et 122 signes dans l'échantillon de formation et 49 000 enregistrements et 121 signes dans le test. L'écart est évidemment dû au fait qu'il n'y a pas d'attribut cible TARGET dans l'échantillon de test, et nous le prédirons.
Examinons de plus près les données
pd.set_option('display.max_columns', None)
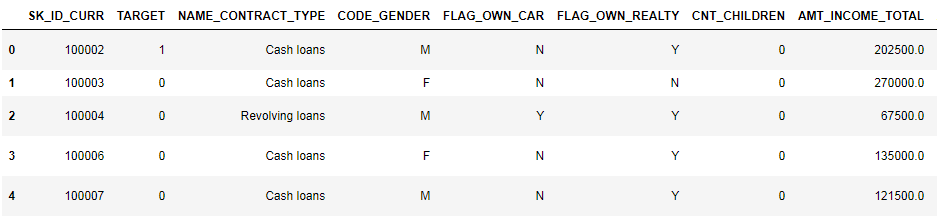
(8 premières colonnes affichées)
Il est assez difficile de regarder des données dans ce format. Regardons la liste des colonnes:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBRappelez les annotations détaillées par champ dans le fichier HomeCredit_columns_description. Comme vous pouvez le voir dans les informations, une partie des données est incomplète et une partie est catégorique, elles sont affichées en tant qu'objet. La plupart des modèles ne fonctionnent pas avec de telles données, nous devrons en faire quelque chose. Sur ce point, l'analyse initiale peut être considérée comme terminée, nous irons directement à EDA
Analyse exploratoire des données ou exploration de données primaires
Dans le processus EDA, nous comptons les statistiques de base et dessinons des graphiques pour trouver les tendances, les anomalies, les modèles et les relations dans les données. L'objectif d'EDA est de découvrir ce que les données peuvent révéler. En règle générale, l'analyse va de haut en bas - d'un aperçu général à l'étude des zones individuelles qui attirent l'attention et peuvent être intéressantes. Par la suite, ces résultats peuvent être utilisés dans la construction du modèle, la sélection des caractéristiques pour celui-ci et dans son interprétation.
Distribution variable cible
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
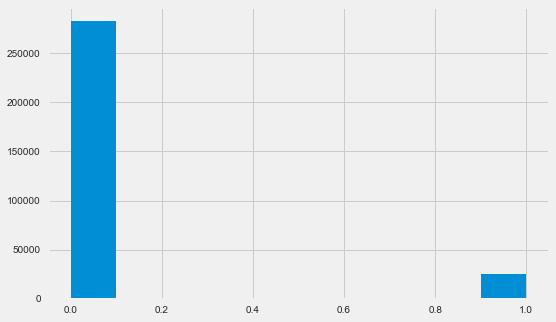
Permettez-moi de vous rappeler que 1 signifie des problèmes de toute nature avec un retour, 0 signifie aucun problème. Comme vous pouvez le constater, principalement les emprunteurs n'ont aucun problème de remboursement, la part des problématiques est d'environ 8%. Cela signifie que les classes ne sont pas équilibrées et cela peut devoir être pris en compte lors de la construction du modèle.
Recherche de données manquantes
Nous avons vu que le manque de données est assez important. Voyons plus en détail où et ce qui manque.
122 .
67 .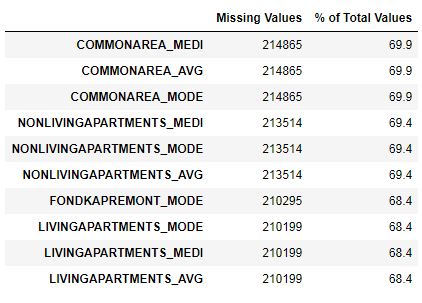
Au format graphique:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
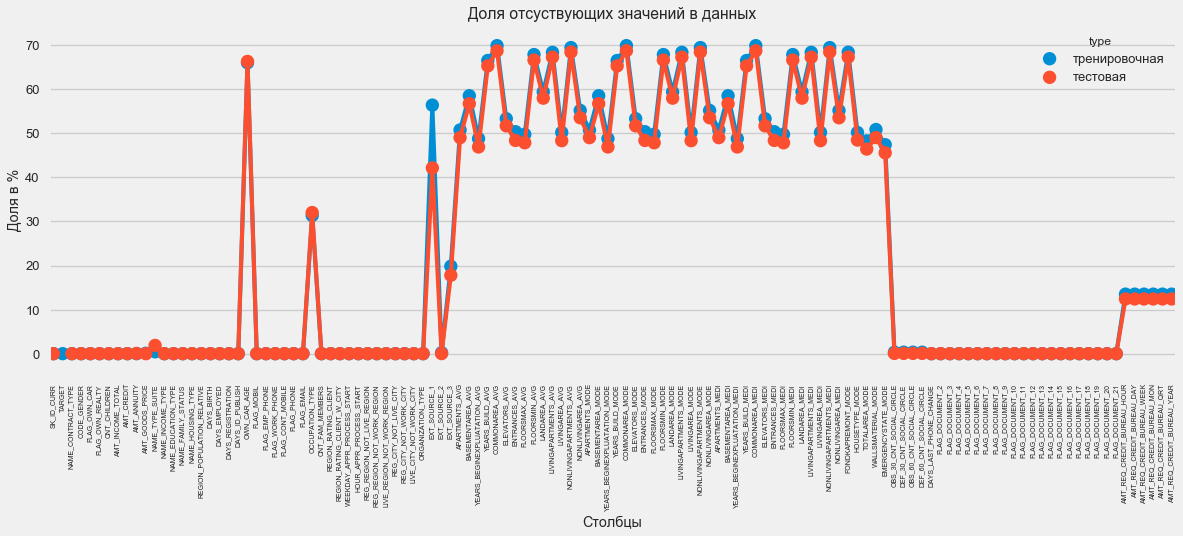
Il existe de nombreuses réponses à la question «que faire de tout cela». Vous pouvez le remplir de zéros, vous pouvez utiliser des valeurs médianes, vous pouvez simplement supprimer des lignes sans les informations nécessaires. Tout dépend du modèle que nous prévoyons d'utiliser, car certains d'entre eux font parfaitement face aux valeurs manquantes. Alors que nous nous souvenons de ce fait et que nous laissons tout tel quel.
Types de colonnes et codage catégorique
Comme nous nous en souvenons. une partie des colonnes est de type objet, c'est-à-dire qu'elle n'a pas de valeur numérique, mais reflète une certaine catégorie. Examinons ces colonnes de plus près.
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64Nous avons 16 colonnes, chacune avec 2 à 58 options de valeur différentes. En général, les modèles d'apprentissage automatique ne peuvent rien faire avec de telles colonnes (à l'exception de certaines, telles que LightGBM ou CatBoost). Étant donné que nous prévoyons d'essayer différents modèles sur l'ensemble de données, quelque chose doit être fait avec cela. Il existe essentiellement deux approches:
- Encodage des étiquettes - les catégories se voient attribuer les chiffres 0, 1, 2 et ainsi de suite et sont écrites dans la même colonne
- One-Hot-encoding - une colonne est décomposée en plusieurs selon le nombre d'options et ces colonnes indiquent quelle option a cet enregistrement.
Parmi les plus populaires, il convient de noter l'
encodage cible moyen (merci pour la clarification des
roryorangepants ).
Il y a un petit problème avec le codage d'étiquettes - il attribue des valeurs numériques qui n'ont rien à voir avec la réalité. Par exemple, si nous avons affaire à une valeur numérique, alors le revenu de l'emprunteur de 100 000 est nettement supérieur et meilleur que le revenu de 20 000. Mais peut-on dire que, par exemple, une ville est meilleure qu'une autre parce qu'on lui attribue la valeur 100 et l'autre 200 ?
Par contre, le codage à chaud est plus sûr, mais peut produire des colonnes "supplémentaires". Par exemple, si nous encodons le même sexe à l'aide de One-Hot, nous obtenons deux colonnes, «sexe masculin» et «sexe féminin», bien qu'une seule suffise, «est-ce masculin».
Pour un bon ensemble de données, il serait nécessaire de coder des signes à faible variabilité en utilisant le codage d'étiquettes, et tout le reste - One-Hot, mais pour plus de simplicité, nous codons tout selon One-Hot. Cela n'affectera pratiquement pas la vitesse de calcul et le résultat. Le processus de codage des pandas lui-même est très simple.
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)Étant donné que le nombre d'options dans les colonnes de sélection n'est pas égal, le nombre de colonnes ne correspond plus. L'alignement est requis - vous devez supprimer les colonnes de l'ensemble de formation qui ne sont pas dans l'ensemble de test. Cela rend la méthode d'alignement, vous devez spécifier axe = 1 (pour les colonnes).
: (307511, 242)
: (48744, 242)Corrélation des données
Une bonne façon de comprendre les données consiste à calculer les coefficients de corrélation de Pearson pour les données par rapport à l'attribut cible. Ce n'est pas la meilleure méthode pour montrer la pertinence des fonctionnalités, mais elle est simple et vous permet d'avoir une idée des données. Les coefficients peuvent être interprétés comme suit:
- 00-.19 «très faible»
- 20-.39 «faible»
- 40 à 0,59 «moyenne»
- 60-.79 fort
- 80-1,0 «très fort»
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64Ainsi, toutes les données sont faiblement corrélées avec la cible (à l'exception de la cible elle-même, qui, bien sûr, est égale à elle-même). Cependant, l'âge et certaines «sources de données externes» se distinguent des données. Il s'agit probablement de données supplémentaires provenant d'autres organismes de crédit. Il est amusant que, bien que l'objectif soit déclaré indépendant de ces données dans la prise d'une décision de crédit, en fait, nous nous baserons principalement sur elles.
Âge
Il est clair que plus le client est âgé, plus la probabilité de retour est élevée (jusqu'à une certaine limite, bien sûr). Mais pour une raison quelconque, l'âge est indiqué en jours négatifs avant qu'un prêt ne soit émis, il est donc en corrélation positive avec le non-remboursement (ce qui semble quelque peu étrange). Nous le portons à une valeur positive et examinons la corrélation.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088Examinons de plus près la variable. Commençons par l'histogramme.
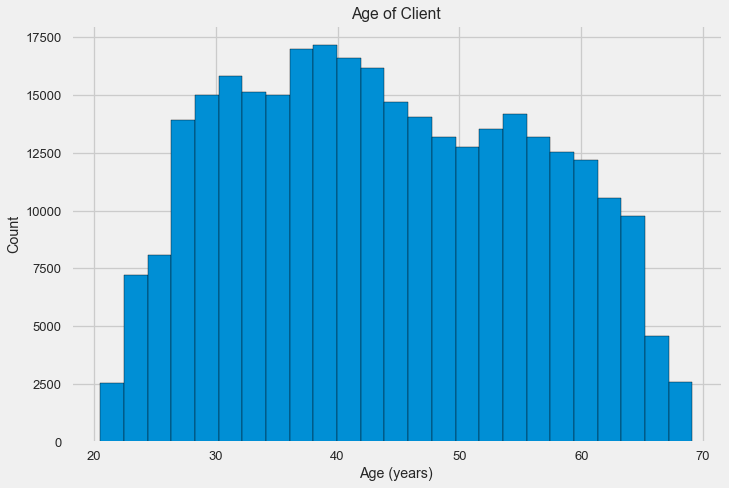
L'histogramme de distribution lui-même peut dire un peu utile, sauf que nous ne voyons pas de valeurs aberrantes spéciales et que tout semble plus ou moins crédible. Pour montrer l'effet de l'influence de l'âge sur le résultat, nous pouvons construire un graphique d'estimation de la densité du noyau (KDE) - la distribution de la densité nucléaire, peinte aux couleurs de l'attribut cible. Il montre la distribution d'une variable et peut être interprété comme un histogramme lissé (calculé comme un noyau gaussien pour chaque point, qui est ensuite moyenné pour lisser).
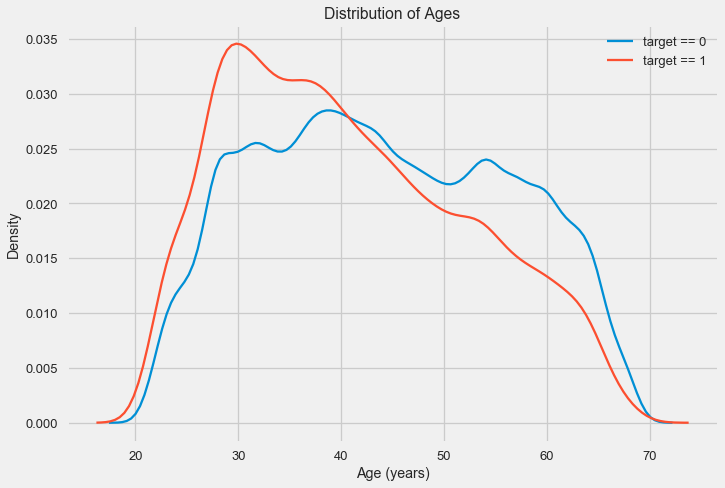
Comme on peut le voir, la part des défauts de paiement est plus élevée pour les jeunes et diminue avec l'âge. Ce n'est pas une raison pour refuser toujours le crédit aux jeunes, une telle «recommandation» ne fera que conduire à une perte de revenus et de marché pour la banque. C'est l'occasion de réfléchir à un suivi plus approfondi de ces prêts, à une évaluation et peut-être même à une forme d'éducation financière pour les jeunes emprunteurs.
Sources externes
Examinons de plus près les «sources de données externes» EXT_SOURCE et leur corrélation.
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
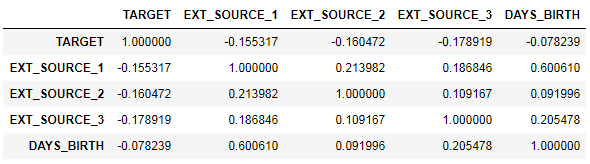
Il est également pratique d'afficher la corrélation à l'aide de la carte thermique
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
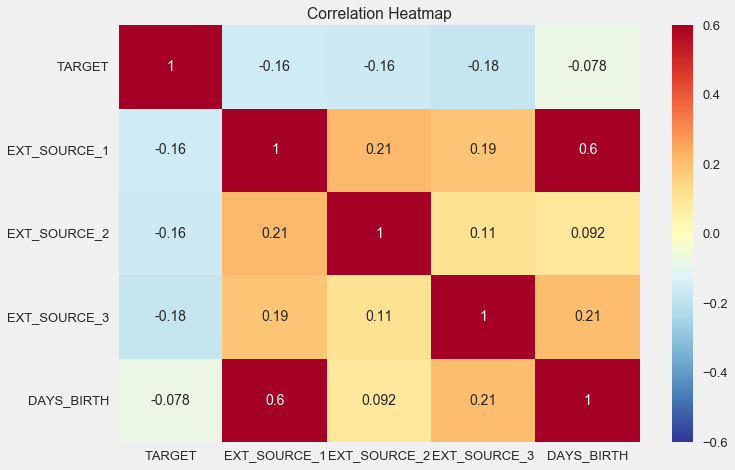
Comme vous pouvez le voir, toutes les sources présentent une corrélation négative avec la cible. Examinons la distribution de KDE pour chaque source.
plt.figure(figsize = (10, 12))
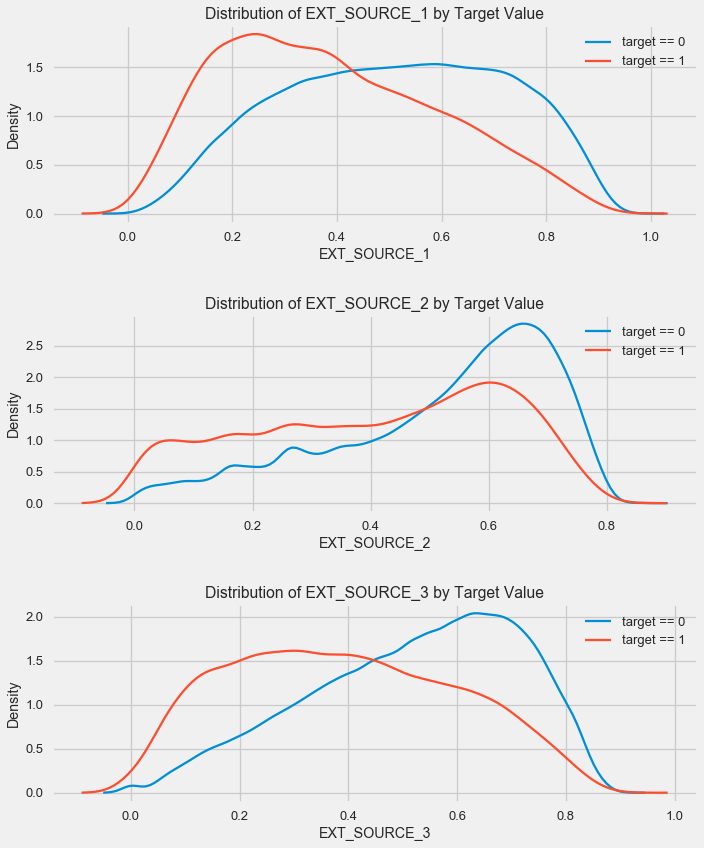
Le tableau est similaire à la répartition par âge - avec une augmentation de l'indicateur, la probabilité d'un rendement de prêt augmente. La troisième source est la plus puissante à cet égard. Bien qu'en termes absolus, la corrélation avec la variable cible soit toujours dans la catégorie «très faible», les sources de données externes et l'âge seront de la plus haute importance dans la construction du modèle.
Calendrier des paires
Pour mieux comprendre la relation de ces variables, vous pouvez construire un diagramme de paires, en lui, nous pouvons voir la relation de chaque paire et un histogramme de la distribution le long de la diagonale. Au-dessus de la diagonale, vous pouvez afficher le nuage de points, et en dessous - 2d KDE.
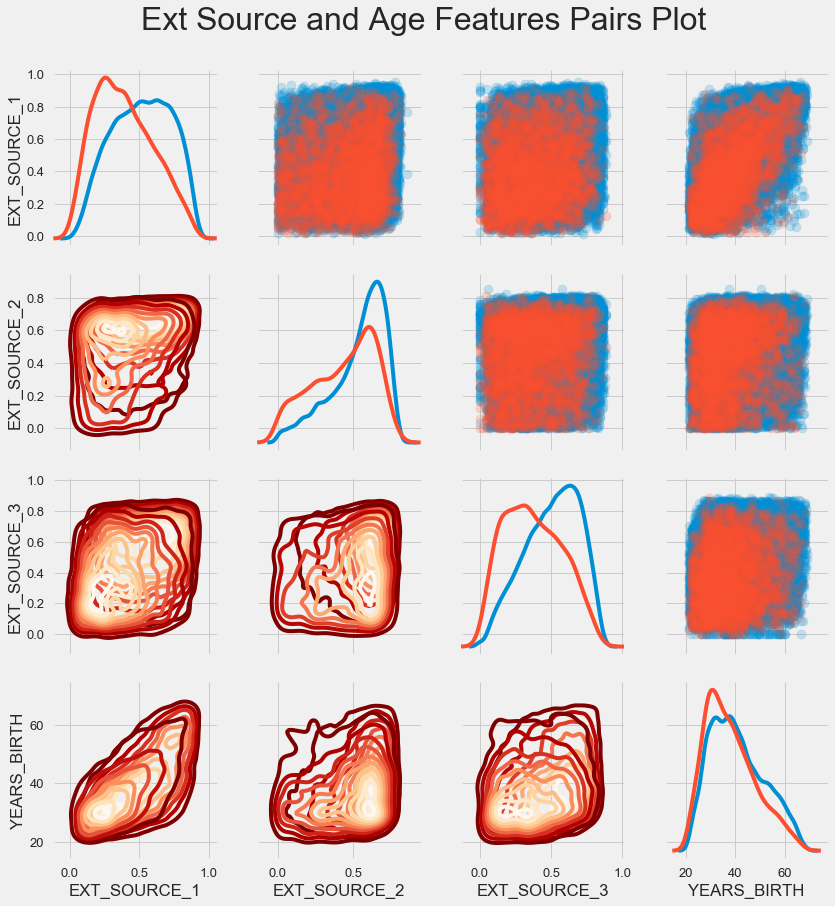
Les prêts remboursables sont indiqués en bleu, non remboursables en rouge. Interpréter tout cela est assez difficile, mais une bonne impression sur un T-shirt ou une image dans un musée d'art moderne peut sortir de cette image.
Examen d'autres signes
Examinons plus en détail d'autres fonctionnalités et leur dépendance à la variable cible. Puisqu'il y en a beaucoup (et nous avons déjà réussi à les encoder), nous avons à nouveau besoin des données initiales. Appelons-les un peu différemment pour éviter toute confusion
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
Nous aurons également besoin de quelques fonctions pour afficher magnifiquement les distributions et leur influence sur la variable cible. Un grand merci
à eux pour l'
auteur de ce
noyau def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
Nous allons donc considérer les principaux signes de clients
Type de prêt
plot_stats('NAME_CONTRACT_TYPE')
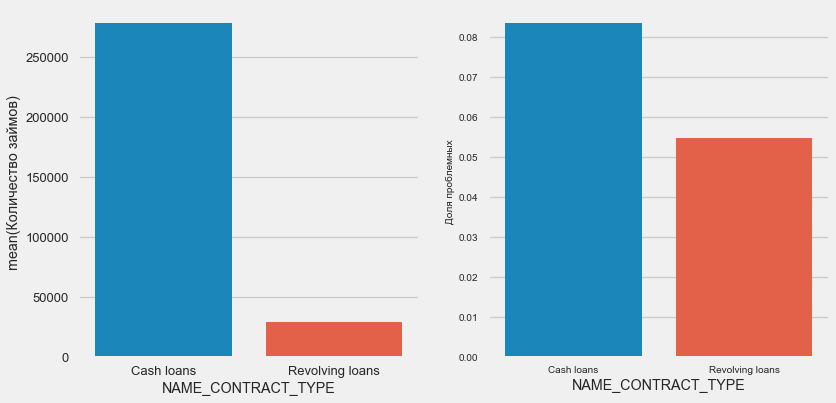
Fait intéressant, les prêts renouvelables (probablement des découverts ou quelque chose du genre) représentent moins de 10% du nombre total de prêts. Dans le même temps, le pourcentage de non-retour parmi eux est beaucoup plus élevé. Une bonne raison de revoir la méthodologie de travail avec ces prêts, voire de les abandonner.
Sexe du client
plot_stats('CODE_GENDER')
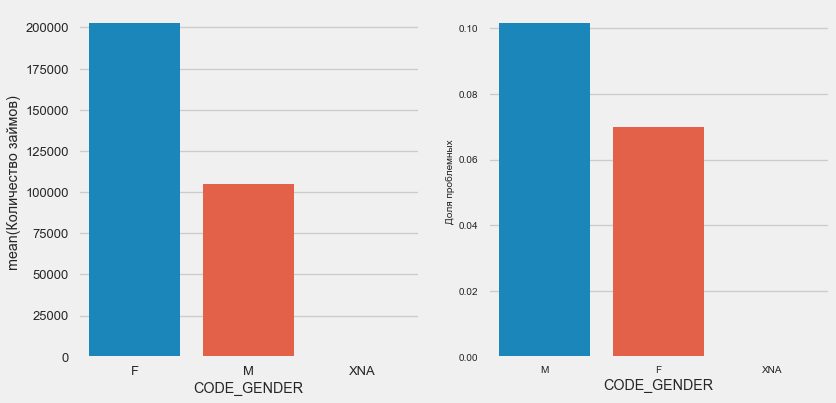
Il y a presque deux fois plus de femmes que d'hommes, les hommes présentant un risque beaucoup plus élevé.
Propriété de voiture et de propriété
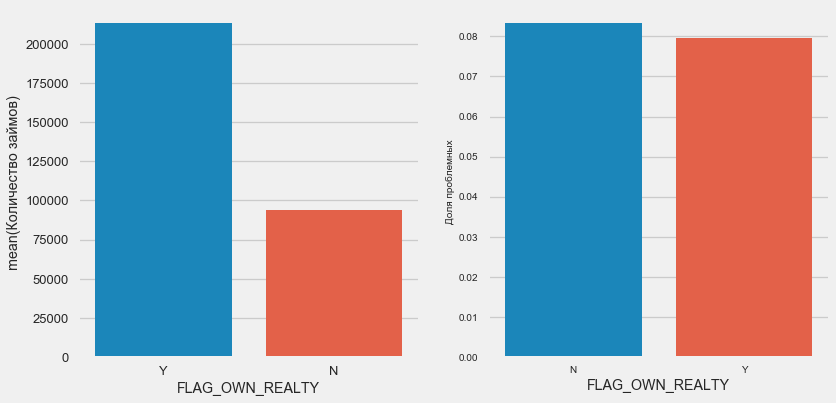
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
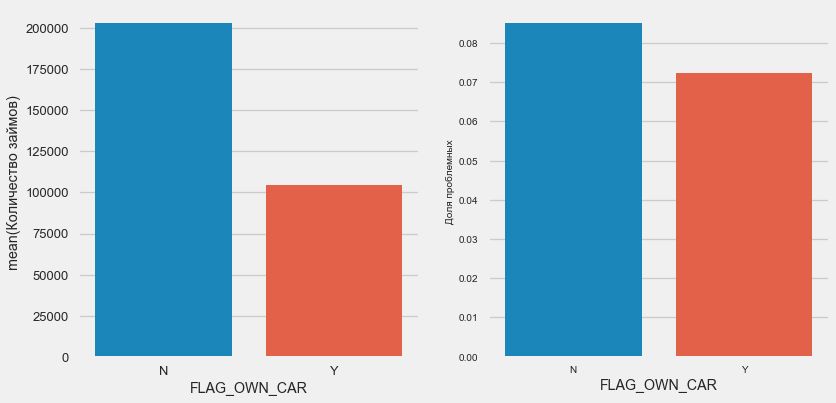
Les clients avec la voiture sont deux fois moins "sans chevaux". Le risque est presque le même, les clients avec la machine paient un peu mieux.
Pour l'immobilier, l'inverse est vrai - il y a deux fois moins de clients sans elle. Le risque pour les propriétaires est également légèrement moindre.
État matrimonial
plot_stats('NAME_FAMILY_STATUS',True, True)
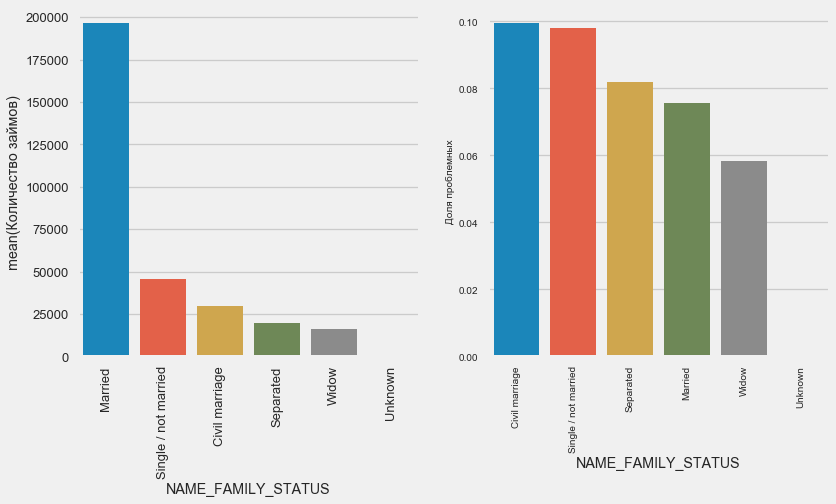
Alors que la plupart des clients sont mariés, les plus risqués sont les clients civils et célibataires. Les veufs présentent un risque minimal.
Nombre d'enfants
plot_stats('CNT_CHILDREN')
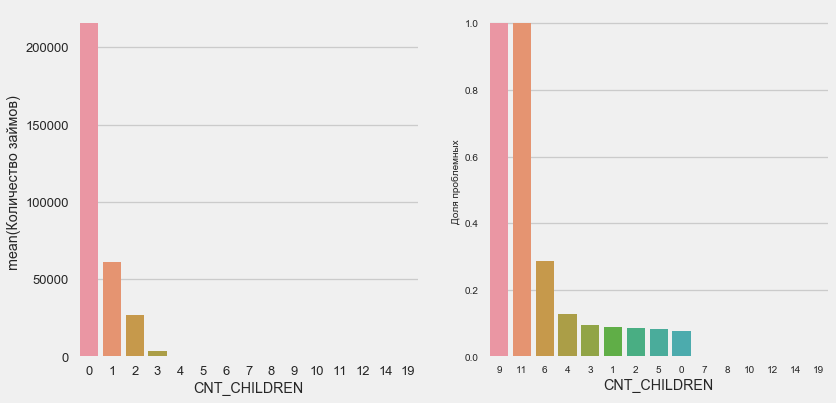
La plupart des clients sont sans enfant. Dans le même temps, les clients avec 9 et 11 enfants montrent un non-remboursement complet
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64Comme le montre le calcul des valeurs, ces données sont statistiquement non significatives - seulement 1-2 clients des deux catégories. Cependant, tous les trois ont fait défaut, tout comme la moitié des clients avec 6 enfants.
Nombre de membres de la famille
plot_stats('CNT_FAM_MEMBERS',True)
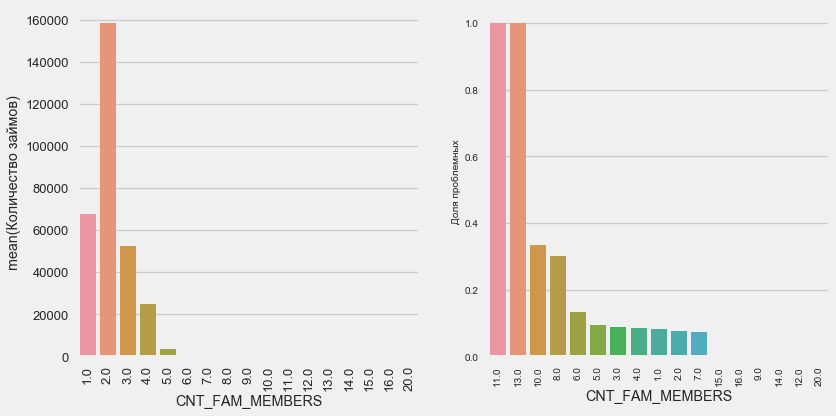
La situation est similaire - moins il y a de bouches, plus le rendement est élevé.
Type de revenu
plot_stats('NAME_INCOME_TYPE',False,False)
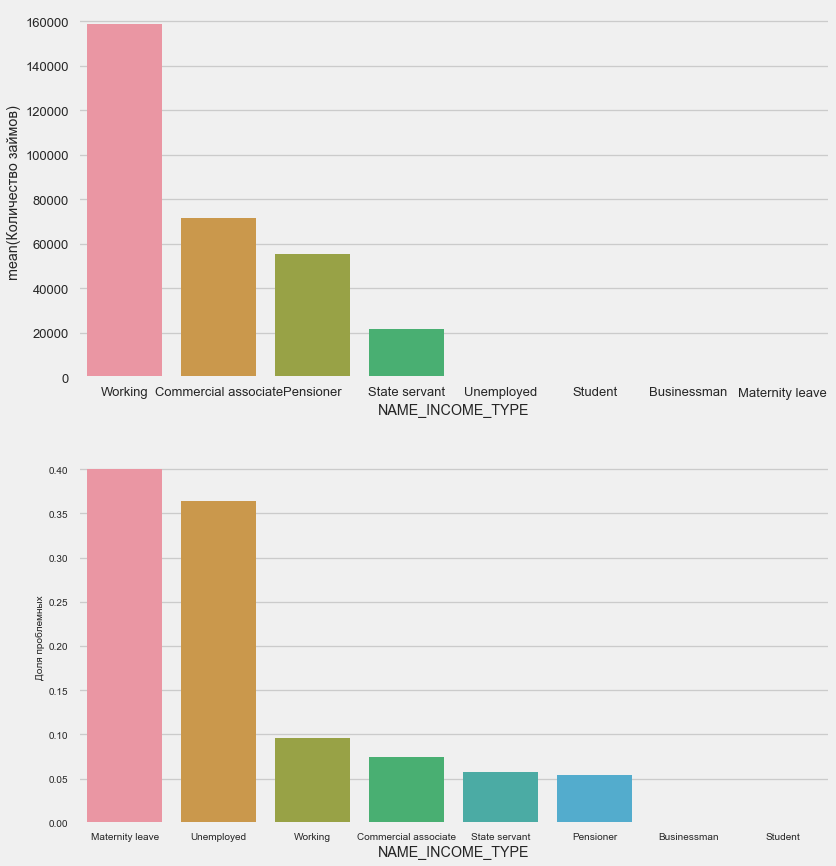
Les mères célibataires et les chômeurs seront probablement coupés au stade de la demande - il y en a trop peu dans l'échantillon. Mais les problèmes sont stables.
Type d'activité
plot_stats('OCCUPATION_TYPE',True, False)
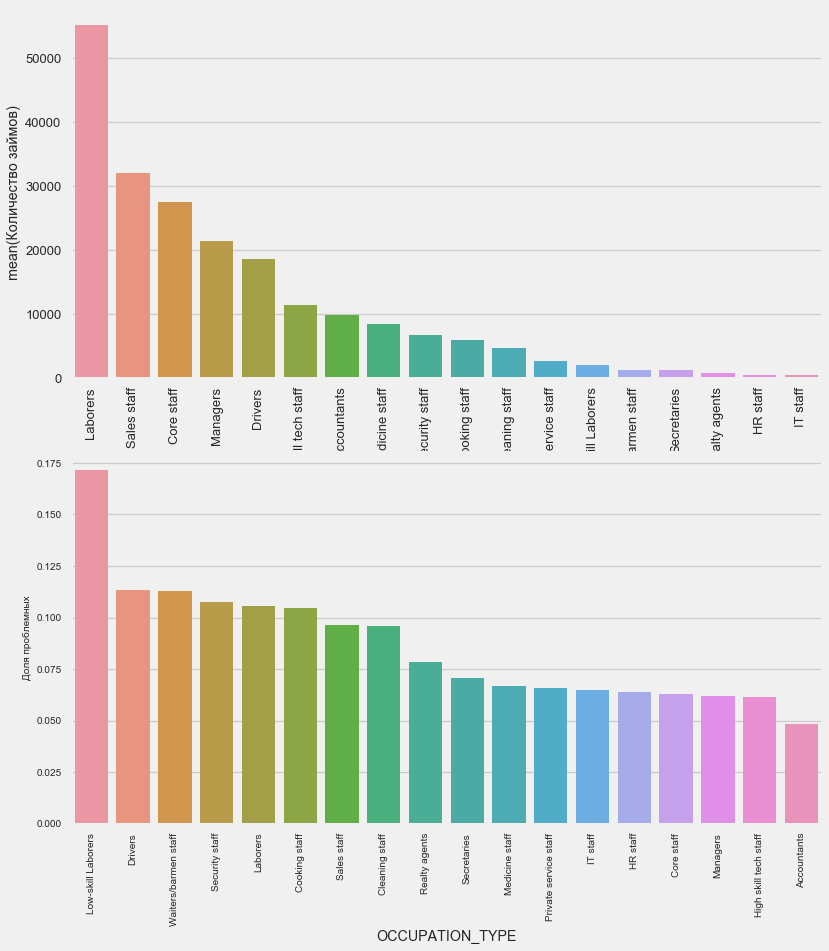
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64Elle intéresse les chauffeurs et les agents de sécurité qui sont assez nombreux et rencontrent des problèmes plus souvent que les autres catégories.
L'éducation
plot_stats('NAME_EDUCATION_TYPE',True)
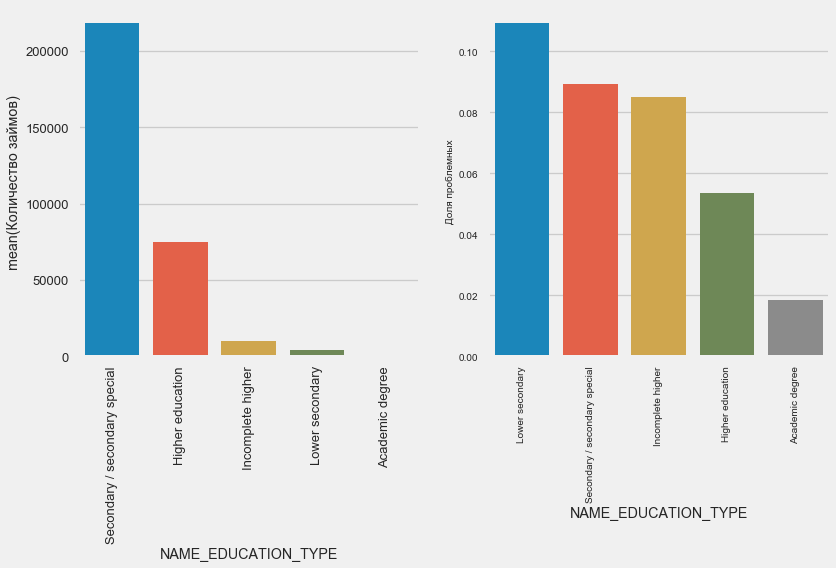
Plus l'enseignement est élevé, meilleure est la récurrence, évidemment.
Type d'organisation - employeur
plot_stats('ORGANIZATION_TYPE',True, False)
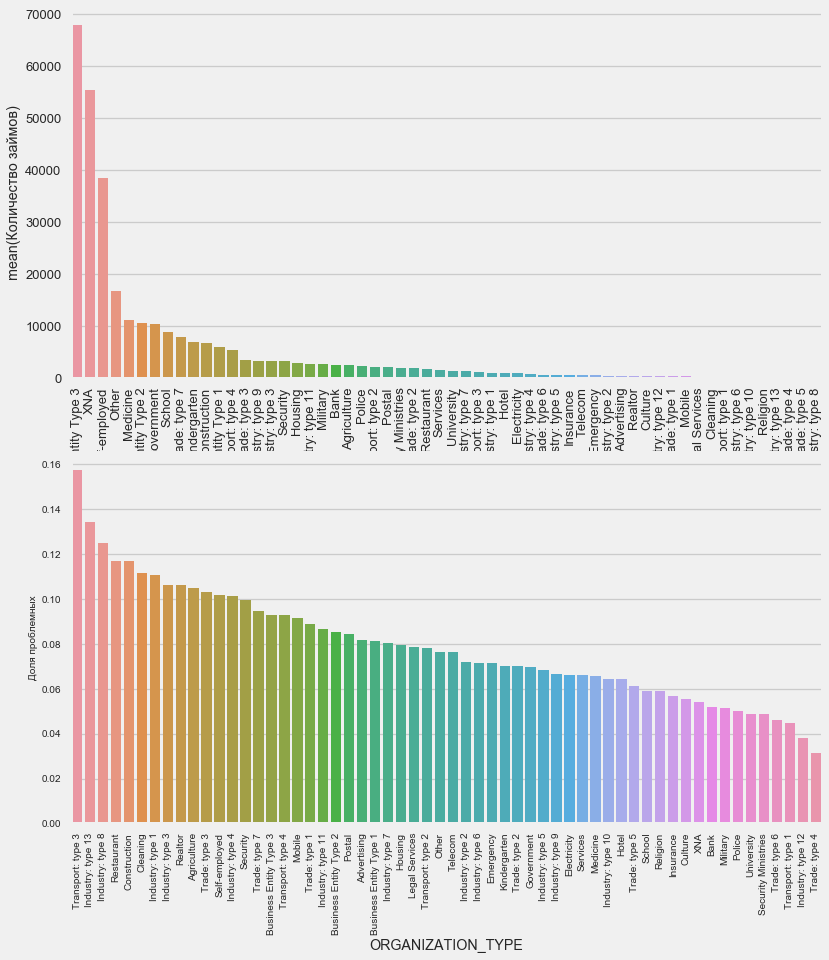
Le pourcentage le plus élevé de non-retour est observé dans les transports: type 3 (16%), l'industrie: type 13 (13,5%), l'industrie: type 8 (12,5%) et la restauration (jusqu'à 12%).
Affectation des prêts
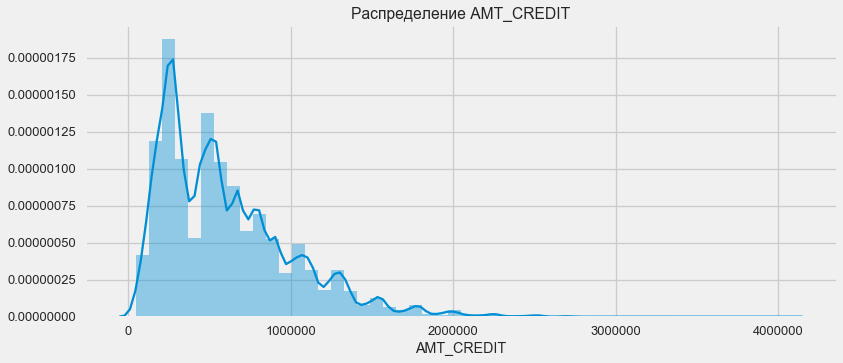
Tenez compte de la répartition des montants des prêts et de leur impact sur le remboursement
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
plt.figure(figsize=(12,5))
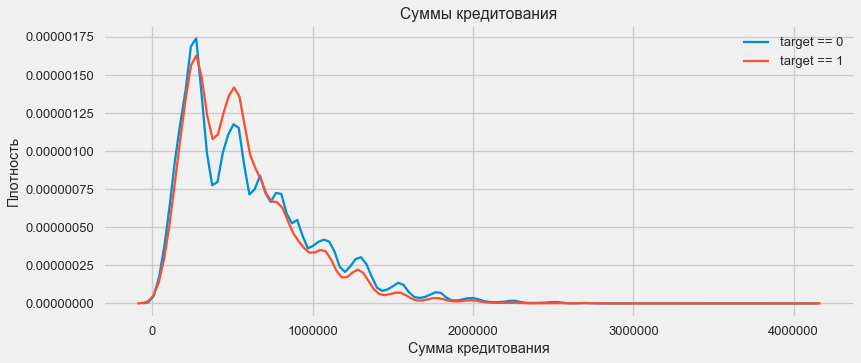
Comme le montre le graphique de densité, les quantités robustes sont retournées plus souvent
Distribution de densité
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
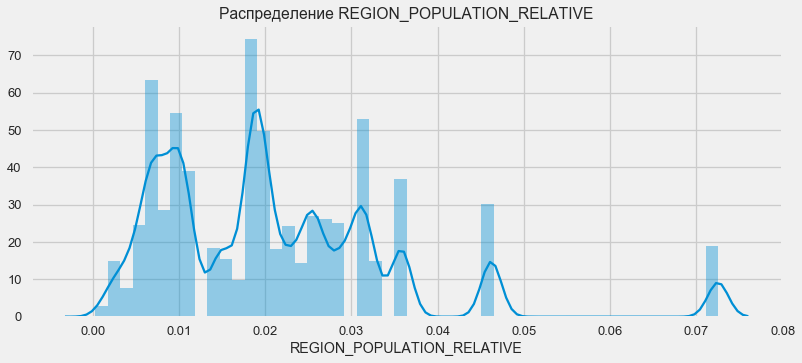
plt.figure(figsize=(12,5))
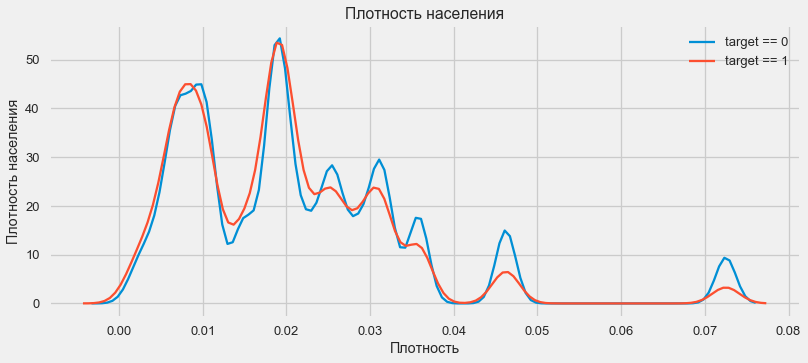
Les clients des régions plus peuplées ont tendance à mieux payer leurs prêts.
Ainsi, nous avons eu une idée des principales caractéristiques de l'ensemble de données et de leur influence sur le résultat. Nous ne ferons rien de particulier avec ceux énumérés dans cet article, mais ils peuvent s'avérer très importants dans les travaux futurs.
Ingénierie des fonctionnalités - Conversion des fonctionnalités
Les compétitions sur Kaggle sont gagnées par la transformation des signes - celui qui pourrait créer les signes les plus utiles à partir des données gagne. Au moins pour les données structurées, les modèles gagnants sont maintenant des options de renforcement de gradient fondamentalement différentes. Le plus souvent, il est plus efficace de passer du temps à convertir des attributs que de configurer des hyperparamètres ou de sélectionner des modèles. Un modèle ne peut encore apprendre que des données qui lui ont été transférées. S'assurer que les données sont pertinentes pour la tâche est la principale responsabilité de la date du scientifique.
Le processus de transformation des caractéristiques peut inclure la création de nouvelles données disponibles, la sélection des plus importantes disponibles, etc. Nous allons essayer cette fois les signes polynomiaux.
Signes polynomiaux
La méthode polynomiale de construction des fonctionnalités consiste à créer simplement des fonctionnalités correspondant au degré de fonctionnalités disponibles et à leurs produits. Dans certains cas, ces caractéristiques construites peuvent avoir une corrélation plus forte avec la variable cible que leurs «parents». Bien que ces méthodes soient souvent utilisées dans les modèles statistiques, elles sont beaucoup moins courantes dans l'apprentissage automatique. Cependant. rien ne nous empêche de les essayer, d'autant plus que Scikit-Learn a une classe spécialement conçue pour ces fins - PolynomialFeatures - qui crée des fonctionnalités polynomiales et leurs produits, il vous suffit de spécifier les fonctionnalités originales elles-mêmes et le degré maximum auquel elles doivent être augmentées. Nous utilisons les effets les plus puissants sur le résultat de 4 attributs et le degré 3 afin de ne pas trop compliquer le modèle et éviter le surapprentissage (surentraînement du modèle - son ajustement excessif à l'échantillon d'apprentissage).
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']Un total de 35 caractéristiques polynomiales et dérivées. Vérifiez leur corrélation avec la cible.
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64Ainsi, certains signes montrent une corrélation plus élevée que l'original. Il est logique d'essayer d'apprendre avec et sans eux (comme beaucoup plus dans l'apprentissage automatique, cela peut être déterminé expérimentalement). Pour ce faire, créez une copie des cadres de données et ajoutez-y de nouvelles fonctionnalités.
: (307511, 277)
: (48744, 277)Formation modèle
Niveau de base
Dans les calculs, vous devez partir d'un certain niveau de base du modèle, en dessous duquel il n'est plus possible de tomber. Dans notre cas, cela pourrait être de 0,5 pour tous les clients test - cela montre que nous n'avons aucune idée du fait que le client remboursera le prêt ou non. Dans notre cas, un travail préliminaire a déjà été fait et des modèles plus complexes peuvent être utilisés.Régression logistique
Pour calculer la régression logistique, nous devons prendre des tableaux avec des caractéristiques catégorielles codées, remplir les données manquantes et les normaliser (les amener à des valeurs de 0 à 1). Tout cela exécute le code suivant: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)Nous utilisons la régression logistique de Scikit-Learn comme premier modèle. Prenons le modèle de défoliation avec une correction - nous abaissons le paramètre de régularisation C pour éviter le sur-ajustement. La syntaxe est normale - nous créons un modèle, le formons et prédisons la probabilité à l'aide de predire_proba (nous avons besoin d'une probabilité, pas de 0/1) from sklearn.linear_model import LogisticRegression
Vous pouvez maintenant créer un fichier à télécharger sur Kaggle. Créez une trame de données à partir de l'ID client et de la probabilité de non-retour et téléchargez-la. submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
Donc, le résultat de notre travail titanesque: 0,673, avec le meilleur résultat pour aujourd'hui est 0,802.Modèle amélioré - Forêt aléatoire
Logreg ne se montre pas très bien, essayons d'utiliser un modèle amélioré - une forêt aléatoire. Il s'agit d'un modèle beaucoup plus puissant qui peut construire des centaines d'arbres et produire un résultat beaucoup plus précis. Nous utilisons 100 arbres. Le schéma de travail avec le modèle est le même, tout à fait standard - chargement du classificateur, formation. prédiction. from sklearn.ensemble import RandomForestClassifier
le résultat de la forêt aléatoire est légèrement meilleur - 0,683Modèle d'entraînement avec caractéristiques polynomiales
Maintenant que nous avons un modèle. qui fait au moins quelque chose - il est temps de tester nos signes polynomiaux. Faisons de même avec eux et comparons le résultat. poly_features_names = list(app_train_poly.columns)
le résultat d'une forêt aléatoire avec des caractéristiques polynomiales est devenu pire - 0,633. Ce qui remet fortement en cause la nécessité de leur utilisation.Augmentation du gradient
L'amplification du gradient est un «modèle sérieux» pour l'apprentissage automatique. Presque toutes les dernières compétitions sont «traînées» exactement. Construisons un modèle simple et testons ses performances. from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
Le résultat de LightGBM est de 0,735, ce qui laisse derrière tous les autres modèles.Interprétation des modèles - Importance des attributs
La façon la plus simple d'interpréter un modèle consiste à examiner l'importance des fonctionnalités (ce que tous les modèles ne peuvent pas faire). Puisque notre classificateur a traité le tableau, il faudra un peu de travail pour réinitialiser les noms de colonne en fonction des colonnes de ce tableau.
Comme on pouvait s'y attendre, le plus important pour modéliser tous les mêmes caractéristiques 4. L'importance des attributs n'est pas la meilleure méthode d'interprétation du modèle, mais elle vous permet de comprendre les principaux facteurs que le modèle utilise pour les prédictionsfeature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
Ajout de données à partir d'autres tables
Nous allons maintenant examiner attentivement les tableaux supplémentaires et ce qui peut être fait avec eux. Commencez immédiatement à préparer des tableaux pour la formation continue. Mais d'abord, supprimez les anciennes tables volumineuses de la mémoire, videz la mémoire à l'aide du garbage collector et importez les bibliothèques nécessaires pour une analyse plus approfondie. import gc
Importez des données, supprimez immédiatement la colonne cible dans une colonne distincte data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
Encode immédiatement les fonctionnalités catégorielles. Nous l'avons déjà fait auparavant, et nous avons codé séparément les échantillons d'apprentissage et de test, puis aligné les données. Essayons une approche légèrement différente - nous trouverons toutes ces fonctionnalités catégorielles, combinerons les trames de données, encoderons à partir de la liste des trames trouvées, puis diviserons à nouveau les échantillons en formations et tests. categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)Données du bureau de crédit sur le solde du prêt mensuel.
buro_balance.head()
 MONTHS_BALANCE - le nombre de mois avant la date de demande de prêt. Regardons de plus près les «statuts»
MONTHS_BALANCE - le nombre de mois avant la date de demande de prêt. Regardons de plus près les «statuts» buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64Les statuts signifient ce qui suit:- fermé, c'est-à-dire prêt remboursé. X est un statut inconnu. 0 - prêt en cours, pas de retard. 1 - délai de 1 à 30 jours, 2 - délai de 31 à 60 jours, et ainsi de suite jusqu'au statut 5 - le prêt est vendu à un tiers ou amorti.Ici, par exemple, les signes suivants peuvent être distingués: buro_grouped_size - le nombre d'entrées dans la base de données buro_grouped_max - le solde de prêt maximum buro_grouped_min - le solde de prêt minimumEt tous ces statuts de prêt peuvent être encodés (nous utilisons la méthode unstack, puis attachons les données reçues à la table buro, car SK_ID_BUREAU est le même ici et là. buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
Informations générales sur les bureaux de crédit
buro.head()
 (les 7 premières colonnes sont affichées) Il ya beaucoup de données que, en général, vous pouvez essayer de coder simplement avec One-Hot-Encoding, grouper par SK_ID_CURR, moyenne et, de la même manière, préparer la jonction avec la table principale
(les 7 premières colonnes sont affichées) Il ya beaucoup de données que, en général, vous pouvez essayer de coder simplement avec One-Hot-Encoding, grouper par SK_ID_CURR, moyenne et, de la même manière, préparer la jonction avec la table principale buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
Données sur les applications précédentes
prev.head()
 De même, nous encodons les fonctionnalités catégorielles, faisons la moyenne et combinons sur l'ID actuel.
De même, nous encodons les fonctionnalités catégorielles, faisons la moyenne et combinons sur l'ID actuel. prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
Solde de carte de crédit
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64Nous encodons des caractéristiques catégorielles et préparons un tableau pour combiner le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Données de la carte
credit_card.head()
 (7 premières colonnes)Travaux similaires
(7 premières colonnes)Travaux similaires credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Données de paiement
payments.head()
 (7 premières colonnes affichées)Créons trois tableaux - avec les valeurs moyennes, minimales et maximales de ce tableau.
(7 premières colonnes affichées)Créons trois tableaux - avec les valeurs moyennes, minimales et maximales de ce tableau. avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
Jointure de table
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)Et, en fait, nous atteindrons ce tableau doublé avec un boost de gradient! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
le résultat est 0,770.OK, enfin, essayons une technique plus complexe avec le pliage en plis, la validation croisée et le choix de la meilleure itération. folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845Score final sur kaggle 0.783Où aller ensuite
Certainement continuer à travailler avec des panneaux. Explorez les données, sélectionnez certains des signes, combinez-les, joignez des tableaux supplémentaires d'une manière différente. Vous pouvez expérimenter avec des hyperparamètres Mogheli - beaucoup de directions.J'espère que cette petite compilation vous a montré des méthodes modernes de recherche de données et de préparation de modèles prédictifs. Apprenez des données, participez à des compétitions, soyez cool!Et encore des liens vers les noyaux qui m'ont aidé à préparer cet article. L'article est également publié sous la forme d'un ordinateur portable sur Github , vous pouvez le télécharger, l' ensemble de données et exécuter et expérimenter.Will Koehrsen. Commencez ici: une introduction doucesban. HomeCreditRisk: Base de référence EDA + étendue [0.772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM