Le prétraitement est un terme général pour toutes les manipulations effectuées avec des données avant de transférer leur modèle, y compris le centrage, la normalisation, le décalage, la rotation, le recadrage, etc. En règle générale, le prétraitement est requis dans deux cas.
- Nettoyage des données . Supposons que certains artefacts soient présents dans les images. Pour faciliter la formation du modèle, les artefacts doivent être retirés au stade du prétraitement.
- Ajout de données . Parfois, de petits ensembles de données ne suffisent pas pour une formation de modèle profond de haute qualité. Une approche de supplément de données est très utile pour résoudre ce problème. Il s'agit du processus de transformation de chaque échantillon de données de diverses manières et d'ajout de tels échantillons modifiés à l'ensemble de données. De cette façon, la taille effective de l'ensemble de données peut être augmentée.
Examinons quelques méthodes de transformation possibles lors du prétraitement et leur implémentation via Keras.

Les données
Dans cet article et les suivants, un ensemble de données sera utilisé pour analyser la coloration émotionnelle des images. Il contient 1 500 exemples d'images, divisés en deux classes - positives et négatives. Regardons quelques exemples.
 Exemples négatifs
Exemples négatifs Exemples positifs
Exemples positifsTransformations de nettoyage
Considérons maintenant un ensemble de transformations possibles couramment utilisées pour nettoyer les données, leur implémentation et leur impact sur les images.
Tous les extraits de code peuvent être trouvés dans le livre
Preprocessing.ipynb .
Redimensionnement
Les images sont généralement stockées au format RVB (rouge vert bleu). Dans ce format, l'image est représentée par un réseau tridimensionnel (ou à trois canaux).
 Décomposition RVB de l'image. Graphique tiré de Wikiwand
Décomposition RVB de l'image. Graphique tiré de WikiwandUne dimension est utilisée pour les canaux (rouge, vert et bleu), les deux autres représentent l'emplacement. Ainsi, chaque pixel est codé avec trois nombres. Chaque numéro est généralement stocké sous la forme d'un type entier non signé 8 bits (0 à 255).
Le redimensionnement est une opération qui modifie la plage numérique de données en la divisant simplement par une constante prédéterminée. Dans les réseaux de neurones profonds, il peut être nécessaire de limiter les données d'entrée à une plage de 0 à 1 en raison d'un débordement possible, de problèmes d'optimisation, de la stabilité, etc.
Par exemple, nous redimensionnons nos données à partir de la plage [0; 255] à la plage [0; 1]. Ci-après, nous utiliserons la classe Keras
ImageDataGenerator , qui vous permet d'effectuer toutes les transformations à la volée.
Créons deux instances de cette classe: une pour les données transformées, l'autre pour la source:

(ou pour les données par défaut). Il suffit de spécifier la constante de mise à l'échelle. De plus, la classe
ImageDataGenerator vous permet de diffuser des données directement à partir d'un dossier sur votre disque dur à l'aide de la méthode
flow_from_directory .
Tous les paramètres se trouvent dans la
documentation , mais les principaux paramètres sont: le chemin d'accès au flux et la taille de l'image cible (si l'image ne correspond pas à la taille cible, le générateur la coupe ou la construit simplement). Enfin, nous obtenons un échantillon du générateur et considérons les résultats.
Visuellement, les deux images sont identiques, mais la raison en est que les outils Python * redimensionnent automatiquement les images
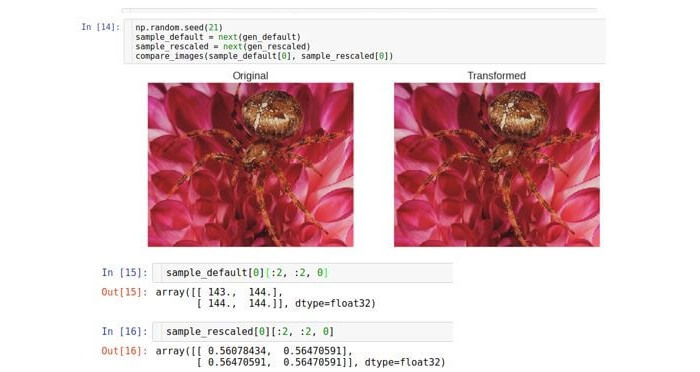
à la plage par défaut afin qu'ils puissent être affichés à l'écran. Considérez les données brutes (tableaux). Comme vous pouvez le voir, les massifs bruts diffèrent exactement 255 fois.
Niveaux de gris
Un autre type de transformation qui peut être utile est l'
échelle de gris , qui convertit une image RVB couleur en une image dans laquelle toutes les couleurs sont représentées en nuances de gris. Le traitement d'image conventionnel peut utiliser la traduction en niveaux de gris en combinaison avec un seuil ultérieur. Cette paire de transformations peut rejeter les pixels bruyants et définir des formes dans l'image. Aujourd'hui, toutes ces opérations sont effectuées par Convolutional Neural Network (CNN), mais la conversion en niveaux de gris comme étape de prétraitement peut toujours être utile. Exécutez cette étape dans Keras avec la même classe de générateur.
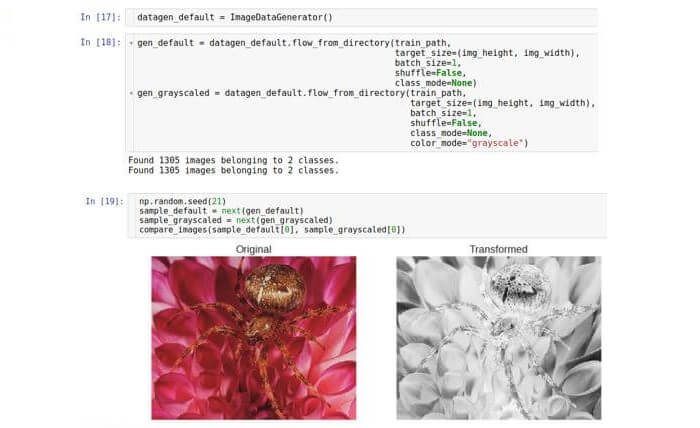
Ici, nous ne créons qu'une seule instance de la classe et en prenons deux générateurs différents. Le deuxième générateur définit le paramètre
color_mode sur "niveaux de gris" (la valeur par défaut est "RVB").
Échantillons de centrage
Nous avons déjà vu que les valeurs des données brutes se situent dans la plage de 0 à 255. Ainsi, un échantillon est un tableau tridimensionnel de nombres de 0 à 255. À la lumière des principes de stabilité de l'optimisation (se débarrasser du problème de la disparition ou de la saturation des valeurs), il
peut être nécessaire de normaliser l'ensemble de données de sorte que la moyenne de chaque échantillon de données est de 0 .
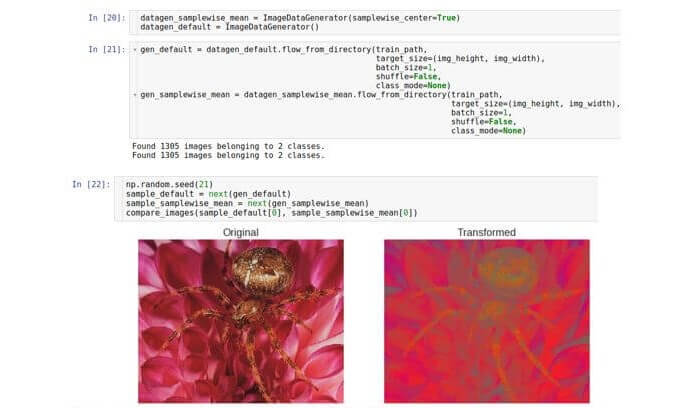
Pour cela, il est nécessaire de calculer la valeur moyenne sur l'ensemble de l'échantillon et de la soustraire de chaque nombre de l'échantillon donné.
Dans Keras, cela se fait à l'aide du paramètre
samplewise_center .
Normalisation de l'écart type des échantillons
Cette étape de prétraitement est basée sur la même idée que le centrage des échantillons, mais au lieu de régler la moyenne à 0, elle définit l'écart type à 1.

La normalisation de l'
écart- type est contrôlée par le paramètre
samplewise_std_normalization . Il convient de noter que ces deux méthodes de normalisation des échantillons sont souvent utilisées ensemble.
Cette transformation peut être utilisée dans les modèles d'apprentissage en profondeur pour améliorer la stabilité de l'optimisation en réduisant l'impact de l'explosion des gradients.
Centrage des fonctionnalités
Les deux sections précédentes ont utilisé une technique de normalisation qui a examiné chaque échantillon individuel de données. Il existe une approche alternative à la procédure de normalisation. Considérez chaque nombre dans le tableau d'images comme un signe. Ensuite,
chaque image est un vecteur caractéristique . Il existe de nombreux vecteurs de ce type dans l'ensemble de données; par conséquent, nous pouvons les considérer comme une
distribution inconnue. Cette distribution est multi-paramètres et sa dimension sera égale au nombre d'entités, c'est-à-dire largeur × hauteur × 3. Bien que la véritable distribution des données soit inconnue, vous pouvez essayer de la normaliser en soustrayant la valeur de distribution moyenne. Il est à noter que la valeur moyenne est un vecteur de même dimension, c'est-à-dire qu'elle est également une image. En d'autres termes, nous faisons la moyenne sur l'ensemble des données et non sur un échantillon.
Il existe un paramètre Keras spécial appelé
featurewise_centering , mais, malheureusement, en août 2017, il y avait une erreur dans sa mise en œuvre; par conséquent, nous le mettons en œuvre nous-mêmes. Tout d'abord, nous considérons l'ensemble de données en mémoire (nous pouvons nous le permettre, car nous avons affaire à un petit ensemble de données). Nous l'avons fait en définissant la taille du paquet sur la taille de l'ensemble de données. Ensuite, nous calculons l'image moyenne sur l'ensemble des données et finalement la soustrayons de l'image de test.
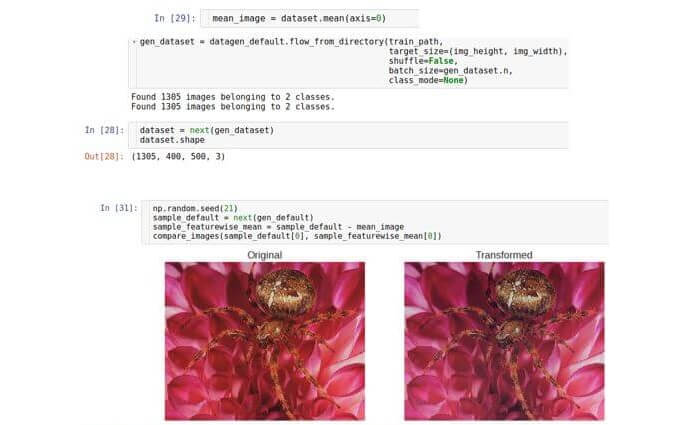
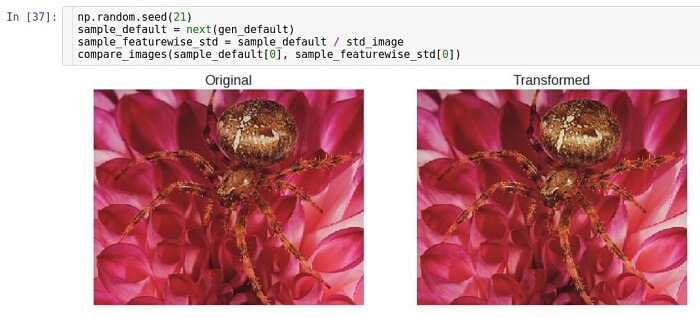
Normalisation de l'écart type des symptômes
L'idée de normaliser l'écart-type est exactement la même que l'idée de centrage. La seule différence est qu'au lieu de soustraire la moyenne, nous divisons par l'écart-type. Visuellement, le résultat n'est pas très différent. La même chose s'est produite

lors de la mise à l'échelle, car la normalisation de l'écart-type n'est rien d'autre que la mise à l'échelle avec une constante calculée d'une certaine manière, et avec une mise à l'échelle simple, la constante est spécifiée manuellement. Notez qu'une idée similaire de normalisation des paquets de données est au cœur d'une technique moderne d'apprentissage en profondeur appelée
BatchNormalization .
Transformation avec l'ajout
Dans cette section, nous examinons plusieurs transformations dépendantes des données qui utilisent explicitement la nature graphique des données. Ces types de transformations sont souvent utilisés dans les procédures d'ajout de données.
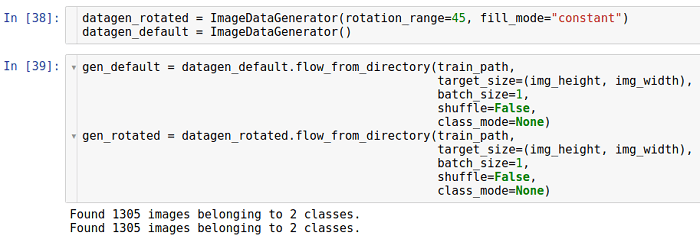
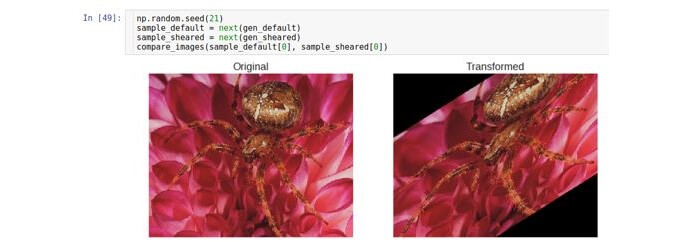
Rotation
Ce type de transformation fait pivoter l'image dans une certaine direction (dans le sens horaire ou antihoraire).
Le paramètre qui permet la rotation est appelé
rotation_range . Il indique la plage en degrés à partir de laquelle l'angle de rotation est sélectionné au hasard avec une distribution uniforme. Il convient de noter que pendant la rotation, la taille de l'image ne change pas. Ainsi, certaines parties de l'image peuvent être recadrées et certaines remplies.
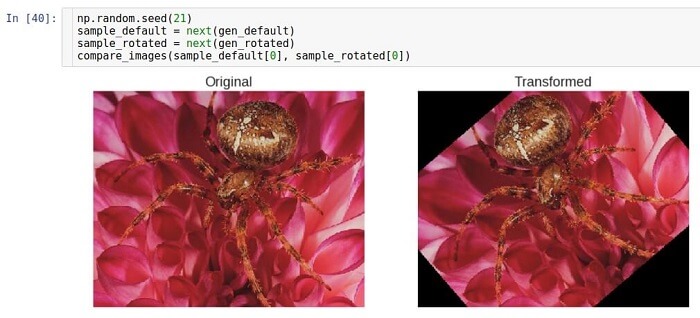
Le mode de remplissage est défini à l'aide du paramètre
fill_mode . Il prend en charge diverses méthodes de remplissage, mais nous utilisons ici la méthode
constante comme exemple.
Décalage horizontal
Ce type de transformation décale l'image dans une certaine direction le long de l'axe horizontal (gauche ou droite).

La taille du décalage peut être déterminée à l'aide du paramètre
width_shift_range et mesurée dans le cadre de la largeur totale de l'image.
Décalage vertical
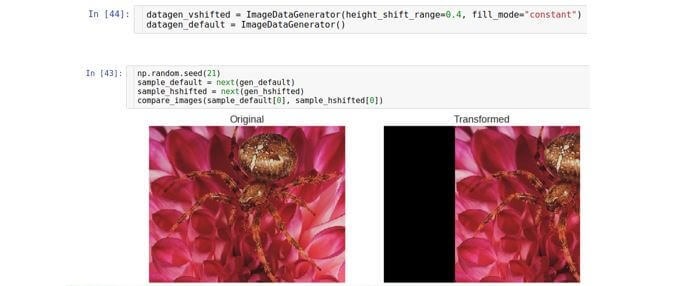
Décale l'image le long de l'axe vertical (haut ou bas). Le paramètre qui contrôle la plage de décalage s'appelle le générateur
height_shift et est également mesuré comme faisant partie de la hauteur totale de l'image.
Taille
Une conversion de recadrage ou un recadrage décale chaque point dans la direction verticale d'une quantité proportionnelle à la distance entre ce point et le bord de l'image. Notez que dans le cas général, la direction n'a pas besoin d'être verticale et est arbitraire.
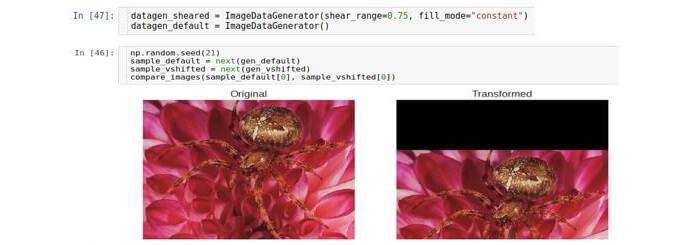
Le paramètre contrôlant le déplacement est appelé
shear_range et correspond à l'angle de déviation (en radians) entre la ligne horizontale dans l'image d'origine et l'image (au sens mathématique) de cette ligne dans l'image transformée.
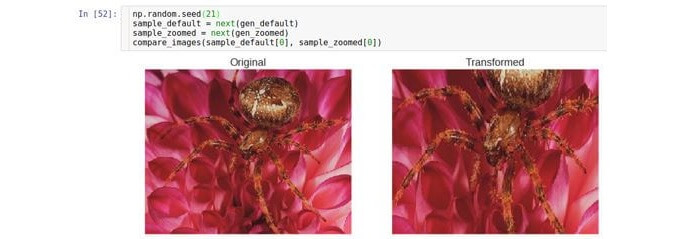
Zoom avant / arrière

Ce type de transformation rapproche ou supprime l'image d'origine. Le paramètre
zoom_range contrôle le facteur de zoom.
Par exemple, si
zoom_range est 0,5, le facteur de zoom sera sélectionné dans la plage [0,5, 1,5].
Retournement horizontal

Retourne l'image par rapport à l'axe vertical. Il peut être activé ou désactivé à l'aide du paramètre
horizontal_flip .
Retournement vertical

Retourne l'image autour de l'axe horizontal. Le paramètre
vertical_flip (de type booléen) contrôle la présence ou l'absence de cette transformation.
Combinaison
Nous appliquons tous les types de transformations décrits du complément en même temps et voyons ce qui se passe. Rappelez-vous que les paramètres de toutes les transformations sont choisis au hasard dans une certaine plage; par conséquent, nous devons obtenir un ensemble d'échantillons avec un degré important de diversité.
Nous
lançons ImageDataGenerator avec tous les paramètres disponibles et vérifions la borne rouge sur l'image.

Notez que le mode de remplissage
constant a été utilisé uniquement pour une meilleure visualisation. Nous allons maintenant utiliser un mode de remplissage plus avancé appelé le
plus proche ; ce mode affecte la couleur du pixel existant le plus proche au pixel vide.
Conclusion
Cet article fournit une vue d'ensemble des techniques de base pour le prétraitement d'images, telles que: la mise à l'échelle, la normalisation, la rotation, le décalage et le recadrage. Ils ont également démontré la mise en œuvre de ces techniques de transformation à l'aide de Keras et leur introduction dans le processus d'apprentissage profond à la fois techniquement (classe
ImageDataGenerator ) et idéologique (supplément de données).