Nous continuons à partager notre expérience dans l'organisation de l'entrepôt de données, dont nous avons commencé à parler dans un post précédent . Cette fois, nous voulons parler de la façon dont nous avons résolu les tâches d'installation de CDH.

Installation CDH
Nous démarrons le serveur Cloudera Manager, l'ajoutons au chargement automatique et vérifions qu'il est passé à l'état actif:
systemctl start cloudera-scm-server systemctl enable cloudera-scm-server systemctl status cloudera-scm-server
Après avoir augmenté, nous suivons le lien "nom d'hôte: 7180 /", connectez-vous (admin / admin) et continuez l'installation à partir de l'interface graphique. Après autorisation, l'installation démarrera automatiquement et une transition sera effectuée vers la page d'ajout d'hôtes au cluster:

Il est recommandé d'ajouter tous les hôtes qui seront en quelque sorte connectés à l'environnement déployé (même s'ils n'hébergeront pas les services Cloudera). Il peut s'agir de machines dotées d'outils d'intégration continue, d'outils BI ou ETL ou d'outils de découverte de données. L'inclusion de ces machines dans le cluster vous permettra d'installer les passerelles des services de cluster (passerelles) contenant des fichiers avec la configuration et l'emplacement des services de cluster, ce qui simplifiera l'intégration avec les programmes tiers. Cloudera Manager fournit également des outils de surveillance pratiques et la création de moniteurs de métriques clés pour toutes les machines du cluster dans une seule fenêtre, ce qui simplifiera la localisation des problèmes pendant le fonctionnement. Les hôtes sont ajoutés à l'aide du bouton «Nouvelle recherche» - une transition est effectuée vers la page pour ajouter des machines au cluster, où il est proposé de leur fournir des données pour la connexion via SSH:

Après avoir ajouté les hôtes, nous passons à l'étape du choix de la méthode d'installation. Depuis que nous avons téléchargé les parsels, nous sélectionnons la méthode «Utiliser les parcelles (recommandé)», et maintenant nous devons ajouter notre référentiel. Nous cliquons sur le bouton «Plus d'options», supprimons tous les référentiels par défaut qui y sont installés et ajoutons l'adresse du référentiel avec le CDH parsel - «hostname / parcels / cdh /». Après confirmation, à droite de l'inscription «Sélectionnez la version de CDH», la version CDH présentée dans le parsel téléchargé doit être affichée. Pour cette méthode d'installation, rien ne peut être configuré sur cet onglet:

L'onglet suivant vous invite à installer le JDK. Comme nous l'avons déjà fait en préparation de l'installation, nous sautons cette étape:

Lorsque vous passez à l'onglet suivant, l'installation des composants du cluster sur les hôtes spécifiés commence. Une fois l'installation terminée, la transition vers l'étape suivante sera disponible. Si, lors de l'installation, des erreurs se produisent (j'ai rencontré cette situation lors de l'installation des environnements de développement locaux), vous pouvez voir leurs détails en utilisant la commande «tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log» et en cliquant sur le bouton Détails sur le côté droit du tableau:

À l'étape d'installation suivante, vous serez invité à sélectionner l'un des ensembles de services préparés pour l'installation. À l'avenir, les services et leurs rôles peuvent être configurés manuellement, il n'est donc pas très important de choisir quoi dans cet onglet. Dans notre cas, «Core with Impala» était généralement installé. Ici aussi, vous pouvez indiquer la nécessité d'installer Cloudera Navigator. Si vous installez la version Enterprise, vous devez installer cet outil utile:

Dans l'onglet suivant pour les services de l'ensemble sélectionné, il est proposé de sélectionner les rôles et les hôtes sur lesquels ils seront installés. Vous trouverez ci-dessous quelques instructions pour l'installation de rôles sur des hôtes.
Rôles HDFS
NameNode - est placé en une seule copie sur l'un des nœuds principaux, de préférence le plus déchargé, car il est très important pour le fonctionnement du cluster et apporte une contribution significative à l'utilisation des ressources.
SecondaryNameNode - est placé en une seule copie sur l'un des nœuds principaux, de préférence pas sur le même nœud que NameNode (pour garantir la tolérance aux pannes).
Balancer - est placé en une seule copie sur l'un des nœuds principaux.
HttpFS - une API supplémentaire à HDFS, vous ne pouvez pas l'installer.
Passerelle NFS - un rôle très utile, vous permet de monter HDFS en tant que lecteur réseau. Il est placé en une seule copie sur l'un des nœuds principaux.
DataNode - placez tous les nœuds de données.
Rôles de la ruche
Passerelle - Fichiers de configuration Hive. Il est placé sur tous les hôtes du cluster.
Hive Metastore Server - un serveur de métadonnées, est installé en une seule copie sur l'un des nœuds principaux (par exemple, celui où PostgreSQL est installé - il y stocke ses données).
WebHCat - pas besoin d'installer.
HiveServer2 - est
installé en une seule copie sur le même nœud maître que le serveur Hive Metastore (une exigence pour leur travail conjoint).
Rôles de teinte
Hue Server - GUI pour HDFS, est installé en une seule copie sur l'un des nœuds principaux.
Load Balancer - un équilibreur de charge sur l'interface graphique pour HDFS, est installé en une seule copie sur l'un des nœuds principaux.
Rôles Impala
Impala StateStore - est placé en une seule copie sur l'un des nœuds principaux.
Impala Catalog Server - est placé en une seule copie sur l'un des nœuds principaux.
Impala Daemon - mettez tous les nœuds de données (vous pouvez laisser la valeur par défaut).
Rôles des services Cloudera Manager
Service Monitor, Activity Monitor, Host Monitor, Reports Manager, Event Server, Alert Publisher sont installés en une seule copie sur l'un des nœuds principaux.
Rôles d'Oozie
Oozie Server - est placé en une seule copie sur l'un des nœuds principaux.
Fil de rôles
ResourceManager - est placé en une seule copie sur l'un des nœuds principaux.
JobHistory Server - est
installé en une seule copie sur l'un des nœuds principaux.
NodeManager - placez tous les nœuds de données (vous pouvez laisser la valeur par défaut).
Rôles de ZooKeeper
ZooKeeper Server - pour garantir la tolérance aux pannes, il est installé en triple sur les nœuds principaux.
Rôles de Cloudera Navigator
Navigator Audit Server - est installé en une seule copie sur l'un des nœuds principaux.
Navigator Metadata Server - est placé en une seule copie sur l'un des nœuds principaux.

Après la distribution des rôles, il y a un onglet avec une courte liste de paramètres pour les services installés. Leur changement sera disponible après l'installation et à ce stade, ils peuvent rester inchangés:

Après les paramètres de service, il existe une configuration de base de données pour les services qui en ont besoin. Nous entrons le nom complet de l'hôte sur lequel PostgreSQL est installé, dans les zones de liste «Type de base de données», sélectionnez l'élément approprié et dans les champs restants spécifiez les données pour la connexion aux bases de données correspondantes. Une fois toutes les données entrées, cliquez sur le bouton «Tester la connexion» et vérifiez que les bases de données sont disponibles. Si tel est le cas, alors sur le côté droit du tableau en face de chacune des bases de données l'inscription «Réussi» apparaîtra:

Tout est prêt pour le déploiement des services. Passez à l'onglet suivant et observez ce processus. Si nous avons tout fait correctement, toutes les étapes seront terminées avec succès. Sinon, le processus sera interrompu à l'une des étapes et le journal des erreurs sera disponible en appuyant sur la flèche:

Félicitations - CDH est opérationnel!

Vous pouvez procéder à l'installation de parcelles supplémentaires.
Définition de parsels supplémentaires
Dans les cas où l'ensemble de base des services CHD n'est pas suffisant ou si une version plus récente est requise, vous pouvez installer des parsels supplémentaires qui étendent la liste des services disponibles qui peuvent être déployés dans le cluster. Au cours de notre projet, nous avions besoin du service Spark version 2.2 pour lancer les tâches développées et le fonctionnement des outils Data Discovery. Il ne fait pas partie de CDH, alors installez-le séparément. Pour ce faire, cliquez sur le bouton «Hôtes» et sélectionnez l'élément de la liste déroulante «Parcelles»:

Un onglet avec des parsels s'ouvre, affichant une liste des clusters gérés par ce Cloudera Manager et les parsels installés sur eux. Pour ajouter un parsel avec Spark 2.2, sélectionnez le cluster souhaité et cliquez sur le bouton "Configuration" dans le coin supérieur droit.

Nous cliquons sur le bouton "+", dans la ligne qui apparaît nous indiquons l'adresse du référentiel avec le parsel Spark 2.2 ("hostname / parcels / spark /") et cliquons sur le bouton "Save Changes":

Après ces manipulations, une nouvelle avec le nom SPARK2 devrait apparaître dans la liste des parsels de l'onglet précédent. Initialement, il apparaît comme disponible pour téléchargement, donc l'étape suivante consiste à le télécharger en cliquant sur le bouton "Télécharger":

Le parsel téléchargé doit être dispersé sur les nœuds du cluster afin que les services puissent être installés à partir de celui-ci. Pour ce faire, cliquez sur le bouton "Distribuer" qui apparaît sur le côté droit de la ligne avec le parsel SPARK2:

La dernière étape de l'utilisation du colis consiste à l'activer. Nous l'activons en cliquant sur le bouton "Activer", qui apparaît sur le côté droit de la ligne avec le fourchel:

Après confirmation, le service dont nous avons besoin devient disponible pour l'installation. Mais il y a des nuances. Pour installer certains services dans le cluster, vous devez effectuer des actions supplémentaires en plus d'installer le parsel. Habituellement, cela est écrit sur le site officiel dans la section sur l'installation et la mise à jour de ce service (voici son exemple pour Spark 2 - www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html ). Dans ce cas, vous devez télécharger le fichier CSD Spark 2 (disponible sur la page Informations sur la version et l'emballage - www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html ), l'installer sur l'hôte avec Cloudera Manager et redémarrer ce dernier. Faisons-le - téléchargez ce fichier, transférez-le sur l'hôte souhaité et exécutez les commandes à partir des instructions:
mv SPARK2_ON_YARN-2.1.0.cloudera1.jar /opt/cloudera/csd/ chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar chmod 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar systemctl restart cloudera-scm-server
Lorsque Cloudera Manager se lève, tout est prêt à installer Spark 2. Sur l'écran principal, cliquez sur la flèche à droite du nom du cluster et sélectionnez l'élément «Ajouter un service» dans le menu déroulant:

Dans la liste des services disponibles pour l'installation, sélectionnez celui dont nous avons besoin:

Dans l'onglet suivant, sélectionnez l'ensemble de dépendances pour le nouveau service. Par exemple, celui où la liste est plus large:

Vient ensuite l'onglet avec le choix des rôles et des hôtes sur lesquels ils seront installés, similaire à celui qui était lors de l'installation de CDH. Il est recommandé de placer le rôle de serveur d'historique en une seule copie sur l'un des nœuds principaux et la passerelle sur tous les serveurs de cluster:

Après avoir sélectionné les rôles, il est proposé de vérifier et de confirmer les modifications apportées au cluster lors de l'installation du service. Ici, vous pouvez tout laisser par défaut:

La confirmation des modifications démarre l'installation du service dans le cluster. Si tout est fait correctement, l'installation se terminera avec succès:
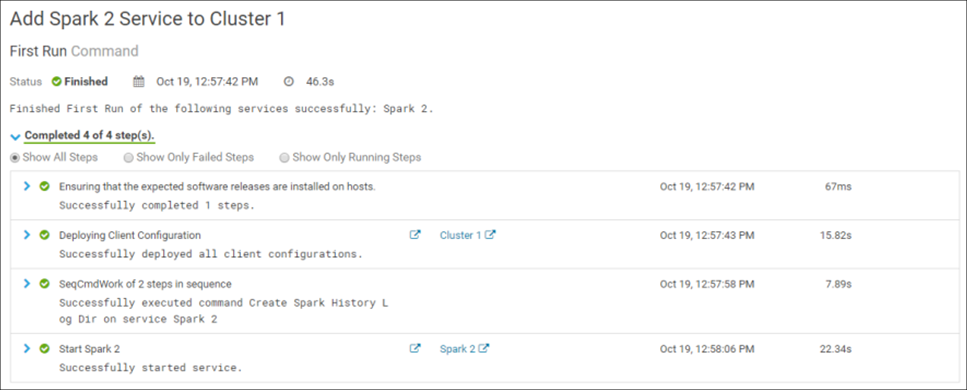
Félicitations! Spark 2 a été installé avec succès dans le cluster:

Vous devez redémarrer le cluster pour terminer le processus d'installation. Après cela, tout est prêt.
Des erreurs peuvent survenir lors de la phase d'installation du service. Par exemple, lors de l'installation sur l'un des environnements, il n'a pas été possible de déployer le rôle de passerelle Spark 2. La solution à ce problème a été aidée en copiant le contenu du fichier / var / lib / alternatives / spark2-conf de l'hôte sur lequel ce rôle a été installé avec succès dans un fichier similaire dans la machine à problème. Pour diagnostiquer les erreurs d'installation, il est pratique d'utiliser les fichiers journaux des processus correspondants, qui sont stockés dans le dossier / var / run / cloudera-scm-agent / process /.
C'est tout pour aujourd'hui. Le prochain article de la série couvrira le sujet de l'administration du cluster CDH.