Récemment, le concours iMaterialist Challenge (Furniture) s'est terminé à Kaggle, où la tâche consistait à classer les images en 128 types de meubles et d'articles ménagers (la classification dite à grains fins, où les classes sont très proches les unes des autres).
Dans cet article, je décrirai l'approche qui nous a amenés à la troisième place avec
m0rtido , mais avant de passer au point, je propose d'utiliser le réseau neuronal naturel dans ma tête pour résoudre ce problème et de diviser les chaises de la photo ci-dessous en trois classes.

Avez-vous deviné? Moi non plus.
Mais arrêtez-vous, tout d'abord.
Énoncé du problème
Lors du concours, nous avons reçu un ensemble de données dans lequel 128 classes d'objets de la vie courante étaient présentés, tels que des chaises, des téléviseurs, des casseroles et des oreillers sous la forme de personnages animés.
La partie formation de l'ensemble de données comprenait ~ 190 000 images (il est difficile de dire le nombre exact car les participants ne disposaient que d'un ensemble d'URL de téléchargement, dont certaines, bien sûr, ne fonctionnaient pas), et la distribution des classes était loin d'être uniforme (voir l'image cliquable ci-dessous) .

L'ensemble de données de test était représenté par 12800 images, et il était parfaitement équilibré: il y avait 100 images pour chaque classe. Un ensemble de données de validation a également été publié, qui avait également une distribution équilibrée des classes et était exactement la moitié de la taille de celle du test.
La mesure d'évaluation des tâches était
.
Comment avons-nous décidé?
Tout d'abord, nous avons téléchargé les données et regardé une petite partie avec nos yeux. Au lieu de nombreuses images, une image 1x1 ou un espace réservé avec une erreur a été téléchargé. Nous avons immédiatement supprimé ces images avec un script.
Transfert d'apprentissage
Il était évident qu'avec le nombre d'images et les délais disponibles, ce n'était pas une bonne idée de former des réseaux de neurones à partir de zéro sur cet ensemble de données. Au lieu de cela, nous avons utilisé l'approche d'apprentissage par transfert, dont l'idée est la suivante: le poids du réseau formé sur une tâche peut être utilisé pour un ensemble de données complètement différent et obtenir une qualité décente, voire une augmentation de la précision par rapport à l'apprentissage à partir de zéro.
Comment ça marche? Les couches cachées dans les réseaux de neurones profonds agissent comme des extracteurs de caractéristiques, extrayant des caractéristiques qui sont ensuite utilisées par les couches supérieures directement pour la classification.
Nous en avons profité en complétant une série de CNN profonds préalablement formés sur ImageNet. À ces fins, nous avons utilisé Keras et son zoo de modèles, où le code suivant était suffisant pour charger l'architecture terminée:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
Après cela, nous avons extrait les soi-disant signes de goulot d'étranglement (caractéristiques à la sortie de la dernière couche convolutionnelle) du réseau et formé softmax avec
abandon au-dessus d'eux.
Ensuite, nous avons connecté les poids «supérieurs» formés à la partie convolutionnelle du réseau et formé le réseau entier à la fois.
Voir le code. for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
Avec un tel réglage des réseaux, nous avons réussi à essayer les hacks suivants:
- Augmentation des données . Pour lutter contre le sur-ajustement, nous avons utilisé une augmentation très stricte: réflexion horizontale, zoom, décalages, rotations, inclinaisons, ajout de bruit de couleur, changements de canaux de couleur, entraînement sur cinq lignes de recadrage (angles et centre de l'image). Nous voulions également essayer FancyPCA , mais nous avons échoué par manque de ressources informatiques.
- TTA Pour prédire les classes lors de la validation et du test, nous avons utilisé l'augmentation, légèrement moins agressive que pendant l'entraînement, et avons fait la moyenne des résultats des prédictions pour augmenter la précision.
- Taux d'apprentissage du cyclisme . L'augmentation et la diminution cycliques du rythme d'entraînement ont aidé les modèles à ne pas rester coincés dans les creux locaux.
- Modelez la formation sur un sous-ensemble de classes . Comme vous pouvez le voir sur l'image au-dessus de la coupe, l'ensemble de données contenait des classes très proches les unes des autres. Si proches que sur certains groupes d'objets (par exemple, sur des chaises et fauteuils, qui étaient représentés jusqu'à 8 classes), nos modèles se sont beaucoup plus trompés que sur d'autres types d'objets. Nous avons essayé de former un CNN distinct pour reconnaître uniquement les chaises, en espérant qu'un tel réseau apprendrait à mieux distinguer les variétés de chaises qu'un réseau à usage général, mais cette approche n'a pas permis d'augmenter la précision.
Pourquoi? Une partie de la réponse à cette question est présentée dans l'image avant la coupe - les classes étaient si similaires que même avec le balisage initial des données, les personnes qui notaient les étiquettes de classe ne pouvaient pas les distinguer, il serait donc toujours impossible d'extraire les données de ces données. - Réseau de transformateurs spatiaux . Malgré le fait que nous ayons formé l'un des réseaux avec lui et obtenu une assez bonne précision, il n'a malheureusement pas été inclus dans la soumission finale.
- Fonction de perte pondérée . Pour compenser la distribution déséquilibrée des classes, nous avons utilisé la perte pondérée. Cela a aidé à la fois dans la formation des «tops» softmax et dans la formation continue de l'ensemble du réseau. Les poids ont été calculés à l'aide de la fonction de scikit-learn, puis passés à la méthode d'ajustement du modèle:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
Les réseaux ainsi formés représentaient 90% de notre ensemble final.
Empilement des étiquettes de goulot d'étranglement
Avertissement: ne jamais répéter la technique décrite plus tard dans la vie réelle.
Ainsi, comme nous l'avons déterminé dans la section précédente, les fonctionnalités de goulot d'étranglement des réseaux formés sur ImageNet peuvent être utilisées pour la classification sur d'autres tâches.
m0rtido a décidé d'aller plus loin et a proposé la stratégie suivante:
- Nous prenons toutes les architectures pré-formées à notre disposition (en particulier, NasNet Large, InceptionV4, Vgg19, Vgg16, InceptionV3, InceptionResnetV2, Resnet-50, Resnet-101, Resnet-152, Xception, Densenet-169, Densenet-121, Densenet-201 ont été prises ) et en extraire les signes de goulot d'étranglement. Nous compterons également les signes pour les versions réfléchies des images (une telle augmentation minimaliste).
- Réduisez la dimension des fonctionnalités de chacun des modèles à trois reprises à l'aide du SAR afin qu'elles s'intègrent normalement dans la mémoire RAM de 16 Go dont nous disposons.
- Concaténez ces entités en un grand vecteur d'entités.
- Nous allons enseigner un perceptron multicouche en plus de cela et générer des prédictions. Nous allons également nous entraîner avec la rupture en plis et faire la moyenne de toutes ces prédictions.
L'empilement monstrueux résultant a donné une énorme augmentation de la précision à l'ensemble global.
Ensemble de modèles
Après tout ce qui précède, nous avions environ deux douzaines de réseaux convolutifs obscurcis, ainsi que deux perceptrons au-dessus des signes de goulot d'étranglement. La question était: comment obtenir une seule prédiction de tout cela?
Dans le bon sens, dans la meilleure tradition Kaggle, nous devions nous
empiler par-dessus tout cela, mais pour faire l'empilement OOF, nous n'avions ni le temps ni un GPU, et la formation d'un modèle de haut niveau sur un document de validation a abouti à une très grande tenue. Par conséquent, nous avons décidé d'implémenter un algorithme assez simple pour la création d'un ensemble gourmand:
- Initialisez un ensemble vide.
- Nous essayons d'ajouter chaque modèle tour à tour et considérons le score. Nous sélectionnons le modèle qui augmente le plus la métrique et l'ajoutons à l'ensemble. Les résultats de la prédiction des modèles dans l'ensemble sont simplement moyennés.
- Si aucun des modèles n'améliore les performances, nous parcourons l'ensemble et essayons d'en supprimer les modèles. S'il s'avère que certains modèles sont supprimés pour que le score s'améliore, nous le faisons et revenons à l'étape 2.
Comme une métrique a été sélectionnée
. Cette formule a été choisie empiriquement de telle manière que
et
avéré être à peu près la même échelle. Une telle métrique intégrale était bien corrélée avec
à la fois sur la validation et sur un classement public.
De plus, le fait qu'à chaque itération nous ajoutions ou supprimions un modèle (c'est-à-dire que les poids du modèle restaient toujours des entiers), jouait le rôle d'une sorte de régularisation, ne permettant pas à l'ensemble de s'ajuster sous l'ensemble de données de validation.
En conséquence, l'ensemble comprenait les modèles suivants:
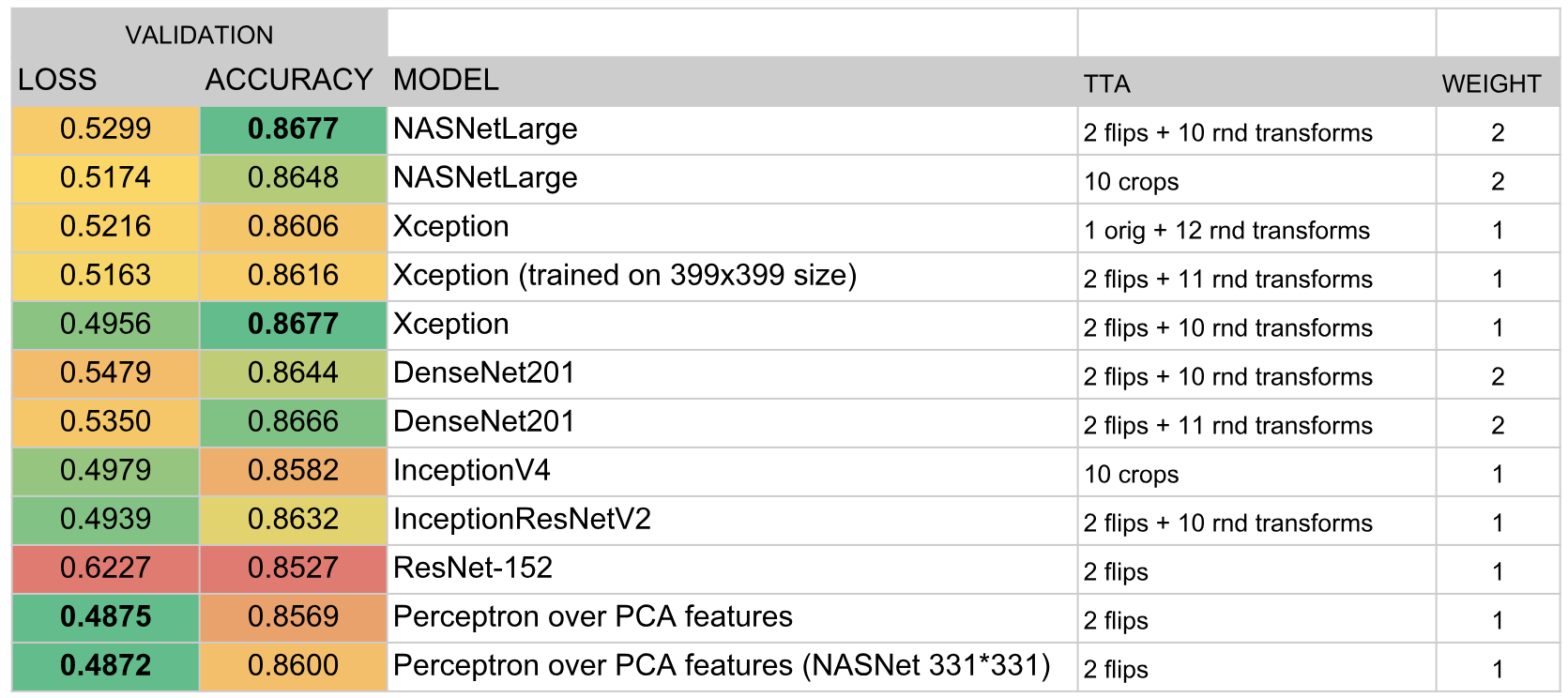
Résultats
Selon les résultats du concours, nous avons pris la troisième place. La clé du succès, il me semble, a été le choix réussi de l'algorithme d'ensemble et le temps considérable que
m0rtido et moi avons investi dans la formation d'un grand nombre de modèles.
