Salut Je m'appelle Sergey, je travaille comme ingénieur en chef à Sbertekh. Je travaille dans le domaine informatique depuis environ 10 ans, dont 6 dans les bases de données, les processus ETL, DWH et tout ce qui concerne les données. Dans cet article, je parlerai de Vertica - un SGBD analytique et véritablement en colonnes qui compresse, stocke, fournit rapidement des données de manière efficace et constitue une excellente solution de Big Data.

Informations générales
Le Big Data a commencé à se développer dans les années 2000, et des moteurs étaient nécessaires pour tout digérer. En réponse à cela, un certain nombre de SGBD en colonnes destinés à cet effet sont apparus - y compris Vertica.
Vertica ne stocke pas seulement ses données dans des colonnes, il le fait de manière rationnelle, avec un degré de compression élevé, il planifie également efficacement les requêtes et distribue rapidement les données. Les informations, qui dans un SGBD classique en minuscules occupent environ 1 To d'espace disque, sur Vertica prendront environ 200-300 Go, ce qui nous permet de réaliser de bonnes économies sur les disques.
Vertica a été initialement conçu comme un SGBD de colonne. D'autres bases essaient simplement d'imiter divers mécanismes de colonnes, mais elles ne réussissent pas toujours car le moteur est toujours conçu pour traiter les chaînes. En règle générale, les imitateurs transposent simplement la table, puis la traitent avec le mécanisme de ligne habituel.
Vertica est tolérant aux pannes, il n'a pas de nœud de contrôle - tous les nœuds sont égaux. En cas de problème avec l'un des serveurs du cluster, nous recevrons toujours les données. Très souvent, la réception des données à temps est essentielle pour les clients commerciaux, en particulier à un moment où la déclaration est fermée et où vous devez fournir des informations aux autorités financières.
Domaines d'application
Vertica est principalement un entrepôt de données analytiques. Vous ne devez pas lui écrire dans de petites transactions, vous ne devez le visser sur aucun site, etc. Vertica doit être considéré comme une sorte de couche batch, où il vaut la peine d'immerger les données dans de grands packs. Si nécessaire, Vertica est prêt à fournir ces données très rapidement - les requêtes pour des millions de lignes sont effectuées en quelques secondes.
Où cela peut-il être utile? Prenons, par exemple, une entreprise de télécommunications. Vertica peut y être utilisé pour la géoanalyse, le développement de réseaux, la gestion de la qualité, le marketing ciblé, l'étude des informations provenant des centres de contact, la gestion des sorties de clients et les solutions anti-fraude / anti-spam.

Dans d'autres secteurs d'activité, tout est à peu près le même - des analyses fiables et opportunes sont importantes pour le profit. Dans le commerce, par exemple, tout le monde essaie de personnaliser les clients, de distribuer des cartes de réduction à cet effet, de collecter des données sur où, quoi et quand une personne a acheté, etc. En analysant les tableaux d'informations de tous ces canaux, nous pouvons les comparer, construire des modèles et prendre des décisions menant à la croissance des bénéfices.
Seuil d'entrée
Aujourd'hui, tout employeur a besoin d'un analyste pour comprendre ce qu'est SQL. Si vous connaissez ANSI SQL, vous pouvez être appelé un utilisateur Vertica sûr. Si vous pouvez construire des modèles en Python et R, alors vous n'êtes qu'un «masseur» de données. Si vous maîtrisez Linux et avez des connaissances de base de l'administration Vertica, vous pouvez travailler en tant qu'administrateur. En général, le seuil d'entrée dans Vertica est bas, mais, bien sûr, toutes les nuances ne peuvent être trouvées qu'en bourrant une main pendant le fonctionnement.
Architecture matérielle
Envisagez Vertica au niveau du cluster. Ce SGBD fournit un traitement de données massivement parallèle (MPP) dans une architecture informatique distribuée - «rien partagé» - où, en principe, n'importe quel nœud est prêt à reprendre les fonctions de tout autre nœud. Propriétés principales:
- Il n'y a pas de point de défaillance unique
- chaque nœud est indépendant et indépendant,
- Il n'y a pas de point de connexion unique pour l'ensemble du système,
- les nœuds d'infrastructure sont dupliqués,
- les données sur les nœuds de cluster sont automatiquement copiées.
Le cluster évolue linéairement sans aucun problème. Nous mettons simplement les serveurs dans une étagère et les connectons via une interface graphique. En plus des serveurs série, le déploiement sur des machines virtuelles est possible. Que peut-on réaliser avec l'extension?
- Le volume augmente pour les nouvelles données
- Augmentez la charge de travail maximale
- Amélioration de la résilience. Plus il y a de nœuds dans le cluster, moins il est probable que le cluster tombe en panne en raison d'une défaillance, et donc, plus nous nous rapprochons de la disponibilité 24/7.
Mais il y a quelques points à considérer. Périodiquement, les nœuds doivent être supprimés du cluster pour la maintenance. Un autre cas assez courant dans les grandes organisations est que les serveurs sortent de la garantie et passent d'un environnement productif à une sorte d'environnement de test. À leur place, il y en a de nouveaux qui sont sous la garantie du fabricant. Sur la base des résultats de toutes ces opérations, un rééquilibrage est nécessaire. Il s'agit d'un processus où les données sont redistribuées entre les nœuds - en conséquence, la charge de travail est redistribuée. Il s'agit d'un processus gourmand en ressources et sur les clusters contenant une grande quantité de données, il peut réduire considérablement les performances. Pour éviter cela, vous devez sélectionner la fenêtre de service - l'heure à laquelle la charge est minimale, auquel cas les utilisateurs ne la remarqueront pas.
Projections
Pour comprendre comment les données sont stockées dans Vertica, vous devez traiter avec l'un des concepts de base - la projection.
Les unités logiques de stockage d'informations sont des diagrammes, des tableaux et des vues. Les unités physiques sont des projections. Les projections sont de plusieurs types:
- Superprojection
- Projections spécifiques aux requêtes
- Projections agrégées
Lors de la création d'une table, une
super projection est automatiquement créée qui contient toutes les colonnes de notre table. Si vous avez besoin d'accélérer l'un des processus habituels, nous pouvons créer une
projection orientée requête spéciale qui contiendra, disons, 3 colonnes sur 10.
Le troisième type est également destiné aux
projections agrégées d'accélération. Je n'entrerai pas dans leurs sous-classes - ce n'est pas très intéressant. Je tiens à vous avertir immédiatement qu'il ne vaut pas la peine de résoudre constamment vos problèmes d'exécution de requêtes en créant de nouvelles projections. Finalement, le cluster commencera à ralentir.
Lors de la création de projections, nous devons évaluer si nos requêtes ont suffisamment de superprojections. Si nous voulons toujours expérimenter, nous ajoutons strictement une nouvelle projection. Si des problèmes surviennent, il sera plus facile de trouver la cause profonde. Pour les grands tableaux, créez une projection segmentée. Il est divisé en segments répartis sur plusieurs nœuds, ce qui augmente la tolérance aux pannes et minimise la charge sur un nœud. Si les comprimés sont petits, il est préférable de faire des projections non segmentées. Ils sont entièrement copiés sur chaque nœud et les performances sont ainsi augmentées. Je vais faire une réservation: pour Vertica, une "petite" table fait environ 1 million de lignes.
Tolérance aux pannes
La tolérance aux pannes dans Vertica est implémentée à l'aide du mécanisme K-Safety. Il est assez simple en termes de description, mais complexe en termes de travail au niveau du moteur. Il peut être contrôlé à l'aide du paramètre K-Safety - il peut avoir une valeur de 0, 1 ou 2. Ce paramètre définit le nombre de copies de données de projection segmentées.
Les copies des projections sont appelées projections de copains. J'ai essayé de traduire cette phrase par le biais du traducteur Yandex et il s'est avéré quelque chose comme une «projection acolyte». Google proposait des options et plus intéressantes. Typiquement, ces projections sont appelées partenaires ou voisines, selon leur fonction. Ce sont des projections qui sont simplement stockées sur des nœuds voisins et donc réservées. Les projections non segmentées n'ont pas de projections copain - elles sont copiées complètement.
Comment ça marche? Prenons un cluster de cinq machines. Soit K-safety égal à 1.

Les nœuds sont numérotés et sous eux se trouvent des projections de partenaires écrites qui sont stockées sur eux. Supposons que nous ayons un nœud déconnecté. Que va-t-il se passer?

Le nœud 1 contient une projection conviviale du nœud 2. Par conséquent, la charge sur le nœud 1 augmentera, mais le cluster ne cessera pas de fonctionner. Et maintenant, cette situation:
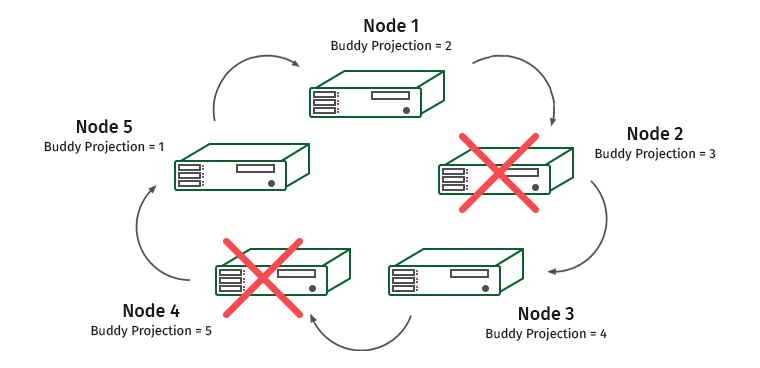
Le nœud 3 contient la projection du nœud 4 et les nœuds 1 et 3 seront surchargés.
Nous compliquons la tâche. K-Safety = 2, désactivez deux nœuds adjacents.
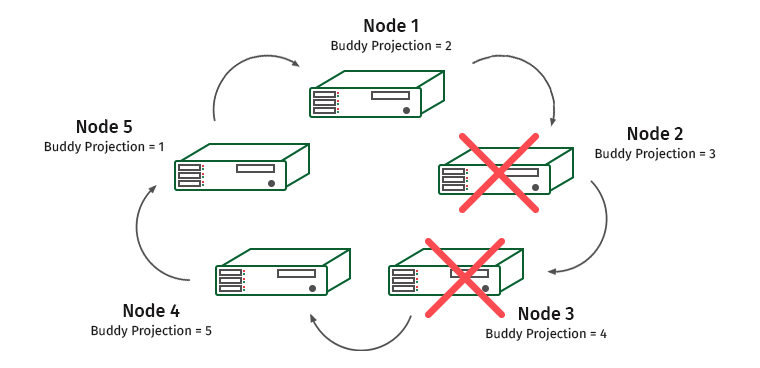
Ici, les nœuds 1 et 4 seront surchargés (le nœud 2 contient la projection du nœud 1 et le nœud 3 contient la projection du nœud 4).
Dans de telles situations, le moteur du système reconnaît que l'un des nœuds ne répond pas et la charge est transférée au nœud voisin. Il sera utilisé jusqu'à ce que le nœud soit à nouveau restauré. Une fois que cela se produit, la charge et les données sont redistribuées. Dès que nous perdons plus de la moitié du cluster ou des nœuds contenant toutes les copies de certaines données, le cluster se lève.
Stockage de données logique
Vertica possède des zones de stockage optimisées pour l'écriture, des zones optimisées pour la lecture et un mécanisme Tuple Mover qui permet aux données de circuler du premier au second.
Lorsque vous utilisez les opérations COPY, INSERT, UPDATE, nous nous retrouvons automatiquement dans WOS (Write Optimized Store), une zone où les données ne sont pas optimisées pour la lecture et triées uniquement sur demande, stockées sans compression ni indexation. Si les volumes de données sont trop importants pour la zone WOS, alors en utilisant l'instruction DIRECT supplémentaire, ils doivent être écrits immédiatement dans ROS. Sinon, le WOS sera plein et nous planterons.
Une fois le délai spécifié dans les paramètres expiré, les données du WOS sont transférées vers ROS (Read Optimized Store) - une structure de stockage sur disque optimisée et orientée en lecture. ROS stocke la majeure partie des données, ici elles sont triées et compressées. Les données ROS sont divisées en conteneurs de stockage. Un conteneur est un ensemble de lignes créées par des opérateurs de traduction (COPY DIRECT) et est stocké dans un groupe spécifique de fichiers.
Peu importe où les données sont écrites - en WOS ou en ROS - elles sont disponibles immédiatement. Mais la lecture à partir de WOS est plus lente car les données n'y sont pas regroupées.

Tuple Mover est un outil de nettoyage qui effectue deux opérations:
- Déplacement - compresse et trie les données dans WOS, les déplace vers ROS et crée de nouveaux conteneurs pour elles dans ROS.
- Mergeout - balayant derrière nous lorsque nous utilisons DIRECT. Nous ne sommes pas toujours en mesure de charger autant d'informations pour obtenir de gros conteneurs ROS. Par conséquent, il combine périodiquement de petits conteneurs ROS dans des conteneurs plus grands, nettoie les données marquées pour la suppression, tout en travaillant en arrière-plan (selon l'heure spécifiée dans la configuration).
Quels sont les avantages du stockage sur colonne?
Si nous lisons des lignes, alors, par exemple, pour exécuter une commande
SELECT 1,11,15 from table1
nous devrons lire tout le tableau. C'est une énorme quantité d'informations. Dans ce cas, l'approche par colonne est plus rentable. Il vous permet de compter uniquement les trois colonnes dont nous avons besoin, économisant ainsi de la mémoire et du temps.

Affectation des ressources
Afin d'éviter les problèmes, l'utilisateur doit être un peu limité. Il y a toujours une chance que l'utilisateur écrive une requête lourde qui engloutira toutes les ressources. Par défaut, Vertica occupe une partie importante de la zone générale, et en outre, des zones distinctes pour Tuple Mover, WOS et les processus système (récupération, etc.) sont mises en évidence.
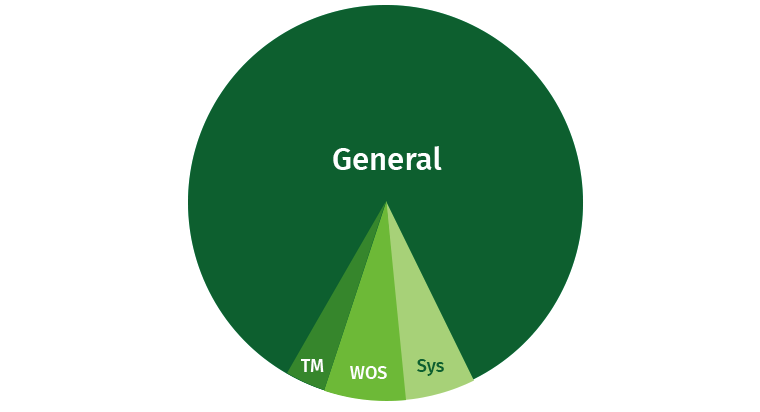
Essayons de partager ces ressources. Nous créons des zones pour les écrivains, pour les lecteurs et pour les requêtes lentes et de faible priorité.

Si nous regardons les tables système dans lesquelles nos ressources sont stockées - les pools de ressources - alors nous verrons de nombreux paramètres avec lesquels vous pouvez tout ajuster plus finement. Au début, vous ne devriez pas vous lancer là-dedans, il vaut mieux se limiter simplement à couper la mémoire pour certaines tâches. Lorsque vous acquérez de l'expérience et êtes sûr à 100% que vous faites tout correctement, il sera possible d'expérimenter.
Les paramètres légers incluent la priorité d'exécution, les sessions compétitives et la quantité de mémoire allouée. Et même avec des processeurs, nous pouvons corriger quelque chose. Pour travailler avec ces paramètres, vous avez besoin d'avoir pleinement confiance dans l'exactitude de vos actions, il est donc préférable de solliciter le soutien de l'entreprise et d'avoir le droit de faire une erreur.
Vous trouverez ci-dessous un exemple de demande par laquelle vous pouvez voir les paramètres du pool général:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL et autres fonctionnalités
- Vertica vous permet d'écrire en SQL-99 - toutes les fonctionnalités sont prises en charge.
- Verica possède de grandes capacités d'analyse - même des outils d'apprentissage automatique sont inclus
- Vertica peut indexer des textes
- Vertica traite des données semi-structurées
Intégration
Vertica, comme tous les outils actuels, est sérieusement intégré à d'autres systèmes. Capable de bien fonctionner avec HDFS (Hadoop). Dans les versions antérieures, Vertica ne pouvait télécharger que des données depuis HDFS de certains formats, mais maintenant il peut tout faire, fonctionne avec tous les formats, par exemple, ORC et Parquet. Il peut même joindre des fichiers en tant que tables externes et stocker ses données dans des conteneurs ROS directement sur HDFS. Dans la huitième version de Vertica, une optimisation significative de la vitesse de travail avec HDFS, un catalogue de métadonnées et l'analyse de ces formats ont été effectués. Vous pouvez créer un cluster Vertica directement sur un cluster Hadoop.
À partir de la version 7.2, Vertica peut fonctionner avec Apache Kafka - si quelqu'un a besoin d'un courtier de messages.
Vertica 8 a un support complet pour Spark. Il est possible de copier des données de Spark vers Vertica et vice versa.
Conclusion
Vertica est une bonne option pour travailler avec des mégadonnées qui ne nécessitent pas beaucoup de connaissances en entrée. Ce SGBD possède de vastes capacités analytiques. Parmi les inconvénients - cette solution n'est pas open source, mais vous pouvez essayer de déployer gratuitement avec une limite de 1 To et trois nœuds - cela suffit pour comprendre si vous avez besoin de Vertica ou non.