Tous les systèmes de modération modernes utilisent le
crowdsourcing ou l'apprentissage automatique qui est déjà devenu un classique. Lors de la prochaine formation ML à Yandex, Konstantin Kotik, Igor Galitsky et Alexey Noskov ont parlé de leur participation au concours pour l'identification en masse des commentaires offensants. Le concours s'est déroulé sur la plateforme Kaggle.
- Bonjour à tous! Je m'appelle Konstantin Kotik, je suis un data scientist de la société Button of Life, un étudiant du département de physique et de la Graduate School of Business de l'Université d'État de Moscou.
Aujourd'hui, nos collègues, Igor Galitsky et Alexei Noskov, vous parleront du concours Toxic Comment Classification Challenge Challenge, dans lequel notre équipe DecisionGuys a pris la 10e place parmi 4551 équipes.
Une discussion en ligne sur des sujets qui nous importent peut être difficile. Les insultes, l'agression et le harcèlement qui se produisent en ligne obligent souvent de nombreuses personnes à abandonner la recherche d'opinions appropriées sur des questions qui les intéressent, à refuser de s'exprimer.
De nombreuses plateformes ont du mal à communiquer efficacement en ligne, mais cela conduit souvent de nombreuses communautés à simplement fermer les commentaires des utilisateurs.
Une équipe de recherche de Google et d'une autre société travaille sur des outils pour améliorer la discussion en ligne.
L'une des astuces sur lesquelles ils se concentrent consiste à explorer les comportements négatifs en ligne tels que les commentaires toxiques. Ce sont des commentaires qui peuvent être offensants, irrespectueux ou simplement forcer l'utilisateur à quitter la discussion.

À ce jour, ce groupe a développé une API publique qui peut déterminer le degré de toxicité d'un commentaire, mais leurs modèles actuels font encore des erreurs. Et dans ce concours, nous, les Kegglers, avons été mis au défi de construire un modèle capable d'identifier les commentaires contenant des menaces, de la haine, des insultes, etc. Et idéalement, ce modèle devait être meilleur que le modèle actuel pour leur API.
Nous avons pour tâche de traiter du texte: identifier puis classer les commentaires. En tant qu'exemples de formation et de test, des commentaires ont été fournis à partir des pages de discussion Wikipédia. Il y avait environ 160 000 commentaires dans le train, 154 000 dans le test.

L'échantillon de formation a été marqué comme suit. Chaque commentaire comporte six étiquettes. Les étiquettes prennent la valeur 1 si le commentaire contient ce type de toxicité, 0 sinon. Et il se peut que toutes les étiquettes soient nulles, un cas de commentaire adéquat. Ou il se peut qu'un commentaire contienne plusieurs types de toxicité, immédiatement une menace et une obscénité.
En raison du fait que nous sommes en ondes, je ne peux pas démontrer d'exemples spécifiques de ces classes. En ce qui concerne l'échantillon d'essai, pour chaque commentaire, il était nécessaire de prévoir la probabilité de chaque type de toxicité.
La métrique de qualité est l'AUC ROC moyenne sur les types de toxicité, c'est-à-dire la moyenne arithmétique de l'AUC ROC pour chaque classe séparément.
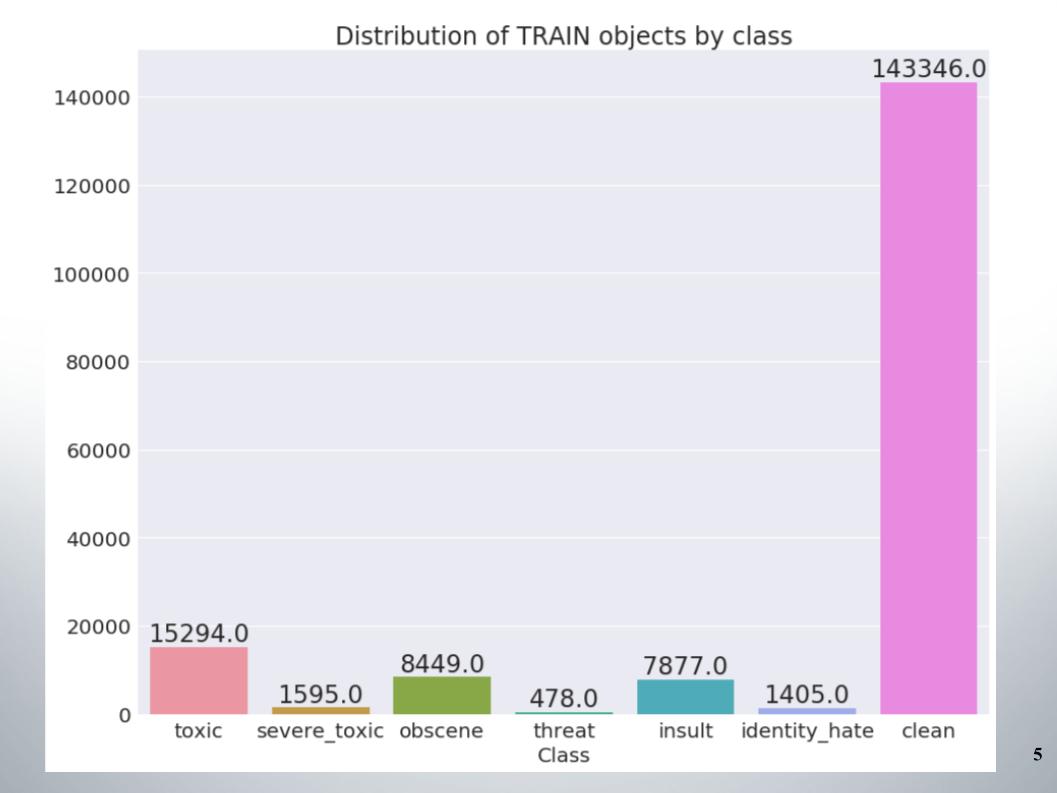
Voici la répartition des objets par classes dans l'ensemble d'apprentissage. On peut voir que les données sont très déséquilibrées. Je dois dire tout de suite que notre équipe a obtenu un score sur un échantillon de méthodes pour travailler avec des données déséquilibrées, par exemple le suréchantillonnage ou le sous-échantillonnage.

Lors de la construction du modèle, j'ai utilisé un prétraitement des données en deux étapes. La première étape est le prétraitement de base des données, ce sont les transformations de la vue sur la diapositive, cela amène le texte en minuscules, supprimant les liens, les adresses IP, les nombres et la ponctuation.

Pour tous les modèles, ce prétraitement de base des données a été utilisé. Lors de la deuxième étape, un prétraitement partiel des données a été effectué - en remplaçant les émoticônes par les mots correspondants, en déchiffrant les abréviations, en corrigeant les fautes de frappe en profanant, en ramenant les différents types de tapis sous la même forme, et en supprimant également les images. Dans certains commentaires, des liens vers des images étaient indiqués, nous les avons simplement supprimés.
Pour chacun des modèles, un prétraitement partiel des données et de ses différents éléments a été utilisé. Tout cela a été fait pour que les modèles de base réduisent la corrélation croisée entre les modèles de base lors de la construction d'une composition supplémentaire.
Passons à la partie la plus intéressante - la construction d'un modèle.
J'ai immédiatement abandonné l'approche classique du sac de mots. En raison du fait que dans cette approche, chaque mot est un attribut distinct. Cette approche ne prend pas en compte l'ordre général des mots, on suppose que les mots sont indépendants. Dans cette approche, la génération du texte se produit de sorte qu'il y ait une certaine distribution dans les mots, un mot est sélectionné au hasard dans cette distribution et inséré dans le texte.
Bien sûr, il existe des processus génératifs plus complexes, mais l'essence ne change pas - cette approche ne prend pas en compte l'ordre général des mots. Vous pouvez aller aux engrammes, mais seul l'ordre des mots des fenêtres y sera pris en compte, et non général. Par conséquent, j'ai également compris mes coéquipiers qu'ils devaient utiliser quelque chose de plus intelligent.
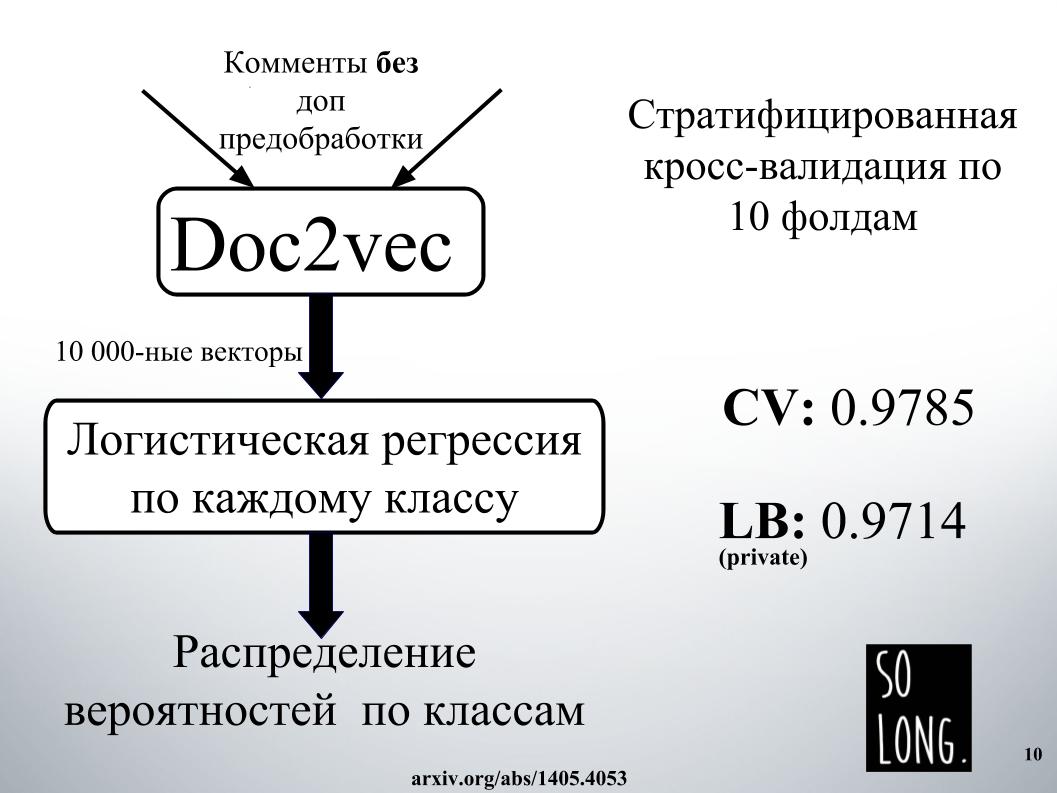
La première chose intelligente qui m'est venue à l'esprit a été d'utiliser une représentation vectorielle à l'aide de Doc2vec. Il s'agit de Word2vec plus un vecteur qui prend en compte l'unicité d'un document particulier. Dans l'article d'origine, ce vecteur est appelé paragraphe id.
Ensuite, selon une telle représentation vectorielle, une régression logistique a été étudiée, où chaque document était représenté par un vecteur de 10 000 dimensions. L'évaluation de la qualité a été réalisée sur une validation croisée de dix plis, elle a été stratifiée, et il est important de noter que la régression logistique a été étudiée pour chaque classe, six problèmes de classification ont été résolus séparément. Et à la fin, le résultat a été une distribution de probabilité par classe.
La régression logistique est entraînée depuis très longtemps. Je ne rentre généralement pas dans la RAM. Dans les installations d'Igor, ils ont passé une journée quelque part pour obtenir le résultat, comme sur une diapositive. Pour cette raison, nous avons immédiatement refusé d'utiliser Doc2vec en raison d'attentes élevées, bien qu'il puisse être amélioré de 1 000 si un commentaire avec un prétraitement de données supplémentaire était effectué.

Les plus intelligents que nous et les autres concurrents avons utilisés étaient des réseaux de neurones récurrents. Ils reçoivent séquentiellement les mots à l'entrée, mettant à jour leur état caché après chaque mot. Igor et moi avons utilisé le réseau récurrent GRU pour l'intégration de mots fastText, ce qui est spécial en ce qu'il résout de nombreux problèmes de classification binaire indépendants. Prédisez la présence ou l'absence du mot de contexte indépendamment.
Nous avons également effectué une évaluation de la qualité sur la validation croisée de dix plis, elle n'a pas été stratifiée ici, et ici la distribution de probabilité a été immédiatement obtenue par classe. Chaque problème de classification binaire n'a pas été résolu séparément, mais un vecteur à six dimensions a été immédiatement généré. C'était notre l'un des meilleurs modèles simples.
Vous demandez, quel était le secret du succès?
Cela consistait à mélanger, il y en avait beaucoup, avec empilement et mise en réseau dans l'approche. L'approche de réseautage doit être représentée sous forme de graphique dirigé.
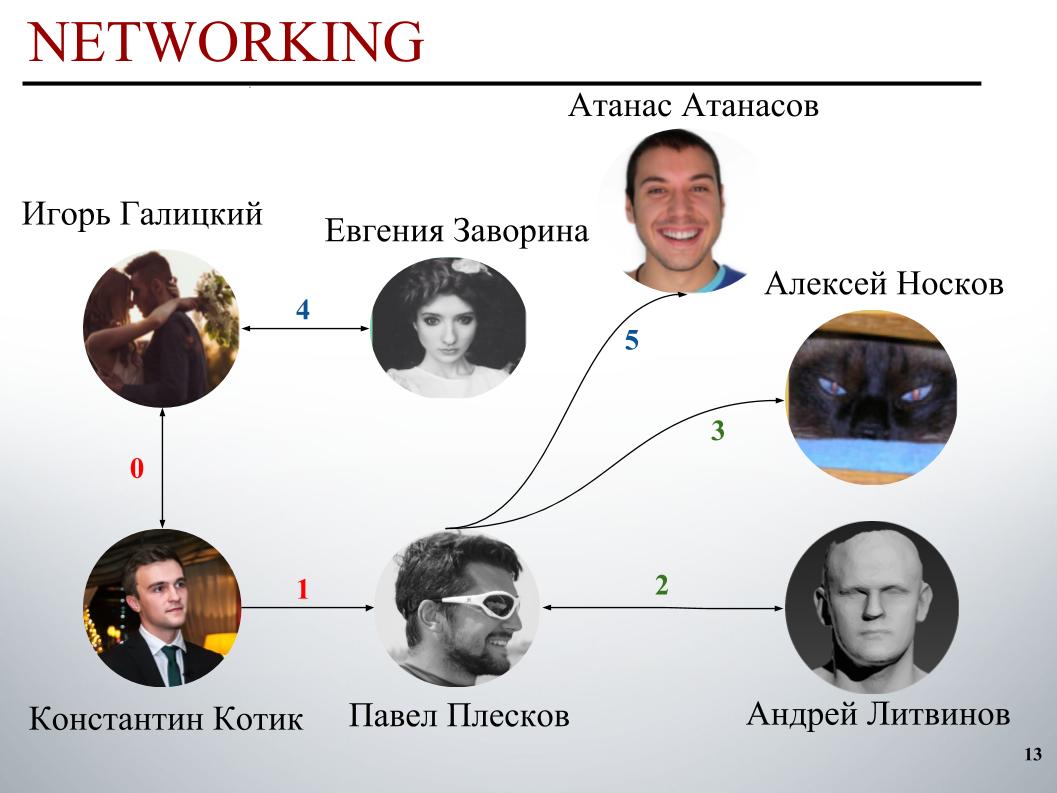
Au début du concours, l'équipe de DecisionGuys était composée de deux personnes. Ensuite, Pavel Pleskov dans la chaîne ODS Slack a exprimé le désir de faire équipe avec quelqu'un du top 200. A cette époque, nous étions quelque part à la 157e place, et Pavel Pleskov à la 154e place, quelque part dans le quartier. Igor a remarqué son désir de se joindre et je l'ai invité dans l'équipe. Andrey Litvinov nous a ensuite rejoint, puis Pavel a invité le grand maître Alexei Noskov dans notre équipe. Igor - Eugene. Et le dernier partenaire de notre équipe était le Bulgare Atanas Atanasov, et c'était le résultat d'un ensemble international humain.
Maintenant, Igor Galitsky racontera comment il a enseigné le gru, plus en détail il parlera des idées et des approches de Pavel Pleskov, Andrei Litvinov et Atanas Atanasov.
Igor Galitsky:
- Je suis data scientist chez Epoch8, et je vais parler de la plupart des architectures que nous avons utilisées.
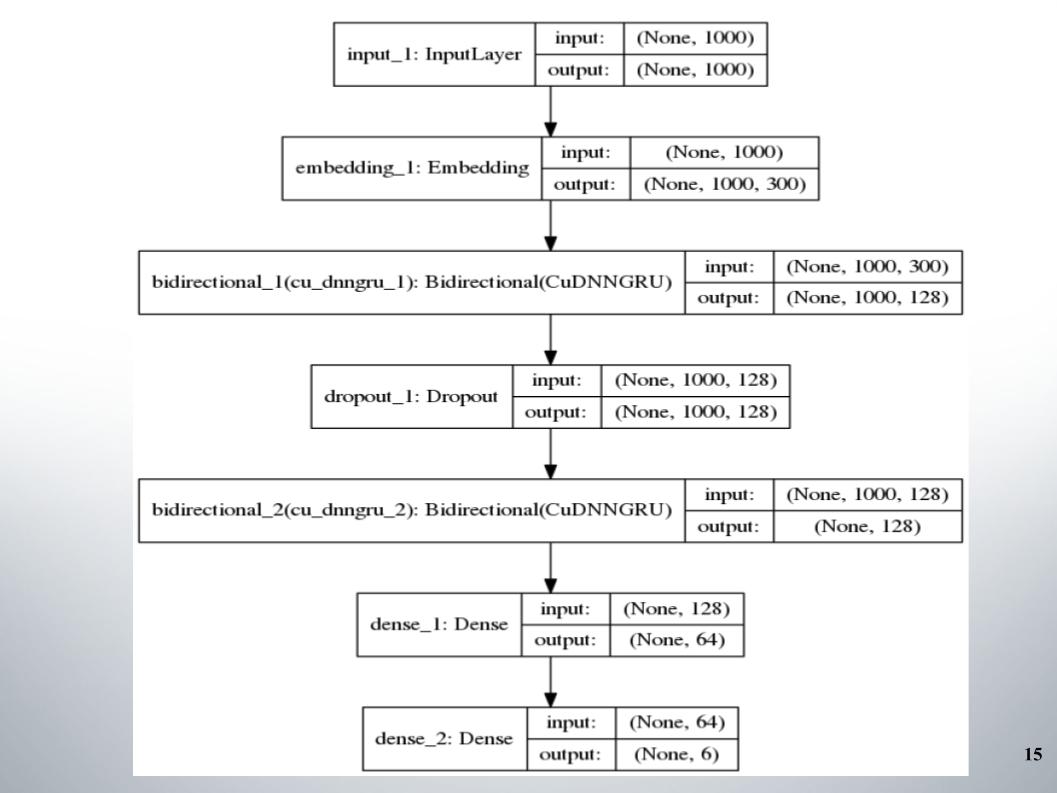
Tout a commencé avec le gru didirectionnel standard à deux couches, presque toutes les équipes l'ont utilisé, et fastText, la fonction d'activation EL, a été utilisée comme intégration.
Il n'y a rien de spécial à dire, une architecture simple, sans fioritures. Pourquoi nous a-t-elle donné de si bons résultats avec lesquels nous sommes restés dans le top 150 pendant un certain temps? Nous avons eu un bon prétraitement du texte. Il fallait continuer.
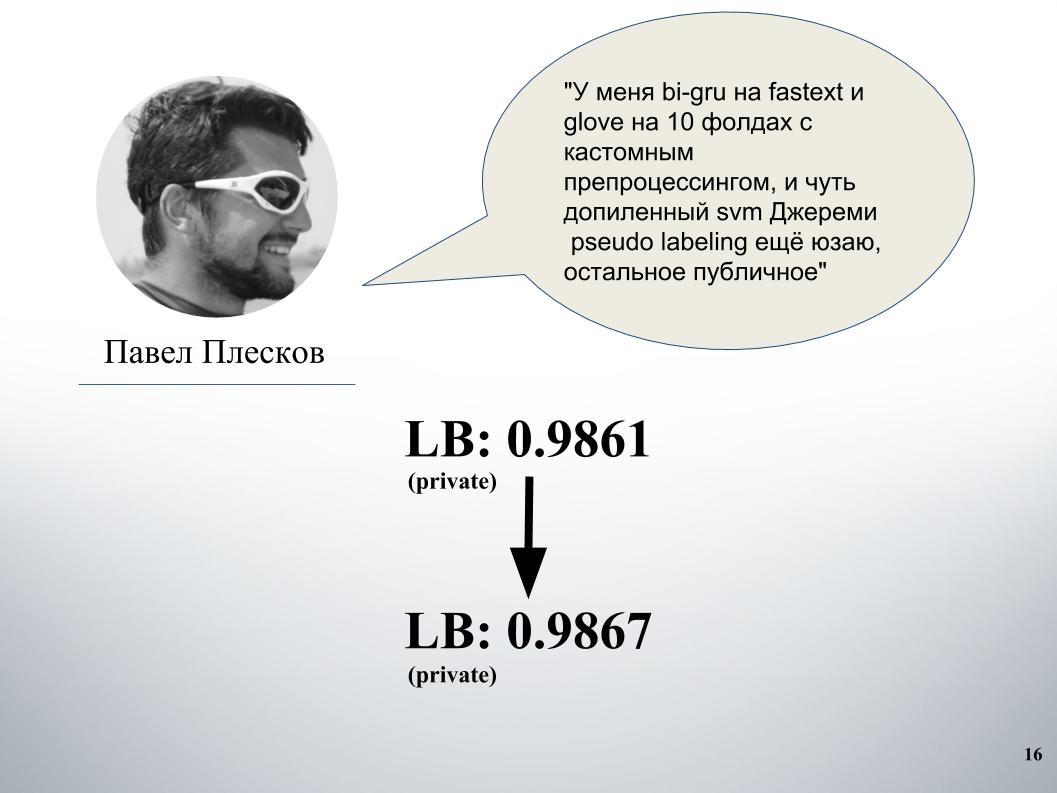
Paul avait sa propre approche. Après avoir fusionné avec le nôtre, cela a donné une augmentation significative. Avant cela, nous avions un mélange de gru et de modèle sur Doc2vec, cela donnait 61 LB.
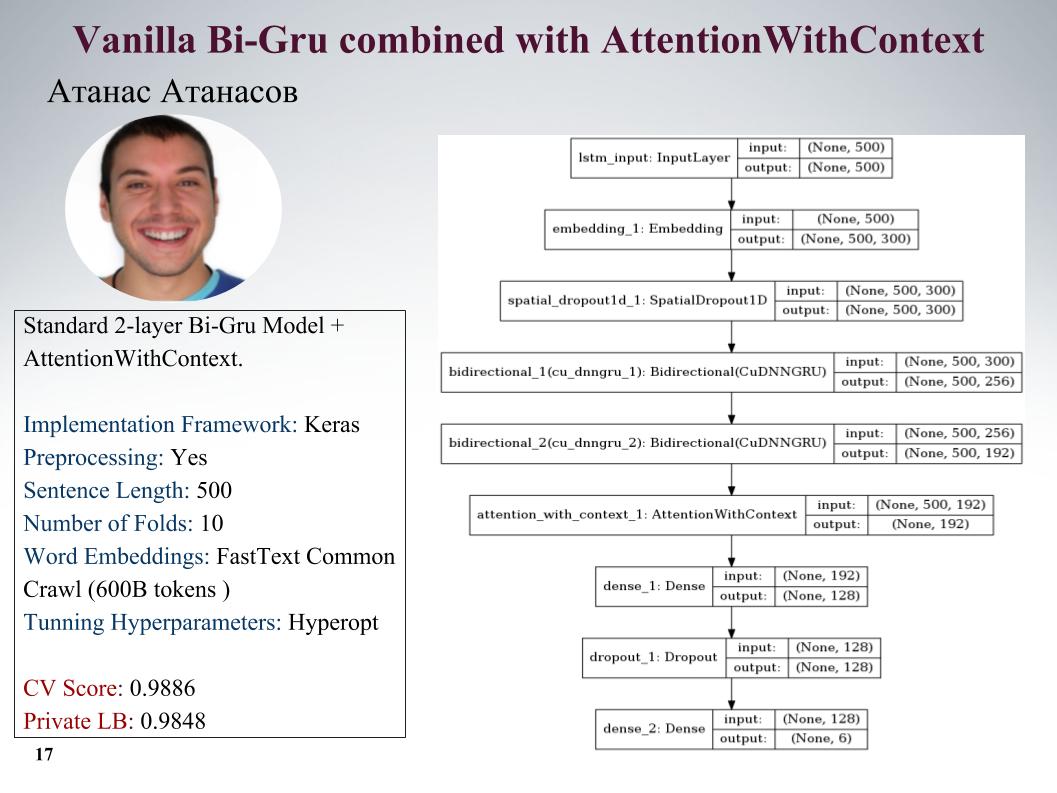
Je vais vous parler des approches d'Atanas Atanasov, il est directement un passionné de tout nouvel article. Voici gru avec attention, tous les paramètres de la diapositive. Il avait beaucoup d'approches vraiment cool, mais jusqu'au dernier moment, il a utilisé son prétraitement, et tous les bénéfices ont été nivelés. Vitesse sur la diapositive.
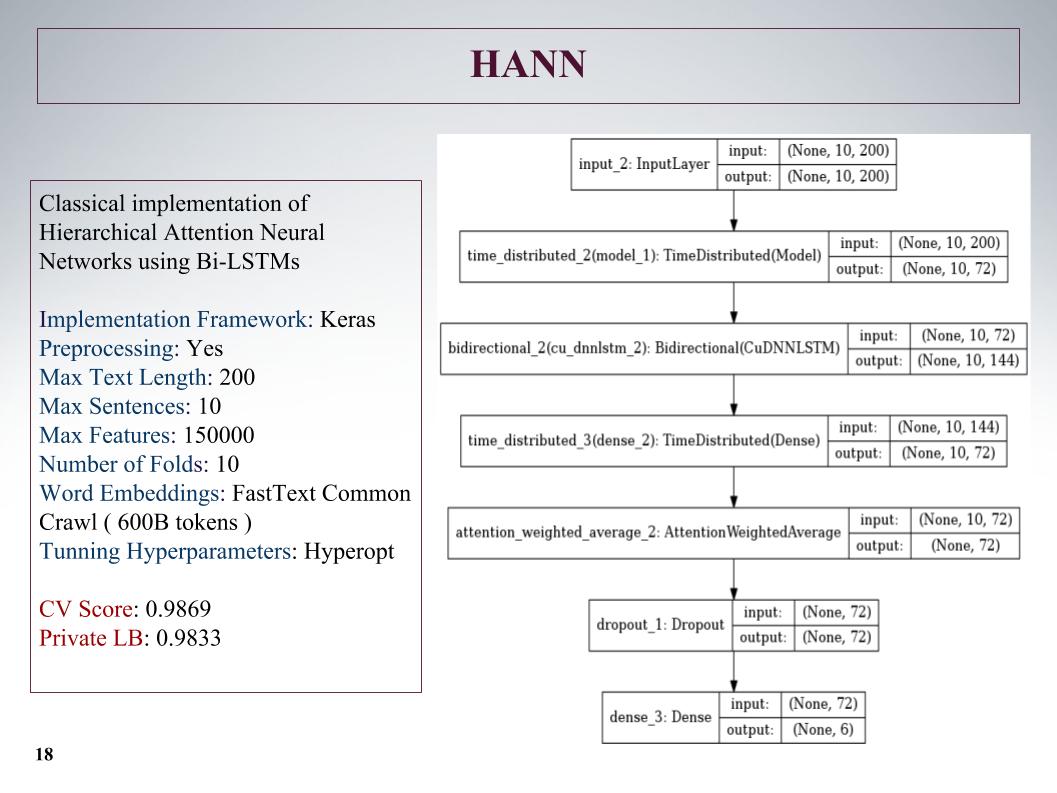
Ensuite, il y a eu une attention hiérarchique, elle a donné des résultats encore pires, car au départ c'était un réseau de classification des documents composés de phrases. Il l'a foutu, mais l'approche n'est pas très.
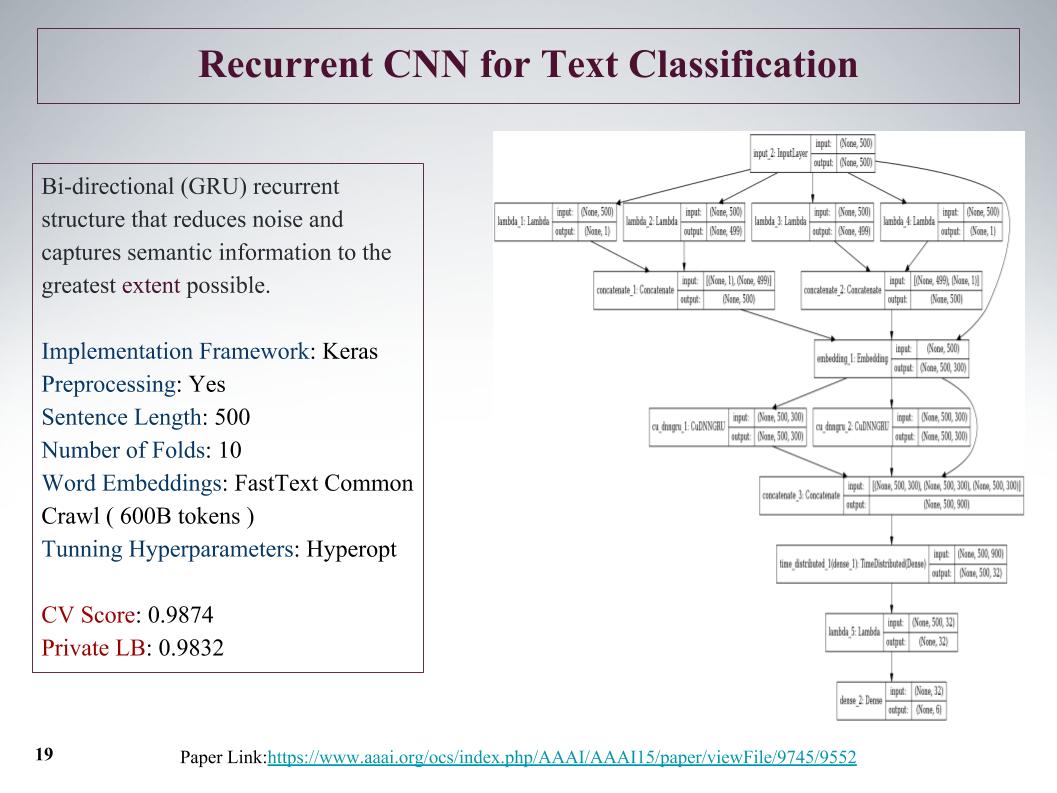
Il y avait une approche intéressante, nous pouvons initialement obtenir des fonctionnalités de l'offre depuis le début et la fin. Avec l'aide de la convolution, des couches convolutionnelles, nous obtenons séparément des fonctionnalités à gauche et à droite de l'arborescence. C'est du début et de la fin de la phrase, puis ils fusionnent et parcourent à nouveau gru.

Également Bi-GRU avec bloc d'attention. C'est l'un des meilleurs sur le privé était un réseau assez profond, a montré de bons résultats.

La prochaine approche consiste à mettre en évidence les fonctionnalités autant que possible? Après la couche du réseau récurrent, nous faisons trois autres couches parallèles de convolution. Et ici, nous n'avons pas pris des phrases aussi longues, les avons réduites à 250, mais en raison de trois circonvolutions, cela a donné un bon résultat.

C'était le réseau le plus profond. Comme Atanas l'a dit, il voulait juste enseigner quelque chose de grand et d'intéressant. Une grille convolutionnelle ordinaire qui a appris des caractéristiques du texte, les résultats n'ont rien de spécial.

C'est une nouvelle approche assez intéressante, en 2017 il y avait un article sur ce sujet, il a été utilisé pour ImageNet, et là cela nous a permis d'améliorer le résultat précédent de 25%. Sa principale caractéristique est qu'une petite couche est lancée parallèlement au bloc de convolution, qui enseigne les poids pour chaque convolution dans ce bloc. Elle a donné une approche très cool, malgré la réduction des peines.
Le problème est que la longueur maximale des phrases dans ces tâches atteint 1 500 mots, il y a eu de très gros commentaires. D'autres équipes ont également réfléchi à la façon d'attraper cette grande offre, comment la trouver, car tout n'est pas très poussé. Et beaucoup ont dit qu'à la fin de la phrase il y avait un INFA très important. Malheureusement, dans toutes ces approches, cela n'a pas été pris en compte, car le début a été pris. Cela donnerait peut-être une nouvelle augmentation.

Voici l'architecture AC-BLSTM. L'essentiel est que si la division inférieure en deux parties, en plus de l'attention, est une traction intelligente, mais en parallèle, il est toujours normal, et tout cela se concrétise. Aussi de bons résultats.

Et Atanas tout son zoo de mannequins, alors c'était un mélange cool. En plus des modèles eux-mêmes, j'ai ajouté quelques fonctionnalités de texte, généralement la longueur, le nombre de lettres majuscules, le nombre de mauvais mots, le nombre de caractères, tout cela ajouté. Validation croisée de cinq plis, et obtenu d'excellents résultats sur le LB 0.9867 privé.
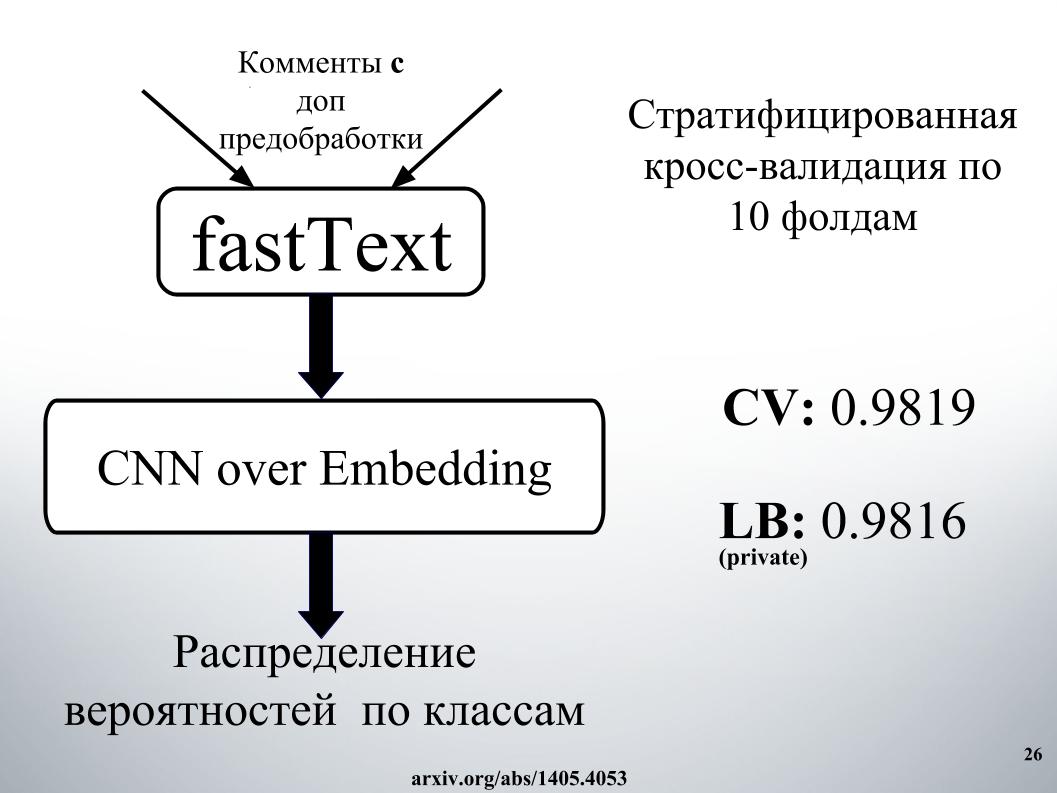
Et la deuxième approche, il a enseigné avec une intégration différente, mais les résultats étaient pires. Presque tout le monde a utilisé fastText.
Je voulais parler de l'approche de notre autre collègue, Andrei, avec le surnom de Laol à ODS. Il a enseigné beaucoup de noyaux publics, il les buvait comme s'il était hors de lui, et cela a vraiment donné des résultats très cool. Vous ne pourriez pas faire tout cela, mais prenez simplement un tas de noyaux publics différents, même sur tf-idf, il existe toutes sortes de gru convolutionnaires.
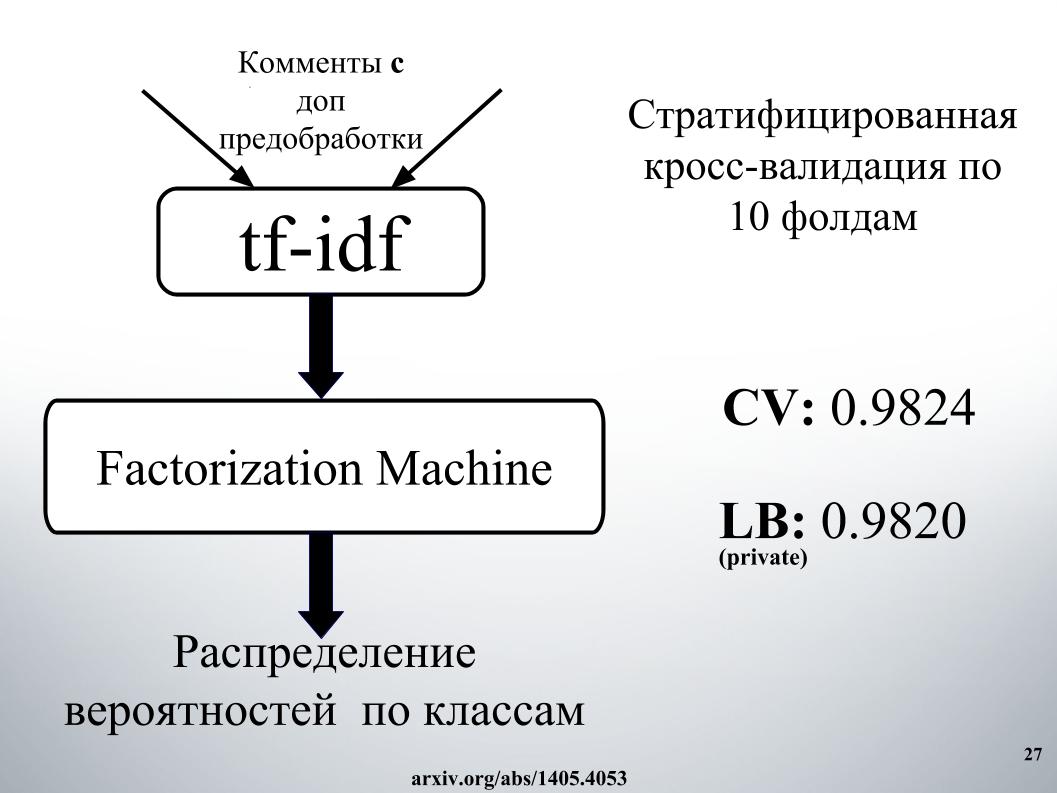
Il a eu l'une des meilleures approches, avec laquelle nous sommes restés longtemps dans le top 15, jusqu'à ce qu'Alexey et Atanas nous rejoignent, il a combiné le mélange et l'empilement de tout cela. Et aussi un moment très cool, dont, si je comprends bien, aucune des équipes n'a utilisé, nous avons également créé des fonctionnalités à partir des résultats de l'API des organisateurs. À ce sujet, dites-le à Alex.
Alexey Noskov:
- salut. Je vais vous parler de l'approche que j'ai utilisée et de la façon dont nous l'avons mise en œuvre.

Tout était assez simple pour moi: 10 plis de validation croisée, des modèles pré-entraînés sur différents vecteurs avec différents prétraitements, pour qu'ils aient plus de diversité dans l'ensemble, une petite augmentation et deux cycles de développement. Le premier, qui fonctionnait essentiellement au début, a formé un certain nombre de modèles, examiné les erreurs de validation croisée, sur les exemples où il fait des erreurs évidentes et corrigé le prétraitement en fonction de cela, car il est plus clair comment les corriger.
Et la deuxième approche, qui a été plus utilisée à la fin, a enseigné un certain nombre de modèles, examiné les corrélations, trouvé des blocs de modèles faiblement corrélés les uns aux autres, renforcé la partie qui les constituait. Il s'agit de la matrice de corrélation de validation croisée entre mes modèles.
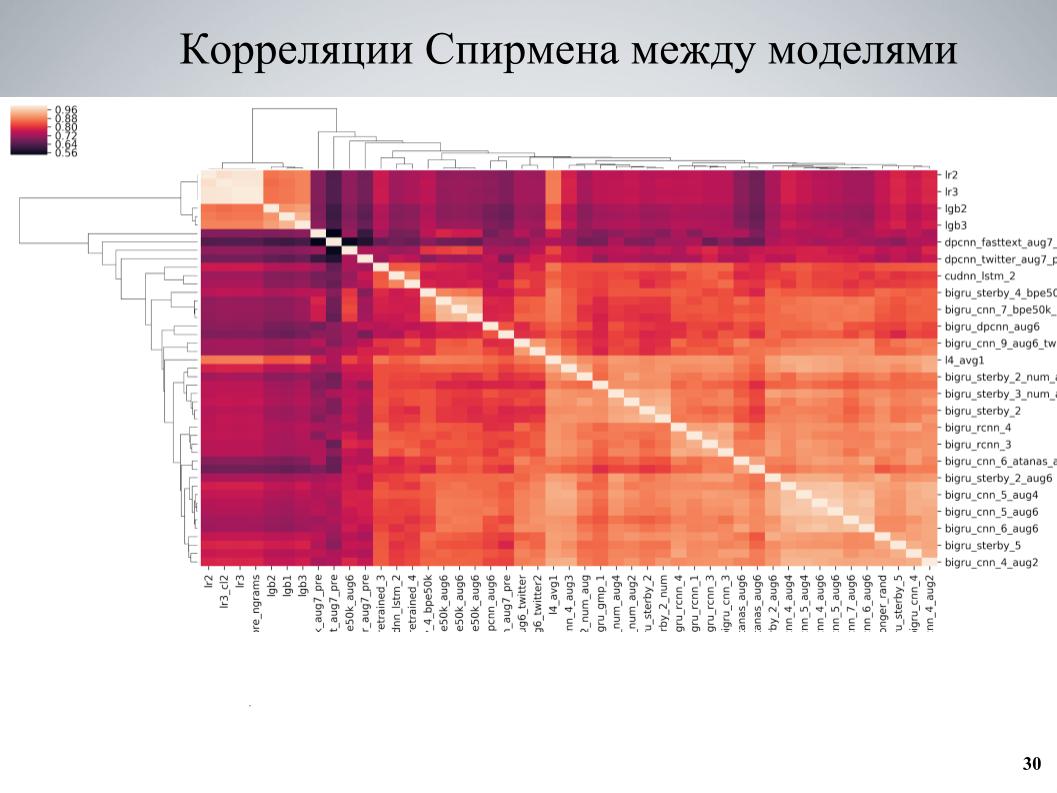
On peut voir qu'il a une structure en blocs à certains endroits, alors que certains modèles étaient de bonne qualité, ils étaient faiblement corrélés avec les autres, et de très bons résultats ont été obtenus lorsque j'ai pris ces modèles comme base, leur ai enseigné plusieurs variations différentes qui diffèrent dans différents hyperparamètres ou prétraitement, puis ajoutés à l'ensemble.

Pour l'augmentation, l'idée qui a été publiée sur le forum par Pavel Ostyakov a le plus suscité. Cela consistait dans le fait que nous pouvons prendre un commentaire, le traduire dans une autre langue, puis revenir. En raison de la double traduction, une reformulation est obtenue, quelque chose est un peu perdu, mais dans l'ensemble un texte similaire légèrement différent est obtenu, qui peut également être classé et ainsi élargir l'ensemble de données.
Et la deuxième approche, qui n'a pas beaucoup aidé, mais aussi aidé, est que vous pouvez essayer de prendre deux commentaires arbitraires, généralement pas très longs, les coller et prendre comme étiquette sur la cible une combinaison d'étiquettes ou un peu de zeste où il n'y a qu'une seule des ils contenaient une étiquette.
Ces deux approches ont bien fonctionné si elles n'étaient pas appliquées à l'avance à l'ensemble d'ensemble complet, mais pour changer l'ensemble d'exemples auxquels l'augmentation devrait être appliquée à chaque époque. A chaque époque du processus de constitution d'un lot, on choisit, disons, 30% des exemples qu'il passe par des traductions. Au contraire, à l'avance, quelque part en parallèle se trouve déjà en mémoire, nous sélectionnons simplement la version à traduire en fonction de celle-ci et l'ajoutons au lot pendant sa formation.

Une différence intéressante réside dans les modèles formés au BPE. Il y a un SentencePiece - un tokenizer Google qui vous permet de vous diviser en tokens dans lesquels il n'y aura aucun UNK. Un dictionnaire limité dans lequel toute chaîne est divisée en quelques jetons. Si le nombre de mots dans le texte réel est supérieur à la taille cible du dictionnaire, ils commencent à se diviser en morceaux plus petits, et une approche intermédiaire est obtenue entre les modèles de niveau caractère et de niveau mot.
Deux algorithmes de construction principaux y sont utilisés: BPE et Unigram. Pour l'algorithme BPE, il était assez facile de trouver des intégrations pré-déposées sur le réseau, et avec un vocabulaire fixe - j'avais juste un bon vocabulaire de 50k - je pouvais aussi former des modèles qui étaient bons (inaudible - environ Ed.), Un peu pire que d'habitude sur fastText, mais ils étaient très faiblement corrélés avec tous les autres et ont donné un bon coup de pouce.
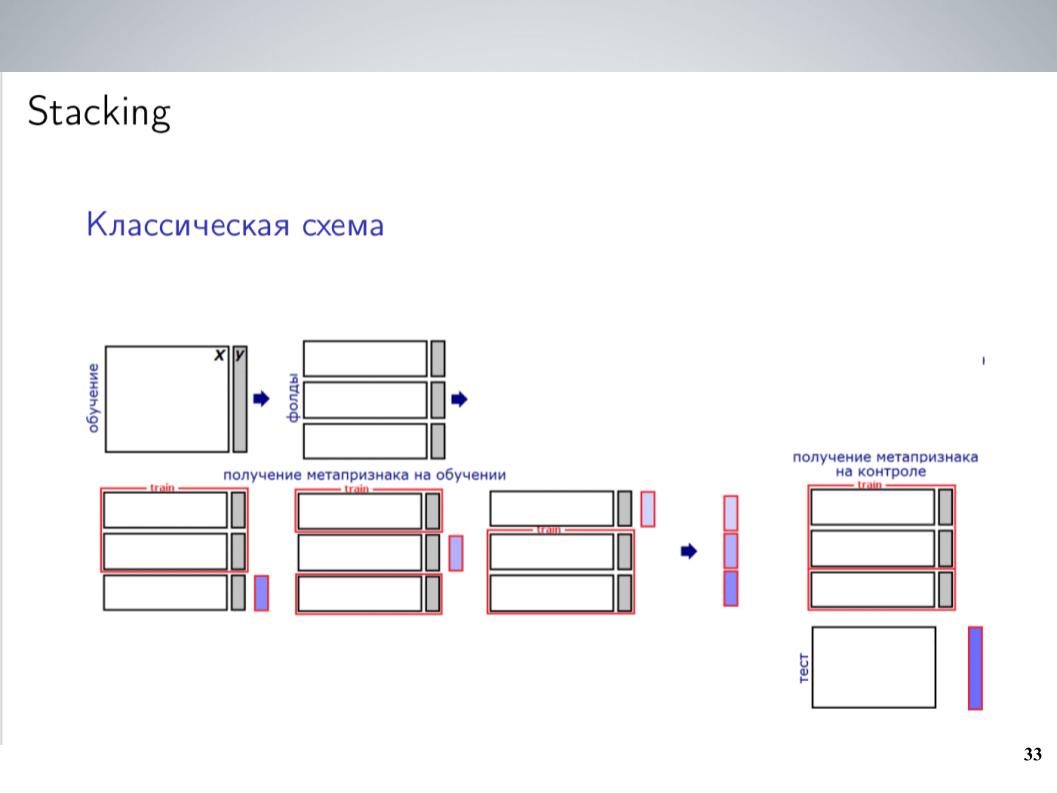
Il s'agit d'un schéma d'empilement classique. En règle générale, pour la plupart de la compétition, avant de combiner, je mélangeais simplement tous mes modèles sans poids. Cela a donné les meilleurs résultats. Mais après la fusion, j'ai pu obtenir un schéma un peu plus complexe, ce qui a finalement donné un bon coup de pouce.

J'avais un grand nombre de modèles. Jetez-les tous dans une sorte d'empileur? Cela n'a pas très bien fonctionné, a-t-il recyclé, mais comme les modèles étaient des groupes qui étaient assez fortement corrélés, je les ai simplement unis dans ces groupes, au sein de chaque groupe, j'ai fait la moyenne et j'ai reçu 5-7 groupes de modèles très similaires, dont Le niveau suivant utilisait des valeurs moyennes. J'ai formé LightGBM à ce sujet, buggé 20 lancements avec divers échantillons, téléchargé un peu de méta-fonctionnalité similaire à ce qu'Atanas a fait, et finalement, il a finalement commencé à fonctionner, donnant un coup de pouce à la moyenne simple.

Surtout, j'ai ajouté l'API que Andrei a trouvée et qui contient un ensemble d'étiquettes similaire. Les organisateurs ont construit des modèles pour eux au départ. Comme il était à l'origine différent, les participants ne l'ont pas utilisé, il était impossible de le comparer simplement avec ceux que nous devions prévoir. Mais s'il se jetait dans un empilement qui fonctionnait bien en tant que méta-fonctionnalité, il donnerait un formidable coup de pouce, en particulier dans la classe TOXIC, qui, apparemment, était la plus difficile du classement et nous permettait de sauter à plusieurs endroits à la fin, littéralement le dernier jour. .

Depuis que nous avons trouvé que l'empilement et l'API fonctionnaient si bien pour nous, avant les soumissions finales, nous avions peu de doute sur la façon dont cela serait porté à des fins privées. Cela a très bien fonctionné de manière très suspecte, nous avons donc choisi deux soumissions selon le principe suivant: l'une - un mélange de modèles sans API reçu avant cela, plus un empilement avec la métaphysique de l'API. Ici, il s'est avéré 0,9880 en public et 0,9874 en privé. Ici, mes marques sont confuses.

Et le second est un mélange de modèles sans API, sans utiliser d'empilement et sans utiliser LightGBM, car il y avait des craintes que ce soit une sorte de reconversion mineure pour le public, et nous pourrions voler avec cela. C'est arrivé, ils n'ont pas décollé, et en conséquence, avec le résultat de 0,9876 en privé, nous avons obtenu la dixième position. C’est tout.