Les grandes entreprises et les entreprises sanglantes ont longtemps trouvé un remplacement pour les rdbds adultes pour DWH et analytique. DWH se dirige massivement vers DataLake et Hadoop. Il semble que les petites entreprises n'ont plus beaucoup de sens pour lancer l'analyse sur un rsbd sérieux. Avec le nombre croissant de cœurs disponibles même pour les petites entreprises, essayer de faire sous licence une version à part entière d'un sous-type adulte comme Oracle n'a pas de sens. Édition standard Oracle, bien que sous licence pour les sockets, mais en même temps couper les fonctionnalités les plus importantes. Tout d'abord, dans l'édition standard, il n'y a pas de partitionnement
, il n'y a qu'une vue de partitionnement - partage de table à la manière de Postgres, qui ne peut aider que dans certaines situations. Deuxièmement, il n'y a pas de veille à part entière, les opérations parallèles sont supprimées. Le cluster RAC est limité à quatre sockets. Par conséquent, avec la croissance moderne des données, vous commencez rapidement à rencontrer les limites de l'édition Standard, et le prix des licences de l'édition Entreprise rend cette tâche inutile. Dans Oracle, il est nécessaire de concéder une licence non seulement au serveur de combat, mais également au serveur de secours, tandis que l'édition Enterprise est concédée sous licence par core. Les options de cluster, de partitionnement et DataGuard / Standby nécessitent une licence distincte et également un noyau. En conséquence, même un serveur d'entrée de gamme avec 16 cœurs et son stanby déjà pour les licences EE tirent des centaines de milliers de dollars, et même la gestion sanglante de l'entreprise s'évanouit.
Nous devons chercher une alternative à Khadupov. J'ai essayé de comparer certaines demandes pour une vitrine de données construite sur des fichiers parquet dans une sauvegarde, contre Oracle Standard sur 8 cœurs xeon, des trames de 196 Go, un certain magasin d'entreprise avec cache HDD et SSD, qui peut être fouillé avec plusieurs autres systèmes. La première requête affecte 4 tables, dans Oracle, elles occupaient 62, 12, 6,5 et 3,5 Go. Dans une assiette de plus de 880 millions de lignes. Dans un plan de demande était tel:
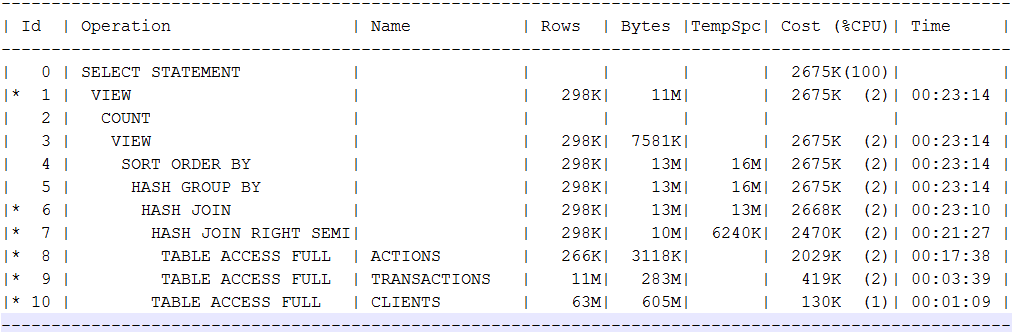
Dans le plan, je voulais spécifiquement voir les analyses complètes et les jointures de hachage qui sont typiques dans mes requêtes analytiques. En réalité, une demande pour une édition standard d'Oracle prend environ 7 minutes. Spark 2.3 lancé via spark2-submit à 14 exécuteurs avec 4 cœurs / trames de 16 Go répond à presque la même demande des disques durs 10k en une minute. Cloudera Impala poussant avec du fil et de l'étincelle sur le même cluster (impalade sur 8 nœuds, ressources comparables à 14 exécuteurs à 4 cœurs) donne une réponse stable en 11-12 secondes. Dans le même temps, Impala fonctionne constamment en parallèle avec la charge, qui doit laver les données mises en cache.
Les jeux avec une taille de bloc, passer à l'édition Oracle EE avec son parallélisme et le partitionnement adulte auraient probablement réduit le temps d'exécution de plusieurs fois, mais je doute légèrement que le temps soit comparable même à ce que j'ai obtenu dans Spark. D'un autre côté, seuls 3-4 nœuds du Cloudera Hadoop pratiquement gratuit vous permettent essentiellement d'obtenir le SQL habituel, la vitesse pour laquelle Oracle aurait incomparablement beaucoup d'argent.
Oracle devrait sérieusement réfléchir à la politique de licence, si les grands fans, comme moi, ne trouvent aucune raison de payer pour l'édition Enterprise.