On m'a informé que sur les nouveaux ordinateurs, certains tests de régression devenaient plus lents. Une chose courante, ça arrive. Configuration incorrecte quelque part dans Windows ou pas les valeurs les plus optimales dans le BIOS. Mais cette fois, nous n'avons pas réussi à trouver le même paramètre «renversé». Étant donné que le changement est important: 9 contre 19 secondes (sur le graphique, le bleu est l'ancien fer et l'orange est le nouveau), j'ai dû creuser plus profondément.
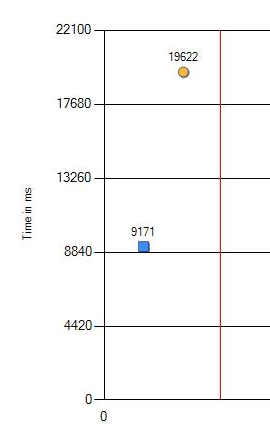
Même système d'exploitation, même matériel, processeur différent: 2 fois plus lent
La baisse des performances de 9,1 à 19,6 secondes peut certainement être qualifiée de significative. Nous avons effectué des vérifications supplémentaires avec un changement dans les versions des programmes testés, des paramètres Windows et BIOS. Mais non, le résultat n'a pas changé. La seule différence n'apparaissait que sur différents processeurs. Voici le résultat sur le dernier CPU.
Et voici celui qui est utilisé pour la comparaison.

Xeon Gold fonctionne sur une architecture différente appelée Skylake, commune aux nouveaux processeurs Intel depuis la mi-2017. Si vous achetez le dernier matériel, vous obtiendrez un processeur avec l'architecture Skylake. Ce sont de bonnes voitures, mais, comme les tests l'ont montré, la nouveauté et la vitesse ne sont pas la même chose.
Si rien d'autre ne vous aide, vous devez utiliser le profileur pour des recherches approfondies. Essayons sur des équipements anciens et nouveaux et obtenons quelque chose comme ceci:
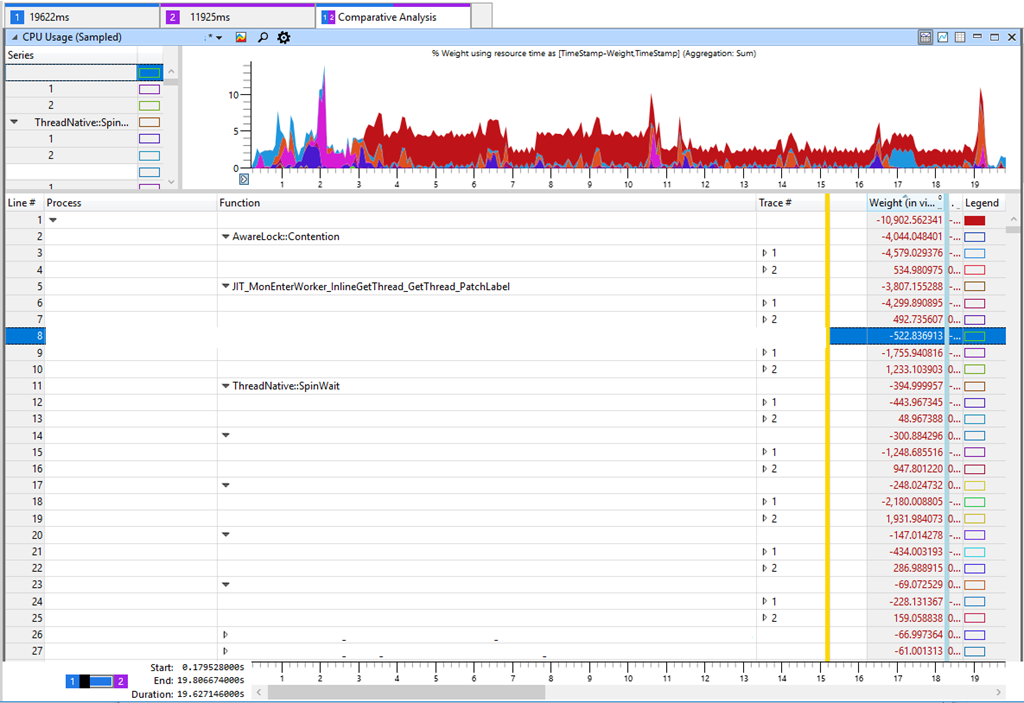
L'onglet dans Windows Performance Analyzer (WPA) indique dans le tableau la différence entre la trace 2 (11 s) et la trace 1 (19 s). Une différence négative dans le tableau correspond à une augmentation de la consommation de CPU dans un test plus lent. Si vous regardez les différences les plus importantes dans la consommation de CPU, nous verrons
AwareLock :: Contention ,
JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel et
ThreadNative.SpinWait . Tout indique une «rotation» dans le CPU [rotation - une tentative cyclique pour obtenir un verrou, env. par.], lorsque les threads se battent pour le blocage. Mais c'est une fausse marque, car la filature n'est pas la principale raison de la baisse de productivité. La concurrence accrue pour les verrous signifie que quelque chose dans notre logiciel a ralenti et conservé le verrou, ce qui a entraîné une augmentation de la rotation du processeur. J'ai vérifié le temps de verrouillage et d'autres indicateurs clés, tels que les performances du disque, mais je n'ai rien trouvé de significatif qui pourrait expliquer la dégradation des performances. Bien que ce ne soit pas logique, mais je suis revenu à augmenter la charge sur le processeur de différentes manières.
Il serait intéressant de trouver exactement où le processeur est bloqué. WPA a des colonnes de fichier # et de ligne #, mais elles ne fonctionnent qu'avec des caractères privés, ce que nous n'avons pas, car il s'agit du code .NET Framework. La prochaine meilleure chose que nous pouvons faire est d'obtenir l'adresse dll où se trouve l'instruction appelée Image RVA. Si vous chargez cette dll dans le débogueur et faites
u xxx.dll+ImageRVAalors nous devrions voir l'instruction qui brûle la plupart des cycles de CPU, car ce sera la seule adresse "chaude".
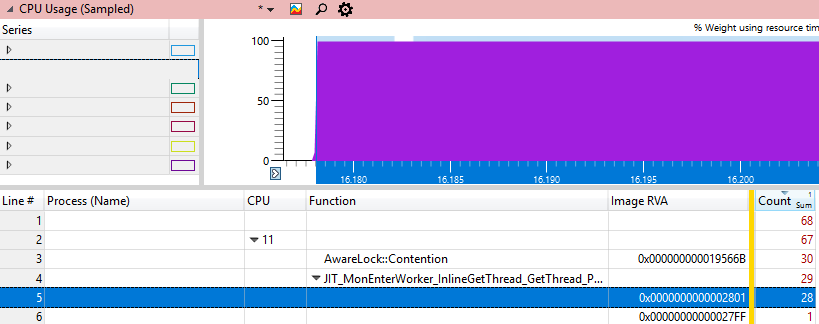
Nous examinerons cette adresse en utilisant différentes méthodes Windbg:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)Et avec différentes méthodes JIT:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)Nous avons maintenant un modèle. Dans un cas, l'adresse chaude est une instruction de saut, et dans l'autre cas, c'est une soustraction. Mais les deux instructions chaudes sont précédées de la même instruction de pause générale. Différentes méthodes exécutent la même instruction de processeur, ce qui, pour une raison quelconque, prend beaucoup de temps. Mesurons la vitesse d'exécution de l'instruction pause et voyons si nous raisonnons correctement.
Si le problème est documenté, il devient alors une fonctionnalité.
| CPU | pause en nanosecondes |
| Xeon E5 1620v3 3,5 GHz | 4 |
| Xeon® Gold 6126 à 2,60 GHz | 43 |
La pause dans les nouveaux processeurs Skylake prend un ordre de grandeur plus long. Bien sûr, tout peut devenir plus rapide et parfois un peu plus lent. Mais
dix fois plus lentement? Cela ressemble plus à un bug. Une petite recherche sur Internet sur les instructions de pause mène au
manuel d'
Intel , qui mentionne explicitement la microarchitecture Skylake et les instructions de pause:

Non, ce n'est pas une erreur, c'est une fonction documentée. Il y a même une
page indiquant le temps d'exécution de presque toutes les instructions du processeur.
- Pont de sable 11
- Ivy Bridege 10
- Haswell 9
- Broadwell 9
- SkylakeX 141
Le nombre de cycles du processeur est indiqué ici. Pour calculer l'heure réelle, vous devez diviser le nombre de cycles par la fréquence du processeur (généralement en GHz) et obtenir l'heure en nanosecondes.
Cela signifie que si vous exécutez des applications hautement multithread sur .NET sur le dernier matériel, elles peuvent fonctionner beaucoup plus lentement. Quelqu'un l'a déjà remarqué et a
enregistré un bug en août 2017. Le problème a été
résolu dans .NET Core 2.1 et .NET Framework 4.8 Preview.
Amélioration du spin-wait dans plusieurs primitives de synchronisation pour de meilleures performances sur Intel Skylake et les microarchitectures ultérieures. [495945, mscorlib.dll, bogue]
Mais comme il reste encore un an avant la sortie de .NET 4.8, j'ai demandé de rétroporter les correctifs pour que .NET 4.7.2 revienne à la vitesse normale sur les nouveaux processeurs. Étant donné qu'il existe des verrous mutuellement exclusifs (verrous tournants) dans de nombreuses parties de .NET, vous devez suivre l'augmentation de la charge du processeur lorsque Thread.SpinWait et d'autres méthodes de rotation fonctionnent.

Par exemple, Task.Result utilise en interne la rotation, donc je prévois une augmentation significative de la charge CPU et une baisse des performances dans d'autres tests.
À quel point est-ce mauvais?
J'ai regardé le code .NET Core pendant combien de temps le processeur continuera de tourner si le verrou n'est pas libéré avant d'appeler WaitForSingleObject pour payer le changement de contexte «cher». Un changement de contexte prend quelque part une microseconde ou bien plus si de nombreux threads attendent le même objet noyau.
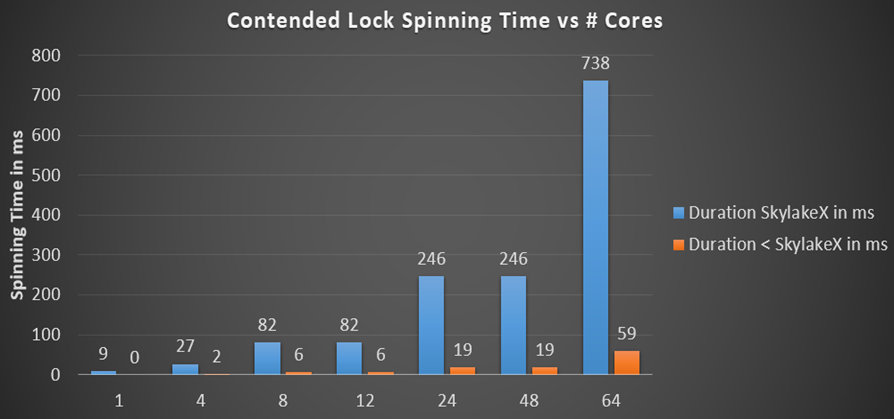
Les verrous .NET multiplient la durée maximale de rotation par le nombre de cœurs, si nous prenons le cas absolu où le thread sur chaque cœur attend le même verrou et la rotation continue suffisamment longtemps pour que tout le monde travaille un peu avant de payer l'appel du noyau. La rotation dans .NET utilise un algorithme de vieillissement exponentiel lorsqu'elle démarre avec un cycle de 50 appels de pause, où pour chaque itération le nombre de rotations triple jusqu'à ce que le compteur de rotation suivant dépasse leur durée maximale. J'ai calculé la durée totale de rotation par processeur pour différents processeurs et un nombre différent de cœurs:
Voici le code de rotation simplifié dans les verrous .NET:
/// <summary> /// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls /// </summary> /// <param name="nCores"></param> void Spin(int nCores) { const int dwRepetitions = 10; const int dwInitialDuration = 0x32; const int dwBackOffFactor = 3; int dwMaximumDuration = 20 * 1000 * nCores; for (int i = 0; i < dwRepetitions; i++) { int duration = dwInitialDuration; do { for (int k = 0; k < duration; k++) { Call_PAUSE(); } duration *= dwBackOffFactor; } while (duration < dwMaximumDuration); } }
Auparavant, le temps de rotation était dans l'intervalle de millisecondes (19 ms pour 24 cœurs), ce qui est déjà beaucoup par rapport au temps de commutation de contexte susmentionné, qui est un ordre de grandeur plus rapide. Mais dans les processeurs Skylake, le temps de rotation total pour le processeur explose simplement jusqu'à 246 ms sur une machine 24 bits ou 48 cœurs, simplement parce que l'instruction de pause a ralenti de 14 fois. En est-il vraiment ainsi? J'ai écrit un petit testeur pour vérifier la rotation globale du processeur - et les chiffres calculés sont bien conformes aux attentes. Voici 48 threads sur un processeur 24 cœurs en attente d'un verrou, que j'ai appelé Monitor.PulseAll:
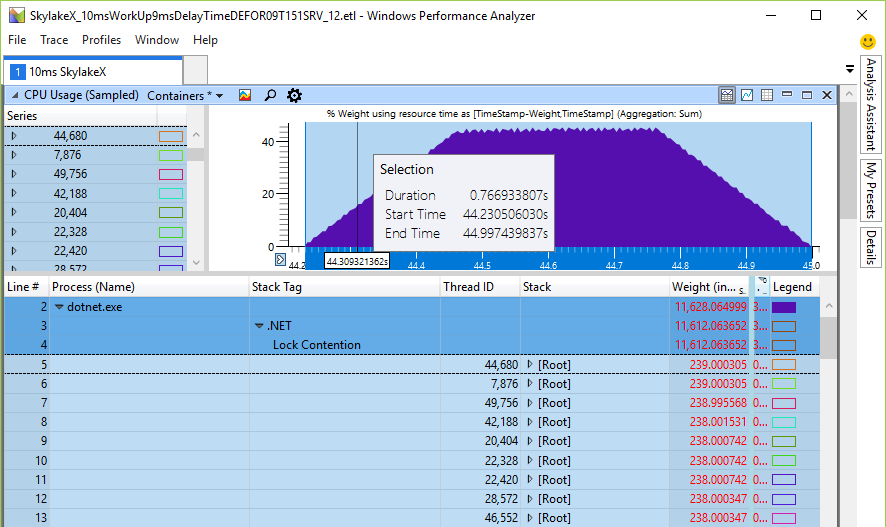
Un seul fil gagnera la course, mais 47 continueront de tourner jusqu'à ce qu'ils perdent leur fréquence cardiaque. Ceci est une preuve expérimentale que nous avons vraiment un problème de charge CPU et que la rotation très longue est réelle. Cela mine l'évolutivité, car ces cycles vont à la place du travail utile d'autres threads, bien que l'instruction de pause libère certaines des ressources partagées du CPU, offrant un sommeil plus long. La raison de la rotation est une tentative d'obtenir un verrou plus rapidement sans accéder au noyau. Si c'est le cas, l'augmentation de la charge sur le processeur ne serait que nominale, mais n'affecterait pas du tout les performances, car les noyaux sont engagés dans d'autres tâches. Mais les tests ont montré une diminution des performances dans des opérations presque à un seul thread, où un thread ajoute quelque chose à la file d'attente de travail, tandis que le thread de travail attend un résultat, puis effectue une certaine tâche avec l'élément de travail.
La raison est plus facile à montrer dans le diagramme. La rotation adversaire se produit avec un triplement de rotation à chaque étape. Après chaque tour, le verrou est à nouveau vérifié pour voir si le thread actuel peut le recevoir. Bien que la rotation essaie d'être honnête et passe de temps en temps à d'autres threads pour les aider à terminer leur travail. Cela augmente les chances de libérer le verrou lors du prochain contrôle. Le problème est qu'une vérification de prise n'est possible qu'à la fin d'un tour complet:

Par exemple, si au début du cinquième tour de rotation un verrou signale la disponibilité, vous ne pouvez le prendre qu'à la fin du tour. Après avoir calculé la durée de rotation du dernier tour, nous pouvons estimer le pire cas de retard pour notre flux:

Plusieurs millisecondes d'attente jusqu'à la fin de la rotation. Est-ce un vrai problème?
J'ai créé une application de test simple qui implémente une file d'attente de fabricants de consommateurs, où le flux de travail effectue chaque élément de travail pendant 10 ms, et le consommateur a un délai de 1 à 9 ms avant l'élément de travail suivant. Cela suffit pour voir l'effet:
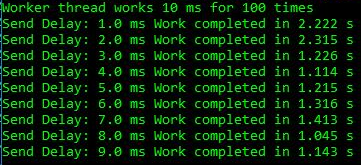
Nous constatons que pour des retards de 1 à 2 ms, la durée totale est de 2,2 à 2,3 s, tandis que dans d'autres cas, le travail est plus rapide jusqu'à 1,2 s. Cela montre que la rotation excessive du processeur n'est pas seulement un problème esthétique dans les applications sur-threadées. Cela nuit vraiment au filetage simple du producteur-consommateur, qui ne comprend que deux fils. Pour le run ci-dessus, les données ETW parlent d'elles-mêmes: c'est l'augmentation du spin qui provoque le retard observé:
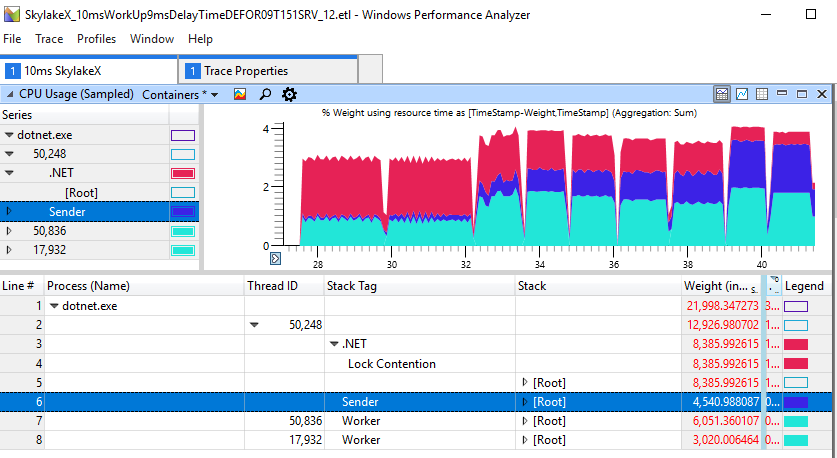
Si vous regardez attentivement la section avec «freins», nous verrons 11 ms de rotation dans la zone rouge, bien que le travailleur (bleu clair) ait terminé son travail et ait donné le verrou il y a longtemps.
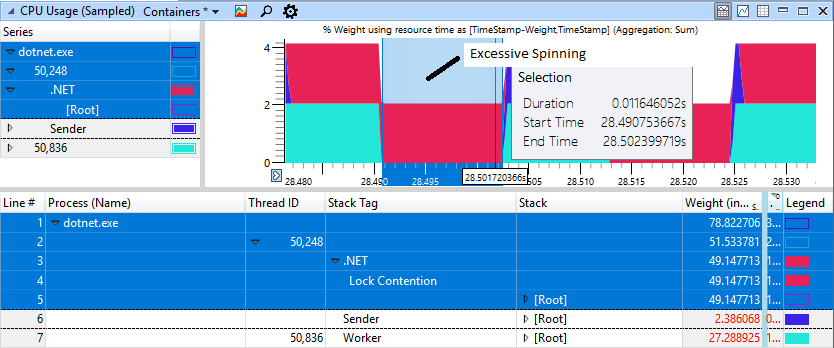
Un cas non dégénératif rapide semble beaucoup mieux, ici seulement 1 ms est dépensé pour tourner pour bloquer.
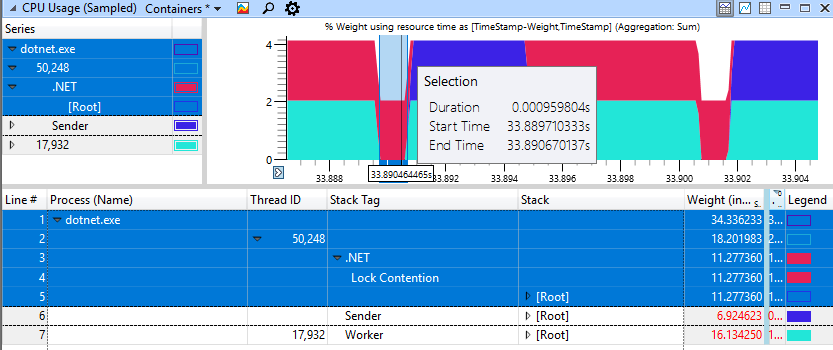
J'ai utilisé l'application de test
SkylakeXPause . L'
archive zip contient du code source et des fichiers binaires pour .NET Core et .NET 4.5. À titre de comparaison, j'ai installé .NET 4.8 Preview avec des correctifs et .NET Core 2.0, qui implémente toujours l'ancien comportement. L'application est conçue pour .NET Standard 2.0 et .NET 4.5, produisant à la fois exe et dll. Vous pouvez maintenant vérifier côte à côte l'ancien et le nouveau comportement de rotation sans avoir à réparer quoi que ce soit, c'est très pratique.
readonly object _LockObject = new object(); int WorkItems; int CompletedWorkItems; Barrier SyncPoint; void RunSlowTest() { const int processingTimeinMs = 10; const int WorkItemsToSend = 100; Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times"); // Test one sender one receiver thread with different timings when the sender wakes up again // to send the next work item // synchronize worker and sender. Ensure that worker starts first double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; foreach (var sendDelay in sendDelayTimes) { SyncPoint = new Barrier(2); // one sender one receiver var sw = Stopwatch.StartNew(); Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay), () => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs)); sw.Stop(); Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s"); Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs } } /// <summary> /// Simulate a worker thread which consumes CPU which is triggered by the Sender thread /// </summary> void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs) { SyncPoint.SignalAndWait(); while (CompletedWorkItems != maxWorkItemsToWork) { lock (_LockObject) { if (WorkItems == 0) { Monitor.Wait(_LockObject); // wait for work } for (int i = 0; i < WorkItems; i++) { CompletedWorkItems++; SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock } WorkItems = 0; } } } /// <summary> /// Insert work for the Worker thread under a lock and wake up the worker thread n times /// </summary> void Sender(int workItems, double delayInMs) { CompletedWorkItems = 0; // delete previous work SyncPoint.SignalAndWait(); for (int i = 0; i < workItems; i++) { lock (_LockObject) { WorkItems++; Monitor.PulseAll(_LockObject); } SimulateWork(delayInMs); } }
Conclusions
Ce n'est pas un problème .NET. Toutes les implémentations spinlock utilisant l'instruction pause sont affectées. J'ai rapidement vérifié le cœur de Windows Server 2016, mais il n'y a pas un tel problème en surface. Il semble qu'Intel a été assez gentil - et a laissé entendre que certains changements dans l'approche de la rotation sont nécessaires.
Un bogue pour .NET Core a été signalé en août 2017, et en septembre 2017,
un correctif et une version de .NET Core 2.0.3 ont été publiés. Le lien montre non seulement l'excellente réaction du groupe .NET Core, mais aussi le fait qu'il y a quelques jours, le problème a été résolu dans la branche principale, ainsi qu'une discussion sur des optimisations de rotation supplémentaires. Malheureusement, Desktop .NET Framework ne se déplace pas si vite, mais face à l'aperçu de .NET Framework 4.8, nous avons au moins la preuve conceptuelle que les correctifs sont également implémentables. J'attends maintenant le backport pour .NET 4.7.2 pour utiliser .NET à pleine vitesse et sur le dernier matériel. C'est le premier bogue que j'ai trouvé qui est directement lié aux changements de performances dus à une instruction CPU. ETW reste le principal profileur sous Windows. Si je le pouvais, je demanderais à Microsoft de porter l'infrastructure ETW sur Linux, car les profileurs Linux actuels sont toujours de la merde. Ils ont récemment ajouté des fonctionnalités de noyau intéressantes, mais il n'y a toujours pas d'outils d'analyse comme WPA.
Si vous travaillez avec .NET Core 2.0 ou le bureau .NET Framework sur les derniers processeurs sortis depuis la mi-2017, en cas de problèmes de dégradation des performances, vous devez absolument vérifier vos applications avec un profileur - et mettre à niveau vers .NET Core et, espérons-le, bientôt Bureau .NET Mon application de test vous informera de la présence ou de l'absence d'un problème.
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detectedou
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detectedL'outil signalera un problème si vous travaillez sur le .NET Framework sans la mise à jour appropriée et sur le processeur Skylake.
J'espère que vous avez trouvé l'enquête sur ce problème aussi excitante que moi. Pour vraiment comprendre le problème, vous devez créer un moyen de le reproduire, vous permettant d'expérimenter et de rechercher des facteurs d'influence. Le reste n'est qu'un travail ennuyeux, mais maintenant je suis beaucoup mieux à même de comprendre les causes et les conséquences d'une tentative cyclique de verrouiller le processeur.