
En mars, notre équipe de développement sous le nom de fierté «Hands-Auki» a vigoureusement combattu pendant deux jours sur les terrains numériques du hackathon AI.HACK. Au total, cinq tâches de différentes entreprises ont été proposées. Nous nous sommes concentrés sur la tâche de Gazpromneft: prévoir la demande de carburant des clients B2B. Selon des données anonymisées, il était nécessaire d'apprendre à prédire combien un client particulier achètera à l'avenir, en fonction de la région d'achat de carburant, du numéro de carburant, du type de carburant, du prix, de la date et de l'ID client. Pour l'avenir - notre équipe a résolu ce problème avec la plus grande précision. Les clients étaient divisés en trois segments: grand, moyen et petit. Et en plus de la tâche principale, nous avons également construit une prévision de la consommation totale pour chacun des segments.
Le déchargement contenait des données sur les achats des clients pour la période de novembre 2016 au 15 mars 2018 (pour la période du 1er janvier 2018 au 15 mars 2018, les données n'incluaient PAS les volumes).
Exemples de données:
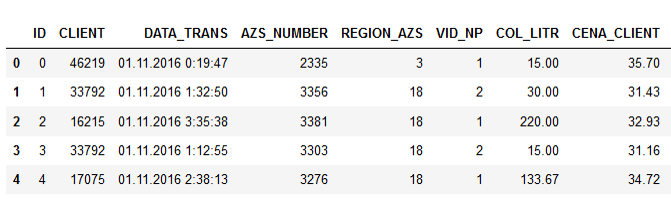
Les noms des colonnes parlent d'eux-mêmes, je pense que cela n'a aucun sens à expliquer.
En plus de l'échantillon de formation, les organisateurs ont fourni un échantillon d'essai pour trois mois de cette année. Les prix sont pour les clients d'entreprise, en tenant compte de remises spécifiques, qui dépendent de la consommation d'un client particulier, d'offres spéciales et d'autres points.
Après avoir reçu les données initiales, nous avons, comme tout le monde, commencé à essayer les méthodes classiques d'apprentissage automatique, en essayant de construire un modèle approprié, pour ressentir la corrélation de certains signes. Nous avons essayé d'extraire des fonctionnalités supplémentaires, construit des modèles de régression (XGBoost, CatBoost, etc.).
L'énoncé du problème lui-même impliquait initialement que le prix du carburant influence en quelque sorte la demande, et il est nécessaire de comprendre plus précisément cette dépendance. Mais lorsque nous avons commencé à analyser les données fournies, nous avons vu que la demande n'était pas en corrélation avec le prix.

Corrélation des signes:
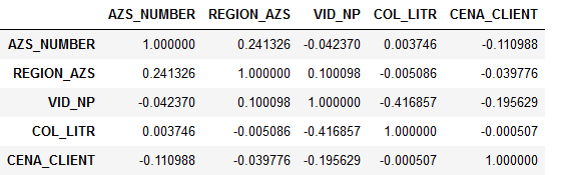
Il s'est avéré que le nombre de litres ne dépend pratiquement pas du prix. Cela a été expliqué de façon assez logique. Le conducteur va sur l'autoroute, il doit faire le plein. Il a le choix: soit il fera le plein dans une station-service avec laquelle l'entreprise coopère, soit dans une autre. Mais le conducteur ne se soucie pas du prix du carburant - l'organisation le paie. Par conséquent, il s'éteint simplement à la station-service la plus proche et remplit le réservoir.
Cependant, malgré tous les efforts et les modèles éprouvés, il n'a pas été possible d'atteindre la précision de prévision minimale acceptable (ligne de base), qui a été calculée à l'aide de cette formule (erreur de pourcentage absolu moyen symétrique):
Nous avons essayé toutes les options, rien n'a fonctionné. Et puis il nous est venu à l'esprit de cracher sur l'apprentissage automatique et de nous tourner vers les bonnes vieilles statistiques: il suffit de prendre la valeur moyenne du type de carburant, de valider et de voir quelle précision vous obtenez.
Nous avons donc d'abord dépassé la valeur seuil.
Nous avons commencé à penser comment améliorer le résultat. Nous avons essayé de prendre des valeurs médianes par groupes de clients, types de carburant, régions et numéros de stations-service. Le problème était que dans les données de test, environ 30% des identifiants des clients qui étaient dans l'échantillon de formation manquaient. Autrement dit, de nouveaux clients sont apparus dans le test. C'était une erreur que les organisateurs n'ont pas vérifiée. Mais nous devions résoudre le problème nous-mêmes. Nous ne connaissions pas la consommation de nouveaux clients et ne pouvions donc pas établir de prévisions pour eux. Et ici, l'apprentissage automatique a aidé.
À la première étape, les données manquantes ont été remplies avec la valeur moyenne ou médiane pour l'ensemble de l'échantillon. Et puis l'idée est venue: pourquoi ne pas créer de nouveaux profils clients à partir des données existantes? Nous avons des réductions par région, combien de clients y achètent du carburant, avec quelle fréquence, quels types. Nous avons regroupé les clients existants, compilé des profils spécifiques pour différentes régions et formé XGBoost sur ceux-ci, qui ont ensuite «complété» les profils de nouveaux clients.
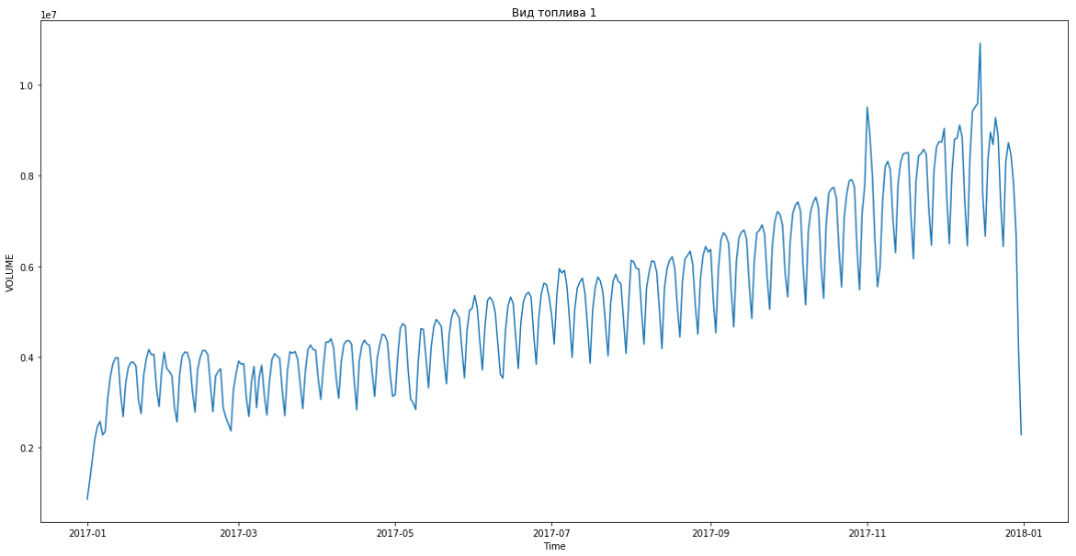
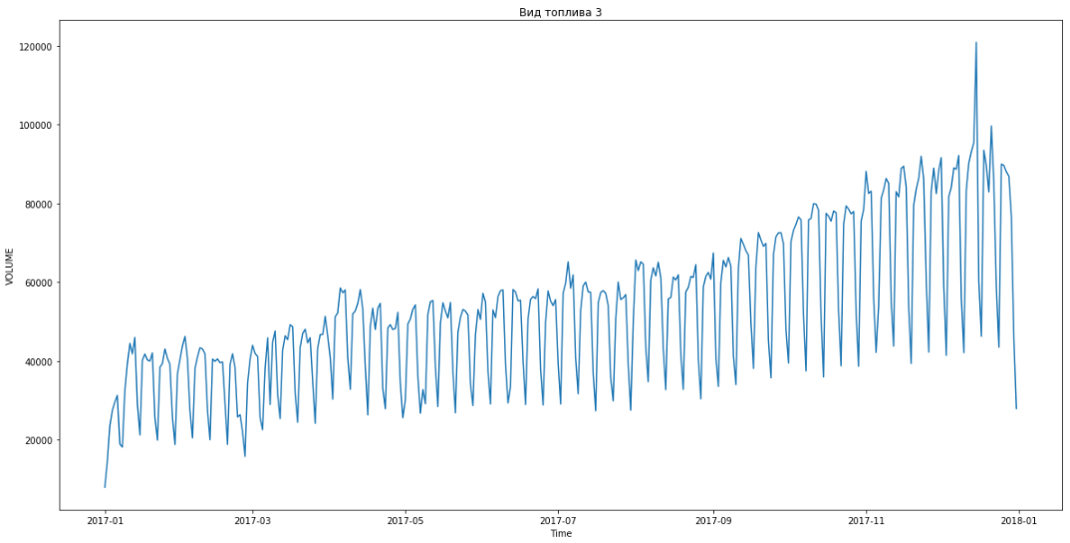
Cela nous a permis de percer en première place. Il restait encore trois heures avant de résumer les résultats. Nous avons été ravis et avons commencé à résoudre le problème des bonus - prévisions par segments pendant trois mois à l'avance.
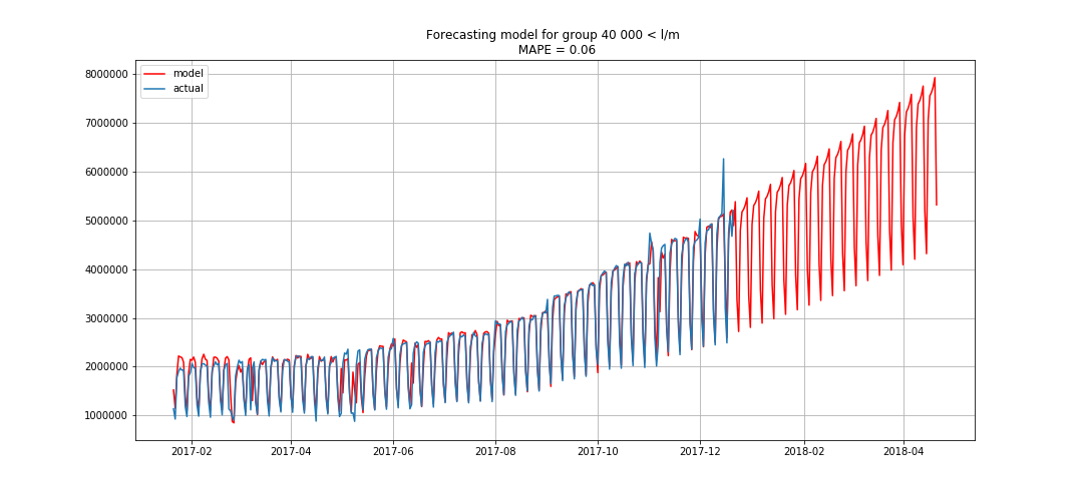
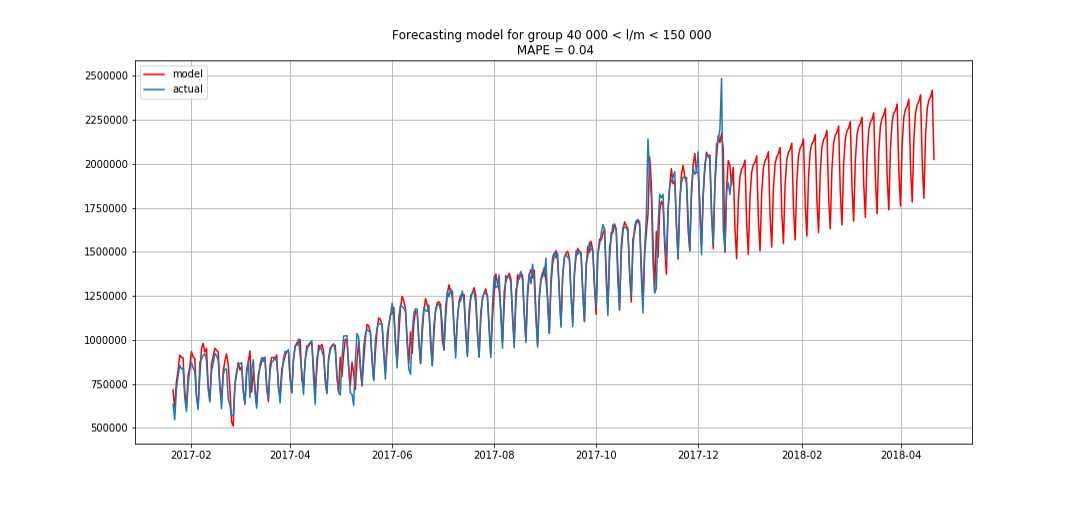
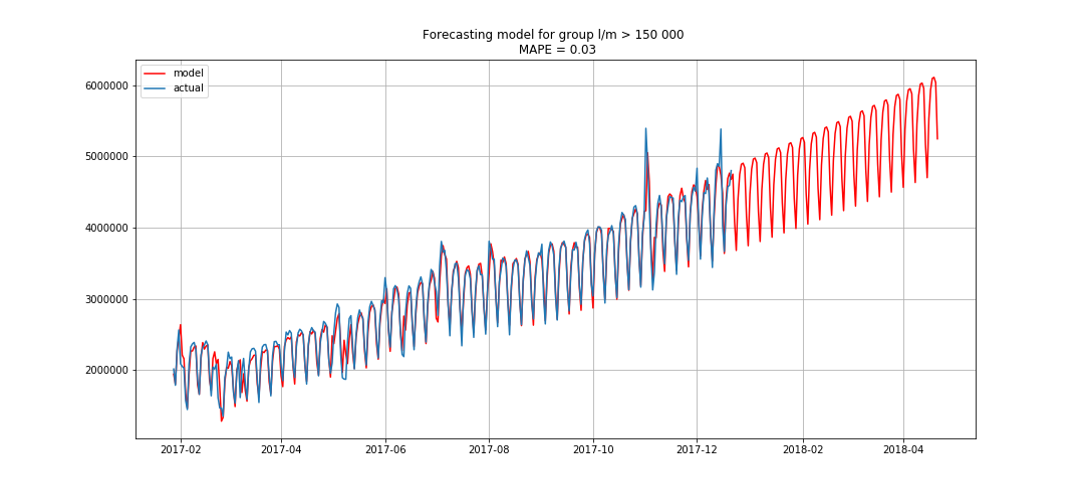
Le bleu montre les données réelles, le rouge - les prévisions. L'erreur variait de 3% à 6%. Pourrait être calculé de façon encore plus précise, par exemple, en tenant compte des pics saisonniers et des vacances.
Pendant que nous faisions cela, une équipe a commencé à nous rattraper, améliorant notre résultat toutes les 15 à 20 minutes. Nous aussi, nous avons commencé à nous agiter et avons décidé de faire quelque chose au cas où ils nous rattraperaient.
Ils ont commencé à faire un autre modèle en parallèle, qui classait les statistiques par degré d'importance, sa précision était légèrement inférieure à celle du premier. Et lorsque les concurrents nous ont battus, nous avons essayé de combiner les deux modèles. Cela nous a donné une légère augmentation de la métrique - jusqu'à 37,24671%, en conséquence, nous avons regagné notre première place et l'avons gardée jusqu'à la fin.
Pour la victoire, notre équipe Ruki-Auki a reçu un certificat pour 100 mille roubles, honneur, respect et ... plein d'estime de soi, je suis allé au spa! ;)
Équipe de développement de Jet Infosystems