Remarque perev. : Ce petit article (mais volumineux!) Écrit par Michael Hausenblas de l'équipe OpenShift de Red Hat nous a tellement plu qu'il a été ajouté à notre base de connaissances internes Kubernetes presque immédiatement après sa découverte. Et puisque les informations qui y sont présentées seront évidemment utiles à l'ensemble de la communauté informatique russophone, nous sommes heureux de publier sa traduction.
Comme vous l'avez peut-être deviné, le titre de cette publication fait référence au dessin animé Pixar de 1998
«La vie d'un insecte» (au box-office russe, il s'appelait «Les aventures de Flick» ou «La vie d'un insecte» - environ trad. ) , Et en effet: entre les anti- Kubernetes a beaucoup en commun avec les travailleurs et les foyers. Nous examinerons attentivement le cycle de vie complet du foyer d'un point de vue pratique - en particulier, les façons dont vous pouvez influencer le comportement au démarrage et à l'arrêt, ainsi que les approches correctes pour vérifier l'état de l'application.
Que vous ayez créé sous vous-même ou, mieux, via un contrôleur comme
Deployment ,
DaemonSet ou
StatefulSet , under peut se trouver dans l'une des phases suivantes:
- En attente : le serveur API a créé une ressource de pod et l'a enregistrée dans etcd, mais elle n'était pas encore planifiée et les images de ses conteneurs n'ont pas été reçues du registre;
- Running (fonctionnement): under a été assigné au nœud et tous les conteneurs ont été créés par kubelet ;
- Réussi (terminé avec succès): l'opération de tous les récipients de foyer a été terminée avec succès et ils ne redémarreront pas;
- Échec : tous les conteneurs dans l'âtre ont cessé de fonctionner et au moins l'un des conteneurs est tombé en panne;
- Inconnu : API Server n'a pas pu interroger l'état du foyer, généralement en raison d'une erreur d'interaction avec kubelet .
Lors de l'exécution de
kubectl get pod , notez que la colonne
STATUS peut afficher d'autres messages (à l'exception de ces cinq) - par exemple,
Init:0/1 ou
CrashLoopBackOff . En effet, la phase n'est qu'une partie de l'état général du foyer. Un bon moyen de savoir ce qui s'est exactement passé est d'exécuter
kubectl describe pod/$PODNAME et de regarder l'entrée
kubectl describe pod/$PODNAME Events: ci
Events: dessous. Elle affiche une liste d'actions pertinentes: que l'image du conteneur a été reçue, c'était prévu, le conteneur est dans un état «
malsain» .
Jetez maintenant un œil à un exemple spécifique du cycle de vie d'un foyer du début à la fin, comme le montre le diagramme suivant:
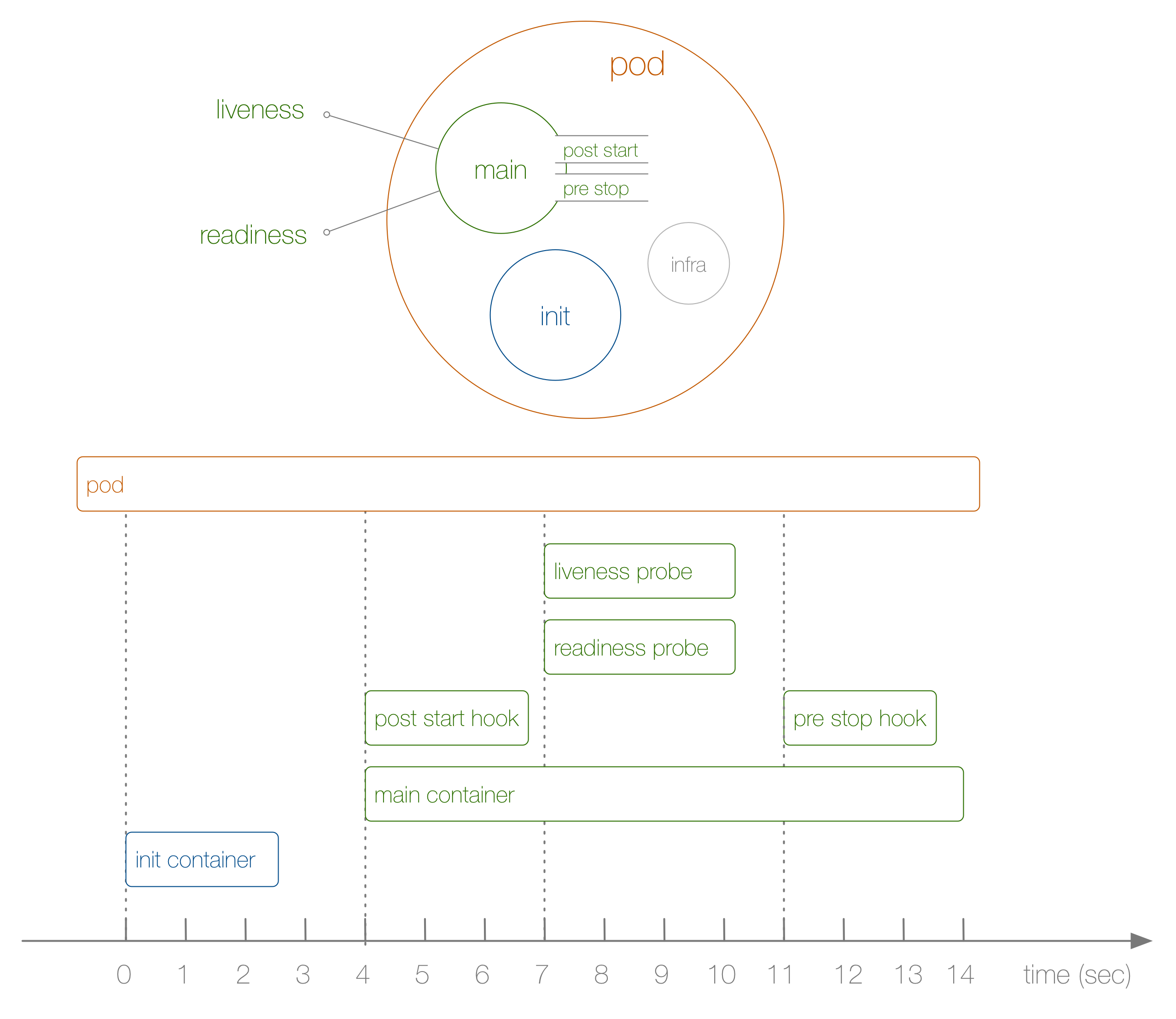
Que s'est-il passé ici? Les étapes sont les suivantes:
- Cela n'est pas illustré dans le diagramme, mais au tout début, un infra-conteneur spécial est lancé et définit les espaces de noms auxquels les conteneurs restants se joignent.
- Le premier conteneur défini par l'utilisateur qui démarre est le conteneur init ; il peut être utilisé pour des tâches d'initialisation.
- Ensuite, le conteneur principal et le crochet post-démarrage sont lancés simultanément; dans notre cas, cela se produit après 4 secondes. Des crochets sont définis pour chaque conteneur.
- Ensuite, à la 7e seconde, des tests de vivacité et de préparation entrent en jeu, à nouveau pour chaque conteneur.
- À la 11e seconde, lorsque le sous est tué, un crochet de pré-arrêt est déclenché et le conteneur principal est tué après une période de grâce . Veuillez noter qu'en réalité, le processus d' achèvement du module est un peu plus compliqué.
Comment en suis-je arrivé à la séquence ci-dessus et à son timing? Pour ce faire, nous avons utilisé le
déploiement suivant, créé spécifiquement pour suivre l'ordre des événements (ce n'est pas très utile en soi):
kind: Deployment apiVersion: apps/v1beta1 metadata: name: loap spec: replicas: 1 template: metadata: labels: app: loap spec: initContainers: - name: init image: busybox command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing'] volumeMounts: - mountPath: /loap name: timing containers: - name: main image: busybox command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing; sleep 10; echo $(date +%s): END >> /loap/timing;'] volumeMounts: - mountPath: /loap name: timing livenessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing'] readinessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing'] lifecycle: postStart: exec: command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing'] preStop: exec: command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing'] volumes: - name: timing hostPath: path: /tmp/loap
Notez que pour arrêter de force le pod lorsque le conteneur principal fonctionnait, j'ai exécuté la commande suivante:
$ kubectl scale deployment loap --replicas=0
Nous avons examiné une séquence spécifique d'événements en action et nous sommes maintenant prêts à passer à des pratiques dans le domaine de la gestion du cycle de vie des foyers. Ils sont les suivants:
- Utilisez des conteneurs d'init pour préparer le foyer pour un fonctionnement normal. Par exemple, pour obtenir des données externes, créer des tables dans la base de données ou attendre la disponibilité du service dont elles dépendent. Si nécessaire, vous pouvez créer de nombreux conteneurs d'initialisation et tous doivent se terminer avec succès avant le lancement de conteneurs réguliers.
- Ajoutez toujours
livenessProbe et readinessProbe . Le premier est utilisé par kubelet 'ohm pour comprendre si et quand redémarrer le conteneur, et déploiement ' ohm pour décider si la mise à jour continue a réussi. Le second est utilisé par le service pour décider de la direction du trafic vers le sous-marin. Si ces échantillons ne sont pas définis, kubelet pour les deux suppose qu'ils ont été complétés avec succès. Cela entraîne deux conséquences: a) la politique de redémarrage ne peut pas être appliquée, b) les conteneurs dans l'âtre reçoivent instantanément du trafic du service auquel ils sont confrontés, et même s'ils sont toujours occupés par le processus de démarrage. - Utilisez des crochets pour initialiser correctement le conteneur et le détruire complètement. Par exemple, cela est utile dans le cas du fonctionnement d'une application dont vous n'avez pas accès au code source ou que vous ne pouvez pas modifier, mais qui nécessite une certaine initialisation ou préparation pour l'achèvement - par exemple, la suppression des connexions à la base de données. Notez que lors de l'utilisation du service , l'arrêt du serveur API, du contrôleur de noeud final et du proxy de cube peut prendre un certain temps (par exemple, supprimer les entrées correspondantes d'iptables). Par conséquent, la fin de votre travail sous peut affecter les demandes de candidature. Souvent, pour résoudre ce problème, un simple crochet avec un appel de sommeil suffit.
- Pour les besoins de débogage et pour comprendre en général pourquoi elle a cessé de fonctionner, l'application peut écrire dans
/dev/termination-log , et vous pouvez afficher les messages à l'aide de kubectl describe pod … Ces paramètres par défaut sont modifiés via terminationMessagePath et / ou en utilisant terminationMessagePolicy dans la sous-spécification - voir la référence API pour plus de détails.
Cette publication ne traite pas des
initialiseurs (certains détails à leur sujet peuvent être trouvés à la fin de ce document - environ la traduction ) . Il s'agit d'un tout nouveau concept introduit dans Kubernetes 1.7. Les initialiseurs fonctionnent à l'intérieur du plan de contrôle (serveur API) au lieu d'être dans le contexte du
kubelet , et peuvent être utilisés pour enrichir les foyers, par exemple, avec des conteneurs side-car ou appliquer des politiques de sécurité. De plus, les
PodPresets n'ont pas été pris en compte, ce qui à l'avenir peut être remplacé par un concept plus flexible d'initialiseurs.
PS du traducteur
Lisez aussi dans notre blog: