Plus récemment, nous avons recherché un scientifique des données dans l'équipe (et trouvé - bonjour,
nik_son et Arseny!). En discutant avec les candidats, nous avons réalisé que beaucoup de gens veulent changer d'emploi parce qu'ils font quelque chose «autour de la table».
Par exemple, ils assument les prévisions complexes proposées par le chef, mais le projet s'arrête parce que l'entreprise ne comprend pas quoi et comment inclure dans la production, comment réaliser un profit, comment «récupérer» les ressources dépensées sur le nouveau modèle.

HeadHunter n'a pas une grande puissance de calcul, comme Yandex ou Google. Nous comprenons combien il est difficile de mettre en production un ML complexe. Par conséquent, de nombreuses entreprises s'attardent sur le fait que les modèles linéaires les plus simples sont mis en production.
Au cours de la prochaine mise en œuvre du BC dans le système de recommandation et dans la recherche de postes vacants, nous avons rencontré un certain nombre de "râteaux" classiques. Faites attention à eux si vous avez l'intention de mettre en œuvre le ML à la maison: peut-être que cette liste vous aidera à ne pas y aller
et à trouver votre propre râteau personnel .
Rake n ° 1: Data Scientist - Artiste libre
Dans chaque entreprise qui commence à introduire l'apprentissage automatique, y compris les réseaux de neurones dans son travail, il y a un écart entre ce que le data scientist veut faire et ce qui profite à la production. Y compris parce que l'entreprise ne peut pas toujours expliquer ce qu'est un avantage et comment il peut aider.
Nous traitons cela de la manière suivante: nous discutons de toutes les idées émergentes, mais ne mettons en œuvre que ce qui bénéficiera à l'entreprise - maintenant ou à l'avenir. Nous ne faisons pas de recherche en vase clos.
Après chaque mise en œuvre ou expérience, nous considérons la qualité, les ressources et les effets économiques et mettons à jour nos plans.
Rake numéro 2: mise à jour des bibliothèques
Ce problème se produit dans plusieurs. De nombreuses bibliothèques nouvelles et pratiques apparaissent dont personne n'avait entendu parler il y a quelques années, ou pas du tout. Je voudrais utiliser les dernières bibliothèques, car elles sont plus pratiques.
Mais il y a plusieurs obstacles:
1. Si le prod utilise, par exemple, le 14e Ubuntu, alors il n'y a probablement pas de nouvelles bibliothèques. La solution consiste à transférer le service vers docker et à installer les bibliothèques Python à l'aide de pip (au lieu des packages deb).
2. Si un format dépendant du code est utilisé pour le stockage de données (tel que le pickle), cela fige les bibliothèques utilisées. Autrement dit, lorsque le modèle d'apprentissage automatique a été obtenu à l'aide de la bibliothèque scikit-learn version 15 et enregistré au format pickle, alors pour la récupération correcte du modèle, la bibliothèque scikit-learn à quinze versions sera nécessaire. Vous ne pouvez pas passer à la dernière version, et c'est un piège beaucoup plus insidieux que celui décrit au paragraphe 1.
Il y a deux façons de s'en sortir:
- Utiliser un format indépendant du code pour stocker des modèles
- être toujours en mesure de recycler n'importe quel modèle. Ensuite, lors de la mise à jour de la bibliothèque, il sera nécessaire de former tous les modèles et de les enregistrer avec la nouvelle version de la bibliothèque.
Nous avons choisi la deuxième voie.
Râteau numéro 3: travailler avec d'anciens modèles
Faire quelque chose de nouveau dans un ancien modèle appris est moins utile que faire quelque chose de simple dans un nouveau. Souvent, au final, il s'avère que l'introduction de modèles plus simples mais plus récents est plus utile et la quantité d'effort est moindre. Il est important de s'en souvenir et de toujours tenir compte de la quantité d'efforts communs dans la recherche de modèles.
Râteau numéro 4: uniquement des expériences locales
De nombreux experts en science des données aiment expérimenter localement sur leurs serveurs de machine learning. Seuls les producteurs n'ont pas une telle flexibilité: en conséquence, un tas de raisons sont révélées pour lesquelles il est impossible de faire glisser ces expériences en production.
Il est important de configurer la communication entre le spécialiste DS et les ingénieurs commerciaux pour une compréhension commune - comment tel ou tel modèle fonctionnera en production, s'il y a la puissance et la capacité physique nécessaires pour le déployer. De plus, plus les modèles et les facteurs sont complexes, plus il est difficile de les rendre fiables et de pouvoir les réentraîner à tout moment. Contrairement aux compétitions Kaggle, en production, il est souvent préférable de sacrifier les dix millièmes sur les métriques locales et même un petit KPI en ligne, mais mettre en œuvre la version des modèles est beaucoup plus simple, stable dans les résultats et facile dans les ressources informatiques.
Copropriété du code (les développeurs et les scientifiques des données savent comment fonctionne le code écrit par d'autres développeurs), réutilisation des signes et des méta-attributs dans divers modèles à la fois dans le processus d'apprentissage et dans le travail en prod (nous sommes aidés par us framework), unit- et autotests, que nous pilotons très souvent, intégration de code avec retest. Nous mettons les modèles finaux dans les référentiels git et les utilisons également en production.
Râteau numéro 5: test uniquement prod
Chacun de nos développeurs et scientifiques des données a son propre banc de test, parfois pas un. Les principaux composants de la production HH y sont déployés. C'est cher, mais ça paie pour la qualité et la rapidité de développement. C'est nécessaire, mais pas suffisant. Nous chargeons non seulement les modèles qui sont déjà en production, mais aussi ceux qui seront bientôt là. Cela permet de comprendre avec le temps que les modèles qui fonctionnent parfaitement sur les machines locales, les bancs d'essai ou en production pour 5% des utilisateurs, et lorsqu'ils sont allumés à 100%, sont trop lourds.
Nous utilisons plusieurs étapes de test. Nous vérifions le code très rapidement (c'est le point clé) - lors de l'ajout ou de la modification de composants dans le référentiel, le code est collecté, les tests unitaires et automatiques sont exécutés sur les composants correspondants, si nécessaire, nous les testons également manuellement - et si quelque chose ne va pas, donnez une réponse "Le tien est cassé, décide."
Râteau numéro 6: longs calculs et perte de concentration
Si un modèle nécessite, disons, une semaine de formation, il est facile de perdre sa concentration sur la tâche en raison du passage à un autre projet. Nous essayons de ne pas donner aux développeurs et aux scientifiques des données plus de deux tâches dans une main. Et pas plus d'un urgent afin que vous puissiez y basculer dès que les calculs ou les expériences A / B sont terminés pour lui. Cette règle est nécessaire pour ne pas perdre le focus, et par crainte que certaines de ces tâches ne courent généralement le risque d'être perdues, et une autre partie qui se déroule bien plus tard que nécessaire.
Nous avons marché sur un râteau mais n'avons pas abandonné
Nous avons récemment terminé une expérience sur l'introduction de réseaux de neurones dans un système de recommandation. Tout a commencé avec le fait qu'en deux jours, le hackathon interne a rédigé un modèle de prévision des réponses par CV, ce qui a grandement facilité la recherche de postes vacants appropriés.
Mais plus tard, nous avons appris: pour le mettre en production, vous devez mettre à jour à peu près tout - par exemple, transférer le système à double usage, qui considère les signes et enseigne les modèles, à Docker, ainsi que la mise à jour des bibliothèques d'apprentissage automatique.
Comment c'était
Nous avons utilisé le modèle DSSM avec un réseau neuronal monocouche. Dans l'article original de Microsoft, un réseau neuronal à trois couches a été utilisé, mais nous n'avons pas observé d'amélioration de la qualité avec une augmentation du nombre de couches, nous nous sommes donc installés sur une seule couche.

En bref:
- Le texte de la requête et l'en-tête de la vacance sont convertis en deux vecteurs trigrammes de symboles. Nous utilisons 20 000 trigrammes de caractères.
- Le vecteur trigramme est alimenté à l'entrée d'un réseau neuronal monocouche. À l'entrée de la couche de réseau neuronal, il y a 20 000 nombres, à la sortie, 64. Essentiellement, le réseau neuronal est une matrice de 20 000 x 64 par laquelle le vecteur trigramme d'entrée de dimension 1 x 20 000 est multiplié. Un vecteur constant de dimension 1 x 64 est ajouté au résultat de la multiplication. la sortie d'un tel réseau de neurones correspond à la demande (ou au titre de la vacance).
- Le produit scalaire du vecteur dssm de requête et du vecteur dssm d'en-tête de vacance est calculé. La fonction sigmoïde est appliquée au travail. Le résultat final est le méta-signe dssm.
Lorsque nous avons essayé d'inclure ce modèle pour la première fois, les mesures locales sont devenues meilleures, mais lorsque nous avons essayé de l'intégrer dans le test A / B, nous avons constaté qu'il n'y avait aucune amélioration.
Après cela, nous avons essayé d'augmenter la deuxième couche de neurones à 256 - déployée par 5% des utilisateurs: il s'est avéré que le système de recommandation et la recherche étaient devenus meilleurs, mais lorsque vous avez allumé le modèle à 100%, il s'est avéré soudain qu'il était trop lourd.
Nous avons analysé pourquoi le modèle est si lourd, enlevé la tige et expérimenté à nouveau ce réseau de neurones. Et ce n'est qu'après cela, après avoir parcouru tout le chemin, qu'ils ont découvert que le modèle est utile: le nombre de réponses dans le système de recommandation a augmenté de 700 par jour, et dans la recherche, après tous les recomptages, de 4200.
L'introduction d'un réseau neuronal aussi peu complexe permet à nos clients d'embaucher plusieurs dizaines d'employés supplémentaires chaque jour via hh.ru, et pendant la mise en œuvre, nous avons vaincu une partie importante des gros problèmes. Par conséquent, nous prévoyons de développer davantage nos réseaux de neurones. Les plans sont d'essayer la racine générale, la lemmatisation supplémentaire, de traiter les textes complets de la vacance et de reprendre, de faire des expériences avec la topologie (couches cachées et, éventuellement, RNN / LSTM).
La chose la plus importante que nous ayons faite avec ce modèle:
- Ne laissez pas tomber l'expérience au milieu.
- Nous avons calculé les indicateurs d'augmentation de la réponse et avons constaté que le travail sur ce modèle en valait la peine. Il est très important de comprendre les avantages de chacune de ces implémentations.
Fait intéressant, le modèle que nous avons fait et finalement ajouté à la prod est très similaire à la méthode des composants principaux (PCA) appliquée à la matrice [texte de la requête, titre du document, s'il y a eu un clic]. C'est-à-dire, à une matrice dans laquelle une ligne correspond à une requête unique, une colonne à un en-tête vacant unique; la valeur dans la cellule est 1 si après cette demande, l'utilisateur a cliqué sur un poste vacant avec cette rubrique, et 0 s'il n'y a pas eu de clic.
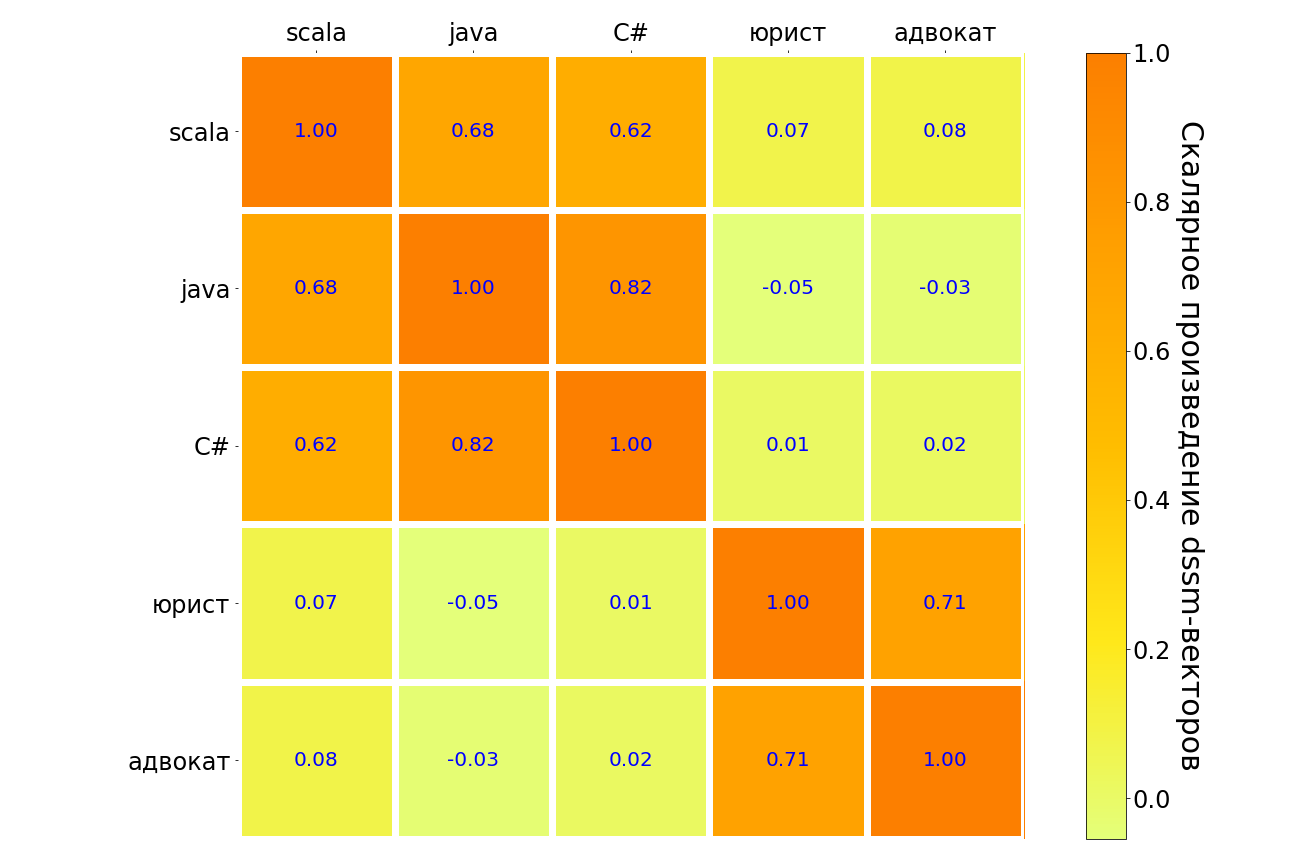
Les résultats de l'application de ce modèle aux demandes scala, java, C #, «avocat», «avocat» sont présentés dans le tableau ci-dessous. Semblable dans le sens, les paires de requêtes sont mises en évidence dans l'obscurité, contrairement à la lumière. On peut voir que le modèle comprend la connexion entre différents langages de programmation, il y a une forte connexion entre la requête «avocat» et «avocat». Mais entre "l'avocat" et tout langage de programmation, la connexion est très faible.
À un moment donné, je veux vraiment abandonner - les expériences se poursuivent, mais elles ne «s'enflamment» pas. À ce stade, un data scientist peut trouver utile de soutenir l'équipe et de calculer à nouveau les avantages: il peut être utile «d'enterrer l'hôtesse de l'air» et de ne pas essayer de «monter à cheval», ce n'est pas un échec, mais une expérience réussie avec un résultat négatif. Ou, après avoir pesé le pour et le contre, vous effectuerez une autre expérience qui «tirera». Cela nous est donc arrivé.