À la fin de l'hiver de cette année, le concours IEEE Signal Processing Society - Camera Model Identification a eu lieu. J'ai participé à ce concours par équipe en tant que mentor. A propos d'une méthode alternative de team building, de décision et de la deuxième étape sous la coupe.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
Énoncé du problèmeA partir de la photo, il est nécessaire de déterminer le dispositif sur lequel cette photo a été obtenue. L'ensemble de données se composait d'images de dix classes: deux iPhones, sept smartphones Android et une caméra. L'échantillon de formation comprenait 275 images en taille réelle de chaque classe. Dans l'échantillon test, seule la récolte centrale de 512 x 512 a été présentée. De plus, l'une des trois augmentations a été appliquée à 50% d'entre elles: compression jpg, redimensionnement avec interpolation cubique ou correction gamma. Il était possible d'utiliser des données externes.
 Essence (tm)
Essence (tm)Si vous essayez d'expliquer la tâche dans un langage simple, l'idée est présentée dans l'image ci-dessous. En règle générale, les réseaux de neurones modernes apprennent à distinguer les objets sur une photographie. c'est-à-dire vous devez apprendre à distinguer les chats des chiens, la pornographie des maillots de bain ou les réservoirs des routes. Dans le même temps, il doit toujours être indifférent à la façon dont et sur quel appareil une photo d'un chat et d'un réservoir est prise.

Dans le même concours, tout était tout à fait le contraire. Indépendamment de ce qui est montré sur la photo, vous devez déterminer le type d'appareil. Autrement dit, utilisez des éléments comme le bruit de matrice, les artefacts de traitement d'image, les défauts optiques, etc. C'était le principal défi - développer un algorithme qui capture les caractéristiques de bas niveau des images.
Caractéristiques du travail d'équipeL'écrasante majorité des équipes kaggle est formée comme suit: les participants avec une avance proche sur le classement sont réunis en une équipe, tandis que chacun scie sa version de la solution du début à la fin. J'ai écrit un
article sur un exemple typique d'un tel discours. Cependant, cette fois, nous sommes allés dans l'autre sens, à savoir: nous avons divisé les parties de la décision en personnes. De plus, selon les règles de la compétition, les 3 meilleures équipes étudiantes ont reçu un billet pour le Canada pour la deuxième étape. Par conséquent, lorsque l'épine dorsale s'est rassemblée, nous avons manqué de personnel pour respecter les règles.
SolutionPour montrer un bon résultat sur cette tâche, il a fallu assembler le puzzle suivant en fonction des priorités:
- Recherchez et téléchargez des données externes. Ce concours a été autorisé à utiliser un nombre illimité de données externes. Et assez rapidement, il est devenu clair qu'un grand ensemble de données externes traînait.
- Filtrer les données externes. Les gens publient parfois des images traitées, ce qui tue toutes les fonctionnalités de l'appareil.
- Utilisez un schéma de validation local fiable. Étant donné qu'un seul modèle a montré une précision de l'ordre de 0,98+ et que, dans le test, il n'y avait que 2 000 tirs, le choix du point de contrôle du modèle était une tâche distincte.
- Modèles de train. Une ligne de base très puissante a été publiée sur le forum. Cependant, sans une pincée de magie, il n'a autorisé que l'argent.
Collecte de donnéesCette partie était occupée par
Arthur Fattakhov . Pour cette tâche, il était assez facile d'obtenir des données externes, ce ne sont que des images de certains modèles de téléphones. Arthur a écrit un script python qui utilise la bibliothèque pour analyser facilement les pages html appelées
BeautifulSoup . Mais, par exemple, sur la page de l'album Flickr, des blocs de photos sont chargés dynamiquement, et pour contourner cela, j'ai dû utiliser du
sélénium , qui émulait l'action du navigateur. Au total, plus de 500 Go de photos ont été téléchargés à partir de yandex.fotki, flickr, wiki commons.
Filtrage des donnéesCe fut ma seule contribution à la solution sous forme de code. Je viens de regarder à quoi ressemblaient les photos brutes et j'ai établi un tas de règles: 1) la taille typique d'un modèle particulier 2) la qualité jpg est supérieure au seuil 3) la présence des méta-tags nécessaires des modèles 4) le logiciel correct qui a été traité.
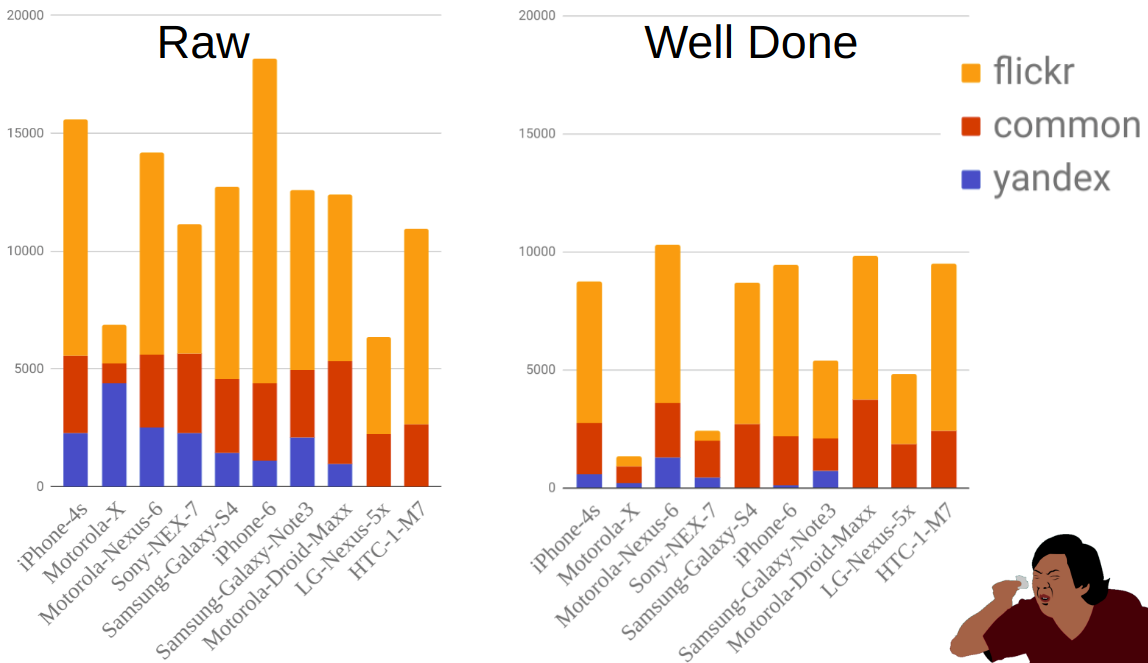
La figure montre la répartition des photographies par source et mobile avant et après filtrage. Comme vous pouvez le voir, par exemple, Moto-X est beaucoup plus petit que les autres téléphones. Dans le même temps, il y en avait beaucoup avant le filtrage, mais la plupart d'entre eux ont été éliminés car il existe de nombreuses options pour ce téléphone et les propriétaires n'ont pas toujours correctement indiqué le modèle.
ValidationL'implémentation de la partie avec formation et validation a été réalisée par
Ilya Kibardin . La validation sur un morceau de train kaggle n'a pas fonctionné du tout - la grille a assommé la précision de près de 1,0, et au classement, elle était d'environ 0,96.
Par conséquent, la validation a été prise des photos de
Gleb Posobin , qu'il a prises sur tous les sites avec des critiques téléphoniques. Il y avait une erreur: au lieu de l'iPhone 6, il y avait un iPhone 6+. Nous l'avons remplacé par un véritable iPhone 6 et lâché 10% des images du train du kagla pour équilibrer les classes.
Lors de l'apprentissage de la métrique a été considérée comme suit:
- Nous considérons l'entropie croisée et l'akurasi au centre de la culture depuis la validation.
- Nous considérons l'entropie croisée et l'akurasi (manipulation + centre de culture) pour chacune des 8 manipulations, en les moyennant sur huit manipulations avec une moyenne arithmétique.
- Nous ajoutons la vitesse de l'article 1 et de l'article 2 avec les poids 0,7 et 0,3.
Les meilleurs points de contrôle ont été sélectionnés en fonction de l'entropie croisée pondérée obtenue dans la section 3.
Formation modèleQuelque part au milieu de la compétition,
Andres Torrubia a affiché le
code entier
pour sa décision . Il était si bon en termes de précision des modèles finaux qu'un groupe d'équipes a volé avec lui dans le classement. Cependant, il était écrit en keras et le niveau de code souhaité.
La situation a changé une deuxième fois quand
Ivan Romanov a publié une
version pytorch de ce code. Il était plus rapide et, en plus, il se connectait facilement à plusieurs cartes vidéo. Le niveau de code, cependant, n'était toujours pas très bon, mais ce n'est pas si important.
La tristesse est que ces gars ont terminé respectivement aux 30e et 45e places, mais dans nos cœurs, ils sont toujours restés au sommet.
Ilya dans notre équipe a pris le code de Misha et a apporté les modifications suivantes.
Prétraitement:- De la photo originale est faite un recadrage aléatoire 960x960.
- Avec une probabilité de 0,5, une manipulation aléatoire est appliquée. (Selon qu'il a été utilisé, is_manip = 1 ou 0 est défini)
- Un recadrage aléatoire est effectué 480x480
- Il y avait deux options de formation: soit une rotation aléatoire de 90 degrés est effectuée dans une direction spécifique (simulant la prise de vue horizontale / verticale pour un téléphone mobile), soit une conversion aléatoire du groupe D4.
 La formation
La formationLa formation a été entièrement réalisée par le réseau finetune, sans geler les couches convolutives du classificateur (nous avions beaucoup de données + intuitivement, les poids qui extraient des objets de haut niveau sous forme de chats / chiens peuvent être étendus, car nous avons besoin de fonctionnalités de bas niveau).
 Délais:
Délais:Adam avec lr = 1e-4. Lorsque la perte de validation cesse de s'améliorer pendant 2-3 époques, nous réduisons lr de moitié. Donc à la convergence. Remplacez Adam par SGD et apprenez trois cycles avec un lr cyclique de 1e-3 à 1e-6.
Ensemble final:J'ai demandé à Ilya de mettre en œuvre mon approche du concours précédent. Pour l'ensemble filial, nous avons formé 9 modèles, à partir de chacun, nous avons sélectionné les 3 meilleurs points de contrôle, chaque point de contrôle a été prédit avec TTA et au final toutes les prédictions ont été moyennées par moyenne géométrique.
 Postface de la première étape
Postface de la première étapeEn conséquence, nous avons pris la 2e place au classement et la 1ère place parmi les équipes d'étudiants. Et cela signifie que nous sommes arrivés à la 2e étape de ce concours dans le cadre de la
Conférence internationale 2018 de l'IEEE sur l'acoustique, le traitement de la parole et du signal au Canada. Parmi les remarquables, l'équipe qui a pris la 3e place était également formellement étudiante. Si nous calculons la vitesse, il s'avère que nous l'avons contournée avec une image correctement prédite.
Final IEEE Signal Processing Cup 2018Après avoir reçu toutes les confirmations, moi, Valery et Andrey avons décidé de ne pas aller au Canada pour la deuxième étape. Ilya et Arthur F. ont décidé de partir, ils ont commencé à tout arranger et ils n'ont pas reçu de visa. Pour éviter un scandale international sur l'oppression des scientifiques russes les plus puissants, les orgies ont été autorisées à participer à distance.
La chronologie était comme ceci:
03.03 - compte tenu des données du train
04.09 - données d'essai publiées
12.04 - nous avons été autorisés à participer à distance
13.04 - nous avons commencé à regarder ce qu'il y a avec les données
16/04 - final
Caractéristiques de la deuxième étapeÀ la deuxième étape, il n'y avait pas de classement: il fallait envoyer une seule soumission à la toute fin. Autrement dit, même le format des prédictions ne peut pas être vérifié. De plus, les modèles de caméras n'étaient pas connus. Et cela signifie deux fichiers à la fois: cela ne fonctionnera pas en utilisant des données externes et la validation locale peut être très peu représentative.
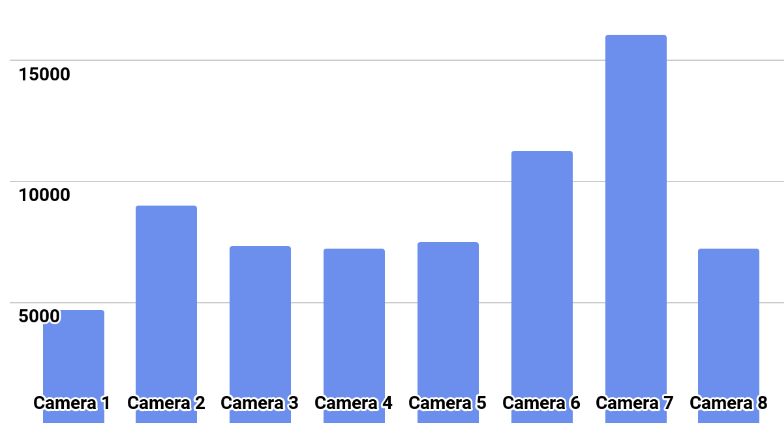
La distribution des classes est montrée dans l'image.
SolutionNous avons essayé de former des modèles avec un plan de la première étape à partir des échelles des meilleurs modèles. Tous les modèles se sont joyeusement entraînés à une précision de 0,97+ sur leurs plis, mais lors du test, ils ont donné une intersection de prédictions dans la région de 0,87.
Ce que j'ai interprété comme une sur-tenue dure. Il a donc proposé un nouveau plan:
- Nous prenons nos meilleurs modèles du premier étage comme extracteurs de fonctionnalités.
- Nous prenons le PCA des fonctionnalités extraites pour que tout apprenne du jour au lendemain.
- Learning LightGBM.

La logique ici est la suivante. Les réseaux de neurones sont déjà formés pour extraire les caractéristiques de bas niveau du capteur, de l'optique, de l'algorithme de démonstration et, en même temps, ne s'accrochent pas au contexte. De plus, les entités extraites avant le classificateur final (en fait, la régression logistique) sont le résultat d'une transformation fortement non linéaire. Par conséquent, on pourrait simplement enseigner quelque chose de simple, non sujet à un recyclage, comme la régression logistique. Cependant, comme les nouvelles données peuvent être très différentes des données de la première étape, il est toujours préférable de former quelque chose de non linéaire, par exemple, l'augmentation du gradient sur les arbres de décision. J'ai utilisé cette approche dans plusieurs compétitions, où j'ai posté le code.
Puisqu'il y a eu une soumission, je n'ai aucun moyen fiable de tester mon approche. Cependant, DenseNet s'est avéré être le meilleur extracteur de fonctionnalités. Les réseaux Resnext et SE-Resnext ont montré des performances inférieures sur la validation locale. Par conséquent, la décision finale ressemblait à ceci.
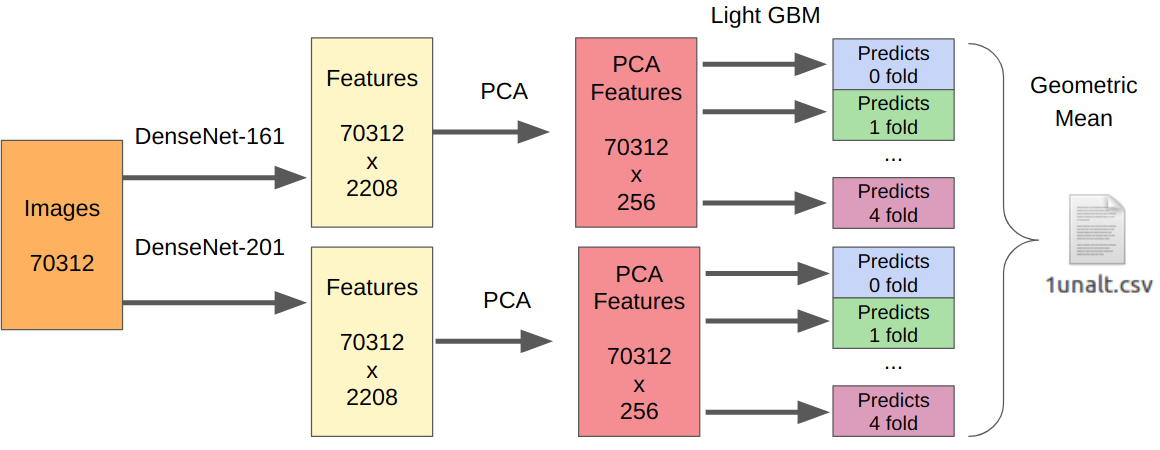
Pour la partie avec des manipulations, le nombre de tous les échantillons d'apprentissage doit être multiplié par 7, car j'ai extrait les fonctionnalités de chaque manipulation séparément.
PostfaceEn conséquence, à l'étape finale, nous avons pris la deuxième place, mais il y a beaucoup de réserves. Pour commencer, la place a été décernée non pas en fonction de la précision de l'algorithme, mais en fonction des estimations de la présentation du jury. L'équipe, qui a obtenu la première place, a fait non seulement une preza, mais aussi une démo en direct avec le travail de leur algorithme. Eh bien, nous ne connaissons toujours pas la vitesse finale de chaque équipe, et les organisations ne les divulguent pas par correspondance même après des questions directes.
Parmi les choses amusantes: lors de la première étape, toutes les équipes de notre communauté ont indiqué le nom de l'équipe [ods.ai] et ont occupé le classement de manière assez puissante. Après cela, des légendes de Kegle comme l'
inversion et
Giba ont décidé de nous rejoindre pour voir ce que nous faisions ici.

J'ai vraiment aimé participer en tant que mentor. Sur la base de l'expérience de participation à des compétitions précédentes, j'ai pu donner un certain nombre de conseils précieux sur l'amélioration de la base de référence, ainsi que la construction d'une validation locale. À l'avenir, un tel format sera plus que le cas: Kaggle Master / Grandmaster en tant qu'architecte de la solution + 2-3 Kaggle Expert pour écrire du code et tester des hypothèses. À mon avis, c'est purement gagnant-gagnant, car les participants expérimentés sont déjà trop paresseux pour écrire du code et peut-être pas beaucoup de temps, et les débutants obtiennent de meilleurs résultats, ne commettent pas d'erreurs banales par inexpérience et acquièrent de l'expérience encore plus rapidement.
→
Code de notre solution→
Enregistrement des performances avec l'entraînement ML