Déployer kubernetes HA avec containerd

Bonjour chers lecteurs de Habr! Le 24 mai 2018, un article intitulé Kubernetes Containerd Integration Goes GA a été publié sur le blog officiel de Kubernetes, qui indique que l'intégration de containerd avec Kubernetes est prête pour la production. En outre, des gars de la société Flant ont publié une traduction de l'article en russe sur leur blog, ajoutant une petite clarification d'eux-mêmes. Après avoir lu la documentation du projet sur github , j'ai décidé d'essayer containerd sur "ma propre peau".
Notre entreprise a plusieurs projets au stade de "encore très loin de la production". Ils deviendront donc notre expérimental; pour eux, nous avons décidé d'essayer de déployer un cluster de basculement de Kubernetes à l'aide de containerd et de voir s'il y a de la vie sans docker.
Si vous êtes intéressé de voir comment nous l'avons fait et ce qui en est arrivé, bienvenue chez cat.
Description du schéma et du déploiement
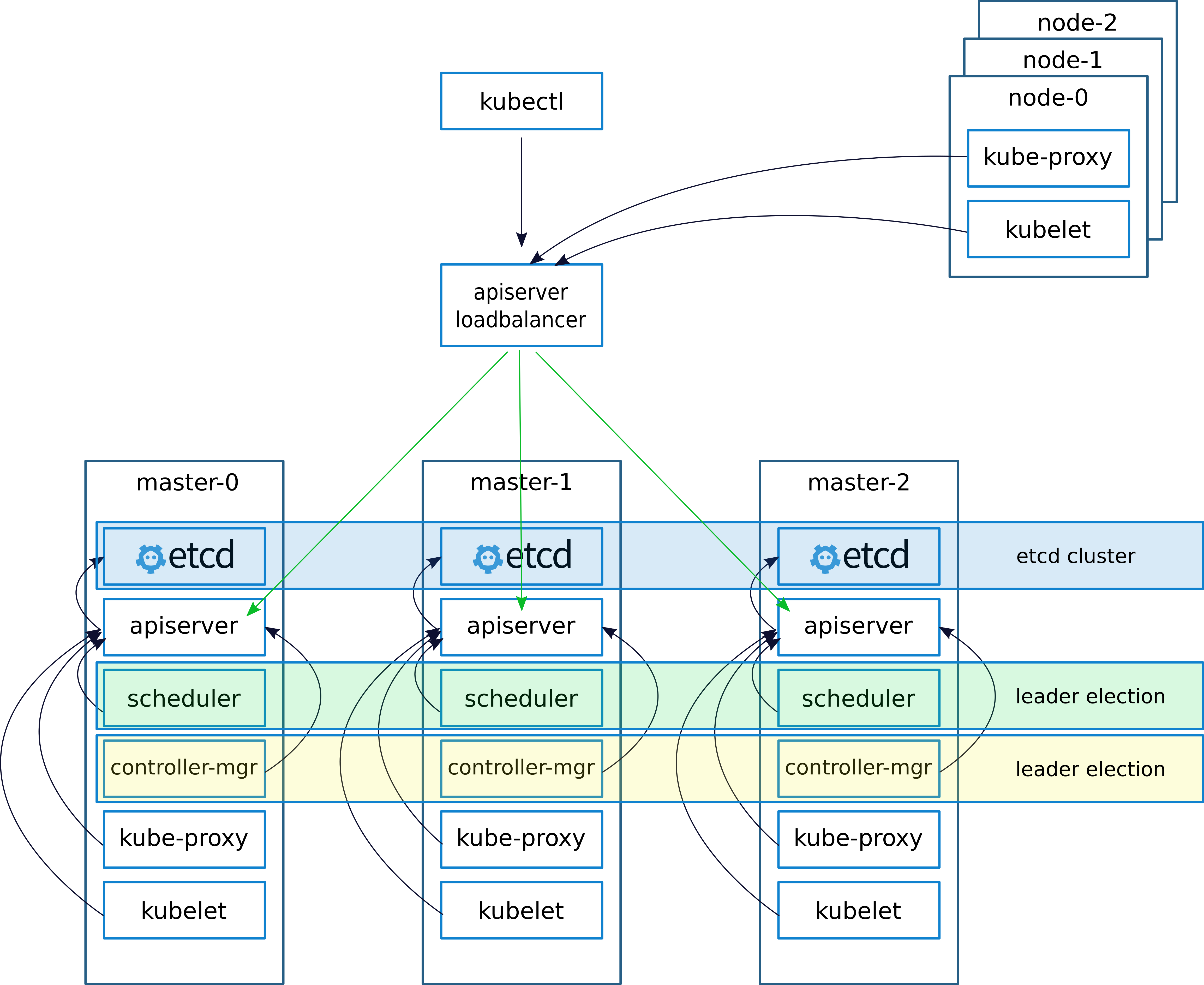
Lors du déploiement d'un cluster, comme d'habitude, (j'ai écrit à ce sujet dans un article précédent
keepalived - implémentations de VRRP (Virtual Router Redundancy Protocol) pour LinuxKeepalived crée une IP virtuelle (VIRTIP) qui "pointe" (crée une sous-interface) vers l'IP de l'un des trois maîtres. Le démon keepalived surveille la santé des machines et, en cas de panne, exclut le serveur défaillant de la liste des serveurs actifs en basculant VIRTIP vers l'IP d'un autre serveur, selon le "poids" spécifié lors de la configuration de keepalived sur chaque serveur.
Les démons Keepalived communiquent via VRRP, s'envoyant des messages à l'adresse 224.0.0.18.
Si le voisin n'a pas envoyé son message, après la période, il est considéré comme mort. Dès que le serveur en panne commence à envoyer ses messages au réseau, tout revient à sa place
Nous configurons le travail avec le serveur API sur les nœuds kubernetes comme suit.
Après avoir installé le cluster, configurez kube-proxy, changez le port de 6443 en 16443 (détails ci-dessous). Sur chacun des maîtres, nginx est déployé, qui fonctionne comme un équilibreur de charge, écoute sur le port 16443 et fait un amont des trois maîtres sur le port 6443 (détails ci-dessous).
Ce schéma a permis d'augmenter la tolérance aux pannes en utilisant keepalived, ainsi qu'en utilisant nginx, un équilibrage entre les serveurs API sur les assistants a été atteint.
Dans un article précédent, j'ai décrit le déploiement de nginx et etcd dans docker. Mais dans ce cas, nous n'avons pas de docker, donc nginx et etcd fonctionneront localement sur les masternodes.
Théoriquement, il serait possible de déployer nginx et etcd en utilisant containerd, mais en cas de problème, cette approche compliquerait le diagnostic, nous avons donc décidé de ne pas l'expérimenter et de l'exécuter localement.
Description des serveurs à déployer:
| Nom | IP | Les services |
|---|
| VIRTIP | 172.26.133.160 | ------ |
| kube-master01 | 172.26.133.161 | kubeadm, kubelet, kubectl, etcd, containerd, nginx, keepalived |
| kube-master02 | 172.26.133.162 | kubeadm, kubelet, kubectl, etcd, containerd, nginx, keepalived |
| kube-master03 | 172.26.133.163 | kubeadm, kubelet, kubectl, etcd, containerd, nginx, keepalived |
| kube-node01 | 172.26.133.164 | kubeadm, kubelet, kubectl, containerd |
| kube-node02 | 172.26.133.165 | kubeadm, kubelet, kubectl, containerd |
| kube-node03 | 172.26.133.166 | kubeadm, kubelet, kubectl, containerd |
Installer kubeadm, kubelet, kubectl et les packages associés
Toutes les commandes s'exécutent à partir de root
sudo -i
apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl unzip tar apt-transport-https btrfs-tools libseccomp2 socat util-linux mc vim keepalived
Installer conteinerd
cd / wget https://storage.googleapis.com/cri-containerd-release/cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz tar -xvf cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz
Configuration des configurations containerd
mkdir -p /etc/containerd nano /etc/containerd/config.toml
Ajouter au fichier:
[plugins.cri] enable_tls_streaming = true
On démarre conteinerd on vérifie que tout va bien
systemctl enable containerd systemctl start containerd systemctl status containerd ● containerd.service - containerd container runtime Loaded: loaded (/etc/systemd/system/containerd.service; disabled; vendor preset: enabled) Active: active (running) since Mon 2018-06-25 12:32:01 MSK; 7s ago Docs: https://containerd.io Process: 10725 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS) Main PID: 10730 (containerd) Tasks: 15 (limit: 4915) Memory: 14.9M CPU: 375ms CGroup: /system.slice/containerd.service └─10730 /usr/local/bin/containerd Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Get image filesystem path "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs"" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=error msg="Failed to load cni during init, please check CRI plugin status before setting up network for pods" error="cni con Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="loading plugin "io.containerd.grpc.v1.introspection"..." type=io.containerd.grpc.v1 Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start subscribing containerd event" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start recovering state" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg=serving... address="/run/containerd/containerd.sock" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="containerd successfully booted in 0.308755s" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start event monitor" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start snapshots syncer" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start streaming server"
Installer et exécuter etcd
Remarque importante, j'ai installé la version 1.10 du cluster kubernetes. Quelques jours plus tard, au moment de la rédaction de l'article, la version 1.11 était disponible. Si vous installez la version 1.11, définissez la variable ETCD_VERSION = "v3.2.17", si 1.10 alors ETCD_VERSION = "v3.1.12".
export ETCD_VERSION="v3.1.12" curl -sSL https://github.com/coreos/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin/
Copiez les configurations de gitahab.
git clone https://github.com/rjeka/k8s-containerd.git cd k8s-containerd
Configurez les variables dans le fichier de configuration.
vim create-config.sh
Description des variables du fichier create-config.sh
paramètres sur la machine locale de chaque nœud (chaque nœud a le sien)
K8SHA_IPLOCAL - Adresse IP du noeud sur lequel le script est configuré
K8SHA_ETCDNAME - nom de la machine locale dans le cluster ETCD
K8SHA_KA_STATE - rôle dans keepalived. Un nœud MASTER, tous les autres BACKUP.
K8SHA_KA_PRIO - priorité persistante , le maître a 102 pour les 101, 100 restants. Lorsque le maître avec le numéro 102 tombe, le nœud avec le numéro 101 prend sa place et ainsi de suite.
K8SHA_KA_INTF - Interface réseau keepalived. Le nom de l'interface que keepalived écoutera.
Les paramètres généraux pour tous les masternodes sont les mêmes:
K8SHA_IPVIRTUAL = 172.26.133.160 - IP virtuelle du cluster.
K8SHA_IP1 ... K8SHA_IP3 - Adresses IP des maîtres
K8SHA_HOSTNAME1 ... K8SHA_HOSTNAME3 - noms d'hôte pour les masternodes. Un point important, par ces noms, kubeadm générera des certificats.
K8SHA_KA_AUTH - mot de passe pour keepalived. Vous pouvez spécifier tout
K8SHA_TOKEN - jeton de cluster. Peut être généré avec la commande kubeadm token generate
K8SHA_CIDR - adresse de sous-réseau pour les foyers. J'utilise de la flanelle donc CIDR 0.244.0.0/16. Assurez-vous de filtrer - dans la configuration devrait être K8SHA_CIDR = 10.244.0.0 \ / 16
Exécutez le script qui configurera nginx, keepalived, etcd et kubeadmin
./create-config.sh
Nous commençons etcd.
etcd j'ai soulevé sans tls. Si vous avez besoin de tls, alors dans la
documentation officielle de kubernetes, il est écrit en détail comment générer des certificats pour etcd.
systemctl daemon-reload && systemctl start etcd && systemctl enable etcd
Vérification de l'état
etcdctl cluster-health member ad059013ec46f37 is healthy: got healthy result from http://192.168.5.49:2379 member 4d63136c9a3226a1 is healthy: got healthy result from http://192.168.4.169:2379 member d61978cb3555071e is healthy: got healthy result from http://192.168.4.170:2379 cluster is healthy etcdctl member list ad059013ec46f37: name=hb-master03 peerURLs=http://192.168.5.48:2380 clientURLs=http://192.168.5.49:2379,http://192.168.5.49:4001 isLeader=false 4d63136c9a3226a1: name=hb-master01 peerURLs=http://192.168.4.169:2380 clientURLs=http://192.168.4.169:2379,http://192.168.4.169:4001 isLeader=true d61978cb3555071e: name=hb-master02 peerURLs=http://192.168.4.170:2380 clientURLs=http://192.168.4.170:2379,http://192.168.4.170:4001 isLeader=false
Si tout va bien, passez à l'étape suivante.
Configurer kubeadmin
Si vous utilisez kubeadm version 1.11, vous pouvez ignorer cette étape
Pour que kybernetes commence à fonctionner non pas avec docker, mais avec containerd, configurez la configuration kubeadmin
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Après [Service], ajoutez une ligne au bloc
Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
La configuration entière devrait ressembler à ceci: [Service] Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock" Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true" Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin" Environment="KUBELET_DNS_ARGS=--cluster-dns=10.96.0.10 --cluster-domain=cluster.local" Environment="KUBELET_AUTHZ_ARGS=--authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt" Environment="KUBELET_CADVISOR_ARGS=--cadvisor-port=0" Environment="KUBELET_CERTIFICATE_ARGS=--rotate-certificates=true --cert-dir=/var/lib/kubelet/pki" ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_SYSTEM_PODS_ARGS $KUBELET_NETWORK_ARGS $KUBELET_DNS_ARGS $KUBELET_AUTHZ_ARGS $KUBELET_CADVISOR_ARGS $KUBELET_CERTIFICATE_ARGS $KUBELET_EXTRA_ARGS
Si vous installez la version 1.11 et souhaitez tester CoreDNS au lieu de kube-dns et tester la configuration dynamique, décommentez le bloc suivant dans le fichier de configuration kubeadm-init.yaml:
feature-gates: DynamicKubeletConfig: true CoreDNS: true
Redémarrez le kubelet
systemctl daemon-reload && systemctl restart kubelet
Initialisation du premier assistant
Avant de démarrer kubeadm, vous devez redémarrer keepalived et vérifier son état
systemctl restart keepalived.service systemctl status keepalived.service ● keepalived.service - Keepalive Daemon (LVS and VRRP) Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2018-06-27 10:40:03 MSK; 1min 44s ago Process: 4589 ExecStart=/usr/sbin/keepalived $DAEMON_ARGS (code=exited, status=0/SUCCESS) Main PID: 4590 (keepalived) Tasks: 7 (limit: 4915) Memory: 15.3M CPU: 968ms CGroup: /system.slice/keepalived.service ├─4590 /usr/sbin/keepalived ├─4591 /usr/sbin/keepalived ├─4593 /usr/sbin/keepalived ├─5222 /usr/sbin/keepalived ├─5223 sh -c /etc/keepalived/check_apiserver.sh ├─5224 /bin/bash /etc/keepalived/check_apiserver.sh └─5231 sleep 5
vérifier si VIRTIP pings
ping -c 4 172.26.133.160 PING 172.26.133.160 (172.26.133.160) 56(84) bytes of data. 64 bytes from 172.26.133.160: icmp_seq=1 ttl=64 time=0.030 ms 64 bytes from 172.26.133.160: icmp_seq=2 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=3 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=4 ttl=64 time=0.056 ms --- 172.26.133.160 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3069ms rtt min/avg/max/mdev = 0.030/0.046/0.056/0.012 ms
Après cela, exécutez kubeadmin. Assurez-vous d'inclure la ligne --skip-preflight-checks. Kubeadmin recherche par défaut Docker et sans ignorer les vérifications échouera avec une erreur.
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
Une fois que kubeadm a fonctionné, enregistrez la ligne générée. Il sera nécessaire d'entrer des nœuds de travail dans le cluster.
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Ensuite, indiquez où le fichier admin.conf est stocké
Si nous travaillons en tant que root, alors:
vim ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf source ~/.bashrc
Pour un utilisateur simple, suivez les instructions à l'écran.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
Ajoutez 2 assistants supplémentaires au cluster. Pour ce faire, copiez les certificats de kube-master01 vers kube-master02 et kube-master03 dans le répertoire / etc / kubernetes /. Pour ce faire, j'ai configuré l'accès ssh pour root, et après avoir copié les fichiers, j'ai renvoyé les paramètres.
scp -r /etc/kubernetes/pki 172.26.133.162:/etc/kubernetes/ scp -r /etc/kubernetes/pki 172.26.133.163:/etc/kubernetes/
Après avoir copié vers kube-master02 et kube-master03, exécutez.
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
Installer la flanelle CIDR
sur kube-master01 exécuter
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
La version actuelle de flanel se trouve dans la documentation de kubernetes .
Nous attendons que tous les conteneurs soient créés.
watch -n1 kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE kube-system kube-apiserver-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-apiserver-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-apiserver-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-controller-manager-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-controller-manager-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-controller-manager-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-dns-86f4d74b45-8c24s 3/3 Running 0 17m 10.244.2.2 kube-master03 kube-system kube-flannel-ds-4h4w7 1/1 Running 0 2m 172.26.133.163 kube-master03 kube-system kube-flannel-ds-kf5mj 1/1 Running 0 2m 172.26.133.162 kube-master02 kube-system kube-flannel-ds-q6k4z 1/1 Running 0 2m 172.26.133.161 kube-master01 kube-system kube-proxy-9cjtp 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master01 1/1 Running 0 18m 172.26.133.161 kube-master01 kube-system kube-scheduler-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03
Nous faisons la réplication de kube-dns aux trois maîtres
Sur kube-master01 exécuter
kubectl scale --replicas=3 -n kube-system deployment/kube-dns
Installer et configurer nginx
Sur chaque nœud maître, installez nginx en tant qu'équilibreur pour l'API Kubernetes
J'ai toutes les machines du cluster sur Debian. Parmi les packages nginx, le module de flux ne prend pas en charge, alors ajoutez les référentiels nginx et installez-le à partir des référentiels nginx`a. Si vous avez un système d'exploitation différent, consultez la documentation nginx .
wget https://nginx.org/keys/nginx_signing.key sudo apt-key add nginx_signing.key echo -e "\n#nginx\n\ deb http://nginx.org/packages/debian/ stretch nginx\n\ deb-src http://nginx.org/packages/debian/ stretch nginx" >> /etc/apt/sources.list apt-get update && apt-get install nginx -y
Créer une configuration nginx (si ce n'est déjà fait)
./create-config.sh
nginx.confuser nginx;
worker_processes auto;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
événements {
travailleurs_connexions 1024;
}
http {
inclure /etc/nginx/mime.types;
application par défaut_type / flux d'octets;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf;
}
stream {
apiserver en amont {
serveur 172.26.133.161:6443 poids = 5 max_fails = 3 fail_timeout = 30s;
serveur 172.26.133.162:6443 poids = 5 max_fails = 3 fail_timeout = 30s;
serveur 172.26.133.163:6443 poids = 5 max_fails = 3 fail_timeout = 30s;
} server { listen 16443; proxy_connect_timeout 1s; proxy_timeout 3s; proxy_pass apiserver; }
}
Nous vérifions que tout va bien et appliquons la configuration
nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful systemctl restart nginx systemctl status nginx ● nginx.service - nginx - high performance web server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2018-06-28 08:48:09 MSK; 22s ago Docs: http://nginx.org/en/docs/ Process: 22132 ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf (code=exited, status=0/SUCCESS) Main PID: 22133 (nginx) Tasks: 2 (limit: 4915) Memory: 1.6M CPU: 7ms CGroup: /system.slice/nginx.service ├─22133 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf └─22134 nginx: worker process
Testez l'équilibreur
curl -k https://172.26.133.161:16443 | wc -l % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 233 100 233 0 0 12348 0 --:--:-- --:--:-- --:--:-- 12944
Configurer kube-proxy pour fonctionner avec l'équilibreur
Une fois l'équilibreur configuré, modifiez le port dans les paramètres kubernetes.
kubectl edit -n kube-system configmap/kube-proxy
Modifiez les paramètres du serveur en https://172.26.133.160:16443
Ensuite, vous devez configurer kube-proxy pour fonctionner avec le nouveau port
kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-9cjtp 1/1 Running 1 22h 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 1 22h 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 4 22h 172.26.133.162 kube-
Nous supprimons tous les pods, après leur suppression, ils sont automatiquement recréés avec les nouveaux paramètres
kubectl delete pod -n kube-system kube-proxy-XXX ```bash . ```bash kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-hqrsw 1/1 Running 0 33s 172.26.133.161 kube-master01 kube-system kube-proxy-kzvw5 1/1 Running 0 47s 172.26.133.163 kube-master03 kube-system kube-proxy-zzkz5 1/1 Running 0 7s 172.26.133.162 kube-master02
Ajout de nœuds de travail au cluster
Sur chaque note fondamentale, exécutez la commande générée par kubeadm
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX --cri-socket /run/containerd/containerd.sock --skip-preflight-checks
Si la ligne est "perdue", vous devez générer un nouveau
kubeadm token generate kubeadm token create <generated-token> --print-join-command --ttl=0
Sur les nœuds de travail dans les fichiers /etc/kubernetes/bootstrap-kubelet.conf et /etc/kubernetes/kubelet.conf
valeur variable du serveur à notre virtip
vim /etc/kubernetes/bootstrap-kubelet.conf server: https://172.26.133.60:16443 vim /etc/kubernetes/kubelet.conf server: https://172.26.133.60:16443
Et redémarrez containerd et kubernetes
systemctl restart containerd kubelet
Installation du tableau de bord
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
Créez un utilisateur avec des privilèges d'administrateur:
kubectl apply -f kube-dashboard/dashboard-adminUser.yaml
Nous obtenons le jeton d'entrée:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Configuration de l'accès au tableau de bord via NodePort sur VIRTIP
kubectl -n kube-system edit service kubernetes-dashboard
Nous remplaçons la valeur de type: ClusterIP par type: NodePort et dans la section port: ajoutez la valeur de nodePort: 30000 (ou le port dans la plage de 30000 à 32000 sur lequel vous souhaitez que le panneau soit accessible):

Le panel est désormais disponible sur https: // VIRTIP: 30000
Heapster
Ensuite, installez Heapster, un outil pour obtenir des métriques des composants du cluster.
Installation:
git clone https://github.com/kubernetes/heapster.git cd heapster kubectl create -f deploy/kube-config/influxdb/ kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml
Conclusions
Je n'ai remarqué aucun problème particulier lors de l'utilisation de containerd. Une fois, il y a eu un problème incompréhensible avec un foyer après le retrait du déploiement. Kubernetes croyait que under avait été supprimé, mais under était devenu un "zombie" si particulier. Il restait à exister sur le nœud, mais dans le statut étendu.
Je crois que Containerd est plus orienté en tant que runtime de conteneur pour kubernetes. Très probablement, à l'avenir, en tant qu'environnement de lancement de microservices dans Kubernetes, il sera possible et nécessaire d'utiliser différents environnements qui seront orientés pour différentes tâches, projets, etc.
Le projet se développe très rapidement. Alibaba Cloud a commencé à utiliser activement conatinerd et souligne qu'il s'agit de l'environnement idéal pour l'exécution de conteneurs.
Selon les développeurs, l'intégration de containerd dans la plateforme cloud de Google Kubernetes équivaut désormais à l'intégration de Docker.
Un bon exemple de l'utilitaire de console crictl . Je vais également donner quelques exemples du cluster créé:
kubectl describe nodes | grep "Container Runtime Version:"

La CLI Docker n'a pas les concepts de base de Kubernetes, par exemple, pod et espace de noms, tandis que crictl prend en charge ces concepts
crictl pods

Et si nécessaire, nous pouvons regarder les conteneurs au format habituel, comme docker
crictl ps

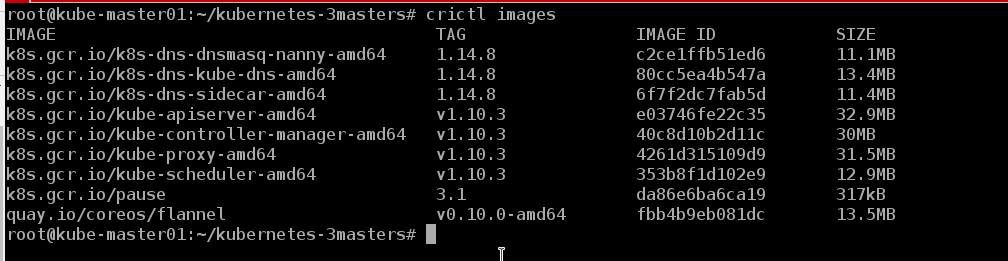
Nous pouvons voir les images qui se trouvent sur le nœud
crictl images
En fait, la vie sans docker est :)
Il est trop tôt pour parler de bugs et de bugs, le cluster travaille avec nous depuis environ une semaine. Dans un avenir proche, le test lui sera transféré, et en cas de succès, très probablement le stand de développement de l'un des projets. Il y a une idée à ce sujet pour écrire une série d'articles couvrant les processus DevOps, tels que: créer un cluster, configurer un contrôleur d'entrée et le déplacer vers des nœuds de cluster séparés, automatiser l'assemblage d'images, vérifier les images pour les vulnérabilités, le déploiement, etc. En attendant, nous examinerons la stabilité, chercherons des bugs et développerons de nouveaux produits.
En outre, ce manuel convient au déploiement d'un cluster de basculement avec docker, vous devez uniquement installer docker conformément aux instructions de la documentation officielle de Kubernetes et ignorer les étapes pour installer containerd et configurer la configuration kubeadm.
Ou vous pouvez mettre containerd et docker simultanément sur le même hôte et, comme les développeurs le garantissent, ils fonctionneront parfaitement ensemble. Containerd est l'environnement de lancement du conteneur konbernetes, et docker est comme docker)))
Le référentiel containerd possède
un playbook pour la configuration d'un cluster à assistant unique. Mais il était plus intéressant pour moi de «soulever» le système de mes mains afin de comprendre plus en détail la configuration de chaque composant et de comprendre comment il fonctionne dans la pratique.
Peut-être qu'un jour mes mains atteindront et j'écrirai mon livre de jeu pour déployer un cluster avec HA, car au cours des six derniers mois, j'en ai déployé plus d'une douzaine et il serait probablement temps d'automatiser le processus.
De plus, lors de la rédaction de cet article, la version kubernetes 1.11 a été publiée. Vous pouvez lire les principales modifications sur le blog Flant ou sur le blog officiel de kubernetes . Nous avons mis à jour les clusters de test vers la version 1.11 et remplacé kube-dns par CoreDNS. De plus, nous avons inclus la fonction DynamicKubeletConfig pour tester les capacités de mise à jour dynamique des configurations.
Matériaux utilisés:
Merci d'avoir lu jusqu'au bout.
Étant donné que les informations sur kubernetes, en particulier sur les clusters fonctionnant en conditions réelles, sont très rares dans RuNet, les indications d'inexactitudes sont les bienvenues, tout comme les commentaires sur le schéma général de déploiement des clusters. J'essaierai de les prendre en compte et d'apporter les corrections appropriées. Et je suis toujours prêt à répondre aux questions dans les commentaires, sur githab et dans tous les réseaux sociaux indiqués dans mon profil.
Cordialement, Eugene.