Une grande entreprise minière a proposé une tâche intéressante: il existe de nombreux sites dotés de systèmes informatiques. Ils sont situés à la fois dans les villes et dans les gisements. Il s'agit de plusieurs dizaines de bureaux régionaux et d'entreprises minières. 500 kilomètres dans la taïga sans route - facile! Dans chaque installation, il y a du matériel qui doit être «plié» dans une infrastructure commune et pour déterminer ce qui et dans quelle condition il fonctionne.
Ce qui était nécessaire ici n'était pas seulement un inventaire technique de tous les appareils sur le réseau (numéros de série, versions de logiciel, etc.), mais un système de surveillance complet. Pourquoi? Afin d'identifier les causes profondes des accidents et de les avertir rapidement, créer des cartes réseau, établir des connexions entre les équipements, surveiller l'état du fer et des canaux de communication, faire des avertissements sur la façon de quitter le support ou d'allumer de nouveaux équipements non comptabilisés, etc. En outre, l'intégration était requise avec CMDB (en tenant compte des unités de configuration), de sorte que tout le fer que le système de surveillance "trouvé" est comparé à ce qui est enregistré dans une branche particulière, c'est-à-dire en fait dans le réseau.
Un autre système de surveillance devait être «ami» de la téléphonie Asterisk, afin que ce dernier
en cas de situations d'urgence graves telles qu'une panne de courant sur le site de Krasnoyarsk, il pourrait automatiquement appeler rapidement les personnes responsables. Il s'agissait également de faire la distinction entre la visibilité des objets de surveillance et les pouvoirs des groupes d'utilisateurs. Les opérateurs s'occupent de l'équipement, Moscou - Moscou, les ingénieurs sur le terrain - uniquement leur domaine.
Le client a choisi entre plusieurs systèmes de surveillance: 1) produit shareware; 2) l'une des solutions commerciales; 3) Système Infosim StableNet. À la suite des tests, les inconvénients du produit shareware sont devenus évidents pour le client: il était long et difficile à configurer, et il ne disposait pas de la quantité de fonctionnalités requise (dans la même partie, par exemple, le rendu des connexions entre les appareils sur le réseau). Hors de la boîte, il ne sait pas comment faire, mais avec des plugins, cela se passe comme ça. Le produit commercial ne disposait pas d'agents de surveillance distribués - ceux-ci sont installés sur un site spécifique et ne contrôlent que leur «buisson». En conséquence, nous nous sommes arrêtés à Infosima - il a fermé toute liste de souhaits. Et c'est pourquoi.
Voici à quoi ressemble l'écran principal d'administration d'InfoSim StableNet (ce n'est pas un projet minéral, mais une infrastructure de test).
L'écran principal sur lequel l'état actuel du réseau est affiché:

Le panneau de contrôle est visible sur la gauche, dans lequel nous pouvons configurer le système et afficher les statistiques dont nous avons besoin. Par exemple, le bouton Analyseur vous permet d'afficher des statistiques pour tout paramètre que nous collectons, en particulier le temps d'aller-retour pour une période d'une heure pour un morceau de fer particulier.

Le bouton Inventaire affiche les données d'inventaire des objets de surveillance, les voisins, la table MAC pour chaque périphérique qui est dans le système. Incroyablement pratique: le processus de recherche de tout paramètre d'équipement dans le réseau par numéros de série, types d'équipement, versions de système d'exploitation, etc., est facilité.

Lorsque, quelque part loin dans la taïga, des employés locaux, par exemple, ont installé un nouvel interrupteur et n'en ont parlé à personne, il est immédiatement devenu visible dans le système. Cet équipement tombe dans une branche spéciale de l'arborescence des appareils «Nouveaux appareils» et automatiquement dans CMDB.

Les objets de surveillance sont interrogés non seulement pour les modèles et modèles série, mais également pour le chargement de la mémoire, des interfaces, etc. Il existe un support pour de nombreux fournisseurs - en particulier, les serveurs, le stockage, les équipements de télécommunications, les machines des utilisateurs finaux. Si quelque chose manque, le client nous écrit directement ou au vendeur et de nouveaux morceaux de fer sont ajoutés. Tout est simple.

Le système s'intègre aux serveurs MS Active Directory et RADIUS pour l'autorisation générale et l'application des stratégies de groupe. Voici à quoi ressemble l'architecture du système:
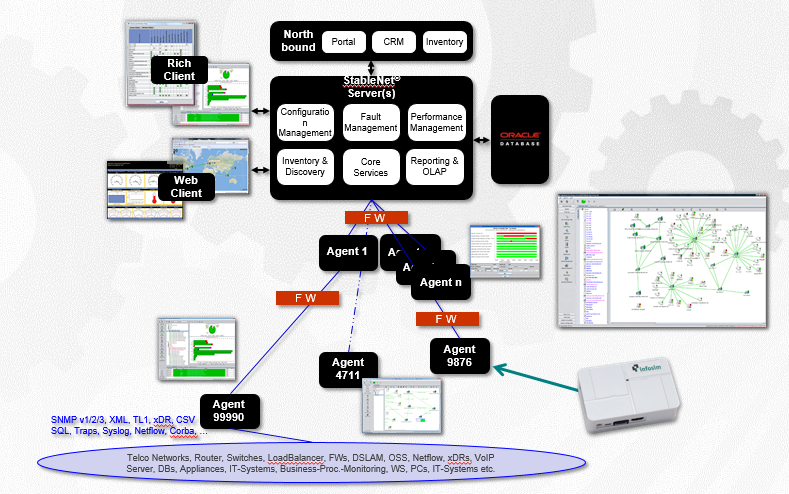
Le serveur central est responsable du traitement et de l'affichage des statistiques collectées à partir du matériel.
Le deuxième élément important est l'agent chargé d'interroger l'équipement et de vérifier la disponibilité du fer. Il peut y avoir plusieurs agents (logiciel distant), nous avons un sujet géo-distribué, avec un agent pour chaque site. Ceci est nécessaire afin de ne pas diriger le trafic de télémétrie brut vers l'organisation mère - le client dispose d'un grand nombre de sites connectés via des canaux satellites coûteux, donc seul le résultat de la mesure est envoyé. Et une base de données pour stocker tout ce qui est collecté.
Si le site distant n'est pas disponible, les employés sur place peuvent se connecter directement à l'agent et voir l'état de leur «bush» du réseau même sans accès au serveur central.
Un agent peut être un serveur x64 / x86 exécutant RedHat, CentOS, Ubuntu, Windows Server (pour les grandes plates-formes) ou un micro-agent basé sur de petits ordinateurs ARM comme Raspberry PI (pour les petites plates-formes). Nous ne chargeons pas le canal avec des pings de fer, l'agent le fait et il agrège déjà les paquets avec des statistiques.

Nous pouvons également supprimer les variations de délai, de gigue et de gigue pour les équipements Cisco (IP SLA) et Huawei (NQA). Par conséquent, si à l'avenir le client ajoute un autre fer à repasser, la société n'aura aucun problème - nous pouvons également aider à mesurer les indicateurs de qualité des canaux, effectuer des tests synthétiques et tester les canaux de communication entre les agents.
Le système de surveillance est capable de recevoir des messages syslog, des pièges SNMP de fer, de les filtrer et de générer des messages d'alarme. Il construit automatiquement la topologie aux niveaux L2 et L3, et sur cette base, les dépendances des situations d'urgence (analyse des causes profondes) sont automatiquement configurées. C'est très cool, car cela permet aux administrateurs d'être informés de la cause profonde de l'accident, réduisant ainsi le temps nécessaire pour le résoudre. Par exemple, si dans une chaîne de cinq commutateurs, un au milieu tombe, nous recevrons un message indiquant que le troisième commutateur (cause racine) est tombé et que les quatrième et cinquième sont inaccessibles à cause de cela.

La solution est prête à l'emploi, mais le processus peut être personnalisé. Ainsi, par exemple, pour faciliter le travail de notre support technique, nous avons «ajouté» l'état de l'alimentation sans coupure et l'état de l'alimentation: si l'alimentation sur le site est coupée, alors au lieu de 30 alarmes, nous en obtenons une pour l'alimentation. La corrélation se produit selon la topologie, les utilisateurs et les règles.
Il y a une configuration de groupe d'équipements, vous pouvez non seulement interroger passivement le matériel, mais déployer des configurations comme les paramètres sur les commutateurs. Enregistrer vlan ou ntp sur 40 commutateurs? C'est facile!
Il est également très cool que le système permette au client de sauvegarder la configuration de l'équipement selon un calendrier: collecter les configurations une fois par jour ou pendant un événement (par exemple, un message sur un changement de configuration arrive - vous pouvez configurer une tâche qui fonctionnera au moment où l'événement se produit et collecter la configuration modifiée). La même chose vaut pour les rampes, pour les événements d'urgence. Cela facilitera grandement le «débriefing» et la recherche des principaux coupables des changements de configuration. De plus, en fait, une base de données à jour de toutes les configurations de périphériques sur le réseau est créée.
Il existe une API pour l'intégration. Dans notre projet, le suivi de l'intégration avec CMDB 1C a été réalisé: ITIL Enterprise information technology management pour stocker toutes les informations sur les équipements (immobilisations corporelles). Les informations de l'enquête sont comparées à ce qui se trouve dans les actifs, lorsqu'il détecte des équipements non comptabilisés, le système dit: "Voici un interrupteur incompréhensible." Découvrez ce que c'est, ils obstruent tous les champs nécessaires - l'emplacement d'installation, le nom, etc. Le numéro de série, le nom, le numéro de pièce et la version du firmware sont obtenus à partir du matériel. Ensuite, la tâche est envoyée à la surveillance - le nom de la pièce de fer dans le système est modifié, défini à la position correcte dans l'arborescence d'emplacement, les paramètres de surveillance sont appliqués en fonction du type de pièce de fer (par exemple, l'équipement périphérique doit être interrogé plus souvent que les autres), le nom d'hôte sur l'appareil lui-même change, etc. d.
Processus sur le terrain
Tout d'abord, nous avons mis en place l'intégration avec AD. Cela nous a facilité la vie lors de la mise en œuvre, ainsi que lors des opérations ultérieures. Pas besoin de créer et de supprimer des comptes pour les utilisateurs à chaque fois. Le système recevra automatiquement tous les comptes actifs d'AD. Si soudainement quelqu'un quitte, le système lui-même désactive ce compte à la maison et personne d'autre ne peut y entrer.
Pour les administrateurs et les cadres intermédiaires, une tâche très urgente était d'obtenir beaucoup de rapports. Lors du lancement, des rapports sur l'utilisation et l'accessibilité des canaux, sur la disponibilité des presse-étoupes sur les sites, les situations d'urgence les plus fréquentes, des rapports sur des types d'accidents spécifiques, des versions de système d'exploitation, des rapports sur les changements de configuration des équipements, etc. ont été configurés.
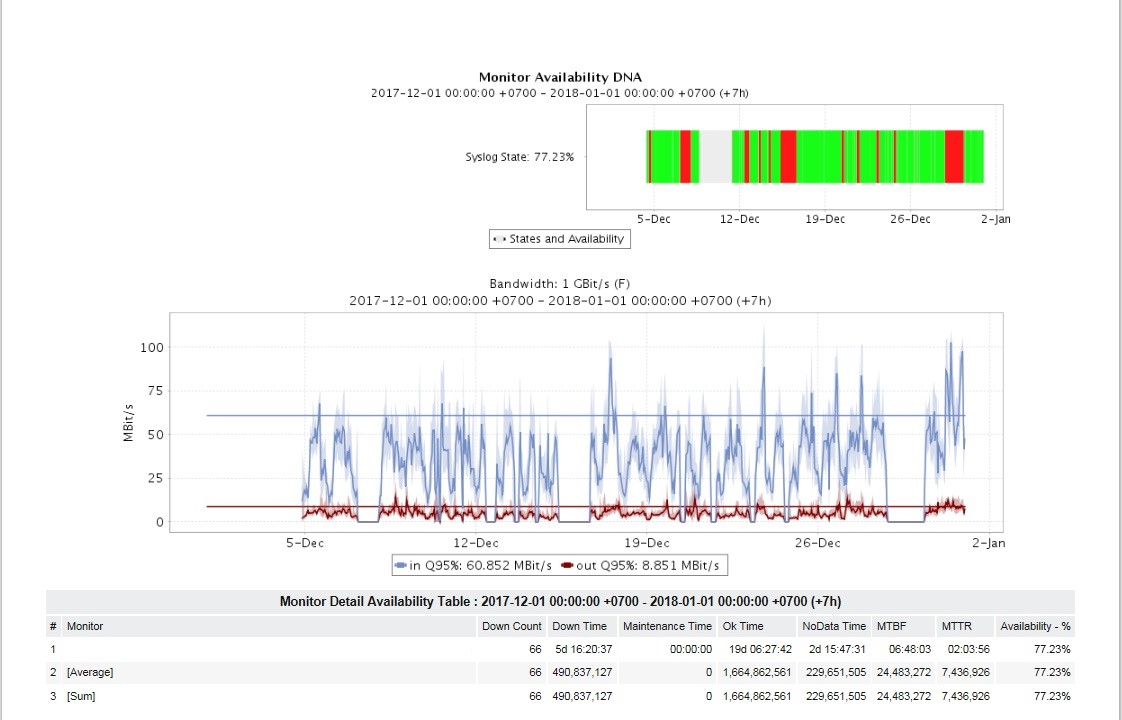
Les rapports peuvent être consultés au format HTML, reçus par courrier aux formats PDF et XLSX avec la fréquence souhaitée (une fois par jour, semaine, mois, etc.). Pour différents rapports, sa fréquence et son ciblage personnel du consommateur de rapports ont été définis.
Le système a également la possibilité de notifier et d'effectuer des actions personnalisées en cas d'urgence, peut envoyer des messages électroniques, des messages SMS (à l'aide d'une passerelle SMS externe), ainsi que rédiger vos propres scripts qui seront lancés. Par exemple, nous avons créé un bot Telegram dans notre service de surveillance cloud, qui informe les employés responsables de notre service d'exploitation des situations d'urgence. Il peut également être interrogé pour divers paramètres: «CPU, 10.1.1.100» renvoie «95%», mais étant donné le support d'une application mobile, cela peut sembler un peu redondant, bien que pratique.
Ensuite, nous avons écrit un script pour l'intégration avec le central téléphonique. Maintenant, lorsqu'une situation mégacritique survient (panne de courant sur des sites critiques ou des centres de données), le système appelle des personnes responsables sur les téléphones mobiles et d'une voix comme Siri dit: "La tension à un tel objet est en dessous d'un niveau critique." Cela se fait tout simplement: l'accident est dupliqué dans un dossier spécifique du central téléphonique, où il est traité par le service de téléphonie - il suffit de spécifier à l'avance les numéros auxquels appeler automatiquement. En fait, nous avons automatisé le processus de notification aux administrateurs ou à la direction responsables en cas d'accident. En d'autres termes, ils ont remplacé la personne qui devait appeler et signaler l'accident.
Fonction de recherche très pratique pour les utilisateurs et les glandes. L'utilisateur appelle, dit: "Mon réseau ne fonctionne pas." Par son adresse IP, vous pouvez immédiatement voir où il est connecté (quel commutateur, quel port, quel pavot) et où il est connecté avant:

Vous pouvez créer différents types de topologies graphiques qui facilitent la vie des ingénieurs. Vous devez, par exemple, voir où nous avons une sorte de commutateur. C'est simple: ils l'ont trouvé dans la bonne branche (ou ont utilisé la recherche) et ont ouvert ses voisins. Plusieurs niveaux de voisinage sont pris en charge (le premier est voisin immédiat, le second est voisin de voisins, etc.). Et vous pouvez voir immédiatement où se trouve notre commutateur dans la topologie, quels ports et où il est connecté, quelles adresses de pavot sont sur les ports. Ou regardez la carte de protocole OSPF, BGP, EIGRP, STP, PIM, MPLS - le système traitera et dessinera tout cela lui-même.

Ou voyez visuellement comment le réseau "se sent" sur l'un des sites. Pour plus de commodité, nous avons divisé les parties des sites WAN et LAN et les avons dessinées avec des cartes distinctes. Tous les indicateurs et liens sont interactifs. Lorsque vous passez la souris dessus, vous pouvez voir l'état actuel et tomber dans n'importe quel appareil particulier. Je voudrais également attirer l'attention sur le fait que le schéma de Microsoft Visio, qui a été dessiné par l'ingénieur lui-même, est utilisé comme substrat pour un tel rapport. Il a vu ce schéma à plusieurs reprises comme une image statique sur papier ou sur écran. Maintenant, il «prend vie» et fournit une rétroaction en temps réel. Très confortable.

Conformément aux exigences du client, les droits d'accès des utilisateurs ont été délimités. Il existe de nombreux rôles, mais ils sont configurés de manière flexible. Étant donné la différence de fuseaux horaires entre les objets, la caractéristique des heures de travail dans les rôles a été très utile: à quelle heure, pour quels accidents, à qui SMS et ainsi de suite.
InfoSim StableNet collecte des statistiques sur les incidents. Selon notre expérience, dans de tels cas, il y a des problèmes avec le travail prévu - ils gâchent les rapports et causent des soucis inutiles. On peut noter ici qu'ici et là il y aura du travail: alors les alarmes passeront en mode silencieux, et le rapport indiquera dans une couleur différente que ce temps d'arrêt est un plan. Oui, les activités prévues ne sont pas annoncées rétroactivement.

S'il n'y a pas suffisamment d'opportunités prédéfinies, vous pouvez créer des modèles auto-écrits. Par exemple, il y avait des points d'accès Motorola sur le projet. Il n'y avait pas de modèles prêts à l'emploi pour eux. À l'aide de «l'assistant» intégré, nous avons créé des modèles et surveillé les paramètres que le client voulait voir (niveau du signal, rapport signal / bruit).
Il y a eu un autre cas où le système «n'a pas compris» un fabricant russe et a montré le code du fabricant au lieu d'un nom. Dans ce cas, le système possède des fonctionnalités qui vous permettent d'ajouter de nouveaux fournisseurs et modèles de matériel en quelques secondes.
Voici la liste des fonctionnalités que le système de surveillance permet actuellement au client d'effectuer:
- Surveillez la disponibilité à l'aide des pings ICMP.
- Collectez des informations à l'aide de SNMP.
- Analyser les sous-réseaux pour de nouveaux matériels.
- Envoyez des rapports par période.
- Implémentez des configurations de sauvegarde.
- Analysez la disponibilité.
- «Sonner l'alarme» sur l'indisponibilité de l'équipement ou la sortie d'indicateurs en dehors de la plage normale.
- Script SNMP pièges comme déclencheurs, données Syslog et toute entrée.
- Intégration avec AD.
- Détectez automatiquement la connectivité des périphériques (CDP, LLDP, quartier L3) et en fonction de cela, dessinez automatiquement une carte réseau.
- Créez des "cartes météo" pour visualiser l'état du réseau avec la possibilité d'utiliser des substrats graphiques.
- Créez des écrans de travail (tableaux de bord) pour afficher des informations opérationnelles sur l'état du réseau et des appareils.
- Effectuer un inventaire des équipements (type d'équipement, fabricant, modèle, version du logiciel, date de fin d'EoS / EoL, etc.)
- Il existe une API REST pour une intégration approfondie avec CMDB 1C et d'autres systèmes externes.
- Effectuez la configuration de groupe des équipements à partir du système de surveillance.
- Vérifier la configuration de l'appareil pour les politiques de l'entreprise
Les références
-
Vélos de support de première ligne.-
Canaux de communication pour les gisements minéraux.- Mon mail: DDrozhzhin@croc.ru